본 논문에서는 depth map에서 2d cnn을 이용해 direct하게 feature를 포착하여 3d object detection을 하는 task를 제안한다. input은 3d point cloud가 아니라 2d로 누른 depth map을 사용한다. 대부분의 3d object detection 방법론의 경우 point cloud를 input으로 하여 좋은 결과를 보이지만, mobile device에 적용하거나 real-time scenario에 적용하기에는 많은 연산량과 복잡도로 인해 어려움이 있다고 한다. 따라서 본 논문에서는 depth map기반의 3d detection pipeline인 2.5D-VoteNet을 제안한다. model이 depth map으로부터 feature를 추출하기 때문에 2d space공간에서 효율적인 연산이 가능하다. 또 흔히 사용하는 3d cnn을 사용하지 않고 relative depth convolution(RDConv)를 사용하여 더 강인한 local feature를 추출할 수 있도록 했다고한다. sunrgbd에서 sota를 달성했다. 또 69 FPS로 기존에 존재하는 모델들보다 높은 inference time을 보였다고 한다.
Introduction
대부분의 많은 3d object detection 방법론들은 point cloud data를 사용한다. 또 그 안에서 2d로 projection해서 사용하던가 point cloud based 방법을 사용하는 등 다양하게 나눠진다. projection하는 방법의 경우 bird eye view, front view, multiple view 등 다양하게 point cloud를 projection할 수 있다. 이 경우 point cloud가 2d로 projection되기때문에 2D cnn을 사용할 수 있다. 하지만 겹치거나 위로 쌓여있는 경우가 많은 indoor의 경우는 projection했을 때 정보손실이 크게 발생하기 때문에 적용하기가 어렵다는 문제가 있다. point cloud based방법의 경우 point cloud를 voxelize하거나 raw point cloud를 사용하는 방법이 있다. 이 경우 local feature와 global feature를 합치기 위해 보통 hierarchical한 방법으로 downsampling하여 convolution을 연산을 하는 것이 일반적인 경우이다. 하지만 point cloud는 sparse하고 irregular한 특성을 가지기 때문에 많은 연산량을 필요로하게된다. 따라서 보통 10FPS 내외의 느린 inference time을 보일 수 밖에 없다고한다. 결과적으로 mobile hardware device에 적용하기 어렵고 real-time에 적용하기도 어렵다고 한다.
저자는 이러한 문제점을 지적하면서 point cloud를 하나의 single depth map으로 변환하여 사용한다. camera calibration정보를 이용해 depth map을 생성하는데 depth map과 point cloud는 같은 정보를 다른 방식으로 표현한 것이다. 따라서 depth map을 이용해서도 3d object detection을 수행할 수 있다고 한다. detection head와 3d space에서 processing과정을 유지한다고 하니 depth map에서 feature를 추출한다는 점만 다르게 느껴진다. network의 backbone은 기존 2d cnn과는 조금 다르게 relative depth정보로부터 local feature를 학습할 수 있는 relative depth convolution(RDConv)로 변환된다. RDConv는 edge, corner와 같은 local geometry정보가 absolute depth보다 relative depth에 더 의존한다는 간단한 개념에서 영감을 얻어 만들어진 것이라고 한다. absolute depth를 사용하는 다른 일반적인 convolution과 비교해서 RDConv는 더 풍부한 정보의 feature를 추출하고 detection성능도 더 좋다고 한다.
contribution은 아래와 같다.
1. depth map을 사용한 간단하고 효율적인 3d detection pipeline
2. relative depth convolution(RDConv)를 활용하여 local 정보 포착 가능
3. SUNRGBD에서 sota
4. scannet에서 base model인 votenet보다 좋은 결과 보임
Related Works
3d detection on point clouds
bird eye view(BEV)기반의 방법론들은 LiDAR point cloud를 ground plane으로 projection하여 pseudo-image를 생성하는 방법으로 autonomous driving에서 많이 사용된다. 하지만 겹치는 물체가 많거나 위로 stack이 많이 되어있는 경우에는 projection을 하게되면 정보손실이 크기때문에 사용하는 것이 좋지 않다. votenet은 deep hough voting을 통해 point feature의 center를 찾는 end-to-end 3d detection pipeline으로 최근에는 votenet을 최적화하고 성능을 향상시킨 연구들이 나왔다. 하지만 inference speed를 고려하지 않았다는 단점이 있다. convolution기반으로는 voxelize를 하고 sparse 3d conv를 태우는 방법론들이 있는데 GSDN같은 방법론이 존재한다. 하지만 3d conv방법은 3d scan데이터에만 적용이 가능하다.
