연구실에 들어온지는 2년 6개월 정도 지났는데 오프라인 학회는 이번 KCCV가 처음이네요. 처음 알았는데 KCCV가 2014년에 처음 개최될 때는 대학교에서 작게 진행하다가 국내에서 컴퓨터비전 연구들이 활발하게 늘어나면서 지금과 같은 프로그램으로 발전했다고 하네요. 학부 3학년때 코엑스에서 하던 인공지능 전시회에 처음 갔을 때는 아는게 없으니 제대로 물어보지도 못하는 그런 사람이었는데 이제는 그래도 이런 행사에 갔을 때 사람들이랑 대화도 되고 발표도 어느정도 알아먹는 수준으로 성장한 것 같습니다. 학위과정을 계속해서 이어 나간다고 하면 언젠가 저곳에서 발표를 하는 것을 목표로 하고 열심히 해야겠습니다.
우선 간단한 소감을 정리했고 KCCV 기간 동안 인상 깊게 들었던 발표들에 대해서 정리 좀 해보도록 하겠습니다.
Oral & Poster Session
[2023 CVPR] B-Spline Texture Coefficients Estimator for Screen Content Image Super Resolution
사실 논문 자체는 Super Resolution 내용이고 이해를 제대로 하지는 못했지만 발표를 듣다가 naturalness value라는 것을 알게 되었습니다.
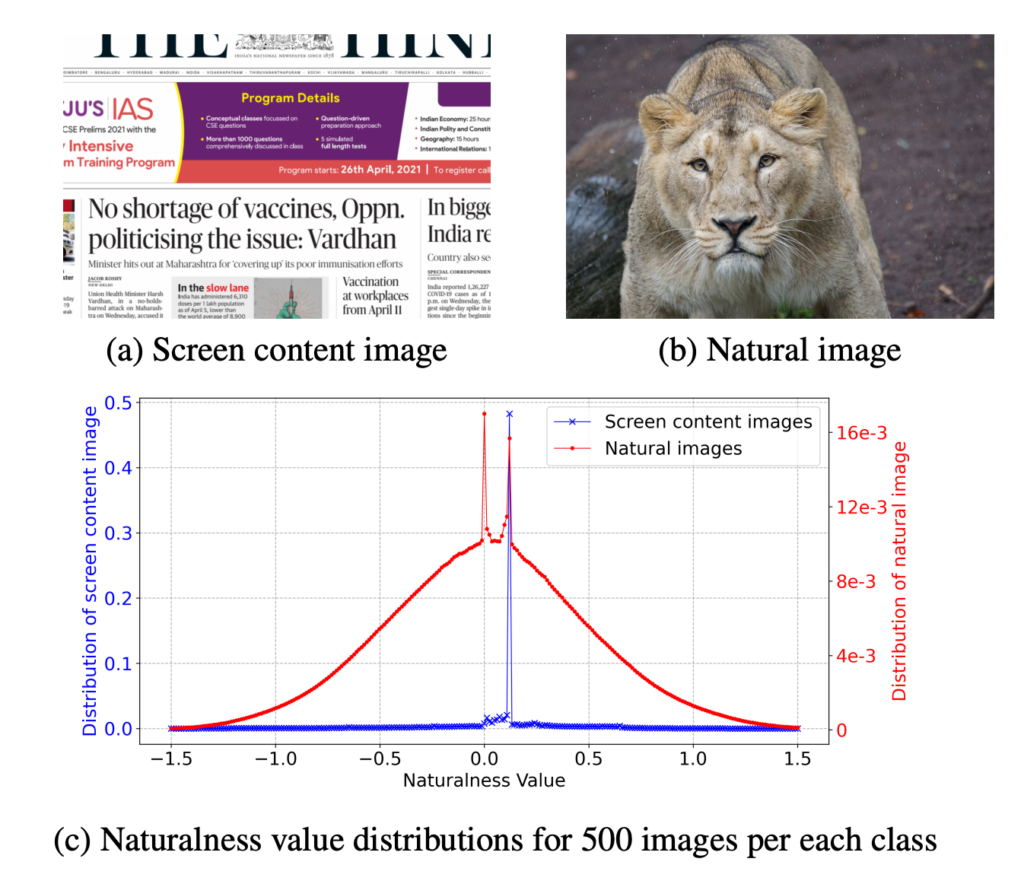
물론 본 논문에서 제안된 개념은 아닙니다. Naturalness value는 위의 그림과 같이 자연스러운 이미지는 이 값의 분포가 가우시간 분포를 따르지만 Screen content image는 그렇지 않다는 것 입니다.
