Introduction
여느 논문처럼 감정인식 task의 중요성을 언급하는 것으로 시작하는데요, human-interactive에는 감정인식이 중요하며, 인간이 다른 사람의 감정을 유추할 때 그 사람의 표정, 말투, 행동 등을 종합적으로 고려하는 것 처럼, 감정인식 AI도 다양한 센서로부터 수집된 정보를 종합적으로 사용하고자 하였으며 이것을 mulatimodal emotion recognition이라 합니다.
멀티모달 감정인식 시스템을 개발하는데 있어 연구자들은 다양한 모달리티를 결합하고 대조하는 것이 중요하며 (1)더 많은 정보와 (2) 센서 잡음에 대한 강인성을 그 이유라고 설명해 왔습니다. 당연하게 생각할 수 있듯, 하나의 모달리티, 단일 센서로만 취득한 데이터 보다는 여러 종류의 센서로 취득한 서로 다른 모달리티의 데이터가 더 풍부한 정보를 가지고 있다는 것입니다. 이러한 정보들을 상호 보완적으로 사용함으로써 더 정교한 예측 알고리즘을 생성할 수 있다고 합니다. 또한 센서를 통해 취득한 다양한 모달리티 정보는 종종 노이즈에 의해 손상된 채로 입력될 수도 있고, occlusion에 의해 특정 모달리티의 정보값이 누락될 수도 있습니다. 이 상황을 논문에서는 해당 모달리티가 ineffectual하다고 표현하였으며 특히 wild dataset에 많이 존재한다고 합니다. 그리고 멀티모달의 경우 여러 센서를 복합적으로 사용함으로써 ineffectual한 모달리티를 다른 데이터로 보완할 수 있기에 단일 모달리티에 비해 유리하다고 주장하는 것이죠.
그러나 멀티모달 감정인식에는 challenge들이 존재하는데요, 바로 어떤 모달리티를 어떻게 결합할 지를 결정하는 것입니다.
인간의 감정과 관련된 모달리티는 다양하게 존재하는데요, 가장 대표적으로는 얼굴 표정, 몸의 움직임, 말의 어조, 말의 의미와 같이 표면적으로 드러나는 정보가 있습니다. 감정인식 과제의 경우 심박수의 변화로 감정은 인식하는데, 이러한 정보 또한 하나의 모달리티로써 사용할 수 있습니다. 이렇듯 감정 인식에는 다양한 모달리티가 사용될 수 있는데요, 어떤 모달리티들은 동시적으로 발생하여 함께 수집하고, 운용하기 쉽습니다. 대표적으로는 얼굴의 표정 변화와 speech, 그리고 그 speech의 text정보로 이 논문에서도 사용하는 모달리티에 해당합니다.
어떤 모달리티 정보를 사용할 지 정했다면 이제 이를 어떤 방식으로 fusion할 지 고민해야 합니다. 논문에서는 아직까지 모달리티를 결합하는 가장 효율적인 매커니즘이 합의되지 않았다고 언급합니다. fusion방식에 대한 합의가 이루어지지 않았다는 말처럼, 기존 연구를 살펴보면 다양한 방식으로 fusion을 진행하는데요, 그 중에서도 가장 보편적으로 사용되는 두 가지의 방법으로 ‘Feature-level fusion’과 ‘decision-level fusion’이 있습니다. Featue-level fusion은 early fusion으로 input modality를 하나의 특징 벡터로 결합하고, 이 벡터값으로 최종 예측을 수행하는 방법론입니다. decision-level fusion은 late fusion으로 각 모달리티 별 독립적인 예측을 수행하고 각 예측값들을 하나의 final classification으로 결합하는 방식입니다.
이러한 연구들은 모든 modality가 potentially useful하다고 가정하며 joint representation을 사용하였습니다. 그러나 이러한 가정은 센서 노이즈가 발생하기 쉬운 wild dataset, real 환경에서는 성립하지 않으므로 이 논문에서는 어떤 modality는 유용하지 않을 수도 있음을 고려하는 multiplicative method를 사용한다고 합니다. 이는 보다 높은 신뢰도를 가지는 모달리티에 더 높은 가중치가 부여되도록 각 모달리티의 상대적인 신뢰도를 sample단위로 모델링하는 것이라고 합니다.
논문에 제시된 세 가지의 contribution은 다음과 같습니다.
