안녕하세요.
이번주 참석했던 KCCV 학회의 참관기를 글로 남겨보고자 합니다.
우선 오프라인 학회는 3일 간 오전 10시부터 오후 6시까지 진행되었고, 그 중 3시 반까지는 국제학회 논문을 발표하신 교수님들 또는 박사 분들의 Oral 세션으로 구성되었습니다. 3시 반부터 5시까지는 마찬가지로 약 25편 정도의 국제학회 논문에 대한 포스터 발표가 매일 이루어졌고, 이후 6시까지는 Oral 세션 또는 초청 연사, 기업 임원분들의 세미나로 구성되었습니다.
1. Oral & Poster session
1.1 Research trend
이번 KCCV의 Oral 세션 및 포스터 세션을 지켜보았을 때, 22년도 한 해 동안의 CV연구에는 여러 트렌드가 있었지만 그 중에서도 Image-Text pair 정보의 활용을 세 손가락 안에 꼽을 수 있을 것 같습니다. Task를 가리지 않고 Oral 세션을 진행하신 교수님들과 포스터를 발표해주시는 석, 박사분들께서 “정의한 문제에 대해 요즘 핫한 ‘CLIP’으로부터 representation 정보를 빌려와 활용해볼 수 있을 것 같다.”라는 이야기를 정말 여러번 들을 수 있었습니다.
물론 CLIP representation을 그대로 가져다 쓰는 것이 아니라, 현재 풀고자 하는 task에 대해 CLIP representation을 그대로 적용하면 이런이런 문제가 존재하고, 이를 변형하여 적용했더니 좋은 성능을 달성할 수 있었다는 흐름으로 연구가 진행되었죠. 저는 CLIP을 처음 접했을 때 그냥 자연어 처리 분야의 모델인가보다.. 하고 큰 관심을 갖지 않았었습니다. 하지만 이렇게나 많은 CV task에 적용되고 있는지 몰랐고, KCCV에서의 경험과 제가 주로 연구해보고자 하는 task인 Weakly-supervised Temporal Action Localization에도 CLIP을 적용한 23년도 CVPR 논문(리뷰)이 등장하며 거대 모델로부터 지식을 받아와 이를 잘 활용하는 것도 좋은 연구방향이었음을 깨달았습니다. 새로운 프레임워크에 거부감을 갖지 말라는 이병욱 박사님의 말씀이 다시 한 번 떠올랐습니다.
한편으로 나름 두려웠던(?) 것은, KCCV에서 발표한 논문들은 전부 22, 23년도에 발표된 논문이었다는 것입니다. 이는 해당 연구가 21년도, 22년도 말 쯤 이루어졌다는 것인데, 거의 1년 이상이 지난 지금 CV 연구가 어떠한 트렌드로 진행되고 있는지 잘 모르고 있다는 것이었습니다. 물론 트렌드만을 따라가며 아무 생각없이 사용하고 갖다 붙이는 것은 바람직한 방향이 아니라고 생각하기 때문에 지양해야겠지만, 지금처럼 제가 수행하는 task의 연구 트렌드만 파악하고 있는 것은 해결하고자 하는 문제점을 찾았을 때 선택할 수 있는 도구의 폭이 굉장히 좁아지는 것이라는 생각이 들었습니다.
이번 KCCV에 다녀온 뒤로 나름 제가 잘 모르는 task의 발표를 듣거나 글을 읽을 때 어느 정도 이해할 수 있는 능력이 생긴 것 같은데요, 앞으로 이를 잘 활용해 CV 내외 여러 연구 분야의 트렌드를 파악해보고자 합니다.
CLIP 이외에 제가 자주 볼 수 있었던 task level의 키워드들을 뽑자면,
- Video (Video Instance Segmentation, Frame Interpolation, Generation, Representation Learning 등)
- GAN, Diffusion을 통한 생성
- 3D Reconstruction, Editing
위 키워드는 아무래도 제가 video 분야 위주로 찾아다니기도 했고 다른 task에 대한 이해가 깊지 않아 좀 주관적일 수도 있습니다…
1.2 Poster
다음으론 제가 관심있게 보았던 포스터들 중 2가지만 정리해보겠습니다.
