
안녕하세요. 열 여덟번째 x-review입니다. 이번에 리뷰할 논문은 올해 CVPR에 게재된 pedestrian detection 논문으로, 2D pedestrian detection과 관련하여 3-4편 가량의 논문 중 한 편입니다. 본 논문의 1저자는 전년도 CVPR에도 2d pedestrian detection으로 논문을 게재하였는데, 1년만에 다시 CVPR에 게재하였네요. 코드를 받고자 메일을 주고 받은 적이 있는데, 착한 사람인 것 같아보였습니다. 그럼, 시작하겠습니다.
Preliminary
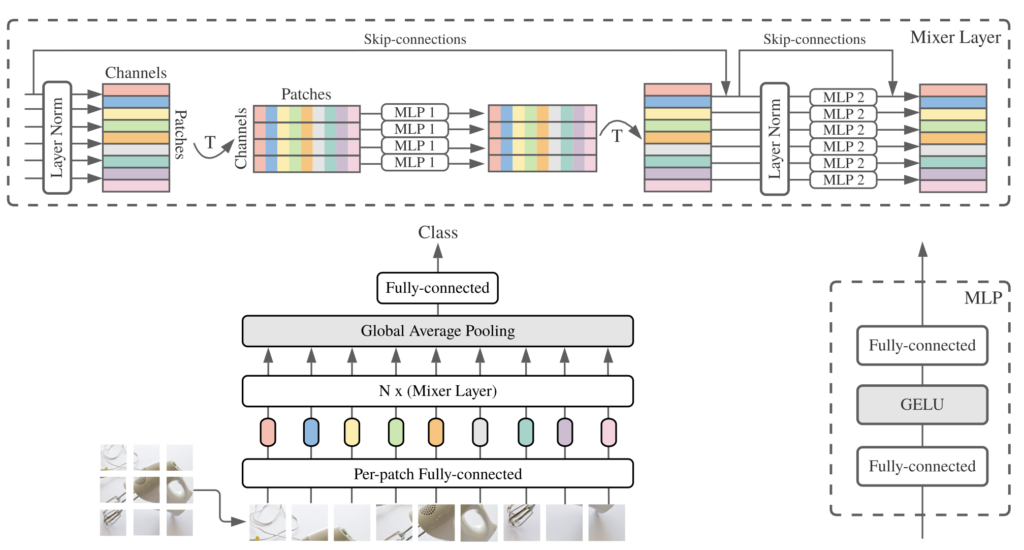
본 논문을 이해하고자 한다면, 우선 다음의 논문을 이해해야합니다. 2021 Neurips에 게재된 “MLP-Mixer: An all-MLP Architecture for vision”로, CNN과 ViT의 computational resource로 인한 아쉬움을 극복하고자, MLP만을 이용하여 비전 문제를 풀고자한 방법입니다. 현대 딥러닝 모델은 (1) 한 spatial location에서 feature를 mixing해주는 layer, (2) 서로 다른 spatial location들 간 feature를 mixing해주는 layer로 구분할 수 있습니다. 이 때 feature를 mixing해준다함은 CNN을 예로 들었을 때 이미지에 convolution 연산을 통해 학습하는 feature map을 생성하는 과정을 의미합니다.
일반적인 NxN kernel을 사용하는 convolution 연산과 pooling layer는 (2)의 역할을, 1×1 pointwise CNN은 (1)의 역할을 한다고 볼 수 있습니다. 반면, ViT의 self-attention layer는 (1), (2)를 모두 수행한다고 볼 수 있습니다. 일반적으로 (1), (2)의 역할을 모두 수행한다면 성능에 도움이 되겠지만, 연산량이 많이 소요되는 등의 몇몇 문제점이 있습니다. MLP-Mixer는 channel-mixing layer와 token-mixing layer를 통해 (1), (2)의 역할을 모두 수행하도록 분리합니다. 이 때 channel-mixing layer는 한 patch내 location의 feature를 mixing하는 (1)의 역할을, token-mixing layer는 서로 다른 spatial information을 mixing해주는 (2)의 역할을 수행합니다.
더 자세히, 그림의 아래 부분을 살펴보면 H*W 사이즈의 이미지를 P*P 사이즈의 S(H*W / P*P)개의 패치로 나눕니다. 이제 한 패치는 P*P*3(RGB) 차원으로, FC layer를 통과함으로써 C차원으로 projection합니다. 총 S*C차원의 패치들은 그림 위의 token-mixing layer를 통과하며 서로 다른 location의 feature를 mixing합니다. 동일한 MLP 연산임에도 token-mixing으로 불리는 이유는, 패치들을 Transpose한 이후 MLP를 통과하기 때문입니다. 반면, 다시 Transpose된 이후(원본) MLP를 통과할 때는 channel-mixing으로 명합니다. 한 번 이해하고나면, 어렵지 않습니다. 그럼 다시 본 논문을 살펴보겠습니다.
Introduction
pedestrian detection; PD는 자율주행 산업 분야에서 중요합니다. 이제는 상투적인 시작부입니다. 현 시점에서의 SoTA PD 모델들은 자율주행에 초점을 맞추기보단 연구하는 데이터 셋에서 좋은 성능을 보이는 방법에 몰두하다보니, 성능의 향상은 오를지언정 효율성, 이식성은 고려하지 않습니다. 사실 FPS를 reporting하니 고려하지 않는다기 보단, 후순위로 둡니다. 높은 성능을 보이는 무거운 모델을 자동차 시스템에 넣기 위해 경량화한다면 다시 성능은 낮아지겠죠. 그렇다면 만약 사람을 95% 이상 찾는다면 다 좋은 모델이라고 한다면, 이제 어떤 점을 고려해야할까요? 모델의 취약점입니다. PD에서는 보통의 모델들은 occlusion, small-scale pedestrian, motion blur의 상황에서 취약점을 보입니다. occlusion, small-scale은 잘 알테니, motion-blur에 대해 알아보자면 자동차의 주행 환경으로 인해 취득한 영상에서 사람을 찾는 것에 어려움을 보인다는 점입니다. 보통의 딥러닝 연구에서는 이런 데이터들은 Annotation 시 제외하고서 학습하니, 어찌보면 당연히 취약할 수 밖에 없습니다.
본 저자는 이전에 리뷰한 pedestron 저자의 의견에도 전적으로 동의하는데, “domain generalization”으로 부르는 날씨, 조도등의 자연 환경적 요인, 교통 체증 등의 주행 환경적 요인 등의 다양한 상황 및 환경에서도 강건하게 동작해야한다는 점입니다. 이를 위해 pedestron의 저자는 cross-dataset validation 즉, A dataset에서 학습한 후 B dataset에서 평가하여 성능을 비교하는 방법을 사용하였으며, 본 논문의 저자 또한 학습 데이터에서 보지 않았던 unseen 데이터에서도 잘 작동해야한다고 말합니다. 이 점은 저도 전적으로 동의하는 바입니다.
다시, 저자는 위에서 언급한 최근 PD 연구들은 computational cost를 고려하지 않은 채 단순히 accuracy를 높이는데에만 혈안이 되었다고 주장하며 그럼에도 불구하고 heavy occlusion과 small case pedestrian에 대한 성능은 향상의 여지가 있다고 주장합니다. 만약 accuracy를 높이고자한다면, FPN, ViT류의 방법이 효과적입니다. 하지만, accuracy와 computational cost (inference time)은 trade-off이며 ViT는 대표적으로 괜찮은 accuracy를 보임에도 computational cost는 quadratic하게 늘어난다는 문제가 있습니다. sensor fusion (RGB-thermal, RGB-point cloud)의 상황도 동일합니다.
저자는 해당 문제점을 극복하고자, 앞서 리뷰한 MLPMixer의 방법을 떠올립니다. MLPMixer는 MLP만으로 구성되어있어 메모리 효율성에 좋으며 이미지 분류에 있어 CNN, ViT와 비슷한 수준의 준수한 성능을 보입니다. 하지만 MLPMixer에서는 이미지를 P*P 사이즈의 S개의 토큰으로 나누기 때문에, image resolution이 높아진다면 parameter의 수가 늘어남으로 그 또한 문제가 될 순 있겠죠. 저자는 이 점을 보완한 MLPMixer 기반의 detection head를 고안합니다. 또한 앞서 말한 occlusion과 motion blur의 영향을 받지 않고자, hard mixup augmentation을 사용합니다. mixup augmentation은 존재하는 augmentation 방법이기에 제안한 것은 아니지만, 해당 방법을 통해 현존 데이터에서는 보이지 않는 motion blur된 pedestrian의 데이터를 끌고올 수 있으며, small-case pedestrian에 대한 데이터도 많이 만들 수 있습니다. 이 점은 mixup augmentation을 안다면 어렵지 않게 이해할 수 있습니다. 마지막으로, 저자는 useen 데이터에서도 잘 작동해야함을 보이고자 cross dataset evaluation을 통해 모델의 일반성을 보입니다.
