Abstract
6D Pose Estimation은 고품질의 CAD 모델에 의존도가 높다는 문제가 있어 많은 수의 instance로 확장이 어렵다는 한계가 있습니다. 해당 논문은 본 적 없는 unknown object에 대한 적은 수의 여러 view영상을 이용하는 방식을 통해 open-set 문제에 대한 연구를 수행하였습니다. 문제를 해결하기 위해 저자들은 주어진 view들과 query scene patch 사이의 외관과 기하학적 관계를 완전하게 파악하는 것의 중요성을 지적하고, transformer를 이용하여 dense한 RGBD prototype을 추출하고 매칭하는 dense prototypes matching 프레임워크를 제안하였습니다. 또한, 다양한 외관과 shape으로 얻은 prior가 일반화에 중요하다는 것을 보이고 네트워크 사전학습을 위한 대규모 RGBD 데이터셋인 ShapeNet6D를 제안합니다.
Introduction
6D Pose Estimation은 object 좌표계에서 카메라 좌표계로의 강체의 transformation을 추정하는 것을 목표로 하며, 로보틱스와 AR 등의 application에서 중요한 task입니다.
딥러닝의 발전으로 6D Pose Estimation의 성능은 상당히 개선이 되었고, 최근 연구들에서는 기존 벤치마크에 대해 99% 정도의 높은 recall 성능을 달성하였습니다. 수치상으로는 6D Pose Estimation 문제를 해결한 것으로 보이지만, train과 test 데이터가 유사한 환경에서 촬영되었으며, 실제 동적인 세계와 차이가 있습니다. 또한, instance-level의 pose 추정에서 좋은 성능을 얻기 위해서는 CAD 모델의 품질에 의존하고, 대규모 데이터가 필요합니다. 즉, 밴치마크에 대해서는 좋은 성능을 보였으나 이를 일반화하여 실제 세계에 적용하기는 어렵습니다.
최근 제안된 category-level의 pose estimation은 동일한 카테고리 내의 새로운 object에 대해서도 pose를 추정할 수 있도록 하는 작업으로, instance-level의 작업보다 문제의 제한을 완화하는 방법론입니다. 그러나 category-level의 작업도 close-set이라는 제한이 있습니다.
본 논문은 open-set 문제로 few-shot 방식을 이용하여 unknown object에 대해 추가 학습 없이 몇 장의 support view 이미지를 활용하여 pose를 추정하는 연구를 수행하였습니다. 아래의 Figure 1로 확인할 수 있듯 CAD 모델을 사용하지 않고 몇 장의 RGBD 이미지만을 입력으로 받아 query scene patch에서 object의 pose를 추정합니다. 이러한 연구를 통해 네트워크와 인간의 시각 시스템 사이의 격차를 줄이고자 하였고, 새로운 object를 빠르게 추가하여 활용할 수 있으므로 광범위한 실제 application 분야에 적용이 가능합니다.

본 논문에서는 인간의 경우 object의 pose를 추정하기 위해 외관 정보와 기하학적 정보를 모두 활용한다는 점에서 착안하여 dense RGBD prototypes matching 프레임워크를 제안하였습니다. transformer를 이용하여 query scene patch와 새로운 객체에 대한 view 사이의 semantic 정보와 geometric 정보를 모두 사용하고자 하였습니다. 또한 대규모 데이터셋의 다양한 모양과 외형의 prior가 네트워크의 일반화에 필수적이라는 것을 지적하며, 이를 위해 prior를 학습하기 위해 대규모 ShapeNet6D 데이터셋을 도입합니다. 랜더링된 RGB 이미지와 실제 장면 사이의 domain gap을 해결하고자 online texture blending augmentation을 도입하여 외관의 다양성은 증가시키고 cost는 낮추어 네트워크의 성능을 증가시킵니다.
본 논문의 contribution을 정리하면
- challenging한 open-set 문제를 도입하고 이를 위한 밴치마크를 제안
- 문제를 dense RGBD prototyes matching으로 공식화하고 외관과 기하학적 정보를 완전하게 활용하여 문제를 해결하는 FS6D-DPM을 소개
- few-shot 6D pose Estimation을 위해 다양한 shape과 외관을 가진 대규모 photorealistic 데이터 셋인 ShapeNet6D를 제안하고, 적은 비용으로 domain gap 없이 texture-rich objects를 포함하는 장면을 얻을 수 있는 online texture blending augmentation을 제안
Proposed Method
1. Problem Forumlation
few-shot과 domain 일반화 문제에 대한 문제 정의를 먼저 정리하겠습니다.
