안녕하세요, 열한번째 x-review 입니다. 이번 논문은 CVPR 2022에 게재된 TransFusion으로 outdoor scene에서 RGB image와 point cloud를 fusion한 3D Object Deteciton 방법론 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
3D Object Detection에서 point cloud만으로도 좋은 결과를 낼 수 있는 모델들이 등장하고 있지만, 이렇게 LiDAR만을 사용하는 경우에는 훨씬 더 sparse한 point cloud로 이루어진 large scale의 데이터셋인 (ex. nuScenes, Waymo)에서 camera data와 함께 사용하는데 비해 성능이 저하될 수 있다고 합니다. 물체가 작거나 멀리 있다면 LiDAR 센서로는 감지하기 힘들겠지만, RGB 이미지에서는 그러한 물체까지 감지하고 구별할 수 있습니다. 이렇게 두 가지 모달리티의 장점을 모두 사용하기 위한 fusion 방법에 대한 연구가 진행되고 있는데, 크게 3가지로 나누어 생각해볼 수 있습니다. 먼저 result-level의 방법으로 3D proposal을 위해서 2D detector을 사용하는 방식이고, 두번째로 proposal-level 방법론은 각각의 모달리티에서 region proposal을 적용하여 얻은 proposal을 공유하여 RoIPooling을 적용하는 방식 입니다. 마지막이 주된 방식이라고 할 수 있는 point-level fusion 입니다. calibration matrix를 사용하여 point cloud와 이미지 픽셀 사이의 hard association을 찾는 방식인데요, 포인트를 BEV 평면으로 projection하여 BEV 픽셀과 이미지 feature을 fusion하는 방식이라고 할 수 있습니다. point-level fusion으로 성능이 개선된 것은 사실이지만 이러한 방식에도 두 가지 주요한 문제점이 존재하였습니다. 먼저 두 모달리티의 fusion이 element-wise addition이나 단순 concat으로 너무 간단하게 진행되어 만약 조도 변화와 같이 이미지가 낮은feature를 가지고 있다면 심각한 성능 하락에 원인이 될 수 있다는 것 입니다. 두번째는 위에서 언급한 것처럼 hard association은 찾는다는 것은 sparse한 포인트 클라우드 기준으로 이미지를 사용하게 되어 이미지에서의 semantic한 정보를 상당수 사용할 수 없게 되어 버리고, calibration matrix에 대한 의존도가 높다는 점 입니다. 일반적으로 내재하는 spatial-temporal misalignment 때문에 높은 퀄리티의 calibration matrix를 얻기가 어렵기 때문에 calibration matrix에 많이 의존한다는 것은 단점으로 적용하게 됩니다.
이러한 본래 point-level fusion의 문제점을 해결하기 위해서 본 논문은 위와 같은 misalignment와 이미지의 퀄리티에 강인할 수 있는 soft-association 기반의 fusion model을 제안하고자 하였습니다. 두 개의 transformer decoder layer을 사용하는 것이 핵심 아이디어로, 첫번째 decoder layer에서는 sparse한 포인트 특징들을 사용하여 초기 bounding box를 만듭니다. 단 2D에서는 입력에 의존하지 않는 object query를 만들지만 제안하는 방법론에서는 입력에 의존하면서 위치와 class 정보를 더 잘 전달할 수 있는 object query를 만들고자 하였습니다. 두번째 decoder layer에서는 의미있는 이미지 특징과 adative하게 fusion을 하는데, Method에서 더 자세하게 설명하도록 하겠습니. 저자는 또한 point cloud만으로 검출하기 어려운 물체들을 위해서 이미지에 기반한 query initialization module을 새롭게 제안하고 있습니다. 이러한 방법론을 제안한 본 논문의 contribution을 정리하자면 다음과 같습니다.
