
안녕하세요. 이번에도 6D pose estimation 논문입니다.
좀 지난 논문이긴 하지만, 아직까지도 reference가 달리기도 하고 6D 관련 논문에서는 꽤 많은 인용수를 가지고 있는 논문이라 읽으려고 항상 ‘생각’만 가지고 있었던 논문이었습니다. 이번 기회에 Autoencoder(AE)라는 것을 어떻게 사용하는지도 이해해볼겸 읽어보았습니다.
리뷰 시작하겠습니다.
Abstract
해당 논문에서는 object detection 및 6D pose estimation을 위한 real-time RGB-based 파이프라인을 제안합니다. 새로운 3D 방향 추정 방법은 Domain Radomization(DR)을 사용하여 3D 모델에 대한 simulation-view에 대해 학습된 Denoising Autoencoder(DAE)의 변형을 기반으로 합니다. 이를 저자는 Augmented Autoencoder(AAE)라 이름을 붙입니다.
이러한 AAE는 기존 방식의 DAE에 비교해서 몇 가지 장점이 있습니다.
- 실제로 pose에 대한 annotation이된 학습 데이터가 필요하지 않음
- 다양한 test-sensor에 일반화할 수 있음
- 물체와 view의 대칭을 자체적으로 처리할 수 있음
입력 이미지에서 오브젝트 pose에 대한 명시적 매핑을 학습하는 대신, latent space에서 샘플로 정의된 오브젝트 방향에 대한 latent representation을 제공합니다.
1. Introduction
모바일 로봇 manipulator 및 AR(Augmented Reality)과 같은 애플리케이션을 위한 최신 컴퓨터 비전 시스템에서 가장 중요한 구성 요소 중 하나는 안정적이고 빠른 6D object detection module입니다. 하지만 여전히 속도 측면이나 강인하도록 만들어주는 솔루션은 없는 현실입니다. 이유는 여러가지가 있는데요. 첫 번째로는 오브젝트에 대한 occlusion, clutter, 환경의 변화와 같은 일반적인 문제에 대한 해결책이 부족한 상황입니다. 두 번째로 기존 방법에서는 confusion을 피하기 위해 충분한 텍스처 표면 구조 또는 비대칭 모양과 같은 특정 개체 속성이 필요한 경우가 많습니다. 마지막으로, 현재 시스템은 런타임과 필요한 annotation된 학습 데이터의 양 측면에서 효율적이지 않습니다.
따라서 저자는 이러한 문제를 직접적으로 해결하는 새로운 접근 방식을 제안합니다. 단일 RGB 이미지에서 작동하므로 깊이 정보가 필요하지 않으므로 사용성이 크게 향상될 것을 기대합니다. 물론 다들 아시다시피 깊이 정보를 활용하는 경우, 성능면에서는 단일 RGB 보다 훨씬 좋습니다.
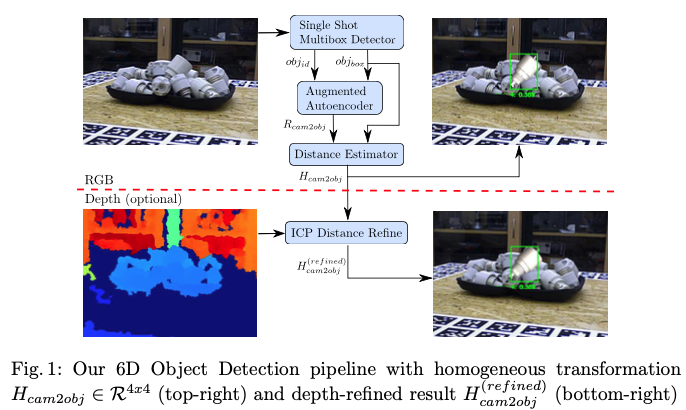
그림(1)과 같이 Depth(optional)로 나와있는 것을 보아 저자는 필요에 따라 depth map을 이용하여 pose estimation의 결과를 refinement 할 수 있다고 합니다. 전체적인 파이프라인 구조의 첫 번째 단계로, 객관적인 Bbox와 identifier를 제공하는 SSD를 사용한다고 합니다. 여기서 말하는 identifier는 label과 confidence score를 의미하는 것으로 보입니다. 해당 최종 결과물인 scene crop에서는 사전에 학습된 모델을 기반으로 하는 새로운 3D 방향 추정 방법을 사용하게 됩니다. 해당 논문에서의 접근 방식은 좀 특이하게도 학습 중에 3D pose에 대한 annotation을 통해서 학습하지 않는다는 것이 흥미로운데요. 그럼 어떻게 학습을 한다는 것일까요? 렌더링된 3D 모델의 view에 대해서 즉, latent representation을 학습한다고 합니다. 그럼 latent representation을 어떻게 얻는지 알아보겠습니다. 이는 Domain Randomization(DR)을 사용하여 Augmented Autoencoder(AAE)라고 부르는 Denoising Autoencoder(DAE)의 일반화된 버전을 학습함으로써 얻을 수 있습니다. 그럼 이러한 AAE를 사용하면서 얻는 이점이 있을텐데요. 다음과 같은 이점이 있었다고 합니다.
