[go to paper: pdf]
본 논문의 주제인 Active Teacher는 무엇인가요?
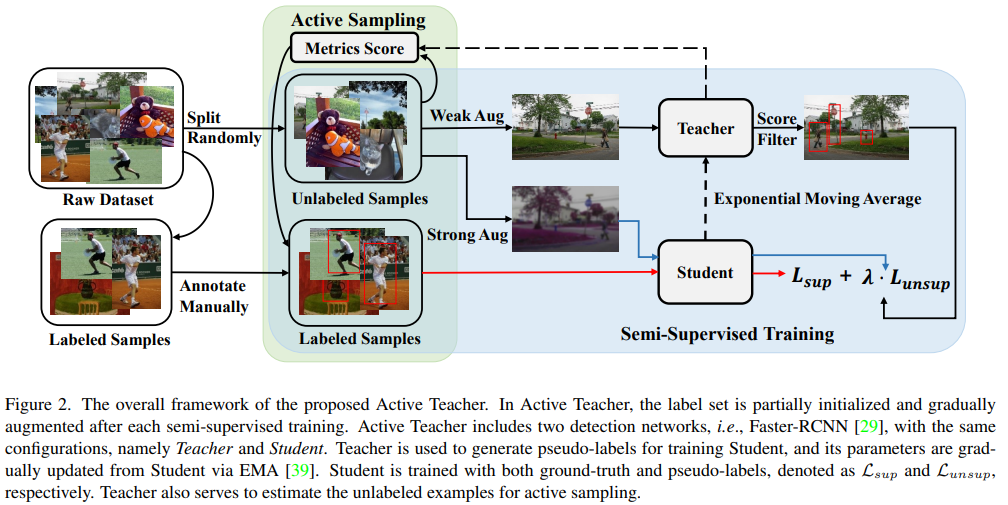
Active Teacher란 active learning의 특징처럼 “주기적인 학습”을 하며 “teacher-student 구조를 갖는” 형태의 학습을 의미합니다. 즉, 프로세스를 순차적으로 설명하자면 다음과 같습니다. 먼저 labeleld pool과 unlabeled pool을 통해 teacher와 student 모델의 학습을 진행합니다. 이후 teacher network를 통해 unlabeled examples에 대한 선별 과정을 거치며, 선별된 데이터는 labeled pool에 포함됩니다. 재구성된 labeled pool과 unlabeleld pool은 다음 주기에서 teacher, student 모델 학습을 위해 사용됩니다.
해당 논문은 어떤 특이점이 있나요?
본 논문은 기존 teacher-student 구조에 active learning을 접목했을 뿐만 아니라 semi-supervised learning 도 적용하였는데, 해당 기술이 image classification task가 아닌, object detection를 위해 디자인 되었다는 것이 포인트입니다. 많은 active learning기술이 image classification task를 중점으로, 혹은 해당 태스크만 지원하도록 설계되었다는 것은 지난 세미나 등을 통해 아실꺼라 생각됩니다. Semi-supervised learning 도 마찬가지 인데요, Semi-supervised learning의 큰 두개의 축인 consistency based approach와 pseudo labeling을 모두 사용한 대표적인 semi-supervised 연구인 fixmatch[paper] 역시 image classification task에 대한 벤치마크만을 제공합니다. ground truth 정보 없이 모델 자체의 지식이나, 데이터에 대한 예측의 분포를 통해 학습하는 semi-supervised 연구는 학습 단계가 불안정성이 높은 위험을 내재하고 있기에 비교적 쉬운 태스크인 image classification에 적용이 우선시되어 task의 확장을 필수적으로 요구하지 않기도 합니다. 하지만 아무리 좋은 기술이라도, 실제 상황에 사용되기 위해서는 image classification이라는 하나의 태스크에 만 제한되면 안되겠지요.
