안녕하세요. 열 아홉번째 x-review입니다. 이번에 작성하는 리뷰는 최근 연구에 대해 고민하던 도중 김남일 연구원님의 연사를 듣고 흥미있어지게 된, 그러면서 권석준 연구원이 발표한 KCCV 모교수님의 “Top-down 방식으로 생각하라”를 오래 고민하다 지금의 흥미를 갖게 된 (물론 일을 하다보면 바뀔 수도 있겠지만) “자율 주행 차가 등장했을 때, Active learning도 필수적일테지만 Few-shot, One-shot detection도 필수적일 것이다”는 생각 아래 처음 읽어 본 분야의 논문입니다. 지난 주에 작성하고 싶었지만, 처음 읽어보다 보니 모르고 있는 개념이 많아 어려웠습니다. 그리고 Few-shot object detection을 제안한 첫 논문이지만, 논문은 주로 Transfer-learning을 다루고 있어 아쉬움도 있습니다. 그럼, 리뷰 시작하겠습니다.
Introduction
흔히 object detection 분야는 saturation 되었다고 표현합니다. 실제로, 최근 CVPR, ICCV, ECCV에서도 영상단에서의 object detection 분야 논문은 손에 꼽을 수준입니다. 하지만 현존하는 object detection은 COCO, Pascal VOC 등의 large-scale의, bounding box와 class에 대한 annotation이 존재하는 데이터에서의 성능입니다. 이제 앞선 시작부에서 자율 주행 차가 등장했을 때 Few-shot detection이 필수적일 것이라고 말한 이유를 말하자면, 쉬운 예로 최근 유행한다는 3차원 횡단보도와 같은 주행로에 새로운 클래스의 객체가 등장했을 때 자율 주행 차가 이를 탐지하는 것은 중요할 것이지만 급변하는 사회에서 그때마다 새로운 클래스에 대한 영상을 획득하고, 일일이 annotation하는 것은 무리입니다. 모델의 실시간 모델의 추론을 요하면서, 막상 새로운 객체가 등장하면 모델이 어떻게 대응해야 할지는 알려주지 못하는 실정입니다.
“현존하는 object detection은 주로 fully-annotated benchmark를 대상으로 한다.”의 문제를 풀고자 잘 알려진 방법 중 하나는 “처음 보는 클래스를 포함한 새로운 영상을 획득한 이후, 비교적 쉬운 수준의 label (e.g. classification)로 annotation”하는 방법입니다. 이 때, weakly-supervised learning이나 semi-supervised learning 등이 사용될 수 있습니다. object detection을 예로, weakly-supervised learning은 모델의 학습 및 예측을 위해서는 bounding box 좌표와 class 정보가 필요한데 일부만 존재 (예를 들면 이미지 내 객체의 클래스만 존재)하는 상황에서의 학습 방법을 다루고 있으며, semi-supervised learning은 일부 데이터만 label이 존재할 때 labeled 데이터로부터 모델링하여 unlabeled 데이터에 대한 결과를 내는 방법입니다. 하지만 위의 두 방법은 학습 이미지에 대한 supervision이 부족하여 성능면에서 한계를 보입니다.
다른 하나의 방법은 transfer learning입니다. 저자는 transfer learning에 대해 weakly-supervised, semi-supervised에 비해 성능 면에서나, 학습을 위한 추가적인 데이터 수집을 하지 않는 점에서 차라리 나은 방법이라고 말합니다. 하지만 transfer learning은 몇가지의 이유로 low-shot (few-shot, one-shot, etc) detection에서 어려움을 보이는데, 이유 중 첫 번째는 target dataset에 fine-tuning할 때, target dataset의 한 클래스에 대한 수가 적다보니, classification (class)과 detection (offset)의 태스크 차이를 극복하기 어렵다는 점입니다. 이는 예시로 학습 데이터에 없는, 처음 보는 고양이 클래스에 해당하는 사진이 3장 있다고 할 때, 3장의 이미지만으로 classification과 detection을 모두 잘 수행하기엔 분류 측면과 위치 측면에서 모델이 일반화되지 못하는 것과 같습니다. 이는 다시, “예시가 적어, 모델이 classification을 잘 할지, detection을 잘 할지 학습하는 것에 한계가 있어 이도저도 아니게 되어버린다.”로 표현할 수 있습니다.
다음의 이유로, transfer learning의 특성 상 일부를 freeze한 다음 fine-tuning하기 때문에 학습 과정에서 과적합되는 경향을 보입니다. 저자는 detection은 classification과 달리 localization을 포함하므로 object-specific한 representation을 학습해야 하지만, 전이 학습에서 적은 수의 데이터에서는 과적합될 위험이 높다고 주장합니다. 마지막으로는, 단순한 fine-tuning은 정보의 이식성을 감소시키며, 이는 source domain (학습하는 도메인)과 target domain (Few-shot이 존재하는 도메인) 간 중요한 정보가 무시될 수 있다고 주장합니다.