저희팀에서 계속 투고 중인 VVS에서는 이러한 이미지를 filtering 하기 위해 feature 의 magnitude를 이용하여 접근하고 있는데 이러한 특성이 있다는 것을 Super Resolution 발표에서 처음 알게 됐습니다. 물론 뭐 이제 와서 VVS를 수정하거나 그럴 일은 없겠지만 이러한 개념을 알고 있으면 언젠가 또 trouble shooting 할 때 도움이 될 것 같아 정리했습니다.
[2023 CVPR] A Generalized Framework for Video Instance Segmentation
논문은 Video Instance Segmentation에 다룬 연구로 Video Instance Segmentation은 Image Instance Segmentation + Instance Tracking가 합쳐진 task라 볼 수 있습니다.
해당 연구는 benchmark data 상황에서만 연구를 하는 것이 아니라 이제는 real world 시나리오에도 대응할 수 있는 연구를 하는 것이 핵심 입니다. 이를 위해서는 비디오의 길이가 길어져도 처리할 수 있는 framework를 요구로 합니다.
하지만 이를 해결하기 위해서는 학습과 평가 사이에 발생하는 discrepency 문제를 해결해야 합니다.
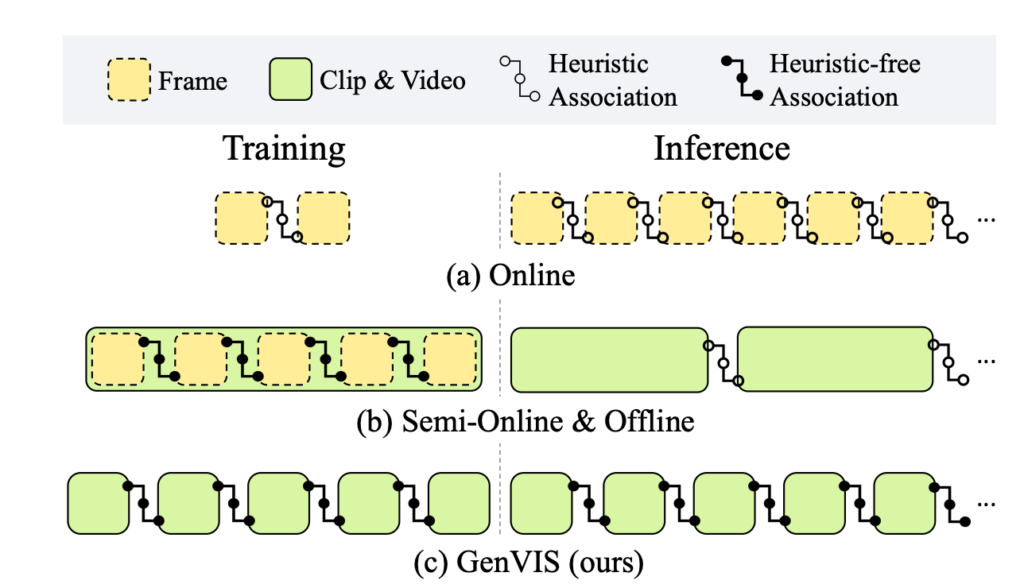
학습을 할 때는 Clip 간의 관계를 고려하고 있지 않다가 추론 단계에서 이를 요구로 하고 있으니 gap이 발생한다는 것이고 이러한 gap을 줄이기 위해 저자는 memory를 별로 요구로 하지 않으면서 다른 방법론에 쉽게 plug-and-play 할 수 있는 framework를 제안합니다.
제한된 입력 길이, 제한된 GPU 메모리 그리고 보통 고정된 사전학습 피처를 사용하는 video 분야에서 이러한 task discrepency는 자주 발생하는 문제 입니다.
개인적으로 방법론이 인상 깊어 발표가 끝나고 발표를 담당하신 김선주 교수님께 해당 연구를 temporal aciton localization 이나 Video QA 등 다른 task에 사용할 수는 없는지 질문을 드렸었습니다.