- 학습이 SO(3) 내에서 오브젝트 방향의 구체적인 representation(ex, quarternion)과 독립적이기 때문에 이미지에서 방향으로의 one-to-many 매핑을 피하기 때문에 symmetric view로 인한 ambiguous pose를 처리할 수 있다.
- 3D 방향을 구체적으로 encoding하는 representation을 학습하는 동시에 occlusion, clutter에 대한 robustness를 달성하고 다양한 환경과 테스트 센서에 일반화합니다.(시뮬레이션 환경이나 실험 환경에서 다양한 조건을 시뮬레이션하거나 재현하여 시스템의 동작을 평가하는 센서라고 이해를 하였습니다.)
- AAE는 실제 pose-annotation이 되어있는 학습 데이터가 필요하지 않습니다. 대신, self-supervised 방식으로 3D 모델 view를 encoding하도록 학습됩니다.
2. Related work
2.1. Simulation to Reality Transfer
합성 데이터에서 실제 데이터로 일반화하기 위한 세 가지 주요 접근법이 있습니다.
Domain Adaptation(DA)
DA는 레이블이 지정된 데이터(supervised DA) 또는 레이블이 지정되지 않은 데이터(unsupervised DA)의 일부를 사용할 수 있는 소스 도메인의 학습 데이터를 타겟 도메인에 활용하는 것을 말합니다. synthetic 이미지에서 realistic한 이미지를 생성하여 classifier, 3D pose esitmator, grasping 알고리즘을 학습하는 Generative Adversarial Network(GAN)가 unsupervised DA에 도입되었습니다. 하지만 GAN은 종종 취약한 학습 결과를 도출합니다. supervised DA는 real annotation된 데이터의 필요성을 낮출 수 있지만, 이를 완전히 제거하지는 않습니다.
Domain Randomization(DR)
DR은 다양한 self-realistic 설정(임의의 조명 조건, 배경, 채도 등으로 augmentation)에서 렌더링된 뷰로 모델을 학습하면 실제 이미지에도 일반화할 수 있다는 가설을 기반으로 합니다. [36]에서는 CNN을 사용하여 3D shape detection을 위한 Domain Randomization(DR) 패러다임의 잠재력을 입증했습니다. [13]에서는 텍스처가 있는 3D 모델의 Randomized synthetic view로 Faster R-CNN의 헤드 네트워크만 학습하면 실제 이미지에도 잘 일반화된다는 것을 보여주었습니다. [17]의 저자는 밝기와 대비를 변경하면서 MS COCO 배경 이미지위에 무작위 pose로 텍스처가 있는 3D 오브젝트 reconstruction view를 렌더링합니다.
[36] Tobin, J., Fong, R., Ray, A., Schneider, J., Zaremba, W., Abbeel, P.: Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. In: Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 23–30. IEEE (2017)
[13] Hinterstoisser, S., Lepetit, V., Wohlhart, P., Konolige, K.: On Pre-Trained Image Features and Synthetic Images for Deep Learning. arXiv preprint arXiv:1710.10710 (2017)
[17] Kehl, W., Manhardt, F., Tombari, F., Ilic, S., Navab, N.: SSD-6D: Making RGB- Based 3D Detection and 6D Pose Estimation Great Again. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1521–1529 (2017)
3. Method
AAE를 기반으로 한 새로운 3D rotation 추정 방법을 한 번 알아보겠습니다.
3.1. Autoencoders
original AutoEncoder는 이미지, 오디오 또는 깊이와 같은 고차원 데이터를 위한 차원 축소 기법입니다. 이는 encoder \Phi와 decoder \Psi로 구성되며, 둘 다 일반적으로 신경망에서 임의의 학습 learnable function으로 근사시켜주는 역할을 합니다. 학습 목표는 low-dimensional bottleneck을 통과한 후 입력 x \in R^D를 reconstruct하는 것인데, 이를 latent representation z \in R^n(n << D)이라고 합니다.

식(1)을 보면 앞서 설명했던 의미라고 이해하시면 좋을 것 같습니다. 중간의 수식을 보면 합성함수이므로 좌측에서 우측방향으로 연산이 될 것이므로 encoder → decoder로 구성되어 있는 것을 확인할 수 있고 이를 reconstruction 한 결과가 \hat x인 것을 확인할 수 있습니다. 이를 latent representation으로 \Psi(z)으로 표현한 것으로 이해하시면 되겠습니다.
