이런 분들께 이 논문을 추천드립니다.
- CLIP이 도대체 뭔지 궁굼하신 분
- Multi-modal Joint Embedding에 관심이 있으신 분
- 27 페이지에 달하는 이 논문을 읽을 엄두가 안 나시는 분
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- ResNet, ViT, Transformer 등 이미지, 자연어 백본에 대한 이해
- Contrastive Learning에 대한 이해 (Metric Learning에 대해 다룬 제 블로그, 혹은 InfoNCE Loss를 다룬 TCA 리뷰)
이 논문의 후속 연구
- ImageBind [CVPR 2023] (리뷰)
안녕하세요. 백지오입니다.
열두 번째 X-REVIEW는 최근 멀티 모달 열풍의 주역(?)이라고도 할 수 있는 CLIP을 제안한 논문입니다. 굉장히 분량도 많고 내용도 어려워서 약간 피하고 있었는데, 용기를 내어 읽어보고자 REVIEW에 도전하게 되었습니다. 논문이 27 페이지로 분량이 매우 긴데, 16페이지까지는 우리가 흔히 논문에서 볼 수 있는 Method, Expermients와 같은 내용이며 그 이후로는 심층적인 분석과 한계, CLIP의 영향에 대한 고찰 등이 담겨있습니다. 때문에 X-REVIEW는 Motivation과 Method를 담은 파트 1과 Experiments들과 그 분석을 담은 파트 2로 나누어 작성해보고자 합니다.
내용이 굉장히 어렵고, 여러 모달리티와 방법론을 조합한 연구이다보니 모르는 내용이 많아 리뷰에 부족함이 많을 것 같습니다만, 댓글로 남겨주시면 아는 것은 댓글로, 모르는 것이 있다면 공부해서 다음 리뷰에라도 답변드릴 수 있도록 해보겠습니다. 그럼, 시작하겠습니다!
Introduction
논문은 기존의 SOTA 컴퓨터 비전 모델들이 학습된 데이터셋에서 사전에 정의된 class들만을 이용하여 학습되기 때문에, 새로운 task를 적용하기 위한 활용성과 일반화 성능이 떨어지는 한계를 지적하며 시작됩니다. 예를 들어, 강아지와 고양이를 구분하기 위한 데이터셋에서 학습된 모델에 사람을 분류하도록 하려면, 사람으로 라벨링된 이미지들을 데이터셋에 추가하여 다시 학습해야 한다는 것이죠. 이러한 컴퓨터 비전 모델들의 근본적인 한계를 극복하기 위해, 저자들은 인터넷에서 수집된 약 4억 개의 (이미지, 텍스트) 쌍으로 구성된 데이터셋으로 학습된 CLIP 모델을 제안합니다. 이 모델은 다양한 이미지에서 학습되었을 뿐만 아니라, 이미지와 자연어 텍스트로 학습되었기 때문에, 자연어를 통해 시각적인 개념을 다룰 수 있습니다. 이게 무엇을 의미하는지는 아래에서 자세히 설명하기로 하고, 이러한 특성 덕분에 CLIP 모델은 다양한 downstream task들에 대하여 zero-shot transfer, 즉 downstream task에 대한 데이터를 전혀 학습하지 않고 task를 수행할 수 있습니다. 저자들은 30 가지 이상의 기존 컴퓨터 비전 데이터셋에서 CLIP의 zero-shot 성능을 검증하였으며, 그 결과 CLIP은 많은 task에서 기존 모델들과 유사하거나, 심지어 더 높은 성능을 보였다고 합니다.
What’s the point of Natural Language Supervision?
이 문단은 원래 논문에 있는 것은 아니고, Multi-modal embedding, 특히 (이미지, 텍스트) 쌍을 활용하는 장점이 무엇이길래 중요한지 소개드리고자 제가 추가한 내용입니다. 논문에서는 2.1. 절의 Natural Language Supervision이 유사한 내용을 다루니 참고하시면 좋을 것 같습니다.
먼저 기존의 컴퓨터 비전 문제를 생각해보겠습니다. 예를 들어, 우리가 강아지와 고양이를 분류하는 모델을 학습시킨다고 한다면 다음과 같은 과정을 거치게 됩니다.
- 강아지와 고양이 사진을 모으고, 각각에 라벨링을 수행해줍니다. (crowd-labeled dataset)
- 각 라벨을 컴퓨터가 이해할 수 있는 원-핫 인코딩 형태로 변환합니다.
- 예를 들어, 강아지는 [1, 0] / 고양이는 [0, 1]의 라벨링 벡터가 생성됩니다.