- 기존 LiDAR와 camera sensor fusion에 존재하는 어려움을 해결하기 위해 soft-association 기반의 알고리즘 구현
- 3D Object Detection을 위해 sensor misalignment와 이미지 quality에 강인한 새로운 transformer 기반의 센서 fusion model인 TransFusion 제안
- nuScenes 데이터셋에서 SOTA 달성
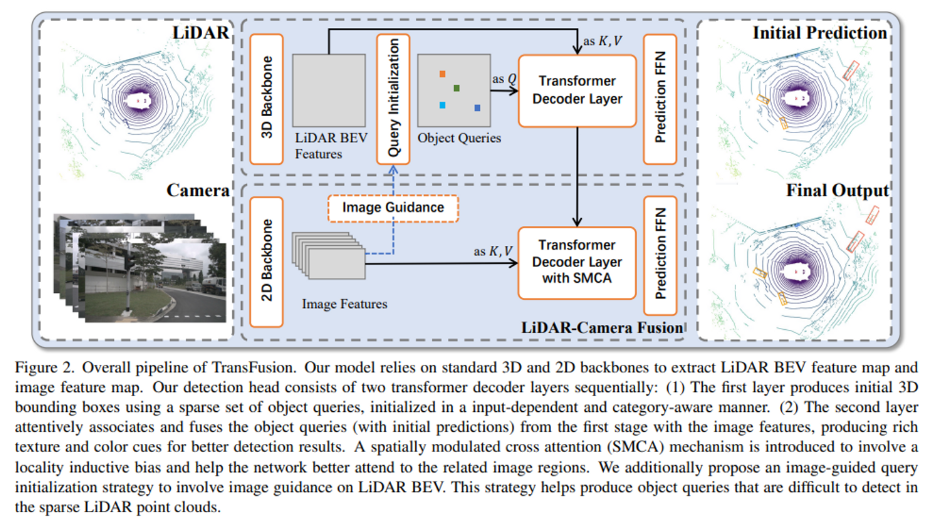
2. Methodology
TransFusion에 대해 간략하게 설명하면, LiDAR 센서의 데이터가 3D backbone을 지나 BEV 평면으로 projection한 feautre map과 2D backbone을 지난 이미지 feature map이 각각 주어지게 됩니다. 그럼 첫번째 transformer decoder layer에서 BEV feature에서 object query를 뽑아 초기 bounding box 예측을 위해 decoding하고 그 다음 decoder layer에서 이미지 feature와 adaptive하게 합치게 됩니다. TransFusion의 구조에 대해서는 아래에서 더 자세하게 살펴보도록 하겠습니다.
2.1. Query Initialization
기존 Detr과 같은 방법론에서의 query에서는 입력 데이터에 의존하지 않고 랜덤하게 생성되거나 learnable한 파라미터로 만들어졌습니다. 하지만 이렇게 입력과 관계없이 만들어지는 query의 경우에는 실제 object의 중심을 제대로 찾아가도록 하기 위해서 추가적인 decoder를 필요로 하였습니다. 하지만 본 논문에서는 하나의 decoder layer만을 사용하기 위해서 center heatmap을 기반으로하는 입력 데이터에 의존하여 만들어지는 query initialization을 제안하였습니다. d차원의 feature로 이루어진 X x Y x d 사이즈의 LiDAR BEV feautre map이 주어지면 convolution 연산을 통해서 class-specific heatmap이라는 것을 예측하게 됩니다. 여기서 K는 class의 수가 되겠죠. 예측한 heatmap을 X x Y x K개의 object 후보라고 간주하게 되고 그 중에 상위 N개의 후보를 초기 object query로 선택하게 됩니다. 서로 너무 가까이 존재하는 query들이 선택되는 것을 방지하기 위해서 하나의 후보에 대해서 인접한 8개의 이웃 query와 비교하여 가장 크거나 같은 후보를 초기 object query로 할당하였습니다. 이렇게 선택된 후보들의 위치와 feeature가 초기 query 위치와 feature을 initialization 하기 위해서 사용되는 것 입니다. 이러한 query initialization을 통해서 실제 object의 중심이 되는 곳과 가까워지도록 query가 위치할 수 있고 그렇기 때문에 위치를 더 개선하기 위해서 뒤쪽에서 여러개의 deocder layer가 추가적으로 필요하지 않게 됩니다.
