Masked autoencoder는 시각적인 표현력을 잘 학습할 수 있어 몇몇의 독립적인 modality에서 좋을 결과를 보였지만 multi-modal의 경우 많이 적용이 되지 못했다. 본 논문에서는 point cloud와 rgb 두 modality를 모두 사용하는데 집중했고 PiMAE를 제안했다. PiMAE는 self-supervised pre-training framework로 2d와 3d를 세 가지 측면을 통해 상호작용할 수 있도록 한다. 먼저 두 modality간 masking 전략의 중요성을 파악했고 projection module을 통해 두 modality의 mask token과 visible token간 align을 맞추려고했다. 그리고 두 branch구조의 shared decoder를 포함하는 MAE pipeline을 통해 mask token에서 cross-modality interaction을 강화하고자했다. 그리고 cross-modal reconstruction module을 통해 두 modality에서의 feature representation을 강화하고자했고 sunrgbd와 scannetv2에서 좋은 결과를 보였다.
Introduction
robotics나 autonomous driving분야에서 3d point cloud와 2d rgb image data는 함께 많이 활용되고있다. 이때 pair한 2d pixel과 3d point는 같은 scene에 대해 서로 다른 관점에 대한 정보를 나타낸다. 각각 서로 다른 정도의 정보를 가지기 때문에 함께 활용하기위해 결합한다면 더 좋은 성능 향상을 기대할 수 있을 것이다. 하지만 3d point와 2d image를 서로 잘 interaction할 수 있는 model을 고안하기 위해서는 어려움이 있는데 model에 direct하게 입력된다면 모델이 좋은 성능을 보이지 못한다는 결과가 있다고 한다.
본 논문에서 저자는 model이 더 좋은 표현력을 학습할 수 있도록 어떻게 더 interactive한 unsupervised multi-modal learning framework를 고안할지에 대해 고민했다고 한다. 그리고 직관적이고 효과적으로 pre-training할 수 있는 vision transformer framework인 MAE에 대해 더 알아보았다고 한다. 하지만 기존에 존재하는 MAE pre-training 기법들은 오직 single modality에 대해서 국한되어있었다. 특히 기존에 MAE가 multiple modality에서 좋은 결과를 보일 수 있을 것이란 말은 많았지만 관련된 연구가 실제 이뤄지고 결과를 보인적은 없었다고 한다.
따라서 본 논문에서는 multi-modal fusion방법으로 poitn cloud와 image data를 fusion하는 PiMAE를 제안한다.
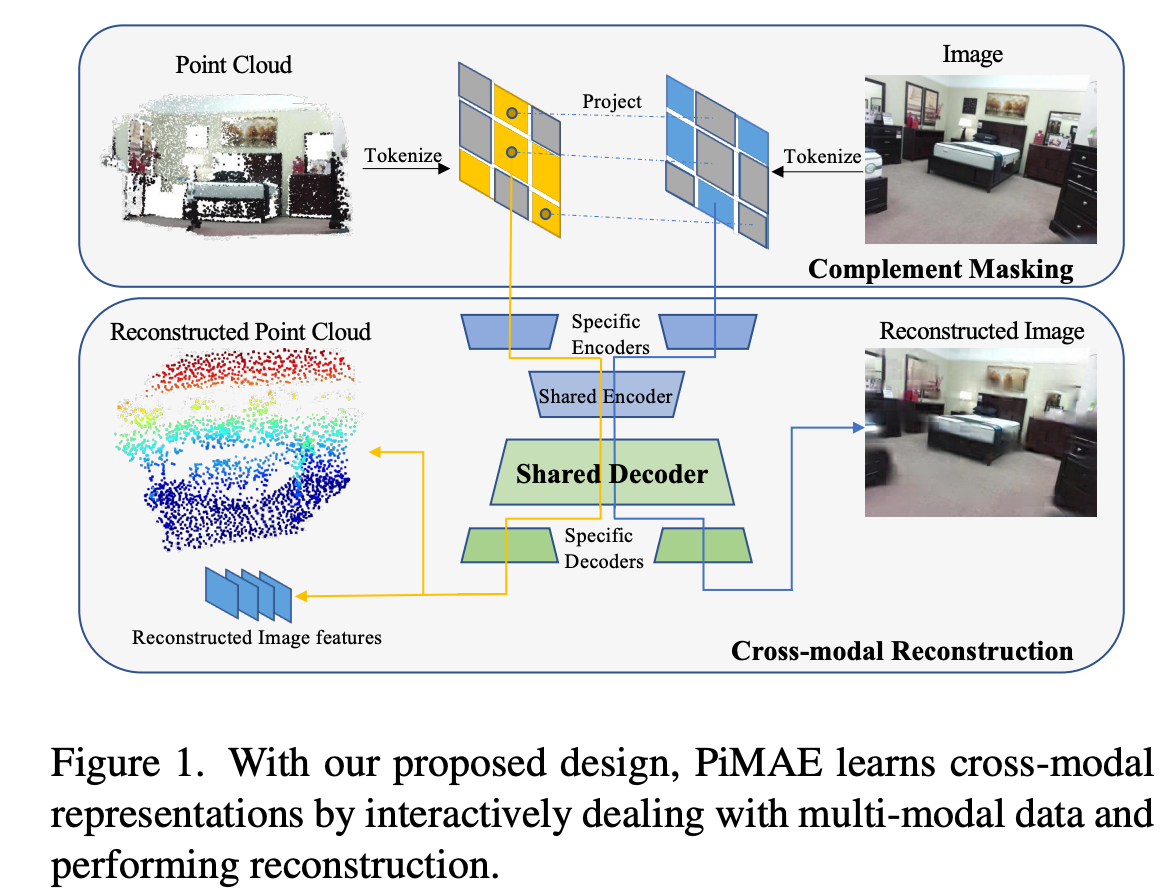
