안녕하세요. 이번 리뷰도 VQA 논문인데요. 이전에 RUBi 방법론이 2019년도 방법론으로 꽤 이전의 논문이라 최신 방법론은 어떤식으로 debiasing하고 있지?라는 의문이 들어 리뷰하게 되었습니다. 그럼 리뷰 시작하겠습니다.
<Introduction>
이전 리뷰를 통해서 VQA가 데이터셋 내의 bias에 취약하고 데이터셋 내의 존재하는 langugae biase에 매우 의존하는 경향을 보이는 것을 확인하였습니다. 그리고 VQA model이 image를 고려하지 않고 question에 기반하여 비슷한 answering을 예측하는 경향이 있다는 것 또한 확인하였습니다. 그래서 VQA 연구자들은 이에 대응하기 위해서 다양하게 bias를 줄이는 방법을 연구하고 있고, 최근에는 이전에 리뷰한 rubi와 같은 ensemble 기반 debiasing 방법이 광범위하게 활용되고 있다고 합니다.
ensemble 기반 방법 중에서는 각 modality 또는 데이터셋 내에 존재할 수 있는 bias를 동시에 학습하기 위해서 추가 모델이 도입되는 경우가 있는데요. 예를 들어서. RUBi와 같은 연구에서는 question-answer 모델을 활용하여서 모델에 question에만 기반하여서 answer을 주었을 때 존재하는 language prior bias를 판단합니다. 그런다음 이 question-answer 모델은 inference에 사용되는 robust한 “target” 모델을 학습하는데 사용됩니다. ensemble “bias” 모델의 key 목적은 주어진 입력으로부터 형성된 bias, 즉, question-answer model의 language prior bias를 포착하는 겁니다. 이 과정에서 이 모델이 bias를 잘 표현할 수 있다면 이 bias 모델을 사용하여서 target 모델에 대한 bias된 answer를 피하도록 학습시킬 수 있습니다. 그래서 위의 말을 정리하면 bias 모델이 bias를 더 잘 학습할수록 target 모델도 bias를 더 잘 피할 수 있다는 말입니다.

기존의 emsemble 기반 방법론은 training data의 사전에 계산된 label statistics를 사용하거나 question이나 image로부터 answer를 계산하는 single modal branch를 사용하였습니다. 그러나 모델의 representative capacity가 input에 의해 제한되어 있기 때문에 이러한 방법으로 얻을 수 있는 bias representation에는 한계가 있을 거라고 본 논문에서는 예상하는데요. 또한 사전에 계산된 label statistics는 bias의 일부만 나타내기 때문에 한계가 있습니다. Figure 1에서 볼 수 있듯이, question type이 주어지면 사전에 계산된 label statistics는 question 또는 image와 question으로 학습된 모델의 예측과는 눈에 띄게 다른 모습을 확인할 수 있습니다. 이러한 차이는 이전 방법만으로는 완전히 모델링 할 수 없는 bias가 존재한다는 것을 의미하는데요. 따라서 본 논문에서는 target 모델에서 직접 biase를 학습하는 새로운 stochastic bias 모델을 제안합니다.
좀 더 구체적으로 설명드리겠습니다. 직접적으로 target 모델의 bias distribution을 학습하기 위해서, 본 논문에서는 random noise vector를 도입함으로써 동일한 question input이 들어왔을 때 target 모델의 answer distribution을 stochastically하게 모방하기 위해 bias 모델을 Generative Adversarial Network (GAN)으로 모델링합니다. 대부분의 bias는 question 내에서 발생하므로[2], question을 main bias modality로 사용합니다. 이를 더욱 강화하기 위해서 ㅁadversarial training에 knowledge distillation [20]를 활용하여 bias 모델 target 모델에 최대한 가까워지도록 하여 target 모델이 bias 모델로부터 더 강한 negative supervision을 통해 학습하도록 합니다. 마지막으로, generative bias 모델과 함께, modified debiasing loss function을 사용하여 target 모델을 학습시킵니다. 최종 bias 모델은 이전의 uni-modal과 multi-modal ensemble 기반 debiasing 방법론 보다 뛰어난 성능을 발휘하는 target 모델을 학습시킬 수 있다고 합니다. 본 논문에서는 VQA 모델에서 generative 모델을 사용하여서 target 모델의 behavior를 직접 활용하여 bias 모델을 학습시키는 것은 처음이라고 합니다.