Few-shot 6D object pose estimation.
open-set task인 few-shot 6D pose estimation은 k 개의 support RGBD patches P = \{ p_1, p_2, ..., p_k \}가 주어졌을 때, inference시 새로운 query scene image I 에서 새로운 object의 6D pose 파라미터를 구하는 것으로 정의합니다. 기존의 close-set 문제와 비교하였을 때, 정확한 CAD 모델에 대한 의존성을 없애고, 학습된 모델이 unseen objects에 대해 일반화 가능하도록 하는 것에 집중합니다.
이러한 open-set 문제의 일반화를 위해서는 domain generalization이라는 문제도 연구되어야 합니다.
Domain generalization.
domain generalization은 학습된 모델과 실제 데이터 사이의 domain gap을 줄이는 것을 목표로 합니다. 데이터 부족을 해결하기 위해, 6D Pose Estimation 분야에 도입되었으나 close-set 문제는 real-world를 반영하는 데이터 셋이 잘 구축되어있어 연구가 적었다고 합니다. 그러나 기존 데이터 셋은 object가 제한되어있어 규모가 작지만 few-shot open-set 세팅에서는 형태와 외관의 다양성이 few-shot 6D Pose Estimation 알고리즘의 일반화 가능성에 중요한 영향을 미치므로, 댇규모 데이터가 필요합니다. 그러나, 대규모 real 데이터를 촬영하고, label을 생성하는 것에는 비용이 많이 들기 때문에 실용적이지 않으므로, 대규모 photorealistic(real은 아닌, real같은 영상) 데이터로 외관과 shape의 다양성을 학습하여 real-world로 일반화하는 것이 중요합니다. 이러한 이유로, domain generalization 문제는 few-shot 6D Pose Estimation르 연구하기 위해 중요합니다.
2. Datasets
few-shot learning을 위해서는 대규모 데이터에서의 prior를 학습하는 것이 중요합니다. object detection이나 segmentation에 대한 few-shot learning에는 ImageNet의 pre-trained 정보를 활용하였습니다. 2D vision task는 주로 RGB 이미지의 semantic한 정보를 활용하지만, few-shot 6D Pose Estimation을 위해서는 semantic한 정보 뿐만 아니라 shape에 대한 prior도 중요합니다. 그러나 기존 데이터셋은 대규모 데이터셋이 아니고, 한정된 외관 정보와 shape을 가지고 있었으므로 prior를 학습하기에 적절하지 않습니다. 따라서 본 논문에서는 다양한 shape과 외관을 가진 대규모 데이터 셋인 ShapeNet6D를 제안하였습니다.
ShapeNet6D
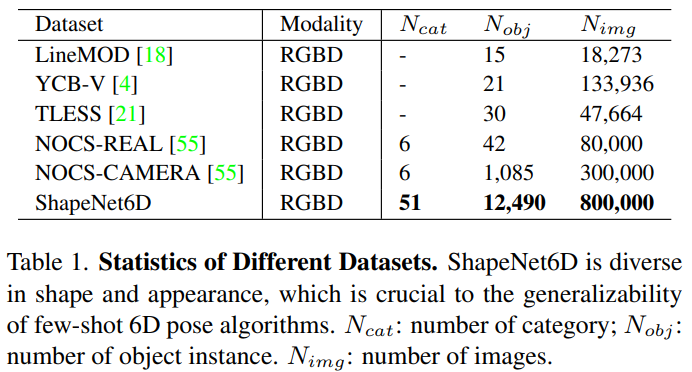
ShapeNet6D 데이터는 ShapeNet** repository의 12K 이상의 object instance의 RGBD scene 이미지를 포함하는 photorealistic 데이터 셋으로 각 scene 이미지는 instance semantic segmentation과 pose 파라미터 GT 정보를 포함하고있습니다. 6D Pose Estimation을 위해 real 데이터를 수집하는 것에는 어려움이 있으므로, 물리엔진을 이용하여 사실적인 이미지를 생성하여 대량의 6D Pose Estimation을 위한 데이터셋을 구축하였습니다. 이때, 물리엔진으로는 Blender을 이용하였다고 합니다. 렌더링을 위해 scene을 정려하고, ShapeNet의 object를 랜덤하게 선택하고, 재질과 texture도 랜덤하게 적용하여 scene 이미지를 생성하였다고 합니다. 또한, 배경의 다양성을 위해 HDRI Haven에서 물리기반 렌더링 자료를 선택하여 배경을 다양하게 하였고, 조명 조건을 생성하기 위해 랜덤하게 조명을 적용하였다고 합니다. 아래의 Table 1은 기존 데이터와 ShapeNet6D를 비교한 것으로, 카테고리와 object, 이미지 수를 모두 고려하였을 때 기존 데이터보다 다양하고 대용량임을 확인할 수 있습니다.
