안녕하세요. 백지오입니다.
열세 번째 X-REVIEW는 지난 리뷰에 이은 CLIP 리뷰 파트 2입니다. 지난 파트 1 리뷰에서 CLIP의 개념과 방법론을 알아보았는데, 이번 리뷰에서는 저자들이 수행한 실험과 분석들, CLIP의 한계점들을 리뷰해보겠습니다.
논문에는 이외에도 인간과 CLIP의 차이점, 인터넷에서 수집된 CLIP 학습 데이터와 평가 데이터셋의 overlap 분석, 데이터의 social bias를 포함한 Broader Impact 분석과 같은 심도깊은 내용들이 있으니, 관심이 있으신 분들은 한번 읽어보시면 좋을 것 같습니다.
그럼, 리뷰 시작하겠습니다.
Experiments
Zero-Shot Transfer
Motivation
기존에 컴퓨터 비전에서 zero-shot learning이라 하면, 개와 고양이를 분류하도록 학습한 모델이 새를 분류하도록 하는 것과 같이 unseen class에 대한 분류를 수행하는 것을 의미했다고 합니다. 저자들은 이러한 zero-shot의 개념을 unseen task에 대한 수행으로 확장합니다. 기존의 연구들이 머신러닝 기법의 representation learning 능력에 집중하였다면, unseen task에 대한 zero-shot은 task learning 능력과 관련이 있습니다.
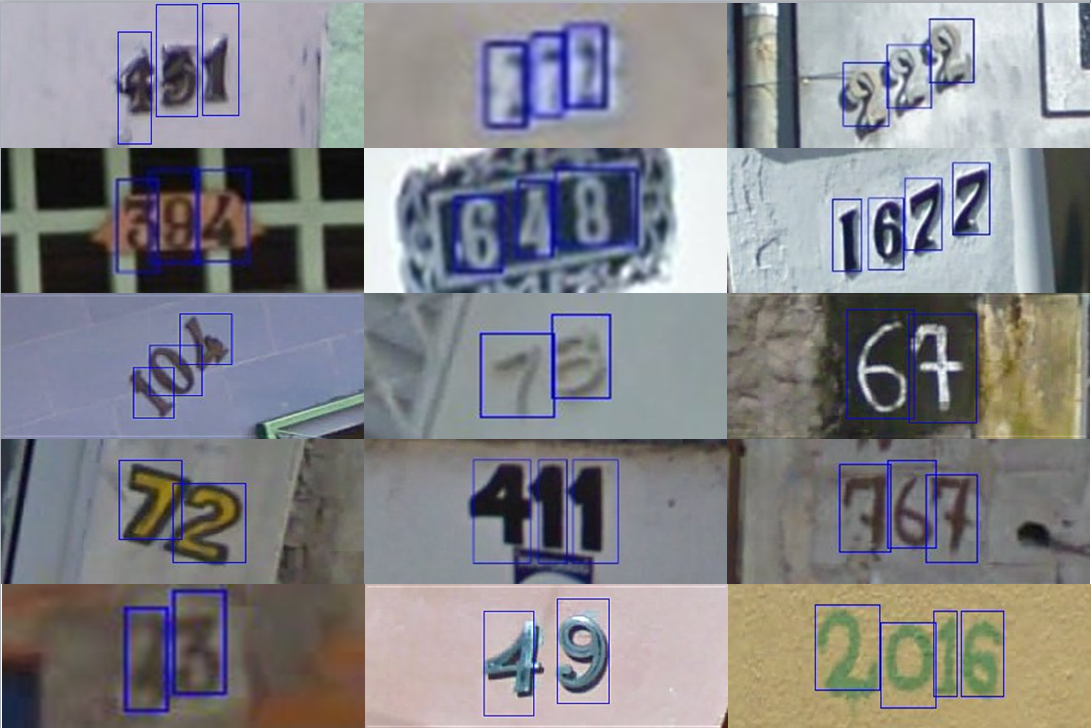
평가에 사용되는 각 데이터셋은 task와 분포 관점에서 살펴볼 수 있는데요. 예를 들어, SVHN 데이터셋은 street number transcription task와 관련이 있으며, Google Street View 분포에 속합니다. 한편, CIFAR와 같이 데이터셋이 속한 분포는 알 수 있으나, task가 명확하지 않은 데이터셋도 있는데요. 이러한 데이터셋은 모델의 task learning 성능보다는 distribution shift에 대한 robustness나 domain generalization 성능을 측정하는데 적합합니다.
zero-shot transfer를 통해 task learning 능력을 평가하는 방법은 NLP의 task learning에서 영감을 받았다고 합니다. Liu et al. (2018)은 Wikipedia 문서를 생성하도록 학습한 모델이 언어 간 이름 변환(transliterate name)을 잘 수행하는 예상치 못한 효과가 있음을 발견하였고, GPT-1은 사전 학습 과정에서 모델이 supervision 없이도 네 가지 heuristic zero-shot transfer method들의 성능이 상승함을 보였습니다. 이를 바탕으로 GPT-2는 zero-shot transfer를 통하여 언어 모델의 task-learning 능력을 보였습니다. 최근 chatGPT로 유명한 GPT-3.5는 question answering, translation 등 다양한 task에 사용할 수 있어 task learning이 뛰어남을 알 수 있죠.
기존의 이미지 분류 데이터셋에서 위에서 설명한 것과 같은 zero-shot transfer를 수행한 첫 실험인 Visua N-Grams (Li et al., 2017)는 142,806 개의 visual n-gram들의 사전을 학습하여 Jelinek-Mercer smoothing을 통해 주어진 이미지에 대한 text n-grams와의 확률을 최대화하도록 학습하였다고 합니다. 다시 말해, 데이터셋의 각 클래스 이름 text들을 n-gram representation으로 변환한 후, 입력된 visual n-gram과 가장 높은 확률을 갖는 text n-gram을 취하여 분류를 수행한 것이죠.