Localized Semantic Feature Mixers
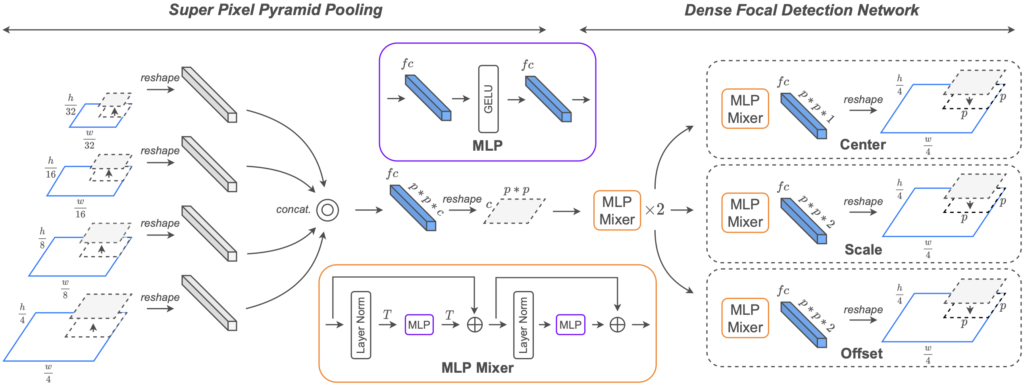
Super Pixel Pyramid Pooling (SP3)
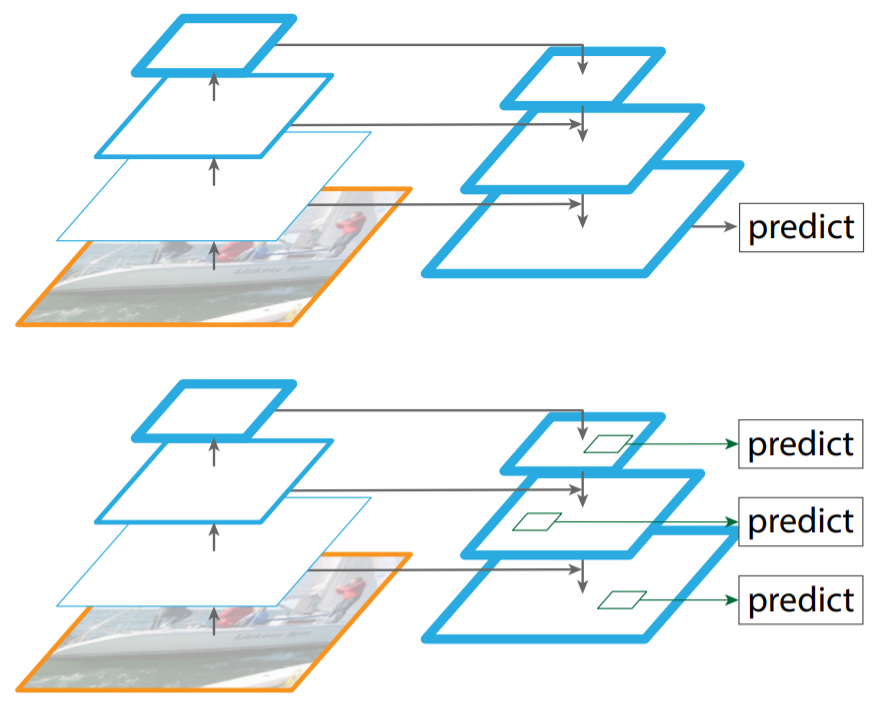
Figure. 1의 Super Pixel Pyramid Pooling을 먼저 살펴보겠습니다. cascade feature map을 사용하는 면에서 FPN과 유사한 모습을 보이는데, 저자는 FPN의 장단점에 대해 말합니다. 우선 FPN은 detection-network에서 서로 다른 scale의 feature map을 사용하므로 해당 feature map의 representation이 풍부해진다는 면이 있습니다. 이 점은 우리가 알고 있습니다. 하지만, FPN의 단점도 우리는 알고 있습니다. 서로 다른 scale의 feature map을 unified된 scale(uniform-scale)의 feature map으로 병합하고자 upscaling, downscaling 방법을 사용해야합니다. downscaling도 물론이지만 upscaling 방법을 살펴보면 주로 transposed convolution과 interpolation이 사용됩니다.(deconvolution도 있지만, transposed convolution과 deconvolution은 엄밀히는 다릅니다) 이 때, 두 방법 모두 computational resource와 memory cost가 높은 단점이 있습니다.
저자는 이 점에서 MLPMixer의 아이디어를 들고 오는데, linear layer만을 사용하므로 하나의 unified scale로 만드는 점에서 큰 무리가 없다고 주장합니다. 그렇다면 우리가 해야하는 부분은 backbone network의 서로 다른 지점(stage)에서, 패치의 개수만 맞춰주면 됩니다. 패치의 수만 맞다면, 이후에는 큰 문제가 없습니다. 왜냐하면, 이후 동일한 sptial location의 패치들을 묶고자 하는데 (예를 들면 각 feature map 사이즈에서 (0,0)지점에서 시작하는 패치), 패치의 수가 다르다면 쌍이 안맞아 이후 연산이 어렵겠죠.
패치의 수를 맞추기 위해서는, 단순히 patch를 split하는 사이즈 (P*P라고 명했던)를 달리해주면 됩니다. 예를 들어 32*32 feature map에서는 패치 사이즈 P를 8로, 16*16 feature map에서는 P를 4로 한다면 둘 다 16개의 패치를 갖게 됩니다. 이후 서로 다른 feature map의 패치들은 서로 일치하는 spatial location의 patch끼리 묶인 이후 concatentate하여 하나의 feature vector를 갖게 됩니다. 해당 feature vector는 이제 서로 다른 scale의 feature map에서, 상응하는 위치의 patch들을 묶어 이전보다 semantic하고 high representation을 갖게 될 준비가 되어 있습니다. 저자는 이 형태를 Super Pixel Form이라고 명하며, 해당 Super Pixel은 linear layer 하나를 통과하며 향상된 representation을 갖도록 학습합니다. linear layer(FC)를 통과하며 생성된 p*p*c의 1-Dimension의 feature vector를 reshape하여 p*p의 C-Dimension의 feature로 만드는 과정을 통해 FPN에 비해 효율적인 방법으로 feature를 풍부하게끔 만드는데 성공합니다.
Dense Focal Detection Network
이제 MLPMixer를 사용할 차례입니다. MLPMixer의 역할에서 Self-attention의 역할을 대체할 수 있다(Token-mixing layer)는 장점을 언급하였는데, 왜 필요한지 다시 생각해보겠습니다. 일반적인 detection 모델을 생각해보면 (SSD보다는 YOLO 계열을 상상해봅시다), detection network에 입력이 되는 feature map은 spatial context information은 충분하다고 생각할 수 있습니다. CNN 연산을 생각해보면, 정해진 kernel 내 연산의 결과로 나온 Feature map은 receptive field를 고려했을 때 이전 Feature map의, 이전 Feature map의, …, 입력 이미지의 일정 영역에 대한 이해도가 충분히 좋은 상태입니다.
이젠 다른 영역과의 연산도 충분히 진행된다면 좋을테죠. 예를 들면 Self-attention처럼, 이미지의 (0,0) 영역과 (width, height) 영역의 연관성도 고려한다면 더욱 풍부한 feature representation을 획득할 수 있습니다. 즉, 당연히 성능에도 좋은 영향을 미치겠죠. 이를 잘 수행할 수 있도록 설계한 것이 ViT였습니다. ViT는 Self-attention 연산을 통해 이미지 전반적인 영역의 관계성을 계산할 수 있습니다. 하지만 ViT는 앞서 언급한 바처럼 computational resource 측면에서 비효율적이므로, MLPMixer layer를 사용합니다. Figure. 1을 살펴보면 이전 Super Pixel을 p*p 사이즈의 C차원으로 reshape한 feature map을 patch로 나눈 이후 MLP Mixer를 통과합니다. 성능을 위해 2번 반복한다고 하지만, 2번쯤이야, ViT는 8번을 반복하니 괜찮다고 하죠.