- 모델을 (Binary) Cross Entropy Loss로 학습시킵니다.
이때, CNN은 강아지와 고양이를 분류하는데 필요한 시각적인 특징들을 low-level부터 high-level까지 학습해나갑니다.
각 CNN 필터는 뾰족한 귀의 형상은 고양이 / 둥근 귀는 강아지, 삼각형의 고양이 두상 / 둥글거나 긴 형상의 강아지 두상 과 같이 시각적인 특징들을 학습하고, 최종적으로 이러한 feature들의 활성화 정도에 따라 몇 개의 MLP layer를 거쳐 분류가 수행됩니다.
한편, (이미지, 텍스트) 쌍을 이용한 학습은 다음과 같은 방법으로 수행됩니다.
- 데이터셋은 (이미지, 텍스트) 형식으로 구성됩니다. 예를 들어, (사진, “귀여운 강아지”), (사진, “사나운 맹견”), (사진, “검은 고양이”), (사진, “강아지 상 고양이”)와 같습니다.
- 이미지와 텍스트는 각각 인코더를 통해 representation vector로 변환되고, 공통 embedding space에 선형으로 투영됩니다.
- 이때, 같은 쌍의 이미지와 텍스트는 가깝게, 다른 쌍의 이미지와 텍스트는 멀게 임베딩 되도록 학습합니다.
앞서 예시에서 보여드린 것처럼 기존의 컴퓨터 비전 모델은 모든 강아지 사진을 [1, 0]에 가까운 벡터로 만드는 반면, Natural Language로 supervision을 수행하면 각 이미지가 어떤 텍스트와 유사한 임베딩 벡터를 갖도록 만들게 됩니다.
충분히 많은 데이터에서 이러한 모델을 학습할 경우, 크게 두 가지 장점을 얻을 수 있는데요.
1. zero-shot transfer가 가능해집니다.
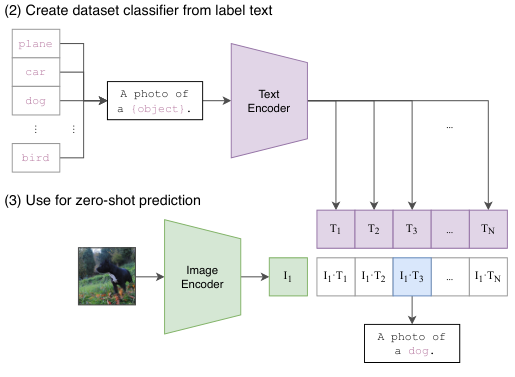
기존의 컴퓨터 비전 모델은 classification에서 학습되었다면 classification, action recognition에서 학습되었다면 action recognition과 같이 정해진 task만을 수행할 수 있었습니다. 그러나 CLIP은 입력에 대한 출력의 형태를 조절하여 다양한 task에 zero-shot transfer가 가능합니다.
예를 들어, 어떤 이미지가 입력되었을 때, “A photo of a (???)”의 빈칸을 채우도록 하면 classification 모델로 활용할 수 있고, “The guy is doing (???)”을 사용하면 action recognition으로 활용할 수 있습니다.
2. Representation 간의 관계를 학습할 수 있습니다.
앞서, classification과 같은 경우 모든 강아지 사진을 [1,0]으로, 모든 고양이 사진을 [0,1]로 학습시켰습니다. 그러나 CLIP은 강아지의 사진들도 내용에 따라, 자연어 “갈색 강아지”, “검은색 강아지”와 같은 표현들로 학습시킵니다. 이때, <강아지>라는 표현은 동일하지만 <갈색> 혹은 <검은색>의 텍스트가 다르고, 이미지도 이에 따라 차이가 있을 것인데요.
이러한 representation들을 올바르게 embedding하는 과정에서, 각 representation들이 어떤 관계를 갖는지 학습할 수 있기 때문에, 모델의 유연성이 증가하게 되고 인간이 모델을 이해하는 것도 쉬워지게 됩니다.
이와 관련하여 제가 읽은 글 중 Multi-modal neurons in Artificial Neural Nets.라는 글이 있는데, 관심이 있으신 분은 읽어보시기를 권합니다.
Introduction and Motivating Works (Related Works)
Raw text로부터 바로 학습을 진행하는 사전학습 방법들은 어찌보면 당연하게도 NLP 분야에서 많이 연구되었습니다. Autoregressive, Masked language modeling과 같이 task-agnostic한 방법론들이 computation, model capacity, data와 같은 다양한 관점에서 연구되었고, 그 결과 자연어 처리 분야에서는 “text-to-text” 형식이 일반적인 입출력 구조가 되었습니다. 대표적인 예시가 GPT인데요. GPT는 text라는 자유도 높은 출력 구조를 갖기 때문에, 추가적인 MLP layer를 설계하거나 모델을 수정하지 않고도 분류, 번역, 질의응답 등 다양한 task들을 수행할 수 있습니다.