저자는 위의, 근본적으로는 Few-shot 상황에서의 문제를 해결하고자 LSTD (Low-Shot Transfer Detector)를 제안합니다. 사실 Few-shot learning에 대해 많은 논문을 읽어보진 않았지만, Transfer Detector라는 말에서부터 Few-shot의 어떠한 방법 (기저 지식이 많지 않아 어떠한 방법이 무엇인지는 아직 모르겠습니다만)을 제안했다기보단, Transfer learning을 Few-shot 상황에서 효과적으로 수행할 수 있는 방법을 제안한 것으로 느껴집니다. 또한, 당시 SotA에 준하는 1-stage, 2-stage detector인 SSD와 Faster R-CNN을 섞어 사용하는 방식으로 설계하였으니 이해에 어렵진 않을 것 입니다. 사실 이번 리뷰에서는 Few-shot learning에 대해, Few-shot, One-shot, Zero-shot의 Few,One,Zero는 어떤 것을 의미하는지, Shot은 어떤 것을 의미하는지에 대해 자세히 다루는 것이 목적이였으니, 이는 리뷰 작성 이후 남는 시간에 앞단 Preliminaries를 다시 작성하겠습니다.
Low-Shot Transfer Detector (LSTD)
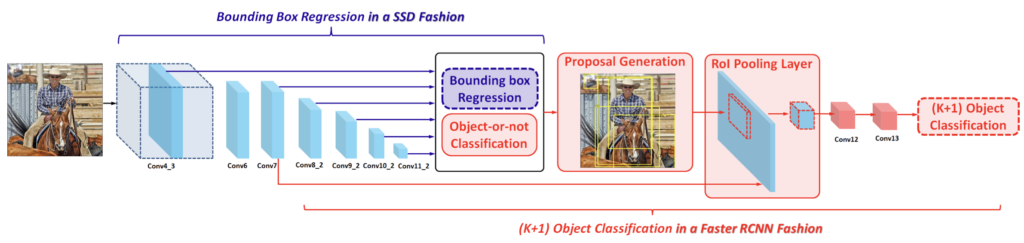
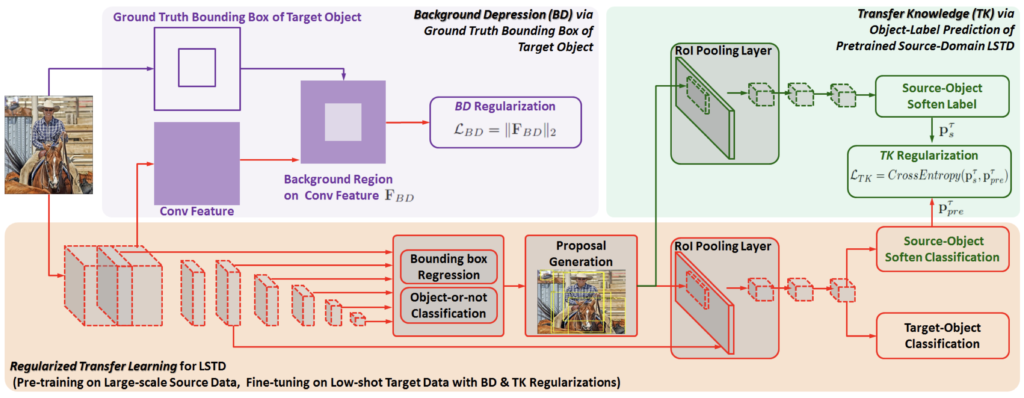
위 두 Figure를 통해 방법을 살펴보겠습니다. 우선, Low-shot (지금은 Few-shot이라고 부르겠습니다)의 목적은 Target dataset이 한정적일 때, 예를 들어 새로운 클래스 A에 대해 충분한 학습 및 평가 데이터가 확보되지 않았을 때, 좋은 성능을 보이는 것임을 잊지 않고 봐야합니다. 이 때는 우선 transfer learning이나 fine tuning를 하려해도, 데이터가 충분하지 않기 때문에 어려움을 겪을 것 입니다.
앞서 말한 바와 같이 저자는 SSD와 Faster R-CNN을 혼합하여 구성하였습니다. 요약하자면 bounding box regression은 SSD의 방식을, classifcation의 방식은 Faster R-CNN을 차용하였는데, 왜 그렇게 해야하는지, 하나의 detector로 구성하면 무엇이 문제였는지를 알아야합니다. 우리는 다음의 의문을 품을 수 있기 때문이죠. 1. Few-shot의 상황에 대비한 새로운 detector, detection 방법이 등장해야하지 않나? 2. 기존 detector를 차용했다면, 하나의 detector만 사용하면 되지 않나? 굳이 두 detector를 섞어 구성한 이유는 무엇일까? 우리는 두 의문을 풀고자, Related works를 다시 살펴보고 와야겠네요.
Related Works
Object Detection.
SSD는 다들 너무나 잘 알것이고, Faster RCNN도 잘 알겠지만, Faster RCNN만 잠시 짚고 넘어가겠습니다. Faster RCNN의 구성을 Figure 3을 통해 살펴보면, Achor box를 sliding window 방식을 통해 이미지 (혹은 Feature map)의 객체가 있음직한 영역을 제안합니다. (Region Proposal Nework, RPN) 이후, proposals들을 RoI Pooling을 통해 동일한 feature map 사이즈로 맞춘 이후, classifier를 통과시켜 객체 클래스를 구분하게 됩니다. 그러고 나면, 남은 것은 객체에 대한 bounding box regression을 진행하면 됩니다. 코드적으로는 자세히 보진 않았으나, 어려운 구성은 아니죠. 하지만, RoI Pooling 이후 classification이 일어나고, 이후 bounding box regression이 일어나는, 즉 객체에 따라 bounding box regression이 진행됩니다.