그리하여 최종적으로는 SOTA를 달성하였다고 합니다.
본 논문의 contribution은 아래와 같습니다.
- We propose a novel bias model for ensemble based debiasing for VQA by directly leveraging the target model that we name GenB
- In order to effectively train GenB, we employ a Generative Adversarial Network and knowledge distillation loss to capture both the dataset distribution bias and the bias from the target model.
- We achieve state-of-the-art performance on VQACP2, VQA-CP1 as well as the more challenging GQAOOD dataset and VQA-CE using the simple UpDn baseline without extra annotations or dataset reshuffling and state-of-the-art VQA-CP2 peformance on the LXMERT backbone.
<Method>
<Visual Question Answering Baseline>
image와 question을 한 쌍의 input으로 사용하여 VQA 모델은 전체 answer set A에서 answer를 정확하게 예측하는 방법을 학습합니다. 전형적인 VQA 모델 $F(\cdot, \cdot)$는 visual representation $v \in \mathbb{R}^{n\times{d_v}}$ (image가 주어지면 Convolutional Neural Network에서 계산된 feature vector의 set으로 여기서 $n$은 image에서 object의 수이고, $d_v$는 vector dimension을 의미합니다) 와 question representation $q \in \mathbb{R}^{d_q}$ (GloVe[40] word embedding에서 계산된 single vector로 구성됩니다)를 input으로 가집니다. 그런 다음 attention module과 multi-layer perceptron classifier $F: \mathbb{R}^{n\times{d_v}} \times{\mathbb{R}^{d_q}} → \mathbb{R}^{|A|}$를 사용하여 answer logit vector $y \in \mathbb{R}^{|A|}$를 생성합니다. $(i.e., y = F(V, Q))$.그 다음에 sigmoid function $σ(·)$를 적용한 다음에, answer probability prediction $σ(y) \in [0, 1]^{|A|}$를 ground truth answer probability $y_{gt} \in [0, 1]^{|A|}$에 가깝게 만들고자 합니다. 본 논문에서는 유명한 SOTA 모델인 UpDn[4]를 사용하였습니다.
<Ensembling with bias Models>
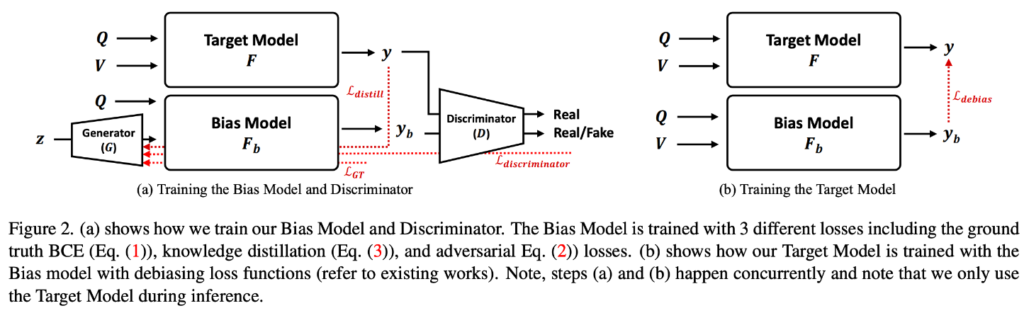
본 논문에서는 이전 연구(ex, RUBi)와 유사하게 bias model을 ensembling을 하여 이를 통한 bias mitigation에 초점을 맞추었습니다. ensemble 기반 방법에서는 $F_b (\cdot, \cdot)$로 정의되는 $y_b \in \mathbb{R}^{|A|}$를 생성하는 “bias”모델과 $F(\cdot, \cdot)$로 정의되는 “target” 모델이 존재합니다. test할 때는 $F_b (\cdot, \cdot)$를 버리고 $F(\cdot, \cdot)$만 사용한다는 것이 주의할 점입니다. 위에서 언급했듯이 기존 bias 모델의 목표는 bias에 최대한 과적합시키는 것인데요. 그런 다음 과적합 bias 모델이 주어지면 target 모델의 robustness를 향상시키기 위해 debiassing loss function을 사용하여 target 모델을 학습시킵니다. 궁극적으로 target 모델은 bias 모델에서 biased answer를 피하여 unbiased anser를 예측하도록 학습됩니다. bias 모델 $F_b (\cdot, \cdot)$은 original$ F(\cdot, \cdot)$와 같거나 다를 수 있습니다 그리고 [37]처럼 여러 모델이 존재할 수도 있습니다. 이전의 연구는 indivisual modality의 bias를 활용하였지만 본 논문에서는 이러한 것이 bias를 나타내는 모델의 ablity를 제한한다고 제안하였고, 따라서 target 모델과 유사한 bias를 표현하기 위해서$ F_b (\cdot, \cdot)$의 archtiecture를 $F(\cdot, \cdot)$와 동일하게 설정하고 UpDn [4] 모델을 사용합니다.