Using CLIP for zero-shot transfer
CLIP은 이미지와 텍스트 쌍의 임베딩이 같은 쌍에 속하는지 예측하도록 사전학습됩니다. 이를 이용한 zero-shot transfer를 수행하기 위해, 각 데이터셋의 각 클래스 이름을 잠재적인 text pairing으로 사용하여 CLIP을 통해 가장 유망한 (이미지, 텍스트) 쌍을 예측합니다. 먼저, 모든 이미지들과 가능한 텍스트(각 클래스의 이름)들을 인코더를 통해 인코딩한 후, 각 임베딩들의 코사인 유사도를 계산하여 temperature parameter $\tau$로 조정하고, softmax 함수를 통해 유사도를 normalize 하여 각 이미지와 가장 유사도가 높은 텍스트(클래스 이름)의 쌍을 얻게 됩니다. 이 과정은 L2-normalized 된 입력과 L2-normalized weight를 갖는 multinomial logistic regression과 같습니다. 이때 이미지 인코더는 이미지의 feature representation을 뽑아낼 컴퓨터 비전 백본이며, 텍스트 인코더는 hypernetwork로 linear classifier의 가중치를 생성합니다.
Initial Comparison to Visual N-Grams
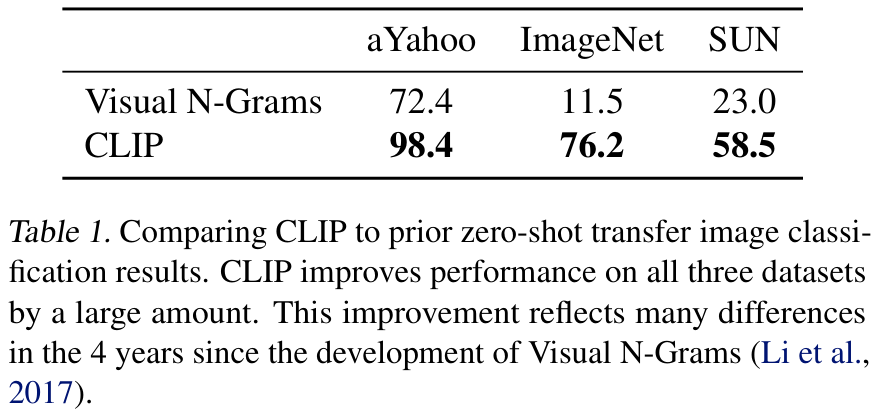
Visual N-Grams와 CLIP의 비교를 수행한 결과, CLIP 모델은 ImageNet의 데이터를 전혀 사용하지 않고도 Visual N-Grams 대비 정확도를 11.5% 향상하여 76.2%를 달성하였는데, 이는 ImageNet에서 학습된 ResNet-50의 성능에 해당한다고 합니다. 또한, CLIP의 top-5 accuracy는 95%로, ResNet-50의 top-1 accuracy보다 높으며 Inception-V4 모델에 상응한다고 하네요. 이렇듯 CLIP은 zero-shot으로도 지도학습 기반의 강력한 방법론들에 준하는 성능을 낼 수 있는 실용적이고 유연한 zero-shot computer vision classifier라고 합니다.
다만, 위 표의 성능 비교는 CLIP의 강력한 성능을 소개하기 위한 것일 뿐, 학습 데이터의 수(CLIP이 10배 많은 데이터에서 학습)나 연산량(CLIP이 추론 시 100배, 학습 시 1000배 더 사용) 측면에서 fair 한 비교는 아니기 때문에 두 모델의 직접적인 성능 차이를 나타내지는 않는다고 합니다. 대신, 조금 더 나은 비교를 위해 저자들은 CLIP ResNet-50을 Visual N-Grams가 학습한 YFCC100M 데이터셋에서 학습시켜 Visual N-Grams 논문에서 당시 논문에서 소개한 ImageNet 성능과 유사한 성능을 내도록 baseline을 설정하였다고 합니다.
저자들은 이외에도 Visual N-Grams에서 사용한 세 가지 데이터셋을 포함해 30개의 데이터셋에서 50개의 기존 컴퓨터 비전 방법론들과의 비교를 통해 CLIP의 효과적인 zero-shot 성능을 보였습니다. (정당한 비교가 불가하기 때문인지, 성능을 증명했다던지 하는 것이 아닌, contextualize라는 유한 표현을 사용하였네요.)
Prompt Engineering and Ensembling
CLIP을 통해 zero-shot transfer를 수행하기 위해서는 데이터셋에 포함된 자연어 형태의 클래스 이름을 사용해야 하는데, 이 과정에서 예상치 못한 문제가 발생하였다고 합니다. 많은 데이터셋에서 클래스를 자연어가 아닌 정수 id로 나타내고 있었고, 자연어를 사용하는 경우에도 동음이의어와 같은 문제로 zero-shot 적용이 어려운 경우가 있었다고 합니다. 예를 들어, ImageNet에서는 construction crane (건설용 크레인)과 crane (두루미)이라는 클래스가 존재하며, Oxford-IIIT Pet dataset에는 boxer (개의 종류, 복서 종)가 존재하는데, 맥락 정보의 부족으로 인해 모델이 이 단어들이 어떤 것을 나타내는지 판단하기 어려웠다고 합니다.
또한, CLIP을 학습할 때 사용된 텍스트들은 대부분 하나의 단어가 아닌 완전한 문장이었는데, 데이터셋에 포함된 라벨은 단어이기에 이로부터 발생하는 domain gap이 있었다고 합니다. 저자들은 이 문제를 “A photo of a {label}”이라는 템플릿으로 라벨을 변경하는 방식으로 해결했다고 합니다. 이 템플릿을 사용하는 것만으로 ImageNet에서의 정확도가 1.3% 상승하였다고 합니다.
이러한 프롬프트 엔지니어링을 통해, 저자들은 앞서 언급한 문제들을 해결하거나 성능을 향상할 수 있었다고 하는데요. 예를 들어, 앞서 언급한 Oxford-IIIT Pets 데이터셋의 경우, 모델이 각 라벨이 어떤 반려동물들과 관련되었다는 맥락을 알 수 있도록 “A photo of a {label}, a type of pet”과 같이 템플릿을 부여하였습니다. 이와 유사하게 Food101 데이터셋에는 “a type of food”, FGVC Aircraft 데이터셋에는 “a type of aircraft”와 같은 템플릿을 부여하는 것이 도움이 되었다고 합니다. 한편, 위성사진 데이터셋에서는 “a satellite photo of a {label}”과 같이 템플릿을 수정하니 도움이 되었다고 하네요.
