이번에 리뷰할 논문은 ICASSP 2023의 Fast Yet Effective Speech Emotion Recognition with Self-Distillation으로 이전에 리뷰했던 self-distilation 기법을 음성 감정인식 분야에 적용한 논문입니다. 최신 논문 중 감정인식 모델의 경량화 라는 키워드를 내세우고 있어 읽어보았는데요, 이전에 리뷰한 논문에서 개념적인 내용은 크게 달라지지 않았으나 self-distilation논문은 이미지 데이터 + CNN기반의 네트워크 환경에서 동작하였다면 이 논문에서는 이를 오디오 데이터 + transformer기반 네트워크로 확장시켰으며, 감정인식 task를 수행하였다는 것이 차이점이겠네요.
Introduction
Speech Emotion Recognition은 사람의 음성 신호를 행복, 슬픔, 분노 등의 감정 상태로 분류하는 task입니다. SER의 일반적인 pipeline은 이미지 분류와 비슷한 구조를 띄고 있는데요, backbone 네트워크에서 입력 음성의 특징을 추출하고, 추출된 특징 벡터를 분류기에 입력하여 여러 감정 중 하나로 classification을 수행합니다.
저자들은 현존하는 SER들은 라벨링된 데이터가 부족하여 limited 되었다고 언급합니다. 다른 도메인의 경우에도 라벨링 비용에 관한 이야기는 있지만, 오디오 데이터는 약 7000개의 언어로 녹음된 음성에 하나하나 라벨링은 진행하는 것의 cost가 높다고 하네요. 이 때문에 최근의 오디오 task는 wav2vec 시리즈와 같은 대규모 사전 학습 모델을 특징 추출 부분에 사용하고, 전체 네트워크를 fine tuning 하는 방식을 많이 사용한다고 합니다.
그러나 저자들은 대규모 모델을 fine tuning하는 방식은 memory space의 사용량이 크고 느린 inference time을 보인다는 점을 문제라고 지적하며 이를 개선하기 위해 self-distilation을 음성 감정인식 모델에 적용하였습니다.
Knowledge Distilation
Self-distilation에 관해 설명하기 전에 간단히 knowledge distilation에 관해 설명드리자면, knowledge-distilation은 모델 경량화 기법 중 하나로 large pretrained 모델인 teacher의 지식을 small 모델인 student에 전달하여 student가 teacher와 비슷한 성능을 낼 수 있도록 하는 것을 의미합니다. 아래의 그림과 같이 사전 학습된 large 모델인 Teacher 모델의 파라미터를 고정하고 Teacher보다 작은 student모델을 학습할 때 student의 soft prediction이 teacher와 유사해지도록 학습합니다.
이때 soft prediction이란 모델이 예측하는 예측값의 분포라고도 할 수 있습니다. 예를 들어 [강아지, 고양이, 새]를 분류하는 모델이 있고, 고양이 이미지 하나를 모델에 입력하여 [0.2, 0.6, 0.2]를 출력했다고 가정해 보겠습니다. 일반적인 supervised learning은 모델의 output과 gt인 [0, 1, 0]의 오차를 이용하여 학습을 진행합니다. 아래 그림의 student loss가 이에 해당되는 것입니다.
그러나 이때 이미 좋은 성능을 보여주는 사전 학습 모델(teacher)이 있으며, 해당 모델의 sofrmax output이 [0.09, 0.9, 0.01]이면 결과적으로는 가장 높은 값을 가진 ‘고양이’로 예측한 것은 동일하나 정답 클래스를 제외한 나머지 예측값에서 ‘강아지’를 ‘새’보다 높은 확률로 예측한 것을 볼 수 있습니다. 이때, 이러한 분포를 teacher모델의 ‘knowledge’라고 하며 student가 이러한 경향성을 따라갈 수 있도록 아래 그림의 distilation loss를 사용하여 학습합니다.
