안녕하세요, 열번째 x-review 입니다. 이번 논문은 ICCV 2021에 게재된 Group-Free Object Detection via Transformers라는 논문으로 3D 데이터인 포인트 클라우드로 기존의 그룹화를 하지 않고 detection이 가능한 모델을 제안한 논문 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
3D Object Detection의 경우 입력으로 포인트 클라우드를 받게 되는데, 포인트 클라우드의 irregular하고 sparse한 특성 때문에 2D detection의 방법론을 그대로 사용하기에는 어려움이 존재합니다. 당시 이러한 관점에 대한 연구 결과로 raw level의 포인트 클라우드를 직접적인 입력으로 사용할 수 있게 되었지만 이전 방법론들에서는 포인트들을 그룹화하는 단계를 통해서 object인 것 같은 후보로 포인트 그룹을 할당하였고, 각 포인트 그룹에서 object의 특징을 추출하여 detection을 수행하였습니다. 예를 들어 VoteNet은 center point를 공유한다고 판단되는 포인트들을 voting하여 그룹화를 진행하였습니다. 물론 이러한 hand-crafted grouping 방식 역시 3D Object Detection에 적합하지 않다고 할 수는 없으나, 저자는 실제 scene에서 물체의 다양성과 복잡성의 정도를 고려해보았을 때 그룹마다 잘못된 포인트가 할당될 수 있음을 지적합니다.
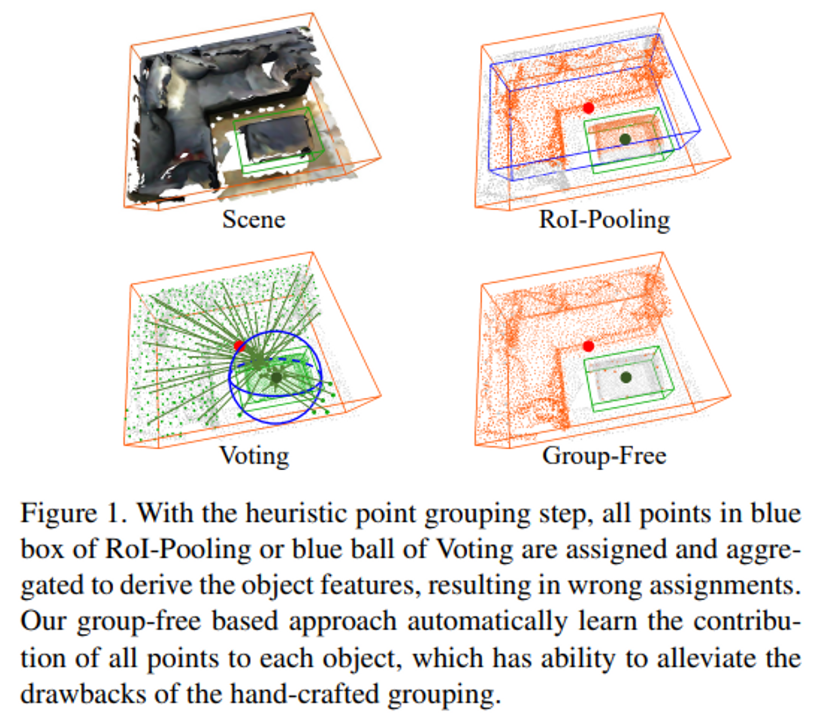
실제로 ROI-Pooling이나 Voting으로 만들어진 포인트 그룹을 보면 테이블에 속해있어야 하는 포인트가 소파의 포인트 그룹에 같이 할당이 되어있거나, 테이블에 해당되는 포인트들이 소파의 center를 기준으로 진행되는 voting에 포함되어 같이 그룹화가 되는 등 실제 객체와 다르게 그룹화가 되는 것을 확인할 수 있습니다.
그래서 본 논문에서는 hand-crafted 그룹화 과정을 없앤 새로운 3d object detection 모델인 Group-Free Object Detection via Transformers을 제안하고 있습니다. 아무래도 기존에 object feature을 추출할 수 있도록 모으는 그룹에 잘못된 포인트가 할당될 수도 있다는 점을 해결하려 했기에 가장 큰 keypoint라고 함은 포인트 클라우드에서 직접적으로 object 후보를 추린 다음, 하나의 object 후보의 특징을 계산할 때 그룹 내의 포인트가 아니라 모든 포인트를 사용한다는 점이라고 할 수 있습니다. 그리고 이를 위해 자동으로 학습되는 tarnsformer의 attention module을 추가하게 되는 것입니다. method에서 더 자세하게 이야기하겠지만 논문에서 해당 task에 맞게 transformer 구조를 두 가지 정도 변경하게 되는데요, 첫번째는 각 단계에서 spatial encoding을 이전 단계의 object box prediction 결과를 이용하여 반복적으로 개선시킵니다. 두번째는 마지막 단계의 결과 뿐만 아니라 모든 단계의 결과를 합쳐서 detection에 사용한다는 점 입니다. 즉 정리하면, 저자는 보편적인 grouping 과정을 생략하고 포인트 클라우드에서 직접적으로 object 후보를 골라서 object 후보와 모든 포인트 클라우드와의 관계를 수정한 transformer 구조를 추가하여 파악함으로써 3D Object detection task를 수행하고자 하였습니다. 이러한 변경 사항이 추가적인 cost가 거의 발생하지 않는 방향으로 3D object detection의 성능을 향상시킬 수 있었다고 합니다. 그 결과로 SUN RGB-D와 ScanNetV2 데이터셋에서 모두 SOTA를 달성하였습니다.