또한 BEV 평면으로 projection을 한다고 하였는데, BEV 평면에서의 물체 같은 경우 같은 class를 가진 물체이면 비슷한 scale을 가지게 됩니다. 이러한 특징을 사용하여 multi class 물체를 더 잘 검출하도록 category embedding을 추가하였습니다. 위에서 얻은 object query의 feature와 one hot category vector을 \mathbb{R}^d vector로 linear projection하여 얻은 cetegory embedding을 element wise sum하여 각각의 object query에 category embedding을 추가해주는 것 입니다. 이렇게 추가한 category embedding은 attention 모듈의 계산에서 유용한 정보를 제공하는데 사용될 수 있습니다.
2.2. Transformer Decoder and FFN
본 논문의 Decoder layer는 기본적으로 DETR의 구조를 따라가고, object query와 feature 간의 self attention과 서로 다른 object query 간의 관계를 파악하는 corss attention으로 이루어져 있습니다. query의 positional encoding은 MLP를 태운 후에 query feature와 element-wise sum을 통해 embedding 됩니다. 보통 FFN을 통해서 box와 class를 예측하게 되는데, TransFusion은 추가적인 decoding 메커니즘으로 FFN과 각 deocder layer를 통과한 이후에 supervision으로 학습을 진행하도록 추가하여 첫번째 deocder layer에서도 초기 bounding box를 예측하도록 하였습니다. 그렇다면 이러한 prediction을 추가한 이유는 무엇일까요?
2.3. LiDAR-Camera Fusion
앞선 introduction에서 언급하였듯이 point-level의 fusion 방식의 성능은 포인트의 sparse함에 영향을 많이 받았습니다. 물체에 대한 포인트가 적은 수로 존재하게 되면 그 물체에 대해서는 이미지에서 또한 적은 feature만을 사용할 수 있기 때문에 이미지에서의 semantic한 정보들이 존재함에도 활용할 수 없게 됩니다. 이러한 문제를 해결하기 위해서 두 도메인 (포인트와 픽셀) 사이의 hard association에 기반하는 것이 아니라 soft association에 기반하고자 하였습니다. 모든 이미지 feauter을 F_C \in \mathbb{R}^{N_v \times H \times W \times d}의 메모리 뱅크로 유지하여놓고 corss attention 계산시 한 곳의 feature에 국한되는 것이 아니라 sparse하고 dense한 특징을 가진 서로 다른 두 도메인의 특징을 adaptive하게 사용할 수 있도록 하였습니다.
SMCA for Image Feature Fusion
본래 LiDAR와 image 사이의 hard association을 형성하기 위해서는 calibration matrix을 사용해서 포인트를 이미지 상의 위치로 변환하게 되는만큼 정확하지 않은 calibration matrix를 구하게 되면 엉뚱한 이미지 feature와 attention을 진행하게 될 수 있습니다. 그래서 soft association을 만들기 위해서 cross attention을 사용함으로써 이미지에서 포인트 특징과 대응하는 어떤 정보를 어디서 가져와야할 지 adaptive하게 결정하고자 하였습니다. multi-head attention 자체가 원래 두 입력 set 간의 soft accosiation을 형성하는데 널리 사용되는 메커니즘이며 feature matching task에서 흔히 사용되고 있다고 합니다. 그럼 어떻게 adaptive하게 사용할 수 있도록 설계하였냐하면, 우선 이전의 self attention에서의 예측과 calibration matrix를 사용합니다. object query가 이미지 차원에서 위치한 곳이 있을 것이고, 그 이미지 feature map과 object query 간의 cross attention을 우선 수행합니다. 그러나 두 데이터의 도메인이 워낙 다르기 때문에 object query가 원래 예측해야 할 이미지의 지역에 집중하지 못할 수도 있기 때문에 집중해야 할 적절한 영역을 인지하는데에 오랜 시간이 걸릴 수 있습니다. 그래서 저자가 제안하는 것이 spatially modulated cross attention (SMCA) 모듈인데요, 우선 원래대로 query들을 projection을 하고 projection을 했을 때의 2D에서 중심값을 구하여 2D circular 가우신 마스크로 cross attention에 가중치를 부여하는 모듈을 설계하였습니다.