PiMAE는 간단하고 효과적으로 3d와 2d feature를 학습할 수 있는 pipeline이라고 한다. 좀 더 자세히 설명하자면 point cloud와 rgb image를 input으로 하여 pre-training을 한다. 이때 두 modality 각각이 독립적인 embedding을 학습하는 2개의 branch를 가지는 구조의 MAE를 사용한다. 그리고 feature alignment를 더 활성화하기위해 추가로 3가지 main features를 고안했다. 먼저 image와 point cloud를 token화하는데 이때 두 modality의 token을 연관시키기 위해 명시적으로 point token을 image patch로 projection한다. 이때 좀 독특한 masking방식이 적용되는데 이것이 token정보를 embedding하는데 도움이 된다고 한다. 그리고 새로운 symmetrical한 구조를 가지는 autoencoder를 통해 강력한 feature fusion을 촉진한다. encoder는 modality 독립적인 branch와 shared-encoder로 되어있는 구조이다. 기존에 MAE에서 mask된 token은 decoder에만 들어가다보니 본 논문에서 적용한 shared-decoder의 구조가 mask token이 두 modality의 통합적인 정보를 학습하는데 중요한 역할을 할 수 있다고 한다. 그리고 마지막으로 multi-modal reconstruction module은 point cloud feature가 향상된 image feature를 통해 image-level의 이해를 encoding할 수 있도록 한다.
본 논문에서 제안하는 PiMAE의 효용성에 대해 평가하기 위해 rgbd scene dataset인 sunrgbd와 scannetv2에서 평가를 수행했고 여러 downstream task에서 좋은 결과를 보임을 입증했다.
본 논문에서 contribution은 아래와 같다.
1. 최초로 point cloud, rgb 두 modality를 활용한 pre-training MAE 제안
2. multi-modal learning에서 두 modality간 interaction을 강화하기 위해 complementary cross-modal masking전략, shared-decoder, cross-modal reconstruction을 새로 도입
3. 실험적으로 기존 방법론들보다 좋은 결과를 보여 PiMAE의 효용성 입증
Related Work
3d object detection은 방향정보를 포함하는 oriented 3d bounding box를 예측해야한다. 이때 기존에 많은 CNN기반 방법론들은 좀 유명한 2d detector를 사용하기 위해 point cloud를 2d로 projection하고 3d bounding box를 검출했다. 또 다른 방법은 3d convolution을 사용하기 위해 point cloud를 voxel화 하여 3d sparse convolution을 적용하였다. 그리고 최근에는 transformer구조가 도입이 되었다. transformer는 3d data에 적용하기 적합하다고 하는데 왜냐하면 hand-craft로 grouping을 할 필요가 없고 permutation invariant를 만족하기 때문이라고 한다. 본 논문에서 제안하는 PiMAE에서는 projection-based와 attention-based를 모두에서 영감을 얻어 3d object detector를 고안했다고 한다. 기존 projection-based는 광범위하게 사용되었지만 attention-based는 더 활용도가 높고 직관적인 solution이라고 한다. 결과적으로 MAE구조의 multi-modal learning framework를 고안했다.