<Generative Bias>
위에서 언급한 것처럼, 본 논문의 목표는 stochastic bias representation을 생성할 수 있는 bias 모델을 학습시키는 것이므로, 주어진 modality와 함께 random noise vector를 사용하여 데이터셋 bias와 target 모델이 나타낼 수 있는 bias를 모두 학습합니다. question은 bias가 발생하기 쉬운 것으로 알려져 있기때문에, question modality는 그대로 유지하여서 bias 모델 $F_b(\cdot, \cdot)$의 input으로 사용합니다. image feature를 사용하는 대신 generator network $G : \mathbb{R}^{n\times{128}}→\mathbb{R}^{d\times{d_v}}에 random noise vector z \in \mathbb{R}^{n\times{128}}$를 도입하여 해당 input에 해당하는 bias 모델 $F_b(\cdot, \cdot)$를 생성합니다. formally하게 random Gauusian noise vector $z ~ N(0, 1)$이 주어지면 generator network $G(\cdot)$는 image feature와 동일한 차원을 갖는 벡터, 즉 $vˆ = G(z) \in \mathbb{R}^{n\times{d_v}}$를 합성합니다. 궁극적으로 본 모델은 question $q$와 $G(z)$를 input으로 받아 $F_b(G(z),q)=y_b$ 형식의 bias logit $y_b$를 생성합니다. 간단하게 하기 위해서, generator와 bias모델을 하나의 network로 간주하고 $F_b(G(z), q)$를 $F_{b,G}(z,q) $형식으로 다시 작성하고 “Generative Bias” 방법을 GenB라고 부릅니다.
<Training the Bias Model>
bias 모델 GenB는 주어진 question에 대한 bias를 학습하기 위해서 전통적인 VQA loss인 Bineary Cross Entropy Loss를 사용합니다.
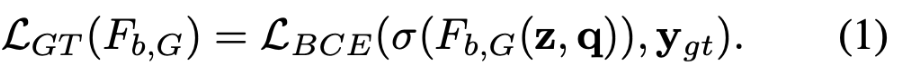
그러나, 기존의 연구와 달리 본 논문은 bias 모델이 target 모델의 bias도 포착하기를 원하기 때문에 본 논문에서는 target 모델의 bias를 answer의 random distribution로 모방하기 위해 [16]과 유사한 adversarial training[16]을 제안하여 bias 모델을 학습시킵니다. 특히, target 모델과 bias 모델의 answer를 “real” 과 “fake”로 구분하는 discriminator를 도입하였습니다. discriminator는 $D(F(v,q)$ 그리고 $D(F_{b,G}(z,q))$로 공식화하거나 또는 $D(y)$와 $D(y_b)$로 rewrite할수도 있습니다. generator $F_{b,G}(\cdot, \cdot)$와 $D(\cdot)$가 있는 adversarial network는 아래와 같이 표현할 수 있습니다.