2. Related Work
related work에서 transformer을 사용한 타 방법론들 중 가장 유사한 구조를 가지고 있는 방법론을 DETR이라고 언급하였습니다. 2D object detection에 transformer을 적용한 구조이기는 하나 해당 구조를 그대로 사용할 경우 3D object detection에서는 상당한 성능 저하가 발생한다고 합니다. 결론적으로 앞서 introduction에서 언급한 본 논문의 방법론의 transformer 구조에 대해 한 번 더 강조하면서 비록 다른 task에서의 convolution 기반의 방법론이 가지는 우수한 성능과는 어느 정도의 차이가 존재할 수 있겠지만 모델 구조에 transformer의 attention을 도입하는 것이 이전의 3D object detection에서 raw level의 포인트 클라우드를 직접적으로 입력으로 사용할 때 고수해오던 그룹화 과정에서 발생하는 이슈를 해결할 수 있는 방안 될 수 있다는 것을 주장하고 있습니다.
3. Methodology
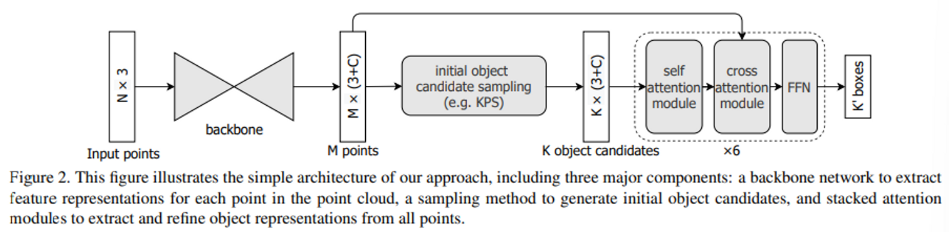
Figure2는 방법론의 전체적인 구조에 대한 그림으로 Nx3 차원의 N개의 포인트가 입력으로 주어지면 3D boundign box를 예측하고 class score를 구하는 것이 최종 목표 입니다. 크게 각 포인트의 특징을 추출할 backbone network와 포인트를 샘플링할 sampling method, 그리고 stacked attention module 3가지로 나눌 수 있습니다.
우선 backbone network의 경우 간단히 PointNet++의 구조를 따릅니다. N개의 포인트를 입력으로 받으면 (예를 들어 2048개의 포인트를 입력으로 받는다고 생각해보겠습니다), 먼저 encoder-decoder 구조로 처음에 4단계의 set abstraction layer을 과정을 거치면 포인트가 1/8배인 256 포인트로 개수가 줄어들게 되고 다시 point feature propagation layer을 거치면서 원래 포인트의 1/2배인 1024 포인트로 복원하게 됩니다. 이러한 backbone network 구조는 위와 같은 과정을 통해 각 포인트의 특징을 추출하는데, 결국 M개의 포인트(예시로 나타내면 1024개의 포인트)에 대한 C 채널의 feature vector \{z_i\}^M_{i = 1}를 출력하는 것 입니다.
3.1. Initial Object Candidate Sampling
2D detection에서는 이미지 내에서 유사한 size와 aspect ratio를 가지고 데이터에 크게 의존하지 않는 anchor box로 초기 object가 있을만한 곳을 추리지만, 이를 3D detection에 그대로 사용하기에는 3D 공간 내에서 너무 많은 anchor box가 존재하기 때문에 다루기 어려워진다고 합니다. 그래서 백본 네트워크를 거친 포인트 클라우드에서 직접적으로 초기 object 후보를 샘플하는 bottom-up 방식을 주로 사용하였고 본 논문에서도 마찬가지로 bottom-up 방식으로 3가지를 고려하였습니다.
- Farthest Point Sampling (FPS)
FPS는 point cloud를 샘플링하는데 널리 사용되고 있는 방식으로 초기 object 후보로 사용할 object를 샘플링할 때도 마찬가지로 활용될 수 있습니다. 처음에 랜덤하게 포인트 클라우드로부터 포인트를 고르고 한 점에서 가장 멀리 떨어져 있는 점을 고르는 것을 반복하면서 object 후보를 만들게 됩니다.
2. k-Closet Points Sampling (KPS)
해당 방법은 포인트 클라우드가 실제 object 후보인지 아닌지 구분하기 위해서 사용됩니다. 학습 과정에서 포인트에 label을 할당해줄 때 그 포인트가 GT bounding box 내에 속하는지, 그리고 object center와의 거리를 계산하여 가까운 순으로 정렬했을 때 미리 지정한 k개 내에 포함이 된다면 해당 포인트를 positive로 할당합니다. inference에는 포인트의 classification score에 따라서 초기 후보가 선택됩니다.