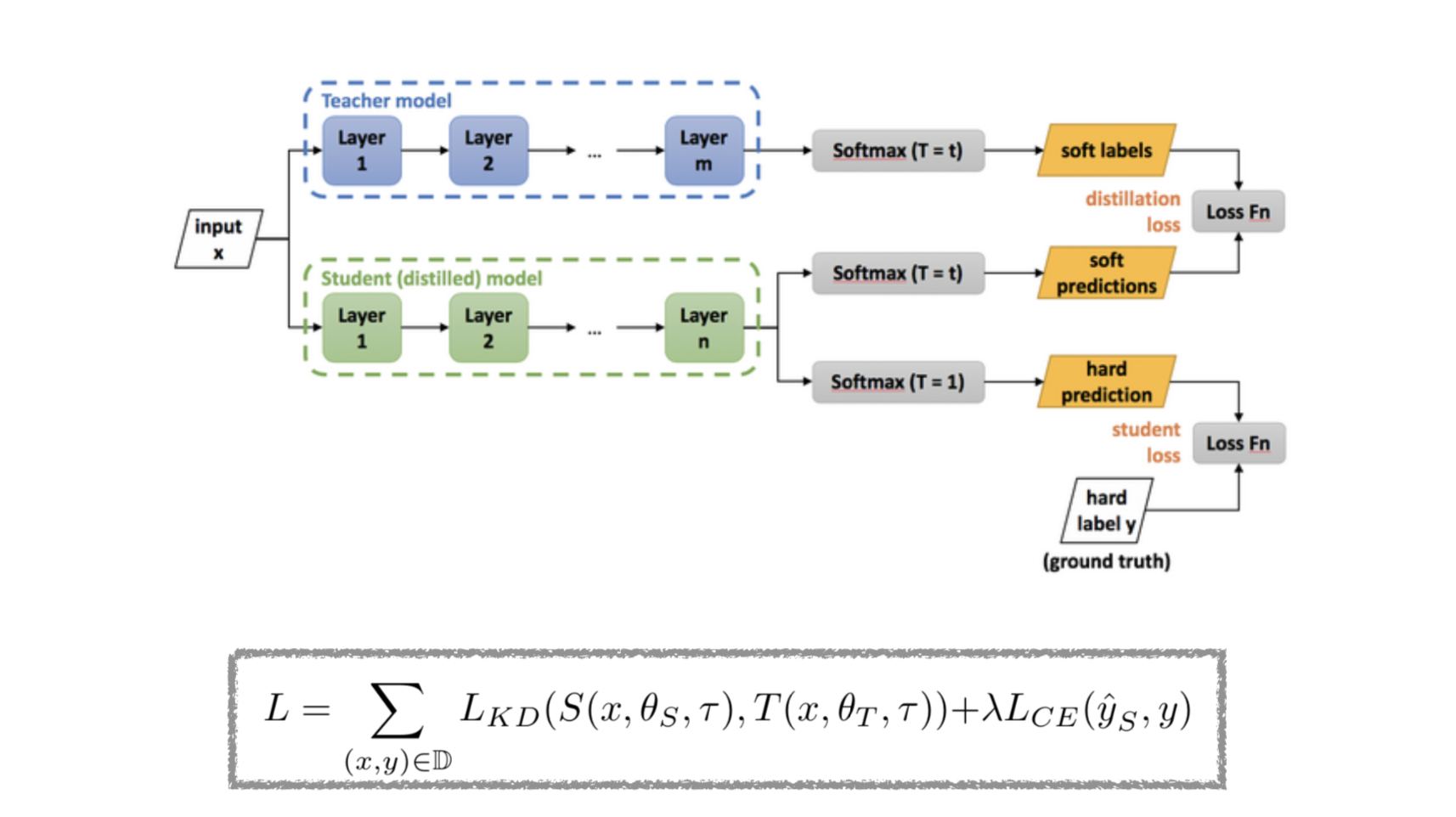
저자들은 distilation방법론 중 하나인 self-distilation에서 motivation을 얻어 아래와 같은 SER pipeline을 제안하였는데요, self-distilation 논문은 이전에 리뷰로 작성했으니 참고 부탁드립니다.
Method
다시 돌아와서 이 논문의 저자들은 빠르고 효과적인 SER을 위해 [그림1]과 같은 self-distilation 프레임워크를 제안하였습니다. 아래의 [그림1]은 wav2vec 2.0에서 self-distilation을 수행하는 것을 나타내고 있습니다.
Model Architecture

Teacher Model
Teacher 모델은 [그림1]에서 Audio wave를 입력으로 받고 출력으로 O를 출력하는 부분에 해당합니다. 이때 Teacher 모델에서 CNN과 Transformer로 표시된 부분이 wav2vec 2.0을 나타내며, 뒷부분의 Linear 레이어 2개는 감정의 분류를 위해 추가된 부분입니다. 모델의 입력 데이터는 (X, y)로 X는 raw audio signal이고 y는 감정 label입니다. Transformer의 output은 (B, F, R)의 크기를 가지며 각각 batch size, time steps, 각 time step의 representation을 의미합니다. 마지막 N번째 transformer T_N의 output은 (B, R)크기의 벡터로 pooling되어 linear에 입력으로 사용된다고 합니다.