김선주 교수님 역시 비단 Video Instance Segmentation 뿐만 아니라 General한 연구를 하고 싶지만 아직은 그러지 못하고 있는 것이 실정이라고 합니다. 하지만 앞으로 연구를 계속하다 보면 결국에는 그러한 방향으로 나아가야 한다고 말씀 하셨습니다.
평소 고민하고 있던 task discrepency를 풀고 있는 논문이라 가볍게 정리해봤습니다.
[2023 CVPR] Dual-Path Adaptation From Image to Video Transformers
요즘 잘 나가는 foundation 모델을 finetune 하기 위해서는 high qual의 데이터와 연산량이 많이 필요한 상황입니다. 특히 비디오 도메인에서 foundation 모델은 더욱 복잡도가 심각해집니다.
CLIP의 저자 중 한분이신 김종욱 연구원님이 이번 KCCV에서 말씀하시길 이미지 데이터가 텍스트 데이터에 비해 가지는 데이터 복잡도가 최소 1000배 이상 차이가 난다고 합니다. 이러한 상황에서 이미지들의 temporal 모델링을 요구로하는 비디오 데이터의 경우는 아직 ChatGPT와 같은 Foundation Model이 등장하기에는 이른 시점이죠.
이렇게 복잡도 측면에서 어려운 상황이니 저자는 이미지 도메인에서 사전학습된 Transformer를 이용한 dual path를 제안합니다.
Convolution 계열의 비디오 Backbone 모델들은 거의 two-stream 방식으로 모델링이 되어 있습니다.
![논문 공부]Two-Stream Convolutional Networks for Action Recognition in Videos(3) : 네이버 블로그](https://mblogthumb-phinf.pstatic.net/MjAyMDAzMjRfNTkg/MDAxNTg1MDMwNTQ0MDM3.3CrpmM6hl6Reouhn1Zf--47IQVPNKxX-3BGxkWgEa48g.uGTKQGyHSzc9CZkwtmGSedhsH3Xq4ll3fHtEbCYD1o0g.PNG.khm159/%EC%BA%A1%EC%B2%98.PNG?type=w800)
위의 그림은 two-stream network (TSN) 이라고 해서 RGB 데이터를 사용해서 spatial stream을 형성하고 motion 정보를 담고 있는 optical flow를 사용해서 temporal stream을 만들고 있습니다.
다음으로는 Kaiming He 선생님이 참여하신 slowfast network 인데 이 역시 frame sampling rate를 다르게 주어서 비슷한 구조를 만들어버립니다.
하지만 이러한 dual path 구조는 convolution 기반의 모델에서만 연구가 되었고 Transformer 모델에서는 연구가 많이 진행되지 않았습니다.
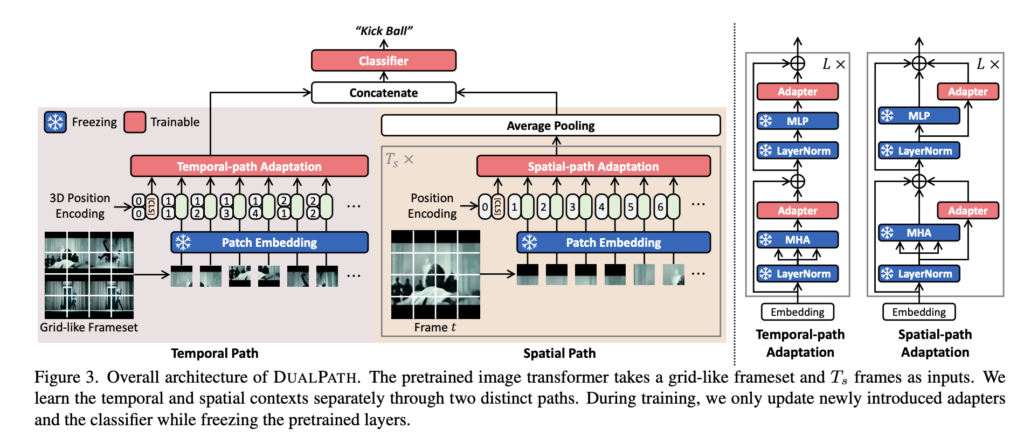
이렇게 spatial, temporal을 골할 수 있는 두가지의 path를 transformer 구조에서 사용할 수 있도록 저자는 제안하였고 이를 효율적으로 처리해줄 linear projection(adapter)만을 학습시키게 됩니다.
