제가 이번에 작성할 내용은 KCCV 2023 참관기입니다. 2021년에 온라인으로 KCCV에 참여하였는데, 그때 당시에도 새로운 분야에 대해 알게 되어 흥미로웠는데, 이번에도 새로운 분야들을 많이 알게 되었습니다. 제가 학회에 참관하며 처음 알게 된 분야들이나, 기억에 남는 논문들을 간단하게 소개하고, 후기 순으로 작성하겠습니다.
Language와 vision의 융합
이번에 학회에 참관하며 느낀 것은, language 분야와 비전이 합쳐진 연구가 굉장히 많다는 것이었습니다.
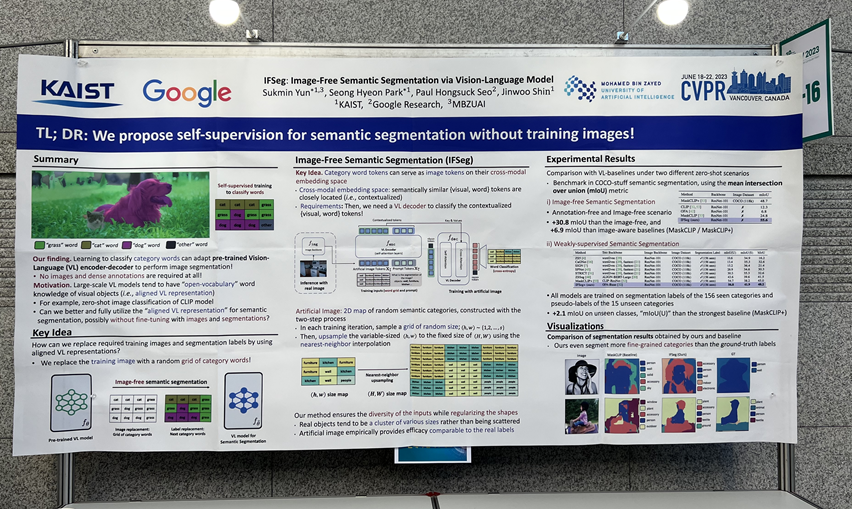
그중 가장 기억에 남는 text 융합 연구는 text와 이미지가 embedding space에서 align이 맞다는 가정하에 text의 token을 이용하여 semantic segmentation을 수행하는 IFSeg라는 연구입니다. token을 이용하여 artificial 이미지를 생성하여 모델을 학습하였다고 합니다. 이 포스터를 보며‘이게 가능한가?’하는 생각이 많이 들었습니다.
Attention 기법의 응용

해당 논문은 point cloud에 맞는 새로운 attention 방식을 제안한 논문으로, global한 관계를 포착하지 못하는 local attention과 모든 point들과 연산해야 하므로 cost가 너무 큰 global attention 방법론의 문제를 해결하기 위해 self-positioning attention이라는 attention 방법을 제안하였습니다. 근접한 비슷한 파트에서 대표하는 지점들을 구하고, 그 지점들과 각 point의 관계를 구하는 방법론으로, 위의 그림에서 잘 안보이지만 오른쪽의 그림을 보면, 결론적으로 대표하는 지점들이 object마다 의미론적으로 동일한 부분에 있다는 것(빨간점을 보면, 다른 형태의 의자이지만 동일한 부분인 의자의 판 부분에, 다른 형태의 비행기이지만 날개 부분에 위치)을 통해 저자들이 제안한 방법론의 타당성을 보인 논문입니다.
3D(4D) human mesh
KCCV에서 3일차에는 이미지로부터 사람에 대한 mesh를 reconstruction하는 것을 주제로 하는 연구가 많았습니다. 그중 오전에 발표하신 Angjoo Kanazawa 교수님의 SLAMHR는 비디오를 이용하여 3D human mesh를 생성하는 연구로, 2D에서는 해결하기 어려운 occlusion 문제를 video를 통해 해결할 수 있었다고 합니다.
이 외에도 다양한 연구를 접해볼 수 있어서 좋았습니다.
후기
처음 KCCV 발표를 들었던 이전에 비해서는 알아들을 수 있게 된 내용이 많아 뿌듯함이 있었지만, 여전히 낯선 분야는 생소하고 어렵게 느껴졌습니다. 그래도 이런 방식으로라도 다른 분야에 대해 접해보아야 다른 분야를 통틀어 흐름을 알 수 있지 않을까 합니다. 이번 KCCV에서 연구 흐름을 키워드들로 흐름을 정리해보면 language 분야의 통합, Defusion, self-supervised, nerf 인 것 같습니다. 이미 알고 있던 트렌드이기는 하지만, 학회를 통해 그 의미가 조금 더 와닿은 것 같습니다.
또한 KCCV 패널 디스커션이 가장 인상깊었습니다. 해당 세션을 통해 language와 다르게 vision 분야에서 AGI를 구축하기 어려운 이유에 대한 생각을 들을 수 있었습니다. 그중 평소에 AGI가 생긴다면 모델이 정말 이해하고 있는지를 어떻게 검증할 수 있는 지에 대한 생각하지 않아서 그런지, 주한별 교수님이 language의 경우 모델이 이해를 하고있는 지 대화를 하면 이를 이해할 수 있지만, vision은 이를 확인하기 위해서는 로보틱스 분야와 합쳐 장면을 이해하는 지 확인해야 한다는 것이 기억에 남습니다. 또한, 임화섭박사님이 컴퓨터비전의 역량에 대해 융합이라 생각한다고 하신 것이 기억에 남습니다.