Student Model
Teacher 모델의 파라미터를 줄이기 위한 student모델은 중간 transformer에서 이어지는 가로 방향의 모델입니다. wav2vec 2.0의 중간에 위치한 transformer로 부터 추출된 feature로 classification을 진행하도록 설계되었으며 간단한 신경망 구조인 블록 M과 teacher와 마찬가지의 linear layer 2개로 구성되어 있습니다.
Loss
사전 학습된 wav2vec 2.0은 이미 음성에서 표현을 학습하는 강력한 능력을 가지고 있기 때문에, 저자들은 사전 학습된 wav2vec 2.0으로 teacher의 파라미터를 initialize하였고, 그 이후에 fine tuning을 진행하였는데요, 그 과정의 Loss function은 아래와 같이 구성하였습니다.
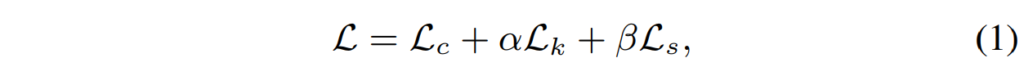
$L _C$는 Cross Entropy loss, $L_K$는 KL divergence(이하 KL loss), $L_S$는 similarity loss를 의미하며, 각각에 대한 설명은 아래에서 진행하겠습니다. $\alpha, \beta$는 각 loss의 가중치를 의미하며 실험 파트에서는 모두 1로 사용하였다고 합니다.
Cross-entropy Loss
L_c는 SER모델의 예측 결과와 GT사이의 loss로, teacher의 Cross-Entropy loss와 student의 Cross-Entropy loss를 모두 포함하도록 구성되었으며 식으로 표현하면 아래와 같습니다.
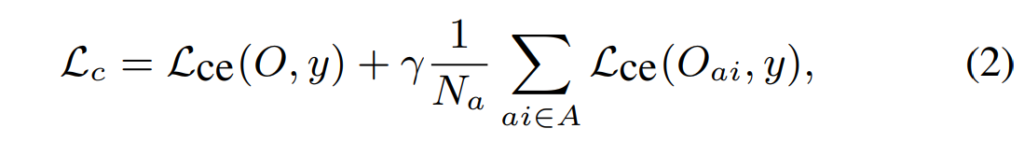
보시는 바와 같이 teacher의 CE loss와 student CE의 평균값으로 이루어져 있으며 가중치 \gamma는 실험에서 1로 설정하였다고 합니다.
KL Loss
위의 CE loss가 teacher의 예측과 GT, student의 예측과 GT사이의 loss라면 KL loss는 teacher와 student의 예측값 사이의 차이를 의미합니다. 즉, student의 linear layer output이 teacher의 linear layer output과 유사해 지도록 하는 것이며 KL divergence를 사용하여 아래의 식과 같이 구성하였다고 합니다.
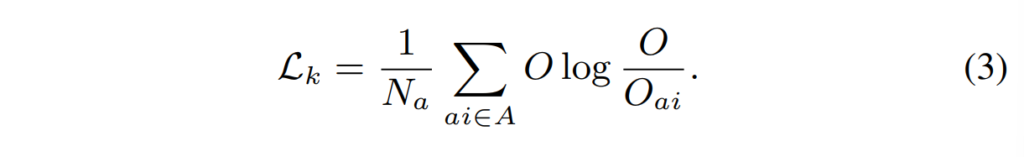
Similarity Loss.
model prediction에서 계산되는 loss와는 별개로, similarity loss는 backbone에서 추출된 feature간의 유사성을 비교하는 loss입니다. 모델의 중간 output(마지막 Transformer이전에 추출된 feature map)을 마지막 feature map에 유사해지도록 하는 것으로 아래의 식과 같이 구성되었습니다.
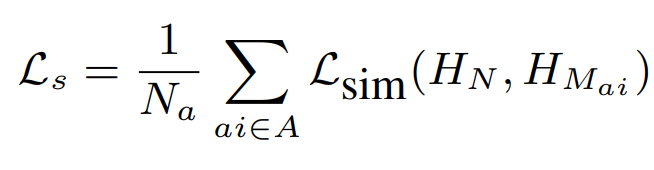
위의 식은 self-distilation의 원본 논문에도 등장한 similarity loss식인데요, 저자들은 transformer의 feature map 간의 similarity loss와 첫 번째 linear layer의 output에서 similarity loss를 구하는 방식 두 가지를 사용하여 이를 비교하였습니다.
