안녕하세요. 열 번째 X-Review입니다. 금주 리뷰할 논문은 AAAI 2020에 게재된 <Real-time Scene Text Detection with Differentiable Binarization>입니다. 본 논문 저자는 지지난번 리뷰했던 Mask TextSpotter 논문의 저자와 동일한 분이네요 . . . . 바로 리뷰 시작하도록 하겠습니다. ?
Introduction
scene text reading이나 scene text detection의 주요한 목표는 text instance 영역을 localize하는 것인데, 이는 여전히 challenging한 task입니다. 그 이유로는 scene 이미지에 있는 text들이 다양한 크기, 모양을 가지고 있으며 회전되어 있거나 곡선 형태로 존재하기 때문입니다. segmentation 기반의 scene text detection은 pixel-level의 예측 결과를 바탕으로 다양한 모양을 가지는 text를 커버할 수 있기에 많이 주목을 받아왔지만, 대부분의 segmentation 기반 방법론들은 text를 검출하기 위해 pixel-level의 예측 결과를 grouping하기 위한 복잡한 후처리 과정이 필요하다는 단점이 있습니다.
2021년 SOTA를 달성하는 2개의 segmentation 기반의 scene text detection 방법론을 예시로 들어보자면, PSENet같은 경우 progressive scale expansion 후처리 과정이 요구되었으며, Pixel embedding in 방법론 같은 경우 pixel을 clustering하는 후처리 과정에서 pixel간의 feature distance들을 계산을 하는 과정이 요구되었습니다.
위의 두 예시와 비슷한 후처리 방식을 사용하는 detection 방법론의 파이프라인은 아래 [Fig2]에서 살펴볼 수 있습니다.
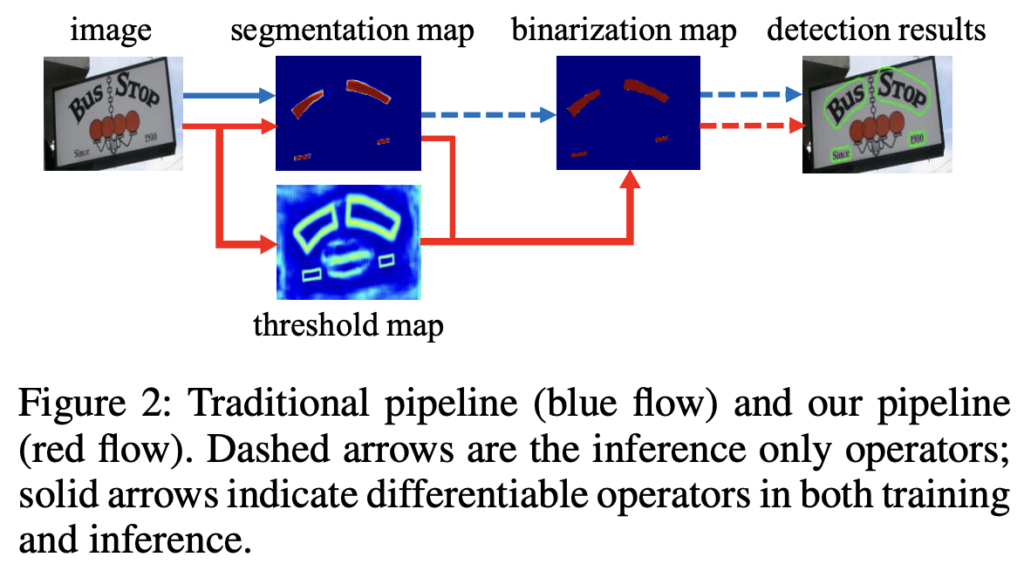
[Fig2]에서 파란색 화살표가 기존 post processing 방식을 사용하는 detection파이프라인인데요, 보시면 먼저 segmentation network에서 예측한 probability map을 binary 이미지로 변환하기 위한 threshold를 사전에 설정해 놓습니다. 그 다음 pixel들을 text instance들로 grouping하기 위해 pixel clustering과 같은 heuristic 기술을 사용합니다.
이런 기존 방식에 대안으로, 저자들은 빨간색 화살표의 파이프라인을 제안합니다. 차이점이라 함은 threshold map이 추가되었고, 이 threshold map과 segmentation map(probability map)을 가지고 binarization map을 생성하는 것이네요. 저자들은 이 binarization 연산 과정을 network에 포함시켜 학습하고자 하였고, 이렇게 함으로써 이미지의 모든 위치에서 threshold 값을 adaptive하게 예측하여 foreground와 background의 pixel을 완전히 구분할 수 있게 됩니다. 하지만, 기존 binarization function는 미분가능하지 않기 때문에 저자들은 대신 segmentation 네트워크와 함께 학습할 수 있도록 완전히 미분 가능한 Differentiable Binarization (DB)를 제안합니다.
본 논문의 주 contribution은 이 미분 가능한 DB 모듈을 제안한 것입니다. 이로 인해 binarization 과정을 end-to-end로 학습가능하게 만들었죠. 이 DB 모듈과 간단한 semantic segmentation 네트워크를 합침으로써 text를 빠르고 정확하게 검출할 수 있는 detector를 제시할 수 있게 되었습니다.
논문의 4가지 contribution은 다음과 같습니다.
- 5개의 scene text benchmark dataset에 대해 더 나은 성능 달성
- DB를 통해 후처리 과정을 간단히 함으로써, 이전 scene text detection 방법론들보다 더 빠른 속도
- DB는 light-weight backbone을 사용했을 때 꽤 잘 동작함
- Inference 과정에서는 DB를 사용하지 않아도 성능이 저하되지 않기에, test를 위해 추가적인 메모리/시간 비용이 들지 않음
Methodology
본 논문의 방법론의 전체적인 구조는 아래 [Fig3]과 같습니다.