1999년 Mori et al. 은 content based image retrieval을 이미지와 쌍을 이루는 명사와 형용사 text를 함께 사용하여 개선하는 방법을 연구하였고, Quattoni et al. (2007)은 이미지와 연관된 자막에 포함될 단어들을 분류하도록 하는 manifold learning을 통해 image representation을 더 잘 학습할 수 있음을 보였습니다. Srivastava와 Salakhutdinov (2012)는 멀티 모달 Deep Boltzmann Machine을 low-level image와 text tag feature들에서 학습시켰고, Joulin et al. (2016)은 이러한 방법들을 CNN을 통해 개선하여 image caption에 들어갈 단어를 예측하도록 하였습니다. 이 연구들은 YFCC100M 데이터셋의 이미지들의 제목, 설명, 해시태그와 같은 메타 정보들을 bag-of-words 형식의 multi-label classification task로 변환하여 사전학습된 AlexNet이 이러한 라벨들을 예측하고 representation들을 학습하게 하는 방식이었는데요. Li et al. (2017)은 이러한 방법론들을 확장하여 이미지에 대한 단어가 아닌 phrase n-grams를 예측하도록 하고, 이 방법이 다른 이미지 분류 데이터셋에서의 zero-shot transfer가 가능함을 보였습니다. 이러한 접근에 최신 모델 구조나 사전학습 기법들을 적용하여 VirTex, ICMLM, ConVIRT와 같은 방법들이 지속적으로 등장하였고, image representation을 text로부터 학습하고자 하는 시도가 계속되었다고 합니다.
그럼에도 불구하고, 이러한 연구들은 학계의 관심을 받지 못하였는데, 이는 앞선 방법론들이 target dataset에서 영 좋지 못한 zero-shot 성능을 보여줬기 때문이라고 합니다. 앞서 언급한 Li et al. (2017)의 방법은 ImageNet에서 고작 11.5%의 정확도를 보였으며, 이는 당시 SOTA 모델의 88.4% 대비 한참 낮은 수치였습니다. 때문에 Image Represenation Learning에서 Text를 이용한 supervision은 큰 관심을 얻지 못하였고, pretext task로 일부 활용되거나 JFT-300M과 같은 대규모 데이터셋에서의 사전학습이 주로 고려되었습니다.
그러나 저자들은 기존 연구들의 낮은 성능에도 불구하고, 자연어의 풍부한 표현력을 고려했을 때 text를 이용한 representation learning이 충분히 잠재력이 있다고 주장합니다. 동시에 기존 모델들의 성능이 낮은 이유를 static softmax classifier로 지적하는데요. 기껏 이미지에 대응되는 text를 예측하게 해놓고, 이를 고정된 몇 개의 단어들 중 하나를 분류하는 softmax로 풀었기 때문에, 모델의 유연성이 심각하게 제한되었기 때문에 효과가 없었다는 것입니다.
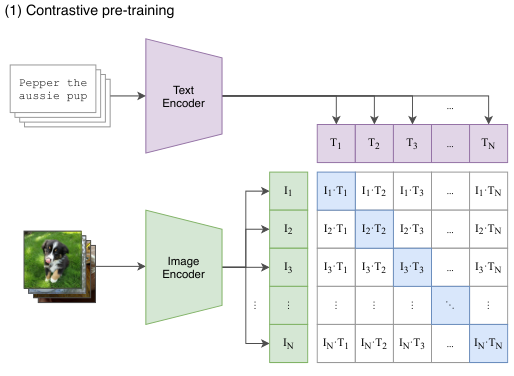
CLIP은 웹 상에서 수집된 4억 개의 (이미지, 텍스트) 쌍 데이터셋에서 학습되며, CLIP은 Contrastive Language-Image Pre-training을 의미합니다. 앞서 softmax를 이용한 기존 방법들과 다르게 어떤 이미지의 embedding과 대응하는 텍스트의 embedding이 유사해지도록, 대응하지 않는 embedding은 유사하지 않아지도록 하는 Contrastive Learning을 적용하여 이미지의 시각적인 표현과 텍스트의 언어적, 개념적인 표현이 align 되도록 하는 것이죠.