**Chang, Angel X., et al. “Shapenet: An information-rich 3d model repository.” arXiv preprint arXiv:1512.03012 (2015).
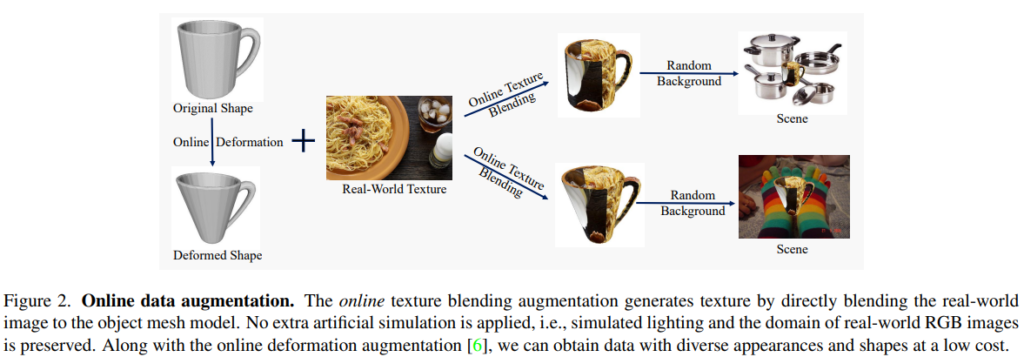
Online texture bledning
texture field는 few-shot 6D Pose Estimation에서 중요한 요소중 하나이지만, 렌더링을 위한 object의 texture와 재질을 생성하는 것에는 시간과 비용이 많이 필요합니다. 또한, photorealistic한 이미지를 생성하기 위해서는 ray tracing과 같이 시간과 연산량이 많이 드는 기술이 필요합니다. 따라서 photorealistic한 이미지는 오프라인에서 사전에 가공하고 저장하고 사용해야 하지만, 대규모 데이터를 사용할 경우 저장 공간이 많이 필요하다는 문제가 발생합니다. 저자들은 효율적으로 texture warpping을 하여 사실적인 이미지를 생성하기 위해 online data augmentation 방식을 제안하였습니다.
online- data augmentation 방식은 다음과 같습니다. 우선 mesh를 unwarpping하여 UV map(texture map)을 얻습니다. 각 픽셀의 UV 좌표를 결정한 다음, MS-COCO에서 무작위로 샘플링한 texture map을 적용하여 온라인에서 다양한 texture를 가진 이미지를 구할 수 있습니다. 이때, online shape deformation도 결합하여 외형(shape)도 다양하게 데이터를 생성할 수 있습니다. 아래의 Figure 2가 online-texture bledning 방식입니다.
3. FS6D-DPM
Preliminaries
- Prototypes-based few-shot learning
few-shot learning을 위해 calssification과 segmentation에 적용된 prototype 기반 알고리즘은 다음과 같습니다. 사전학습된 Siamese backbone을 이용하여 support image와 query image에서 feature를 추출하고, 추출된 support feature map에 global average pooling을 적용하여 support prototypes를 구합니다. 이렇게 구한 global average prototypes은 query 이미지에서 추출된 global feature나 dense pixel-wise feature과의 유사도를 계산하여 예측을 수행하게 됩니다. 그러나 이러한 global-to-global 방식은 6D pose 파라미터를 구하기 충분하지 않아 RGBD 이미지와 query scene patch간의 local-to-local correspondence를 구하기 위해 dense prototypes extraction module을 제안합니다.