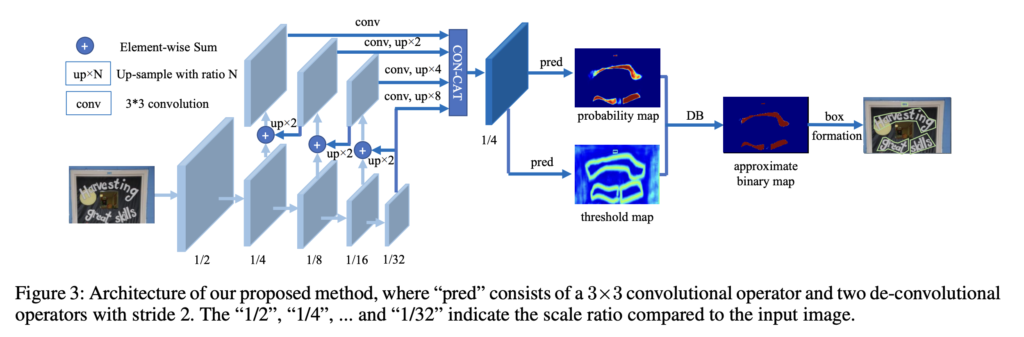
동작 과정을 살펴보자면, 먼저 input 이미지가 feature-pyramid backbone으로 들어가게 되고 여기서 추출된 pyramid feature들은 같은 크기로 up sampling한 후, concat하여 feature map F를 생성해냅니다. 그 다음 이 feature map F는 probability map (P)와 threshold map (T) 이 두 map을 예측하게 되고 마지막으로 backbone으로부터 추출된 feature map F와 그로부터 예측한 probability map(P)를 가지고 approximate binary map을 계산해냅니다.
학습할 때에는 probability map, threshold map, approximate binary map에 대한 label을 가지고 supervised learning을 수행하며, inference 과정에서는 box formulation module을 사용하여 probability map과 approximate binary map 둘 중 하나만을 가지고 쉽게 bounding box를 얻어낼 수 있습니다. 보다 자세한 내용은 아래에서 다시 언급하도록 하겠습니다.
Binarization
Standard binarization
segmentation network로부터 probability map(P ∈ R^{H*W})이 생성되면, 이를 가지고 text가 있을법한 영역의 pixel값을 1로 변환하여 binary map(P ∈ R^{H*W})을 만들 수 있습니다. 일반적으로 이 binarization 과정은 아래 식으로 표현할 수 있겠습니다.
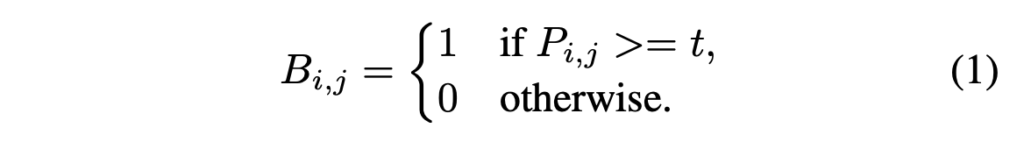
- t : 사전에 설정한 threshold
- (i, j) : probability map 내의 좌표점
Differentiable binarization
위에 standard binarization 식은 미분가능하지 않습니다. 즉, 이건 segmentation network와 함께 학습할 수 없다는 말이 되겠죠. 이러한 문제를 해결하기 위해 저자들은 아래 식을 통해 binarization을 수행하고자 하였습니다.
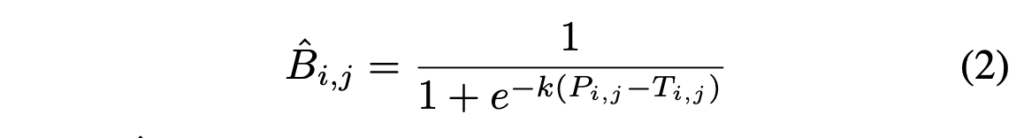
- \hat{B}_{i,j} : approximate binary map
- T : network에서 학습한 adaptive threshold map
- k : amplifying(증폭) 계수
k는 실험을 통해 50으로 설정되었습니다. 이 approximate binarization function은 standard binarization function과 거의 유사하게 동작하지만 미분가능하다는 차이점을 가지고 있으며, 이로 인하여 segmentation network와 함께 학습하는게 가능합니다.
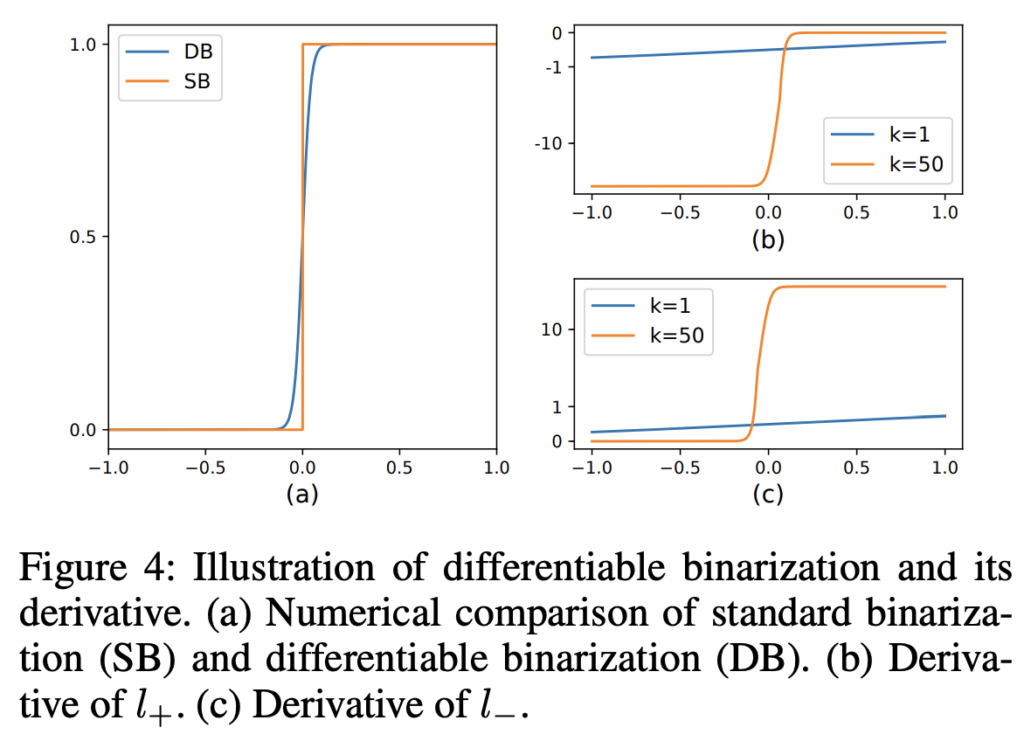
[Fig4]의 (a)를 보면 Standard binarization과 Differentiable binarization을 비교한 것인데, 거의 유사하게 동작함을 확인할 수 있습니다.
adaptive한 threshold를 사용하는 differentiable binarization은 text 영역을 background와 구별할 수 있게 할 뿐만 아니라 가까이 붙어있는 text instance를 구분하는데도 도움이 된다고 합니다. 이후 실험파트에서 보여드릴 정성적 결과로 확인해보면 되겠습니다 . .