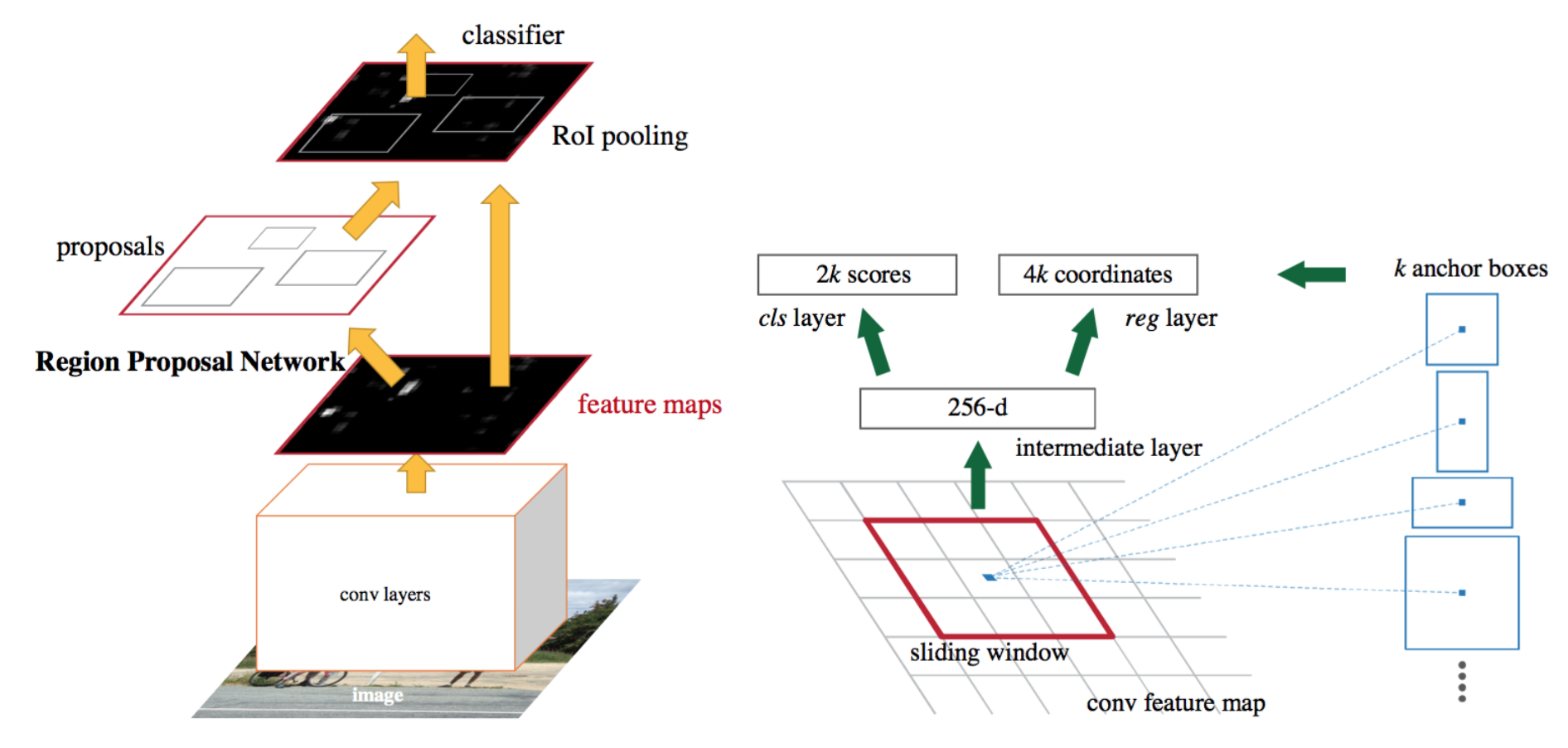
이제 반대로 SSD를 살펴보죠. 살펴볼 필요보다는 Faster R-CNN과 하나의 비교를 하고 싶습니다. SSD는 쉽게 설명하면 하나의 Feature map에 픽셀마다 정해진 수만큼 Anchor box를 생성한 이후, 바로 classification을 진행합니다. 이 때 bounding box regression이 먼저냐, classification이 먼저냐할 것 없이 수 많은 Anchor box에 대해 객체가 있음직하다를 바로 판단하고 bounding box regression도 동시에 일어납니다. 말로 설명해서 이해하기엔 다소 어렵지만, 우리는 SSD의 특성을 그만큼 잘 알고 있으니 이해되었으리라 생각합니다.
이러한 두 detector의 다른 특성이 이제 어떤 영향을 미치는지 살펴보겠습니다. 우선 Faster R-CNN은 객체의 클래스에 따라 bounding box regression을 진행하기 때문에, Few-shot의 상황에서는 bounding box regression은 source domain에서 학습된 파라미터를 이용하지 못하고, 랜덤 초기화로 진행해야 합니다. 왜죠? Few-shot target domain에서는 source domain에서 보지 못한 클래스를 마주하기 때문이죠. 이전 파라미터를 그대로 사용한다면, 물론 classification은 fine-tuning하겠지만 이전 파라미터들은 K개의 클래스에 대한 classification을 위한 파라미터에 대한 bounding box regression 파라미터를 이용해야하는데, 이는 앞뒤 말이 맞지 않습니다. Faster R-CNN이 classification->bounding box regression 순으로 진행하는 특성을 잘 생각해야 이해할 수 있습니다.