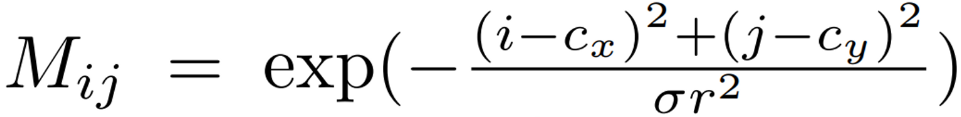
가우시안 마스크 M은 위의 식과 같습니다. 여기서 (i, j)는 가중치 마스크의 인덱스를 의미하고, (c_x, c_y)는 이미지 평면으로 projection된 이전 query의 prediction 결과의 center 값 입니다. r은 예측된 3D bounding box가 projection 되었을 때 corner 점들의 최소 원 반경을 의미하고 \sigma는 가우스 분포의 폭을 조정하는 하이퍼 파라미터 입니다. 위의 식으로 만든 weight map을 모든 attention head의 cross-attention map에 element-wise multiply 해줌으로써 각 ojbect query는 projection된 2D box에 인접하여 관련되어 있다고 정의할 수 있는 영역에 집중하기 때문에 이전에 비해 더 빠르고 정확하게 object query에 대응하는 위치의 이미지 feature을 찾을 수 있게 됩니다.

Figure 3에서 첫번째 행은 사용하는 이미지와 그 이미지에 projection된 예측 박스를 보여주고 두 번째 행은 SMCA 모듈을 지난 cross attention map을 나타냅니다. Figure 3을 통해서 fusion을 할 때에 feature로 사용할 이미지 픽셀을 유동적으로 사용할 수 있고 LiDAR의 포인트가 sparse하다는 사실이 주는 영향을 덜 받으면서 더 정확한 예측을 할 수 있다는 것을 보여주고 있습니다.
SMCA 모듈을 거치고 나면 앞선 decoder layer와 마찬가지로 FFN을 통해 포인트와 이미지 특징을 모두 이용한 최종 bonding box를 예측합니다.
2.5. Label Assignment and Losses
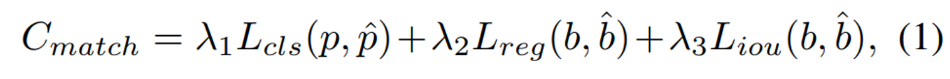
DETR에서처럼 matching 알고리즘으로 예측한 object와 GT object 사이의 bipartite matching을 찾는데, 그 때의 matching cost는 식(1)과 같습니다. classification loss L_{cls}에는 binary cross entropy loss를 사용하고 L_{reg}는 예측한 BEV의 center와 GT center 사이의 L1 loss를 사용합니다. 마지막으로 L_{iou}는 예측한 박스와 GT 박스 사이의 IOU loss를 의미합니다 .
전체 Loss는 식으로 표현되어 있지 않지만 간단하게 classification은 focal loss를 사용하고 positivie sample에 한해서 bounding box regression에 L1 loss를 사용합니다.
2.6. Image-Guided Query Initialization
여기까지의 구조만으로도 저자는 이미 높은 성능을 달성할 수 있다고 언급하면서도, 높은 resolution의 이미지를 사용하여 sparse한 포인트에 강인하게 small object detection과 같은 문제를 해결할 수 있는 image-guided query initialization을 추가적으로 제안합니다.