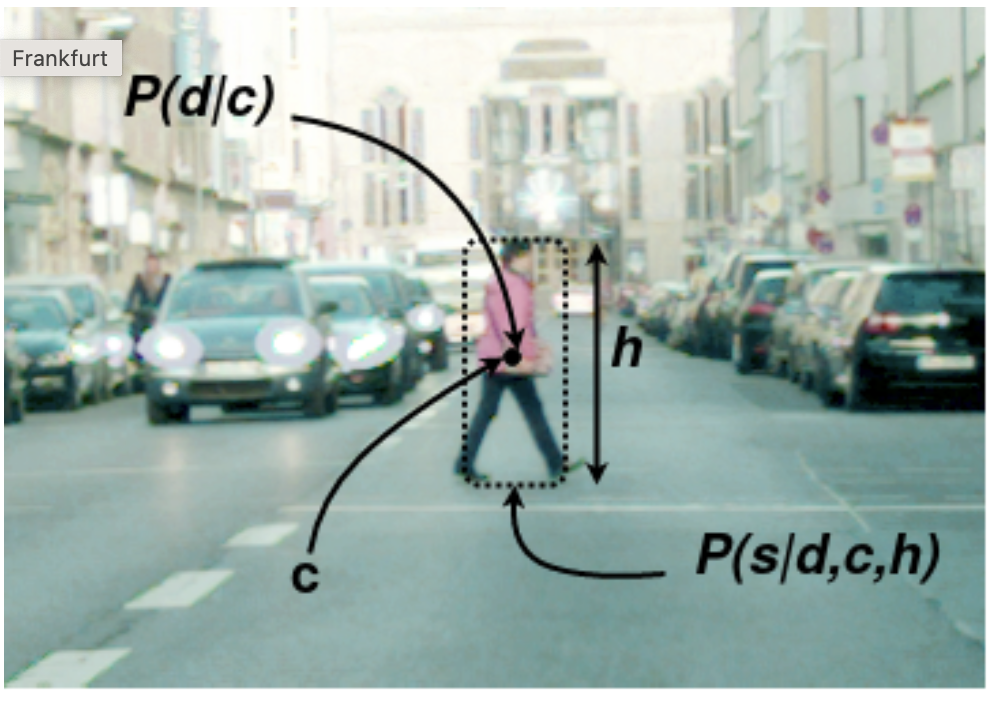
그보다도 짚고 넘어갈점은, 우리가 input image에 대해 다루는 것이 아닌, SP3 network의 결과로 나온 p*p 사이즈의 C차원 feature map에 대해 다루기 때문에 이제는 입력 이미지의 resolution을 고려하지 않아도 됩니다. SP3의 역할이 중요함을 다시 알 수 있으며, 그럼 해당 detection network가 어떻게 작동하는지만 살펴보면 됩니다. 우선, Anchor-free 접근 방식으로, 저자의 전년도 논문인 F2DNet의 아이디어, Loss를 그대로 사용합니다. F2DNet의 전문을 읽어보진 않았지만, 아래 그림과 설명을 통해 살펴보면 pedestrian의 center와 scale을 사용하는 모습을 볼 수 있습니다.
Anchor-free이므로, 모든 픽셀을 pedestrian인지 아닌지 분류하는 작업을 수행하며 동시에 center과 scale을 통해 pedestrian의 height와 width를 regression 합니다. 네.. 방법은 F2DNet을 차용했기에 끝입니다! Loss도 F2DNet을 그대로 가져왔지만, 그래도 언급은 해줍니다. offset regression을 위해선 SmoothL1Loss를, height와 width의 regression을 위해선 log scale을 사용한 L1Loss를, center(pedestrian 분류 지점) 예측을 위해선 Focal Loss를 사용합니다. 이중 Focal Loss에 대한 수식만 존재하므로, 짚고 넘어가겠습니다.
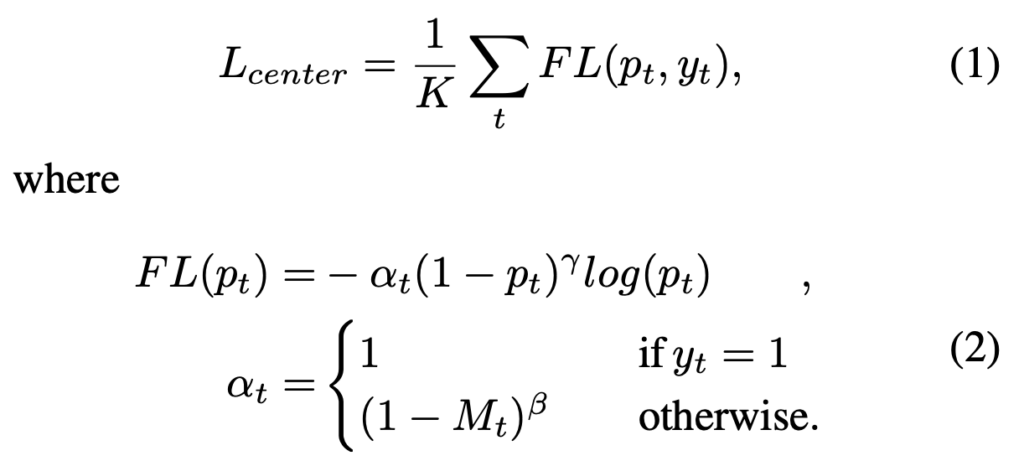
Focal Loss를 안다면 단순합니다. 배치 내 샘플 수 K개에 대해 ground-truth인 y와의 Loss를 계산합니다. 이 때, Focal Loss는 데이터 내 클래스 불균형 (positive, negative에 대해 positive 비율보다 negative 비율이 많아 발생하는 학습 시의 문제)을 극복하고자 고안되었는데, \alpha 가 1이면, 즉 y가 positive sample인 경우에는 일반적인 cross-entropy와 같으며 그렇지 않을 때는 M_t 를 사용합니다. M_t 는 positive sample 근처 gaussian kernel을 사용한 값으로, 예를 들어 small-case에 대해서는 true bounding box와 예측이 조금만 벗어나도 IoU가 급격히 낮아지는 문제를 극복하고자 고안하지 않았을까 생각합니다.