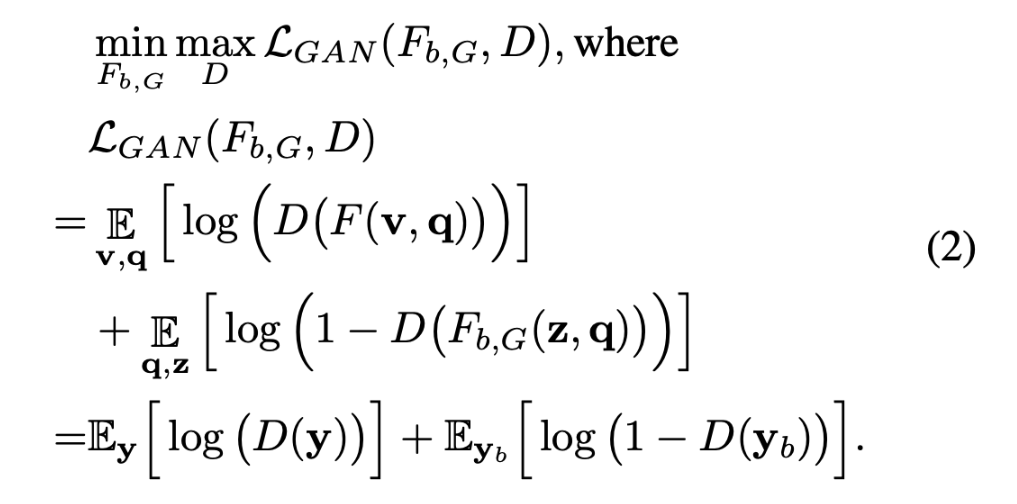
generator $(F_{b,G})$는 objective$(L_{GAN})$를 최소화하려고 하고 adversarial discriminator (D)는 objective를 최대화하고자 합니다. D와 $F_{b,G}$의 alternative training을 통해 bias 모델 $(y_b)$의 answer vector의 distribution이 target 모델$(y)$의 answer vector의 distribution과 가까져야 합니다.
게다가, target 모델에 존재하는 intricate한 bias를 포착하기 위해 bias 모델을 더욱 강화시키고자 하는데, 이를 위해 [12, 27]과 비슷한 knowledge distillation objective[20]을 추가하여 모델 bias 모델이 주어진 $q$만으로 target 모델의 행동을 추적할 수 있도록 합니다. 본 논문에서는 경험적으로 KL divergence와 같은 sample-wise distance를 기반한 metric을 포함하는 것이 유용함을 발견했다고 합니다.이 방법은 image to image translation과 비슷하다고 합니다. 그런 다음 generator의 목표는 discriminator를 속이는 것뿐만 아니라 target 모델의 answer output을 모방하여 target 모델에 hard negative sample synthesis의 형태로 더 까다로운 supervision을 제공하는 것입니다. $F_{b,G}(\cdot, \cdot)$에 대한 adversarial training에 또 다른 objective를 추가하는데 이는 아래와 같습니다.
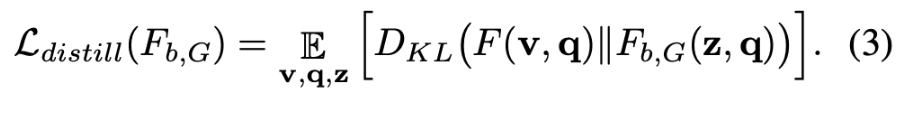
궁극적으로, bias model의 training loss는 아래와 같습니다.
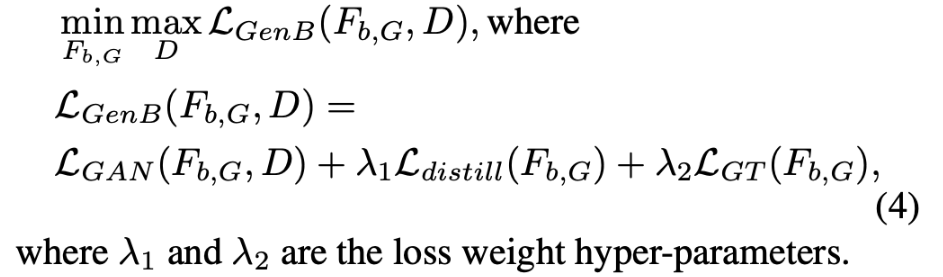
<Debiasing the Target Model>
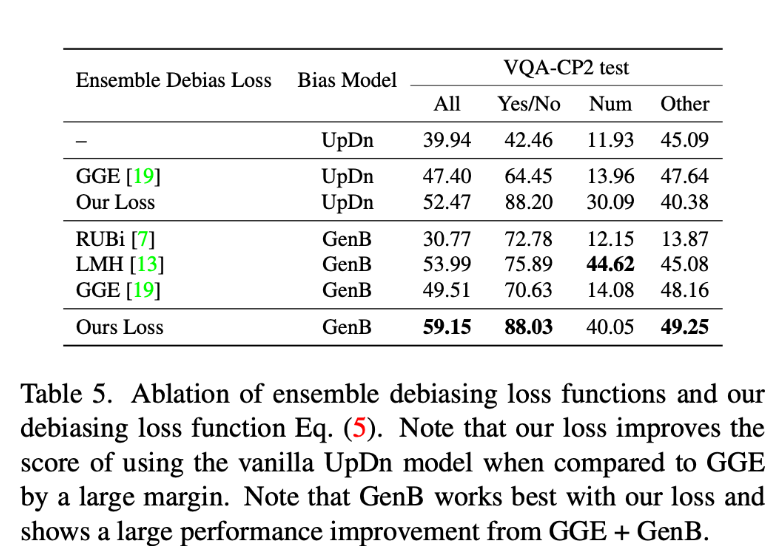