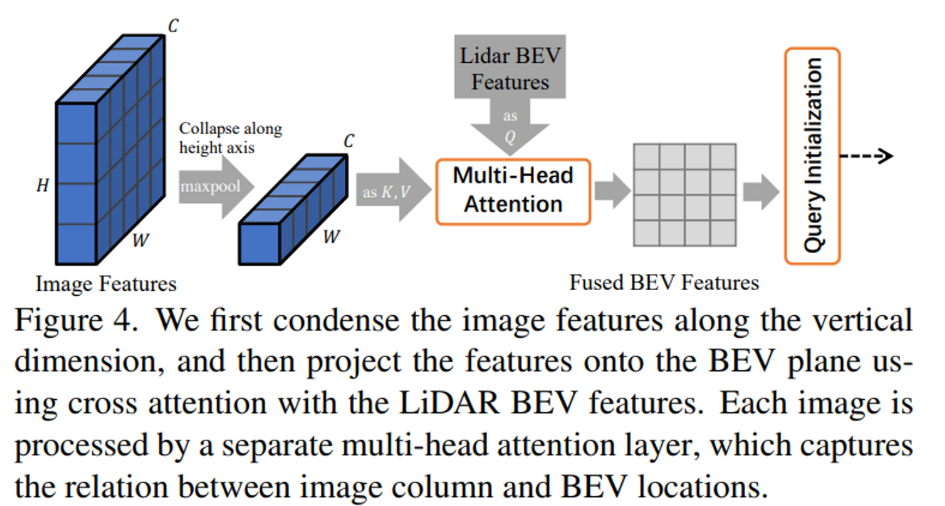
이미지 feature map을 Figure 4에서처럼 H축 방향으로 max pooling을 진행하여새로운 feature map을 만듭니다. 그리고 그 feature map을 LiDAR BEV feature map과의 cross attention을 위한 key, value 값으로 사용하여 최종 LiDAR-camera BEV feature map F_{LC}를 만들 수 있습니다. 그 뒤로는 query initialzation을 시작으로 위에서 설명했던 과정을 거치게 되는 것 입니다.
사실 해당 모듈이 포함되지 않으면 object query는 포인트만으로 만드는 것이기 때문에 LiDAR에서 거리가 멀거나 크기가 작아서 아예 포인트가 만들어지지 않는 물체가 존재할 수 있는데 그런 물체들을 놓치지 않기 위해 object query를 만들 때도 이미지를 고려할 수 있도록 이미지로 물체에 대한 가이드를 주는 것이라고 할 수 있습니다.
3. Experiments
실험은 outdoor dataset인 nuScenes와 Waymo로 진행하였습니다.
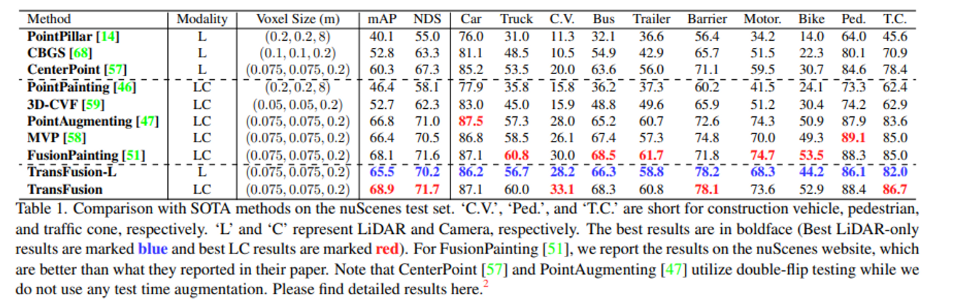
먼저 nuScenes에서의 실험 결과 입니다. Modality의 L/LC은 입력 데이터로 포인트 클라우드만을 쓰는지/이미지와 함께 쓰는지를 나타냅니다. 저자는 TransFusion이 두 모달리티의 데이터를 함께 쓰는 fusion 방법론이기는 하나 포인트 클라우드만을 데이터로 사용하는 방법론들 중에서도 SOTA를 달성하면서 해당 논문에서 제안하는 decoder module이나 query initialization만으로도 성능에 영향을 줄 수 있다고 주장합니다. 이미지까지 함께 사용하였을 때 역시 SOTA를 달성한 것을 확인할 수 있습니다.