한편 “A photo of a big {label}”, “A photo of a small {label}”과 같이 서로 다른 프롬프트를 사용하여 text embedding을 생성한 후, 이 임베딩들을 앙상블 하여 사용하니 성능이 향상되었다고 합니다. 어차피 label에 대한 embedding은 한 번만 수행하면 되기 때문에, 이렇게 여러 방식으로 임베딩을 생성하여 평균 임베딩을 생성하는 과정이 예측 시 추가적인 연산량의 증가로 이어지지는 않았다고 합니다. 이렇게 다양한 임베딩을 생성하여 앙상블을 하는 것은 대부분의 데이터셋에서 성능을 향상했다고 하며, ImageNet에서는 80개의 각기 다른 프롬프트를 앙상블 한 결과 3.5%의 성능 향상을 얻을 수 있었다고 합니다. 결과적으로, ImageNet 데이터셋에서 프롬프트 엔지니어링과 프롬프트 앙상블을 통해 무려 5%에 가까운 성능 향상을 얻을 수 있었다고 하네요.
Analysis of zero-shot CLIP performance
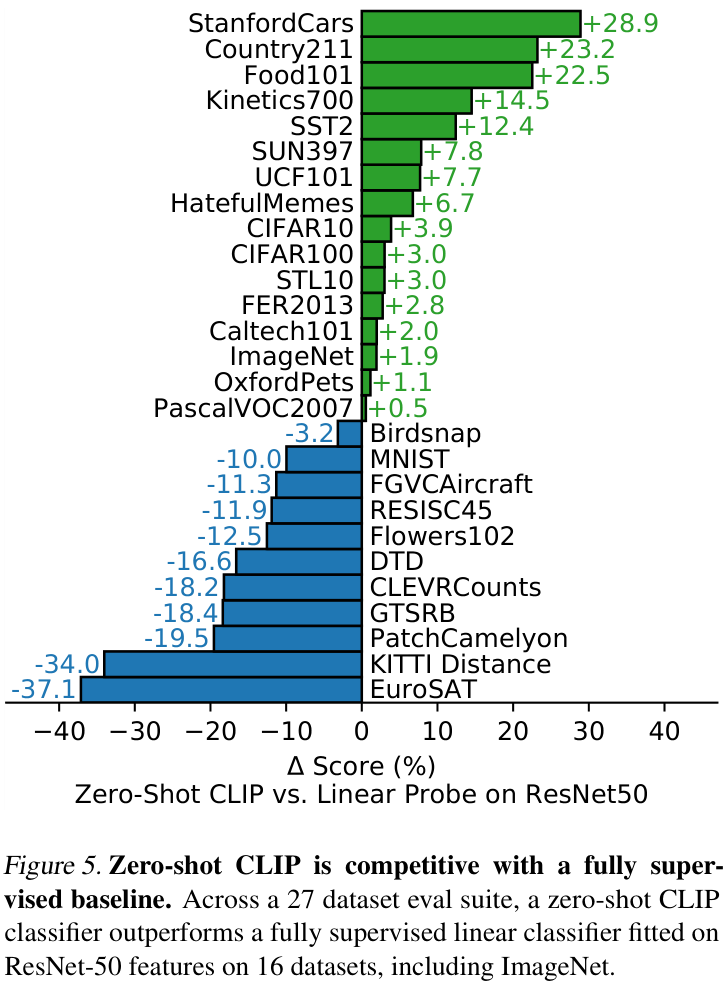
저자들은 CLIP을 통해 task-agnostic zero-shot classifier의 가능성을 보이고자 합니다. 먼저, 단순히 zero-shot classifier가 잘 작동하는지 확인하고, 이를 정당화(contextualize) 하기 위해 fully supervised, regularized, logistic regression classifier on the features of the canonical ResNet-50을 베이스라인 삼아 비교를 수행합니다. 위 그림에서 27개 데이터셋에서의 비교를 확인할 수 있습니다.
27개의 데이터셋 중 16개의 데이터셋에서 CLIP이 베이스라인 성능을 앞서고 있으며, 각 데이터셋을 살펴보면, fine-grained classification task들에서의 성능 차이가 큰 것을 볼 수 있었다고 합니다. Stanford Cars나 Food101 데이터셋의 경우, zero-shot CLIP이 ResNet-50 베이스라인을 20% 이상 앞지른 반면, Flowers102와 FGVCAircraft 데이터셋에서는 오히려 10% 뒤쳐진 것을 확인할 수 있습니다. 저자들은 이러한 차이가 WIT와 ImageNet에서의 per-task supervision의 양의 차이, 즉 사전학습 데이터의 분포 차이로부터 오는 것으로 의심하였습니다. 한편, ImageNet, CIFAR10/100, STL10과 PascalVOC2007와 같이 일반적인 객체 분류 데이터셋에서는 zero-shot CLIP이 베이스라인과 비슷하거나 약간 앞선 성능을 보였습니다.
한편, Kinetics700, UCF101과 같은 video action recognition 데이터셋에서는 CLIP이 베이스라인을 크게 앞섰는데, 이는 CLIP이 자연어를 통한 supervision 과정에서 동사의 시각적 특성을 학습한 반면, ImageNet에서 학습된 베이스라인은 명사 중심의 특성을 학습하였기 때문이라 보았습니다. 또한, zero-shot CLIP이 일부 specialized, complex, 혹은 abstract 한 task들에서 꽤나 약한 모습을 보이는 것을 알 수 있는데요. 예를 들어 위성사진 (EuroSAT, RESISC45)이나 림프절 종양 탐지 (PatchCamelyon), 합성 화면에서 object counting (CLEVRCounts), 자율 주행 관련 task (GTSRB), nearest car 사이의 거리 탐지 (KITTI Distance)와 같은 task들에서 CLIP은 좋지 못한 성능을 보였습니다. 이는 비전문가 인간이 이런 문제들을 쉽게 풀 수 있는 것과 대조적입니다. 그러나, 저자들은 이러한 비교가 적절한지, few-shot에서 평가하는 것이 더 적절하지 않은 지에 대한 의문이 있다고 합니다.