ConvMLP Backbone
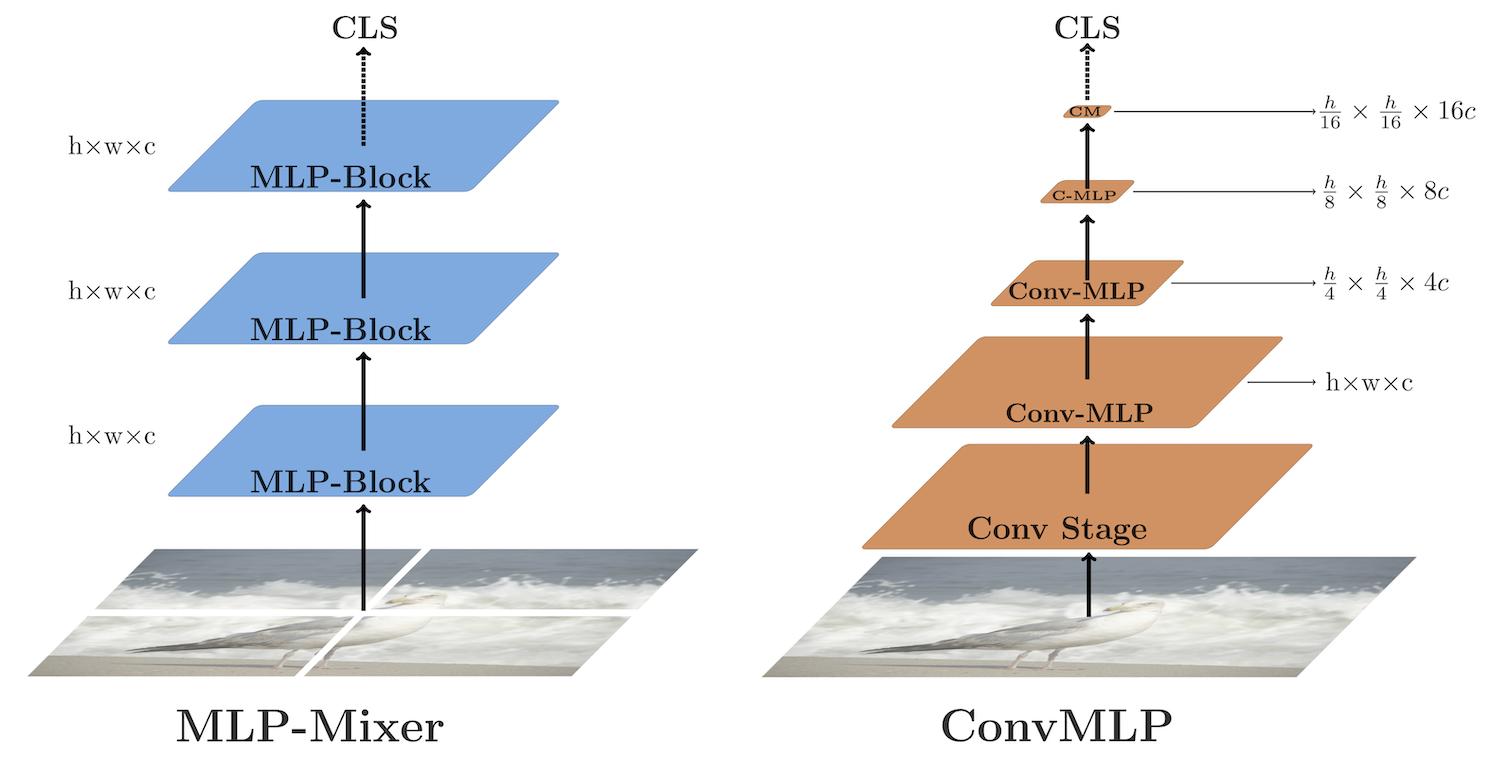
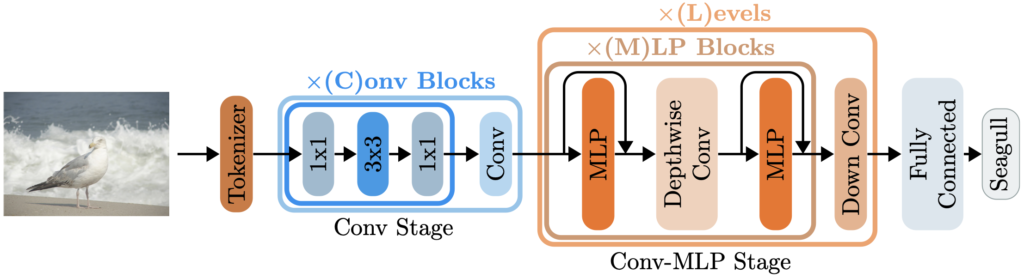
이제 Backbone network 차례입니다. VGG, ResNet 계열 등의 일반적인 backbone network도 존재하지만, 본 논문의 목적이 좋은 성능과 그보다도 우선적으로 memory, computational resource, higher inference speed 등이므로 무엇인가 다른 것을 들고올 필요가 있었습니다. 동시에, pedestrian의 center와 scale representation으로 분류 및 회귀를 진행하니, 좋은 semantic feature도 필요했죠. 그렇기에 저자는 ConvMLP를 backbone으로 사용합니다. ConvMLP는 위 그림에서 보이는 바와 같이 MLPMixer와 비교했을 때 일반적인 CNN의 convolution layer를 MLP와 결합한 형태입니다. Conv Stage와 Cone-MLP Stage로 나뉘는데, Conv Stage에서는 일반적인 Convolution 연산을, Conv-MLP Stage에서는는 MLP와 Depthwise, Downsampling conv를 통과합니다. 최종적으로는 FC layer를 통과한 후 이미지 분류가 목적인데, 저자는 이 아이디어를 가져와 사용합니다.
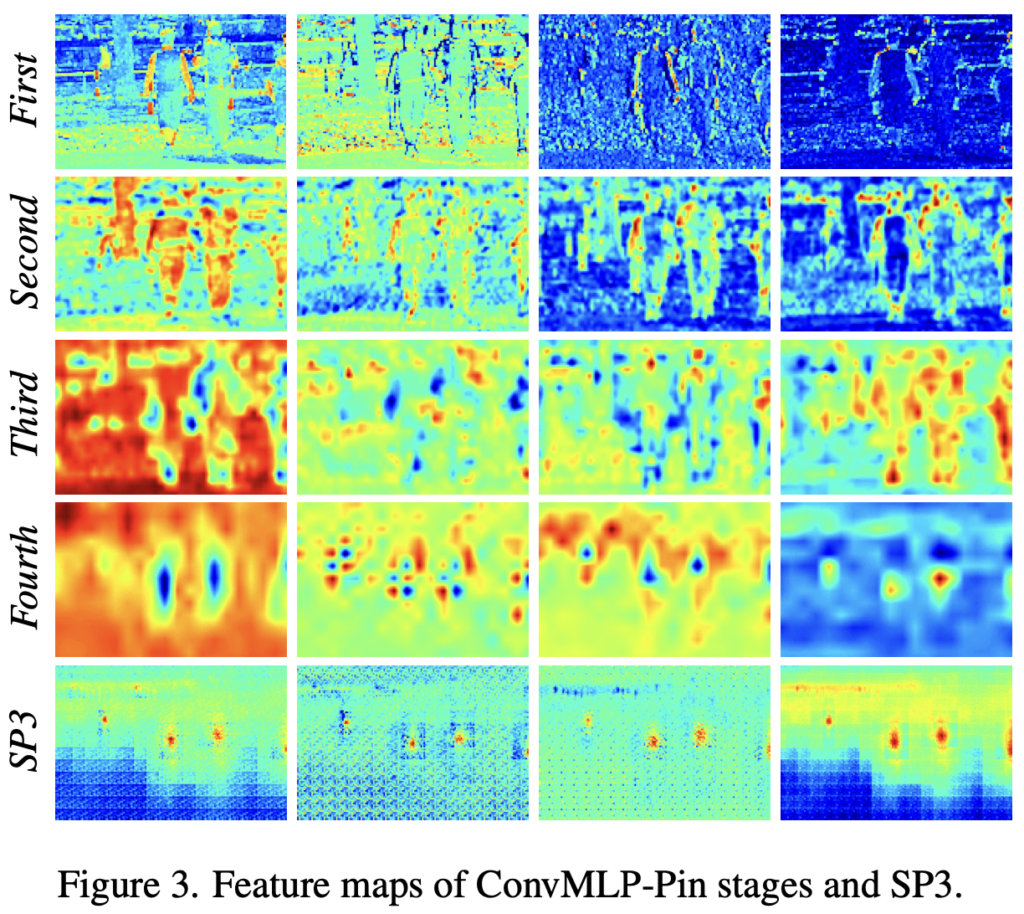
정확히는 Conv Blocks의 수를 몇 번 반복할지, Conv-MLP Stage를 몇 번 반복할 지에 따라 다르지만, 저자는 pedestrian의 semantic feature를 뽑아내기 위해선 기존 ConvMLP에 비해 deeper한 구조가 필요하다고 하며, ConvMLP-Pin을 제안합니다. 제안한다곤 하지만, 사실 구조는 그대로 가져가되 첫 Stage에서는 패치로 나눈 Token과 Residual block을 활용하고, 이후의 Conv-MLP Stage에서 MLP Blocks의 수를 4, 8, 4로 가져가며 이를 총 4개의 스테이지다!라고 언급하는 것을 볼때 굳이 제안까지야 싶긴 합니다. 물론 저자는, 이 점에 대해 더 deeper하고 semantic한 feature를 얻을 수 있고, MLP hidden dimension의 비율을 2배만 설정하여 lightweight한 모델을 위함이였다라고 언급하긴 합니다. 해당 backbone은 ImageNet-1000 dataset으로 100번정도 사전 학습 한 이후 사용하며, 각 Stage 별 feature map 및 이를 활용한 이후 SP3 에서의 feature map은 아래 Figure. 3에서 확인할 수 있습니다.
Hard Mixup Augmentation
이제 Mixup Augmentation입니다. Mixup Augmentation은 익히 아실 수 있지만, 아래 사진만 확인하면 끝입니다. 유명한 데이터 증강 기법이죠. 저자가 왜 detection 분야에서 Mixup 방법을 가져왔는지는 위에서 설명했지만, 다시 살펴보자면 현존하는 공인 pedestrian dataset에서는 차량 흔들림 등으로 인한 motion blur 상황이 드뭅니다. 사실 드물다기보다 해당 데이터들은 annotation 시 제외해버리죠. 그렇기에 현실에서 발생할 수 있는 상황에 대처하고자, Mixup augmentation을 가져옵니다. Motion blur 뿐만 아니라 해당 방법은 heavily occlusion된 case로 볼 수도 있으며, small-case로 볼 수도 있습니다.