- We present a multimodal emotion recognition algorithm called M3ER, which uses a data-driven multiplicative fusion technique with deep neural networks. Our input consists of the feature vectors for three modalities — face, speech, and text.
- To make M3ER robust to noise, we propose a novel preprocessing step where we use Canonical Correlational Analysis (CCA) to differentiate between an ineffectual and effectual input modality signal.
- We also present a feature transformation method to generate proxy feature vectors for ineffectual modalities given the true feature vectors for the effective modalities. This enables our network to work even when some modalities are corrupted or missing.
Method
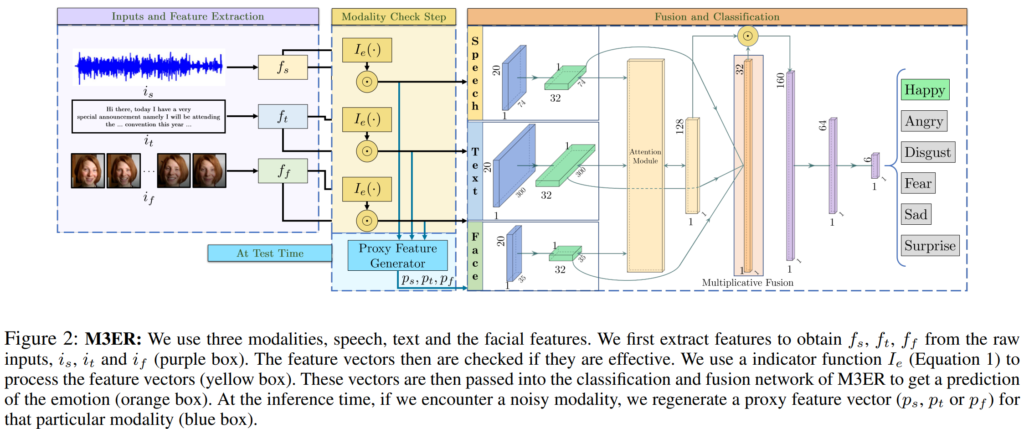
M3ER
저자들이 주장하는 M3ER의 overview는 위의 [그림2]와 같으며, 학습 과정은 크게 feature extraction, modality check step, fusion and classification으로 나눌 수 있습니다. feature extraction 단계에서는 raw data로부터 feature를 추출하고, modality check 단계에서는 추출된 feature를 effective, ineffective로 구분하여 ineffective 정보를 폐기합니다. 마지막 fusion and classification단계에서는 effective signal만을 포함한 feature들을 deep-layered feed-forward neural network channel을 통해 fusion하고 감정을 예측합니다. 이 중 저자들이 새롭게 제안하는 부분은 modality check step으로 자세한 과정은 아래에서 설명드리겠습니다.
Modality Check Step
논문에서 제안하는 Modality Check step이란 inefficient 모달리티를 filtering하는 방법입니다. 실제 상황에서 센서로 데이터를 취득하는 경우, 노이즈의 발생이 불가피한데, 이러한 상황에서 감정 인식을 원활히 수행할 수 있도록 하는 것을 의미합니다.
modality check step은 Shan, Gong, and McOwan의 연구를 바탕으로 하고 있는데요, 해당 논문을 간단히 소개하자면 video sequence에 존재하는 facial expression과 body gesture modality를 fusion하여 장면에 등장하는 인물의 감정을 인식하는 연구입니다. 저자들이 Shan, Gong, and McOwan의 감정 예측 연구에 주목한 점은 ‘correctly predicted된 sample은 각각의 모달리티 신호가 적어도 하나의 다른 모달리티 신호와 상관관계가 있다는 것이었으며, 저자들은 이를 바탕으로 감정 분류에 효과적인 efficient feature와 감정 분류에 효과적이지 않은, 즉, 노이즈가 많이 포함된 inefficient feature를 구분하였습니다.
그렇다면 감정인식에 효과적인 feature를 어떻게 찾을 수 있을까요? 저자들은 모든 입력 모달리티 쌍에 대해 Canonical Correlation Analysis(CCA)를 적용하여 correlation score $\rho$를 계산하였습니다.