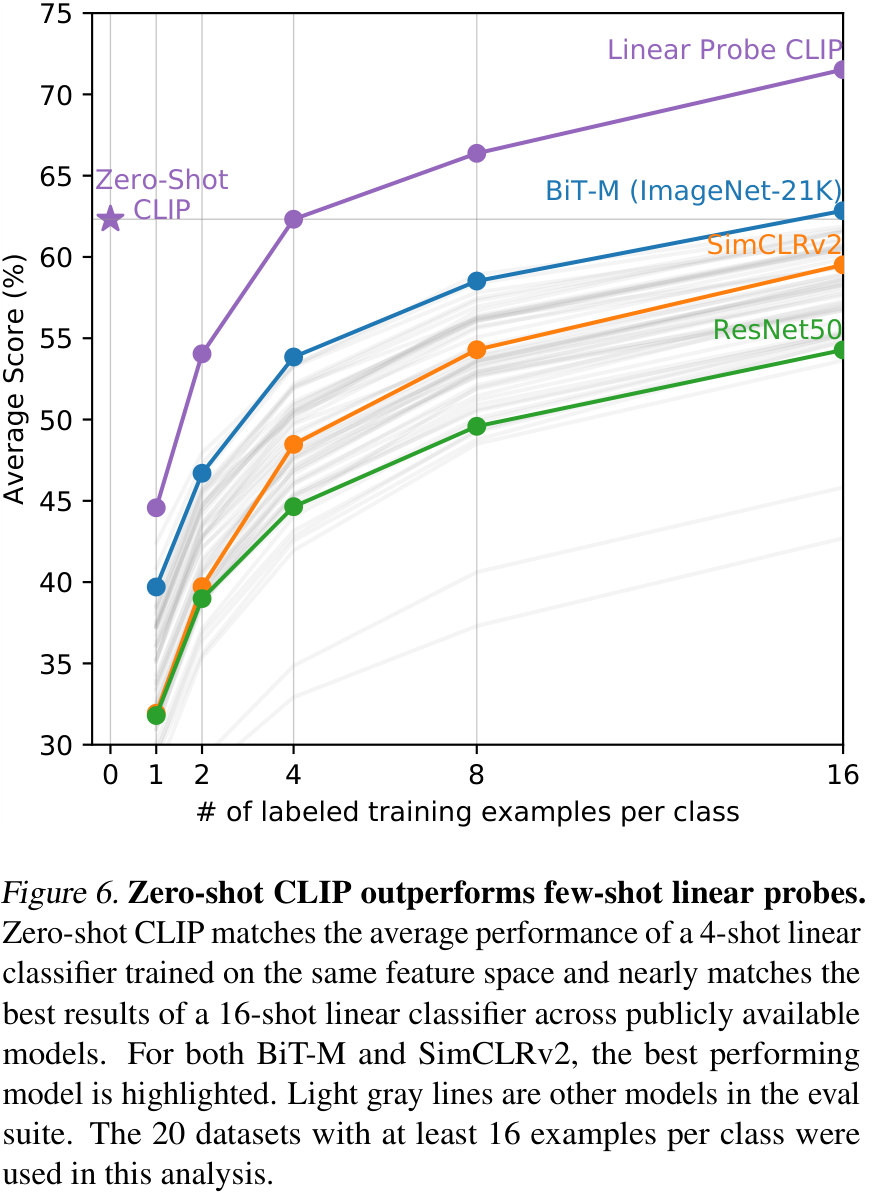
zero-shot CLIP과 fully supervised model의 성능 비교는 CLIP의 task-learning 능력을 보여주는 반면, few-shot CLIP과의 비교는 한층 더 직접적인 비교로 볼 수 있습니다. 위 그림은 zero-shot CLIP의 성능과, 다양한 사전학습 모델로 추출한 feature에서의 few-shot logistic regression 성능을 비교한 결과입니다. zero-shot CLIP이 BiT-M이나 SimCLRv2와 같은 다른 사전학습 방법들이 16 shot 이상 학습한 후에야 달성할 수 있는 성능을 먼저 달성하고 있는 모습을 볼 수 있습니다.
한편, CLIP feature에서는 4 shot의 학습을 진행한 후에야 zero-shot CLIP과 동등한 성능을 얻을 수 있었는데, 이는 zero-shot CLIP이 자연어로 예측을 수행하는 반면, few-shot CLIP은 일반적인 supervised 모델들과 유사하게 뒤쪽의 classification layer를 학습하여 예측을 수행하기 때문에, 추가된 layer의 학습이 요구되기 때문입니다.
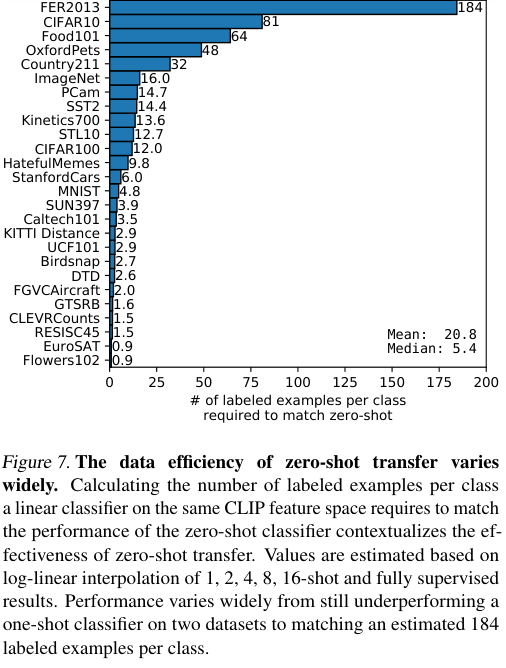
위 그림에서는 각 데이터셋 별로 zero-shot CLIP의 성능을 따라잡기 위해 CLIP feature에서의 linear classifier를 학습시키는데 요구되는 클래스별 샘플의 수 (shot)의 추산치를 나타내었습니다. 결국 두 모델이 같은 feature에서 예측을 수행하기 때문에, 이는 zero-shot transfer의 데이터 효율성을 나타낸다고도 볼 수 있습니다.
few-shot 모델이 zero-shot을 따라잡기 위해, 1 shot에서 최대 184 shot까지 학습해야 하는 만큼, zero-shot이 꽤나 데이터 효율적임을 알 수 있습니다.