3. KPS with non-maximal suppresion (KPS-NMS)
위 2번의 KPS에 NMS를 추가한 방법으로, 공간적으로 가까운 object 후보들을 반복적으로 제거하는 2D detecton에서와 마찬가지인 작업을 거칩니다. 해당 방법에서는 classification score와 더불어 각 포인트가 속해있을 object의 중심까지 예측하여 NMS를 수행합니다. 하이퍼파라미터로 설정하는 반경을 이용하여 특정 반경 내에 위치한 후보들을 suppress하는 것으로, 2D에서의 box IOU와 같이 생각해주시면 좋을 것 같습니다.
저자는 3가지 방식 중에서 실험적으로 고려해본 결과 KPS를 사용하였을 때 가장 좋은 것을 확인하여 기본적으로 KPS 방식을 채택하여 사용하고 있습니다. 추가적으로 덧붙이자면, FPS보다 더 나은 성능을 보였고 더 복잡한 과정을 거쳐야 하는 KPS-NMS 보다 더 효율적이었다고 하네요.
3.2. Iterative Object Feature Extraction and Box Prediction by Transformer Decoder
샘플링을 통해 초기 object 후보를 골랐으니 이제 transformer을 decoder로 사용하여 백본을 지난 모든 포인트를 활용하여 각 후보 object에 대한 특징을 계산해야 합니다. transformer의 multi-head attention network는 기본적으로 세 개의 입력 set인 query set \{q_i\} , key set \{p_k\}, value set을 가지고 있습니다. 입력으로 3개의 set이 들어가면 각 query 요소들의 multi-head attention의 결과로 attention weight에 의해 가중치가 매겨진 값들을 합쳐서 출력하게 됩니다.
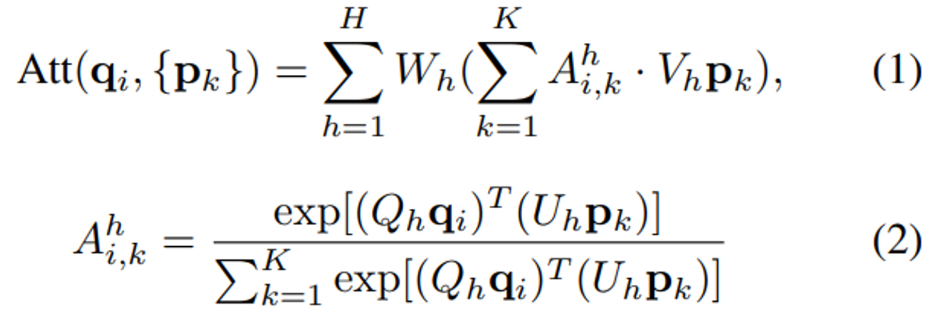
h는 attention head의 index 번호이고 A_h는 attention weight 입니다. Q_h, V_h, U_h, W_h는 차례대로 query projection weight, value projection weight, key porjection weight, 그리고 output projection weight를 의미합니다. 본 논문에서의 transformer의 역할은 object featur를 계산하고 3D object bounding box를 병렬적으로 예측하는 것 입니다.
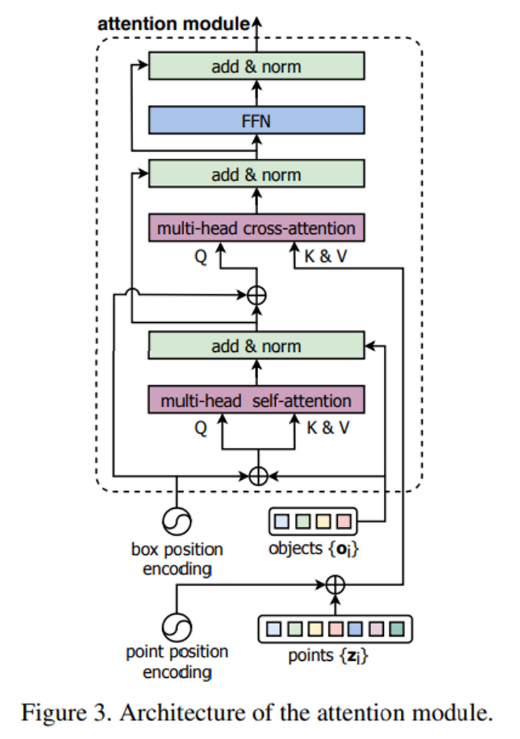
그리고 구성은 Figure 3과 같이 stacked multi-head self attention 모듈과 multi-head cross attention module로 이루어져 있습니다. 앞서 백본 네트워크를 거친 포인트의 C 채널로 추출되는 feature에 대해서 정의했었는데요, transformer의 l 단계에서의 point feature을 \{z^{(l)}_i\}^M_{i = 1}, 샘플링을 거친 object 후보 포인트들의 feature을 \{o^{(l)}_i\}^K_{i = 1}라고 정의해보겠습니다.