2d cnn for range images and depth maps
bird eye view(BEV) 기반 방법론들과는 다르게 어떤 방법론들은 LiDAR point cloud를 front view로 projection하기도 했다. 하지만 2d feature map으로부터 direct하게 3d bounding box를 예측하기 때문에 결론적으로 3d spatial정보를 잃어버린다는 문제가 존재한다고한다. 따라서 여러 view를 combine하는 방법론도 나왔지만 많은 연산량을 필요로했다고 한다. 몇몇 논문에서는 3d cnn을 그대로 모방했는데 본 논문에서는 depth map으로부터 geometrical한 feature를 포착하는데 있어서 3d cnn을 모방하는 것은 의미없다는 것을 보였다고 한다.
Depth Map based 3D Detection
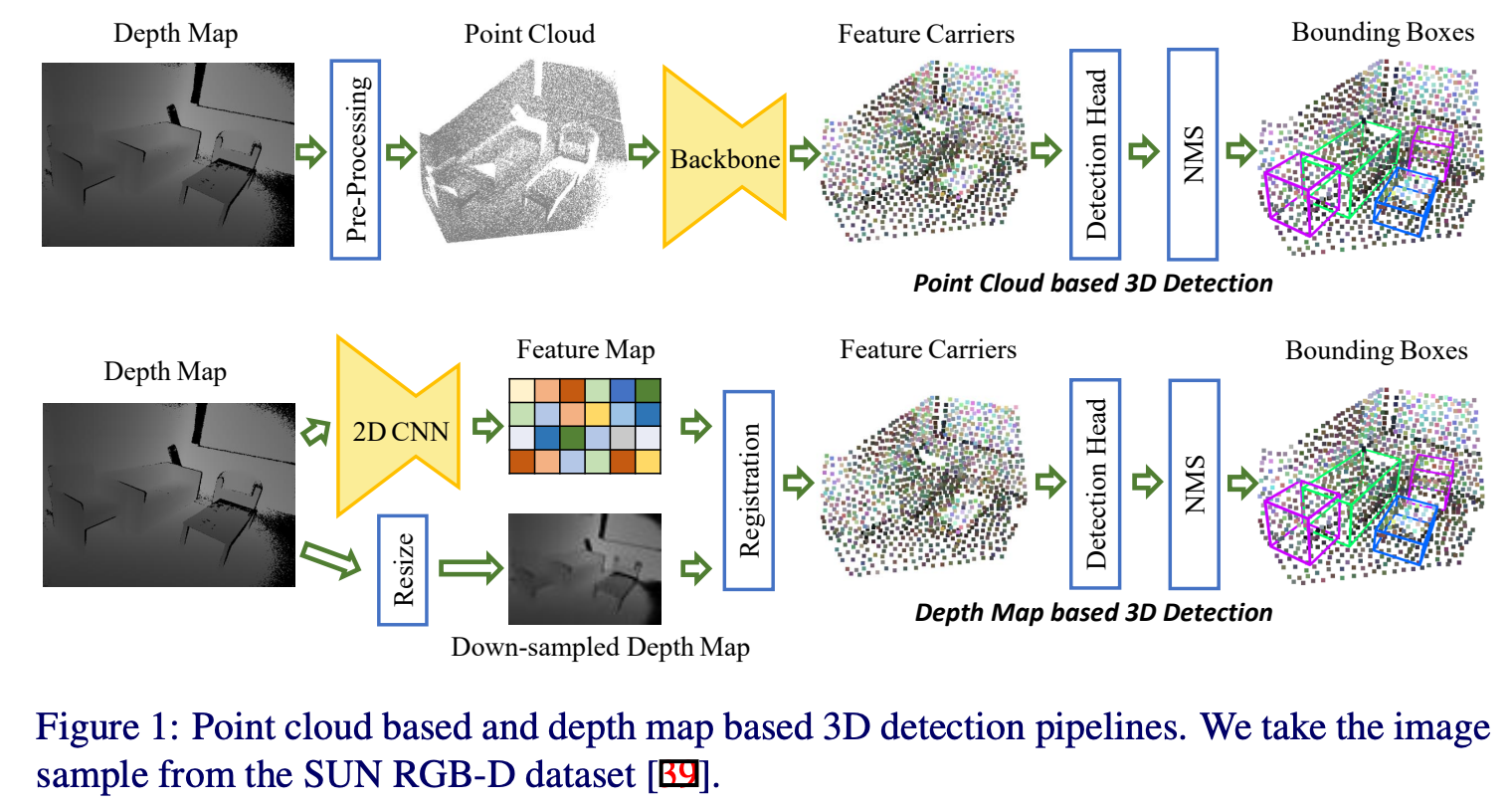
point cloud based pipeline
일반적인 point cloud 기반의 3d object detection workflow는 위의 figure 1에서 확인할 수 있다. 크게 pre-processing, 3d backbone, detection head, post-processing으로 나뉜다. 먼저 pre-processing과정에서 depth map이 point cloud로 변환된다. 보통 point cloud는 연산량을 고려하여 downsampling되거나 voxel형태로 처리된다. 그리고 backbone에서 knn과 같은 방법을 통해 정의된 local한 영역 주변에 point들에 대해 convolution연산을 수행하게된다. output은 high level feature를 의미하며 feature carrier(points of interest)라고도 한다. 이후에 detection head에서 앞에서 추출한 feature정보들을 합쳐 bounding box regression이라던가 semantic classification을 수행하게된다. 그리고 post-processing과정에서는 nms를 통해 predicction결과를 정제한다.
depth map based pipeline
본 논문에서 사용하는 depth map 기반의 pipeline은 위의 figure 1 아래부분에 나타나있다. 우선 U자형태의 2d cnn을 통해 high-resolution의 feature map을 low-resolution feature map으로 encoding한다. 