- BiFormer: Learning Bilateral Motion Estimation via Bilateral Transformer for 4K Video Frame Interpolation
우선 본 논문은 4K 비디오에서 Frame Interpolation을 수행하는 방법론을 제안하고 있습니다. Frame Interpolation은 만약 30FPS의 비디오를 입력받았다면 주어진 프레임 사이사이를 매끄럽게 연결하여 60FPS의 비디오를 만들어내고, 60FPS 의 비디오를 받았다면 120FPS의 비디오를 만들어내는 것입니다.
제가 해당 task의 논문에 대해 살펴본 이유는, 현재 진행하고 있는 WTAL 연구에서 RGB feature에 temporal(motion) 정보를 주입해주거나 computational cost가 큰 flow feature를 대체할 수 있는 방법을 찾고있었기 때문입니다. 해당 task에선 Interpolation 할 프레임을 찾는 과정에서 앞뒤 프레임의 motion 정보를 파악해야 하기 때문에 관심을 갖게 된 것입니다.
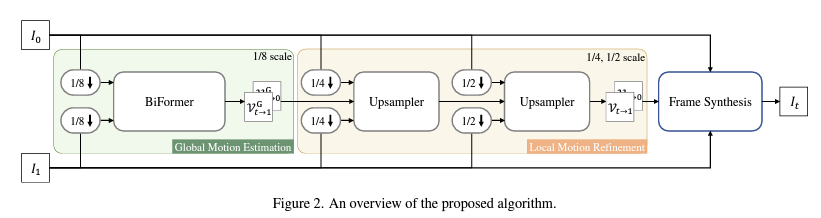
우선 위와 같은 전체 framework에서 Global Motion Estimation 부분에 집중하여 보았습니다. CNN은 local 정보에 집중하지만 4K 비디오의 경우 짧은 순간에도 수 백 프레임의 motion이 발생할 수 있다하여 Global information을 더 잘 capture할 수 있는 transformer 구조를 선택했다고 합니다.
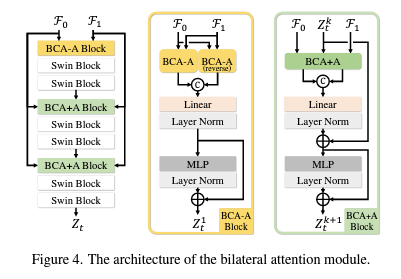
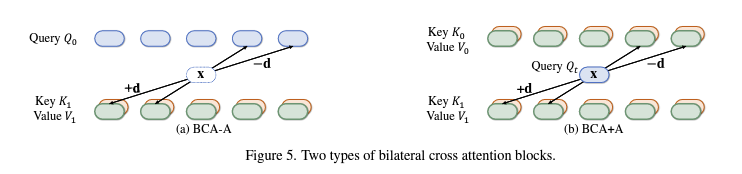
먼저 Interpolate 해야 할 대상 t번 프레임의 feature를 가지고 있지 않으니 이를 먼저 찾아야 합니다. 이를 위해 BCA-A 블록을 통해 주어진 두 프레임 0번, 1번 각각을 d만큼 window를 sliding하며 움직였을 때 가장 매칭이 잘 되는 지점을 찾아냅니다. 이후 BCA+A 블록에서는 찾아낸 중간(t번) frame feature 가 0번으로 가기 위한 motion과 1번으로 가기 위한 motion 정보를 찾아내게 됩니다. 이후 t->0 motion과 t->1 motion은 서로 반대되어야 한다는 점을 이용해 t번 프레임을 찾는다고 합니다.
사실 전날 본 논문을 살짝 읽어보고 갔는데도, 전부 이해하기엔 아직 어려움이 있네요.
- Probabilistic Prompt Learning for Dense Prediction
다음은 영상 분야에서 Dense Prediction task를 수행하는 논문입니다. 이 논문도 클래스 정보를 활용한 CLIP represenation을 가져오는데, 하나의 이미지를 결정적인 하나의 prompt만으로는 표현하기엔 어렵다는 점으로부터 시작하게 되었다고 합니다.