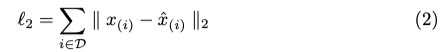
식(2)와 같이 샘플 당 loss는 단순하게 pixel-wise l_2 distance 거리의 합을 사용한다고 합니다.
이렇게 생성된 latent space는 unsupervised clustering에 사용할 수 있습니다. Denoising AutoEncoder(DAE) 에는 개선된 학습 절차가 있습니다. 여기서는 reconstruction 대상이 깨끗하게 유지되는 동안 입력 이미지 x ∈ R^D에 actificial random noise가 적용됩니다. 학습된 모델은 noise가 제거된 test 이미지를 reconstruction하는 데 사용할 수 있습니다. 그럼, latent representaion은 어떤 영향을 받는지 알아보겠습니다.
저자는 DAE는 denoise 이미지의 reconstruction을 용이하게 하기 때문에 noise-invariant하는 latent representation을 생성하게 됩니다. 이러한 학습 전략이 실제로 noise뿐만 아니라 다양한 입력 augmentation에 대해서도 invariant함을 적용한다는 것을 입증할 것이고 마지막으로 시뮬레이션 데이터와 실제 데이터 사이의 도메인 격차를 해소할 수 있을 것으로 가설을 세웁니다.
3.2. Augmented Autoencoder
Augmented AutoEncoder(AAE)의 latent representation이 encoding하는 대상과 무시되는 속성을 제어하기 위해 문제 정의를 했다고 합니다. encoding이 invariance가 되는 입력 이미지 x \in R^D에 random augmentation f_{augm}(.)을 적용합니다. 그럼 reconstruction 대상은 앞서 loss function인 식(2)는 유지하겠지만 식(1)은 아래의 식(3)과 같이 변경이 됩니다.
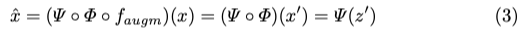
식(1)과 다른 점은 f_{augm}(.)만 추가되었고 앞서 input으로 augmentation을 주었기 때문에 notation이 살짝 변형된 것으로만 이해를 하시면 되겠습니다.
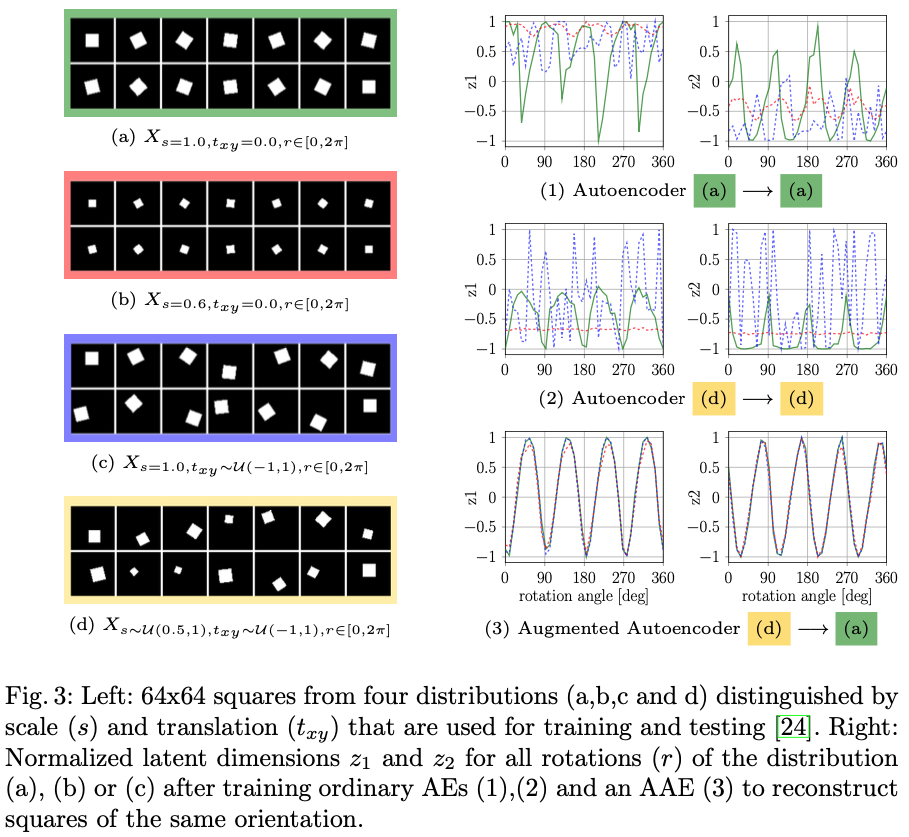
저자는 기하학적 변환에 대해 가설이 성립한다는 것을 분명히 하기 위해 그림(3)과 같은 방법을 수행하게 됩니다. 2D 정사각형을 다양한 scale, 평면 내 translation 및 rotation을 나타내는 binary 이미지의 latent representation을 학습합니다. 저자가 세운 목표는 scale이나 translation에 관계없이 2차원 latent space z \in R^2에서 평면 내에서 rotation r \in [0, 2\pi]만 encoding하는 것입니다. 그림(3)은 그림(5)의 모델과 유사한 CNN-based AE 아키텍처를 학습한 후의 결과를 보여줍니다.