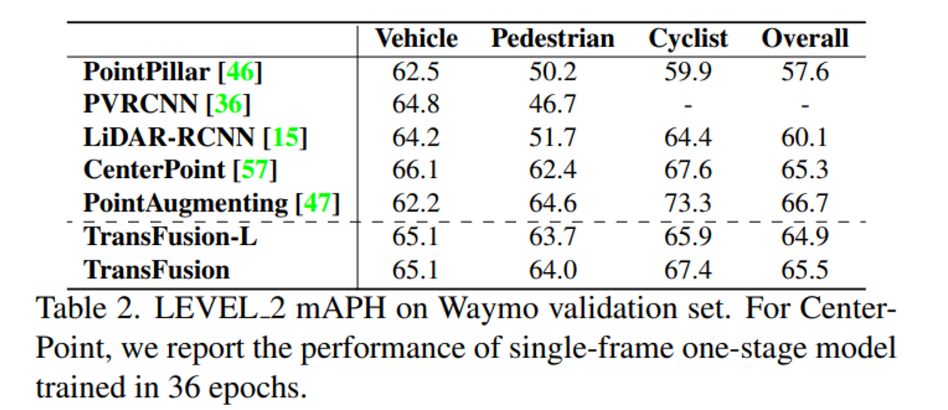
다음은 Waymo validation dataset에서 3개의 클래스에 대한 실험 결과인데, 여기서 nuScenes에서와 다른 점이라고 함은 nuScenes에서는 포인트만을 사용할 때와 fusion 했을 때의 성능 폭이 3-4 이상의 차이를 보여줬지만 Waymo에서는 거의 유사한 성능을 보이고 있다는 것 입니다. 저자는 이러한 결과에 대해 nuScenes보다 Waymo에서 제공하는 포인트 클라우드가 더 dense하기 때문에 첫번째 decoder을 통과한 초기 bounding box부터 이미 거의 정확한 위치를 예측하고 있기 때문에 fusion 했을 때의 두번째 decoder layer의 영향이 비교적 적었을 것이라고 분석하고 있습니다.
3.2. Robustness against Inferior Image Conditions
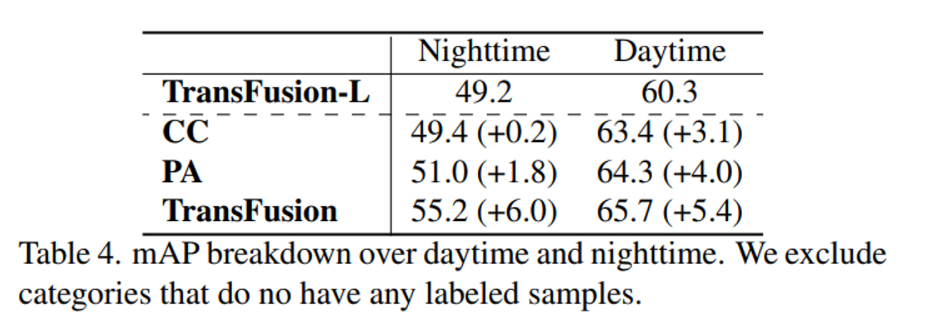
본 논문에서 정의한 문제 정의가 기존의 fusion 방식은 이미지 condition에 취약하다는 것이었는데요, fusion을 통해서 그러한 image condition에 얼마나 강인한지를 보여주는 실험 입니다. 두 데이터를 fusion하는 hard association 방법으로 CC(point-wise concatenation), PA(PointAugmenting)와 TransFusion을 비교합니다. image condition으로 낮과 밤의 환경에서 포인트 클라우드만 입력으로 사용하는 TransFusion을 베이스라인으로 비교를 했는데요, fusion 했을 때 타 방법론 대비 더 큰 폭으로 성능이 향상되는 것을 보면서 기존의 hard association보다 soft association인 TransFusion이 더 2D 이미지의 condition에 강인한지를 보여주고 있습니다.
