안녕하세요, 허재연입니다. 요즘 Self-supervised learning을 활용해 pretrain한 이후 finetuning하는 과정에서 어떻게 하면 성능을 올릴 수 있을까 고민하고 있는데, 고민 도중 찾아본 논문을 소개하고자 합니다. 보통 self-supervised learning으로 pretrain하는 과정에서 어떻게 성능을 향상시킬지 집중하는데, 이 논문은 반대로 fine-tuning 과정에 집중하고 있습니다. 기존의 fine-tuning 방법들은 대규모 DB에서 supervision으로 학습된 모델을 transfer하는데 초점에 맞추어져 있었기 때문에 contrastive loss를 이용해 사전학습을 하였다면 또 이에 맞는 fine-tuning방법을 적용하는것이 맞지 않겠냐고 주장하며 본인들이 제안하는 contrastive loss를 이용한 fine-tuning방법을 새로운 baseline으로 삼기를 추천하고 있습니다. 한 번 살펴보겠습니다.
Abstract
Contrastive self-supervised learning (CSL) 방법론들이 도입되며 unlabeled data를 통한 모델 pre-training에 대한 관심이 커지고 있습니다. CSL 모델은 feature space에 균일하게 분포된 instance-discriminative visual features를 제공합니다. 이를 downstream task에 적용시킬 때 일반적으로 CSL 모델을 cross-entropy를 사용하여 직접 fine-tuning하는데, 사실 이는 최적의 방법이 아닐 수 있습니다. cross-entropy가 inter-class feature를 분리하는 경향이 있지만, 이를 이용해 학습된 모델은 여전히 class 내부 feature의 산포를 줄이는 능력에는 한계가 있습니다.
본 논문에서, 저자들은 fine-tuning에 contrastive learning을 도입하는것에 추가적인 이점이 있는지 조사하고, contrastive loss를 최적화하는것이 discriminative representation learning과 fine-tuning 중 모델 최적화에 도움이 된다는 것을 분석적으로 발견했습니다.
이러한 발견에서, 저자들은 CSL 모델을 fine-tuning하는 새로운 접근법인 ‘Contrast-regularized tuning (Core-tuning)’를 제안합니다. fine-tuning의 objective에 단순히 contrastive loss를 더하는 대신, Core-tuning은 더 효과적인 contrastive fine-tuning을 위해 새로운 hard-pair mining 전략을 적용시키고, 학습된 discriminative feature space를 더 잘 활용하기 위해 decision boundary를 smoothing하였습니다. 최종적으로는 image classification과 semantic segmentation에 대한 다양한 실험으로 core-tuning의 효과를 검증했습니다.
Introduction
기존에는 대규모 데이터베이스에서 심층신경망을 사전 학습 시킨 다음 downstream task에서 fine-tuning하는 방법이 일반적이었습니다. 최근에는, Contrastive self-supervised learning(CSL)이 hand-crafted annotation에 의존하지 않으면서도 downstream task에서 supervised pre-training한 수준의 성능을 보이며 model pre-training에 대한 관심이 커지고 있습니다.
CSL은 unlabeled data를 활용한 contrastive learning을 통해 동일 이미지에 각각 augmentation을 적용한 instance에 대한 유사도는 증가시키고, 다른 두 instance에 대한 유사도를 낮추며 시각 모델을 훈련시킵니다. 학습된 모델은 feature space에 균일하게 흩어진 instance-discriminative visual representation을 제공합니다.
pre-training 단계에서는 CSL 연구가 상당히 많이 진행되었지만, fine-tuning process에 대해서는 거의 연구가 진행되지 않았습니다. 일반적으로는 cross-entropy loss로 CSL 모델을 직접 fine-tuning하게 됩니다. 저자들은 다양한 fine-tuning 방법이 downstream task에서 모델 성능에 큰 영향을 미치며, 이 때 cross-entropy loss를 사용한 fine-tuning이 가장 좋은 방법은 아니라는 것을 발견했습니다.
cross-entropy가 클래스 간 분리 가능한 특징을 잘 학습하기는 하지만, CSL 모델에 존재하는 클래스 내 feature 산포를 줄이기 위한 능력에는 한계가 있습니다. 한편, 기존 대부분의 fine-tuning 방법들은 supervised pre-trained model을 위해 고안되었으며 pre-trained model에서 fine-tuning된 모델이 너무 많이 변경되는 것을 방지하기 위해 regularization을 시행하는 경향이 있습니다. 하지만 downstream task가 pre-training contrastive task와 다르기 때문에 적용에 비효율적인 면이 있습니다. 이러한 의미에서 CSL모델을 fine-tuning하는 방법은 중요하지만서도 충분히 연구되지 않은 문제로 남아 있습니다.