본 논문은 task 확장을 위해 Semi supervised learning 의 학습 불안정성을 낮추기 위한 설계를 진행하였습니다. Object detection을 위해서는 two stage 방법론인 Faster-RCNN을 이용하였고, 수식은 아래와 같이 supervised learning loss인 L_sup와 unsupervised learning loss인 L_unsup으로 구성됩니다. L_sup은 기존 faster-rcnn에서 ground truth를 통해 학습하는 방법과 동일하게 classification loss와 localization loss로 구성됩니다. 그러나 L_unsup은 RPN의 예측값을 활용하되, 그 결과값을 학습에 사용하지는 않습니다. 즉 unlabeled data에 대한 RPN의 예측 영역에 대한 pseudo label을 teacher network로 생성하고 pseudo lablel과 unlabeled data 쌍을 통해 student network를 학습시킵니다.
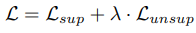
또한 teacher 모델도 student 모델의 학습이 끝나면 업데이트가 되는데, 이는 Exponential Moving Average(EMA) 방식을 이용합니다. 수식은 아래 수식2와 같습니다. EMA를 처음 보시는 분은 업데이트 된 student의 파라미터를 teacher network에 반영하되, 급격한 변화를 막기위해 a 가중치 만큼 기존 파라미터(θt)를 보존하여 업데이트하는 것으로 이해하시면 됩니다.
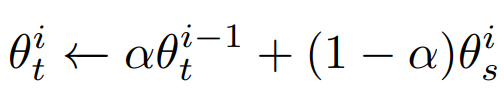
결국 정리하면 논문에서 제안하는 active teacher의 알고리즘은 아래와 같습니다.
먼저 수식1로 student 모델을 학습하고 / 수식 2를 통해 teacher 파라미터를 업데이트 한 후 / teacher network를 이용해 unlabeled pool에서 고가치 데이터를 선별하여 labeled pool을 보충합니다. 이후 재구성된 labeled pool과 unlabeled pool을 통해 student 모델의 학습을 다시 진행하는 반복을 k회 만큼 진행합니다.

그렇다면 고가치 데이터는 어떻게 선별하나요?
본 논문의 특이한 점은 고가치 데이터의 기준을 다양하게 제시하고 이에 대한 실험을 제공한다는 것입니다. 논문에서는 Difficulty, Information, Diversity를 기준으로 제시하였으며, 최종적으로는 AutoNorm이라는 Metrics combination 방법론을 제안합니다. 먼저 각 기준에 대해 살펴보겠습니다.
Difficulty는 Active Learning에서 쉽게 볼 수 있는 uncertainty와 유사하다고 볼 수 있습니다. 실제 연산 과정은 수식3과 같습니다. unlabeled data에 대한 예측의 entropy를 측정하는 수식인데요, 각 기호를 말씀드리자면, nb는 예측한 bounding box 수(nms와 confidence filtering 이후의 실제 예측한 bounding box 수 입니다), Nc는 teacher networks의 예측할 category 갯수 입니다. 다음으로 P(a;b,c)는 예측 확률값인데 c 파라미터를 갖는 네트워크를 통해 b를 c라고 예측할 확률입니다.
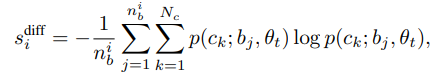
다음으로 Information은 수식4와 같습니다. confidence(a_j, b) 는 teacher network가 예측한 j 번째 바운딩박스(a_j)의 가장 높은 confidence scores를 의미합니다. 수식3과 4 모두 기존 classification task에서는 image 단위로 측정하던 것을 bounding box 단위로 계산하여 object detection task에 적합하도록 변형한 연산 방식입니다.
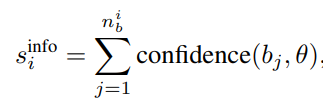
위의 두 방법론은 uncertainty based active learning 에 가까웠다면 Diversity는 diversity based active learning에 가깝습니다. 본 논문에서 diversity score를 계산하는 방법은 수식5와 같습니다.