그리고 spatial information을 충분히 활용하고자 뒤에 feature carrier를 그대로 사용하여 detection head와 nms를 거치는 과정을 사용한다. feature carrier를 생성하기 위해 input depth map은 feature map과 같은 resolution으로 scaling되며 3d space로 lift up된다. 각 feature map의 feature vector는 상응하는 3d point에 register된다. 그리고 voting module과 같은 detection head를 통과하고 votenet과 같은 post-processing을 통과하게되는 것이 논문에서 제안하는 2.5D-VoteNet의 전체적인 pipeline이다.
point cloud 기반의 pipeline과 비교했을 때 depth map 기반 pipeline은 몇가지 면에서 더 효과적이다. 먼저 network가 2d cnn을 사용하기 때문에 속도가 빠르다. 또 낮은 연산량 덕분에 더 깊은 backbone이나 high-resolution의 input을 사용할 수 있어 더 풍부한 의미있는 feature를 사용할 수 있어 detection quality도 좋다. 또 간단한 network design이 실제 세계에서 적용하는 application관점에서도 hardware implementation이 간단하다는 장점이 있다고 한다. 또 geometrical 정보와 color 정보를 fusion할 때도 같은 resoltuion을 가질 수 있기 때문에 쉽게 fusion할 수 있다는 장점이 존재한다. depth map기반의 3d detection의 main convern은 2d backbone이 camera calibration을 알지못한다는 점인데 여기서는 모델이 data augmentation을 통해 calibration invariance를 학습할 수 있었다고 한다. 저자는 본 방법론의 문제는 multiple view의 depth map으로부터 복원된 3d scan을 처리하지 못한다는 점을 한계점으로 지적한다.
relative depth convolution
앞에서 언급했듯이 여기서는 absolute depth보다 relative depth에 의존하는 새로운 convoltuion operation을 제안한다. 이러한 직관은 edge나 corner와 같은 local geometries가 absolute depth보다 relative depth에 더 많이 의존한다는 점에서 착안했다고 한다. 이러한 observation으로부터 absolute depth invariance가 2d cnn이 depth map으로부터 더 중요한 정보를 포착하는데 도움을 줄 수 있다는 점을 나타낸다.