3d point cloud와 2d image를 함께 활용하는 representation learning방법들은 feature fusion을 위해 두 mdoality의 interaction을 강화하는 것에 목적을 둔다. 그리고 기존의 방식들 중 contrastive learning에서 rgb와 point cloud pair를 사용했을 때 좋은 결과를 보였는데 본 논문에서 제안하는 PiMAE은 기존 방식에 비해 더 적은 augmentation이 필요하다는 장점이 있다고 한다.
최근에 masked image modeling(MIM) 접근법이 좋은 결과를 보여 masking한 image를 기반으로 예측을 수행하는 self-supervised training기법이 많이 등장하고 있다. MAE가 큰 성공을 거두고 난 이후로 몇몇 방법론들이 point cloud에 MAE를 적용하는 시도를 해왔다. 하지만 기존의 방법론들은 rgb input을 쉽게 point cloud와 통합할 수 없고 사소한 성능 향상만 가져왔기 때문에 point cloud와 rgb scene dataset의 잠재력을 극대화하지 못한다는 단점이 있다고 지적한다. 본 논문에서 최초로 MAE pre-training를 통해 rgb image와 point cloud의 align을 맞추는 시도를 했다고 한다. MAE에서 최초로 rgb와 point cloud를 썻다는 걸 부각시키고 있다.
Methods
Pipeline Overview
아래 Figure 3는 전체 pipeline을 나타내고있는데 PiMAE는 point cloud와 rgb 각 modality로부터 동시에 cross-modal representation을 학습하게 된다.
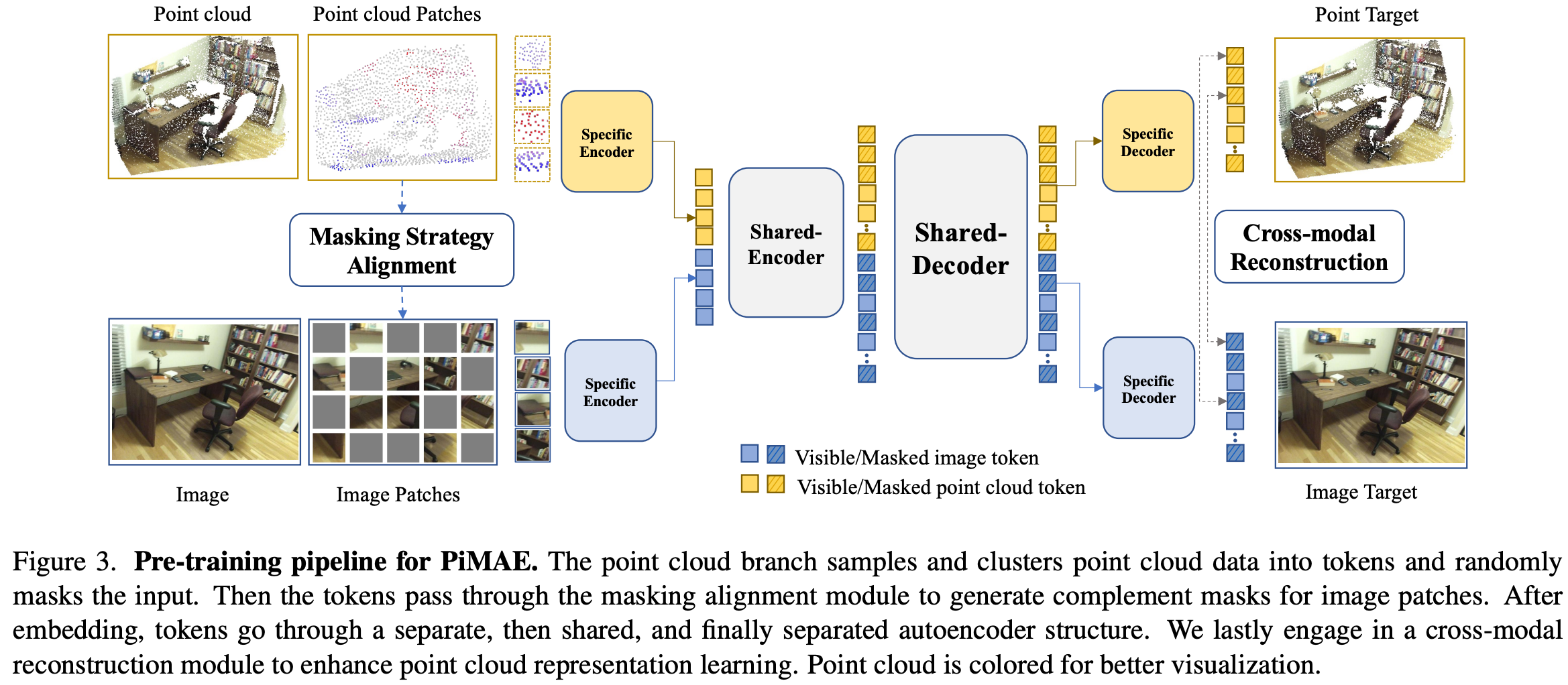
처음에 poit data를 sampling과 clustering을 통해 token으로 embedding하고 point token에 대해 masking을 수행한다. 그리고 image patch에 complement masking을 수행하기위해 mask pattern이 2d plane으로 전달된다. 여기서 complement masking이란 point cloud와 rgb token에 서로 반대로 masking을 하는 방식으로 뒤에서 좀 더 자세히 다루겠다.