Overview

새로운 object에 잘 일반화하기 위한 few-shot pose estimation 알고리즘을 구축하기 위해 Figure 4와 같이 상호보완적인 정보를 활용하여 support view와 query scene patch간의 seamntic 및 geometric 정보를 모두 파악하는 ㄱ서이 중요합니다. 본 파트에서는 이를 위한 dense prototypes matching 프레임워크를 소개합니다. 아래의 Figure 3에서 확인할 수 있듯 크게 3 부분으로 나뉩니다.
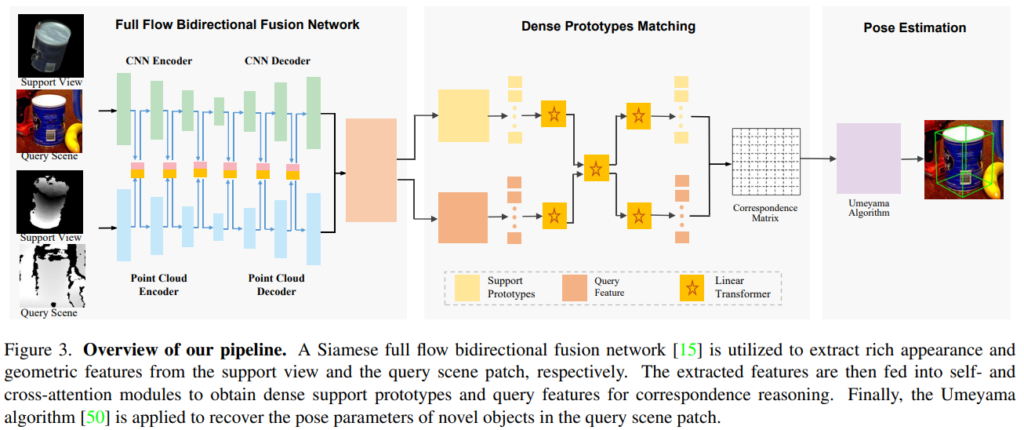
먼저, 각 픽셀/포인트에 대한 풍부한 semantic 및 geometric특징을 추출하기 위해 Siamese RGBD 특징 추출 backbone이 활용됩니다. 그런 다음, 유사도 계산을 위해 서포트 뷰에서 고밀도 RGBD 프로토타입을 추출하고 query scene patch에서 포인트별 local feature를 추출하기 위해 transformer 기반의 dense prototypes extraction network를 적용합니다. 마지막으로 dense prototypes과 scene feature 간의 correspondence를 설정한 후 Umeyama 알고리즘***을 활용하여 6D 포즈 파라미터를 추정합니다.
***Shinji Umeyama. Least-squares estimation of transformation parameters between two point patterns. IEEE Computer Architecture Letters(1991)
Feature Extraction Backbone
RGBD 이미지에서 풍부한 semantic/geometric 정보를 추출하기 위해 기존 연구인 FFB6D를 활용하였습니다. FFB6D는 양방향으로 두 정보를 계속해서 융합하는 방식으로, pose estimation에서 SOTA를 달성한 방법론입니다. (FFB6D는 본 논문을 제안한 저자가 2021 CVPR에 발표한 방법론입니다. 자세한 내용은 x-review를 참고해주세요.) 이를 이용하여 support 이미지와 query scene에서 feature를 추출하기 위한 Siamese 네트워크를 구축합니다.
Dense Prototypes Extraction and Matching
backbone에서 구한 dense한 feature를 이용하여 dense support prototypes과 query feature를 추출하여 둘의 유사도를 계산하고, 대응 관계를 구해야합니다. support view를 잘 묘사하고 대표적인 dense한 RGBD prototypes을 추출하고, query scene에서 dense한 feature를 추출하위해 point cloud의 구조적인 기하학 정보와 RGB 이미지의 semantic한 정보를 충분히 활용하는 것이 중요합니다. 또한, 두 featuer 사이의 context 정보도 중요합니다.