그림(3)에서 고정된 scale과 translation을 의미하는 (1) 또는 random scale과 translation(2)으로 정사각형을 reconstruction하도록 학습된 AE는 rotation만 명확하게 encoding하지 않고 다른 latent factor에도 민감하게 반응하는 것을 관찰할 수 있습니다. 하지만, AAE(3)의 encoding은 방향이 일치하는 모든 사각형이 동일하게 매핑된 것으로 보아 translation 및 sacle에 invariance가 됨을 확인할 수 있을 것입니다. 또한 latent dimension에서 그림(3)에서 AAE(3)의 그래프에서 각각 주기가 f = \frac{4}{2\pi}인 shift 된 sine 및 cosine 함수와 같이 나타내는 것을 확인할 수 있습니다. 그 이유는 정사각형이 2개의 대칭 수직축을 가지고 있기 때문입니다. 즉, \frac{\pi}{2} 회전 후 정사각형은 동일하게 나타납니다. 고정된 파라미터화가 아닌 물체의 모양에 따라 방향을 표현하는 이 속성은 3D 물체의 방향을 학습할 때 대칭으로 인한 모호함을 피하는 데에 대처를 할 수 있습니다.
3.3. Learning 3D Orientation from Synthetic Object Views
앞서 기하학적 augmentation 기법을 사용하여 물체의 평면 내 회전 representation을 명시적으로 학습할 수 있음을 보여주었습니다. 동일한 기하학적 입력에 augmentation을 적용하면 부정확한 물체 detection에 대해 robust하면서도 3D CAD 또는 3D reconstruction의 전체 SO(3)에 대해서 space view를 encoding할 수 있습니다. SO(3)는 3D 공간의 모든 회전 변환을 나타내는 특수한 집합이고, 이러한 변환에 대한 정보를 토대로 회전 변환에 대한 정보를 데이터에 encoding 즉, representation을 할 수 있다는 의미로 이해하시면 좋을 것 같습니다. 그러나 encoder는 다음과 같은 문제가 있습니다.
(1) 3D 모델과 실제 오브젝트가 다름
(2) 시뮬레이션과 실제 조명 조건이 다름
(3) 네트워크가 clutter 및 occlusion을 구분할 수 없음
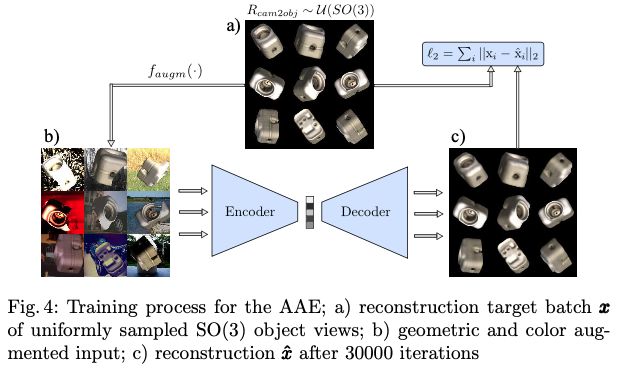
이와 같은 이유로 실제 RGB 센서의 이미지 crop을 여전히 연관시킬 수 없다고 합니다. 시뮬레이션에서 특정 실제 센서 기록의 모든 세부 사항을 따라하는 것 대신에 AAE 프레임워크 내에서 Domain Randomization(DR)을 제안하여 인코딩이 중요하지 않은 환경 및 센서 변화에 변하지 않도록 합니다. 그래서 목표를 학습된 인코더가 실제 카메라 이미지와의 차이를 관련 없는 또 다른 변형으로 취급하는 것으로 합니다. 따라서 reconstruction 대상을 깨끗하게 유지하면서 학습에 사용할 입력으로 view에 대해서 무작위로 추가 증강을 다음과 같은 방법들을 통해 적용합니다.
(1) 무작위 조명 위치와 무작위 확산 및 정반사로 렌더링(OpenGL 사용)
(2) Pascal VOC 데이터셋을 random으로 배경으로 이미지 삽입
(3) 이미지에 contrast, brightness, Gaussian blur, distortion 등 다양하게 적용
(4) 물체에 대해 Random mask 또는 black square를 사용하여 occlusion을 적용
이러한 과정을 통해 그림(4)는 T-LESS 데이터셋의 클래스 5번 오브젝트에 대한 synthetic view에 대한 학습과정의 예시를 의미합니다. 아래 첨부한 이미지가 5번 오브젝트입니다.