그리고 이어서 symmetric한 joint-encoder-decoer 구조를 통해 feature fusion을 수행하게된다. 이때 encoder-decoder구조는 독립된 branch와 shared module로 구성된다. modality별 독립된 branch는 modality-specific learning을 하도록 하고 shared module은 cross-modal interaction을 통해 더 강인한 feature를 얻을 수 있도록 한다. PiMAE는 pre-training에서 학습한 feature를 가지고 cross-modal reconstruction module을 통해 point cloud feature가 명시적으로 image-level의 이해를 표현하도록 한다.
Token projection and alignment
image와 point cloud를 tokenize하는 과정은 MAE와 Point-M2AE를 따라싿고 한다. 먼저 이미지는 overlapping되지 않는 patch로 나뉘어지고 linear projection layer를 통과한 값에 positional embedding(PE)과 modality embedding(ME)를 더해서 patch를 embedding하는 과정을 거친다. 그리고 상응하는 point cloud에 대해서도 Farthest Point Sampling(FPS)와 K-Nearest Neighbor(KNN) 알고리즘을 통해 clustering하고 linear projection layer를 통과한 값과 PE, ME를 더해 token으로 embedding하게된다.
두 modality간 alignment를 맞추기위해 point cloud를 camera image plane으로 projection하여 3d point cloud와 rgb image pixel간 연결을 해준다. 단순히 3d에서 2d로의 사영기하적인 방법을 사용한다. 수식적으로 보면 3D point P를 P ∈ R3라고 할 때 상응하는 2d coordinate는 Proj라는 projection function을 통해 구할 수 있다.
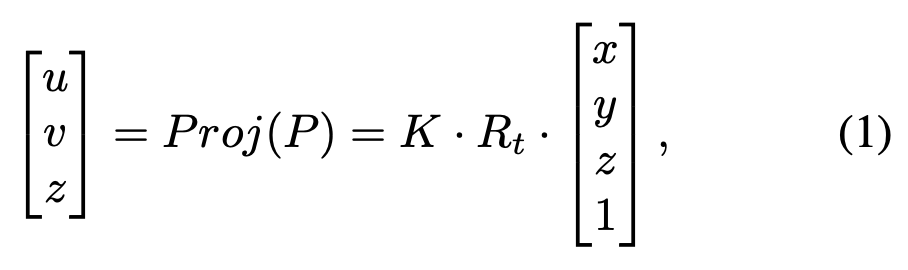
K ∈ 3 × 4 는 camera instrinsic matrices이고 Rt ∈ 4 × 4 는 camera extrinsic matrices를 나타내며 (x,y,z), (u,v)는 각각 original 3d coordinate와 projection된 point P의 2d coordinate를 나타낸다. 수식(1)에서는 homoegenous coordinate로 표현된 것이다.
그리고 위에 projection function을 사용하여 masking token을 생성하게 된다. point cloud token은 clustering된 center를 기준으로 구성되기 때문에 center points들 중 일부를 random하게 선택하여 상응하는 token을 뽑게된다. masking되지 않은 visible point cloud token을 TP라고 할 때 해당 token들의 center point P ∈ R3를 상응하는 camera plane에 projection해서 2d coordinate p ∈ R2를 얻게된다. 이렇게 구한 image patch index Ip는 아래 수식으로 구할 수 있다. 이때 image patch의 index는 visible point cloud token에 대한 patch index이다. image shape이 HxW라고 할 때이고 u,v는 각각 2d coordinate p의 x,y축 값이고 S는 image patch size이다.