사전학습 과정에서 비지도 contrastive loss를 최적화 하는 것이 instance-level discriminativeness를 만들어낸다는 점에서, 저자들은 contrastive learning을 fine-tuning에 적용시키는것이 추가적인 이점이 있는지 조사했으며, 2가지 이점을 확인할 수 있었습니다.
첫 번째로, contrastive loss를 cross-entropy에 통합하는 것은 cross-entropy based fine-tuning과 비교해서 discriminative representation learning에 추가적인 relguarization 효과를 제공합니다. 이 효과는 모델이 각 class에 대한 low-entropy feature cluster(high intra-class compactness)와 high-entropy feature space(large inter-class separation degree)를 학습하게 합니다. 즉 같은 class끼리는 더 잘 clustering되게, 다른 class끼리는 더 잘 구별되도록 학습한다고 받아들이시면 됩니다.
두 번째로, contrastive loss를 최적화하는것은 training data에 대한 cross-entropy loss의 하한을 최소화하며 모델 fine-tuning에 추가적인 최적화 효과를 제공할 수 있습니다.
결국 저자들은 representation에 대한 1. regularization 효과와 2.optimization 효과에 기반해서 fine-tuning 도중 contrastive loss를 최적화하는것이 downstream task에서 CSL 모델 성능을 개선할 수 있다고 주장합니다.
위 효과를 고려해서 나오는 자연스러운 아이디어는 contrastive loss를 fine-tuning의 loss에 직접 더하는 것이고, 당시에 언어 모델 fine-tuning에 contrastive learning을 단순히 직접 적용시킨 연구가 하나 있었습니다.
하지만 이런 방법은 contrastive fine-tuning의 중요한 단점을 무시하는 것이기 때문에 contrastive learning의 이점을 온전히 활용할 수 없습니다. contrastive learning은 positive/negative sample pairs에 크게 의존하지만, 대부분의 sample features는 대조가 쉬워서 너무 작은, 무시해도 될만한 contrastive loss gradients밖에 만들어내지 못합니다. 대부분의 sample로는 최적화가 쉽지 않은 것입니다. 위에서 언급한 언어 모델 fine-tuning에서는 이러한 문제점을 무시해버렸기에 contrastive learning으로 discriminative features를 더욱 학습하는데 실패하였고 CSL 모델을 제대로 fine-tune하지 못했습니다.
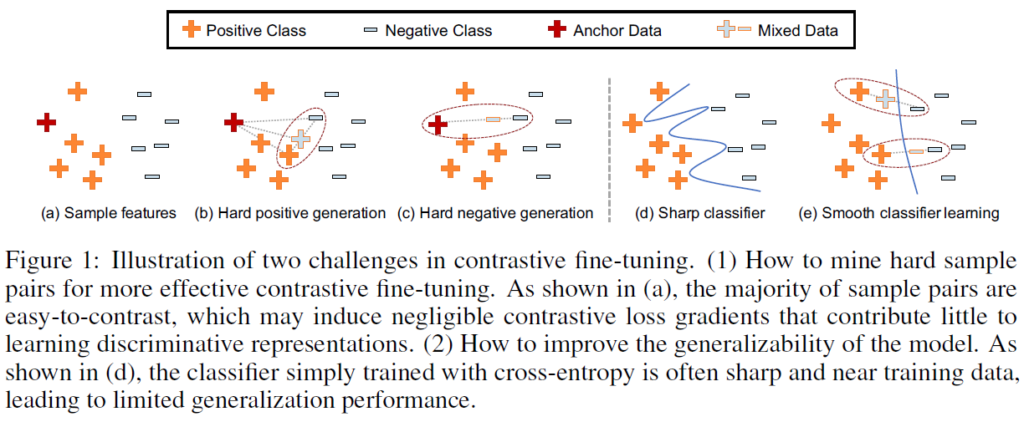
이 논문에서 저자들은 CSL 모델을 더 잘 fine-tune하고 downstream task에서 성능을 향상시키기 위해 hard pair mining strategy에 기반한 Contrast-regularized tuning 접근법(Core-tuning)을 제안합니다. 구체적으로, Core-tuning법은 새로운 hardness-directed mixup strategy에 따라 각 anchor data에 대해 hard positive와 hard negative pairs를 만듭니다. 여기서 hard positives는 anchor와 멀리 떨어져 있는 positive pairs를, hard negatives는 anchor와 가까이 있는 negative pairs입니다. hard pairs는 contrastive learning에 더욱 유용하기 때문에(Active Learning의 uncertainty 기반 방법론에서 결정 경계 와 가까운 instance가 더 informative한 것과 비슷한 느낌으로 생각하시면 될 것 같습니다), Core-tuning은 새로운 focal contrastive loss에 기반해 hard positive pairs에 더 높은 중요도 가중치를 부여합니다. 이런 방법의 contrastive fine-tuning을 통해 모델은 더욱 discriminative한 feature space를 학습할 수 있습니다.