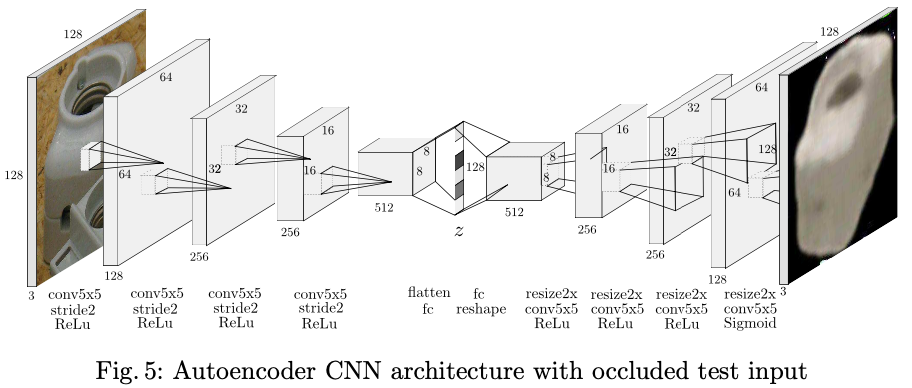
3.4. Network Architecture and Training Details
전체적인 아키텍처는 앞서 그림(5)와 같고, OpenGL을 사용하여 각 오브젝트의 20000개의 view를 카메라 축을 따라 임의의 3D 방향과 일정한 거리(700mm)로 균일하게 렌더링합니다. 렌더링을 통한 결과 이미지는 그림(4)에서 (b)의 이미지가 9개가 있지만 그 중 하나와 같이 4분할로 crop되고 그 크기가 128 \times 128 \times 3으로 resize됩니다.
3.5. Codebook Creation and Test Procedure

학습이 끝나면 AAE는 다양한 카메라 센서의 real scene에 대한 crop을 통해 그림(8)과 같이 3D 모델을 추출할 수 있습니다. decoder reconstruction의 clearity와 orientation은 encoding의 quality을 나타내는 지표입니다.
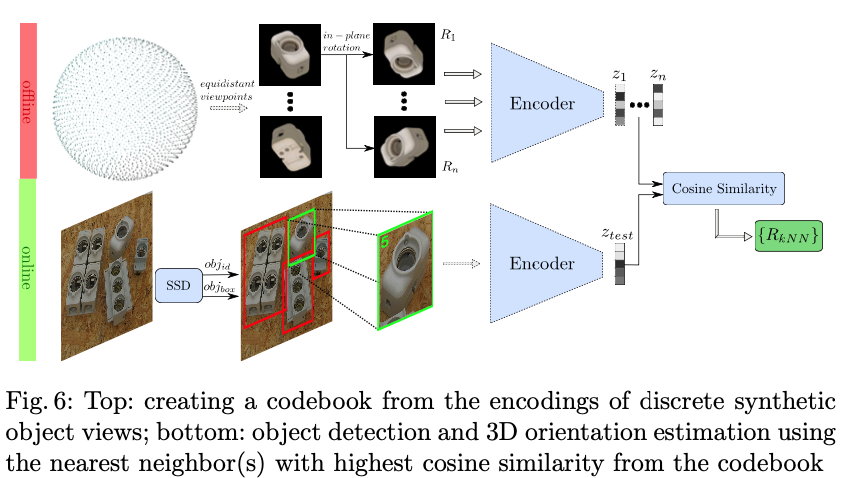
테스트 scene crop에서 3D 모델 방향을 결정하기 위해 코드북을 생성합니다. 이는 그림(6)의 top을 의미합니다. 이러한 코드북을 어떻게 생성하는지 알아보도록 하겠습니다.
- 전체 view-sphere(refinement된 icosahedron-based)에서 equidistant(등거리) viewpoint에 깔끔한 synthetic 오브젝트 view를 렌더링 함
- 각 view를 평면에서 고정된 간격으로 회전하여 전체 SO(3)를 커버합니다.
- 모든 결과 이미지에 대해 latent code z ∈ R^{128}을 생성하여 코드북을 생성하고 이미지에 대해 latent code를을 생성하고 해당 회전을 할당하여 코드북을 생성합니다(R_{cam2obj} ∈ R^{3\times3})
테스트 시 고려되는 오브젝트가 RGB scene에서 먼저 detect됩니다. 이 영역은 encoder 입력 크기에 맞게 4분할로 잘리고 크기가 resize됩니다.

식(4)와 같이 인코딩 후 테스트 code z_{test} \in R^{128}과 코드북의 모든 code z_{i} ∈ R^{128} 사이의 cosine similarity를 계산합니다.
