이번에 소개드릴 논문은 Self-supervised monocular depth estimation task에서 모델의 architecture를 매우 경량화하여 모델 크기 대비 성능을 향상시킨 방법론에 대한 논문입니다.
Intro
Self-supervised monocular Depth Estimation(SDE) task는 영상만으로 깊이 추정을 학습하는 self-supervised learning과 단안 이미지로 깊이를 추론한다는 monocular depth estimation이 합쳐진 task를 의미합니다.
이러한 SDE 분야는 monodepth2가 SDE의 정형화된 framework을 19년도 ICCV에서 제안한 뒤로 대부분 Architecture 관점에서 많은 연구들이 이루어져왔습니다.
이 중에서 20년도 초기까지는 CNN을 활용한 연구들이 많이 진행되었으며, 22년도부터는 본격적으로 ViT를 활용한 방법론들이 SDE 분야에 많이 제안되어왔습니다.
여기서 CNN은 local feature를 잘 추출해내긴 하지만 global context information을 포착하는 능력은 떨어졌기에 성능을 크게 향상시키기에는 어려움이 있었습니다. 반면에 Transformer의 Multi-Head Self-Attention(MHSA)는 global feature를 잘 포착시킴으로써 성능 향상에 매우 큰 영향을 끼치긴 했지만, MHSA 특유의 너무 많은 연산량으로 인하여 추론 속도 측면에서 매우 불안정하다고 볼 수 있습니다.
이러한 관점에서, 저자는 성능도 준수하면서 매우 가볍고 빠른 SDE 방법론을 제안하고자 하였으며 결과적으로 CNN의 빠른 추론속도 + local feature를 포착하는 능력 및 Transformer의 MHSA 연산을 통한 정확도 향상을 취하고자 CNN+Transformer의 Hybrid 구조를 새롭게 제안하였습니다.
Method
그럼 방법론에 대해서 알아보죠. 일단 SDE task가 어떻게 학습하는지에 대해서는 저의 예전 리뷰들을 참고하시면 될 것 같아서 본 리뷰에는 설명하지 않도록 하겠습니다.(링크)
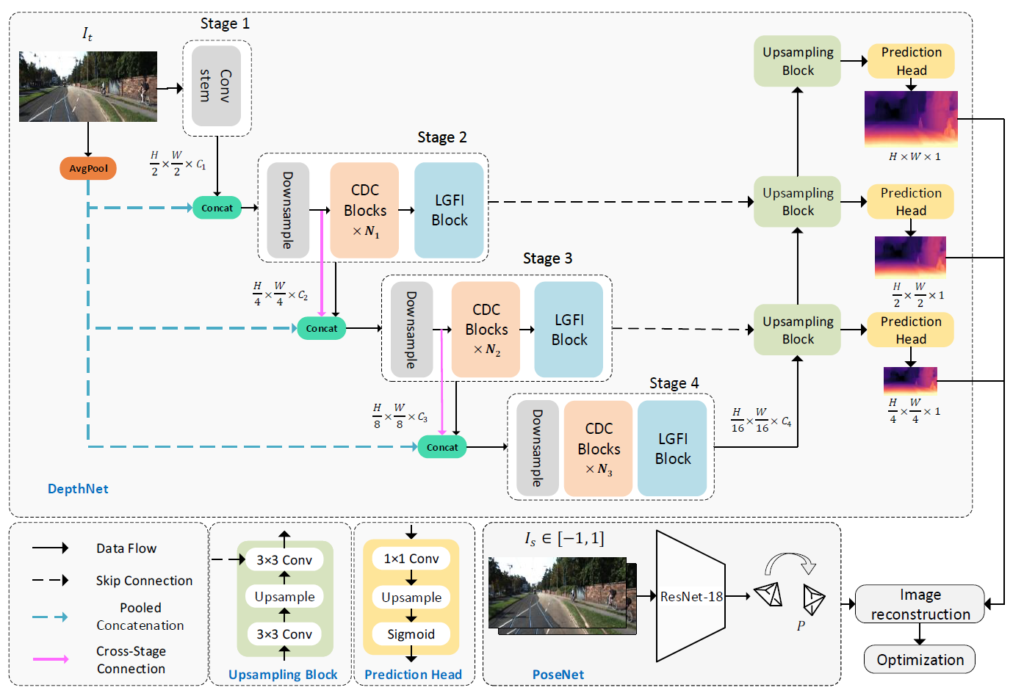
먼저 그림1은 본 논문의 framework을 나타냅니다. 해당 논문에서 가장 중요하면 부분은 Consecutive Dilated Convolution(CDC)와 Local-Global Features Interaction(LGFI) 입니다.