다음으로, 저자들은 core-tuning에서 학습된 discriminative feature space를 어떻게 더 잘 활용할지 연구했습니다. 이전 연구(ICML2019 Manifold mixup)에서 단순히 cross-entropy로 훈련된 decision boundary가 너무 날카롭고 training data에 가까운 경향을 보인다는 것이 알려졌는데(Fig1의 d) 이는 classifier가 discriminative feature space에서 높은 class간 separation degree를 활용하지 못하고 일반화 성능을 제한하는 문제점이 있습니다. 말이 약간 복잡한데, Fig1의 (d)에서 보이듯 경계가 너무 지저분하고 train data에 가까이 있어서 일반성에 악영향을 미친다고 생각해주시면 됩니다. Core-tuning에서는 이 문제를 해결하기 위해 classifier를 학습시킬 때 mixed features를 사용해 decision boundaries가 더욱 smooth해지고 original train data와 멀어질 수 있게 학습합니다(Fig1의 e)
저자들은 이 방법을 제안함으로써 크게 3가지 contribution을 내세웁니다.
- CSL 모델의 fine-tunig단계는 중요하지만 아직 주목 받지 못한 영역이며, 저자들이 아는 한 이 연구가 CSL fine-tuning단계에 대한 가장 초기 연구중 하나이다. 이 부분의 개선을 위해 저자들은 Core-tuning을 제안했다.
- 저자들은 representation learning과 model optimization에 대한 supervised contrastive loss의 이점을 이론적으로 분석하여, 이것이 모델 fine-tuning에 도움이 된다는 것을 밝힌다.
- image classification과 semantic segmentation에 대한 준수한 결과는 CSL 모델의 fine-tuning 성능 향상에 있어 Core-tuning법의 효과를 입증한다.
또한 경험적으로 CSL 모델에 Core-tuning이 도메인 일반화, downstream task에 대한 adversarial robustness 측면에서 이점이 있다는것을 발견했다며, 이론적/실험적 Core-tuning의 효과를 고려하여 CSL model fine-tuning을 위한 baseline으로 사용할 것을 권고했습니다.
Related Work : Contrastive Self-supervised learning (CSL)
자가 지도 학습(self-supervised learning)은 회전 각도 예측, 색상 예측, clustering같은 unsupervised learning method이며, 논문 개제 당시 CSL이 가장 인기 있는 self-supervised 패러다임이었다고 합니다. CSL는 각 instance를 instance-discriminative representation을 학습하는 카테고리로 취급합니다(서로 다른 instance끼리 discriminative하게 학습한다는 뜻 입니다). SOTA CSL 방법으로는 InsDis, MoCo, SimCLR, InfoMin을 언급합니다. 대부분의 CSL 연구는 네트워크 사전 학습에 치중되어 있으며, fine-tuning 과정에서의 연구가 부진하다는 점을 지적합니다.