Experiments
방법론에 관한 설명은 위의 내용으로 마무리하고 이제 논문의 실험 결과들을 살펴보겠습니다.
특이하게도 SER task에 자주 사용되는 RAVDESS, IEMOCAP이 아닌 DEMoS라는 데이터셋을 사용하였습니다. 해당 데이터셋은 처음 보는 것 같아 간단히 정리하고 넘어가겠습니다.
Database
DEMoS는 68명의 화자가 녹음한 9697개의 Italian 음성 데이터를 8개의 클래스(anger, disgust, fear, guilt, happiness, sadness, surprise, neutral)로 라벨링한 데이터셋입니다. 본 논문의 실험에서는 DEMoS를 사용한 다른 감정인식 연구인 [24], [25]와의 비교를 위해 neutral을 제외한 7개의 감정만을 사용하였다고 합니다. 또한 학습 시 발생 할 수 있는 speaker dependency를 방지하기 위해 train, development, test 데이터를 구성할 때 발화자가 겹치지 않도록 구성하였습니다. 각 감졍 별 데이터의 개수와 발화자의 분포는 아래의 표와 같이 설정하였다고 합니다.

Settings
Evaluations Metrics
SER 모델의 성능을 평가하기 위한 metric으로는 가중 평균 recall(UAR)을 사용하였으며, 이는 모든 클래스별 recall의 평균값을 의미합니다.
Implementation Details
Teacher model이 되는 Deepest classifier는 [그림1]과 같이 wav2vec 2.0에 두 개의 linear 레이어를 붙여 구성하였습니다. 이 때 분류할 감정의 개수가 7이므로 D_2 = 7로, batch size는 256으로 설정하였다고 합니다. student 모델(distilation 모델)은 transformer + block M을 backbone으로 하고 teacher와 마찬가지로 2개의 linear 레이어로 감정 분류를 수행하는데요, M은 output 채널이 1인 1*1 CNN으로 설정하였다고 합니다.