생성된 biased된 answer $y_b$가 주어지면, RUBi와 같이 사용할 수 있는 몇 가지 debiasing loss function이 있는데 각 효과는 Table 5를 참고해주시면 됩니다. GGE[19] loss는 label distribution을 사용하지 않고도 가장 성능이 좋은 loss 중 하나라고 합니다. GGE loss는 bias prediction.distribution을 취하고, 반대 방향으로 gradient을 생성하여서 target 모델을 학습시킵니다. 이를 출발점으로 삼아서 bias 모델 GenB의 ensemble을 사용하여 아래와 같이 수정할 수 있습니다.
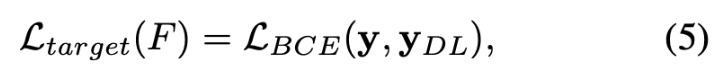
pseudo-label $y_{DL}$의$ i$번째 element는 아래와 같이 정의됩니다.
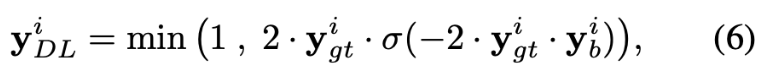
$y^i_{gt}$와 $y^i_b$는 ground truth와 biased model의 output의 $i$번째 element입니다. 주요 차이점은 시그모이드 함수로 biased된 모델의 output을 억제하는 [19]와 달리 시그모이드 함수를 사용하지 않고 $y_b$를 사용한다는 점입니다. 이 경우, $y_{DL}$의 값이 1을 초과할 수 있기 때문에 추가로 값을 잘라내어 [0, 1]에 값이 한정되도록 합니다. 본 논문에서는 이렇게 간단하게 loss function을 수정하면 성능이 크게 향상되는 것을 경험적으로 확인했다고 합니다. 억제되지 않은 biased된 output $y_b$를 통해 target 모델이 bias의 intensity를 더 잘 고려할 수 있어 더 강력한 모델을 만들 수 있지 않나 추측한다고 합니다. 또한 target 모델을 학습할 때 $F_{b,G}(z,q)$와 같이 noise input을 사용하는 대신 실제 이미지를 $F_b(v,q)$와 같이 사용하는 것이 더 효과적이라는 경향을 본 논문에서는 경험적으로 발견했기 때문에 $F_b(v,q)$의 출력을 사용하여 target 모델을 학습시킨다고 합니다.