저자는 위에서의 직관을 통해 각 sliding window마다 depth value를 normalize하는 relative depth convolution(RDConv)를 제안했다. 이 새로운 operation은 무시할만한 연산량 증가를 보이기 때문에 2d cnn의 첫 번째 conv layer를 RDConv로 대체해도 문제가 없다고 한다. x ∈ Z2 를 임의의 2D coordinate, d(x) : Z2 → R 은 depth map, y(x) : Z2→ Rn 은 n차원의 feature map이라고 할 때 RDConv는 아래와 같이 표현할 수 있다.
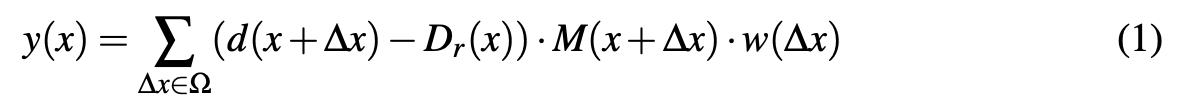
∆x ∈ Z2 은 offsets을 의미하고, Ω ⊂ Z2 은 offset의 집합, 그리고 w(∆x) : Z2 → Rn 은 kernel의 learnable weight를 의미한다. M(x)는 binary mask로 M(x) = 0 if d(x) = 0, and M(x) = 1 if d(x) > 0이다. Dr(x)는 reference depth로 각 sliding window에서 reference로 avarage depth map을 나타내며 아래와 같이 나타낼 수 있다.
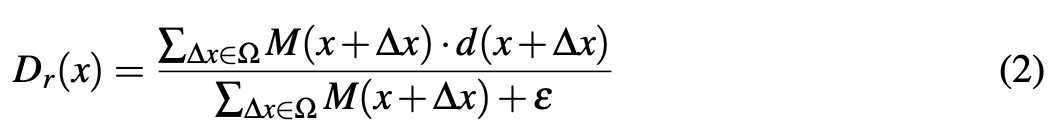
앱슐런은 0으로 나눠지는 것을 방지하기 위한 작은 상수이다. depth map이 bad part(figure 1에서 검정색 부분)을 포함하는데 이것은 depth value가 측정되지 않아 존재하지 않는 부분이기 떄문에 binary mask를 사용해서 제거해준다. 이 경우 bad pixel에 대해 0으로 pre-processing을 해준다.
bad pixel의 depth value가 0으로 pre-processing되기 떄문에 일반적인 2d conv는 masking효과를 이미 누리게된다. 따라서 RDConv는 binary mask보다 local depth normalization으로부터 효과를 얻을 수 있다. 또 깊은 layer에는 binary mask를 사용하지 않는데 bad pixel에서의 missing information은 forward 과정에서 pixel 주변 정보 share를 통해 deeper layer에서 recover될 수 있다고 한다. 경험적으로 deep layer에서 masking하는 방식이 현재 pipeline에서 이득이 없다고 판단해서 제거했다고 한다.
Implementation Details
2.5D-VoteNet의 좀 더 detail한 구조를 살펴보면 backbone으로는 resnet-34를 사용했다. 아래 figure 2에서 볼 수 있듯이 resnet-34에 RDConv layer를 첫 번째 conv layer에 parallel하게 추가했다. 여기서 첫 번째 conv layer는 제거하지 않았는데 absolute depth 정보를 보존하기 위함이다. 처음에 depth map에 대해 RDConv와 일반 conv output을 간단하게 더했는데 경험적으로 더하거나 concat하거나 별 차이가 없었다고 한다. 그리고 마지막 resnet-34 conv block의 Output channel을 512에서 256으로 변경했다. 그리고 downsampling부분과 upsampling부분 사이에 skip connection을 적용했다. backbone의 output feature map은 256 cahnnel을 가진다.