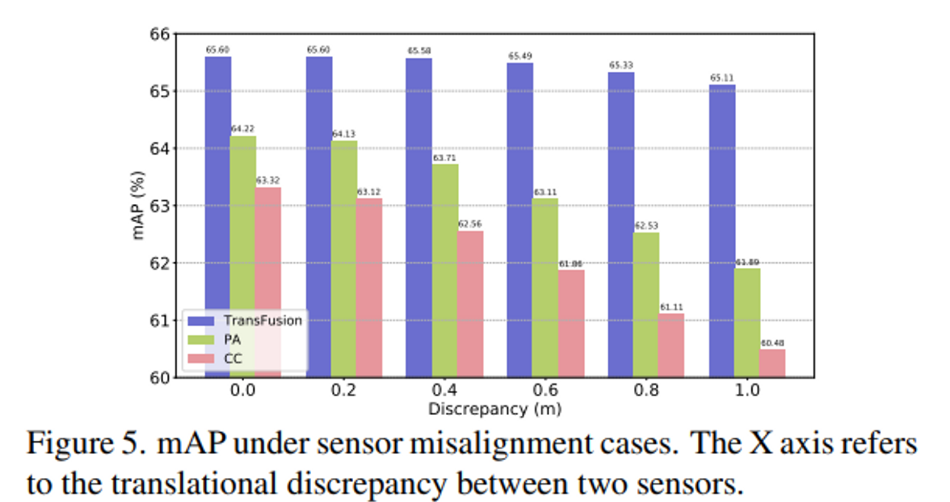
다음은 또 하나 문제점이라고 지적했던 센서의 misalignment에 TransFusion이 얼마나 강인한지에 대한 실험 결과 입니다. X 축이 misalignment가 얼마나 되어있는지를 나타내는 것으로 misalignment가 1m일 때 PA와 CC가 2.33%, 2.85%씩 성능이 하락할 때 TransFusion은 0.49% 정도의 하락만 하면서 이전 방법론 대비 misalgiment에 영향을 덜 받는다는 것을 보여주고 있습니다. TransFusion에서는 calibration matrix를 object query를 이미지에 projection할 때만 사용하며 attention 계산을 할 때에도 adaptive하게 연관되어 있는 이미지 특징을 찾을 수 있도록 설계하였기 때문에 calibration matrix에 큰 영향을 받지 않을 수 있다는 것을 실험적으로 확인하면서 리뷰 마치도록 하겠습니다.
좋은 리뷰 감사합니다.
bev로 projection해서 fusion하는 경우 cross attention을 통해 관심영역을 사전에 가중치를 부여하는 2 stage느낌이네요.
architecture그림을 보고 헷갈리는게 혹시 camera image는 multiple image가 입력되는건가요? figure2에서 이미지가 여러 장인 것으로 보여서 질문드립니다.
그리고 image-guided query initialization에서 Height방향으로 maxpooling을 하는 이유는 무엇인가요?
마지막으로 SMCA에서 gaussian masking을 적용했는데 혹시 다른 masking기법에 대한 비교실험은 없었는지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
먼저 camera image는 하나의 이미지씩 입력으로 들어가는 것으로 알고 있습니다. 그리고 height 방향으로 maxpooling을 하는 이유는 실험적으로 BEV 평면에서의 위치와 이미지 열 사이에서 보통 이미지의 열에는 최대 하나의 object만 관찰된다는 가정을 기반으로 한다고 합니다. 따라서 height 방향으로 축소를 하면 semantic한 정보를 잃지 않으면서 계산 비용을 줄이는 효과를 가져오기 때문에 height 방향으로 maxpooling을 진행합니다. 마지막으로 SMCA에서의 다른 masking 기법을 적용한 ablation study가 포함되어있진 않습니당.