Correlation score를 계산하기 위해, 먼저 feature vector 쌍 f_i, f_j를 동일한 형태가 되도록 각각 projection을 진행합니다. 수식으로는 f'_i = H^i_{i,j}f_i, \ f'_j = H^j_{i,j}f_j로 나타낼 수 있습니다.
그리고 f'_i, f'_j의 correlation score를 다음과 같이 계산합니다.
\rho(f'_i, f'_j) = {{cov(f'_i, f'_j)}\over\sigma_{f'_i}\sigma_{f'_j}}마지막으로는 위의 correlation score를 경험적으로 선택된 \tau 값으로 thresholding을 진행하여 아래의 [수식 1]과 같이 임계값 이상의 모달리티만 그 정보를 유지할 수 있도록 하였습니다.
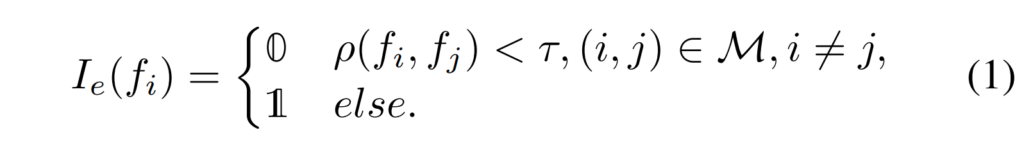
[그림2]에서도 볼 수 있듯이 modality check step의 최종 output은 I_e(F) \odot f로, 모든 모달리티의 feature에 I_e(f)를 element-wise multiplication하였습니다.
Regenerating Proxy Feature Vectors
위의 modality check step에서 모달리티가 ineffectual하다고 간주된 경우, 해당 부분은 0으로 바뀌게 되는데요, 논문에서는 보다 높은 정확도를 위해 test time에서는 Proxy Feature Vector라는 것을 생성하여 감정 인식에 사용하였습니다.
저자들은 주변 modality 정보로 missing modality에 대한 특징 벡터를 생성하는 것은 modality간의 nonlinear relationship때문에 어렵다고 하는데요, 그러나 실험적으로 이러한 non-linear constraint를 완화하는 linear 알고리즘이 존재함을 보이며, 이를 통해 missing modality정보를 근사하는 특징 벡터를 생성하였다고 언급합니다. 이때 이러한 특징 벡터가 proxy feature vector라고 합니다.
Proxy Feature Vector는 p_i = \mathcal{T} f_i와 같이 생성되는데요, 여기서 i는 모달리티를, \mathcal{T}는 임의의 선형 변환을 의미합니다.
만일 speech 데이터 S={w_1,w_2,…,w_q}가 inefficient로 , face데이터 F={f_1,f_2,…,f_n}가 effecient로 판명되었다고 한다면, f_f에 대응하는 speech의 proxy feature vector p_s를 생성하는 과정은 다음과 같습니다.
먼저 입력값을 preprocessing하여 F와 S의 column spaces에서 base vector F_b={v_1,v_2,…,v_p}와 S_b={w_1,w_2,…w_q}를 각각 구성합니다. 이제 T : F_b→S_b를 만족하는 임의의 linear transformation이 존재한다고 가정한 뒤, 아래의 두 단계를 거쳐 p_s를 생성하게 됩니다.
1. KNN 알고리즘 등의 distance metric minimization 알고리즘을 통해 v_j=argmin_j d(v_j, f_f)을 만족하는 v_j를 계산합니다. 여기서 d는 임의의 distance metric으로 논문에서는 L_2 norm을 사용하였습니다.
2. 다음으로는 식 f_f = \sum^p_{i=1}a_iv_i 을 풀어 상수 a_i를 계산하면 p_s를 아래와 같이 계산할 수 있습니다.
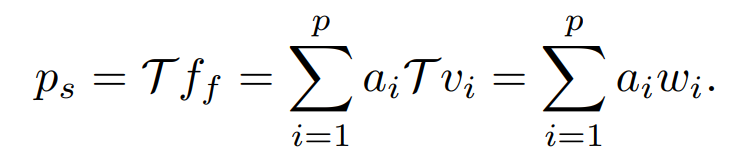
이러한 proxy feature vector계산 알고리즘은 여러 모달리티에 대해 각각 생성하도록 확장될 수 있는데요(만일 A,V,T중 A만 inefficient인 경우, A-V, A-T의 경우가 있음), 이러한 경우에는 각 결과들의 평균값을 사용할 수 있다고 합니다.