rgb를 fusion하는 경우, 그냥 2d conv layer를 network 처음 부분에 추가해서 rgb image를 입력받을 수 있다. 그리고 rgb feature와 geometrical feature를 early fusion하는데 이때 효율성을 고려하고 간단하기 때문에 early fusion했다고 한다.
loss function은 votenet의 loss를 사용하는데 voting loss, objectness loss, 3d bounding box loss, semantic classification loss의 가중합 된 loss를 사용한다. 하나 차이점이 있다면 heading angle residual과 size residual regression loss는 사용하지 않고 3d-Giou loss를 사용했다고 한다.
input 정보의 경우 depth map이나 rgb image는 416×544크기이다. 원본 비율을 유지하기 위해 zero padding을 적용하고 data augmentation으로 random하게 resize, flip을 적용한다. 또 bad pixel에 대해 강인함을 보이기 위해 depth value의 20%를 random하게 0으로 처리한다고 한다. 또 image scaled, rotated, fliped할 때 intrinsic, extrinsic parameters도 위에와 동일하게 적용된다.
Experiments
실험은 sunrgbd, scannet에서 수행되었다.
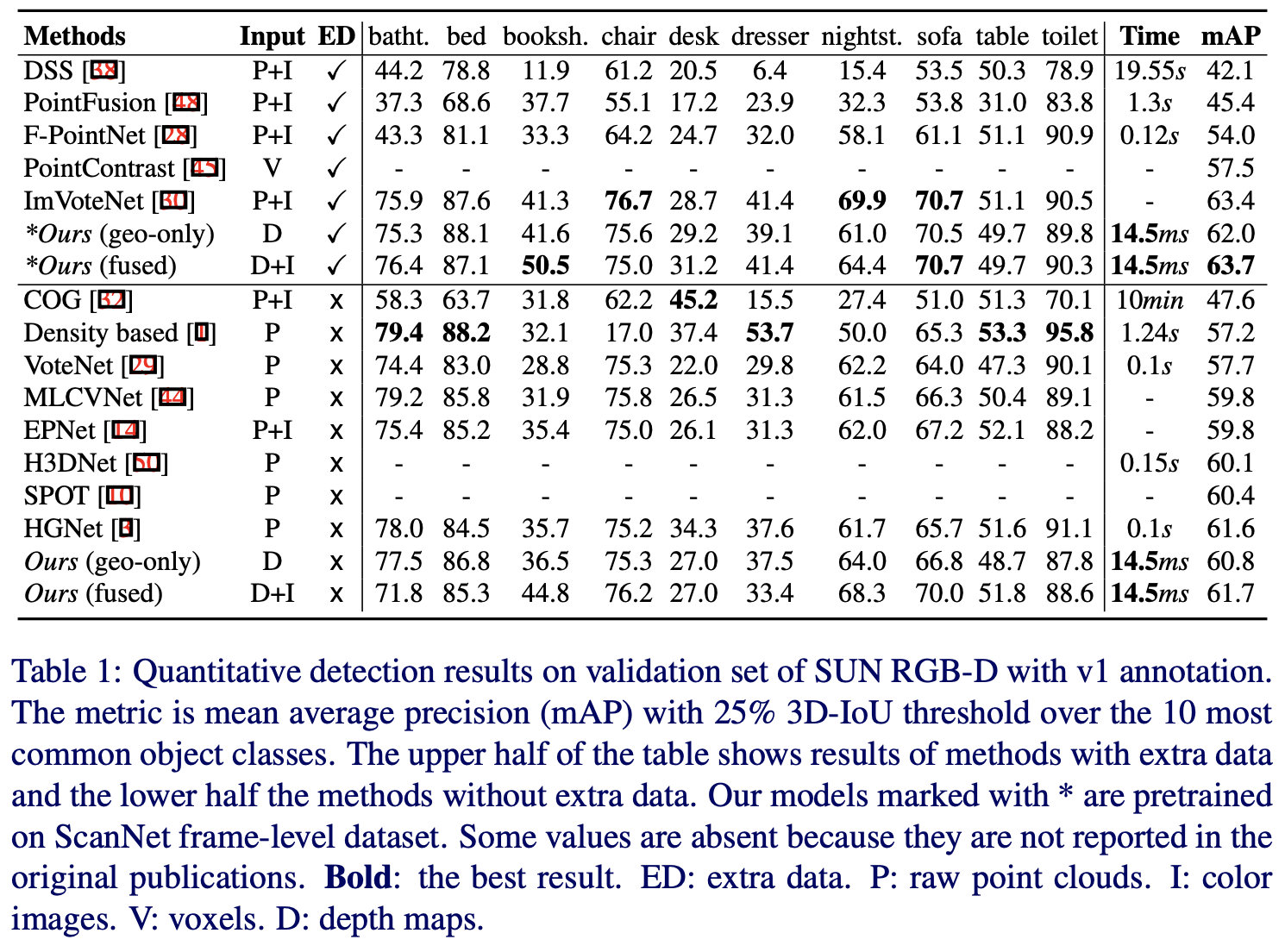
먼저 아래 Table 1에서는 sunrgbd에서의 실험 결과를 보인다. 가운데 가로선을 기준으로 위에는 추가적인 데이터를 필요로하는 방법이고 아래는 추가데이터를 필요로 하지 않는 방법이다. 무슨말이냐면 다른 데이터에서 pre-training한 모델을 함께 사용하는 경우를 의미한다.(rgb를 fusion할 때 rgb module은 imagenet같은 데이터로 사전학습한 모델을 사용)
결과를 보면 Ours로 보이는 모델이 2.5D-VoteNet인데 기존에 다른 방법론들과 비교했을 때 더 빠르고 성능도 더 높은 것을 확인할 수 있다. base인 votenet과 비교했을 때 geometry정보만 사용했을 때는 3.1%정도 높은 성능을 보이고 rgb를 함께 사용한 fusion model의 경우 4%정도 높은 성능을 보인다. 기존의 다른 방법론들은 정확도를 높이는데 집중했다면, 본 논문에서 제안하는 방식은 정확도와 속도까지 모두 고려했기때문에 더 인상적이라고 할 수 있다.