<Experimetns>
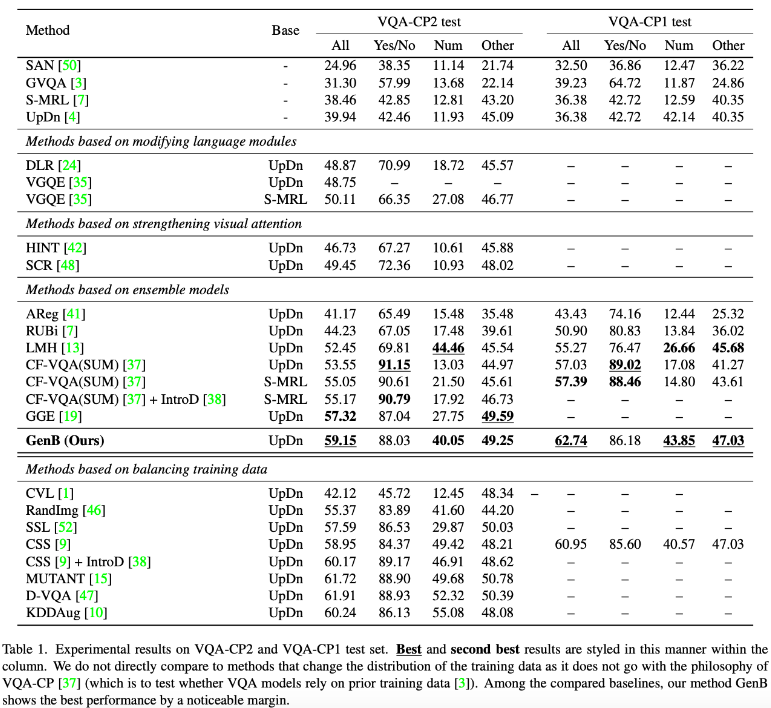
VQA-CP2의 경우, 먼저 첫 번째 섹션에서 baseline 아키텍처를 나열합니다. 그런 다음 language models을 수정하는 방법론(DLR [24], VGQE [35]), visual attention을 강화하는 방법론(HINT [42], SCR [48]), ensemble 기반 방 (AReg[41], RUBi [7], LMH [13], CF-VQA [37], GGE [19]) 그리고 training distribution을 변경하여 train data를 balancing하는 방법론(CVL [1], RandImg [46], SSL [52], CSS [9], Mutant [15], D-VQA [47], KDDAug [10])와 본 논문의 방법론을 비교해보겠습니다.
Table 1에서 볼 수 있듯이, 본 논문의 방법론은 VQA-CP2에서 SOTA를 달성하였고 2위(GGE [19])를 1.83%로 능가하는 성능을 보입니다. 정말 대단하네요. 세 가지 범주(“Yes/No”, “Num”, “Other”) 모두에서 본 논문의 모델의 성능은 동일한 backbone architecture에서 일관되게 상위 3위 안에 들었습니다. 또한 “Others”에서도 매우 우수한 성능을 보이는 것을 확인할 수 있습니다.
또한 VQA-CP2 데이터 세트의 subset인 VQA-CP1 데이터셋에서의 성능도 확인할 수 있는데요. 이 데이터셋에 대한 본 논문의 방법론은 비교 대상 중 두 번째로 좋은 방법인 CFVQA(SUM)[37]보다 성능이 크게 개선된 최신 결과를 보여줍니다.
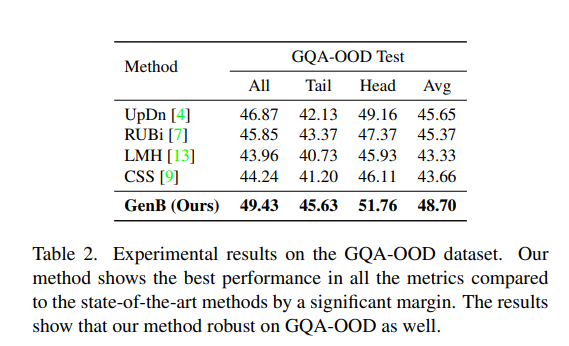
최근에 VQA debiasing을 위한 새로운 데이터셋인 GQA-OOD[26] 데이터셋이 출시되어서, 이 데이터셋에서도 실험을 진행하였는데요. 최신 ensemble 기반 방법인 RUBi [7], LMH [13], CSS [9]와 비교하여 성능을 보여주는데 모든 metric에서 SOTA와 비교하여 상당한 차이로 최고의 성능을 달성한 것을 확인할 수 있습니다. CSS와 같이 VQA-CP2에서 GenB와 유사한 성능을 보이는 방법론과 비교하더라도, GenB는 GQA-OOD에서 전체적으로 5.19% 더 나은 성능을 보입니다. 흥미로운 점은 앞에서 나열한 모든 방법론은 다른 데이터셋에서는 기본 UpDn 모델보다 성능이 뛰어나지만, GOA-OOD에서는 성능이 저하되는데, GenB는 GQA-OOD에서 성능이 향상된 것을 보면 GenB가 roubust하게 작동한다는 것을 확인할 수 있습니다.