Multiplicative Modality Fusion
M3ER의 feature fusion은 Liu et al.의 multiplicative fusion을 기반으로 하고 있으며, 해당 방법론의 key idea는 weaker modality를 명시적으로 억제하여 보다 강한 표현력을 지닌 모달리티를 간접적으로 강조하는 것으로, 이때 i번째 모달리티에 대한 loss를 [수식 2]와 같이 나타낼 수 있었다고 합니다.
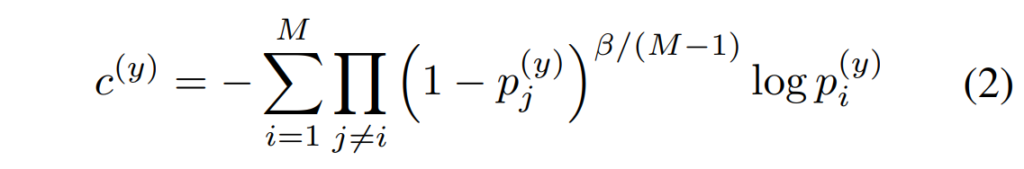
y는 true label, 전체 M은 모달리티의 수를, p^{(y)}_i는 i번째 모달리티에서 클래스 y에 대한 예측값을 나타내며, \beta는 하이퍼파라미터로 신뢰도가 낮은 모달리티를 down-weight하는 역할을 수행한다고 합니다.
기존 multiplicative fusion이 약한 모달리티의 가중치를 줄이는 방향으로 fusion을 진행하였다면, 저자들은 이를 반대로 강한 모달리티의 비중을 증가시키는 방향으로 loss를 재구성하였는데요, 저자들이 사용한 loss는 아래의 [수식 3]과 같으며, 이러한 변화가 더 나은 classification 성능을 실험적으로 보여주었다고 합니다.
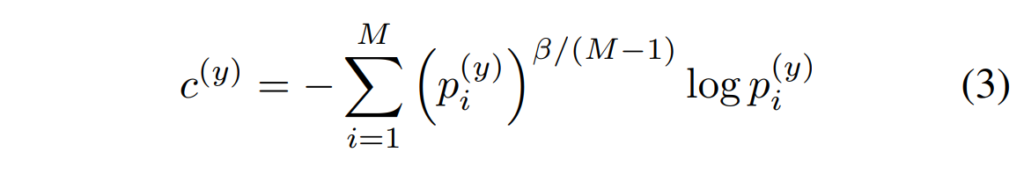
Experiments and Results
저자들은 IEMOCAP과 CMU-MOSEI데이터셋에서 실험을 진행하였습니다.
두 데이터셋 모두 감정인식 논문에 자주 등장하는 데이터셋으로, 간단히 설명드리자면 IEMOCAP은 10명의 배우가 4가지 감정(angry, happy, neutral, sad)을 연기한 것이고, CMU-MOSEI는 SNS에서 수집한 영상 데이터로 총 6가지의 감정(anger, disgust, fear, happy, sad and surprise)을 포함하고 있습니다.
평가 metric은 F1 score와 감정 별 accuracy의 평균(MA)를 사용하였습니다.