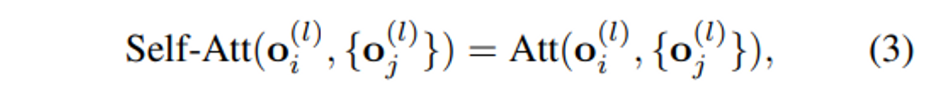
그러면 stacked multi-head self-attention에서는 식(3)과 같이 object feature들 사이의 관계를 계산하게 되고,
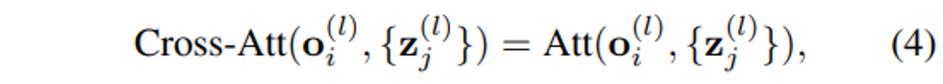
cross-attention 모듈에서는 하나의 object feature에 대해서 식(4)처럼 모든 point feature와의 관계를 계산합니다. self-attention과 cross-attention의 결과로 기존의 object feature가 갱신되고 나면 feed-forward network (FFN)을 적용하여 3D bounding box를 예측합니다.
여기서 저자가 기존의 transformer decoder를 3D Object Detection이라는 task에 맞게 변형한 몇 가지 변경 사항에 대해서 알아보도록 하겠습니다.
Iterative Object Box Prediction and Spatial Encoding
기존 transformer에서는 모든 stacked attention 모듈에 대해서 각각의 word에 index를 부여함으로써 고정된 spatial encoding을 적용하였습니다. 이 부분을 본 논문에서는 각 단계마다 object 후보에 대해서 spatial encoding을 개선하는 것으로 변경합니다. 즉 각 decoder 단계에서 3D box의 위치를 예측하고 class를 분류하는데, 한 단계에서 예측한 box의 위치는 다음 단계에서 같은 object의 spatial encoding을 개선하기 위해서 사용되는 것 입니다. 그래서 각각의 단계에서 개선된 spatial encoding vector는 다음 단계에 사용되기 위해서 그 decoder 단계의 output으로 함께 출력합니다. object feature의 경우 3D bounding box의 요소인 (x, y, z, l, h, w), 포인트의 경우 3차원 좌표인 (x, y, z)를 parameterization vector로 설정하여 독립적으로 두 종류의 vector을 linear layer에 적용하여 계산됩니다.
Ensemble from Multi-Stage Predictions
또 다른 차이점이라고 함은 기존 transformer에서는 마지막 단계의 출력값만을 최종 결과로 반영하는 반면, 본 논문에서는 모든 단계의 결과를 최종 dection 결과를 결정하는데 사용하도록 ensemble한다는 점 입니다. 모든 단계의 결과가 합쳐진 상태로 NMS를 적용하는 메커니즘이 실험적으로 상당히 향상된 결과를 얻을 수 있는 방법이라고 합니다.
3.3. Heads and Loss Functions
Decoder Head
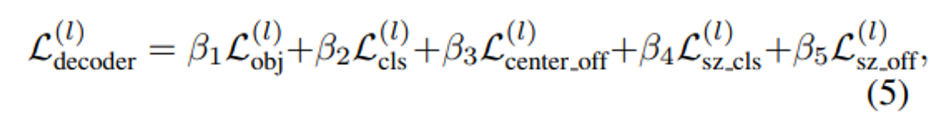
decoder head에서는 총 5개의 예측을 할 수 있습니다. Loss function은 식(5)에서 볼 수 있듯이 먼저 object prediction으로 binary focal loss인 L_{obj}, box classification으로 cross entropy loss인 L_{cls}, box의 중심 좌표 offset을 예측하기 위해 smooth-L1 loss로 이루어진 L_{center\_off}, box의 크기를 분류하기 위한 cross entropy loss L_{sz\_cls}, 그리고 마지막으로 box 사이즈의 offset을 예측하기 위한 smooth-L1 loss L_{sz\_off}로 이루어져 있습니다.
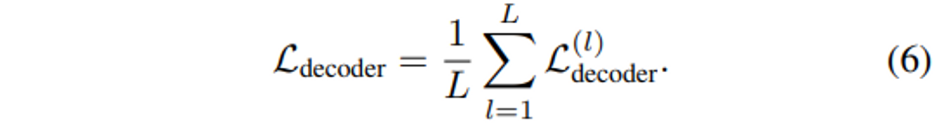
식(5)는 특정 decoder 단계 l에서의 loss function을 나타낸 것으로 모든 단계에서의 loss를 합치면 식(6)과 같이 평균을 내어 정의할 수 있습니다.
Sampling Head
Sampling 모듈의 loss function은 위에서 정의한 decoder head loss function과 비교해보았을 때 아직 3D box와 관련된 작업을 하기 이전이기 때문에 box와 관련된 loss를 포함하지 않아도 되고, objectness 작업은 KPS 설명할 때 언급한 것 처럼 poistivie 라벨을 할당해준다는 차이가 존재합니다.
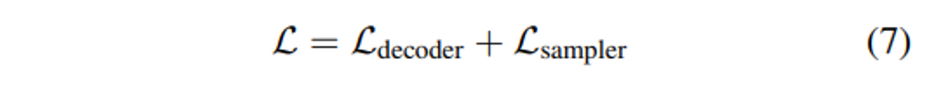
그래서 최종 loss function은 decoder head loss와 sampling loss를 합친 형태로 정의합니다.
4. Experiments
실험은 indoor 3D dataset인 ScanNet V2와 SUN RGB-D를 사용하였습니다.
4.1. System-level Comparison
두 데이터셋에서 GroupFree 3D 방법론과 이전 방법론과의 비교 실험을 진행한 결과에 대해서 리포팅하고 있습니다.