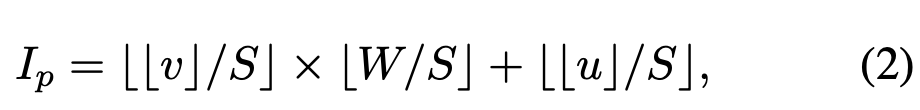
projection하고 indexing까지 한 각 visible point cloud token에 대해 상응하는 image patch를 얻을 수 있다. 그리고 명시적으로 해당image patch들을 masking하게 된다. 아래 Figure 2를 보면 좀 더 complement masking에 대해 이해가 수월할 것이다. 먼저 point cloud를 token화해서 masking하고 상응하는 위치를 2d로 projection하여 상응하는 image patch를 알아낸다. 이것들이 위에 오른쪽 그림에서 노란색 patch부분이된다. 그리고 visible point cloud token에 대해서는 해당 patch와 complement하게, 즉 point cloud가 masking되지 않은 영역에 대해 masking을 하는 것이다.

이론적으로 이러한 형태의 masking전략이 visible token에 대해 uniform masking을 하는 것보다 더 semantic한 정보를 많이 얻을 수 있다고 한다. 따라서 model이 더 풍부한 cross-modal feature를 추출할 수 있다고 한다.
Encoding phase
encoder는 modal-specific encoder와 cross-modal encoder 두 module로 구성되어있다. modal-specific encoder는 각 modality 내에서 specific한 feature를 추출할 수 있고 cross-modal encoder는 두 modality간 interaction을 통해 feature를 추출할 수 있다. modality-specific encoder는 point cloud와 rgb image 각각 독립적인 2개 branch로 되어 ViT backbone으로 구성되어있다. 이때 align된 visible token이 상응하는 positional, modality embedding과 함께 input으로 들어간다.
그리고 shared-encoder를 통해 visible patches에 대해 cross-modality interaction으로 feature fusion을 하게된다. 이때 align된 token이 3d와 2d data에 모두 반영된 유사한 정보를 나타내기 때문에 이 단계에서 masking alignment가 중요하다고 주장한다.
수식적으로 표현하면 먼저 각각 separate encoding 과정에서 EI : TI → LI1, EP : TP → LP1 는 각각 image specific encoder, point-specific encoder를 나타내고 TI, TP는 각각 visible image, point patch token을 나타낸다. LI1, LP1은 각각 image latent space와 point latent space를 나타낸다. 그리고 shared-encoder는 ES : LI1 , LP1 → LS2 로 나타낼 수 있으며 서로 다른 latent representation을 fusion한다.
Decoding Phase
일반적으로 MAE encoder는 image와 point cloud data 모두에 대한 고차원의 encoding된 데이터의 표현력을 학습해야하는데 서로 다른 두 modality의 차이로 인해 modality 별 고차원의 latent representation을 decode하기 위해서는 특별한 decoder가 필요하다고 한다. 여기서는 shared-decoder다음 modality-specific-decoder 구조로 구성했다. shared-decoder구조가 추가된 것인데 이것은 encoder가 더 feature extraction에 더 focus하고 modality interaction에 대한 detail한 부분들을 무시할 수 있도록 하기 위한 구조라고 한다. MAE는 masked token은 shared-encoder를 통과하지 않는 asymmetric한 autoencoder구조를 사용하기 때문에 masked token을 보완하기 위해 visible token과 함께 shared-decoder를 통과시킨다. 이러한 설계가 없으면 서로 다른 modality의 masked token은 feature fusion에 관여하지 않기 때문이라고 한다. shared-decoder를 통과한 이후에 modaltiy-specialized decoder를 통해 더 나은 reconstruction을 할 수 있도록 한다.
두 modality에 대한 reconstruction을 하기 때문에 loss도 두 modality에 대해 구해주게된다. point cloud의 경우 l2 chamfer distance를 loss로 사용하고 Lpc로 나타내고, image의 경우 MSE를 loss로 사용하고 Limg로 나타낸다.
기호로 나타내면 shared-decoder의 input은 LS2′로 나타내고 이것은 encoding된 visible feature와 mask token을 모두 포함하고 있다. 이 latent representation을 가지고 shared-decoder에서 cross-modal interaction을 수행하게되고 이것을 DS : LS2′ → LI3, LI3으로 나타낼 수 있다. 그리고 분리된 decoder로 들어가는데 DI : LI3 → T’I, DP : LP3 → T’P으로 나타내고 Di, DP는 각각 image-specific decoder, point-specific decoder를 나타내고 T’I, T’P는 각각 visible image patch, visible point patch를 나타내며 LI3, LP3은 각각 image, point latent space를 나타낸다.