저자들은 CLIP이 OCR, geo-localization, action recognition 등 다양한 task에 zero-shot transfer 될 수 있음을 확인하였고, 30개 이상의 데이터셋에서 그 성능을 측정하여 CLIP의 우수성을 검증하였습니다. 또한, linear-probe representation learning 분석을 통해 CLIP이 기존 ImageNet 모델 대비 좋은 연산 효율로 더 좋은 성능을 보이는 것도 확인하였습니다.
마지막으로, 분석을 통해 CLIP의 zero-shot 성능이 기존의 ImageNet 방법들보다 훨씬 robust함을 확인하였습니다. 이는 얼마 전 방문한 KCCV에서 CLIP의 1저자 김종욱 박사님이 강조하신 부분이기도 합니다.
Approach
Creating a Sufficiently Large Dataset
기존의 연구들은 주로 MS-COCO, Visual Genome, YFCC100M 세 가지의 데이터셋을 활용하였는데요. MS-COCO와 Visual Genome은 좋은 품질의 crowd-labeled 데이터셋이며, 각각 대략 10만 장의 이미지를 가져 최근에는 작은 데이터셋에 속하는 반면, YFCC100M은 1억 개의 이미지로 구성되어 양은 많지만 각 이미지에 대한 메타데이터가 sparse 하고 품질이 들쭉날쭉하다고 합니다. 많은 이미지들이 “20160716_113957.jpg”와 같이 자동 생성된 제목이나 설명과 같은 데이터를 포함하고 있어, 자연어로 구성된 정보를 포함한 이미지만 걸러내면 고작 600~1500만 장의 이미지만 남는다고 하네요. 이는 사실상 ImageNet과 같은 크기이기 때문에, 충분한 양의 데이터를 확보할 수 없다고 합니다.
때문에 저자들은 인터넷상에서 이러한 데이터를 수집하여 직접 4억 개의 (이미지, 텍스트) 쌍 데이터셋을 구축하였습니다. 데이터셋이 다양한 종류의 visual concept를 포함하도록 하기 위해, 저자들은 먼저 영어 위키피디아에서 100회 이상 등장하는 단어 50만 개를 쿼리로 선정하고, 이 단어들이 포함된 텍스트로 구성된 (이미지, 텍스트) 쌍을 수집하였습니다. 그다음, 각 쿼리 별로 최대 2만 개의 쌍을 포함하도록 하여 class imbalance를 해결하였다고 하네요. 결과적으로 이 데이터셋은 GPT-2에 사용된 WebText 데이터셋과 유사한 total word count를 갖게 되었다고 합니다. 매우 방대한 양의 데이터셋이라고 할 수 있겠네요. 이 데이터셋의 이름은 WIT, WebImageText라고 합니다.
Selecting Efficient Pre-Training Method
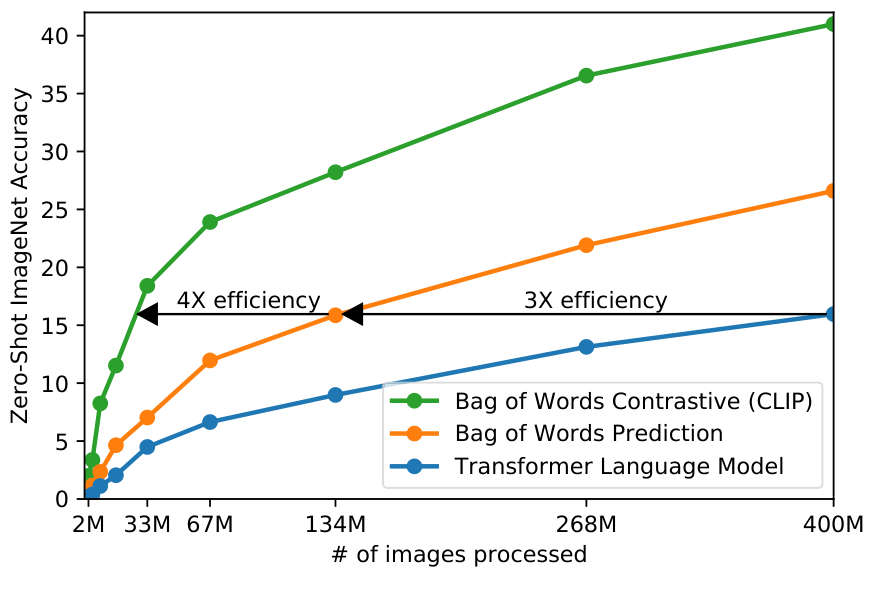
SOTA 컴퓨터 비전 모델들은 매우 많은 연산량을 요구하는데요, ResNeXt101-32x48d은 학습에 19 GPU years가 요구되며, Noisy Student EfficientNet-L2 모델은 33 TPUv3 core-years가 요구됩니다. 이게 고작 1000개의 ImageNet 분류를 위해 학습되는 자원이라니, 대규모 데이터셋의 자연어로부터 뭔가를 학습하는 것은 쉽지 않은 일 같지만, 저자들은 어찌어찌 효율적인 학습 방법을 찾아냈다고 합니다. KCCV에서 김종욱 박사님의 언급을 들어보면 굉장히 많은 실험을 진행한 것 같은데, 이런 고사양의 실험을 마구 돌려댈 수 있는 환경이 참 부럽습니다…
위 그림의 첫 방법인 Transformer Language Model은 VirTex와 유사한데, image CNN과 text transformer를 동시에 학습하여 이미지의 캡션을 예측하도록 하는 방법입니다. 그러나 이 방법은 효율적인 scaling에 있어 한계가 있었는데요, 저자들은 transformer 자연어 모델에 6천3백만 개의 파라미터를 사용하였는데, 이는 이미 ResNet-50의 두 배에 달하는 수치로 자연어 모델이 너무나 커졌다고 합니다. 이 방법은 위 그림에서 보는 것처럼 Bag-of-Words 기반 방법 대비 3배나 효율성이 떨어졌다고 합니다.