Effects of Contrastive Loss for model Fine-tuning
여기서는 fine-tuning에 InfoNCE를 살짝 변형시킨 supervised contrastive loss를 사용합니다. supervision 학습에 contrastive loss가 사용된 것이 이 논문에서 최초인 것은 아니고, NeurIPS2020에 ‘supervised contrastive learning’이라는 논문에서 소개된 loss를 사용합니다. 주어진 sample feature zi를 anchor로 삼고, 같은 class 내부 feature를 positive로, 다른 class를 negative pairs로 간주합니다(unlabeled self-supervised learning에서 contrastive loss를 사용할 때는 동일한 이미지를 positive로 사용했었죠). features가 l2 normalized되었다고 가정하고, contrastive loss는 다음과 같이 계산됩니다.
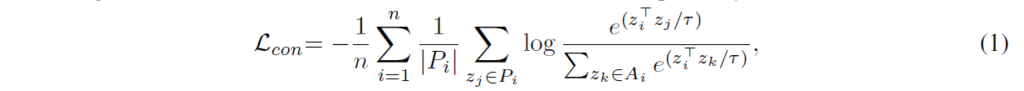
tau는 temperature factor라는 scaler로, 지수함수의 scale이 너무 튀는것을 막아주기 위한 상수라고 생각하시면 됩니다. Pi와 Ai는 zi에 대해서 각각 positive pair set과 full pair set을 뜻합니다. 저자들은 이 loss를 사용하는게 위에서 언급했던 것처럼 1.regularization 효과와 2.optimization 효과가 있다고 합니다.
Regularization Effect of Contrastive Loss
핵심은 feature가 l2 normalized되어있고 class 비슷한 데이터 수를 가져서 밸런스가 깨지지 않는다는 가정 하에, contrastive loss를 최소화 하는 것이 class-conditional entropy H(Z|Y )를 최소화하고 feature entropy H(Z)를 최대화 하는 것과 동일하다고 합니다. 여기서는 수식적 전개를 위해서 data imbalance를 고려하지 않았지만, 이후 experiment에서 imbalance dataset에 대해서도 준수한 성능을 보입니다.
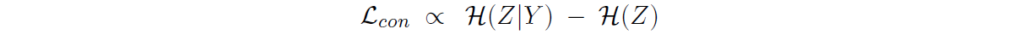
L_con을 최소화하면 H(Z|Y)가 최소화되어 각 클래스에 대해 low-entropy cluster(동일 클래스 내 compactness)를 학습하게 되고, H(Z)가 최대화되어 high-entropy feature space(클래스 간 분리도가 커지는 것)를 학습하게 됩니다. 이는 바로 아래 그림에서 보는것과 같이 feature space에 추가적인 regularization 효과를 준다고 합니다.
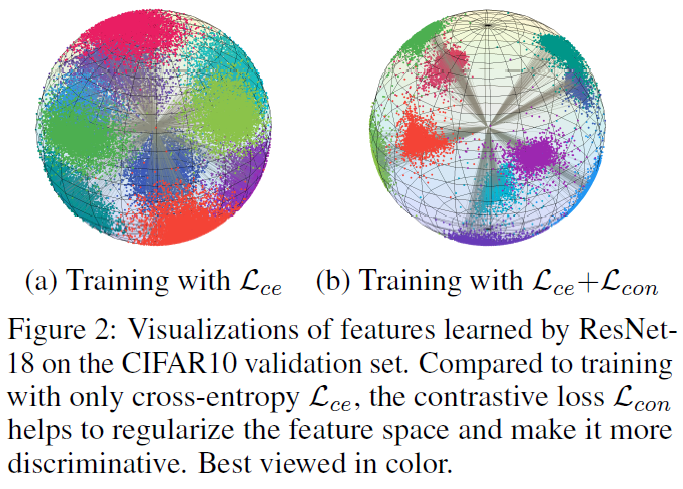
여기서는 instance level이 아닌 class level 분석을 하고 있으므로, unsupervised contrastive learning과는 다르다는 점을 유의하시며 그림을 보시면 되겠습니다. (a)보다는 (b)에서 동일 class 내부 feature가 모여있는것을 확인할 수 있습니다.
Optimization Effect of Contrastive Loss
feature가 l2-normalized되어있고 class imbalance 문제가 없다면, contrative loss는 conditional cross-entropy H(Y;Y|Z)에 비례한다고 합니다.