Results
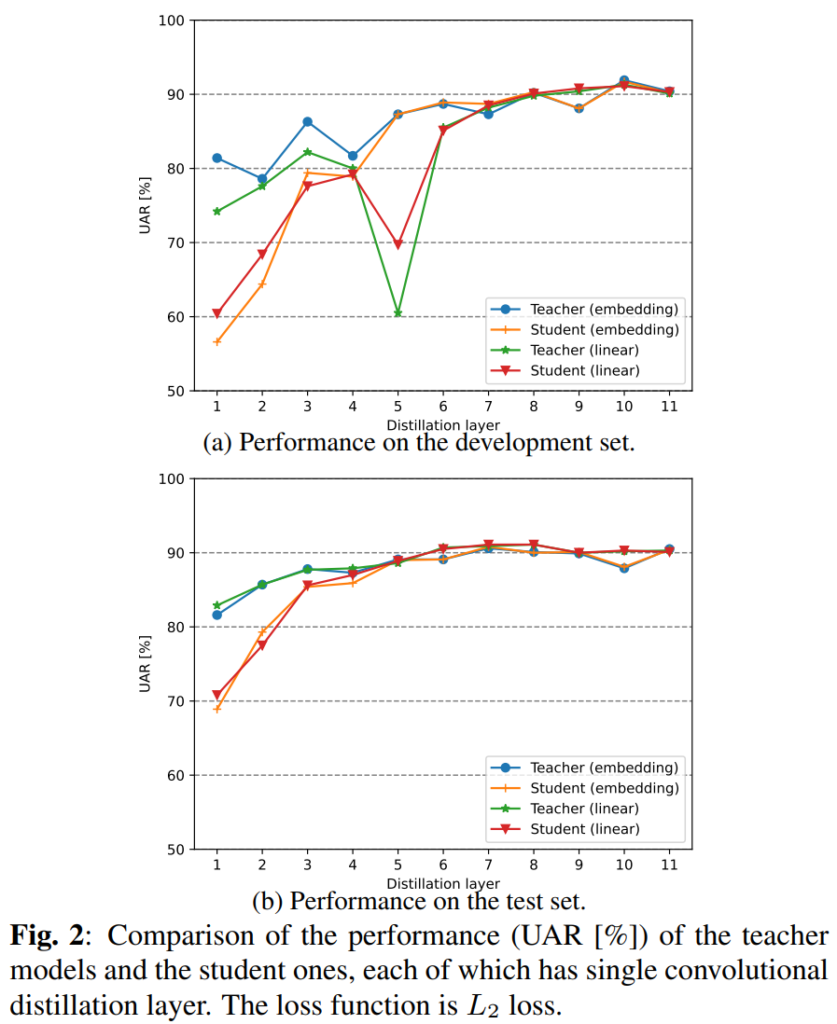
[그림 2]는 self-distilation 성능을 distilation 레이어에 따라 나타낸 것입니다. 위의 [DEMoS 데이터셋 분포]를 보면 데이터를 train, dev, test 세 종류로 나눈 것을 확인할 수 있는데요, [그림2-(a)]는 dev set으로 평가하였고 (b)는 test set으로 평가한 결과인데요, (a)는 train set 만을 학습에 사용하였고, (b)는 train+dev set을 모두 학습에 사용한 뒤 평가한 결과라고 합니다. 그림에서 보실 수 있는 것처럼 더 깊은 레이어에서 더 높은 성능을 보여주고 있으며, 이는 얕은 레이어보다 깊은 레이어가 오디오 전체의 추상적인 표현을 더 잘 학습할 수 있기 때문이라고 합니다. 또한 대체적으로 Teacher가 student보다 높은 성능을 보이지만 7번째 레이어 이후부터는 student의 성능이 teacher의 성능과 비슷해지는 것을 확인할 수 있습니다.
wav2vec 2.0에는 총 12개의 transformer 레이어가 있어 11개의 student가 생성될 수 있는데요, 이를 깊이에 따라 세 그룹으로 나누어 각 그룹에서 가장 성능이 좋은 {3, 8, 10}번째 student 모델을 선택하여 다음 실험에 사용하였다고 합니다.
Ablation Study
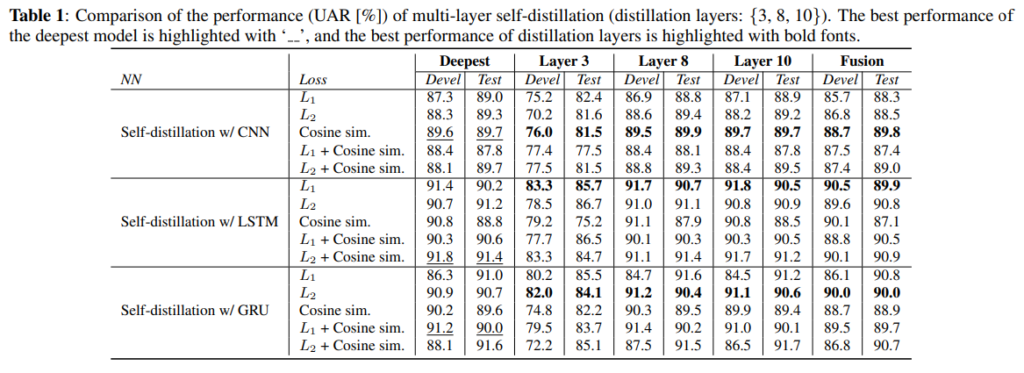
저자들은 총 세가지의 블록(CNN, LSTM-RNN, GRU-RNN)과 similarity loss(L1, L2, Cosine sim.)에 대한 ablation study를 수행하였으며 그 결과는 아래의 [표1]과 같습니다.