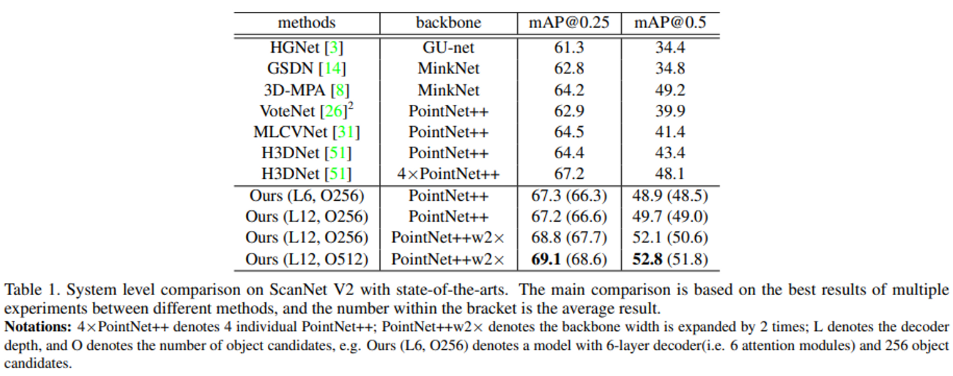
먼저 ScanNetV2에서의 결과 입니다. 표에서 L 옆의 숫자가 의미하는 것은 decoder의 depth를 의미하며 O는 초기 object 후보를 몇 개의 포인트로 설정하였는지를 의미합니다. 기본 세팅인 6개의 decoder layer와 256개의 object 후보만으로도 이전의 방법론 대비 비슷하거나 높은 성능을 보이지만 12개로 decoder layer을 더 늘리고 512개의 object 후보를 사용할 경우에 큰 차이를 가지고 SOTA를 달성함을 확인할 수 있습니다.
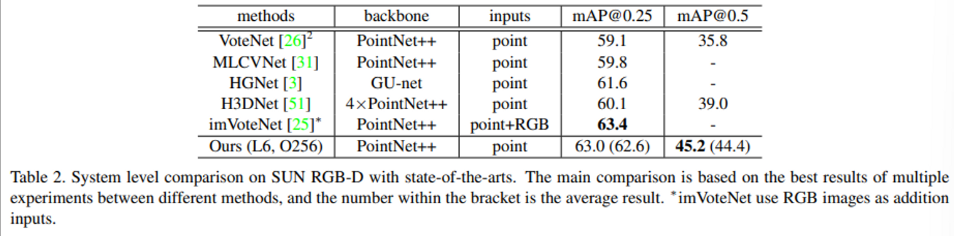
다음으로 SUN RGB-D에 대한 실험 결과 입니다. SUN RGB-D의 경우에도 포인트 클라우드만 입력 데이터로 사용한 방법론들과만 비교했을 때 SOTA를 달성하였습니다. 하지만 imVoteNet은 point + RGB를 입력으로 사용했음에도 비교군으로 넣은 것의 의도가 아마도 두 도메인의 데이터를 모두 입력으로 받는 방법론과 비교해도 유사한 성능이 나오는 것을 보여주기 위함이라고 생각하는데, ScanNetV2에서와 같이 decoder layer와 object 후보의 개수를 변경했을 때의 성능 비교가 SUN RGB-D 실험 결과에는 없는 것이 조금 아쉬운 점이라고 생각이 듭니다.
4.2. Ablation Study
Ablation study는 ScanNetV2에서 진행을 하였고 기본적으로 모두 6개의 decoder layer와 256개의 object 후보를 사용하였습니다.
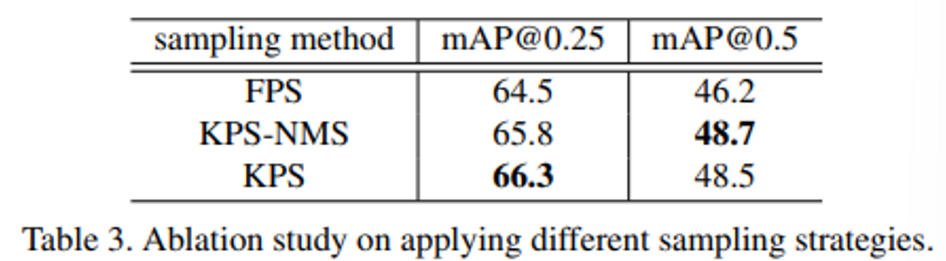
먼저 본문에서 default로 사용한 KPS를 포함하여 3개의 sampling 방식을 소개하였는데, 각각의 방식으로 대체하였을 때 성능을 비교한 실험 입니다. 이를 통해 default 방법 뿐만 아니라 다양한 sampling 방법을 사용하여도 유사한 성능을 달성할 수 있음을 보여주고자 하였습니다.