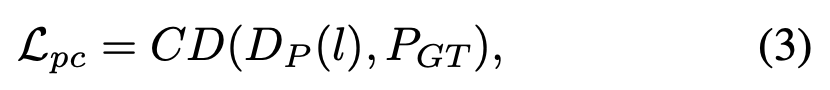
위의 수식(3)에서 CD는 l2 chamfer distance 함수를 의미하고 DP는 decoder reconstruction function을 의미한다. l ∈ LP3 은 point cloud의 latent representation을 나타내며 PGT는 point cloud gt(input point cloud)를 나타낸다.
Cross-modal Reconstruction
본 논문에서 제안하는 PiMAE는 3개의 loss를 사용한다. point cloud reconstruction loss, image reconstruction loss, cross-modal reconstruction loss가 해당된다. 마지막에 reconstruction할 때 처음에 사용한 alignment관계를 활용하여 masked point cloud에 상응하는 2d coordinate를 얻고 upsampling을 통해 masked point cloud와 상응하는 image feature를 얻는다. 그리고 masked point cloud token이 하나의 linear projection layer를 가지는 cross-modal prediction head를 통과해서 상응하는 visible image feature를 복원하게된다. 여기서 visible point cloud token을 사용하지 않았는데 왜냐하면 상응하는 masked image feature(complement masking전략으로 인해 visible point cloud token의 정보를 가지고 있을 수 있음)가 표현력을 학습하는데 방해가 될 수 있기 때문이라고 한다.
cross-modal reconstruction loss는 아래와 같이 표현할 수 있다.
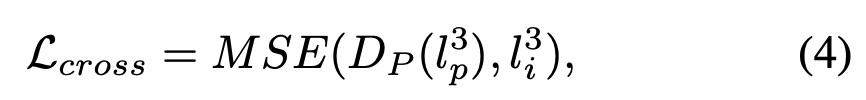
MSE는 mean squared error를 나타내고 DP는 cross-modal reconstruction을 나타낸다. lP3 ∈ LP3 는 point cloud representation, li3 ∈ LI3 은 image latent representation을 나타낸다.
최종 loss는 3개의 loss를 합한 loss로 표현한다. PiMAE는 3d와 2d feature를 각각 학습하지만 두 modality간 interaction도 같이 고려하는 것을 알 수 있다.
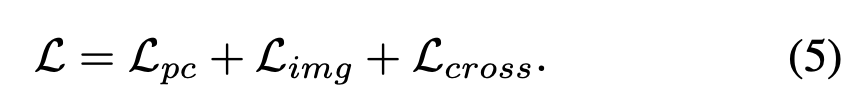
Experiments
PiMAE의 사전학습은 sunrgbd training set으로 진행하였다. downstream task 평가는 3d object detection, 2d object detection, few-show image classification 등 다양하게 수행했는데 여기서는 3d object detection결과에 집중해서 보겠다. point cloud branch에서 ViT backbone태우기전에 pointnet을 사용했고 image branch에서는 16×16 image patch로 나누었다고 한다. 또 main 목표는 patch간 consistency를 유지하는 것이기 때문에 data augmentation은 image와 point cloud input모두에 적용하지 않았다고 한다. 그리고 masking ratio는 60%로 설정했다. 아래 그림을 보면 image와 point cloud에서 60% masking을 하고 복원한 결과를 확인할 수 있다.

그리고 fine-tunning할 때는 3d, 2d모두 modality-specific encoder와 shared-encoder를 feature extractor로 사용했다고 한다.
우선 indoor 3d object detection결과를 보면 평가는 sunrgbd와 scannetv2에서 수행했다.

Table 1에서 기존 sota인 3DETR과 GroupFree3D와 비교한 결과를 볼 수 있는데 PiMAE를 적용하였을 때 1~2%정도 향상된 결과를 확인할 수 있다. 참고로 3DETR과 GroupFree3D는 모두 transformer기반 방법론이고 첫 번째 가로선 위 방법론들은 transformer기반이 아닌 방법론들로 보인다.
아래 Table 11은 sunrgbd에서 각 class별 성능을 보여준다. groupfree3d가 더 좋은 성능을 보이는 클래스들도 존재하지만 큰 폭의 차이가 나지는 않고 PiMAE를 적용했을 때 큰 margin의 성능 향상을 보이는 class들이 있음을 알 수 있다.