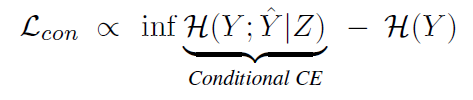
Y는 데이터셋에 의해 결정되므로 H(Y)는 상수이기 때문에 무시할 수 있습니다. 따라서 L_con을 최소화하면 conditional cross entorpy H(Y; Y|Z)의 하한을 최소화할 수 있으며, 이는 cross entropy만을 사용한 fine-tuning에 비해 추가적인 최적화 효과를 제공한다고 합니다.
Contrast-Regularized Tuning
위의 분석으로 contrastive learning을 fine-tuning에 도입하는게 좋다는 것은 알았지만, 밑의 Table2(experiment에 있습니다)를 참조하면 알 수 있듯 단순히 fine-tuning loss에 contrastive loss를 더해주는 것으로는 원하는 성능이 나오지 않습니다. 주요 원인은 introduction에서 언급했듯이 대부분 sample이 easy-to-contrast pair이기 때문에 유의미한 contrastive loss gradients를 만들어내지 못하기 때문입니다. 이 문제를 해결하기 위해 Contrast-regularized tuning(Core-tuning)에서는 hard sample mining strategy를 도입합니다. Core-tuning에서는 새로운 hardness-directed mixup strategy를 통해 hard positive와 hard negative를 생성하고, focal contrastive loss를 통해 hard positive pairs에 더 높은 중요도 가중치를 부여합니다.
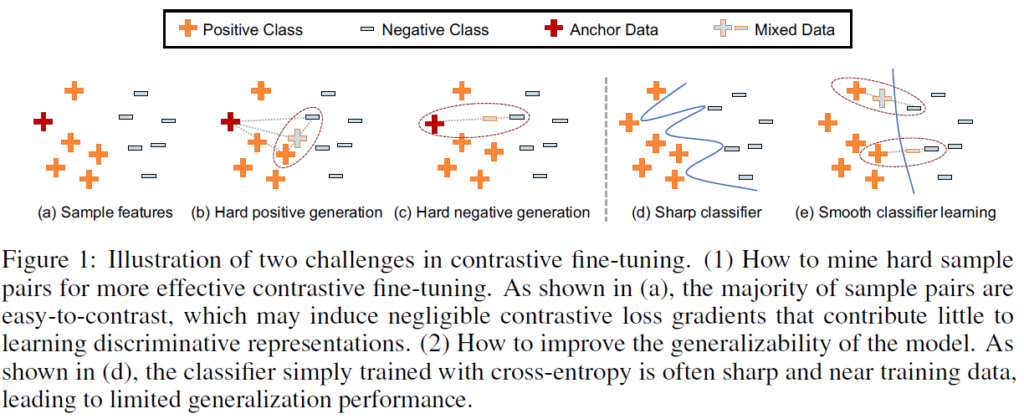
Hard positive pair generation
Fig1(b)를 참고하시면 됩니다. feature anchor zi에 대해서, 코사인 유사도 기반으로 hardest positive data (zi_hp, yi_hp)와 hardest negative data(zi_hn, yi_hn)를 선별합니다. zi_hp는 동일 class중 anchor와 가장 유사도가 낮은 데이터고, zi_np는 다른 class중 anchor와 가장 유사도가 높은 데이터입니다. 그 뒤에는 두 hardest pairs의 convex combination을 통해 hard positive pair를 생성합니다.
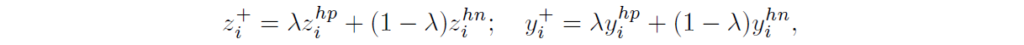
Hard negative pair generation
Fig1(c)를 참고하시면 됩니다. 주어진 anchor zi에 대해서 무작위로 negative sample (zi_n,yi_n)를 뽑아서 다음과 같이 semi-hard negative pair를 합성합니다:
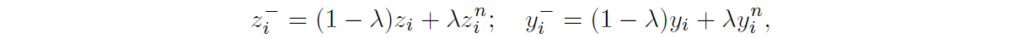
hardest negative 대신 random negative sample을 선택하는 이유는 너무 hard한 negatives를 생성하는것은 false negative나 성능 악화의 원인이 될 수 있기 때문이라고 합니다. metric learning에서 semi-hard negative가 더 나은 성능을 보인다고 합니다.