아래 Table 2에서는 scannet에서의 결과를 확인할 수 있다.

모델은 18개 class에 대해 평가했는데 geometry정보만 사용한 경우 6.8%정도, rgb를 함께 fusion한 경우 7.2%정도 더 높은 성능을 보인다. 이 결과는 sunrgbd에서보다 더 높은 성능 향상을 보이는데, 이것은 아래 figure 5에서 확인해보면 scannnet데이터에 물체가 가려져 일부만 보이는 물체들이나 hard sample들이 많아 이러한 결과를 보이는 것 같다.

몇 가지 ablation을 보면 RDConv를 사용했을 때 효과에 대한 실험이다.
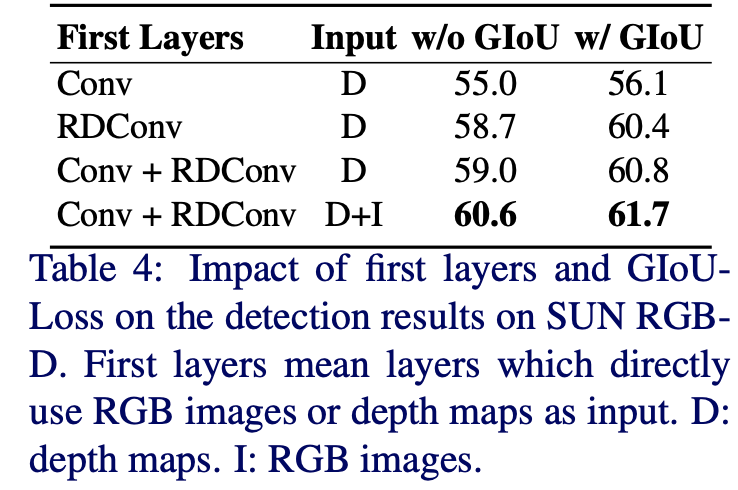
일반적인 conv를 첫 번째 layer로 했을 때 detectin 결과는 56.1%로 그다지 만족스럽지 못하다. 단순히 첫 번째 layer를 RDConv로 바꿨을 때 4%정도 성능향상을 보인다. 따라서 RDConv를 적용하는 것이 depth map based detection에서 좋은 정보를 가지는 Feature를 학습했다고 할 수 있다. 또 3D Giou-loss에 대한 실험도 함께 확인할 수 있는데, 오른쪽 두 column을 비교해보면 3D-GIoU loss를 적용했을 때 1.8%정도 더 좋은 성능을 보이며 fusion방법의 경우 1.1%정도 더 좋은 성능을 보인다. 하지만 3D-Giou loss를 적용하지 않아도 사실 이미 baseline인 votenet보다는 좋은 결과를 보인다.
rgb image를 fusion하는 실험도 있다. 여기서는 early fusion을 했을 때 가장 좋은 성능을 보인다. 또 단순히 geometric정보만 사용하는 방식(60.8)이 단순히 concat하는 방식(59.9)보다 더 좋은 결과를 보인다. 이를 통해 RDConv의 효과를 또 보여준다. 또 late fusion이 좋은 결과를 보이지 못하는데, 이러한 two-stream structure는 학습에 더 많은 데이터를 필요로 하여 overfitting되었기 때문이라고 생각된다.