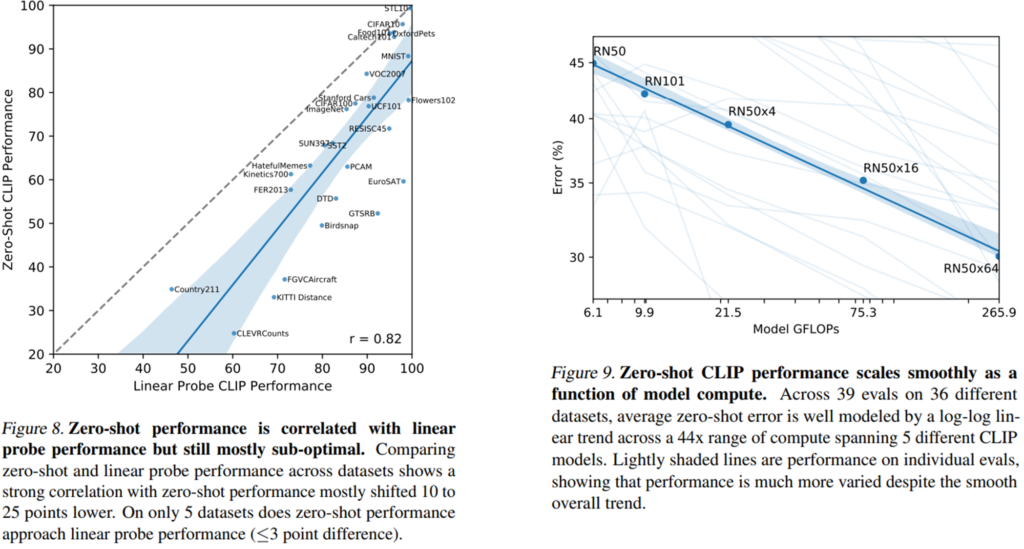
이외에도 저자들은 zero-shot CLIP 성능과 CLIP feature에서의 linear probe의 성능 사이의 상관 관계와 모델 크기에 따른 성능의 차이를 분석하였는데요. zero-shot CLIP의 성능이 높은 경우 일반적으로 few-shot 성능 역시 높았으며, 모델의 크기가 커짐에 따라 전체적인 성능이 증가하는 경향을 보였습니다.
Representation Learning
이어서 저자들은 CLIP의 representation learning 능력을 분석하였습니다. represenation learning 분석에는 흔히 사전학습된 모델을 freeze 시킨 후 추가된 linear layer만을 학습시키는 linear probe 방법과, 모델 전체를 파인튜닝하는 방법이 사용됩니다. 저자들은 모델 전체를 파인튜닝할 경우 CLIP의 representation이 갖는 높은 일반화 성능과 강건성과 같은 장점이 사라질 수도 있으며, 수많은 모델과의 비교 실험을 진행할 때, 모델 전체를 fine-tuning하게 되면 탐색해야할 하이퍼 파라미터가 너무 많아진다는 문제가 있어 linear probe 방법을 통해 representation learning 능력을 분석하였다고 합니다.
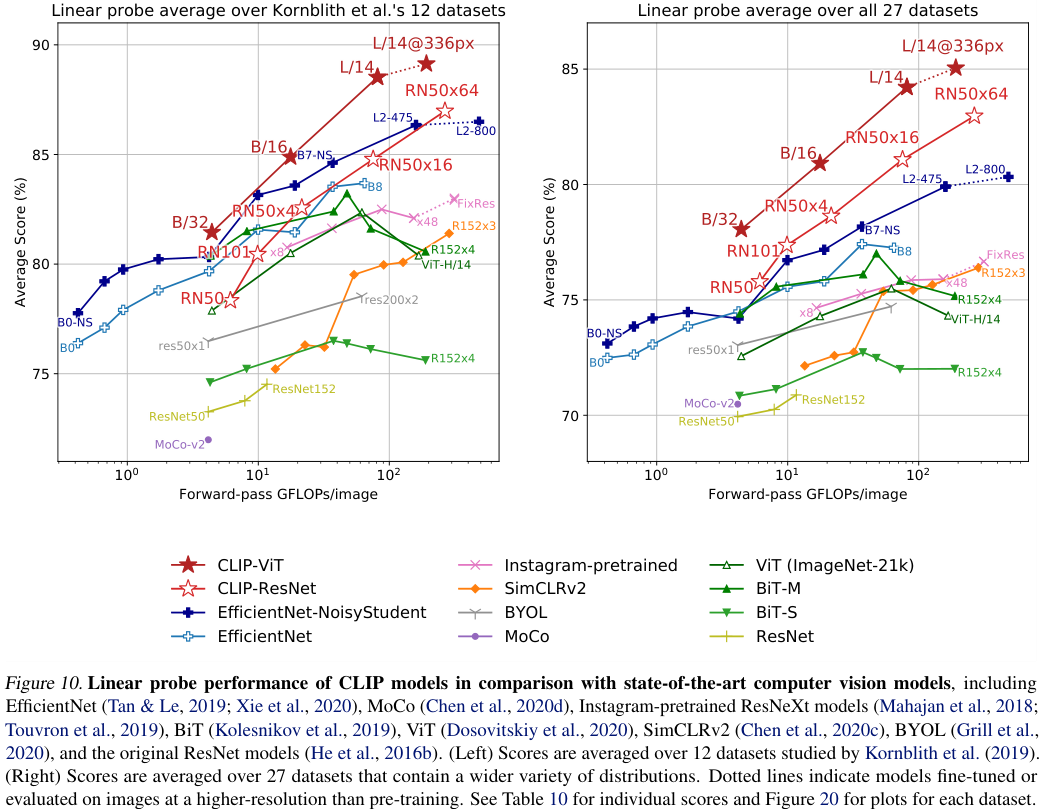
저자들은 여러 가지 데이터셋에서 CLIP의 linear probe 성능과 다른 backbone 모델들의 linear probe를 비교하였는데, 먼저 위 그림의 왼쪽 차트는 Kornblith et al. (2019)(BiT)에서 제안한 12개의 데이터셋에서 평가를 수행한 결과이고, 우측은 저자들이 더욱 다양한 task를 포함하는 27개 데이터셋에서 평가를 진행한 결과입니다.