Overall Training Scheme and Smooth Classifier Learning
fine-tuning에서는 feature extractor와 classifier 모두 학습되어야 하므로 최종적으로 Core-tuning의 학습 과정은 다음 objective를 최소화하는 것으로 설계할 수 있습니다.

이전 연구에서 단순히 cross-entropy로 학습하된 분류기가 날카롭거나 데이터가 가까워서 discriminative feature space에서 high inter-class separation degree를 초래하고 일반화 성능에 제약이 생길 수 있다는 것이 알려졌다고 합니다(Fig1의 d 참고). 이를 smooth decision boundary로 해결하기 위해서 분류기 학습에 생성한 hard sample pair mixing을 추가적으로 사용한다고 합니다.
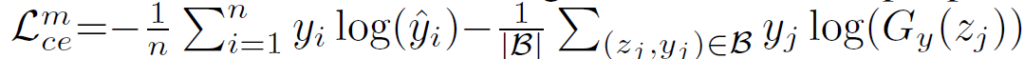
이 방법으로, Core-tuning은 training data와 어느정도 거리를 확보한 smoother classifier를 학습 할 수 있게 되었고 학습된 discriminative feature space를 더 잘 확용할 수 있게 되어 모델 일반성이 향상되었다고 합니다.
Experiments
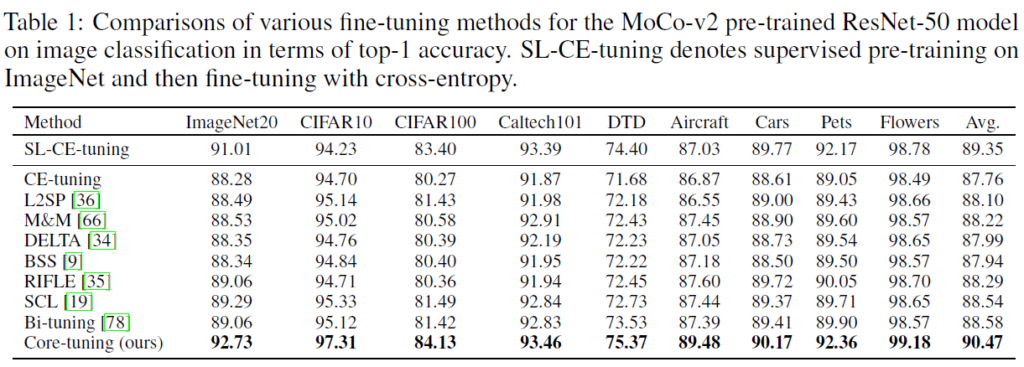
실험 결과에 대해 저자들은 supervised pretrained 모델을 위해 설계된 고전적인 fine-tuning 방법은 contrastive pretrain 모델을 잘 fine-tuning 할 수 없다고 합니다. contrastive pretraining 방법이 downstream classification작업과 본질적으로 다르기 때문에 negative transfer가 발생한다고 하기 때문이라고 합니다(negative transfer는 제대로 적용이 잘 되지 않는 것을 뜻하는 것 같습니다)
Core-tuning은 Figure1의 문제점을 잘 해결했고 fine-tuning의 방법을 수정해 성능에 상당한 개선에 성공했다고 합니다.
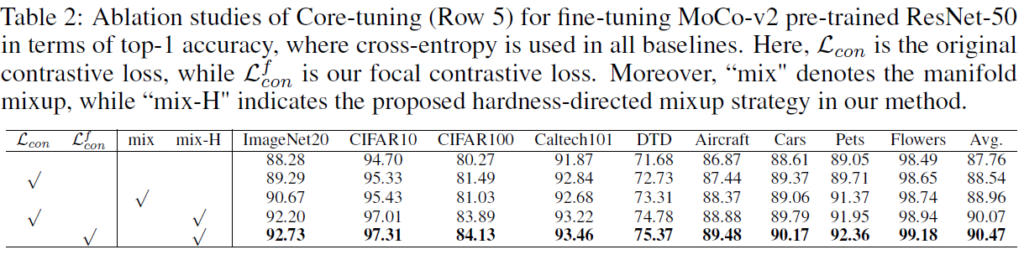
Ablation study에서는 focal contrastive loss와 hardness-directed mixup 전략에 대해 진행되었고, 각 요소가 성능 향상에 긍정적인 영향을 미친다는 것을 보였습니다.