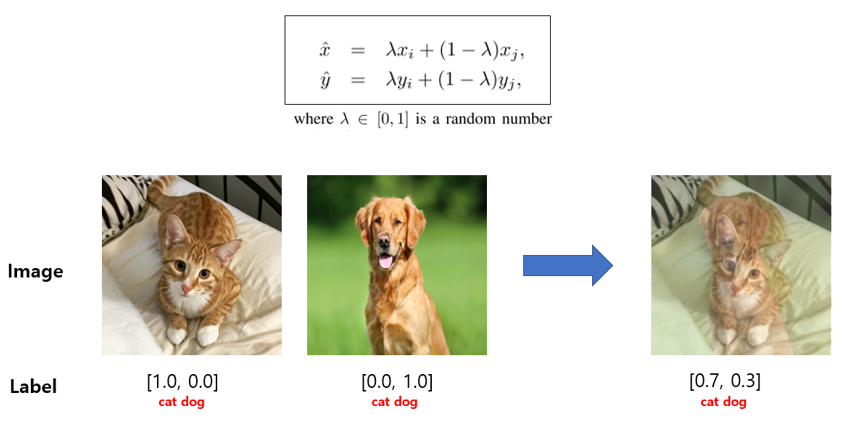
만약 Mixup이 아닌 CutMix와 Erase 기법은 어떨까요? 둘 다 영상에 대한 이해를 위해 좋은 방법들이지만, 사람 눈에도 그렇게 보이듯, 부자연스럽습니다. 분류의 경우에는 효과적인 Augmentation임에는 분명하나, detection에서 bounding-box를 찾기 위해 pixel들을 하나씩 살펴보다 갑자기, 부자연스러운 상황을 만나면 딥러닝 모델의 gradient는 원하지 않는 방향으로 학습해버릴 수도 있습니다. 저자는 Mixup이 좋긴 하지만, 위의 occlusion 상황을 모사하기 위해 Mixup을 적용한 이후 label을 soft-label이 아닌 hard-label ([0.7, 0.3]으로 가져가는 것을 soft-label, [1, 0]으로 가져가는 것을 hard-label)을 적용합니다. 즉, 사람 위 배경을 어느정도 씌어놓고서, 해당 bounding box 내 pixel들은 모두 사람으로 여겨버리는 것이죠.
이는 실제 데이터에서도 빈번히 확인할 수 있는 상황으로, 차량과 occlusion되었거나 사람과 occlusion되었을 때에도 annotator는 보이는 영역을 토대로 bounding box를 치다보니 모델은 이를 학습하고자 하는데, 그런 경우는 미미하다는 것입니다. 인간의 추론이 들어간 것에 대한 경우가 적다는 것이죠. 저자는 이를 보강하고자 [0.4, 0.6]의 비율로, 그래도 사람을 조금 더 가져가되, 모두 사람으로 생각하도록 하는 Augmentation을 제안했으며, 이를 Hard Mixup Augmentation으로 명합니다.
Experimental
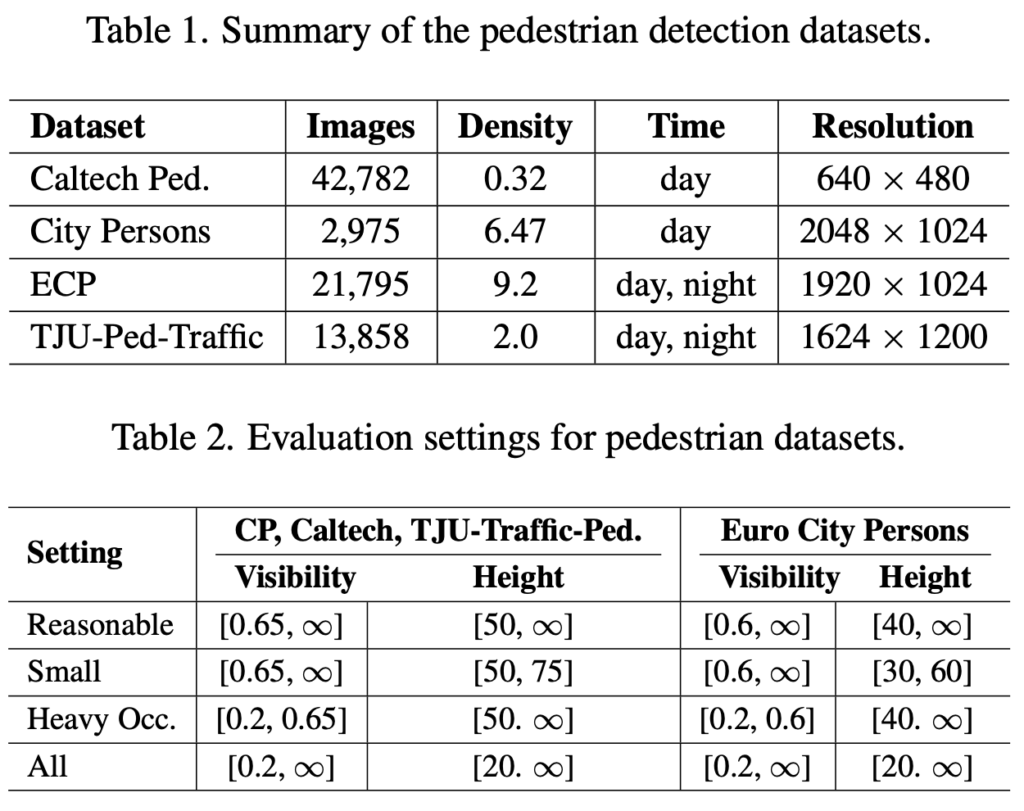
저자가 사용한 pedestrian dataset은 Euro City, CityPerson, Caltech, TJU-Ped-Traffic입니다. TJU-Ped-Traffic은 처음 들어보는데, 조도와 날씨 환경이 다양한 주행 환경에서의 dataset이라고 하네요. 아래 사진을 통해 ‘다양성이 있는 dataset이구나’라고 생각하시면 좋습니다. dataset에 대한 속성 및 평가 방식을 확인하고, 이제 성능을 바로 보겠습니다.

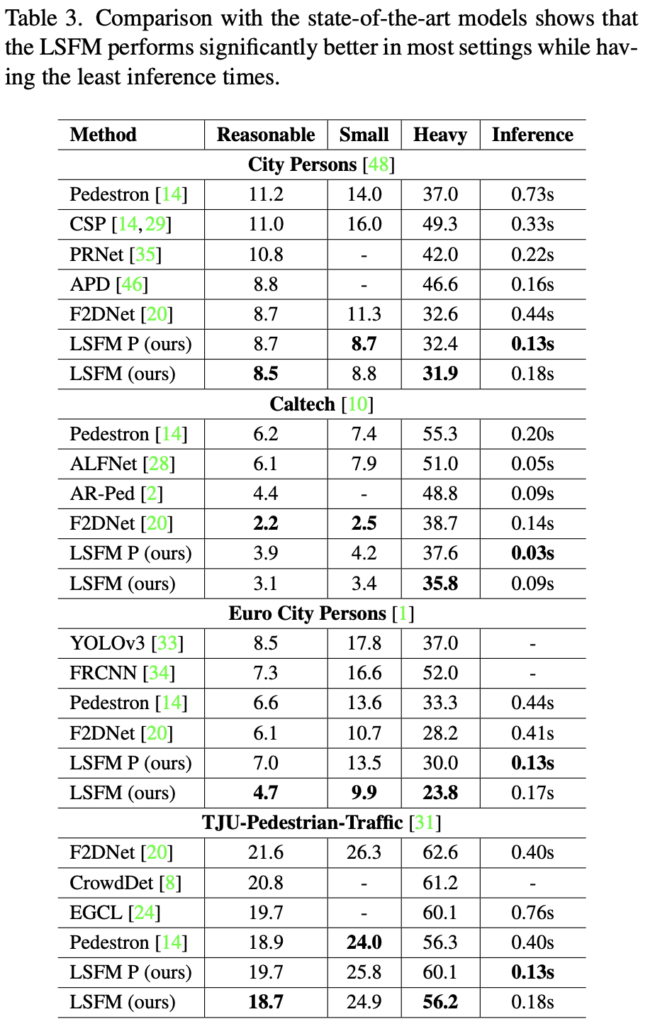
사실 본 논문의 핵심인 Table 3의 성능만 살펴보면 됩니다. LSFM P와 LSFM이 무엇이냐 싶겠지만, 단순히 LSFM P는 ConvMLP-Pin (저자가 제안한)을 backbone으로 사용한, LSFM은 HRNet (최근 SoTA 방법론은 웬만하면 HRNet을 사용합니다. 하지만 HRNet은 그만큼 resource가 엄청납니다)을 backbone으로 사용한 모델입니다.