먼저 좌측 그림을 보시면, ResNet-50이나 ResNet-101 기반의 작은 백본을 가진 CLIP들은 ImageNet-1K에서 사전학습된 모델들(BiT-S 등)보다는 높은 성능을 보였지만, ImageNet-21K에서 학습된 BiT-M과 같은 모델들이나 EfficientNet 계열 모델들보다는 낮은 성능을 보였습니다. 한편, ResNet-50×64와 같이 큰 backbone을 가진 CLIP 모델은 기존의 모델들 대비 정확도와 컴퓨팅 효율이 앞서는 모습을 보여주어, scale이 잘 됨을 확인할 수 있었다고 합니다. 또한, ViT 기반의 CLIP 모델들이 ResNet 기반의 CLIP 모델보다 약 3배 좋은 컴퓨팅 효율을 가졌다고 하네요.
위 그림과 앞선 그림의 우측 차트에서 볼 수 있듯이 저자들은 CLIP을 한층 더 다양한 task들에서 테스트 하였는데, 이때 CLIP 모델들은 스케일과 무관하게 기존의 모델들 대비 컴퓨팅 효율이 좋았다고 합니다. 또한, BiT에서 제안한 12개 데이터셋에서의 평가 방법보다 저자들이 제안한 더 다양한 task를 포함한 새로운 평가 방법에서는 SimCLR 등 self-supervised 방법들이 특히 좋은 성능을 보이는 것을 알 수 있었는데요. 앞선 평가 방식에서는 SimCLRv2가 BiT-M보다 부족한 성능을 보이지만, 새로운 평가 방법에서는 SimCLRv2가 더 좋은 모습을 보여줬다고 합니다. 저자들은 이러한 차이가 평가 방법의 task diversity와 coverage가 확장됨에 따라, 모델의 일반화 성능이 중요하게 작용하게 되었기 때문이라고 합니다.
CLIP은 OCR을 요구하는 task(SST2, HatefulMemes)에서 대체로 성능을 향상시켰으며, geo-localization이나 scene recognition (Country211, SUN397) 그리고 영상에서의 action recognition (Kinetics700, UCF101)에서 성능 향상을 보였다고 합니다. 또한, fine-grained car and traffic sign recognition (Stanford Cars and GTSRB)에서 큰 성능 향상을 보였는데, 이는 ImageNet에서의 overly narrow supervision에 비하여 CLIP이 좋기 때문인 것으로 추정된다고 합니다. ImageNet에서의 supervision pre-training이 intra-class detail을 경시하도록 만들어 정확도가 상대적으로 낮아진 것이 아닌가 추정하고 있네요.
또한 앞서 언급한 것처럼, 몇 가지 데이터셋에서 CLIP은 여전히 EfficientNet 대비 낮은 성능을 보이는데요, 주로 EfficientNet이 학습된 ImageNet이나 CIFAR와 같은 저해상도 이미지에서 그런 경향이 있다고 합니다. 저자들은 이것이 CLIP이 scale-based data augmentation이 부족하여 그런 것이라 의심한다고 하네요. 또한 CLIP은 PatchCamelyon과 CLEVRCounts에서 부족한 모습을 보이는데, 이들 데이터셋은 EfficientNet에서도 성능이 별로 높지 않은 데이터셋이라 합니다.
Robustness to Natural Distribution Shift
저자들은 많은 컴퓨터 비전 모델들이 ImageNet에서는 사람보다 높은 정확도를 보이면서, 다른 데이터셋에서는 훨씬 낮은 성능을 보이는 예를 들며, 딥러닝 모델이 학습 데이터의 in-distribution 패턴은 아주 잘 찾는 반면, out-of-distribution에는 취약한 한계를 지적합니다. 모델들이 이렇게 in-distribution에 편향되는 것이 꼭 나쁘다고만은 할 수 없지만 out-of-distribution도 분명히 고려해야할 요소이며, CLIP은 이러한 문제에 대해 어떤 성능을 보이는지 분석하였습니다.
앞서 이미 이런 연구를 수행한 이들이 꽤 있었다고 하는데요. 그들은 주로 ImageNet에서 학습된 모델들을 ImageNet과 유사하지만 다른 분포로 구성된 ImageNetV2, ImageNet Sketch, ImageNet-Vid 등의 데이터셋과 ImageNet을 변형한 합성 데이터셋인 ImageNet-C, Stylized ImageNet 등에서 테스트하여 Distribution Shift에 대한 성능을 측정하였다고 합니다. 이때, 모델들의 ImageNet 성능(in-distribution)과 out-of-distribution 성능 간에 어떠한 상관관계가 존재하였고, 모델의 robustness을 측정하기 위하여 이를 기반으로 두 가지 성능 지표가 제안 되었는데요. 먼저 Effective robustness는 모델의 정확도 상승 폭과 distribution shift에 의한 성능 변동을 모두 고려하는 지표이며, Relative robustness는 단순히 out-of-distribution 성능의 향상만을 고려한다고 합니다. 이 두 가지를 모두 고려하여야 robust한 모델을 만들 수 있다고 하네요.

앞서 연구된 robustness 관련 방법들은 대부분 ImageNet에서 사전학습 혹은 파인튜닝 되었습니다. 한편, zero-shot CLIP은 ImageNet의 분포를 전혀 본 적이 없기 때문에, 다른 모델들에 비하여 훨씬 높은 effective robustness를 가질 것이라는 예측이 가능한데요. 실제로 위 그림을 보면, CLIP이 기존 모델들 대비 훨씬 robust한 성능을 보이는 것을 알 수 있습니다.