그래서 update가 실제로 되는 부분이 많지 않아 parameter 자체는 적지만 학습 시간이 적지는 않다고 합니다. 이게 실제로 gradient가 밑단까지 가려면 결국 일단 전달은 되어야해서 연산량 자체는 많다고 합니다.
해당 연구를 통해서 일단 linear projection 자체의 포텐셜이 굉장히 높으니 이를 잘 인지하고 있어야겠다는 생각이 들었습니다. 비단 이 연구뿐만 아니라 다른 연구에서도 원하는 embedding이나 representation을 얻기 위해 복잡한 구조가 아닌 linear projection과 정교하게 설정된 loss를 통해 최적화를 하는 느낌을 많이 받았습니다.
[2023 CVPR] Sound to Visual Scene Generation by Audio to Visual Latent Alignment
우리는 시각 정보와 음성 정보와 함께 살고 있다고 합니다. 바깥에서 길을 걷고 있으면 시각 정보뿐 아니라 음성 정보에 많이 의존하고 있습니다. 즉, 바깥에서 내가 장면을 받아들이는 데에 있어 시각뿐 아니라 음성도 중요하게 작용하는 것이죠. 본 연구는 이렇게 visual scene을 생성하는 과정에서 음성정보와 시각정보의 cross modal representation learning을 통해 해결하고자 합니다.
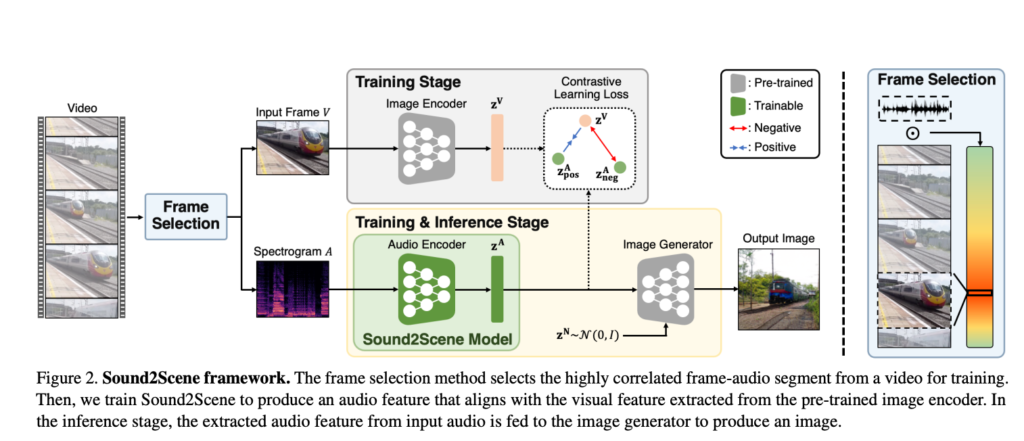
전반적인 framework 자체는 굉장히 간단했습니다. 그런데 제가 이 연구를 조금 인상 깊게 본 이유는
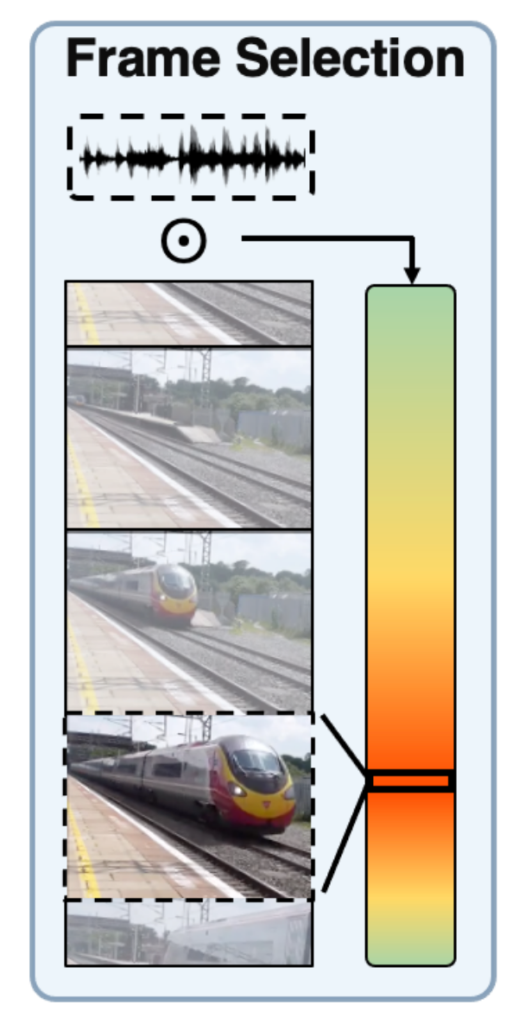
음성정보와 시각정보간의 정교한 pair를 만들어주기 위해 sound localization을 활용해 실제로 sound가 발생하는 구간을 탐지하고 이 구간에서의 pair를 고려했다고 하네요.