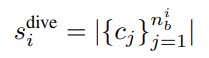
c_j는 j번째 bounding box에 대한 예측 클래스이며, n_b은 이미지i에서 예측된 bounding box 들을 의미합니다. |.| 는 집합의 크기를 의미하며, 이미지i에 포함된 class의 다양성을 측정할 수 있는 수식입니다.
본 논문은 제안한 세가지 지표를 AutoNorm이라는 방법으로 결합하여 active learing의 데이터 가치판단을 진행합니다. 결합을 위한 프로세스는 다음과 같습니다. 먼저 세가지 지표의 스케일이 다르기 때문에 모든 지표에 대해 수식6과 같이 가장 큰 스코어로 전체 스코어를 나누는 normalization을 진행한다고 합니다.
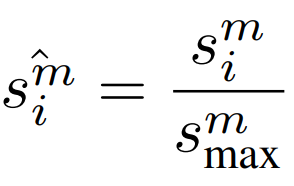
이후 세가지 스칼라 값으로 구성한 벡터 s(수식7)에 대한 normalization 값(수식8, L1 norm 이용)을 최종 데이터의 가치(S_Lp)로 이용합니다.
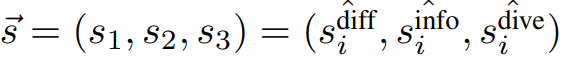
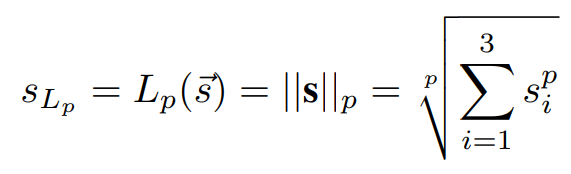
실험 결과는 어떠한가요?
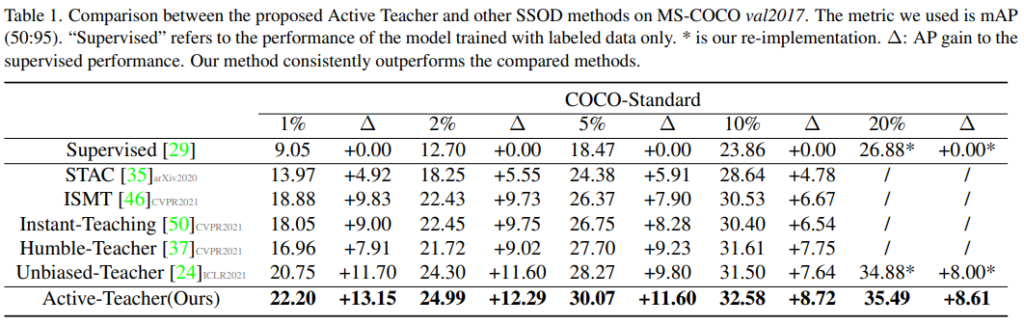
실험은 정량적 비교와 정성적 비교에 대해 모두 진행되었으며 대표적인 object detecion을 위한 benchmark data인 MS-COCO 로 진행했습니다. 정량적 성능은 최신 teacher-student 기반의 semi-supervised object detection 연구들과 비교되었습니다. 다양한 하이퍼파라미터가 수식에 사용되었는데 τ = 0.7, α = 0.9996, λ = 4, k=2 입니다. 기존 연구들이 labeled data 1%를 random으로 선별할 때, Active-Teacher(proposed)의 경우 0.33%를 random으로 선별하고 2번의 active selection을 통해 0.66(0.33+0.33)%를 선별한 격입니다. 실험 결과에서 먼저 주목할 점은 unlabeled data를 활용한 teacher-student 방법론 모두가 supervised learning 만을 이용한 것 보다 성능이 압도적으로 좋다는 점입니다. 또한 active selection을 통해 labeled pool을 구성한 active-teacher가 기존 방법론 대비 높은 성능을 보임을 알 수 있습니다.