반대로 SSD는 어떨까요? SSD는 이제 classification에 문제가 생깁니다. prior bounding box에 대해 바로 K+1 개 (K개의 object + background 클래스)에 대한 classification을 수행해버리는데, 우리는 classification 시 K개가 아닌, Few-shot의 N-way 개의 클래스를 가지고 있으니 이 때도 랜덤 파라미터로 초기화해버려야 합니다. (Few-shot에 대해 아주 간단히 짚고 넘어가자면, 5개의 클래스, 예를 들어 강아지, 고양이, 소, 말, 치타의 클래스가 학습 도메인 (source domain)에서 보지 못했는데, 그러한 클래스에 대한 데이터 (support set, 학습을 위해 충분하지 않은 양의 데이터를 모은 데이터)가 각 1개씩만 존재한다면 5-way One-shot, 몇몇만 존재한다면 5-way Few-shot, 하나도 존재하지 않는다면 (주로 텍스트와 동시에 사용하는 멀티모달 방법을 통해) Zero-shot으로 불립니다).
우리는 두 detector를 살펴보고 나니, 이제 저자가 왜 classification에서는 Faster R-CNN을, bounding box regression에서는 왜 SSD를 사용한지 아직은 미연하지만 그래도 의도가 이해갈 수 있습니다. 오히려 독자들에게 친숙한 두 모델을 붙여 새로운 Task(?)를 해결하고자 했으니 당시엔 더 좋은 평을 받을 수도 있었단 생각도 드네요. 모델의 구성은 우리가 이미 알고 있으니 이를 다른 영역에 효과적으로 활용한 셈이죠.
Continue on… LSTD
다시 방법으로 돌아왔습니다. 바로 위의 Related Works를 이해했다면, 사실 추가 설명할 부분은 많지 않습니다. 먼저 다시 bounding box regression은 SSD의 방식을 가져와, 모든 위치에 후보 bounding box (candidate, default dounding box)를 둔 이후, ground-truth bounding box와 매칭하는 일반적인 방식을 사용합니다. 잊지 말아야할 점은 지금은 source domain 즉, 대용량의 label이 있는 데이터에서는 모델이 일반적인 표현력을 배워야 합니다. 이 때의 SSD에게 기대하는 일반적인 표현력이라 함은 어떤 객체를 담은 이미지가 입력으로 들어와도, 객체의 위치 정도는 찾을 수 있어야한다는 의미겠죠.
결국 우리가 피해야할 점은 대용량의 데이터로 실컷 학습시켜놨더니, 새로운 클래스가 오니까 어? 얘는 본 적이 없어서 다시 초기화 상태로 돌려야하는데?를 피해야 합니다. 그러고자 한다면 SSD에서 왜 bounding box regression이 효과적인지 느끼고 이해할 수 있을 것 입니다. 물론, 이런 점에서 진정한 Few-shot learning인가?하는 의문은 들죠. 학습 방식이 결국 transfer learning이기 때문입니다.
두 번째로, object classification에서는 Faster R-CNN의 방식을 차용합니다. 우선, SSD에서 찾은 bounding box들이 객체가 있음직한 후보군이라고 했을 때, 처음 할 일은 객체인지 아닌지, binary classification을 합니다. 이는 Faster R-CNN의 RPN과 동일합니다. 이후, RoI Pooling을 통해 고정된 사이즈의 Feature map을 생성하고, FC layer 대신 두 층의 convolution layer를 통해 classification을 진행합니다. 저자는 FC layer 대신 convolution layer를 사용함으로써 source domain에 과적합되는 것을 방지할 수 있다고 합니다. 왜 그런지는 생각해보면, FC layer의 output이 K개의 1차원 Feature vector를 생성하기 때문에 convolution layer를 사용하는 것이 효과적임과 연관지어 생각해보면 좋을 듯 합니다.
저자는 이러한 coarse-to-fine detection 방법 (Faster R-CNN에 국한되어 말했는데, 저자가 하고 싶은 말은 binary classification 이후 객체가 있다고 판단된 지점에 대해 객체의 클래스를 구분하는 classification 태스크를 통과하기 때문에 classification을 직접적으로 수행하는 SSD에 비해 효과적이고 transfer learning 시의 어려움을 한층 줄여줄 수 있다고 하지만, 제 생각엔 SSD와 직렬적으로 일어나는 Faster R-CNN의, 현 모델 구조가 coarse-to-fine을 설명하기에 조금 더 적합하지 않는가라고 생각듭니다.)
최종적으로는 이러한 모델 구조를 통해 Few-shot 상황에서도 효과적인 learning, 흠.. Few-shot이라기 보단 transfer learning을 잘 할 수 있으며, 이는 현 모델을 제외하고서도 우리 모두 하나의 가정을 상정해야합니다. 적절히 잘 만든 모델이라면, source domain과 target domain의 공통된 특징, 예를 들면 색상 엣지와 텍스쳐 정보를 배경과 구분할만큼 잘 학습할 수 있을 것임을 기대하는 것이죠. 이는 일반적인 가정이지만 Few-shot과 같은 상황에선 더더욱 마음에 새겨야할 것 같습니다.
Regularized Transfer Learning for LSTD
LSTD라는 Scheme을 만들고나서, 저자는 다시 고민합니다. 이것만으로 충분할까? 가장 피하고 싶은, 파라미터를 랜덤 초기화하는 것을 어느정도 피하고 나서도, source domain의 데이터 양이 방대하다보니 그리고 target domain (support set)의 수가 적다보니 과적합이 여전히 생기지 않을까? 저자는 이 점에 대해 Regularized, 즉 Loss term에 몇 가지 규제화 방법을 둡니다. 어렵진 않으니 바로 살펴보겠습니다. 우선, LSTD의 전체적인 파이프라인을 다시 살펴보고 가겠습니다. 제가 이 파이프라인에 대해 위에서 이미 3-4차례는 이야기한 것 같은데, 그만큼 Few-shot의 개념이 온전치 않은 분들은 몇 번이나 짚고 생각해야만 온전히 알 수 있을 것 같다고 생각이 들었기 때문입니다. 저 또한 마찬가지지만요. 먼저, large-scale의, source domain 데이터에서 LSTD를 학습합니다. 두 번째로는 사전 학습된 LSTD를 N-way Few-shot의, target domain 데이터에서 fine-tuning 해줍니다. 이 때 두 번째에서 과적합을 방지하고 성능 향상을 위한 규제화를 둡니다. 아래 식을 살펴보시죠.