아래 그림에서는 sunrgb에서 3DETR에 대해 prediction한 결과와 PiMAE를 추가했을 때 결과를 시각화해놓았다.

그리고 이번엔 ablation study로 먼저 masking 전략에 대한 실험이다. 위에 Figure 2에서 봤던 것처럼 uniform과 complement masking을 비교했다. baseline은 random masking으로 했다. 아 참고로 ablation 실험은 모두 3DETR에 PiMAE를 적용한 방법으로 수행했다고 한다.
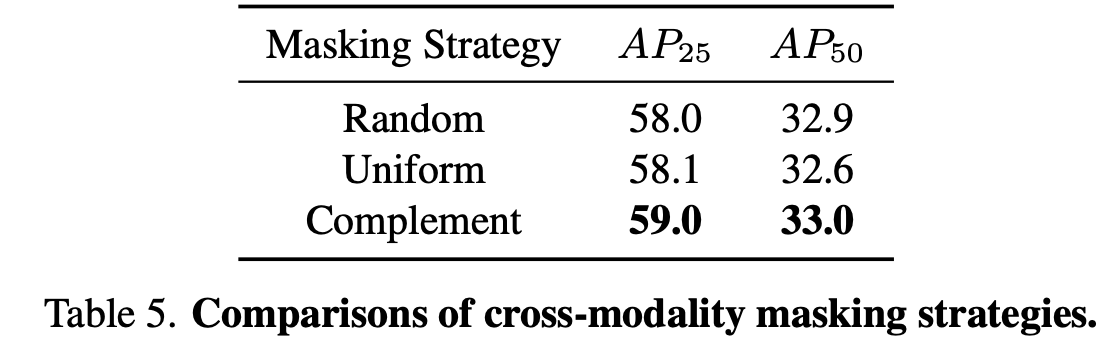
결과를 보면 complement로 masking한 방법이 더 좋은 성능을 보임을 알 수 있다. complement masking은 다양한 semantic information을 가지는 patches들 끼리 서로 다른 modality간 cross-modal interaction을 가능하게 하기 때문에 model이 2d 지식을 3d feature extractor로 전달하는 것을 도울 수 있다고 한다.
그리고 cross-modal reconstruction에 대한 실험도 수행했다.
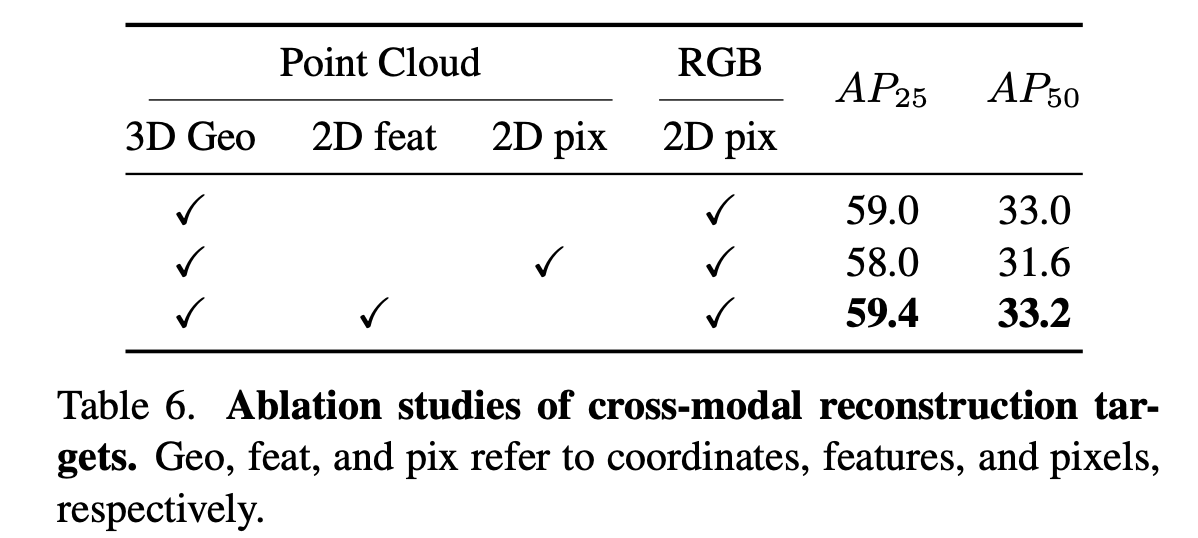
여기서는 point cloud feature를 통해 상응하는 image feature를 복원하는 것이 중요한데 이때 3d point cloud의 어떤 정보를 사용하면 가장 좋은 결과를 보일 수 있을지에 대한 실험이다. point cloud의 geometric정보(위치)와 2d feature를 함께 사용하여 cross-modal reconstruction을 수행했을 때 2d pixel level을 활용하는 것보다 모델이 modality간 interaction을 잘 할 수 있어 더 좋은 성능을 보이는 것을 알 수 있다.