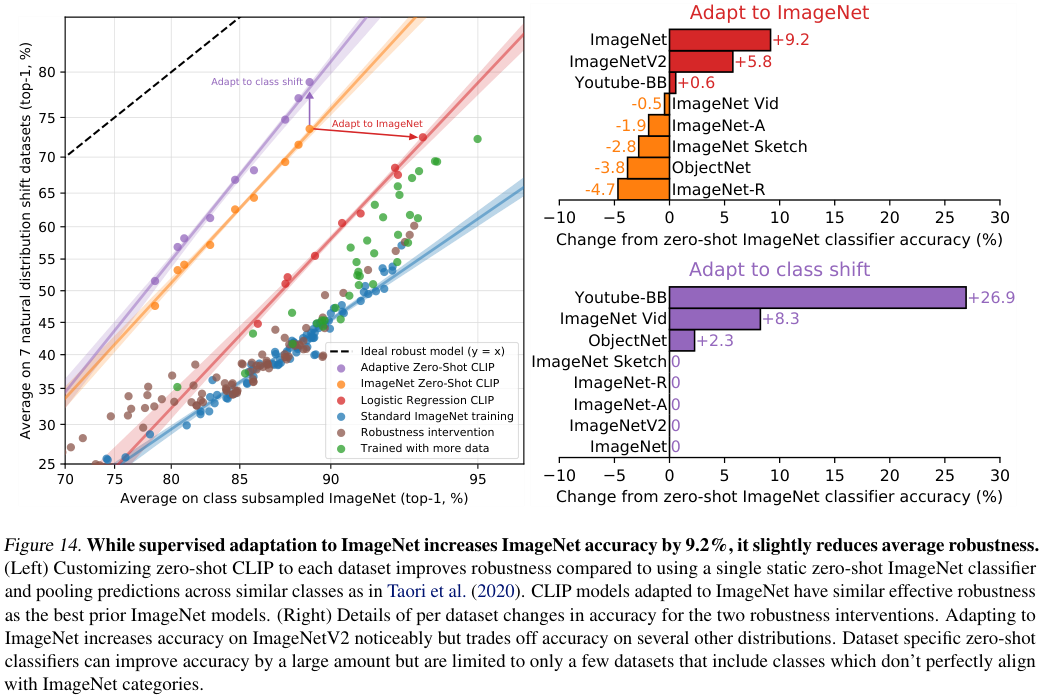
그러나 이것이 꼭 ImageNet에서의 학습과 직접적인 관계가 있는 것은 아닙니다. CLIP은 ImageNet과 다른 분포에서 학습되었다는 것 이외에도, 대규모 사전학습 데이터셋이나 자연어 supervision과 같이 다른 모델들과는 많은 차이가 있기 때문입니다. 한편, 저자들은 CLIP에 logistic regressor를 더하고 ImageNet에 학습시킨 성능을 측정하기도 하였는데요. ImageNet에서의 성능이 85.4%로 증가하기는 하였으나, 이는 ImageNet에서의 2018년 SOTA 성능에 불과하며, distribution shift가 발생했을 때의 성능은 오히려 약간 감소하였다고 합니다. 위 그림을 보면 supervision을 진행하였을 때(붉은색) CLIP의 robust한 이점이 거의 사라지는 것을 볼 수 있습니다.

CLIP에서 few-shot learning을 수행할 경우, 기존의 ImageNet에서 사전학습된 모델들 보다는 강건한 모습을 보이지만 결국 zero-shot CLIP에서 보였던 높은 강건성은 보장되지 않았습니다. 특정 데이터셋에서의 파인튜닝은 해당 데이터셋에서의 성능은 약간 향상시킬 수 있을지언정, 모델의 강건성에는 좋지 않은 결과를 초래한다는 것이죠.
Limitations
앞선 분석들에서도 언급된 것처럼, CLIP에는 많은 한계가 존재한다고 합니다.
먼저, 많은 데이터셋에서 CLIP의 zero-shot 성능이 fully supervised된 ResNet-50 기반 베이스라인과 유사하거나 부족한 모습을 보인다고 합니다. (zero-shot이니까 이 정도만 해도 대단한거라고 생각되긴 합니다만..) 이는 SOTA 모델들 보다는 훨씬 낮은 성능이기 때문에, CLIP의 성능이 아직 많이 부족하다고 하는데요. CLIP의 scale을 키움에 따라 성능도 증가하는 경향이 있어 결국은 SOTA 모델 급의 성능도 달성 가능하겠지만, 이 경우 기존 모델 대비 약 1000 배의 연산이 요구될 정도로 모델을 키워야 하기 때문에, 사실상 달성이 불가능하며, CLIP의 zero-shot 성능을 개선하기 위해 task learning, transfer를 더 개선할 여지가 있다고 합니다.
또한, 앞서 zero-shot 성능 실험에서 본 것처럼, 몇몇 task에서 CLIP은 상당히 약한 성능을 보여줍니다. 서로 다른 종류의 차량, 꽃, 비행기 등을 분류하는 fine-grained classification에서 이러한 경향이 두드러진다고 하며, 이미지에 등장하는 객체의 숫자 세기와 같은 추상적이고 systematic한 문제를 푸는 것에서도 전문가 모델들보다 낮은 성능을 보인다고 합니다. 또한, CLIP의 학습 데이터셋에 포함되지 않은 완전히 새로운 데이터를 다루는, 예를 들어 차량 간의 거리를 구하거나 하는 등의 문제에서는 CLIP의 성능이 거의 랜덤에 가깝다고 하는데 저자들은 이러한 점으로 보아, CLIP이 제 구실을 못하는 task가 아주아주 많을 거라고 장담하고 있습니다.
저자들은 CLIP이 기존 모델들보다는 일반화 성능이 좋지만 여전히 완전히 out-of-distribution인 이미지들에 대해서는 매우 안 좋은 성능을 보인다고 합니다. 예를 들어, CLIP은 디지털로 렌더링된 텍스트, SST2 데이터셋에 대한 OCR은 기가 막히게 잘 수행한다고 합니다. 이는 CLIP의 학습 데이터에 렌더링된 텍스트가 많은 편이기 때문입니다. 그러나, 손으로 쓴 숫자를 다루는 MNIST 데이터셋에서는 고작 88%의 정확도만을 보인다고 합니다. 다들 아시겠지만 단순한 MLP로도 이보다 높은 성능을 달성할 수 있습니다.
CLIP은 다양한 task와 데이터셋에 대한 zero-shot classifier를 만들 수 있지만, 사실 이 또한 클래스별로 주어진 샘플 문장 (“A photo of {label}”)과의 유사도를 구하는 방식으로, 아주 유연하지는 못하다고 합니다. Image Caption Generation과 같이 정말로 유연한 방법들과의 조합을 수행할 수 있는 방법을 고려해봐야 한다고 합니다.
CLIP은 딥러닝 방법들이 갖는 문제인 안 좋은 데이터 효율을 그대로 답습합니다. CLIP의 학습에는 약 128억 장의 이미지가 사용되었는데, 이는 어마어마한 양이기에 self-supervision, self-training과 같이 data-efficiency를 개선할 수 있는 학습 방법을 찾아야 한다고 합니다.