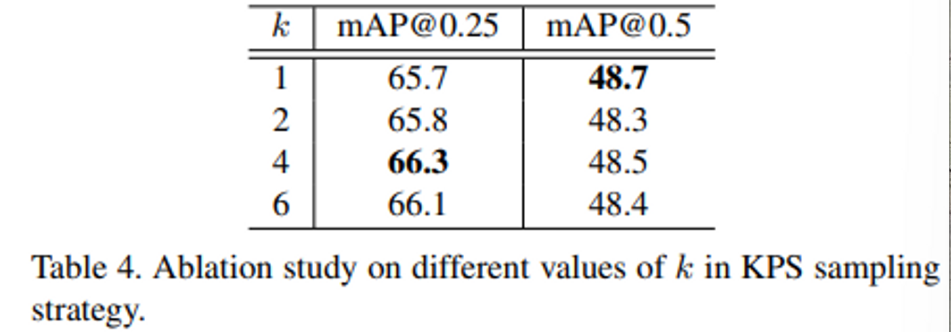
또한 Table 4는 KPS의 기준이 center와의 거리를 비교하여 가까운 순으로 정렬했을 때 k개 내에 포함되어야 한다고 했는데, 이때 하이퍼 파라미터로 지정된 k를 변경함에 따라 성능이 어떻게 변하는지 확인하는 실험 입니다. 1-6까지의 수를 지정하였을 때 실험 결과를 보여줌으로써 안정적인 성능을 보일 수 있는 하이퍼 파라미터의 범위가 넓음을 강조하고 있습니다.
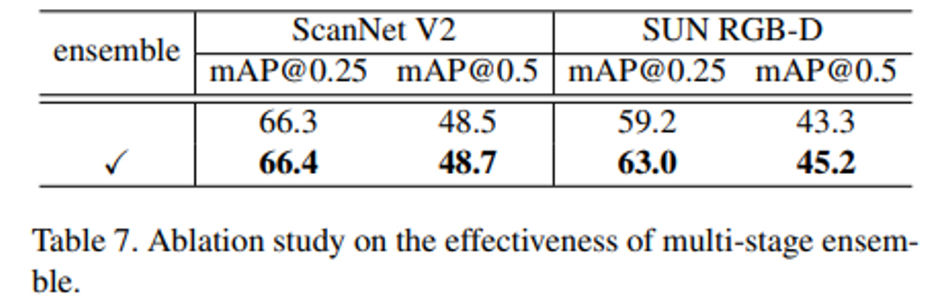
Table 7은 기존의 transformer와의 차이점으로 제시한 ensemble 기법에 대한 ablation study인데, 표를 보면 ScanNet에서는 성능이 ensemble의 사용 유무와 관계없이 차이가 거의 없는 반면에 SUN RGB-D에서는 2-4%의 유의미한 향상이 나타남을 볼 수 있습니다. 저자는 이러한 결과에 대해서 두 데이터셋의 포인트 클라우드 quality를 비교해보았을 때 SUN RGB-D가 더 낮기 때문이라고 가정합니다. SUN RGB-D에서는 물체의 occlusion 등으로 인해 놓친 부분이 다수 존재하는 포인트 클라우드를 제공하지만 ScanNet에서는 보다 완전한 mesh shape의 포인트 클라우드를 제공하기 때문에 SUN RGB-D에서 성능 향상을 보인다는 것은 본 방법론의 ensemble 기법이 실제 3D scene에 가까울수록 성능 향상의 폭이 커질 수 있는 환경이라는 것을 보여준다고 합니다.
4.3. Comparison with DETR
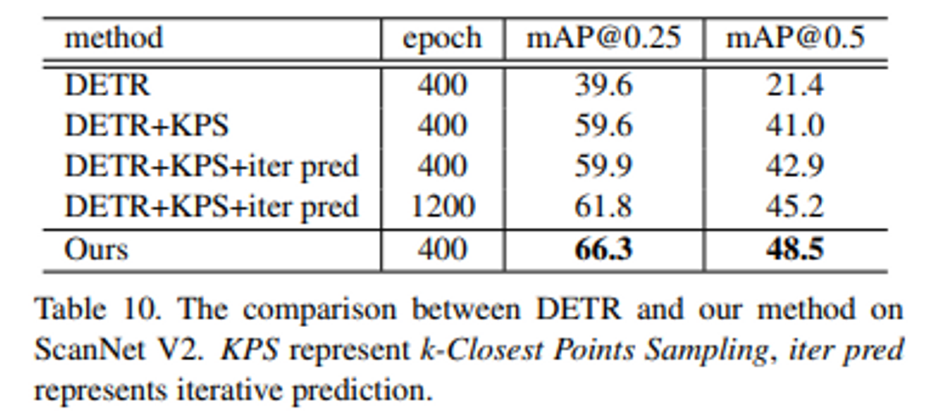
DETR을 3d detection task에 적용시켰을 때 큰 차이를 가지고 성능이 하락하는 것이 보여집니다. 이러한 결과의 원인으로 저자는 DETR은 2D detection으로 데이터에 의존하지 않는 object representation이고 계속해서 refine 되지 않고 고정된 spatial encoding을 사용하기 때문에 성능에 영향을 미쳤을 것이라고 추측합니다. 보다 데이터에 의존적인 KPS와 반복적인 refine을 DETR에 추가하면 눈에 띄는 향상을 보이면서 추측이 타당하다는 것을 알 수 있습니다.
안녕하세요. 손건화 연구원님.
좋은 리뷰 감사합니다.