성능면에서도, 이전 SoTA 모델보다도 더 좋은 것이 신기하네요. MLPMixer는 성능이 CNN, ViT만큼 준수하다고 알뿐 더 좋다고는 하지 않았는데, 어느 면이 성능에 그만큼이나 기여했는지 살펴봐야겠네요. occlusioin에 대한 성능을 증폭시키고자 했다는데, 실제로 보면 굉장합니다. F2DNet도 동일 저자의 1년 전 방법론이지만, 이렇게까지 잘 찾나 싶을정도네요.. 나름 대단하다 싶고 현타도 옵니다.

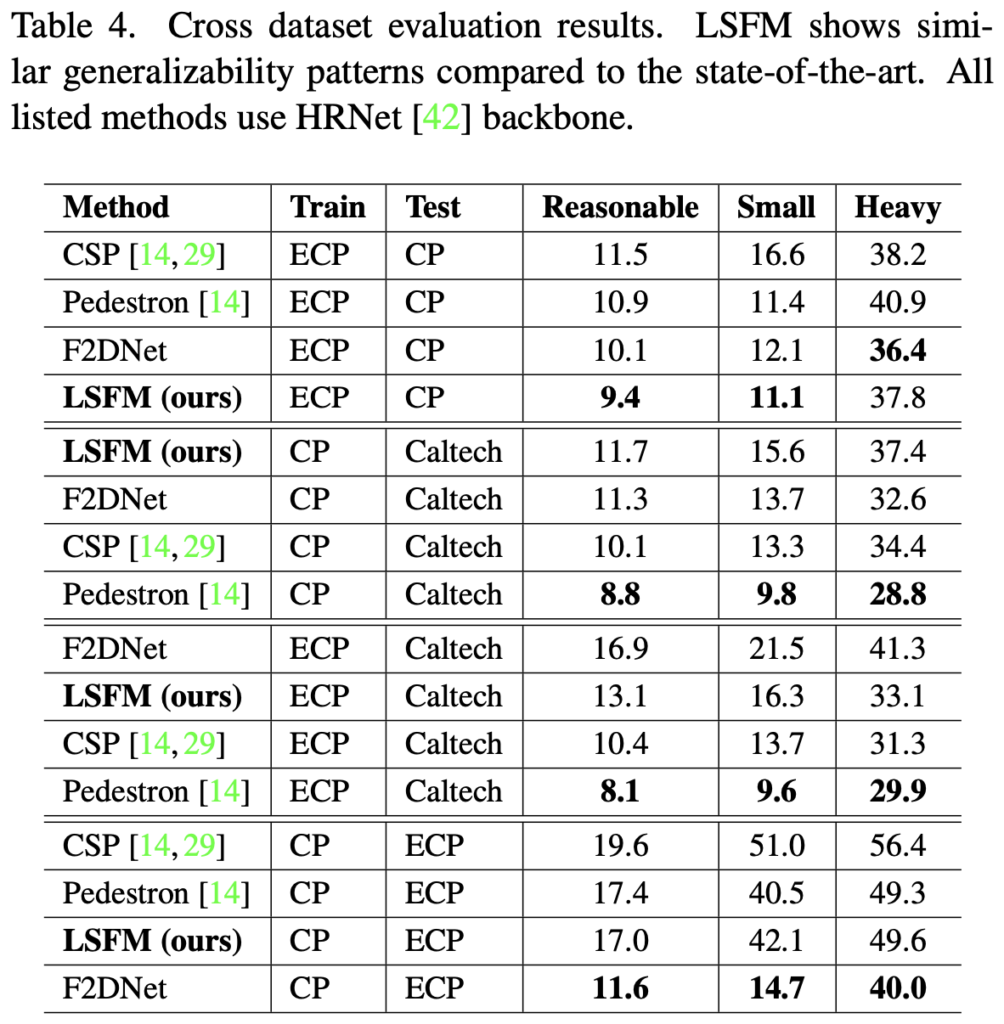
Table 4는 HRNet을 backbone으로 한 모델들의 cross-dataset evaluation 결과입니다. 사실 TJU-Pedestrian dataset 이외에는 Table 3에서 모두 한 자리 수만을 보인 바와는 달리, cross-dataset evaluation을 하면 두 자리 수를 보일때도 있습니다. 이 결과만 보면 pedestron이 제일 좋지 않아?라고 할 수도 있겠네요. pedestron은 일반적인 object detection (cascade HR-Net)을 220 Epoch 수준으로 학습한 모델로, computational resource보다는 “Pedestrian 맞춤형 모델보다 일반적인 detection 모델이 더 일반성이 있다”를 증명한 논문이니, 어찌보면 당연하다고도 볼 수 있겠네요. 그래도 LSFM도 꽤나 준수한 성능을 보입니다. ECP->CP에서만 1등이긴 하네요.
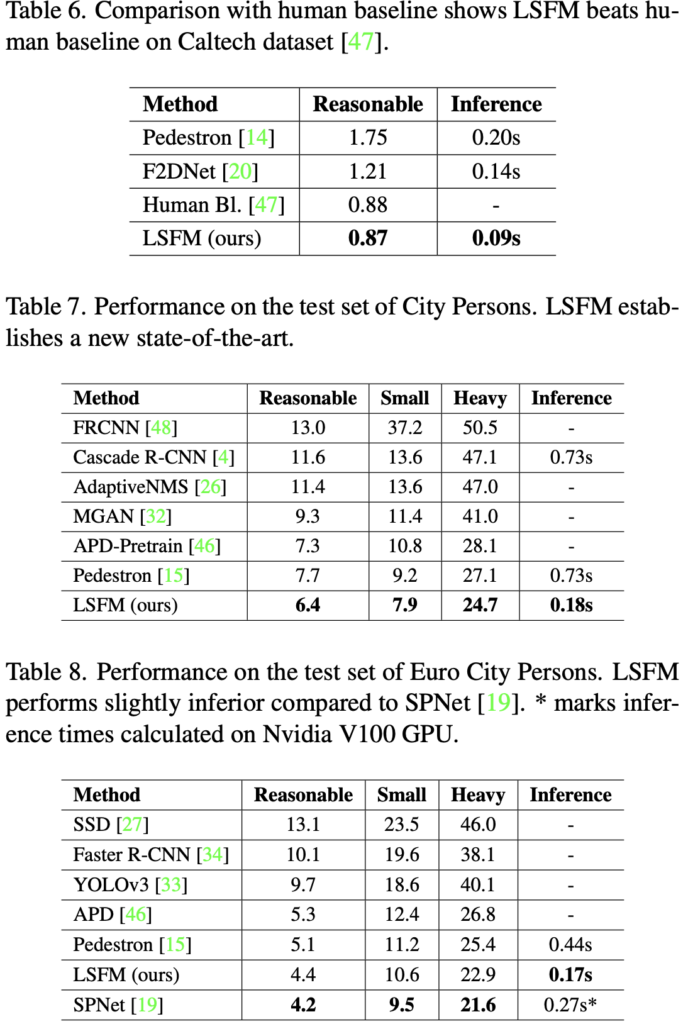
실험이 굉장히 많습니다. 앞서 Human baseline을 처음 돌파했다라고 말헀는데, 이를 보이는 것이 Table 6입니다. 0.88보다도 낮은 MR의 0.87이라니, Inference도 고작 0.09s인 것을 봤을 때, caltech dataset에서의 2D ㅔedestrian detection은 종결난 것 같습니다. Table 7과 Table 8은 Table 3의 결과를 다시 가져오며 기존 SoTA급 모델들과의 성능 비교를 통해 “내 모델이 다 SoTA 찍었다”라고 내세웁니다. SPNet에 비해서는 0.2MR 높긴 하지만, Inference를 살펴보면 더 좋아보이네요.