한편, Bag-of-Words 기반 방법론과 Transformer 방법론 모두 입력 이미지에 알맞는 텍스트를 예측하는 모델이었는데요. 이는 이미지에 대한 텍스트가 제목, 설명, 코멘트 등 굉장히 다양할 수 있다는 점에서 어려운 task 였습니다. 때문에, 저자들은 Bag-of-Words 방법에 Contrastive Learning을 적용하여 학습을 수행하였는데, 그림에서 보시는 것처럼 가장 좋은 효율을 보였다고 합니다.
최근 Contrastive Learning 연구들에 따라 저자들은 모델이 잠재적으로 더 쉬운 proxy task에서 학습하게 하고자, 각 단어가 아닌 텍스트 전체가 어떤 이미지와 맞는지 예측하도록 하였습니다. 이에 따라 CLIP의 구조를 의사코드로 나타내면 아래와 같습니다.

$N$개의 (이미지, 텍스트) 쌍으로 구성된 배치에서, CLIP은 $N\times N$개의 가능한 (이미지, 텍스트) 쌍 중 어떤 것이 실제 쌍인지 예측하도록 학습됩니다. 이를 위해 CLIP은 이미지 인코더와 텍스트 인코더가 생성한 실제 쌍의 embedding의 코사인 유사도가 최대화되고, $N^2-N$개의 음성 쌍의 유사도가 최소화되도록 하여 multi-modal embedding space를 학습하는데 이는 symmetric cross entropy 손실 함수로 최적화됩니다. 이러한 배치 구성과 학습 방식은 deep metric learning 분야에서 multi-class N-pair loss로 처음 소개되었으며 InfoNCE Loss로 발전하였다고 소개하고 있네요. 논문이 나올 때까지만 해도 InfoNCE가 지금만큼 많이 활용되지는 않았던 모양입니다.
사전학습 데이터셋이 워낙 크기 때문에, CLIP 학습 시에 오버피팅은 별로 걱정할 필요가 없었다고 합니다. (기만인가? 화나네요?) 저자들은 (텍스트, 이미지) 쌍에서 representation learning을 수행한 Zhang et al. (2020)의 모델에서 약간 변화를 주었는데, 저자들은 CLIP을 사전학습된 모델에서 가중치를 불러오는 대신 완전히 초기화된 모델부터 학습시켰고, representation과 contrastive embedding space 사이에 비선형 투영을 수행하는 대신 선형 투영을 수행하여 각 인코더의 representation을 multi-modal embedding space로 투영하였다고 합니다. 또한, Zhang et al. (2020)에서 사용된 텍스트에서 하나의 문장을 추출하는 text transformation function $t_u$를 사용하지 않았다. 이는 저자들이 사용한 데이터셋이 대부분 하나의 문장으로 구성되었기 때문이라고 하네요. 또한, image transformation function $t_v$는 단순화하여 random crop과 resize는 학습 시에 데이터 증강 용도로만 사용하였고, 마지막으로 softmax 값의 범위를 조절하는 temperature $\tau$는 학습 시 log-parameterized multiplicative scalar로 최적화되게 하여 하이퍼 파라미터로 사용하지 않았다고 합니다.