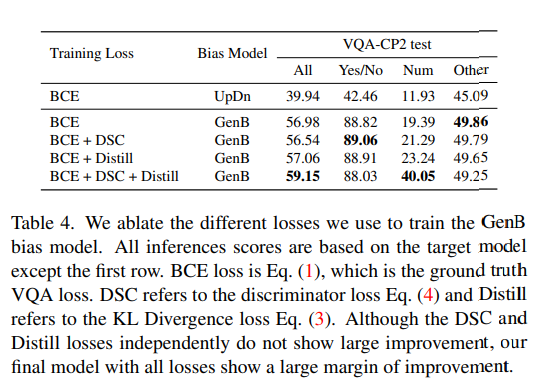
loss에 대해서 ablation 실험을 진행한 것에 대해서 Table 4에서 확인할 수 있습니다. BCE loss 학습된 GenB는 이미 target 모델을 debising하는데 상당한 도움이 되는데요. 여기에 DSC 및 Distill loss를 개별적으로 추가하면 BCE loss로 학습된 GenB와 비슷한 성능을 보입니다. 그러나 두가지 loss를 모두 사용하면 모델이 모델 내에 존재하는 bias를 더 잘 포착할 수 있으므로 성능이 크게 향상되는 것을 확인할 수 있습니다.
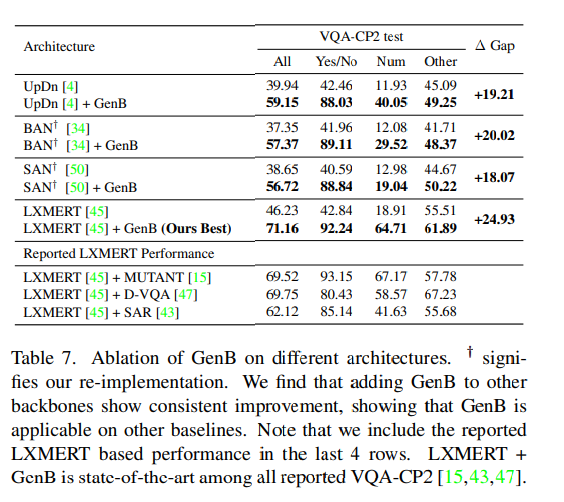
Table7을 통해서 GenB 방법론을 다른 VQA backbone에서도 성능 향상을 이룰 수 있을까에 대해서 추가로 실험한 것을 확인할 수 있는데요. 각 architecture에 대해서 target 모델과 GenB 모델 모두 동일한 architecture로 설정하였다고 합니다. 결과적으로 GenB가 모든 backbone에서 일관되게 상당한 성능 향상을 보이는 것을 볼 수 있며, 이를 통해 GenB가 단순히 UpDn 모델에 국한되지 않음을 보여줍니다.
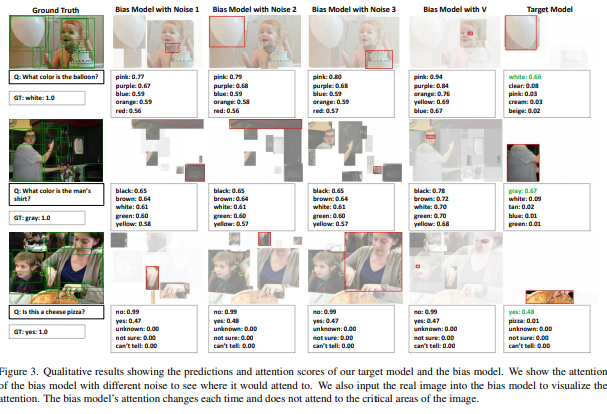
Figure 3을 통해서 모델의 output을 정성적으로 확인할 수 있는데요. bias 모델을 다양한 noise와 함께 3번 실행하여 다양한 attention과 biased prediction을 보여줍니다. 또한 question과 함께 해당 image를 input으로 하여서 모델이 어디에 attention하는지 확인할 결과, 이전에는 볼 수 없었던 image이기 때문에 attnetion이 random하다는 것을 확인할 수 있었습니다. 동일한 question type(ex, what color)을 사용하더라도 bias 모델의 prediction이 눈에 띄게 다르다는 것을 알 수 있습니다.
이렇게 리뷰를 마쳤는데요. RUBi와 비슷한 ensemble 방법론이니 비슷하겠지~하고 덤볐는데 GAN도 나오고 이해하기 어려웠던 논문이 아니었나 싶습니다. 읽으면서 역시 이정도는 해야 CVPR 가는 구나를 느꼈던 논문이었던 것 같습니다. 읽어주셔서 감사합니다.