가장 높은 similarity는 kNN(k-Nearest-Neighbor) search를 통해 결정되며, 코드북의 해당 회전 행렬을 의미하는 R_{kNN}은 3D 모델 방향의 추정치로 반환하게 됩니다. 여기서 cosine similarity를 사용하는 이유는 다음과 같은 이유가 있다고 합니다.
(1) 큰 코드북의 경우에도 단일 GPU에서 매우 효율적으로 계산할 수 있음
→ experiment에서는 equidistant에서의 viewpoint를 2562개 × 평면 회전 36회 = 총 항목 수 92232개를 사용했습니다.
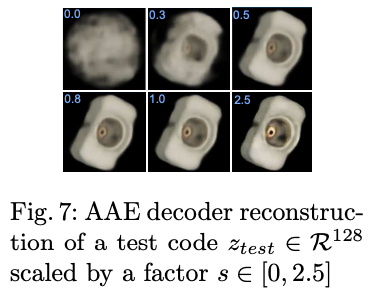
(2) 그림(7)과 같이 회전의 circular한 특성으로 인해 테스트 latent code의 크기를 조정해도 docoder reconstruction의 객체 orientation이 변경되지 않은 것을 확인함
3.6. Extending to 6D Object Detection
Training the Object Detector
VGG16을 backbone으로 사용하는 SSD를 사용하여 fine-tune 진행했다고 합니다. 또한 느리지만 좀 더 정확한 성능을 보이는 ResNet50, RetinaNet50으로 backbone을 바꿔가면서 학습을 진행했다고 합니다. 여러 개의 물체가 scene에 대해서 random orientation 및 translation으로 복제되고 bbox annotation이 그에 따라 조정된다고 합니다. AAE의 경우, 검은 배경이 Pascal VOC 이미지로 대체됩니다. 600만 개의 scene으로 학습하는 동안 다양한 색상 및 기하학적인 augmentation을 적용합니다.
Projective Distance Estimation
카메라에서 오브젝트 중심까지의 전체 3D traslation을 추정합니다. 따라서 코드북의 각 synthetic object view에 대해 해당 2D bbox의 대각선 길이 l_{syn,i}를 저장합니다. 테스트에 대해서는 detect된 bbox 대각선 l_{test}와 해당 코드북 대각선 l_{syn,\max\cos}, 즉 비슷한 방향의 비율을 계산합니다. 그렇게 카메라 만들어진 카메라 모델은 t{pred, z}를 식(5)와 같이 추정하게 됩니다.
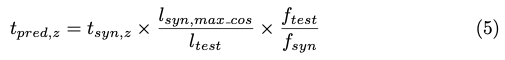
synthetic redering distance를 의미하는 t_{syn,z} 및 test sensor 및 synthetic view의focal length를 의미하는 f_{test}, f_{syn}를 사용합니다.
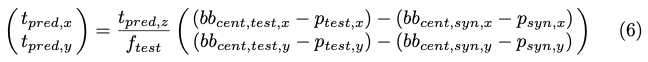
t_{pred,x}, t_{pred, y}는 앞서 구한 t_{pred,z}을 가지고 principal point p_{test},p_{syn} 및 bbox 중심 bb_{cent,test},bb_{cent,syn}을 통해 식(6)으로 나타낼 수 있습니다.
4. Evaluation
4.1. Test Conditions
대부분의 연구에서는 실제의 pose를 annotation이 되어있는 데이터를 사용하며 동일한 scene(약간 다른 viewpoint)에서 학습 및 평가를 하는 경우가 많습니다. 평면 내 회전을 무시하거나 데이터셋에 나타나는 객체 pose만 고려하는 것이 일반적입니다. 대칭인 객체에 대한 view는 종종 개별적으로 처리되거나, 무시된다고 합니다. BOP Challenge는 테스트 scene에 대한 픽셀의 사용을 금지하여 6D localization 알고리즘 간의 공정한 비교를 시도하는 것이므로 이러한 엄격한 평가 지침을 따르지만, scene에 어떤 물체가 존재하는지 알 수 없는 경우 6D detection이라는 더 어려운 문제를 처리해야 하는 문제가 발생하게 된다고 합니다. T-LESS 데이터셋에서 특히 어려운데요. 해당 데이터셋 같은 경우는 물체가 매우 유사하기 때문입니다.
4.2. Metrics
Visible Surface Discrepancy(err_{vsd})는 ambiguty-invariant pose error 함수로, 추정된 오브젝트의 depth surface와 GT visible depth surface 사이의 거리에 따라 결정됩니다. BOP 챌린지에서와 마찬가지로 허용 오차를 \tau=20mm, object visibility 10% 이상, err_{vsd}<0.3에서 올바른 6D pose로 취합니다. ablation study에서는 error_{vsd} vs. recall 즉, 곡선 아래의 영역을 나타내는 AUC_{vsd}도 리포팅합니다.