이를 위해 long-term-dependency를 포착할 수 있는 transformer의 성능을 고려하여 Linear Transformers를 활용합니다. Figure 3에서 확인할 수 있듯 먼저 추출된 feature map에서 self-attention을 설정하여 추출된 dense한 prototype과 dense한 query feature에 존재하는 기하학적 및 의미론적 정보를 강화합니다. 추출된 feature를 query, key, value로 보고 이를 Linear Transformer 네트워크에 입력하여 feature를 향상시킵니다. 이때, support prototypes과 query scene 사이의 context 정보를 고려하기 위해 cross-attention 모듈도 적용합니다. support prototypes에서 query scene feature에 대한 context 정보를 추출하기 위해 각 scene feature를 query로, dense한 prototype을 key와 value로 삼습니다. query scene feature에서 support prototype의 context 정보도 유사하게 구해집니다. 이렇게 구한 context 정보는 또 다른 self-attention 모듈을 이용하여 기하학적 의미론적 특징을 강화합니다.
이렇게 구한 두 feature는 local-matching 파이프라인을 따라 correspondence가 계산됩니다.
C(i,j) =<P(i),Q(j)>- P(i): i번째 prototypes
- P(i): j 번째 query feature
- < . , .>: 내적
Pose Parameters Estimation
dense prototype과 query scene 사이의 correspondence를 구한 후, Umeyama 알고리즘***을 활용하여 6D 포즈 파라미터를 추정합니다. 일치하는 prototype과 query의 쌍 \mathcal{M} = \{ (p_i,q_i), 1 <= i <= N \}이 주어졌을 때, Umeyama 알고리즘은 R과 T를 최소화하여 추정합니다.
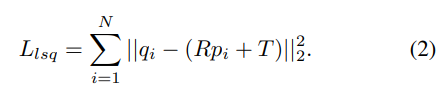
Experiments
- ADD(S)를 평가지표로 활용하였습니다.
- 데이터셋은 3개의 group으로 나누어 하나는test, 나머지 2개는 train에 사용하였습니다.
- Few-shot 6D pose estimation 문제를 위해 local 이미지 feature matching, point cloud registration, template matching의 각 SOTA 알고리즘을 basline으로 선정하였습니다.