Choosing and Scaling a Model
저자들은 이미지 인코더로 두 가지 모델을 고려하는데, 먼저 다양한 분야에서 검증된 ResNet을 사용하였습니다. 저자들은 원본 ResNet을 개선한 ResNet-D에서 몇 가지를 수정하여 사용하였는데, Zhang (2019)이 사용한 antialiased rect-2 blur pooling을 적용하고, global average pooling을 attention pooling 구조로 전환하였다고 합니다. 어텐션 풀링은 트랜스포머 스타일의 multi-head QKV attention을 적용하였고, query는 global average-pooling 된 이미지의 feature를 사용했다고 하네요.
두 번째 모델은 안 등장하면 섭섭한 Vision Transformer (ViT) 입니다. 이 모델에서는 대부분 원본 구조를 따라갔고, combined patch and position embedding에 layer normalization을 추가로 적용하는 약간의 수정만 거쳤다고 합니다.
텍스트 인코더로는 트랜스포머 구조에 Radford et al. (2019) (GPT-2)이 적용한 약간의 수정을 거쳐 사용하였습니다. 63M-parameter 12-layer 512-wide model에 8개의 attention head를 가진 모델을 사용하였고, lower-cased byte pair encdoing (BPE) 처리된 49,152개의 vocab size를 갖는 텍스트를 입력으로 사용했다. 컴퓨팅의 효율을 위해 최대 sequence 길이는 76으로 잘랐고, 앞뒤로 [SOS], [EOS] 토큰을 붙였습니다. 또한, [EOS] 토큰의 활성화가 가장 높은 계층을 feature representation으로 여겨 layer normalize를 수행하고 multi-modal embedding space로 projection 하였다고 합니다. 또한, Masked self-attention을 적용하여 추후에 downstream task를 진행 시 language modeling을 추가 목표로 설정할 수 있도록 하였다고 하는데, 본 논문에서는 이러한 활용은 하지 않고 추후 연구를 위해 남겨두었다고 합니다.
기존의 컴퓨터 비전 연구들이 모델의 너비나 깊이를 독립적으로 조절하여 scaling을 수행한 반면, ResNet 이미지 인코더에 저자들은 Tan & Le (2019) (EfficientNet)의 접근 방식으로 이들을 동시에 조절하여 모델을 scaling 하였습니다. 텍스트 인코더의 경우, 모델의 width를 조절하여 ResNet과 연산량이 상대적으로 동등하게 증가하게 하였고, depth는 조절하지 않았는데 이는 CLIP의 성능이 텍스트 인코더에 덜 민감하였기 때문이라고 합니다.
Training
저자들은 5개의 ResNet과 3개의 ViT를 학습시켜 비교하였습니다. ResNet은 ResNet-50, ResNet-101, 그리고 3개의 EfficientNet-style의 모델들을 대략 ResNet-50의 4배, 16배, 64배 크기로 scaling 하여 학습하였고, 이들은 각각 RN50x4, RN50x16, RN50x64로 표기하였습니다. ViT는 ViT-B/32, ViT-B/16, ViT-L/14를 학습하였습니다. 모든 모델은 32 에포크 학습하였으며, Adam optimizer에 decoupled weight decay regularization을 사용하였고, consine schedule을 통해 learning rate decay를 적용하였으며 초기 하이퍼 파라미터는 ResNet-50을 1 에포크만 학습시키는 환경에서 grid search와 random search, manual tuning의 조합으로 적용했다고 합니다. 학습 가능한 temperature parameter $\tau$는 0.07에 equivalent 하게 초기화하였고, logit이 100 이상이면 clip 하여 학습이 불안정해지지 않도록 규제 하였습나다. (logit은 위 그림의 CLIP 의사코드에서 볼 수 있는 값입니다.) 저자들은 32,768의 매우 큰 배치 크기를 사용하였습니다. Mixed-precision (Micikevicius et al., 2017)을 적용하여 학습을 가속화하고 메모리를 절약하였고, 추가적인 메모리 절약을 위해 gradient checkpointing과 half-precision Adam statistics, half-precision stochastically rounded text encoder weights를 적용했다고 합니다. 실험 ResNet 중 가장 큰 크기의 RN50x64는 592개의 V100 GPU에서 18일간 학습되었으며, 가장 큰 ViT인 ViT-L/14는 256개의 V100에서 12일간 학습되었다고 합니다. ViT-L/14에 대해서는 FixRes와 같은 성능 향상 효과를 위해 더 높은 336 픽셀 해상도에서 한 에포크 추가로 사전학습을 진행하였다고 하네요. 이 모델은 ViT-L/14@336px라 표기하였다고 합니다. 실험 섹션에서 CLIP 모델은 이들 실험 모델 중 가장 성능이 높은 모델을 나타낸다고 보면 된다고 합니다.
여기까지 CLIP의 기본적인 컨셉과 방법을 알아보았습니다. 정리해보겠습니다.