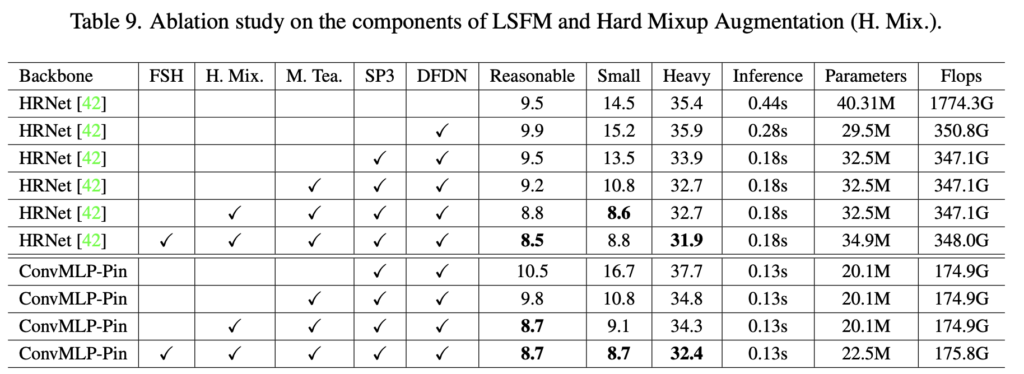
마지막으로 LSFM에서 Backbone과 각 방법론들에 대한 Ablation study입니다. FSH는 Faste Suppression head로, False positive를 줄이기 위한 방법이라고 하는데, 이전 F2DNet에서 소개했다고하니 뭐.. 본인 논문이라 할 말은 없지만 그 논문 먼저 읽어봐야싶었나 하네요.. 가능하다면 세미나때는 읽고서 소개하겠습니다. H. Mix는 Hard Mixup Augmentation, M. Tea는 Mean Teacher로, Knowledge distilation을 통한 overfitting 방지, SP3와 DFDN은 앞서 소개한 방법론들이며 성능 및 Inference 를 비교했을 때 좋은 성능을 보이며 HRNet과도 견줄만하며 0.02의 MR 증가에 비해 0.05s의 Inference를 감소시켰네요. 대단합니다.
금일 자에 소개한 논문은.. 차마 대단하네요. 정말 이 분야는 어느면까지 발전할지 모르겠습니다. 이런 결과를 보면 순간 “어느 것을 해야 성능이 오를까”싶은 마음에 우울해지기도 하네요. 하지만 뭐, 배워나가는 점도 많은 것 같습니다. cross-dataset evaluation에서도 강인한 그런 모델을 만들 수 있을까요. 리뷰 읽어주셔서 감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
방법론은 대부분 잘 설명해주셔서 이해가 되었습니다.
1. Backbone의 바탕으로 사용된 ConvMLP는 실제로 이미지 분류에서 VGG나 ResNet보다 연산량은 적으며 견줄만한 성능을 낸 모델인 것인가요?
2. Cross-dataset evaluation에서 Pedestron의 backbone만 Cascade-HRNet으로 다르다는 의미인지, 아니면 같은 HRNet이지만 220epoch라는 많은 횟수를 학습하여 computational cost가 크다는 것인지 궁금합니다. 사실 inference time으로 효율성을 비교하고 있는 상황에서 학습 횟수가 많다고 성능이 높을 수 있다는 것이 잘 이해되지 않아 여쭤봅니다.
3. 마지막 표의 Ablation에서 Mean Teacher를 이용한 Knowledge distillation 부분도 F2DNet에서 소개한 방식인건가요? 아니면 리뷰에 있는데 제가 놓친 것인지 궁금합니다.
4. 저자가 제안하는 Hard Mixup의 경우, 0.6을 사람으로 준다면 사람의 형체는 온전히 보인다고 할 수 있는데 이 경우가 왜 small에 대한 강인함과 관련 있을 수 있는지가 궁금합니다. 막상 ablation 성능을 보니 heavy 보다는 small에서의 성능 향상이 더 큰것이 의아하여 여쭤봅니다.
안녕하세요. 읽어주셔서 감사합니다.
1. ConvMLP 논문을 읽어봐야만 알 수 있는 내용입니다. 저자는 Resource cost를 줄이는 목적을 위해 들고왔는데, 방금 논문을 살펴보니 ResNet50, ResNet101보다 성능이 좋고 ViT와 견줄만한 성능을 보이네요. Parameter 수는 ResNet50은 25.6M인데 비해 ConvMLP는 17.4M입니다. (ConvMLP도 몇 번의 Block을 반복하는지에 따라 모델 사이즈가 나뉩니다)
2. cross-dataset evaluation이니 아마 Table 4에 대한 질문일텐데, CSP, Pedestrian, F2DNet, LSFM은 모두 HRNet을 backbone으로 취하고 있습니다. 저자는 Pedestron을 Fork해서 해당 실험 환경에서 F2DNet을 만들었고 (CVPR 2022), 올해 LSFM을 만들었습니다. Pedestron에 대해서는 cascade HRNet이라는, pedestrian detector를 위한 모델이 아닌 일반적인 object detector이므로 학습도 일반적인 object detection dataset에서 학습하고, fine-tuning하는 방식을 취합니다. 그러므로 해당 모델은 220Epoch 정도 학습합니다 (다른 모델들은 아닙니다). 학습 횟수라기 보단, Pedestron을 설계한 목적이 cross-dataset evaluation에서 강건하고자 설계하였으니, 그만큼 일반적으로 성능이 좋지 않았을까 싶습니다. Inference time까지 고려한다면, LSFM도 견줄만한 것 같네요.
3. Mean Teacher를 이용한 Knowledge distilation에 대해 작성할까 고민한 부분이였는데, 사실 본 논문에서 말하긴 했는데 고작 몇 줄이여서.. overfitting을 방지하고자.. 저도 정확힌 잘 모르겠습니다. 그래서 내일 권석준 연구원에게 물어본 이후 다시 답글을 수정하겠습니다.
4. Small에 대해서도 중요하지만, Heavy의 성능이 오른 것도 중요하지 않을까 싶습니다. Small에 대해 강인한 것은 원래의 detector가 small-case object를 잘 탐지하지 못한 이유 중 핵심은 “영상 내 보이는 크기가 작은 만큼, 모델이 이해할 수 있을 수준의 Semantic한 정보를 알아내기 어렵다”인데, Mixup augmentation을 통해 pedestrian (object)의 정보가 많지 않은 상황을 만들고 학습하는 파이프라인이, 결과적으로는 small-case에 도움이 되었다고 봅니다. 물론 이 또한 저의 견해일 뿐입니다. 저자는 이유까진 써놓지 않았습니다.
자세한 좋은 리뷰 감사합니다.
마지막에 말씀하신 것처럼 성능을 올리기위해 정말 다양한 방법들을 적용하고있네요.
위에서 언급하신것처럼 저도 unseen data에서 잘 작동하는 것이 자율주행에서 중요하다고 공감이 되는데요, 이렇게 unseen 데이터에서도 잘 작동해야함을 보이고자 cross dataset evaluation을 통해 모델을 평가하는 방식이 2d pedestrian detection 분야에서 해당 논문이 처음 결과를 보인건가요?
그리고 super pixel pyramid pooling에서 transposed convolution과 deconvolution이 엄밀히는 다르다고 하셨는데 어떤 관점에서 다르다고 하신건지 궁금합니다.
마지막으로 anhor-free방법론이라서 생각해본건데 보통 anchor-free의 경우 multi-scale object검출을 위해 FPN구조를 사용하는 것으로 알고있는데, 본 논문에서 FPN대신 적용한 MLP-mixer도 multi-scale object를 검출하는 것을 충분히 고려할 수 있는건지 궁금합니다.
감사합니다.
안녕하세요. 읽어주셔서 감사합니다.
1. unseen data에서 잘 작동하는 것이 중요하다. 사실 딥러닝이 왜 필요한지, 사람들은 딥러닝의 연구에 환호하는 것이 아닌 ChatGPT와 같은 Application에서 사용되는 딥러닝에 환호하는 것이라고 생각하는데 그렇다면 ChatGPT처럼 우리가 문법 하나 지키지 않고 친구한테 말하듯이 써도 잘 알아서 답변해주는 그런 딥러닝을 위해선 어떤 점이 우선시 되어야하는지 생각해보면, cross-dataset evaluation은 앞으로도 중요한 지표로 자리잡아야하지 않을까 생각이 듭니다. 이러한 방법은 “Pedestron”을 제안한 논문에서 처음 등장하였으며, 그 논문은 지난 번 세미나에서 말씀드린바와 같이 일반적인 모델의 중요성을 언급합니다.