CDC 모듈을 통해서 보다 강화된 multi-scale feature map을 포착하고자 하였으며, LGFI에서 MHSA 연산을 통해 Attention 연산을 수행함으로써 Global Feature를 잘 담고자 하였습니다.
각각의 모듈에 대해서는 밑에서 조금 더 자세히 알아보죠.
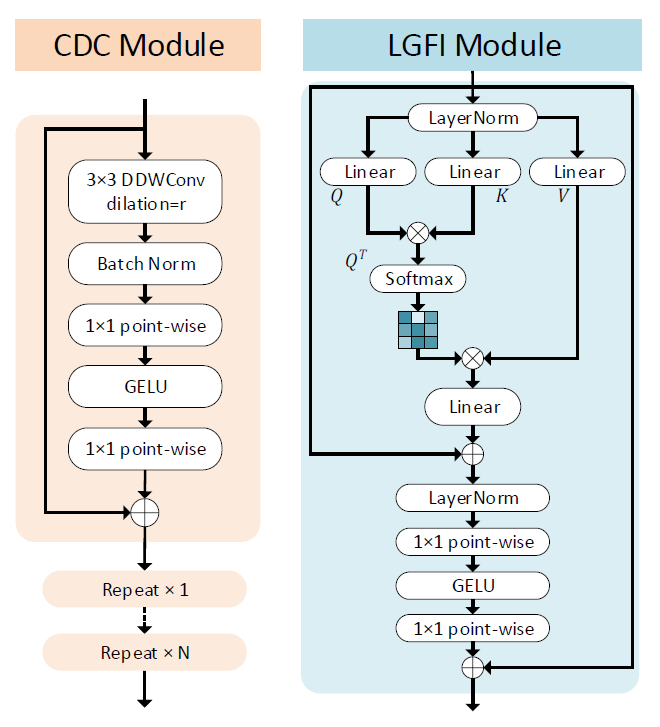
Consecutive Dilated Convolution(CDC) Module
먼저 CDC 모듈에 대한 설명입니다. 그림2 좌측을 살펴보시면 CDC 모듈은 3×3 DDW Conv와 Batch norm- 1×1 conv-GELU-1×1 conv layer로 구성되어 있는 모습입니다. 여기서 DDW Conv란 논문에서 어떤 명칭이라고 딱히 언급한 부분이 없어서 이름은 모르겠지만 Dillated rate의 비율이 서로 다른 컨볼루션들이 있다고 생각하시면 될 것 같습니다.
즉 기존의 Dillated conovlution을 활용하는 방법론들은 dillated convolution의 dillation 비율 값을 항상 고정해서 사용한 반면에, 제안하는 방법론은 각각의 스테이지마다 다른 dillation rate을 사용함으로써 multi-scale feature map을 더 잘 추출할 수 있었다고 합니다.
아무튼 이러한 CDC Module이 각 stage 별, 모델 크기에 따라서 N번 반복을 수행하는 main encoder module이라고 생각하시면 될 것 같습니다.
Local-Global Features Interaction(LGFI) Module
다음은 LGFI 모듈에 대한 설명입니다. 사실 해당 모듈은 그냥 transformer랑 똑같이 생기긴 했습니다. 다만 기존의 transformer의 경우에는 Query와 Key 사이에 내적을 계산할 때 channel dimension 끼리 내적함으로써 최종적인 결과 값이 Spatial Dimension을 의미하는 NxN의 크기를 가지게 됩니다. 즉 이러한 내적 연산은 영상의 해상도가 커지면 커질수록 제곱에 해당하는 연산량이 소모되게 됩니다.
저자는 이러한 방대한 연산량을 줄이기 위해서 spatial dimension에 대한 attention map을 구하는 것이 아닌 channel dimension에 대한 attention map을 구하는 방법을 사용합니다? 사실 이것은 저자가 직접 제안한 방법은 아니고, Neurnips 2021년도에 제안된 XCiT: Cross-Covariance Image Transformers 이라는 방법론에서 사용하는 cross-covariance attention 방식을 그대로 차용했다고 합니다.
사실 이렇게 channel dimension에 대한 attention map을 구하는 것이 우리가 의도하는 ViT 등의 attention 방식과 과연 맞나… 라는 생각이 크게 들긴 하는데, 저 위에 XCiT 논문을 읽어봐야 정확히 알 것 같습니다.