- CLIP, Contrastive Language-Image Pre-training 모델은 Image와 Text 쌍을 Contrastive Learning으로 학습합니다.
- 이를 통해 유연하고 풍부한 Visual Representation을 학습할 수 있으며, zero-shot trasnfer가 가능해집니다.
- 모델이 풍부한 표현을 학습할 수 있도록 무려 4억 개의 (이미지, 텍스트) 쌍 데이터를 사용했습니다.
- CLIP의 임베딩 방식 및 구조는 다음과 같습니다.
- ResNet, ViT 기반의 이미지 인코더
- BoW, Transformer 기반의 텍스트 인코더
- 각 인코더가 생성한 representation은 linear projection을 통해 multi-modal embedding space로 투영됨
- 학습은 positive pair 간의 embedding이 유사하게, negative pair 간의 embedding이 상이하게 되도록 contrastive loss로 진행
컨셉은 생각보다 단순한데, 모델과 데이터셋의 규모가 엄청난 모델인 것 같습니다. 애초에 CLIP의 목표 자체가 이미지 속 visual representation과 텍스트(자연어) 속 representation의 상관 관계를 잡고자 하는 것인데, 이를 위해서는 어마어마한 양의 데이터가 있어야만 가능한 것이지 싶습니다.
한편, 그러한 데이터와 모델이 있다고 해도, 실제로 이 모델이 의도한 것처럼 이미지와 텍스트 사이의 어떤 관계를 잘 잡아낸다는 것도 참 신기합니다. 지금 당장 CLIP과 같은 모델을 직접 만드는 것은 불가능하겠지만, 이 모델을 잘 이해해서 문제를 멋지게 풀어보고 싶다는 생각이 듭니다.
그럼 오늘 리뷰는 여기까지 하고, 다음 리뷰에서 실험과 분석의 분석으로 찾아뵙겠습니다.
좋은 주말 보내세요!
감사합니다. ?
안녕하세요 백지오 연구원님, 좋은 리뷰 감사드립니다.
리뷰가 거의 원문 번역 수준으로 꼼꼼히 작성되어있는것 같은데, 덕분에 이쪽 분야에 생소하지만 읽을 수 있었습니다. 사전학습을 한 후 별다른 추가적인 학습 없이 바로 downstream task에 적용하는 zero-shot은 정말 흥미로운 분야인것 같습니다. 이번 KCCV에서도 zero-shot, few-shot이 인기있다는 느낌을 받았는데 이쪽 분야에도 관심을 갖고 있는 것이 좋을 것 같네요.
몇 가지 질문이 있습니다.
1. CLIP이 contrastive image pre-training으로 놀라운 결과를 보여준 것은 맞지만, 이 학습에 대해서도 image-text pair가 필요하다는것은 일종의 제약으로 작용할 수 있을 것이라는 생각이 드는데요, ’50만개의 쿼리 단어들이 포함된 텍스트로 구성된 이미지-텍스트 pair 수집’ 부분에서 어떻게 pairing했는지에 대한 언급이 있나요? 크롤링으로 쉽게 얻을 수 있는 pair인지, 아니면 이것도 또 다른 형태의 annotation인지 궁금합니다.
2. representation vector와 contrastive embedding space 사이 nonlinear projection 대신 linear projection을 이용했다고 하는데, 그 이유가 있나요? nonlinear projection을 사용하는것이 일반적으로 좋다고 알고 있는데, 그렇게 하지 않은 이유가 궁금합니다.
3. backbone model의 너비가 깊이를 종종 조정하는것으로 알고 있는데, 너비 조정은 어떻게 이루어지나요? 모듈을 추가적으로 붙이는 건가요?
4. image encoder와 text encoder를 거진 representation vector는 차원 수가 같아야 하나요?
감사합니다.
안녕하세요. 허재연 연구원님.
좋은 댓글 감사합니다. ㅎㅎ
질문에 대한 답변 드리겠습니다.
1. 논문에 데이터셋 수집 방법의 제 리뷰에 적힌 것 이상의 자세한 서술은 없었습니다. 다만 어노테이션을 수행하는 것은 아니라고 하며, 뭔가 이미지-텍스트 페어를 잘 수집하는 방법을 가지고 있을 것으로 보입니다. 이번 KCCV에서 저자이신 김종욱 박사님께 수많은 교수님이 비밀을 캐내고자 하는 질문을 드렸으나, 뭔가 디테일은 공유를 안 해주는 것 보니 OpenAI의 노하우가 있지 않을까 싶네요.