저자는 Differentiable binarization(DB)를 사용하면 성능이 향상되는 이유를 gradient의 backpropagation으로 설명합니다. Binary cross entropy loss를 예시로 들어보겠습니다.
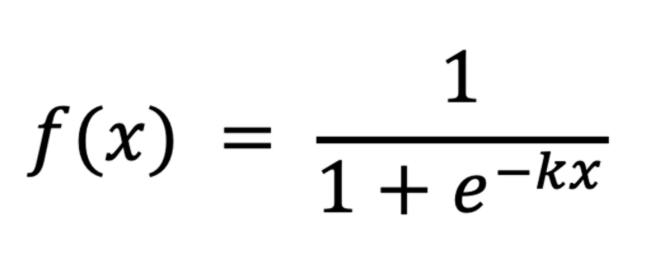
- x : P_{i,j} – T_{i,j}
- P : probability map
- T : threshold map
- k : amplifying(증폭) 계수
DB 함수로 위 함수를 사용한다고 정의한다면(기존 DB식과 동일한 식임..), positive label에 대한 loss l_+와 negative label에 대한 loss l_-는 아래와 같습니다.
식에서 x가P_{i,j} – T_{i,j}이기 때문에 positive label이라 함은 probability map(P)에서 i,j 좌표의 pixel 값이 threshold map에서 i,j좌표의 pixel 값보다 큼을 의미하고, negative label은 이의 반대를 의미하겠습니다.
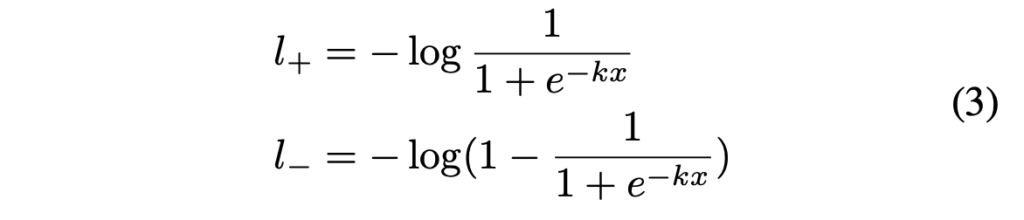
이걸 chain rule을 이용하여 미분을 한다면, 아래와 같이 나타낼 수 있겠죠.
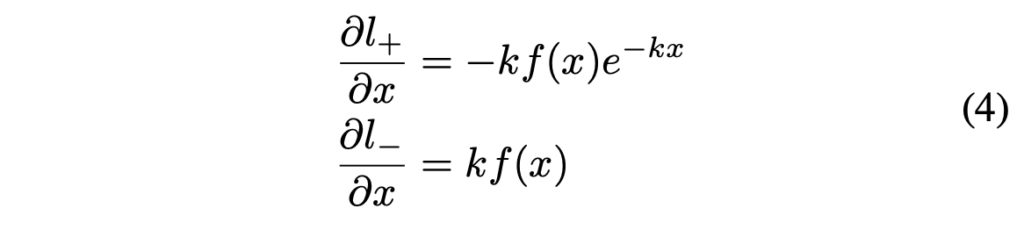
미분 결과를 통해 알 수 있는 것은 두가지 입니다. 1) gradient가 amplifying factor(증폭 계수) k에 의해 증가한다 는 것과 2)positive label과 negative label은 서로 다른 scale로 최적화된다는 것입니다.
f(x)가 1에 가까울수록 gradient 증폭이 크게 일어나며, 이는 더 예측을 잘하도록 도와줍니다. 또, x는 P_{i,j} – T_{i,j}이므로 P의 gradient가 T에 영향을 받고 재조정되겠죠. 이로인해 더 정확한 예측을 할 수 있게 됩니다.
Adaptive threshold
위 threshold map은 [Accurate Scene Text Detection through Border Semantics Awareness and Bootstrapping] 논문에서 제안된 text border map과 유사합니다. 아래 그림 중에 왼쪽이 본 논문의 threshold map이고 오른쪽 그림이 text border map입니다.

하지만, 이 두 map은 외관상 유사할 뿐 그 사용 목적이나, 방법은 다릅니다. ( 솔직히 외관도 그렇게 닮았다고 볼 수는 없을것 같습니다만,, ) 특히 threshold map은 text border map과 다르게 supervision 없이도 text의 경계 영역을 감지할 수 있다는 특성을 가지고 있습니다. 다시 말하자면 threshold map이 자체적으로 text의 경계 영역을 강조할 수 있다는 것입니다.