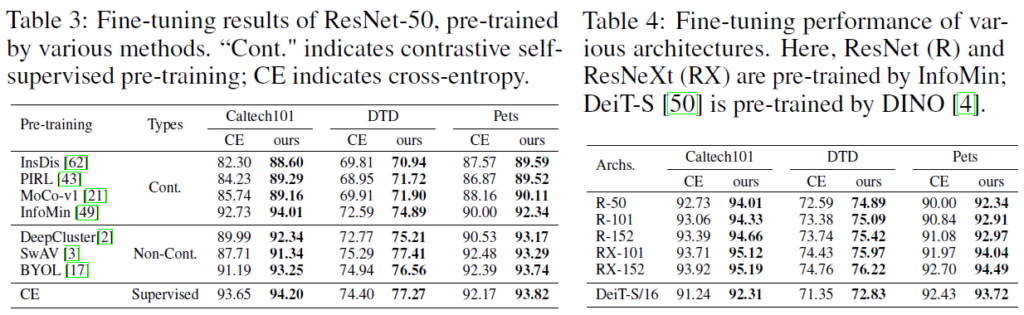
다음으로는 다양한 self-supervised learning에 대해 Core-tuning을 진행한 결과와, 다양한 모델에서 진행한 결과입니다. contrastive pretraining 방법에 대해서는 유효한 것을 확인할 수 있습니다(SwAV, BYOL와 같이 contrastive learning이 아닌 방법으로 pretrain된 모델에 대한 비교도 있는데, 단순히 cross-entropy를 사용한것보다 준수한 성능을 보여줍니다)
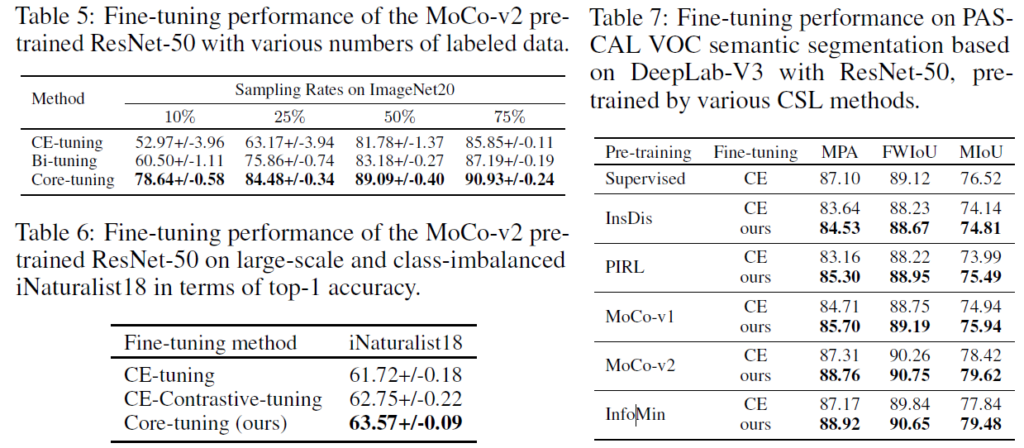
downstream task에서 데이터의 수가 부족할 수 있기 때문에, Table 5에서는 다양한 데이터 수에 대해서 성능을 비교했습니다. 기존의 tuning 방법들은 데이터가 부족하면 상당히 성능이 떨어지는데, Core-tuning은 기존보다 많이 개선된 결과를 보여줍니다. 특히 10%의 데이터로만 학습했을 때는 차이가 큽니다.