2. 제 생각에도 nonlinear projection이 더 좋을 것 같다는 직감이 드는데, 저자들은 실험해보니 linear projection이 더 좋았기 때문에 사용한다고 합니다. 아마 학습 과정에서 자연스럽게 각 modal의 feature extractor가 충분히 좋게 학습되는 것 같습니다.
3. 너비의 조정은 한 레이어의 노드 수를 늘리거나 줄이는 것이고, 깊이는 계층의 수를 조정하는 것 입니다!
4. 그렇지 않습니다. 위 의사코드를 보시면 이미지 인코더의 차원 d_i와 텍스트 인코더의 차원 d_t를 별도로 표기해주는 것을 알 수 있으며, 어차피 linear projection을 통해 차원수를 맞춰주기 때문에 차원수가 달라도 됩니다.
감사합니다!
리뷰 잘 읽었습니다. 앞으로 CLIP에 대한 detail이 궁금해지면 백지오 연구원에게 물어보면 되겠네요.
KCCV에서 CLIP을 활용한 연구들을 많이 보았는데 다들 하나 같이 얘기하는 부분이 CLIP representation도 자체적인 한계를 가지고 있다는 얘기를 많이 들었던 것 같습니다.
저자가 밝히는 CLIP에 대한 limitation에 대해서는 따로 서술된 부분이 있을까요?
안녕하세요. 임근택 연구원님.
CLIP의 전문가가 되어야 할 것 같은 댓글 감사합니다.. ?
말씀하신 것처럼 저자들도, CLIP에는 한계가 많다고 하며 아예 논문의 한 섹션을 할당해 Limitation들을 소개하고 있습니다. 이는 다음 리뷰에서 상세히 다룰 예정이나 몇 가지 미리 공유드리자면 아래와 같습니다.
1. CLIP은 zero-shot으로 기존 지도학습 기반의 SOTA와 경쟁할 수 있는 성능을 보이나, 기존 모델 대비 학습 단계에서 약 1000배의 컴퓨팅을 요구하게 됩니다. 즉, zero-shot transfer가 아직 효율적이지 못합니다.
2. 또한, CLIP은 일부 task에서는 매우 좋지 못한 zero-shot 성능을 보여주며, 학습 데이터에 전혀 포함되지 않은 truly out-of-distribution 샘플에는 낮은 일반화 성능을 보여준다고 합니다. 초대규모의 데이터셋으로 학습하여 일반화가 강한 것이 CLIP의 장점이라 생각했는데, 그래도 정말 심각한 OOD에는 아직 약한 모양입니다.
3. CLIP이 인터넷에서 수집된, 필터링되지 않은 데이터에서 학습되었기 때문에, 다양한 social bias에 취약할 수 있다고 합니다.
저자들은 전반적으로 CLIP이 많은 한계를 가지고 있으며, 특히 CLIP이 사용하는 연산량이나 데이터의 양에 비하면 성능이나 일반화 능력이 좋지 않다고 지적하며, CLIP의 강건한 zero-shot 성능을 기반으로 효율적인 few-shot learning을 수행하는 방법을 연구할 것을 제안하고 있습니다.
감사합니다!
안녕하세요. 리뷰 잘 읽었습니다.
음 예전부터 CLIP 논문을 읽어봐야지 했는데, 이번에 해당 지식이 필요하여 논문을 살펴봤다가 너무 길어서 포기했었는데,
지오님의 리뷰를 읽으니 정말 설명을 잘 해주셨네요.
조금 쉬운 질문인 것 같긴 한데, 헷갈려서 질문드리자면 CLIP의 학습 방식 요약에서 보이는 T1, T2, … TN이 Pseudo code 상 T_f = text_encoder (T) #[n, d_t]에 해당하며, 그럼 다시 T1, T2는 음… [0,d_t], [1,d_t]로 같은 고정된 d_t 크기를 가진다는 의미겠죠? 그렇다면 혹시 그 이후에 L2 Normalize는 왜 해주는지에 대한 설명이 있나요?? Image Representation과 Text Representation의 그.. 데이터 스케일 폭이 다른 점에서 기인하는지.. 그런 사소한 점이 조금 궁금하네요.
다음 주엔 V2를 다시 읽어야겠네요!
안녕하세요. 이상인 연구원님.
feature representation 간의 유사도를 구하기 위해 흔히 코사인 유사도를 사용하게 되는데, 이때 norm이 1인 unit vector의 내적을 통해 유사도를 구하는 방법이 흔히 사용되고 있습니다.
따라서 text representation과 image representation에 l2 정규화를 적용하여 unit vector로 만든 후, 내적을 수행하여 유사도를 구하는 것입니다.
감사합니다.