- LoFTR
- detector-free 방식의 local image feature maching
- 고품질 matching을 위해 Transformer의 self/cross attention을 이용
- PREDATOR
- 두 scan 사이의 overlap 영역을 감지하고, feature point를 샘플링 할 때, overlap 영역에 집중하는 방법을 학습
- Template Matching
- pose estimation 문제를 discrete한 문제로 변환합니다. 이러한 방식은 CAD 모델에 의존하여 수천개의 template을 생성하고, scene에 가장 유사한 template을 찾는 방식입니다.
- LoFTR
- fair comparision을 위해 모든 방법론은 ICP를 적용하지 않았습니다.
Benchmark Results
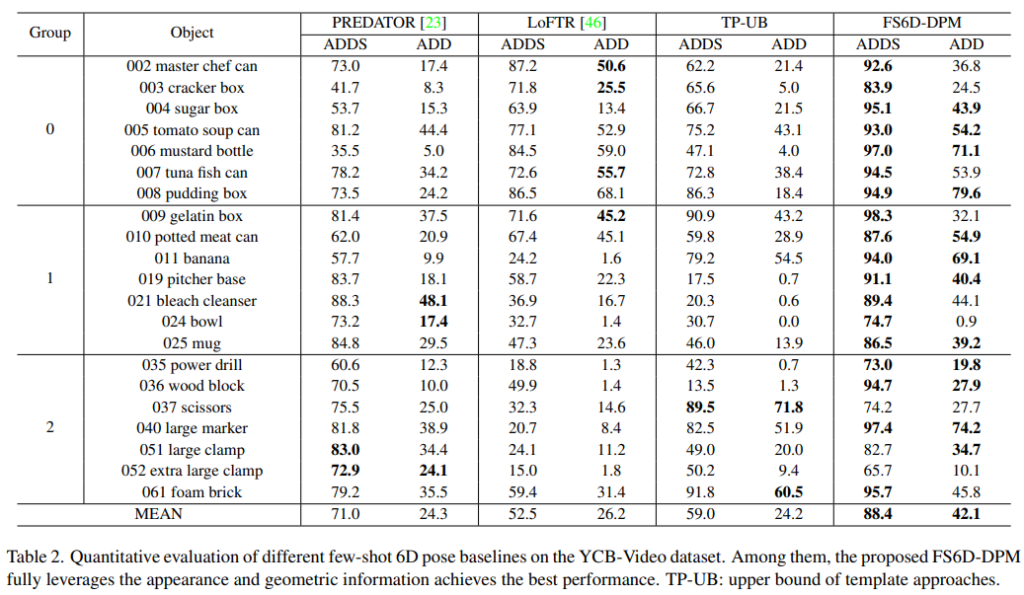
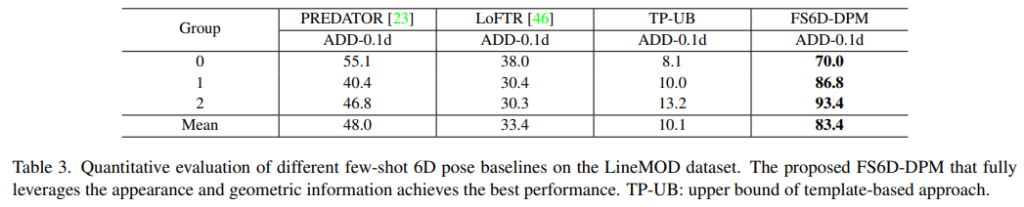
LineMOD와 YCB-Video에 대한 실험 결과는 아래의 Table 2와 Table 3에서 확인할 수 있습니다. 결과를 정리하자면, support image와 query 이미지 사이의 외관과 shape 정보를 함께 이용한 덕분에 본 논문의 방법론은 local image feature matching과 point cloud registration의 SOTA 방법론보다 크게 좋은 성능을 보였습니다.

Ablation Study
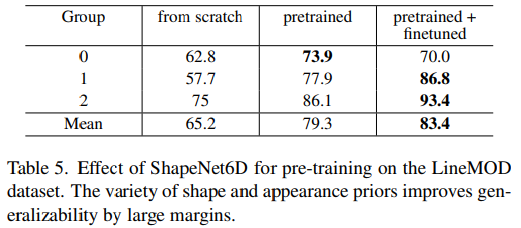
- Table5에서 볼 수 있듯 FS6D-DPM은SahpeNet6D에서 사전학습된 경우 LineMOD 데이터셋로 scratch부터 학습된 결과보다 크게 성능이 개선되었습니다.
- 이는 ShapeNet6D의 shape과 외관이 다양하기 때문입니다.
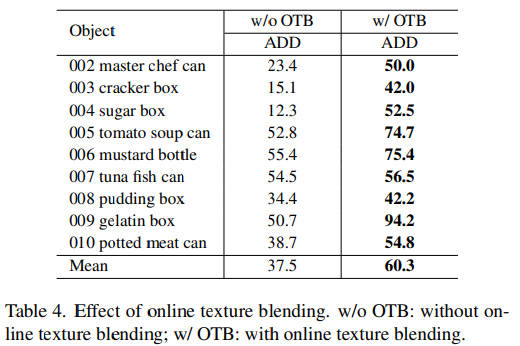
- Table4는 제안된 online texture blending 기법의 효과를 확인할 수 있습니다.
- YCB-Video에 대해 texture가 풍부한 object에서 큰 폭으로 성능이 개선되었다고 합니다.
좋은 리뷰 감사합니다!
몇 가지 질문드리고 가겠습니다.
1. Umeyama alg이 뭔지 부가적린 설명 부탁드리겠습니다. 레퍼런스 달아주셔도 됩니다!
2. Texture와 geometry 형태를 임의적으로 변경하는 ode 기법이 흥미롭게 느껴졌어요. Geometry에 대해서는 너무 강하게 변경하면 형태가 어긋나 노이즈 될 것 같은데 이에 대한 제약 조건은 제시하지 않았나요?
질문 감사합니다.