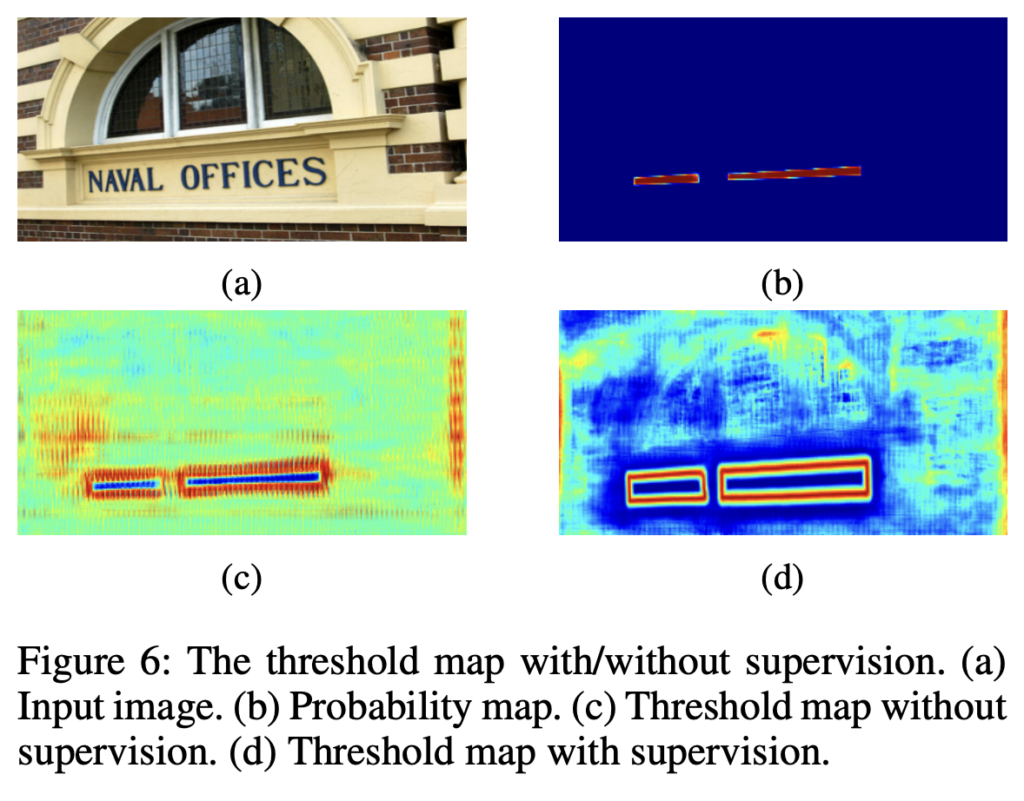
[Fig6]에서 (a)가 input 이미지로 들어갔을 때 supervision 없이 학습한 경우의 threshold map이 (c)이고, 지도학습한 경우의 threshold map이 (d)입니다. (c)를 보면 자체적으로 text의 border 영역을 잘 감지하고 있지만, supervision으로 학습한 경우가 좀 더 명확하고 선명하게 text의 경계를 감지하고 있습니다. 그렇기에 저자는 threshold map에 border supervision을 적용하여 보다 명확하게 text border를 감지하도록 하여 text detection 성능을 향상시키고자 하였습니다.
Deformable convolution
저자는, text의 aspect ratio가 극단적인 경우를 deformable convolution을 사용함으로써 다루고자 하였고, 타 논문(Zhu et al. 2019)를 참고하여 backbone으로 사용하는 ResNet18, ResNet50의 conv3, conv4, conv5 단계에서 3×3 conv layer에 대해 modulated deformabel convolution을 적용하였습니다.
Label generation
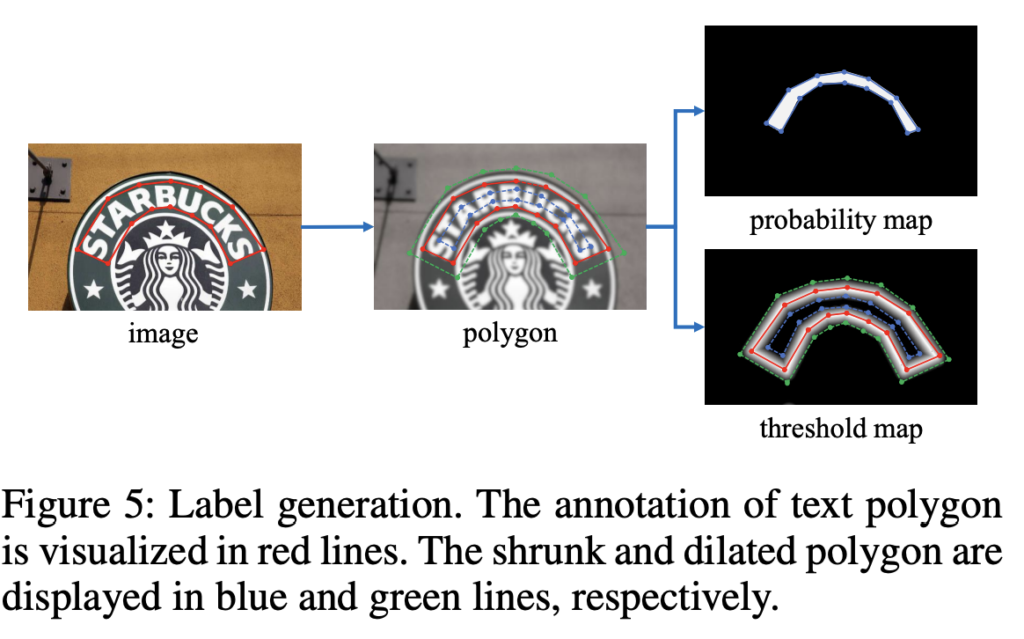
이제 probability map과 threshold map에 대한 label을 생성하는 과정에 대해 설명드리겠습니다. probability map에 대한 label을 생성하는 방법은 PSENet에서 영감을 받았습니다.
이미지에 text가 존재할 때 각 polygon(다각형) text 영역은 text를 둘러싸는 segment(선분)들의 집합으로 나타낼 수 있으며, 이는 아래 식으로 표현할 수 있습니다. [Fig5]에서 image의 빨간색 선에 해당하겠네요.
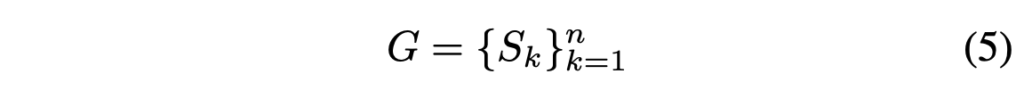
- S_k : polygon text의 k번째 segment(선분)
- n : polygon 꼭짓점 수 (ex. ICDAR 2015 dataset같은 경우 4, CTW1500 dataset같은 경우 16)
- G : polygon
이렇게 다각형 text를 G로 나타내었다면 Vatti clipping 알고리즘을 이용하여 G를 G_s로 축소하여 positive area를 생성해냅니다. 잘 안보이시겠지만, [Fig5] polygon 그림에서 빨간색 다각형 내부에 파란색으로 축소된 다각형이 이에 해당합니다. 여기서 positive area는 text가 존재하는 영역을 의미하는데, 그렇다면 bounding box를 그대로 사용하면 되지 않나 의문이 들 수 있지만, text가 불규칙한 경우 형태를 좀 더 명확히 나타내기 위해 축소하는 것이라고 생각하면 됩니다. 이렇게 다각형을 축소하여 positive area를 생성하게 되면 text 영역의 실제 형태를 더 잘 반영할 수 있겠죠. G를 shrink(축소)한 G_s, 즉 positive area를 생성해내었다면 이 내부 pixel들은 text 영역에 해당하는 것이기에 label을 1로 할당하고, 이외의 pixel들은 label을 0으로 할당하여 probability map에 대한 label을 생성할 수 있게됩니다.