Conclusion
본 논문에서는 간단하고 효과적으로 real-time 3d detection을 수행하기 위한 2.5D-VoteNet을 제안했다. 2.5D-VoteNet은 sota성능을 보이며 기존 point cloud기반 방법론들과 비교했을 때 속도면에서도 높은 향상을 보였다. depth map based pipeline은 2d 구조의 모델이 적용가능하도록 했고 3d detection task도 수행가능하도록 했다. 저자는 추후에는 self-supervised learning기법에 대해 연구해보겠다고하며 논문을 마친다. 2d depth map을 사용하면서 이를 처리하기 위한 RDConv를 고안하는 과정이 인상적이었다.
안녕하세요. 좋은 리뷰 감사합니다.
1. 간단한 용어적인 부분에서 질문이 있습니다. absolute depth와 relative depth의 차이점이 궁금합니다.
2. 그림(1)에서 registration을 진행하는 부분은 Feature map과 Depth map을 가지고 feature matching을 통해 point cloud 형태로 바꾸어 주는 건지 궁금합니다. 해당 부분은 feature carrier라는 것이 어떤 것인지 정확하게 와닿지 않아 이해를 못 하는 부분인 것 같아 질문드립니다.
감사합니다.
댓글 감사합니다.
1. 논문에서 설명으로 보았을 때 absolute depth는 말 그대로 절대적인 depth자체를 의미하고, relative depth는 local한 영역 내에서 정규화된 depth를 의미하는 것으로 보입니다.
2. registration은 말씀하신대로 depth map과의 alginment를 고려하여 3D point로 lift up해주는 것입니다. feature carrier의 경우 위에서도 언급되어있듯이 points of interst라고도 하며 depth map을 통한 3차원 정보를 가지는 중요한 Point를 의미하는 것으로 보입니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
결국 기존의 VoteNet과의 차이점은 입력으로 raw level의 포인트 클라우드를 사용하는지 아니면 2D로
누른 Depth Map을 사용하는지에 따라 나뉘는 것 같습니다.
궁금한 점은 먼저 registraion이 2D feature map과 3D 공간으로 lift up된 3D point 사이에서 이루어지는 것인가요? 아니면 feature map과 depth map 사이의 registraion 후 3D point로 변환되는 것인가요 ?
그리고 absolute depth보다 relative depth에 더 의존한다는 것은 edge나 corner의 depth 값 그 자체보다는 주변 영역의 depth와의 관계를 고려하는 것이 더 적절하다는 의미로 이해해도 되는 것일까요? absolute depth < relative depth로 이해하였는데 "observation으로부터 absolute depth invariance가 2d cnn이 depth map으로부터 더 중요한 정보를 포착하는데 도움을 줄 수 있다는 점을 나타낸다."고 말씀하셔서 의미가 헷갈려서 질문 드립니다.
댓글 감사합니다.
먼저 질문주신거에 대해서는 Feature map과 depth map사이의 registration 후 3d point로 변환하는 것으로 보입니다. 전자의 경우에는 depth map을 사용하는 영향이 적어진다는 생각이 드는 거 같네요.
relative depth에 더 의존한다는 의미도 잘 이해하신 것 같습니다. 그 절대적인 depth가 큰 값이든 작은 값이든 주변 depth와 비교해서 그 차이가 클 때 corner나 edge와 같은 특징으로 나타나기 때문입니다.
헷갈렸다고 하신 부분에 대해서 제가 생각하기로는 absolute depth invariance라는 것이 절대적인 깊이의 불변성을 의미하므로 absolute depth가 불변할 때 relative depth도 보존될 수 있다고 생각이 듭니다.
감사합니다.