2. 우선 Transposed convolution은 일반적인 CNN과 달리 Upsampling을 진행함은 알고 있을 것입니다. input보다 output의 Feature map size가 커지는 형태이죠. 그 때의 Transposed convolution은 “얼만큼 upsampling할지를 계산하여, Dilated convolution처럼 사이사이 0으로 매꾼 다음 convolution을 진행하여 Feature map 사이즈를 늘립니다. 반대로, Deconvolution도 upsampling이긴 하나, convolution 연산과정에서 사용한 kernel, output을 통해 convolution되기 이전의 Feature map으로 되돌리는, 정확히 수학적으로 convolution의 역연산에 해당합니다. 다시 Transposed convolution은, 원본을 찾는다기 보단 지금 상태에서 늘리고자 zero-padding insert 이후 학습을 통해 그럴싸한 Feature map을 찾아나가는 연산 과정에 해당합니다. 엄밀히, 둘은 Upsampling 과정이나 수학적, 코드적으로도 다른 과정에 속합니다.
3. MLP-Mixer의 SP3 방법이, FPN을 따라가고자 설계한 부분입니다. 해당 방법에서 Multi-scale의 Feature map의 상응하는 Spatial location의 토큰(패치)를 Concat.하고 FC layer를 통해 하나의 Feature map (P*P*S)로 만드는 과정이 FPN에 대응되는 동일한 연산입니다.
좋은 질문 감사합니다.
리뷰 잘 읽었습니다.
augmentation 쪽에서 질문? 혹은 의문점이 하나 있습니다.
motion blur 현상을 언급하면서 augmentation 기법을 설계한 거 같은데요, 실제 자율주행 관점에서 해당 센서가 읽어오는 이미지들에 motion blur 현상이 많을까요?? 혹은 이에 대한 저자의 언급이 있나요?
실제 상황에서 셔터스피드를 너무 빠르게 세팅한다면 너무 어두워지기 때문에 motion blur 현상은 어쩔수 없이 발생하게 되므로 저자가 제안한 aug 기법이 효과를 볼까요?
real 한 상황에서에 대한 궁금증입니다 ㅎ.
감사합니다.
네 안녕하세요. 리뷰 읽어주셔서 감사합니다.
네 그렇습니다. 실제 자율주행 시에도 자동차는 일정한 속도로 이동하지만은 않으니, 속도의 변화로 인한 Motion blur, 카메라에 서리가 낀 상황, 좌회전, 우회전, 유턴과 같은 자동차의 이동 등에도 포함될 수 있습니다.
만약 실제 자율 주행차량이 등장한다한들, Shutter speed를 너무 빠르게 세팅할 이유는 없을 것 같습니다. 막상 그만큼의 정보를 바로바로 분석하는 것이 Real-time일지언정, 사람이 인지하는 수준만큼만 받아들여와도 문제는 없을 것 같다고 생각이 듭니다. 실제 Motion blur 시 저자의 Augmentation이 유용할지는 사실 잘 모릅니다. 왜냐하면 그런 데이터들을 취득하진 않았기 때문이죠. 실제 상황에선 Motion blur 시 보일 수 있는 점은 예상 가능할뿐 실제로 딥러닝 모델이 어떻게 받아들일지는 그래도 미지수입니다. 하지만 연구 측면에서, “그럴 수 있는 상황”을 만들고자 한 점에서 고찰이 좋은것 같습니다.
좋은 리뷰 감사합니다.
computational cost를 낮추기 위해, CNN과 transformer를 활용하던 기존의 방법론을 적절히 MLP로 바꾼 논문으로 이해하였습니다.
리뷰와 관련하여 간단한 질문이 있습니다. Figure 3의 결과는 어떻게 이해를 하면 되는지 설명해주실 수 있나요? 우선 4개의 열은 어떤 것을 의미하는지 궁금합니다. 또한, SP3에 대한 결과들을 통해, 사람의 중심에 해당하는 부분에 집중한 것을 보이고자 한 것인가요?
안녕하세요. 리뷰 읽어주셔서 감사합니다.
큰 대목에서, CNN,ViT를 대체한, 그러면서 성능도 더 좋고 Inference time도 더 빠른 MLP로 바꾼 논문이 맞습니다.
Figure 3에 대해 설명했는데?싶어 리뷰를 다시 봤는데, 적는다 생각하고 안 적었네요. First, Second, Thrid는 리뷰에서 언급한 Conv-MLP Stage에서 MLP Blocks의 수를 4, 8, 4로 가져가는 그 첫 번째 (Conv Stage), 나머지 세 Conv-MLP Stage의 Feature map 결과입니다.
이 때, Conv Stage는 물론 Conv-MLP Stage에서도 Feature map이 Semantic한 정보를 학습하면서도 동시에 Feature map size도 달라지는데, 이를 모두 모으고자한 방법이 리뷰에서 언급한 SP3이므로, SP3가 가장 “사람을 잘 Attention하고 있는 Feature map의 모습”을 가지고 있다고 보면 좋을 것 같습니다. 네 그렇죠. 사람의 중심에 해당하는 부분에 집중한 것을 보이고자 한 것입니다. 제가 리뷰에서 쓰려하고 놓친 부분이네요. 짚어주셔서 감사합니다.
이상인 연구원님, 좋은 리뷰 감사합니다.
오랜만에 pedestrain detection 분야의 리뷰를 읽어보는데, 현실적인 자율주행의 문제를 풀기 위해 고민하는것이 당연한 것인걸 알지만서도 해당 부분에 온전히 집중한 것이 낯설었습니다. 저도 URP challenge 시절에 inference time과 occlusion에 대해서는 후순위로 밀어두고 MR을 낮추는 것에만 집중했던 기억이 있네요. 성능 몇 % 올리는것보다는 실제 상황에 안정적으로 동작하는것이 더 중요할 것인데.. 무엇에 집중해야 하는지 생각해 보게 되는 도입부였습니다.
MLPMixer라는 방법론에서 MLP만 사용하였지만 CNN, transformer에 준하는 성능을 보였다는것에서 흥미로웠습니다. 일반적으로 vision에서는 MLP가 적합하지 못하다 라는 인식이 있었는데, memory, computational resource, higher inference speed라는 현실적인 문제를 해결하기 위해 MLP backbone을 도입하였고 SOTA를 갈아치우는 모습이 신기했습니다. 추가적인 백본 공부의 필요성을 느끼네요. 좋은 논문 리뷰해 주셔서 감사합니다.
몇가지 간단한 질문이 있습니다.
1. super pixel pyramid pooling은, cnn으로 학습이 진행되는 feature pyramid에서 각 feature map들을 flatten해서 concat한 것으로 이해했는데, 제가 올바르게 이해한 것인가요?
2. Figure 1의 MLP 부분에서 GELU가 무엇을 의미하는지 궁금합니다. ReLU같은 activation function인가요?
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
우선, 그런 실제 상황을 고려하는 것이 연구자도 반드시 고려해야할 일일지는 또 의문입니다. 그럼에도 사람들의 Needs를 파악하는 것은 중요하겠죠.
1. 네. 해당 부분은 정확히 이해하셨습니다. 단순 Flatten해서 Concat한다기 보다, 상응하는 Spatial location의 패치를 Concat해줍니다.
2. 네. GELU는 ReLU 이후 등장한 Activation function으로, 0근처의 음수 부분에서 조금 유연한 모습의.. 그런 Activation function입니다. 구글링해보면 재미있는 모습의 그림을 볼 수 있습니다.
안녕하세요 상인님. 좋은 논문 리뷰 감사합니다.
MLPMixer을 통해, 낮은 연산량으로 self-attention의 역할 대신할 수 있다는 점이 인상 깊었습니다.
그러나 지금 현재로는 제가 아는바로는 MLPMixer가 아닌 경량 task에서도 transformer를 사용하는 것으로 알고 있습니다.
그렇다면 MLPMixer가 잘 사용되지 않고 transformer가 사용되는 이유로는
MLPMixer가 너무 많은 데이터셋을 필요로하고,
낮아진 성능에 비해 정확도의 trade-off가 크기 때문이라고 생각하면 될까요?