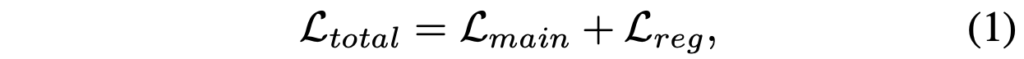
Katex로 수식을 작성할 때는 가독성 면에서 참 좋고 편했는데, 지금 워드프레스에서는 다시 지원을 안하는지 안 찾아지네요. \mathcal{L}_{total} = \mathcal{L}_{main} + \mathcal{L}_{reg} 에서 main으로 표시된 Loss는, bounding box regression (SSD의 SmoothL1Loss)와 coarse-to-fine classification (Faster RCNN의 CELoss, 추가적으로 binary classification도 진행하니 BCELoss도 포함)을 더한 Loss입니다. 다시 classification 과정을 살펴보면, 여전히 의문점이 생길 수 있는데, source와 target은 유사하지만 실제로는 다른 데이터를 포함하고 있고, 그렇기에 우리는 low-shot, Few-shot으로 불리는 이전에 보지 못한 클래스에 대해 잘 학습하는 것이 중요합니다.
저자는 위의 경우, Faster R-CNN의 classfication (RoI를 통한)을 사용하는 것이 SSD로 진행시에는 파라미터를 랜덤 초기화해야하기에 더 좋긴 하지만, 여전히 target domain에서 과적합의 문제가 있을 것이라고 봅니다. 특히, bounding box regression과 object가 있는지 없는지 정도는 사전 학습에서 충분하지만, 실제 클래스를 분류하는 문제는 다르다고 설명합니다. 그렇기에 저자는 reg Loss term을 추가하는데, 그 수식은 또 재미있습니다. 아래를 보시죠.
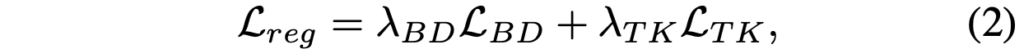
\mathcal{L}_{reg}는 \mathcal{L}_{BD}, \mathcal{L}_{TK} 에 \lambda 만큼 규제를 둔 두 Loss의 합으로 구성되어 있습니다. 그럼 우린, 이제 방법론의 마지막인 BD Loss와 TK Loss에 대해서도 알아봐야합니다. 어쨋든 제 입장에선 애매하다고 생각이 들어도 Few-shot object detection의 시초로 불리는 논문인만큼, 저자가 많은 것들을 고려한 점이 굉장히 인상깊고 그만큼 철저하네요.
Background-Depression (BD) Regularization
Figure. 2의 보라색 박스를 잘 살펴보면, 단번에 이해할 수 있습니다. 단순히, SSD가 입력 받는 이미지에 대해 bounding box를 그리는 것이 일반성을 보이는 좋은 모델이긴 하지만, 여전히 배경으로 인해 transfer learning 시 어려움을 겪을 수 있다고 주장합니다. 이는 아무래도 배경 클래스에 해당하는 다양한 색상, 텍스쳐 정보들이 객체를 판단하는데에 방해가 될 수 있다는 것과 같습니다. 음, 일리가 있는 말도 같습니다. COCO, Pascal의 데이터를 분석해보면 객체들이 가로로 길쭉한 지, 세로로 길쭉한 지, 혹은 객체가 영상 내 한 두개가 등장하는 지, 여러 개가 등장하는 지, 또는 객체가 영상의 중앙에 떡하니 있는 지, 아니면 배경과 굉장히 유사한 상황에 놓여있는 지에 대해 모델의 일반적인 검출 성능을 비교하는 논문 (그 논문에서 해당 부분만 다루지는 않았지만)이 있었는데, 생각해보면 그때는 다양한 배경들이 도움될지..는 몰라도, 지금은 전이 학습 시 배경이 오히려 방해될 수 있단 점입니다. 저자는 “그렇게 적은 수의 데이터로 모델이 일반적인 객체의 표현력을 배워야하는데, 배경이 웬 말이냐”고 하죠.

따라서 아주 간단한 방식, 예를 들면 target domain 데이터의 ground-truth bounding box를 마스킹 씌우고, 그렇다면 우리는 feature map에서 배경에 해당하는 부분에 대한 값들을 확실히 구분지어 추출할 수 있을 것이고, 결과적으로는 background에 해당하는 feature region인 F_{BD} 를 획득할 수 있습니다. 이제, F_{BD} 에 L2 규제화를 통해 penalty를 주어 모델이 조금 더 객체에 집중할 수 있게 해주는 것이죠. 수식으로는 \mathcal{L}_{BD} = ||F_{BD}||_2 로 표현할 수 있습니다.
Transfer-Knowledge (TK) Regularization
이제 classification에 대한 규제입니다. object classification에 대해 사전학습된 파라미터를 사용하고자, 우선적으로는 객체가 있는지 없는지, binary classification을 진행하지만 이전 source domain에서 (K+1)개의 클래스에 대해 진행하던 중, K’개의 새로운 클래스를 만났으니 그 부분은 랜덤 초기화가 되어야한단 것이죠. 이러한 경우, 단순히 target domain의 데이터에 대해 fine-tuning하는 것은 source domain에서 학습한 정보를 이용하지 못하는 꼴입니다.