이 리뷰를 보니 정말 트랜스포머가 안 쓰이는 곳이 없는 것 같습니다… 궁굼한 점이 몇가지 있어 질문드립니다.
1. Spatial Encoding이 개선된다는 것은 즉 학습 가능한 positional encoding을 사용한다고 이해하면 될까요?
2. point 정보는 순서가 별 의미가 없는 것으로 알고 있는데, 어째서 transformer에서 positional encoding이 필요한지 궁굼합니다.
감사합니다!
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
첫번째의 refinement는 이전 stage에서의 예측된 location 정보를 conv layer을 태워서 embedding vector을 구하여 다음 stage에 더해주신다고 보면 됩니다
두번째는 여기서 positional encoding은 각각의 point가 어떤 박스의 범위 내에 존재하는지를 표현하기 위해서 필요하다고 이해해주시면 좋을 것 같습니다.
안녕하세요 손건화 연구원님. 좋은 리뷰 감사합니다.
제가 point cloud라는 도메인을 잘 모르는 관계로… 간단한 질문이 있는데요…
[그림2]에 나타나는 input point cloud가 N*3차원인건 n개의 point가 각각 x, y, z의 좌표값을 포함하기 때문인 걸로 알고 있는데 출력 차원이 M*(3+C)인 이유는 M개의 point가 c채널만큼의 특징값 + xyz좌표값으로 출력되기 때문인가요?
만일 그렇다면 backbone을 통과한 point들이 위치 정보는 그대로 포함하고 있음을 의미하는데 여기에 추가적으로 position정보를 추가해주는 의미가 무었인지도 궁금합니다.
정리하자면 point cloud데이터의 형태와 [그림3]의 points와 object가 어떻게 계산되며 그 형태는 어떤 의미인지 궁금합니다…
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
네, 말씀하신대로 M개의 포인트에 대해서 추출된 C차원의 feature vector + 3차원의 xyz 좌표를 의미하는 것이 맞습니다. 제가 리뷰에 남겨놓지는 않았지만 그런 기존의 위치 정보만을 position 정보로 포함했을 때와 추가적인 embedding을 진행했을 때를 비교한 ablation study가 있었는데요, 확연히 눈에 띄는 성능 향상을 보였기에 실험적으로 의미있다고 할 수 있을 것 같습니다.
좋은 리뷰 감사합니다.
related work에서 이전의 3D object detection에서 raw level의 포인트 클라우드를 직접적으로 입력으로 사용할 때 고수해오던 그룹화 과정에서 발생하는 이슈는 어떤 것들이 있나요?
그리고 loss에서 box의 크기를 분류하기 위한 loss와 box 사이즈의 offset을 예측하기 위한 loss로 각각 cross entropy loss와 smooth l1 loss를 사용했는데 두 loss는 어떤 차이가 있나요? 비교하는 대상이 어떻게되는지 궁금합니다.
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
그룹화 과정에서의 이슈 같은 경우에는 본문에서도 말씀 드렸듯이 A 물체의 박스를 proposal할 그룹에 B 물체의 포인트가 잘못 할당되는 경우등을 의미합니다.
loss에 관련해서는 논문에서 자세한 언급없이 본문에서와 같은 설명으로 끝냈기도 하고 이런 식으로 loss를 나누는 것을 저도 처음 보기에 정확하지 않을 수 있지만 .. box의 크기라고 함은 (w, h, l) 사이즈 자체를 의미하는 것이고, box 사이즈의 offset은 기존 GT의 (w, h, l)와의 잔차 거리를 예측하는 차이가 있는 것으로 이해하였습니다.
손건화 연구원님, 좋은 리뷰 감사합니다.
3d detection 분야는 확실히 2d와는 상당히 다르고 어렵네요. anchor box를 사용하기에는 computation cost가 너무 크니 결국 point cloud를 어떻게든 clustering하면서 object의 후보를 만들어내는 느낌을 받았습니다. 기존에는 voting 등을 사용해서 문제가 생겼다면, 이 논문에서는 FPS, KPS 등을 사용하면서 문제점을 개선한 것 같네요.
두가지 간단한 질문을 드리자면,
1. Figure 1을 보면 GT에 point cloud도 있고 bounding box도 있는 것 같은데, point cloud dataset은 보통 GT값이 box형태로 주어지나요? 아니면 2d image data에서 segmentation data처럼 point cloud 각각에 라벨링이 되어있는건가요? 모델에 예측할때는 point cloud별로 object 예측을 한다고 이해했는데 맞나요?
2. object 후보를 샘플링 하는 방법 중 FPS에 대한 설명에서 ‘ 처음에 랜덤하게 포인트 클라우드로부터 포인트를 고르고 한 점에서 가장 멀리 떨어져 있는 점을 고르는 것을 반복하면서 object 후보를 만들게 됩니다’ 라고 말씀해 주셨는데, 잘 와닿지가 않습니다. 추가적인 설명이 가능하실까요?