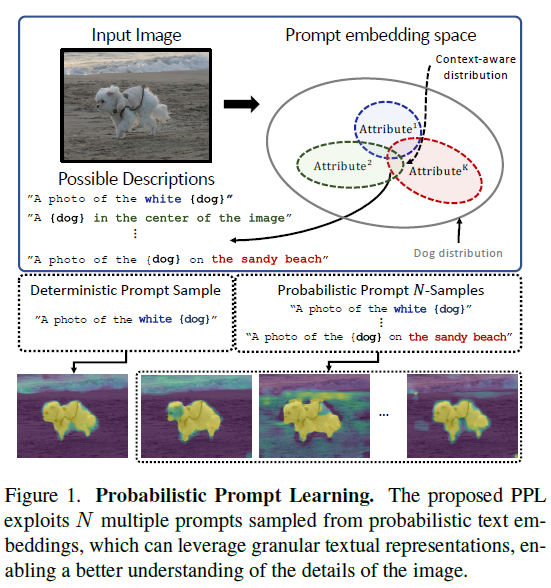
그림에서 강아지를 표현하는 문장이 여러가지가 될 수 있다는 것을 볼 수 있습니다. 그래서 한 영상에 대한 prompt를 결정적으로 하나만 모델링하는 것이 아니라, K개의 prompt를 Mixture of Gaussian(MoG)로 모델링하는 방법론입니다.
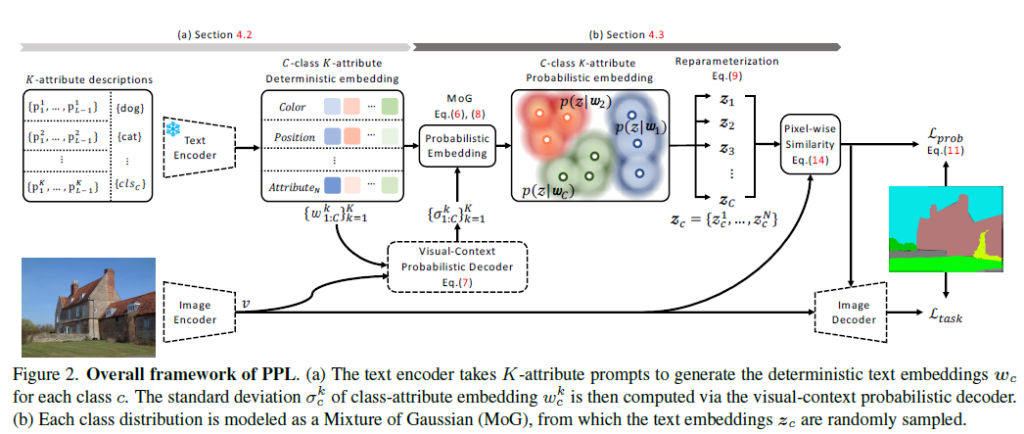
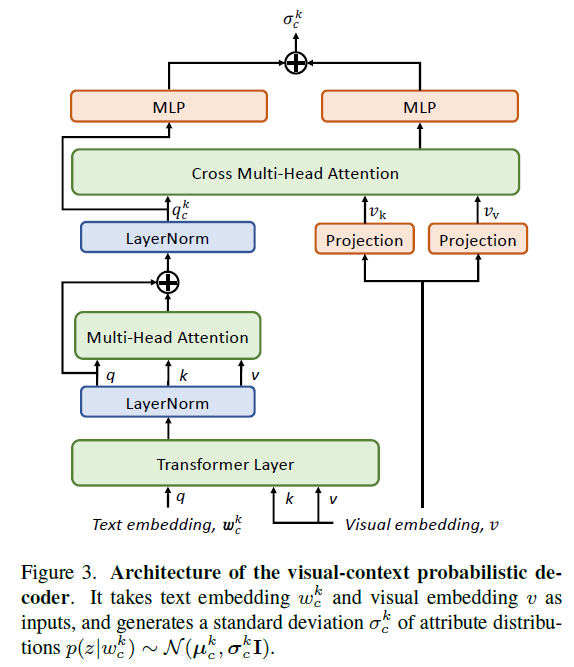
우선 총 K개의 prompt를 MoG로 모델링하여 probabilistic embedding의 평균을 얻고, 이후엔 두 모달(Image-text) 간 uncertainty를 최소화하기 위해 위 그림과 같은 decoder를 태워 분산을 얻습니다. 이후에는 방금 과정을 거쳐 얻은 평균, 분산을 갖는 MoG를 Dense Prediction에 활용하게 되는 것입니다.