아무튼 이렇게 attention 연산을 수행하게 되면 feature map의 해상도가 아닌 channel 길이에 따라서 attention 연산량이 결정되게 되는데, 제안하는 논문의 핵심은 경량화이기 때문에 나중에 표로 보여드리겠지만 feature map의 채널 크기가 256 보다 더 작게 잡혀있습니다.(80~220 정도?)
그리고 또 이러한 MHSA 연산이 들어간 LGFI 모듈은 CDC Module과 달리 각 스테이지 별로 단 한번만 적용이 되기 때문에 MHSA 연산으로 인한 연산량 증가는 그리 크지 않은 편입니다.
DepthNet
이렇게 핵심 모듈에 대해서 알아보았으니 DepthNet 전체가 어떤식으로 동작하는지에 대해서 전반적인 흐름을 간략하게 다뤄보겠습니다.
먼저 입력 영상으로 RGB 3채널 이미지가 입력된다고 하였을 때, 2 stride 값을 가진 3×3 conv 레이어를 통해 해상도가 1/2배 줄어들게 됩니다. 그 이후에 stride 1의 3×3 conv 2개를 연달아 연산하여 1/2 scale의 feature map이 생성됩니다. 해당 과정을 Conv Stem 모듈이라고 합니다.
그 다음에 각각의 1, 2 stage에 대한 연산이 진행이 되는데 각각의 stage는 먼저 stride 2의 3×3 conv layer가 가장 먼저 수행되어 feature map의 해상도를 1/2배 감소시킵니다. 그 이후 N개의 CDC module과 마지막으로 LGFI 모듈이 뒤따라 연산이 됨으로써 스테이지가 마무리 됩니다. 모든 stage는 이러한 downsampling conv layer, CDC Module, LGFI Module로 구성이 되어 있음을 그림1을 통해 다시 한번 확인이 가능합니다.
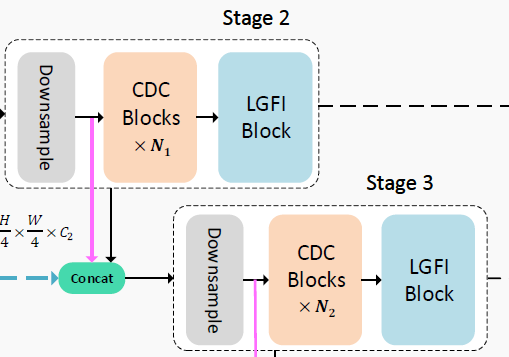
한가지 재밌는 점은, 다음 n+1번째 stage로 입력으로 n번째 stage의 output feature map 뿐만 아니라 n번째 stage 속 downsampling conv를 타고 나온 feature map을 함께 concat해서 넣어준다는 점입니다. 이를 저자는 cross-stage connection이라고 명칭을 붙였는데, 마치 resnet의 residual 연산처럼 각 stage 사이에 residual을 연산해주는 의미라고 생각하시면 됩니다.
또 다른 재밌는 점으로는 각 stage의 입력으로 이전 stage의 input/output 뿐만 아니라 input image의 avg-pool image가 함께 들어온다는 점입니다. 이러한 컨셉은 ESP-Netv2라는 방법론이 제안한 방식으로, 경량화 모델의 경우 feature map의 채널축 차원이 너무 shallow한 나머지 입력 영상의 spatial information이 풍족하지 못하다고 판단되며 따라서 입력 영상을 avg-pooling하여 채널축으로 함께 concat하여 사용한다고 합니다.
Depth Decoder는 monodepth2에서 사용한 3×3 conv – Bilinear Upsampling – 3×3 conv 구조를 활용한다고 합니다.
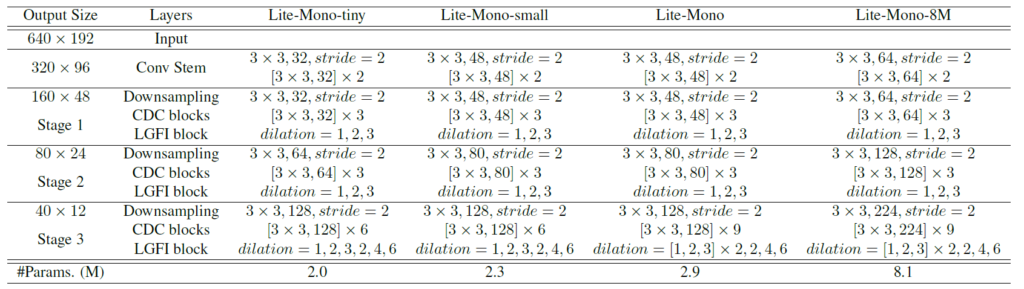
결과적으로 논문에서 제안하는 모델의 구성 및 크기 등 자세한 정보는 아래 표를 통해서 확인이 가능합니다.