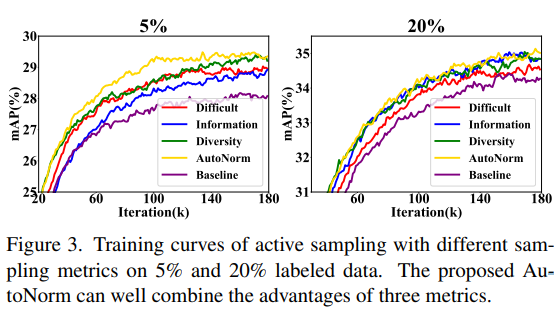
아래는 제안하는 selection 지표들에 대한 ablation study 입니다. 예산이 적은 경우 특히 autoNorm 방법론이 좋은 퍼포먼스를 보임을 확인할 수 있습니다. 또한 baseline인 random 대비 높은 효율성을 보임으로서 제안하는 지표들이 각각 데이터 가치 설계를 위한 합당한 지표였음을 보였습니다.
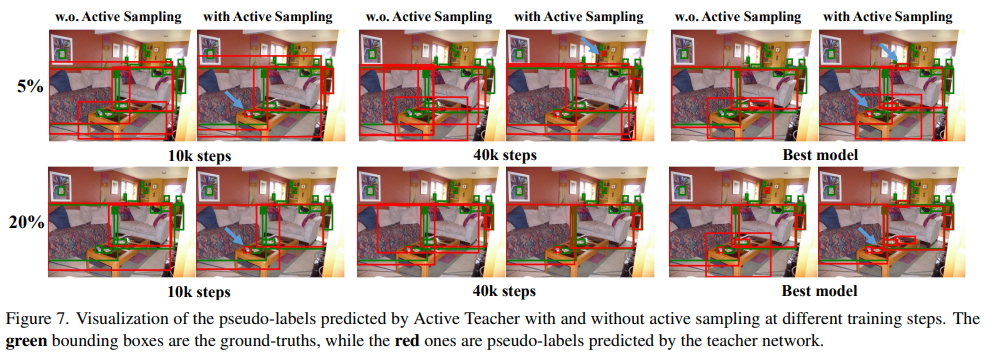
마지막으로 정성적 성능입니다. Figure 6은 각 지표에 대한 ablation study 결과의 확장으로 보시면 되고, 더욱 중요한 그림은 아래의 figure7입니다. figure 7에서 녹색박스는 이미지 내 ground truth이고 붉은 박스가 teacher network로 예측한 결과 입니다. 전체적으로 w.o active sampling 결과가 with active sampling 결과에 비해 ground truth box와 유사하며 그림 내부의 파란색 화살표로 강조했듯이 작은 object에 대해서도 더욱 정확한 예측을 했음을 보입니다. 해당 결과를 통해 localization과 classification 퍼포먼스 모두가 개선되었음을 짐작할 수 있습니다.

마지막으로 하실 말씀이 있으시다면?
본 논문은 active learning for object detection 이라기 보다는, object detection을 위해 좋은 초기셋을 구성하는데 active learning 아이디어를 차용한 것으로 볼 수 있습니다 (제목 그대로 이해하시면 됩니다 ㅎㅎ)
사실 active learning for object detection 논문을 읽고싶었지만.. active learning의 다양한 활용성을 알기 위해 좋은 논문이였던것 같습니다. 본 논문을 읽으면서 active learning 뿐 만 아니라 semi-supervised learning에서도 좋은 initalization set을 구성하려는 시도를 보아서 반가웠습니다. 이상입니다.
안녕하세요. 질문이 몇가지 있어서 드립니다.