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
1. GT 값은 3D bounding box 형태로 주어진다고 이해해주시는 것이 맞습니다.
2. 처음에 랜덤하게 한 점을 선택하고 그 점에 대해서 가장 거리가 먼 점을 고르고, 다시 하나의 점을 선택해서 가장 거리가 먼 점을 선택하는 과정을 반복하는 방법이 FPS 입니다. 만약 random하게 점을 sampling하게 된다면, 일부 영역에 집중되어 sampling되는 문제가 발생할 수 있기 때문에 선택한 점을 기준으로 해당 점으로부터 가장 거리가 먼 점을 선택하여 물체 전반적인 형태를 표현할 수 있는 점들을 선택하기 위해 사용합니다.
안녕하세요 손건화 연구원님. 리뷰 잘 읽고, 이번 주에도 또 찾아뵙습니다.
읽다 중간에 궁금한 점이 하나 생겨 질문드리게 되었습니다.
저자가 말한 hand-crafted grouping 방법이 소파-테이블이 잘못 매칭되는 문제가 있어 그런 grouping에서 hand-crafted를 제거하기 위해 어떤 방법을 제안한 것으로 보이는데.. grouping이 정확히 어떤 것인지 설명해주실 수 있을까요?
뭔가 group이라는 것이 object의 후보군을 만드는 것과 같다는 식으로 설명해주셨는데, grouping과 detection이 다른 것이 있나요? grouping이 잘 되었으면 그것만으로 객체의 bounding box를 치면 끝 아닐까 싶어 궁금합니다.
두 번째로는, 연이어 grouping에는 고수하고 initial candidate sampling은 왜 쓰이나요? 수 많은 point cloud를 다 쓰는 것은 무리기에 그렇나요? 그럼 예를 들어, FPS 방법은 hand-crafted인가요 아닌가요?
리뷰 잘 읽었습니다. 감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
기존의 grouping이라고 함은 sampling된 점들 중에서 FPS와 같은 방식을 사용해 몇개의 점을 선택을 하고 그 점을 기준으로 어떤 반경 내에 존재하는 점들을 묶어 하나의 그룹으로 만드는 과정을 의미합니다. 말씀하신 것처럼 grouping이 잘되었으면 그것만으로 하나의 객체 박스를 만들면 되기에 유용한 세팅이지만 저자는 반대로 grouping이 잘 되지 않았을 때 성능 저하의 원인이 된다는 것을 이야기하고 있습니다.
initial candidate sampling은 GT box와 포인트를 비교함으로써 정말 이 포인트가 box proposal에 사용될 수 있는 포인트인지를 판별하기 위해 사용하는 것 입니다. 포인트에는 background에 해당하는 포인트도 있을 것인데 그런 포인트를 proposal에 사용되면 안되기 때문이죠 .. FPS 방법은 hand crafted 방식 입니당
안녕하세요. 좋은 리뷰 감사합니다.
3d detection 분야 논문을 x-review로 종종 보았지만 transformer를 사용하는 거는 별로 없다고 생각했는데 이번에는 transformer를 사용했길래 재미있게 읽었습니다. 간단한 질문이 있는데요.
Iterative Object Box Prediction and Spatial Encoding 파트에서 등장하는 spatial encodeing을 기존 origal transformer의 positional encoding으로 이해하였는데요. 그러면 “각 단계마다 object 후보에 대해서 spatial encoding을 개선하는 것으로 변경합니다.”은 각 object의 position encoding을 개선한다는 것으로 이해할 수 있을 거 같은데
“즉 각 decoder 단계에서 3D box의 위치를 예측하고 class를 분류하는데, 한 단계에서 예측한 box의 위치는 다음 단계에서 같은 object의 spatial encoding을 개선하기 위해서 사용되는 것 입니다. 그래서 각각의 단계에서 개선된 spatial encoding vector는 다음 단계에 사용되기 위해서 그 decoder 단계의 output으로 함께 출력합니다. “라고 할때 decoder 단계에서도 계속 spatial encoding을 수행하고 이에 대한 output을 계속 decoder에서 출력한다고 받아들이면 되는 걸까요?
안녕하세요 ! 댓글 읽어주셔서 감사합니다.
네, 각 decoder stage에서 박스 위치를 예측하게 되면 그 정보를 더하여 다음 단계로 넘겨주기 때문에 하나의 decoder 단계에서 매번 spatial encoding이 수행되고 output으로 출력하여 다음 단계에 전달할 수 있습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
기존의 grouping 과정에서 잘못된 포인트가 그룹에 할당되는 경우 group 내로 제한되는 검출이 detection 성능을 저하시킬 수 있기에 grouping을 생략하는 방법론을 제안했다고 이해를 하였는데요, 그렇다면 attention 모듈에서 하나의 object candidate에 대해서 백본을 지난 모든 포인트와의 attention을 통해 feature을 계산하는 것은 이해가 되나, object 간의 self-attention을 진행해야 하는 이유에 대해서 조금 의문이 드는 것 같은데, 이에 대해 조금 더 설명해주실 수 있나요 ??
감사합니다.
안녕하세요 ! 리뷰 읽어주셔서 감사합니다.
그룹 내에 제한되지 않는 모든 포인트에 대한 관계를 계산하여 object feature을 계산할 수 있지만, 그 뿐만 아니라 object level에서 다른 두 object의 관계를 계산함으로써 좀 더 object 스스로의 특성을 파악할 수 있기 때문에 object 간의 self-attention 또한 진행하는 것으로 이해하였습니다.