Experiments
그럼 실험 섹션에 대해서 다루고 마무리 짓겠습니다.
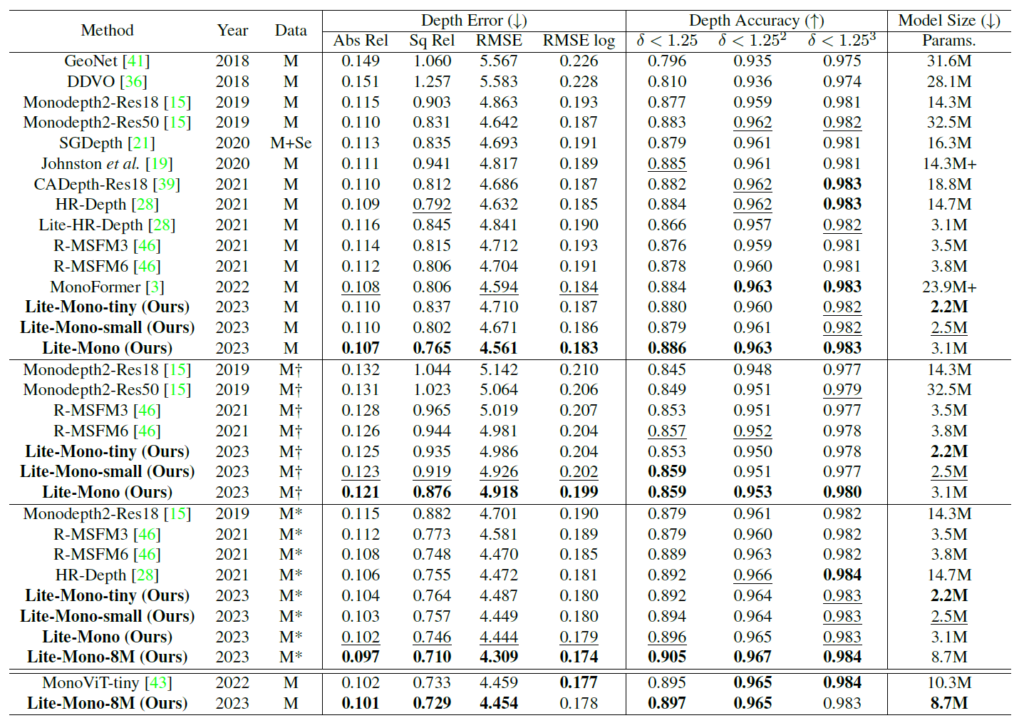
먼저 *은 1024×320의 고해상도 영상을 M은 SDE task의 default setting이라고 볼 수 있는 640×192 해상도를 입력으로 사용한 것을 의미합니다. 그리고 저 십자가 표기는 imagenet pretrained가 없는 버전으로 이해하시면 됩니다.
제안하는 방법론의 모델 종류는 Lite-Mono tiny, small, -, 8M 이렇게 4가지로 tiny의 경우 전체 모델 파라미터 수가 2.2M이며 제일 큰 모델 조차도 8.7M 밖에 안됨을 볼 수 있습니다.
이렇게 작은 사이즈임에도 불구하고 Lite-Mono-8M의 경우 abs_rel 성능이 0.101으로 상당히 높은 것을 볼 수 있습니다. 예전에 제가 SDE 분야에 대해서 논문 쓸 때 그 당시 SOTA 였던 DDV방법론의 Abs_rel 0.106을 넘기 위해서 별의별 실험을 다 하고 했었는데.. 이렇게 작은 모델로 0.101을 훅 달성하는 모습이 정말 기술의 속도가 빠르네요.