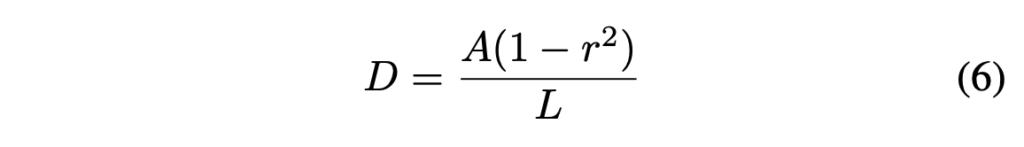
- L : original polygon의 둘레
- A : original polygon의 넓이
- r : shrink(축소) 비율
위 식은 original polygon을 얼마나 shrink(축소)할지 offset을 계산하는 식인데, 여기서 r은 실험적으로 0.4로 설정되었습니다.
이렇게 probability map의 label을 생성하는 방식과 유사한 방식으로 threshold map의 label을 생성할 수 있습니다. 먼저 probability map label을 생성할 때 계산했던 offset D만큼 text polygon G를 팽창시켜G_d를 만듭니다. 이렇게 polygon을 D만큼 팽창시킨 것이 [Fig5]의 threshold map과 polygon 이미지에서의 초록색 다각형에 해당합니다. threshold map은 text region의 border, 즉 경계를 나타내는 map이였죠. 저자는 다각형 G를 축소한 버전인 G_s와 확대한 버전 G_d사이의 간격을 text region의 경계라고 보았습니다. [Fig5]의 threshold map 그림을 보면 초록색 다각형과 파란색 다각형 사이가 흰색으로 채워져있는 것이 이에 해당하겠네요. 최종적으로 threshold map label은 text region의 경계라고 본 영역 내의 각 pixel들과 G 내의 가장 가까운 선분과의 거리를 계산하여 생성됩니다. 거리가 가까울수록 해당 pixel은 text region에 더 가깝다는 의미로 label을 할당하는 것입니다. 그래서 [Fig5]의 threshold map label 부분을 보면, G의 segment들인 빨간색 선분에 가까울수록 더 하얗게, G_s, G_d에 가까울수록 더 어둡게 보이네요.
Optimization
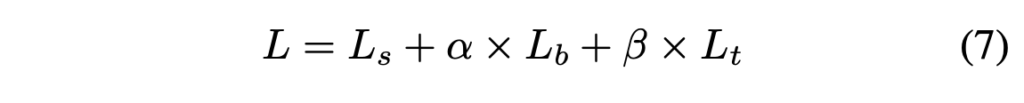
- \alpha : 1.0
- \beta : 10
loss는 위와 같이 probability map loss L_s, binary map loss L_b, threshold map loss L_t의 가중합으로 표현됩니다.
probability map loss L_s와 binary map loss L_b 둘은 binary cross entropy loss이며, positive와 negative의 불균형을 맞춰주기 위해 hard negative mining기법을 사용하여 hard negative들을 sampling해 사용하였습니다.
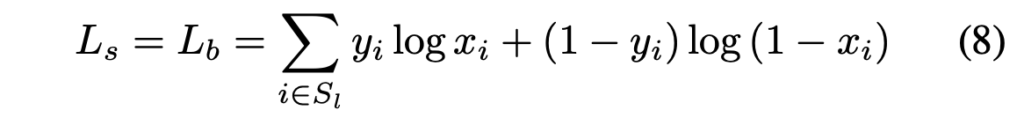
- S_l : positive와 negative를 1:3 비율로 sampling한 set
threshold map loss는 dilated된 text polygon G_d내에서 예측 결과와 label간의 L1 distance의 합으로 계산됩니다.
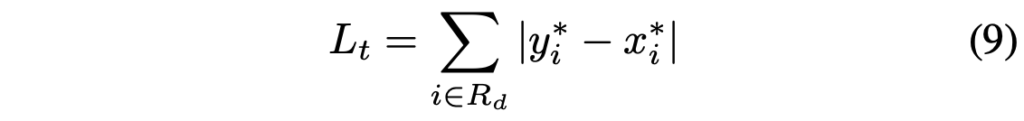
- y^*_i : threshold map label
- x^*_i : threshold map prediction
- R_d : dilate된 polygon G_d내부 픽셀들 index 집합
Inference 과정에서는 probability map 또는 approximate binary map 둘 중 하나를 사용하여 text bounding box를 생성해낼 수 있습니다. 두 map은 거의 동일한 결과를 내뱉기 때문에 아무거나 사용해도 괜찮습니다만, 저자들은 효율성 측면을 고려하여 probability map을 사용하여 bounding box를 생성하도록 하였습니다. 이는 inference 과정에서 trheshold branch가 사용되지 않기 때문에 approximate binary map을 사용하여 bbox를 생성하는 것보다 더 효율적이겠습니다.
bounding box를 생성하는 과정은 세 단계로 이뤄집니다. 1) probability map/approximate binary map을 0.2의 threshold를 이용하여 이진 map으로 만듭니다. 2)이진맵에서 연결된 영역, 즉 shrink(축소)된 영역을 얻어냅니다. 3) 축소된 영역은 Vatti clipping 알고리즘을 사용하여 offset D만큼 확장됩니다. 이렇게 확장된 box가 최종적으로 생성해낸 bounding box에 해당합니다.
아래식은 offset D를 계산하는 식입니다.
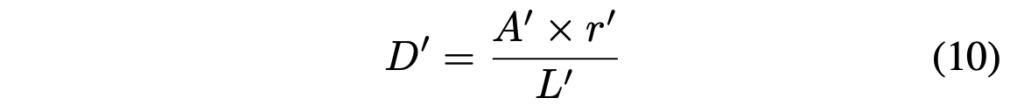
- L’ : shrink polygon 둘레
- A’ : shrink polygon 넓이
- r’ : dilated 비율 (1.5로 setting)
Experiments
실험파트에서 사용한 데이터셋은 MLT-2017 dataset, ICDAR 2015 dataset, MSRA-TD500 dataset, CTW 1500 dataset, TotalText dataset이며, 모델을 사전학습할 때는 800만개의 이미지로 구성된 합성 데이터셋인 SynthText를 사용하였습니다.