Figure 4가 굉장히 도움되겠네요. 저자는 AeroPlane이나 Cow와 같은 Target Image에 대해, Source domain에서 색상이나 형태의 유사성으로 인해 연관성이 강한 kite, bear 클래스의 지식을 활용하고자 합니다. transfer-knowledge (TK) 규제화에서는, source network의 object-label prediction을 source domain의 knowledge로 두고 target domain에서의 규제화를 상정합니다. 우리는 Faster R-CNN을 classification을 위해 사용하므로, 이미지 전체가 아닌 Proposal region에 대해서만 진행하면 되죠. 과정은 아래와 같습니다.
우선, LSTD에 source domain과 target domain 이미지를 입력으로 합니다. 그리고서, source domain을 학습한 LSTD의 RoI Pooling layer부분에 target-domain의 Proposal region을 입력으로 합니다. 이렇게 함으로써 저자는 모델이 source domain과 target domain이 서로의 정보 교환을 효과적으로 가져갈 수 있다고 합니다. 수식은 아래와 같이 표현되며, 이 때 a_s 는 각각의 object proposal의 softmax 적용 이전의 벡터를 의미합니다. \tau 는 temperature parameter라고, softmax 분포를 완만하게 혹은 뾰족하게 만드는 역할을 하는 실수값에 해당합니다. 궁금하신 분은 다음 링크의 블로그를 참고하시면 도움이 됩니다.
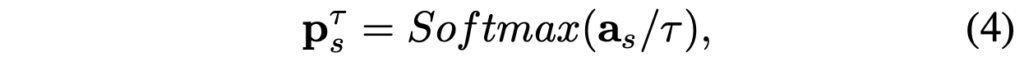
이제 source domain의 knowledge인 p^T_s 를 학습 과정에서 target domain에 포함시키기 위해, 저자는 target domain의 LSTD를 multi-task learning 형식으로 변형합니다. 구체적으로 보자면, source-object의 soften(parameter parameter) classifier를 target domain을 학습하는 시점의 LSTD의 끝단에 추가합니다. 이로써 모델은 이전 source domain에서 유사한 정보를 갖는 class의 다양한 정보를 활용할 수 있게 됩니다. 예를 들어 비행기(Aeroplane)와 유사한 연(kite)은 방대한 양의 데이터가 있고, 모델은 그 표현력을 알테고, 비행기는 몇몇 없으니 비행기에 대한 색상 정보나 형태 정보를 연에서부터 어느정도 학습할 수 있다는 것과 같겠죠. 수식은 아래 (5)와 같이 표현되며, TK Regularization은 최종적으로 두 (4)와 (5)에 CrossEntropy Loss를 적용한 (6)과 같습니다.
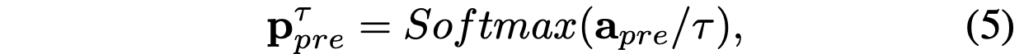
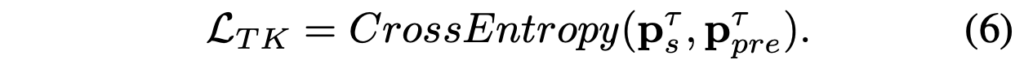

위의 알고리즘을 통해 전체적인 파이프라인을 마지막으로 살펴보고 끝내겠습니다. 자, 이제 방법은 모두 끝입니다. 정말 방대한 양이였네요. 음, 사실 양이 방대했다기보단, 처음 읽어보는 듯한 분야이다 보니 추가적인 검색이 많이 필요했던 것 같습니다. 이제 실험만 보고 마무리해보겠습니다.
Experiment

저자는 object detection 분야의 대표격인 그리고 image classification 데이터도 더불어, COCO, ImageNet, Pascal VOC 2007, 2010을 Source와 Target domain으로 구성하였습니다. Table 1을 통해 확인할 수 있으며, 물론 Few-shot의 개념에 맞게끔 클래스를 겹치지 않게끔 선정하여 구성하였습니다.
클래스의 수가 N-way에 포함된다고 했고, 클래스에 해당하는 샘플의 수가 N-shot이라고 말했는데, 저자는 보통 20, 50개의 클래스 (20-way, 50-way)에 대해 1,2,5,10,30 개의 이미지만 transfer learning 할 수 있게끔 (One-shot도 포함되어 있네요) 설정했습니다. 물론 이 때 랜덤하게 뽑았겠지만, 어떤 데이터를 Target domain으로 구성하느냐도 성능면에서 영향을 미칠 순 있습니다. 하지만, 그 면이 성능에 영향을 미친다는 것이 해당 태스크의 본질에 대해 의구심을 가져선 안됩니다. 왜냐하면, 현실에선 어떤 데이터도 취득될 수 있기에 랜덤이라 한들 사실 그 점은 지당하게 받아들여야합니다. 정말 이 점에서 의문점이 생긴다면, Supervised learning만이 답이라는 결론으로 귀결될 수 밖에 없을 것 입니다.