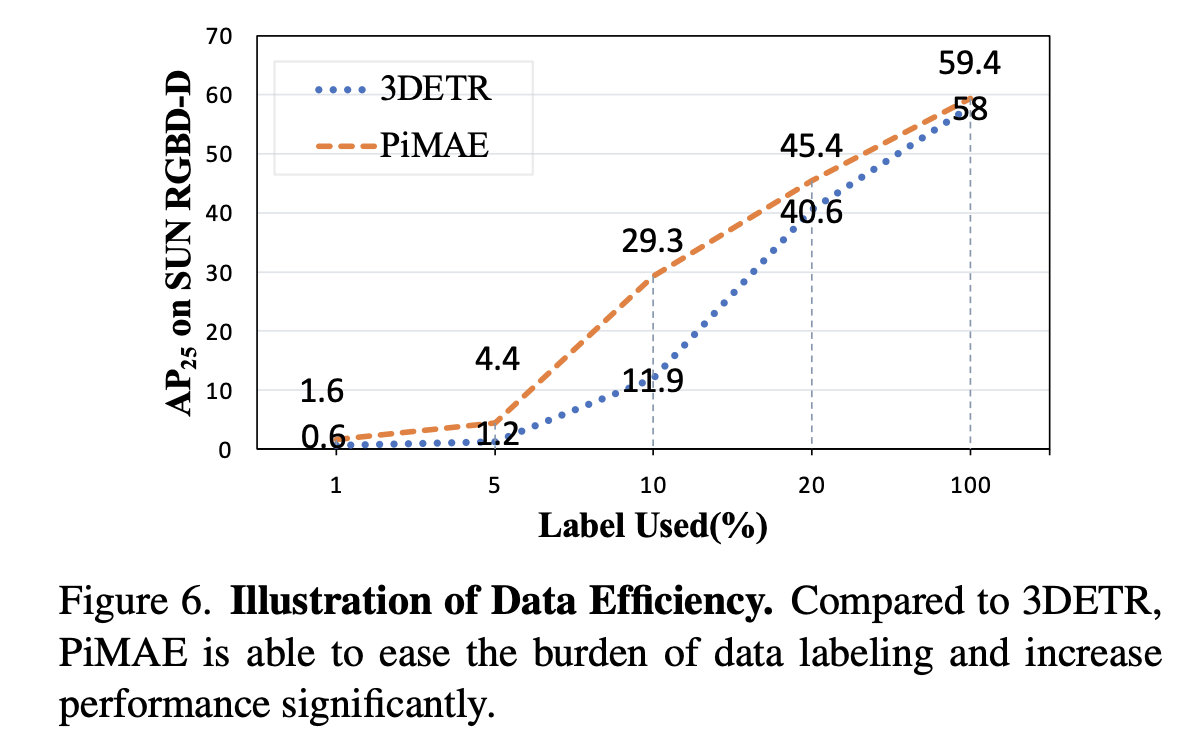
또 labeled data의 사용 비율에 대한 실험도 수행했다. 전체적으로 PiMAE를 적용했을 때 더 좋은 성능을 보이고 있고 특히 10%의 labeling data만 사용했을 때 17.4%의 성능차이를 보이며 적은 annotated data만을 사용하여 얻을 수 있는 이득이 크다고 보여진다.
Conclusion
본 논문에서는 간단하고 효율적으로 rgb와 point cloud 두 modality의 multi-modal learning pipeline인 PiMAE를 제안한다. cross-modality interaction을 촉진하기 위해 크게 3가지 관점에서의 고안을 했는데 먼저 더 나은 feature fusion을 위해 rgb와 point cloud에서 masking pattern의 align을 명시적으로 맞춰주었다. 그리고 shared-decoder구조를 통해 두 modality의 mask token을 함께 입력으로 받았고 cross-modality reconstruction module을 통해 학습된 semantic정보를 바탕으로 더 향상된 복원을 할 수 있었다. 실험결과를 통해서도 PiMAE가 multiple modality에서 잘 동작한다는 것을 알 수 있었고 앞으로 multi-modality task에 baseline으로 삼을 수 있을 것이다.