1. Umeyama 알고리즘[1]은 least-squares estimation 입니다.
[1] Shinji Umeyama. Least-squares estimation of transformation parameters between two point patterns. IEEE Computer Architecture Letters(1991)
2. 좋은 질문 감사합니다. 말씀하신대로 geometry를 너무 심하게 변형한다면 노이즈가 될 수 있다는 대에 동의합니다. 본 논문에서는 geometry를 변형할 때, 기존 연구인 FS-Net[2]이라는 논문의 방식을 적용하였고, 그 외의 어떠한 제약 조건은 제시하지 않았습니다. FS-Net을 살펴보았을 때, deformation에 제약을 주기 위해 object에 박스를 치고 박스에 맞추어 3D object에 변현을 주는것으로 보입니다.
[2] Wei Chen, Xi Jia, Hyung Jin Chang, Jinming Duan, Linlin Shen, and Ales Leonardis. Fs-net: Fast shape-based network for category-level 6d object pose estimation with decoupled rotation mechanism. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
이승현 연구원님, 좋은 리뷰 감사합니다.
이해를 돕기 위해 간단한 질문이 있습니다. 여기서 말하는 open-set과 close-set이라는 게 있는데 해당하는 각 set의 의미가 정확하게 뭔지 와닿지가 않네요. domain 측면에서 gap이 크다/작다 라는 의미인지 궁금합니다.
감사합니다.
질문 감사합니다.
close-set은 기존의 저희가 6D Pose Estimation 모델을 학습시킬 때 처럼 어떤 object와 정확히 그 object에 대한 CAD 모델을 가지고 train을 하고, 동일 object로 test를 수행하는 것이라 생각하시면 될 것 같습니다. 즉 대상의 집합이 한정되어있는 것을 close-set이라 이해하시면 될 것 같습니다.
반면 이 논문에서 제안한 few-shot learning의 경우, train과정에 본 object와 외형과 shape이 다른 데이터를 이용하여 pose를 추정하게 되는데 이러한 경우를 open-set이라 합니다.
이러한 이유로 open-set 세팅이라 실제 application에 응용 가능하다고 생각하시면 됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
한창 멀티모달 분야에 few-shot, zero-shot 붐이 불고 있어 few-shot이라는 단어에 이끌려 보게되었습니다. few-shot learning을 하기 위해서 실제로 데이터셋을 고안했다는 것에서 대단함을 느끼는데요. 이렇게 되면 나중에 unsupervised learning도 가능하게 되지 않을까..?라고 생각도 들게 되는 리뷰였네요. 간단한 질문이 있는데요 linear transformer라는 것이 정확히 무엇을 의미하는 건가요? transformer 하나를 쓰는 것을 linear transformer라고 말하는 건지 아니면 linear transformer라는 것이 따로 있는 것인지 궁금합니다.
질문 감사합니다.
본 논문에서는 Linear Transforemr를 Linformer[1]라는 방법론에서 최적화된 transformer를 이용하였다고 합니다.
[1] Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity.
안녕하세요 좋은 리뷰 감사합니다.
제가 6D pose estimation을 잘 모르는 관계로 간단하게 task에 관해 질문드리겠습니다.
우선 category-level pose estimation이 동일 카테고리 내의 새로운 object의 pose를 추정한다고 하셨는데, 이 경우에도 instance level과 같이 CAD모델이 필요하며 이때 CAD모델들이 동일한 category로 묶여 있어야 하는 것인가요?
그리고 close-set과 open-set의 의미가 궁금합니다. 단순히 unknown의 유무 혹은 CAD모델의 유무에 따라 달라지는 것인가요?
질문 감사합니다.
category-level의 pose estimation은 어떠한 object에 대한 pose를 추정할 때, 그 object와 완전히 동일한 shape과 외관 정보를 가진 CAD 모델을 이용하지 않고 category 별로 대략적인 형태를 갖춘 CAD 모델을 이용하는 것으로 알고있습니다. 그러나 방법론에 따라 CAD 모델이 pose를 추정할 때 필요할수도, 아닐수도 있다고 생각합니다. NOCS라는 희진님이 저번주에 리뷰하신 논문은 category에 대해 normalize 된 CAD 모델을 이용하고, 제가 오늘 리뷰한 논문의 경우 shapeNet6D 데이터는 CAD 모델 없이 RGBD로 구성됩니다.
open-set과 close-set은 CAD 모델의 유무라기보다, train과 test의 데이터 구성으로 이해하시면 될 것 같습니다.