이 컨셉 자체가 저희팀에서 SRA라는 논문에서 foreground selection과 상당히 유사하여 인상깊게 보게 되었습니다. 도메인이 달라도 생각하는 접근법은 비슷할 수 있구나라는 것을 느꼈습니다.
[2023 CVPR] Devil’s on the Edges: Selective Quad Attention for Scene Graph Generation
마지막으로 정리할 연구는 Scene Graph Generation 입니다. 최근 제가 많은 관심을 가지고 있는 연구이기도 하고 마침 포스텍 CV lab에 계시는 조민수 교수님 연구실에서 해당 주제로 포스터 발표를 진행해서 이번 KCCV를 통해 가서 연구 설명도 듣고 궁금한 부분도 많이 물어보고 왔습니다.
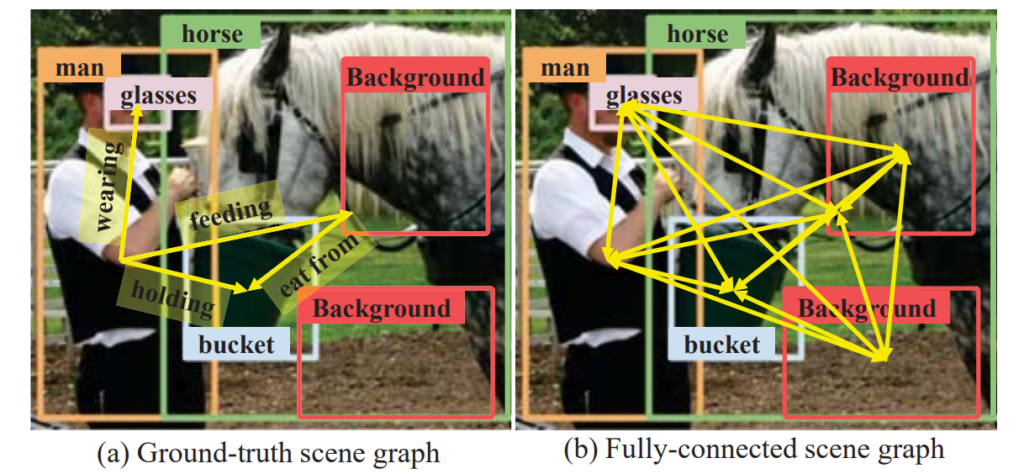
일반적인 Scene Graph Generation에서 학습을 시작하기전에 초기화 단계에서 일단 모든 node(검출된 객체)들끼리 fully connected edge를 가진다고 가정하고 이들간의 관계를 학습을 통해 update하는 구조 입니다.
하지만 실제 GT graph를 보면 이러한 edge 정보가 굉장히 sparse합니다. 즉, 우리가 모델링 해야하는 edge 관계는 많지 않은데 우리가 초기에 이를 fully connected로 가정하고 시작해버리면 학습이 굉장히 노이즈 하다는 것이죠.
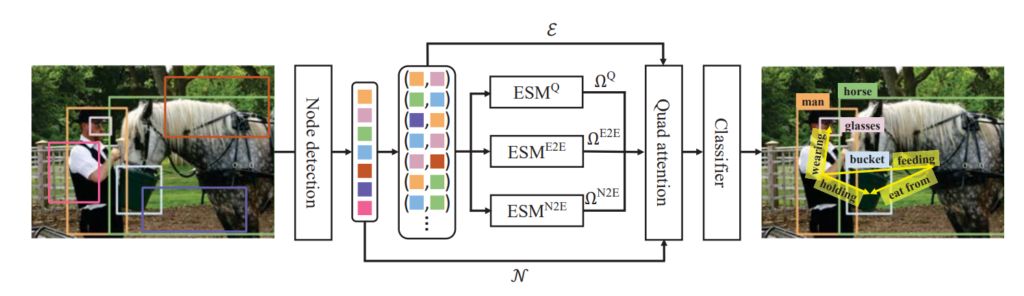
이러한 노이즈에 강인하게 작동하기 위해 저자는 edge pruning을 할 수 있는 edge selection module을 제안합니다. 자세한 구조를 물어봤는데 그냥 여기서도 Linear Projection을 사용했다고 합니다.