Ablation study
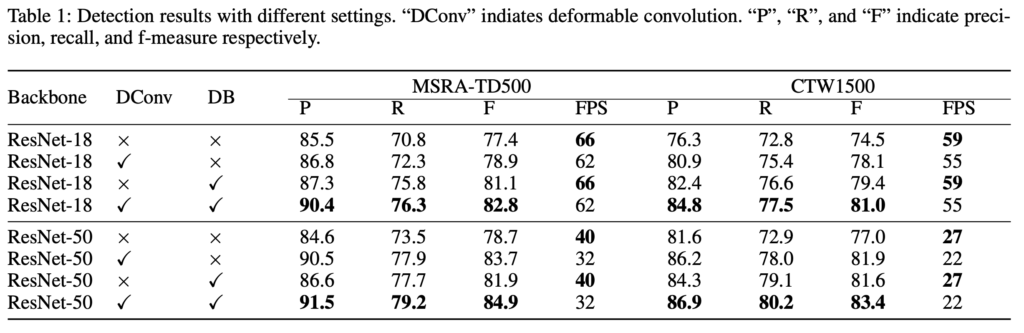
저자는 MSRA-TD500 데이터셋과 CTW1500 데이터셋으로 Differentiable Binarization(DB), Deformable Convolution, 여러 backbone 모델에 대해 대한 ablation study를 수행하였습니다. 밑에 table에서 P, R, F는 각각 precision, recall, f-measure을 의미합니다.
Differentiable binarization
[Table1]에서 DB를 사용한 경우와 사용하지 않은 경우의 성능을 비교해보면 Differentiable binarization이 두 데이터셋에 대해 성능을 향상시킨 것을 확인할 수 있습니다. 예를 들어 ResNet18 backbone을 사용한 경우 MSRA-TD500과 CTW1500 데이터셋에서 F-measure 기준으로 각각 3.7%, 4.9%의 성능 향상을 보이네요. 여기서 볼만한 점은 inference를 수행할 때 DB가 사용되지 않기 때문에 FPS가 DB를 적용하지 않았을 때와 동일하다는 점입니다.
Deformable Convolution
DConv는 backbone model에 flexible한 receptive field를 제공함으로써 성능을 향상시킬 수 있습니다. 실험 결과를보면 DConv를 사용하면 사용하지 않았을 때에 비해 FPS가 조금 줄어들긴 하지만 성능이 더 높습니다.
Supervision of threshold map & Backbone
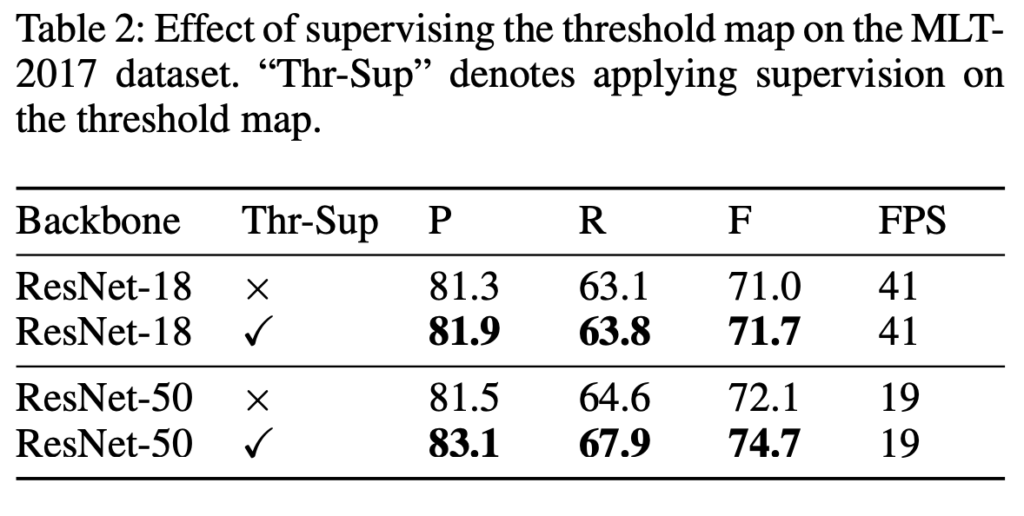
threshold map은 이미지에 존재하는 text의 border 영역을 나타내는 map이였습니다. 저자는 이 threshold map에 대해 supervision의 유무에 따른 ablation study도 수행했는데, [Table2]에서 Thr-Sup이 체크된 부분이 지도학습 기반으로 threshold map을 학습한 것입니다. 결과를 보시면 supervision으로 학습한 경우 MLT-2017 데이터셋에서 ResNet18 backbone을 사용한 경우 0.7%, ResNet50 backbone을 사용한 경우 2.6%의 성능 향상이 있네요.
또, [Table1]을 보면 resnet50과 resnet18에 대한 성능이 각각 리포팅 되어있는데, 한눈에 봐도 resnet50이 성능이 좋은 것을 볼 수 있습니다. 당연하게도 FPS는 떨어진 것도 확인할 수 있습니다. . .
Comparisons with previous methods
Curved text detection
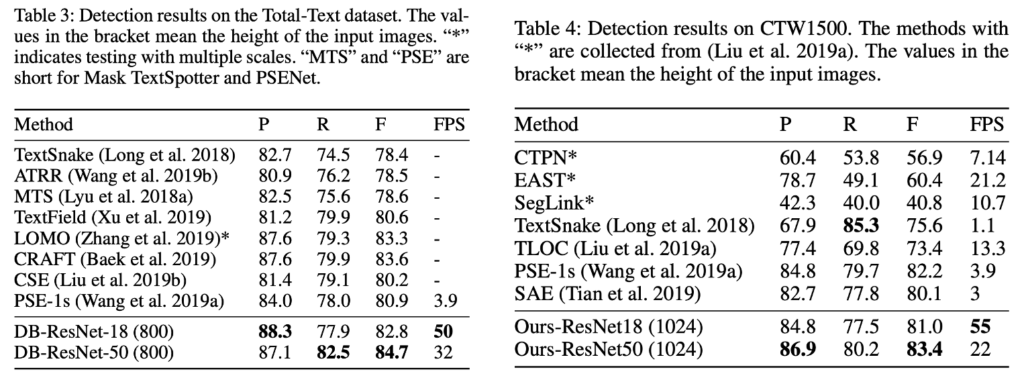
저자는 곡선 text dataset인 total-text, CTW1500 데이터셋에 대해 curved text detection 성능을 확인하였습니다. 위 표들에서 확인할 수 있듯이, 본 논문의 저자가 제안한 방법론이 가장 좋은 성능을 달성하였습니다. [table4]를 보면 이전 모든 방법론보다 DB-REsNet50(ours-ResNet50)이 가장 빠르게 동작하며, resnet18을 사용하게 되면 이보다 더 빠르게 동작할 수 있죠.