연세대 손광훈 교수님 연구실에서 Probabilistic embedding을 활용해 Video Representation Learning을 수행하는 논문이 22년도 CVPR에 등장한 적 있는데, 비슷한 컨셉을 prompt learning에 적용한 것 같습니다. 본 연구를 Video-level class만이 주어지는 WTAL task에 CLIP embedding과 함께 적용해보면 좋을 것 같다는 생각이 들었습니다. 왜냐하면 비디오에 존재하는 action은 위 이미지에서처럼 같은 action임에도 굉장히 다양한 spatial-temporal 주변 정보(context)를 담고 있기 때문입니다. 결정적 embedding보다는 다양한 상황에 강인하게 action 구간을 잘 찾을 수 있을것 같다는 의미입니다.
이외에도 포스터 세션을 돌며 방법론에 대한 질문들 뿐만 아니라, 문제 정의나 분석 과정에 대한 질문도 하며 많은 도움을 받을 수 있었습니다. 포스터 세션은 매일 1시간 반씩 진행되었는데, 한 40~50분정도 지나면 대부분 사람들이 빠지면서 거의 1:1에 가깝게 저자분들께 질문하고 디테일한 이야기들을 들을 수 있어 좋았던 것 같습니다.
2. Conclusion
마지막으로 학회에서 들은 것 중 가장 기억에 남는 이야기를 적어보겠습니다.
서울대학교 주한별 교수님께서, 연구자로서 거대 모델의 급속한 발전 상황에서 어떠한 자세를 취하면 좋을지에 대해 말씀해주신 것이 기억에 남습니다. 자연어처리 분야의 누군가는 ChatGPT가 성능 좋고 따라갈 수 없는 양의 데이터로 학습했기 때문에 이 분야의 연구가 끝난 것은 아닌지, 이제 난 무엇을 연구하면 되는지 잠시 고민에 빠질 수도 있다고 말씀하셨습니다.
이는 CV 분야도 언젠가는 맞이할 수 있는 고민인데요, 교수님께서는 인생에 있어 내가 죽기전에 이 문제는 꼭 풀겠다라는 큰 목표를 잡으라고 말씀해주셨습니다. 그 문제는 현 시점에서는 말도 안되는 문제이기 때문에 그것을 죽기 전에 달성하기 위해서는 10년 내에 무엇을 달성해야 하는지, 또 그 목표를 위해서 5년 내에는, 2년 내에는, 올해에는 무엇을 이뤄내야할지 Top-Down 방식으로 연구를 수행하라고 말씀해주셨습니다. 이런 장기적 목표를 설정한다면, 거대 모델은 그 목표를 달성하는 데에 있어 오히려 좋은 도구가 될 수 있다고 말씀하셨습니다. 속속이 발전하고 있는 거대 모델을 보며 좌절하는 것이 아니라, 목표 달성을 위한 도구로서 잘 활용한다면 제 꿈이 더 빨리 완성될 수도 있는 고마운 존재로 바라볼 수도 있다는 말입니다.
교수님께서 해주신 말씀은 비단 거대 모델에 대응하는 연구자에게만 적용되는 것이 아니라, 모든 사람들이 인공지능의 발전에 대해 마음속에 가지고 있어야 할 삶의 자세라는 생각이 들었습니다. 교수님께서 말씀하신 인생의 가장 높은 목표를 잡지는 못했지만, 단기-장기적 목표가 마음속에 있다면 연구의 고뇌 속에서도 하루하루가 즐거울 것 같다는 생각이 드네요.
이전에 학회에 참석해본 경험이 아예 없었는데, 많은 점을 배우며 유익한 시간을 보낼 수 있게 해주신 교수님께 감사의 말씀 드리며 이상으로 학회 참관기 글을 마치겠습니다.