사실 이 연구는 제가 본 논문의 컨셉 보다는 Scene Graph Generation이라는 연구 자체의 동향에 대해서 좀 많이 물어봤던 기억이 납니다. 제가 물어본 질문들을 좀 정리해보면
- Edge feature는 랜덤하게 초기화시키는 것인지? : 두 객체의 RoI feature를 concat해서 사용한다.
- 본 framework는 Supervised Learning인지 그리고 이러한 방식 말고 Supervision을 덜 사용하는 연구들도 진행되고 있는지 : 해당 연구는 supervised learning이 맞고, 아직 self-supervised 기반의 scene graph generation은 없다고 한다. Caption 정보만을 사용하는 weakly supervised 기반의 연구는 몇개 있지만 아직 활발하게 진행되고 있지는 않다.
- Detector는 무조건 Faster RCNN 고정인지 : 거의 다 고정으로 사용한다. 요즘에는 DETR도 사용하고 있는 것 같기는 하지만 성능이 그렇게 좋은 것 같지는 않다.
사실 번호라도 물어봐서 궁금한 거 생길때마다 물어보고 싶은 심정이었지만 바빠보이시는 거 같아서 그러지는 못 했습니다..ㅎㅎ
연구 정리는 이 정도로 하고 느낀점만 정리하고 참관기를 마무리 하도록 하겠습니다.
Top-Down
서울대학교 주한별 교수님이 하신 말씀 중에 굉장히 인상 깊은 말이 있었습니다.
“문제를 Bottom-Up 방식으로 생각해서는 안된다. 나만 생각 했던 문제를 고민해야 한다.”
이런 말씀을 해주셨습니다. 저는 아직 bottom-up, top-down의 사고방식이 정확히 무엇인지는 모르겠으나 하나 분명한 것은 나만 생각하고 있는 문제 정의가 학위 과정에 필요하다는 것 입니다. 누구나 생각하고 있고 비슷한 고민을 하고 있는 것이 아니라 나만 생각하고 나만 고민하고 있는 문제를 풀어야만 나만의 경쟁력이 생기게 될 것이라는 말씀 입니다.
보통 학위과정은 박사 과정을 가정하고 얘기하기 때문에 5~7년 정도로 잡고 이 기간동안 에이~ 이게 말이 된다고? 라는 느낌의 문제를 정의하고 이를 차근 차근 하나씩 풀고 해결해야 한다는 말씀입니다.
맞는 말씀이기도 하면서 동시에 연구를 어렵게 만드는 말씀이기도 한 것 같습니다.
당장의 저는 천하제일 성능 올리기 대회에 참여하는 마인드로 문제를 bottom-up 방식으로 바라보고 있었습니다. 그리고 솔직히 이러한 태도를 당장 고치기에는 논문 실적이 급한 상황이라 현실적으로 어려운 부분도 있습니다.
하지만 학교에 더 남아 있든, 회사에 가서 연구를 계속하든 연구를 대하는 저의 태도를 언제까지나 bottom-up 방식이 아닌 top-down 방식으로 넓게 시야를 가지고 바라볼 수 있도록 천천히 성장하고 변화하도록 하겠습니다.
이번 KCCV를 통해서 많은 걸 느끼면서 동시에 많은 자극을 받았습니다. 국내 컴퓨터비전 연구 역량이 많이 올라와서 비록 국내 학회이긴 했지만 연구 동향을 파악하는데에는 부족함이 없다고 느꼈습니다. 이번 KCCV를 통해 다시 한번 우물 안 개구리라는 것을 느꼈습니다.
얼른 탑티어 논문 하나 붙여버리고 해외 학회도 나가보고 싶네요. 연구 열심히 해야겠습니다.
이상으로 참관기 작성 마무리 하도록 하겠습니다.