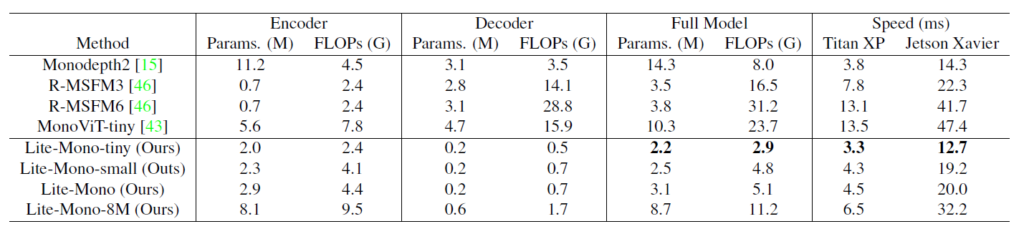
다음은 Model의 복잡도와 속도에 관한 평가인데, Monodepth2와 비교해서 파라미터 수가 6배이상 작은 것을 볼 수 있습니다. 또한 속도 역시 Titan XP와 젯슨 자비에에서 각각 3.3ms, 12.7ms로 매우 빠른 속도 임을 확인할 수 있구요(tiny 기준)
22년도 방법론인 MonoVit-Tiny와 비교하더라도 Lite-Mono-8M의 경우 전체 파라미터의 크기가 더 작으면서(8.7 vs 10.3) 속도 역시 2배 이상 차이나는 것을 볼 수 있습니다.(Titan XP 기준)
다만 한가지 거슬리는 점은 배치를 1이 아닌 16으로 잡고 속도를 측정했다는 점입니다. 실제 추론 관점에서는 사실 배치를 16으로 놓는 것이 아니라 배치1의 sequence한 데이터로 들어올텐데 왜 16으로 잡고 평가를 하였는가.. 라는 의문이 들어서 코드가 공개된 깃허브를 이곳저곳 찾고 있었는데, 마침 속도 관련 이슈가 있더군요.
몇몇 이슈를 확인해보니 batch size가 1인 경우에는 논문에서 말하는 속도보다 더 느리게 나온다고 하는 것 같습니다. 저자 역시도 속도가 논문대로 안나온다는 이슈에 대해 batch size를 1이 아닌 더 크게 해보라는 말을 하는 것으로 보아 무언가 꺼림칙한 단점이 있는 것 같습니다.
물론 batch 1로 하였을 때도 빠르게 동작하긴 하지만 이슈 상으로는 batch 1의 경우 monodepth2 보다 더 느린 속도를 보인다고 하네요. (근데 정확히 어떤 모델 기준인지 이슈를 등록한 사람이 말해주지 않아서 부정확함.)
Ablation Study

다음은 ablation study에 대한 결과 표입니다. 계단 형식이 아닌 각각의 contribution을 하나씩 넣다 뺏다 하는 방식의 ablation table이네용.
보시다시피 LGFI block과 dilated convolution 등을 제거하게 되면 성능적인 측면에서 매우 크게 감소하는 것을 볼 수 있습니다. 이는 SDE task에서 global receptived field의 중요성을 볼 수 있는 대목 중 하나입니다.
또한 RGB 영상을 pooling하여 concatenation하는 것 역시 성능에 어느정도 영향을 끼치는 것을 볼 수 있습니다. 이것 역시 부족한 spatial information을 보충해준다고 합니다.
그 다음에 각 stage의 입력으로 이전 stage의 input을 넣는 cross-stage connection 역시 모든 메트릭에서 마이너한 성능 향상을 일으키는 것을 확인할 수 있습니다.
결론
foundation model을 개발하기 힘드니 이런 경량화 쪽으로 연구하는 것도 나쁘지 않겠다 라는 생각이 들면서도 성능 유지를 참 잘시켰다는 생각이 드는, 단순하면서 좋은 논문이라고 생각이 드네요.
좋은 리뷰 감사합니다.
local 정보 및 연산속도를 위한 CNN모듈과 global 정보를 위한 Transformer 모듈을 함께 사용하여 local 정보와 global 정보를 모두 고려할 수 있는 stage로 만들어 SDE task를 수행한 것으로 이해하였습니다.
stage는 N개의 CDC로 구성되는데 각 stage마다 N은 동일하게 설정하는 것인지 궁금합니다.
또한 global 정보와 local 정보를 개별적으로 처리하지 않고 번갈아가며 처리하는 것에 장점이 있는것인지 궁금합니다.
각 스테이지 별로 몇개의 모듈이 구성되어 있는지는 리뷰 글 내 Experiments 섹션 바로 위 테이블을 참고 부탁드립니다.
그리고 global 정보를 처리하는 Transformer 기반 모듈을 번갈아가면서 넣지 않은 이유에 대해서는 연산량적인 측면을 고려했기 때문입니다. 연산량이 너무 많이 드니 마지막에 한번만 연산하는 것이죠.