Comparison with SOTA
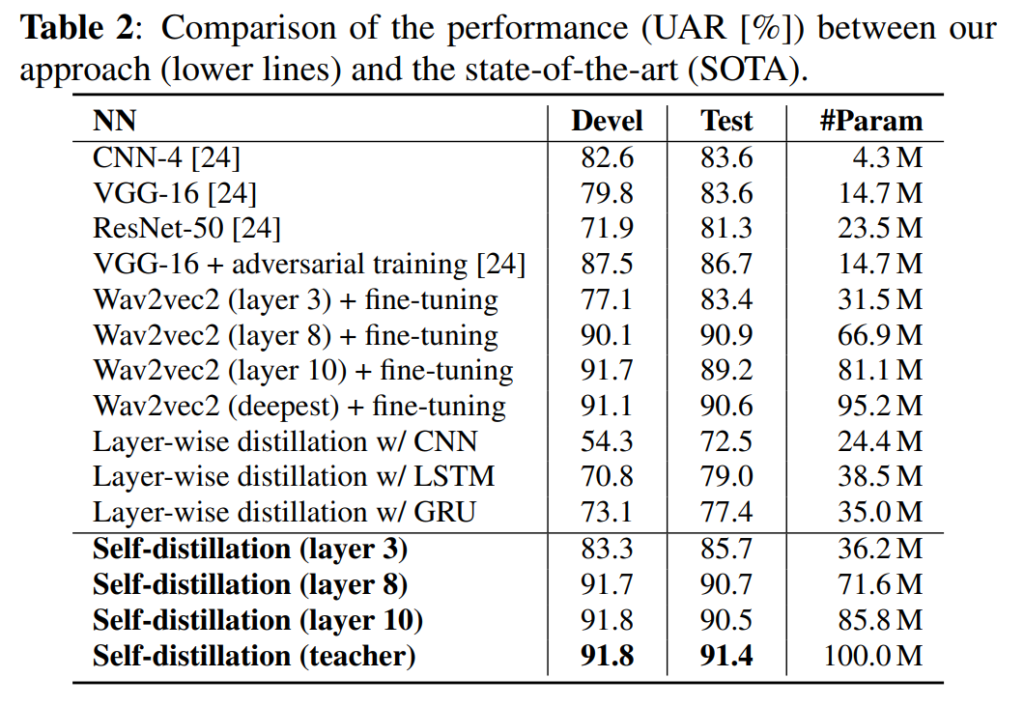
다음으로 SOTA와의 비교 실험입니다. intro에서 열심히 inference time과 memory usage를 언급하였으나 정작 efficiency를 판단할 만한 지표는 파라미터 수 밖에 없다는 점이 아쉽네요.
안녕하세요. 좋은 리뷰 감사합니다.
wav2vec 모델이 나오면서 확실히 오디오 분야에서도 새로운 바람이 부는 것 같아 기분이 좋습니다. 간단한 질문이 있는데요.
1) student 모델의 block M이 무엇일까요? 그리고 모델 구조를 보면 output이 총 3개가 나온는데 그러면 teacher하나 student 2개 이렇게 구성되어 있는 거라고 볼 수 있는 걸까요? 그렇다면 왜 이렇게 설정했는지 아니면 이렇게 설정하는 것이 당연한 것인지 궁금합니다.
2) performance 보면은 teacher-student linear 이렇게 한 쌍 embedding 이렇게 한쌍 이렇게 있는데 이는 무엇을 의미하는 건가요? wav2vec 모델 사용 했냐 안했냐 여부인건가요..?
감사합니다.
안녕하세요 김주연 연구원님. 댓글 감사합니다.
block M은 student모델에서 Transformer에서 뽑은 feature를 linear에 통과시키기 전에 거치는 bottleneck으로 이해하시면 될 것 같습니다. 이러한 구조를 띄게 된 이유는 self-distilation이 원래는 CNN에서 이루어지다 보니 student로 이어지는 backbone이 어느 지점이냐에 따라 feature map의 크기가 달라지는 문제가 발생하였는데요, 이 때문에 Teacher의 마지막 cnn레이어의 output과 동일한 모양을 맞춰주기 위해 student 마다 추가로 bottleneck 블록을 붙여주었습니다. 이 논문에서는 transformer기반의 wav2vec 2.0을 사용하였으나 self-distilation의 기본적인 구조를 동일하게 맞춰주기 위해 block M을 사용하였습니다. 이때 기존 self-distilation과 달리 block M은 입출력의 크기가 동일하게 되겠지요.
[그림1]에서는 i와 j의 두 가지 student를 나타나 있는데요, 모델을 설계할 때 student의 개수는 backbone에 따라 달라지기 때문에 2개의 student를 사용할 필요는 없습니다. Wav2vec 2.0은 12개의 transformer레이어로 이루어져 있으니 총 11개의 student를 사용할 수 있고 이 중 어떤 student를 사용할 지는 [그림2]의 실험을 통해 좋은 성능의 student를 선택하였다고 합니다.
[그림2]의 embedding과 linear는 similarity loss의 사용 위치를 나타냅니다. [그림1]의 L_s를 나타내는 점선이 두 종류가 있는데요, 하나는 transformer output에, 하나는 linear layer의 output에 위치한 것을 볼 수 있습니다. 이때 transformer output 끼리의 similarity를 계산한 경우를 embedding, 아닌 것을 linear로 표기하였다고 합니다.