이어서 저자들은 저자들이 사용한 실험 및 학습 방법론에 문제가 있음을 자백하는데요. 저자들이 zero-shot 성능에 집중하며 실험할 때 수천 장의 이미지로 구성된 validation set을 사용하였는데, 이는 매우 부족한 수의 validation set이라고 합니다. 또한, 앞서 여러 실험에서 여러가지 데이터셋에서의 성능을 비교하였는데, 인터넷에서 데이터를 수집하는 과정에서 이들 데이터셋의 evaluation set 일부가 CLIP의 학습 데이터인 WIT에 섞여 들어갔음을 부정할 수가 없다고 합니다. 누군가 zero-shot transfer 성능 측정을 위한 새로운 데이터셋을 만들어 준다면 이러한 문제를 해결할 수 있을 것이라 하는데.. 인터넷에 없는 이미지들만 가지고 데이터셋을 만들어야 한다는 뜻이네요…
또한 방금 언급한 것처럼, CLIP은 인터넷에서 수집된 (이미지, 텍스트) 쌍으로 학습되었는데요. 이 데이터들을 따로 필터링하거나 선별하는 과정이 없었기 때문에, CLIP은 많은 social bias(인종차별, 성차별 등 사회 문제에 대한 데이터 편향)를 품고 있다고 합니다. 이는 논문의 Broader Impacts에서 상세히 다뤄지는데, 리뷰에는 포함하지 않았으니 궁굼하시다면 직접 읽어보시면 좋을 것 같습니다.
저자들은 few-shot 실험에서, CLIP의 feature extractor 뒤에 초기화된 linear layer를 추가하는 식으로 실험을 진행하였습니다. 이에 따라, 1-shot, 2-shot 과 같이 낮은 shot에서의 성능이 이 layer들의 학습에 요구되는 시간으로 인해 오히려 zero-shot보다 낮게 나왔는데요. 이는 인간이 zero-shot과 one-shot 사이에 큰 성능 향상을 이루는 것과 대비된다고 합니다. 때문에, CLIP의 강력한 zero-shot 성능을 살릴 수 있는 효율적인 few-shot 학습 방법이 연구되면 좋을 것 같다고 합니다.
이번 리뷰에서는 CLIP에서 수행한 다양한 실험들과 저자들이 언급한 CLIP의 한계점들을 알아보았습니다.
정리해보면, CLIP은 다음과 같은 특징을 갖습니다.
- 뛰어난 task learning 능력으로 다양한 task에 대한 zero-shot classification을 수행할 수 있습니다.
- 이때, 적절한 프롬프트 엔지니어링과 앙상블을 통해 성능을 향상하고 문제를 해결하였습니다.
- 동사의 시각적 특성을 학습하여 Kinetics나 UCF와 같은 video action 분류에서 높은 성능을 보였습니다.
- Stanford Cars, Food101과 같은 일부 fine-grained classification task에서 높은 성능을 보였습니다.
- 위성사진, 의료사진 등 specialized, complex, 혹은 abstract한 task들에서는 낮은 성능을 보였습니다.
- 사전학습된 모델에서의 Few-shot 성능이 타 사전학습 방법보다 높았습니다.
- zero-shot CLIP의 data-efficiency가 높습니다.
- CLIP 모델은 scalability와 컴퓨팅 효율이 좋으며, representation learning을 잘 수행함을 확인했습니다.
- CLIP은 ImageNet에서 학습된 모델들에 비하여 distribution shift에 상당히 강건합니다.
- 다만 CLIP에서 few-shot을 진행하면 이 장점이 약해지는 편입니다. 그럼에도 여전히 다른 모델들보다는 낫습니다.
또한, 아래와 같은 한계를 갖습니다.
- 일부 fine-grained classification task와 추상적이고 systematic한 문제들에서 전문가 모델보다 못한 성능을 보입니다.
- 완전히 out-of-distribution인 문제에 대해서는 여전히 성능이 안 좋습니다.
- 예측의 수행 방식이 자유롭지 못한 편입니다.
- 데이터 효율이 좋지 않습니다. (학습에 128억 장의 이미지가 필요합니다.)
- 데이터셋에 문제가 있습니다.
- 평가 데이터셋과의 overlap 문제가 있습니다.
- social bias가 있습니다.
- few-shot 학습 방법이 zero-shot CLIP의 잠재력을 충분히 활용하지 못 합니다.
저는 장기적으로 Computer Perception을 달성하기 위한 연구, 단기적으로 context 정보를 잘 포함하는 좋은 representation을 생성하는 연구를 하고자 하며, 구체적으로 video 분야에 CLIP을 도입하여 더 좋은 video feature를 만들어보고자 합니다.
특히 video retrieval, video question answering 같은 경우 영상에서 벌어지는 상황과 같은 contextual 한 정보가 상당히 중요한데, 이를 CLIP이 가진 자연어와 binding된 feature를 통해 어떻게 잘 만들어 볼 수 있지 않을까 싶습니다.
혹시 제 연구 분야나 다른 연구원분들의 연구 분야에 CLIP을 활용할 아이디어가 있으신 분들은 언제든지 토론 환영입니다. ?
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
리뷰 중간 CLIP의 prompt engineering과 관련된 내용에서,
handcrafted prompt를 설계하는 데에 있어 특별히 고려한 점을 밝히고 있는지 궁금합니다.
다른 연구들을 살펴보면 handcrafted prompt가 task 전문가에 의해 신중히 설계된다고 하는데, 어떠한 부분이 이런 이야기를 만들어내게 된 것인지 궁금하여 여쭈어봅니다.
안녕하세요.
논문에서는 prompt 설계의 과정 등에 대하여 자세히 다루고 있지는 않습니다만, 리뷰에서 언급한 것처럼 task마다 조금씩 다른 prompt를 적용하여 클래스에 대한 정보를 더 부여하거나 prompt ensemble을 통해 성믕을 개선한 것과 같은 내용을 다루고 있습니다.
아마 모델 자체가 특정 task에 specific한 모델이 아니고 테스트한 데이터셋이 많다 보니 각 task 별로 완전히 특화된 prompt를 설계하기 보다 general한 “a photo of (label)”과 같은 적은 양의 prompt engineering을 통하여 비교를 수행한 것으로 생각됩니다.
감사합니다