Multi-oriented text detection
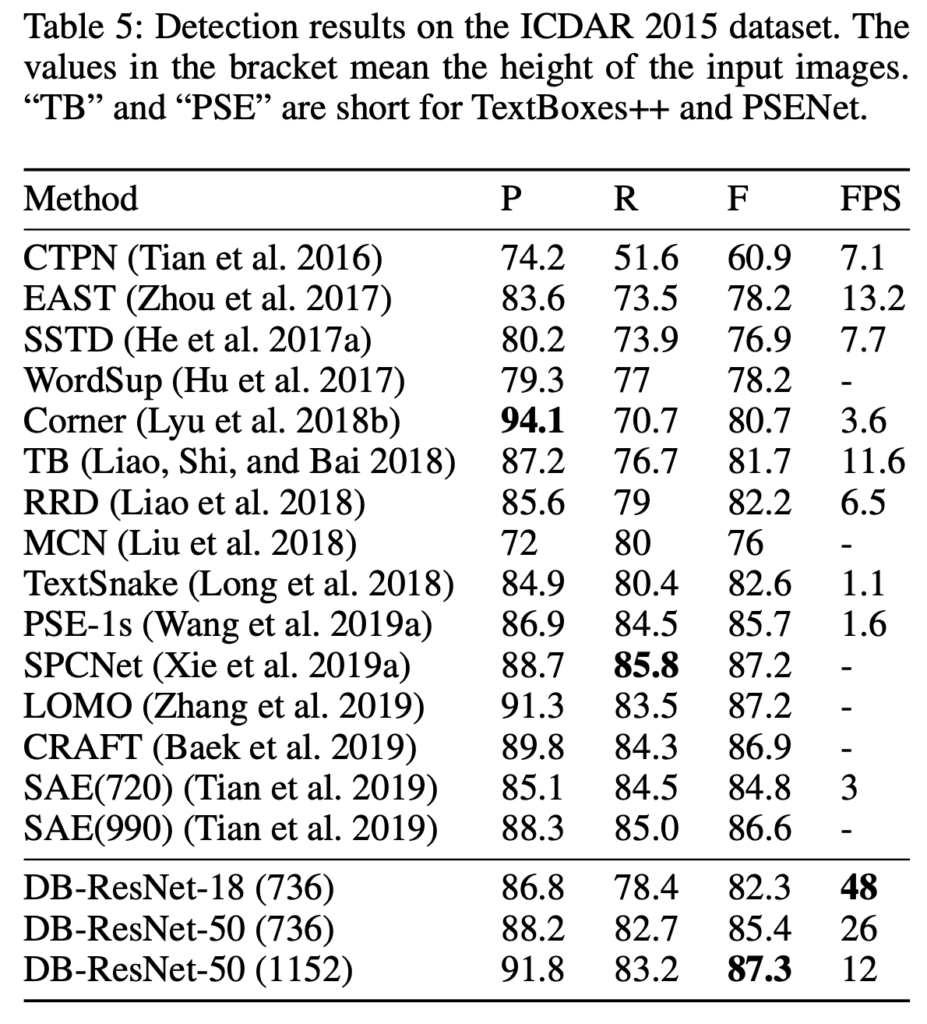
ICDAR 2015 데이터셋은 text 크기가 작고 해상도가 낮은 multi-oriented text instance를 포함하고 있는 데이터셋입니다. 음 .. 이 데이터셋에서는 성능이 그렇게 좋다고 할 수는 없겠습니다만 확실히 post processing을 단순화함으로써 가장 빠른 속도를 가져가고 있음을 확인하면 되겠습니다.
Multi-language text detection
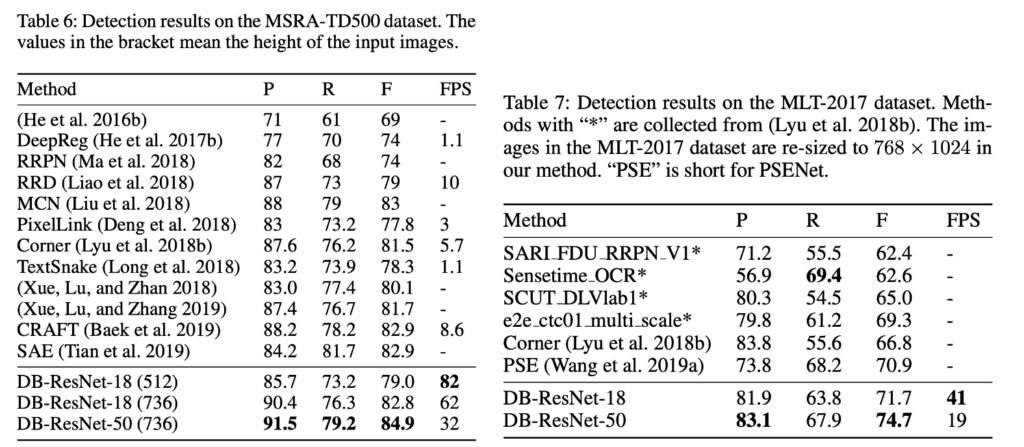
multi-language text detection에서의 실험 결과입니다. MSRA-TD500 데이터셋을 사용하여 실험한 표[Table6]를 보면 속도도 빠르고, 성능도 가장 좋은 것을 확인할 수 있습니다.
Limitation
본 논문의 방법론의 한계로 text inside text 상황을 다루지 못한다는 점을 저자는 언급합니다. text inside text란 text instance가 다른 text instance 내부에 있는 경우를 의미합니다.