[2] Aishwarya Agrawal, Dhruv Batra, and Devi Parikh. Analyzing the behavior of visual question answering models. In EMNLP, 2016
[4] Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. In CVPR, 2018
[9] Long Chen, Xin Yan, Jun Xiao, Hanwang Zhang, Shiliang Pu, and Yueting Zhuang. Counterfactual samples synthesizing for robust visual question answering. In CVPR, 2020
[12] Jae Won Cho, Dong-Jin Kim, Jinsoo Choi, Yunjae Jung, and In So Kweon. Dealing with missing modalities in the visual question answer-difference prediction task through knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
[13] Christopher Clark, Mark Yatskar, and Luke Zettlemoyer. Don’t take the easy way out: Ensemble based methods for avoiding known dataset biases. In EMNLP, 2019
[16] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In NeurIPS, 2014
[19] Xinzhe Han, Shuhui Wang, Chi Su, Qingming Huang, and Qi Tian. Greedy gradient ensemble for robust visual question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1584–1593, 2021
[20] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
[27] Dong-Jin Kim, Jae Won Cho, Jinsoo Choi, Yunjae Jung, and In So Kweon. Single-modal entropy based active learning for visual question answering. In BMVC, 2021
[37] Yulei Niu, Kaihua Tang, Hanwang Zhang, Zhiwu Lu, XianSheng Hua, and Ji-Rong Wen. Counterfactual vqa: A causeeffect look at language bias. In CVPR, 2021
안녕하세요 김주연 연구원님
VQA는 익숙하지 않아 간단한 질문을 드리려고 합니다.
1. 본 논문에서 UpDn 이라는 기존 SOTA를 사용했다고 하는데, 그 방법론과의 가장 큰 차별점이 무엇인가요?
2. 한 쪽 도메인에 치중되는 것을 해결하는 것이 목적인거 같은데, 그런 Bias를 정량적으로 측정하는 방식이 있나요? 있다면 어떻게 측정하나요?
안녕하세요. 댓글 감사합니다.
1. 가장 큰 차별점은 GenB는 모델의 bais를 debiasing하는 방법인 것입니다. UpDn 방법론은 서도 다른 Top-down 모델과의 결합을 통해서 VQA에서 성능을 달성했다면 GenB는 기존의 VQA 모델에서 debias를 어떻게 할 것인가에 대한 방법론이기 때문에 성향이 다르다고 말할 수 있을 것 같습니다.
2. 논문에서는 이에 대해서 정확히 언급하지는 않았지만 이전 리뷰 논문인 RUBi를 바탕으로 답변을 드리자면, bias를 정량적으로 측정하는 방법이 있다면 바로 question-only branch로 성능을 내 보는 것입니다. question-only로 학습시킨 모델과 image와 question을 모두 입력으로 가지는 모델을 학습시켰을 때의 성능 차이를 보면 얼만큼 bias가 되었는지를 알 수 있겠죠.
안녕하세요. 좋은 리뷰 감사합니다.
이전까지의 연구는 indivisual modality의 bias를 활용했는데, 본 논문의 저자는 이런 점이 bias를 나타내는 모델의 ability를 제한한다고 하셨는데 이에 대한 자세한 근거가 존재하는지 궁금합니다. 또, 그 bias model ensembling 설명해주신 부분에서 target 모델과 유사한 bias를 표현하기 위해 F_b()의 구조를 F()와 동일하게 설정하고 UpDn 모델을 사용했다는데 어떻게 사용되었다는지 잘 이해가 가지 않습니다. .좀 더 설명해주실 수 있으실까요 ?
감사합니다.
안녕하세요. 댓글 감사합니다.
1. 이에 따로 reference가 달려있거나 하지는 않지만, 이는 논문의 가설이라고 보시면 될 듯 합니다. 이 가설을 증명하기 위해서 GenB라는 것을 설계하여 직접적으로 성능 향상을 보여 증명했다고 생각합니다.
2. target 모델과 bias 모델의 구조를 동일하게 가져갔다고 이해하시면 될 듯합니다. 그리고 이 모델로 UpDn으로 가져갔다고 생각하시면 됩니다