4.3. Ablation Studies
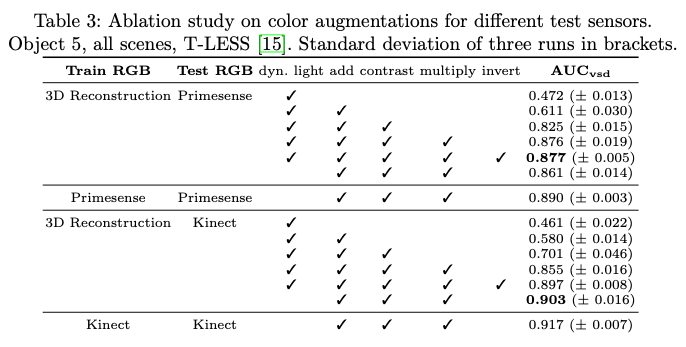
AAE만 평가하기 Primesense 및 Kinect RGB scene crop의 T-LESS 데이터셋에서 5번 오브젝트에 대한 3D 방향만 예측합니다. 표(3)을 보면 다양한 입력에 대해 augmentation의 영향을 보여줍니다. 텍스처가 없는 오브젝트의 경우 색상에 대한 채널이 반전되어도 합성 색상 정보에 overfitting 되는 것을 방지할 수 있으므로 이점이 있는 것으로 보입니다. 또한 무작위 Pascal VOC background 및 augmentation과 함께 T-LESS에서 제공되는 실제 오브젝트 영상을 사용한 학습은 합성 데이터를 사용한 학습보다 약간 더 나은 성능을 제공합니다.
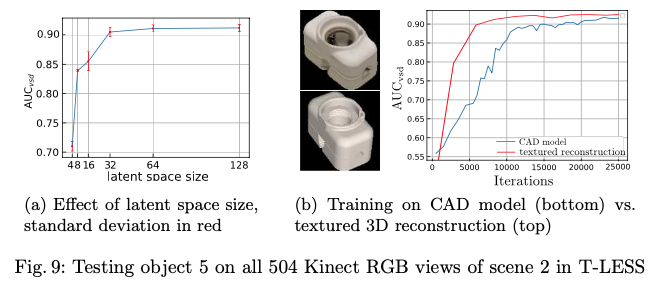
그림9(a)는 다양한 latent space 크기가 3D pose 추정 정확도에 미치는 영향을 보여줍니다. dim=64에서 성능이 saturation되기 시작하는 것을 볼 수 있습니다. 그림9(b)에서는 Domain Randomization(DR)이 텍스처가 없는 CAD 모델에서도 일반화가 가능하다는 것을 보여줍니다.
4.4. 6D Object Detection
먼저 2D detection, 3D orientation estimation 및 projective distance estimation으로 구성된 단일 RGB에서의 결과를 리포팅합니다.
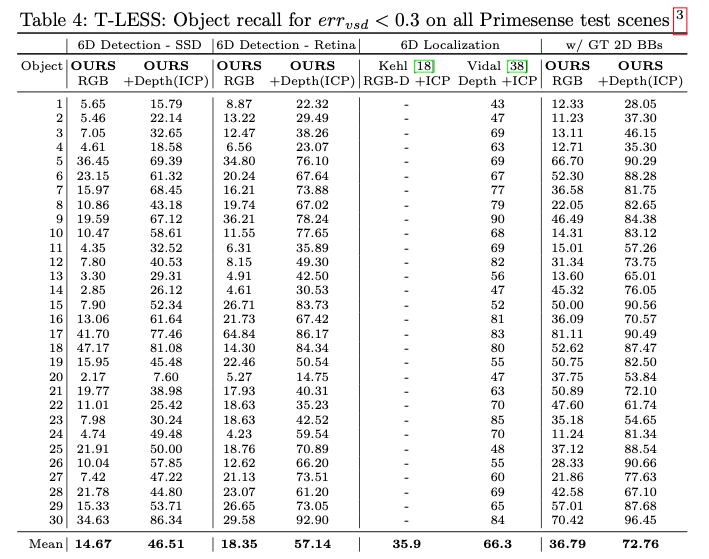
표(4)는 pose ambiguty가 많이 포함된 T-LESS 데이터셋의 모든 scene에 대한 6D detection 평가를 보여줍니다. 표(4)의 오른쪽 부분은 GT bbox를 사용한 결과로 pose 추정 성능의 상한선을 보여줍니다.