우하단에 있는 이미지를 보면, text에 내부에 존재하는 text인 11에 경우에는 검출해내지 못하는 모습을 보입니다. 이런 한계점은 segmentation 기반의 text detection 방법론에 공통적인 한계점이라고 하네요. . . shrunk(축소한) text가 이런 경우에는 잘 작동하지 않는다고 합니다. 흠 . . 정확히 왜 잘 안되는지는 모르겠네요 . ㅎ
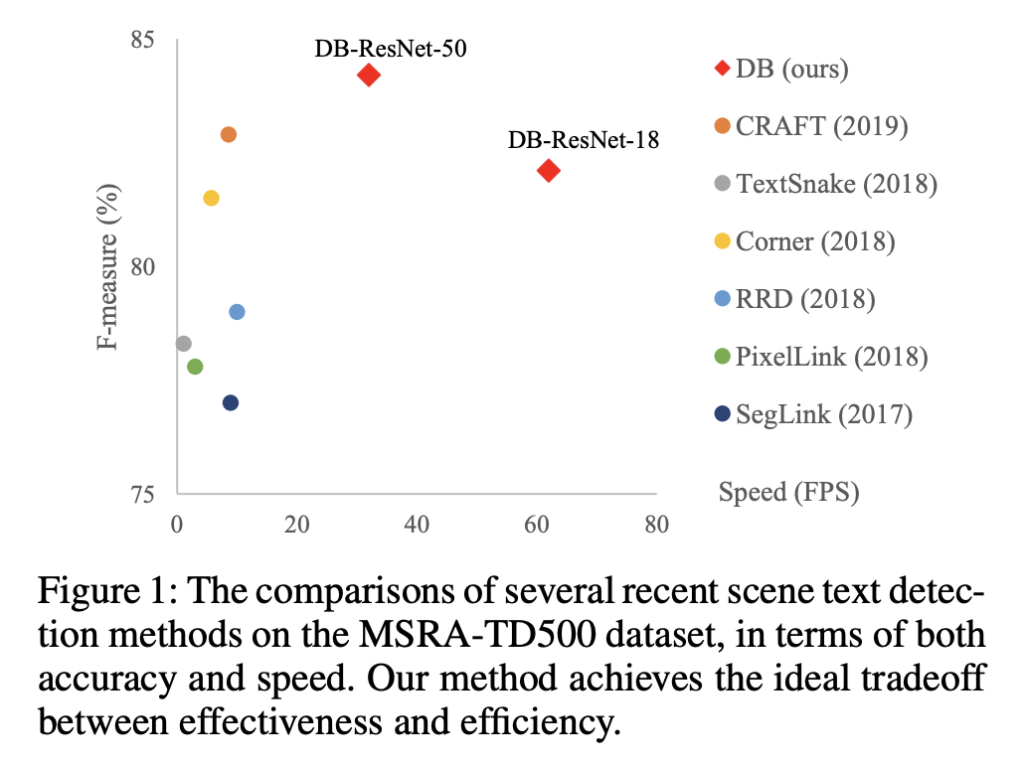
마지막으로 타 방법론 대비 본 논문의 방법론 DB-ResNet18이 압도적인 속도를 보이며, DB-ResNet50은 그보다는 조금 느리지만 타 방법론보다 성능이 좋은 성능을 낸 결과를 보며 리뷰 마무리하도록 하겠습니다.
안녕하세요. 정윤서 연구원님.
오랜만에 댓글 남깁니다..
기존에 사용되던 이진화 방법과 논문에서 제안한 DB가 기능적으로는 크게 다르지 않음에도, 마지막에 보여주신 그림에서 다른 방법론들에 비해 속도와 정확도가 크게 차이나는 것이 신기하네요.
방법론이 아주 복잡한 것도 아니라, 이 정도면 다른 논문들에서도 흔히 DB를 사용하게 되었을 것 같은데 혹시 최근 Text 연구에서는 DB를 많이 사용하나요?
감사합니다!
댓글 감사합니다.
글쎄요 . . 제가 아직 관련 최신 논문을 많이 읽어보지 않아 확답을 드리지는 못하겠지만, 좀 쓰이는 것 같기도 합니다 . . .
안녕하세요 정윤서 연구원님. 리뷰 잘 읽었습니다.
사실 읽다보니 궁금증이 들어 뒷 부분은 답변을 보고서 다시 한 번 읽어봐야겠는데,
굉장히 원초적인 질문일 수 있겠네요.. 왜 binary map이 필요하나요? 물체가 있을법한 위치를 알기 위한다의 느낌 같긴 한데, 굳이 필요한가?에 대한 의문이 들긴합니다.. 감사합니다
댓글 감사합니다.
text와 background을 분리하여 text 영역을 명확히 구분하기 위함이라고 보면 되겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
probability map과 threshold map에 대한 label을 생성하는 과정에서 vatti clipping 알고리즘을 이용하여 text polygon G를 축소하여 G_s를 생성해낸다고 하셨는데요, 여기서 사용되는 vatti clipping 알고리즘이 어떻게 동작하는 건지 궁금합니다.
또, inference과정에서 bbox를 생성해낼 때 probability map에서 연결된 영역을 얻어낸다고 하셨는데, 여기 연결된 영역은 어떻게 얻어낼 수 있는 것인지 설명해주실 수 있나요 ? ?
감사합니다.
댓글 감사합니다.
1. 우선 ,, 논문에서는 vatti clipping 알고리즘을 사용해 shrink했다는 한 줄만 적혀있어 자세한 동작 과정은 모르겠습니다. vatti clipping 알고리즘은 다각형 clipping을 수행하는 알고리즘인데, 다각형과 clipping 영역을 비교하여 polygon의 가시 영역을 결정하는 것이라고 하는데 코드를 보면 pyclipper 라이브러리를 사용하여 구현한 것 같네요.
2. 일반적으로 connected component analysis 알고리즘을 사용하여 얻어냅니다.
안녕하세요 정윤서 연구원님. 좋은 리뷰 감사합니다.
리뷰를 읽다가 개인적으로 OCR 데이터셋에 대한 궁금증이 생겨 질문 드립니다.
Label generation section의 [수식5]를 보면 polygon의 꼭짓점 수를 사전에 알고있는 상수값으로 주는 것 같고, 데이터셋마다 그 수가 정해져 있는 것으로 보이는데요, 이러한 형태는 데이터셋마다 정해져 있는 것인가요? 예를 들어 ICDAR의 경우 polygon의 꼭짓점이 4개라고 하셨는데 데이터셋에 존재하는 다양한 형태의 text들을 4개의 점으로만 labeling하는 것인지 궁금합니다…
댓글 감사합니다.
네. 데이터셋마다 형태가 다릅니다.예시 들어주신 ICDAR의 경우에는 QUAD(x1, y1, x2, y2, … x4, y4)형태로 어노테이션이 되어있어 꼭짓점 수가 4개로, 데이터셋에 존재하는 다양한 형태의 text를 그냥 사각형의 bounding box로 labeling한 것입니다.