실세계 데이터셋은 규모가 크고 클래스 불균형 문제가 있을 수 있기 때문에 long-tailed iNaturalist18 데이터셋에 대한 평가도 진행되었습니다(잘 모르는 데이터셋인데 class imbalance가 있는 데이터셋인것 같습니다) Table6에서 보듯이, Core-tuning 방법이 class imbalance에 대한 상황에서도 성능이 떨어지지 않는 것을 확인할 수 있습니다.
semantic segmentation
마지막에는 self-supervised models를 semantic segmentation에 대해 Core-tuning 방법으로 fine-tuning한 실험 결과입니다. PASCAL VOC semantic segmentation을 위해 DeepLab-V3 framework를 사용하고 backbone으로는 CSL pre-trained 된 ResNet50을 사용했다고 합니다. 평가 metric으로는 Mean Pixel Accuracy(MPA), Frequency Weighted Intersection over Union(FWIoU), Mean Intersection over Union(MIoU)가 사용되었습니다.
Table 7을 보면, Core-tuning이 모든 CSL 모델의 성능에 기여했다는 것 확인할 수 있습니다. 한가지 눈에 띄는것은 supervised pretrained 모델보다 MoCo-v2와 InfoMin으로 pretrain한 성능이 높습니다. 저자들은 여기서 self-supervised 방식으로 사전 학습하는게 classification에 집중해서 supervised learning하는 것보다 visual information을 더 잘 유지할 수 있다고 설명하는데.. 그럼 supervised 에서는 결국 sementic segmentation이 아니라 classification으로 pretrain한 것으로 보이네요. 추가적인 설명이 없습니다.
Conclusion
이 논문에서는 Contrastive Self-supervised visual model을 어떻게 fine-tuning할 것인지 연구했습니다. 이 논문에서 저자들은 이론적으로 fine-tuning 단계에서 contrastive loss를 최적화하는게 representation learning에서 regularization 효과와, classifier training에 optimization 효과가 있음과 함께 이 두가지 효과 모두 model fine-tuning에 유용하다는것을 보였으며, CSL visual model을 fine-tuning하는 새로운 Contrast-regularized tuning(Core-tuning)법을 제안했습니다. 또한, 실험적으로 Core-tuning이 downstream tasks에 있어 model generalization과 robustness가 있음을 발견했고 Core-tuning을 CSL visual model fine-tuning에 대한 표준 baseline으로 사용할 것을 추천합니다. 추가적으로 사람들에게 기반 이론을 이해해서 CSL visual model을 fine-tuning하는 것에 더욱 관심을 가지고 앞으로 더 나은 접근법을 활용하길 바란다고 했습니다.
마지막에는 Core-tuning이 CSL visual model을 fine-tuning하는 것에 집중해서 고안되었으니, 다른 visual model이나 language model, 혹은 더 많은 task로의 확장 연구가 진행되기를 바란다고 언급하면서 논문을 마무리했습니다.
논문이 꽤나 복잡해서 읽는데 특히 오래 걸렸습니다. 평소 fine-tuning하는 부분에서는 하이퍼파라미터 튜닝 말고는 별다른 접근을 고려해본 적이 없었는데 pretrain에 contrastive learning을 사용했으니까 fine-tuning 역시 이를 고려해야 한다고 하는 부분에서 인상적이었습니다. 기초를 어느 정도 쌓고 나서 부터는 수용적인 태도를 살짝 내려놓고 시야를 넓게 바라보는 습관을 가지려 노력해야겠습니다
안녕하세요. 허재연 연구원님
좋은 리뷰 감사합니다.
파인튜닝에서도 사전학습 방법을 고려하는 것이 흥미로운 논문인 것 같습니다.
Hard positive generation과 hard negative generation이 어려운 pos/neg 샘플을 그대로 사용하지 않고 다른 neg/pos 샘플을 일정 비율 섞어서 학습 데이터에 존재하지 않는 샘플을 만들어 학습하는 것으로 이해하였은데 맞게 이해한 것인지, 이때 람다는 어느 정도로 설정하는지 궁굼합니다!
감사합니다
비슷한데, 이름이 generation인만큼 람다값을 이용해 새로운 hard positive/negative sample을 만들어내는 것으로 생각하시면 됩니다. 이 때 positive sample과는 달리 negative sample을 선별할때는 무작위로 선별하는 과정이 들어갑니다.
람다값은 beta distribution을 결정하는 하이퍼파라미터입니다. λ~Beta(α,α)∈[0, 1] 이고, α∈(0,∞)인데, 관심 있으시다면 [ICLR2018] mixup: BEYOND EMPIRICAL RISK MINIMIZATION을 참고하시면 좋을 것 같습니다.