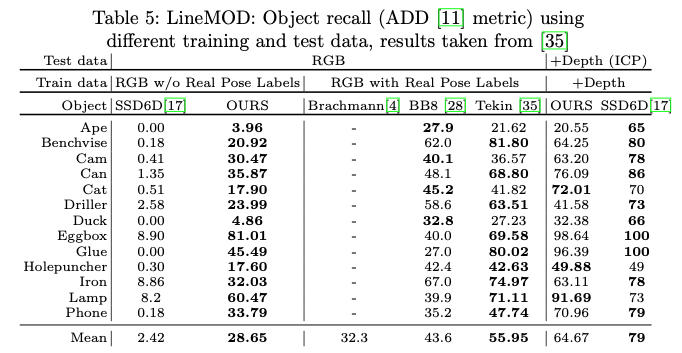
표(5)에서는 다른 방법들과 LINEMOD 데이터셋에서 성능을 비교한 표입니다.
5. Conclusion
3D 모델의 synthetic view로만 학습하면서 다양한 RGB 센서에서 robust한 3D 오브젝트 방향 추정을 가능하게 하는 새로운 Autoencoder(AE) 아키텍처의 self-supervised 학습 전략을 제안했습니다. AE에 기하학적 및 색상 입력에 대해서 augmention에 대해서 revert 하도록 유도함으로써 3D 오브젝트 방향을 구체적으로 encoding하고, 합성 이미지와 실제 RGB 이미지 간의 상당한 도메인 갭에 대해서도 invariance하며, 대칭인 오브젝트 view에서 pose ambiguty를 본질적으로 고려하는 representation을 학습합니다. 이러한 접근 방식을 기반으로 pose에 대한 annotation이 없는 경우에 대해서 적합한 6D object detection을 위한 real-time(42FPS) RGB-based 파이프라인을 만들었습니다.
Autoencoder를 어떻게 사용하였는지 궁금했었던 논문이라 한 번 읽어보았는데, 지금 보면 성능은 그렇게 뛰어난 편은 아니지만 이러한 AE라는 것을 어떻게 적용하였는지, 또 어떤 건지에 대해 한 번 알아볼 수 있었던 논문이었기 때문에 흥미로웠습니다. 이상으로 리뷰 마치겠습니다.
감사합니다.
좋은 논문 리뷰 감사합니다.
해당 기법이 6d pose를 위한 자기지도 학습이라기엔 주어져야하는 정보가 생각보다 많아서 좀 아쉬운 점이 있는 것 같네요.
몇가지 질문드리자면
1. Viewpoint 2562개 × 평면 회전 36회 = 총 항목 수 92232개의 정확한 기준이 궁금합니다.
2. 카메라와의 거리값은 2d detector (e.i. SSD)의 성능에 의존된 결과가 나올 것으로 보이는데 맞나요?
2-1. 또한 synthetic camera info (focal length, principal point)는 어떻게 구하는 것 인가요?
3.현 트렌드도 코드북을 만드는 방식이 대세인지 궁금합니다.
안녕하세요, 김태주 연구원님.
1. 정확한 기준은 supplymentary에도 나와있지 않아 정확한 답변을 드리기 어렵습니다. 하지만, 크기가 92232 x128의 코드북을 사용하는 것을 보아 연산량 측면에서 저자가 주장하는 효율성을 보여주기 위해 최대한 많은 정보를 담은 게 아닌가 하는 주관적인 생각입니다.
2. 네 맞습니다. 식(6)에 따라 bbox 결과에 따라 성능이 다를 것으로 보입니다.
2-1. simulator 내에서 가상의 센서를 사용하게 될텐데 해당 센서에 대한 parameter가 주어지는 것으로 알고 있습니다.
3. 제가 많은 논문을 읽어본 게 아니지만, 이렇게 코드북을 구성하여 pose를 추정하는 것은 처음 접하는 논문이었습니다.
좋은 리뷰 감사합니다.
depth map을 사용할지를 필요에 따라 결정한다고 하셨는데, 이는 사람이 결정하는 것인가요?? 필요하다는 것을 알고리즘적으로 결정하는 것인지 궁금합니다.
또한, 이미지에서 방향으로의 one-to-many 매핑을 피할 수 있다고 하셨는데, 이는 이미지로부터 여러 방향으로 예측이 되는 문제를 피할 수 있다는 것으로 이해하였습니다. 그렇다면 latent representation에 방향 정보가 one-to-many 매핑이 되는 것은 아닌지 궁금합니다.
안녕하세요, 이승현 연구원님.
1. optional 파트를 물어보시는 걸로 이해를 하였습니다. 제가 읽어보았을 때 사용자의 필요에 따라 사용하는 것으로 이해를 하였고, 논문의 저자도 Depth 정보로 refinement를 수행할 수 있도록 설계를 한 것으로 알고 있습니다.
2. 이승현 연구원님 말씀대로 물체의 회전을 표현하는 방식이 quaternion인 경우에도 같은 회전을 나타내는 여러 가지 quaternion 표현이 있을 수 있습니다. 독립적인 표현을 학습으로 사용하기 때문에 latent representation 측면에서는 one-to-many로 매핑이 될 것 같습니니다.
감사합니다.