Implementation detail도 적혀져 있습니다. SSD의 7 번째 Layer에서 RoI Pooling을 진행하는 등의, 그리고 Conv12와 Conv13에서도 진행하는 방식에 대해 적혀 있지만, SSD와 Faster R-CNN을 안다면 어렵지 않게 이해할 수 있고 또한 우리가 지금 구현까진 하지 않을 것이기에 일단은 넘어가겠습니다. 위의 방법론에서 사실 전반적인 파이프라인이 더 중요합니다. 정말 사소한 detail(conv7의 feature map size 등..)이기 때문에 해당 부분은 넘어가고, 이제 실험 결과를 살펴보겠습니다.
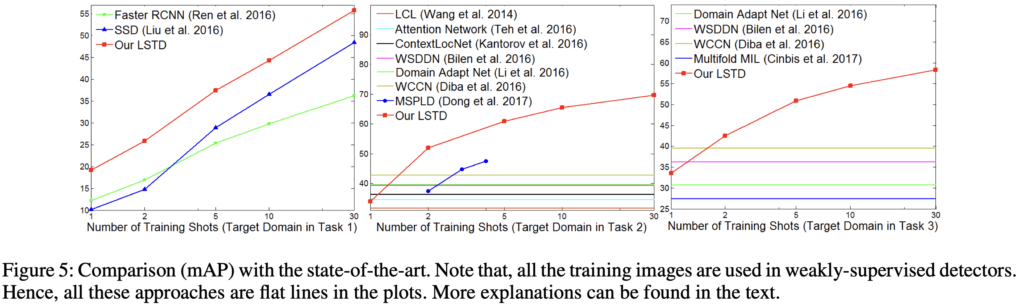
Figure 5는 Training shots (1-Shot, 5-Shot, …, 30-Shot)이 증가함에 따른 성능 비교입니다. weakly-supervised는 Shot의 개념이 존재하지 않으므로, Flat한 모습을 볼 수 있습니다. 그보다 중요한 점은, 당연하지만 우리는 이러한 Few-shot을 처음봤다면 Shot의 수가 많을 수록 모델의 일반 성능이 노아지는 것은 당연하단 점입니다. 그리고, 맨 왼쪽 그래프에서와 같이 SSD와 Faster R-CNN을 단순히 Fine-tuning하는 방식의, classifier만 Freeze하고 Few-shot learning을 진행하면 성능이 그다지 좋진 못한 모습입니다. 아마도, Shot이 많을 수록 SSD의 성능이 높아지는 것은 초반부에는 객체의 클래스에 대한 분류 성능이 전체 성능에 지배적일 수 있었지만, Faster R-CNN은 객체의 위치를 찾는 것에는 영.. 수가 조금 늘더라도 잘 하지 못하는 모습을 보입니다.
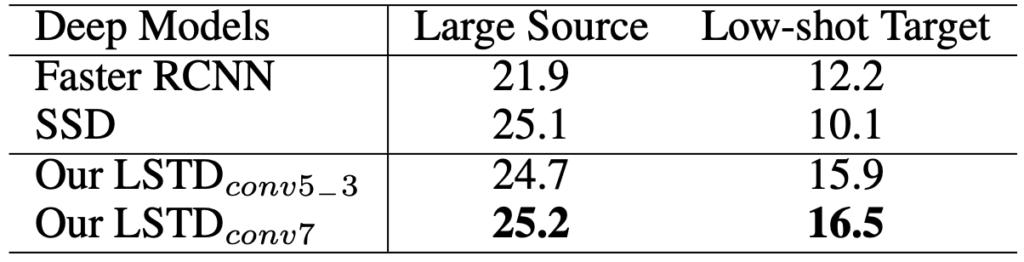
수치적으로는 위의 표와 같습니다. conv7에서 RoI Pooling을 적용한 것이 역시나 성능면에서 더 우수했기 때문에, 그렇게 했다고 이해하고 넘어가는 것이 좋을 것 같습니다.
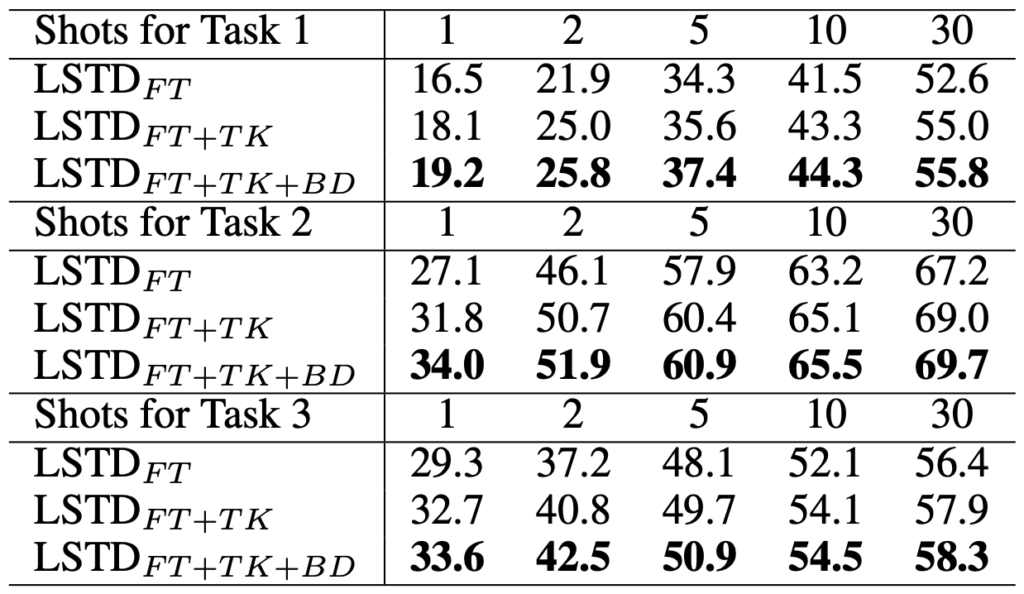
Shot의 수와 FT, TK, BD (순서대로 standard fine-tuning, transfer-knowledge regularization, background-depreesion regulrization)을 추가한 Ablation study입니다. 역시나 위 예시와 같이 Shot이 증가함에 따라 성능이 좋고, Task 1,2,3은 위 Table 1에 보이는 것 처럼 source domain과 target domain에 따른 성능 차이를 보여주며, regularization Loss를 통해 성능 향상이 일어났음을 보이고 있습니다. 마지막으로 정성적 결과를 확인하고 마무리하겠습니다. 결론으로 말하고 싶은 점은, 이러한 Few-shot object detection을 앞으로도 Follow-up할 계획에 있는데, object detection에 새로운 지평을 열어주지 않을까 아니, 앞으로의 deep learning 트렌드로 active learning과 함께 자리잡지 않을까 하는 것이 저의 생각입니다. 리뷰 읽어주셔서 감사합니다.