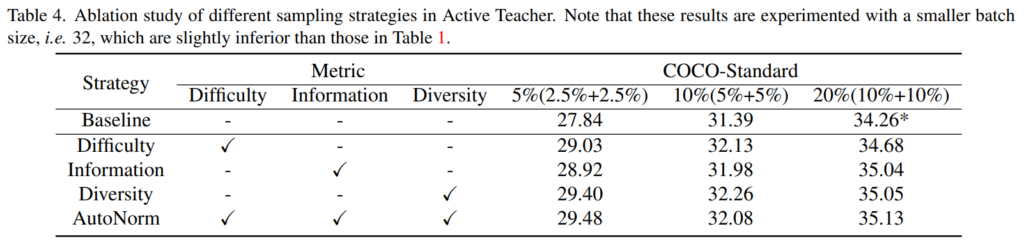
1. Table4 Ablation study에서 baseline은 무엇을 의미하나요? supervised learning만을 진행한 것이 baseline으로 생각했는데 그렇기에는 Table1에서의 supervised랑 성능이 다른 것 같아서요. caption에서 배치크기의 차이로 인해 성능이 조금 다를 수 있다고는 하지만 supervised랑 baseline이랑 9% 가까이 차이나는 것은 아닐 것 같고.. baseline으로 사용한 다른 방법론이 따로 있나요?
2. 만약 있다면 해당 방법론도 역시나 active learning 계열일테니 Difficulty와 Information, Diversity 중에 어떤 방식을 따로 차용한 것 아닌가요? 아니면 active teacher처럼 데이터 샘플링을 설계한 것이 아닌 단순히 랜덤 샘플링한 데이터를 teacher model에게 입력으루 주어 distillation하는 단순한 방법론으로 이해하면 되나요?
3. 마지막으로 Difficulty, Information, Diversity 방법론 모두를 적용한 AutoNorm과 그냥 Diversity 하나만을 사용하는 것과 성능 차이가 거의 나지 않는 것 같습니다. (오히려 10%의 경우에는 Diversity 단독으로 사용하는 것이 더 좋기도 하구요.)
저자는 그럼에도 불구하고 AutoNorm을 사용해야 된다는 이유로 무엇을 이야기하나요? 저는 이 분야를 잘 몰라서 하는 말일 수도 있지만 저렇게 sampling 전략을 다양하게 하는 것 역시도 cost를 많이 소모할 것 같은데, 성능에 큰 이점이 없다면 단순하게 Diversity 기반 방법 하나만 적용하는 것이 더 단순하면서도 효율적이라고 볼 수 있지 않나요?
감사합니다.
안녕하세요 좋은 질문 감사합니다
Table 4의 baseline은 Random 선택을 통해 학습 데이터를 지속적으로 보충한 것으로 제안한 가치판단을 통한 데이터 선별의 효용을 보여주기 위한 실험입니다. Table1의 supervised learning은 이러한 보충을 진행하지 않은 것 입니다. 즉 Table 1은 1%의 데이터만 사용하거나, 5%, 10% 의 데이터만을 사용해 모델을 학습한 것이고, baseline은 active learnig setting 과 유사하지만 데이터 선별과정시 랜덤으로 labeled data를 추가한 것입니다.
모든 질문이 해당 설명의 누락으로 발생한 질문으로 보입니다
부족한 부분을 알려주셔서 감사합니다.
3번에 대한 답변을 잊었네요 ㅎㅎ
우선 대표적인 active learning 연구 갈래 중 하나인 pool based active learning 은 많이 저장된 unlabeled pool에서 고가치 데이터를 선별하는 방법론입니다. 해당 알고리즘에서는 일반적으로 데이터 선별과정에 대한 연산량이나 속도 보다는, 효율적인 데이터 선별을 통한 성능 향상을 중점적으로 다룹니다. 실제로 많은 active learning 연구들이 작은 폭의 성능 상승을 다루기도 하고요..
또한 잘 알려져있듯이 active learning의 대표적인 두 접근법인 diversity 지표와 uncertainty 지표는 서로 상호보완의 관계가 있는데요, 본 논문의 diversity와 information 지표 또한 그러합니다. 실험된 데이터셋에서는 성능 향상폭이 적을 수 있지만 실제 imbalanced set 등에서 active learning을 진행한다면 상호보완되는 두 지표를 사용한 것과 그렇지 않은 결과는 많은 차이가 납니다.
따라서 ablation study에 대해서는 세가지 지표가 서로 상호 보완이 가능하도록, 데이터의 다른 특징을 중점에 두고있음에 초점을 두시면 더욱 이해하시기 쉬울 것 입니다.