(정성적 결과 업로드하려하는데, 파일 용량이 넘는다고 하네요.. 관심 있으시다면 논문을 직접 찾아보셔도 좋을 것 같습니다만, 정말 볼만한 점은 그대로 Shot의 수가 늘어남에 따라 성능이 좋아짐을 말하는 것 외에는 딱히 없긴 합니다..)
리뷰 잘 읽었습니다.
제 이름이 보여서 반가운 마음에 달려와 읽게 되었습니다.
사실 논문 관련된 이야기라기 보다는 상인님의 생각에 관련된 질문일 수 있습니다. 요즘 리뷰해 주시는 논문들이나, 밥 먹으면서 얘기를 나눠보면 zero/few shot, active learning 쪽으로의 가능성도 열고 계신 거 같은데요, 앞으로 하고자 하는 연구의 방향성이 궁금합니다.
가령 원론적인 active learning or zero/few shot 인지, 아니면 이를 detection 이라고 하는 specific task에 녹이고 싶은 건지를요.
감사합니다.
생각을 하다 지금 와서 댓글을 남깁니다.
제가 이전 리뷰한 Pedestron, 코끼리를 방 안에 넣는 동영상을 담은 논문을 읽고 어떤 새로운 시각을 느낀 것이 맞는 것 같습니다.
그 이후 논문이나 연구들을 볼 때, 과연 이 방법은 이 데이터에만 국한된 방법일까?는 생각이 꼬리를 물며 다른 방법이 없을까?도 많이 고민해보게 되었고, 그렇게 석준님이 말씀하신 Top-down은 아니지만 Middle-Middle.. 정도로 고민이 깊어졌습니다. 그래서 제가 홀로 서는 연구자가 되었을 때는 그리고 되고자 한다면 어떤 연구를 하고 싶은지에 대한 고민도 많아졌구요.
그러면서 Pedestron 논문의 시각에서, 진부하지만 “급변하는 현실”에서 생기는 수 많은 데이터를 모델은 어떻게 인지할 수 있을까?에 대한 고민도 생겼습니다. 이는 마치 data-driven deep learning에 대한 진정한 인공지능인가, 진정 사람을 따라하는 것인가에 대한 의구심과도 같이요.
그러면서 몇몇 검색해봤고, 다크데이터 팀의 예전 논문들도 하나 둘 읽으며, 그러면서 Few-shot, Zero-shot이라는 분야를 보며 이것이 미래에는 꼭 필요할 것이라는 것이 와닿아버렸습니다.
그러면서 원론적인 Active learning과 같은 learning 기법이냐, 아니면 detection과 같은 specific task에 녹이고 싶냐고 물어본다면, 그래도 전자가 조금 더 가깝긴 한 것 같습니다만, 지금은 제가 제일 잘 아는 태스크는 detection (잘 안다기 보단 그나마..)이고, 이처럼 specific한 태스크에 녹였을 때 어떻게 풀까가 가장 궁금했습니다.
특히, Few-shot과 같은 경우는 Detection에서 Localization을 대체 어떻게 해결할까?가 굉장히 궁금했거든요… 그렇기에 지금은 제가 친숙한 detection에서 진행한 Few-shot, Zero-shot, AL 등의 논문을 예전꺼부터 하나씩 찾아보고 있긴 합니다. 그나마 이해가 좀 쉽더라구요.,,
그래서 결론은 위의 대답은 아직 답을 찾아가고 있는 중입니다. 막상 원론 Learning 방법을 맞닥드렸을 때, 그 때에서야 딴 이야기를 하지 않게끔요.. ㅎㅎ. 끊임없이 고민중이고, 석준님의 이런 질문들 덕분에 다시 한번 고민하고 의논을 할 때마다 큰 도움이 됩니다. 질문해주셔서 감사합니다.
안녕하세요 상인님 좋은 리뷰 감사합니다!
윗글에서 reg Loss term과 관련해서 질문이 있습니다.
reg Loss의 공식을 보면 BD Loss와 TK Loss에 λ가 곱해져있어서 각각의 가중치가 얼마나 곱해는지 궁금하여
찾아보았는데 논문에서는 각각 0.5씩 곱해진다고 나와있었습니다.
일반적으로 저런 구체적인 숫자를 구하기 위해서는 직접 가중치를 바꿔가면서 성능이 좋게 나올때까지 여러번 실험을 진행해야하나요?? 아니면 적절한 가중치를 구하기위한 방법이 따로 있는건가요??