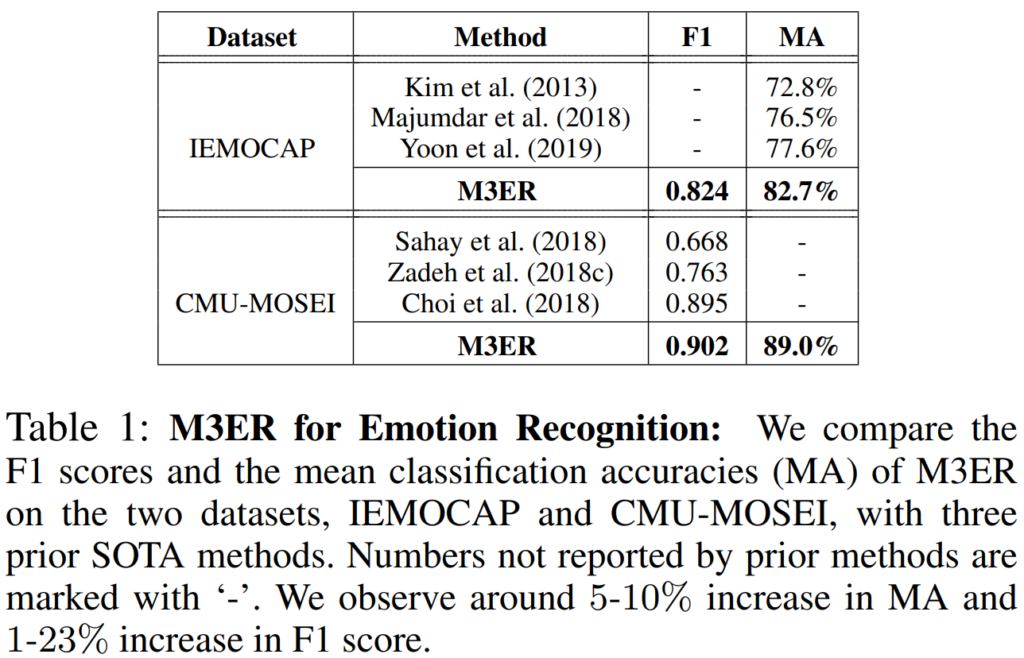
[표1]은 각 벤치마크의 sota와 M3ER의 분류 성능을 비교한 것으로 M3ER을 사용할 경우 IEMOCAP의 F1 score는 1-23%, CMU-MOSEI의 MA는 5~10% 향상되는 것을 관찰할 수 있습니다.
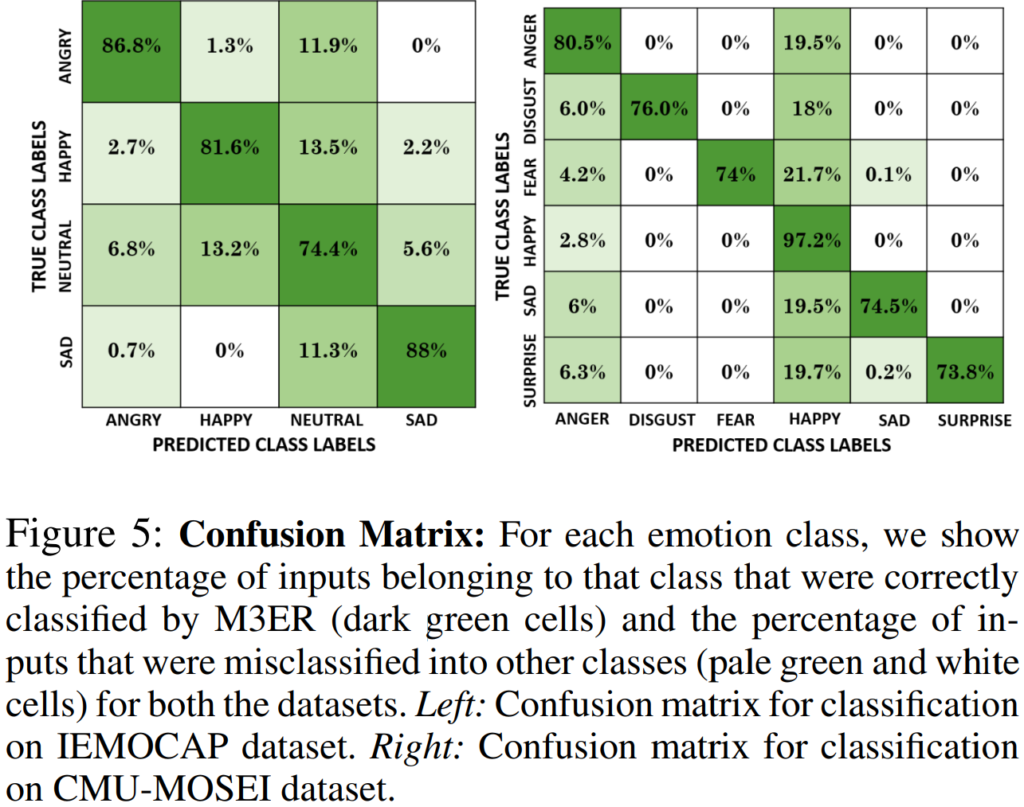
[그림5]는 IEMOCAP 과 CMU-MOSEI에서 M3ER의 클래스별 성능을 나타내는 confusion matrix로, 각 감정에서 샘플의 73% 이상이 M3ER에 의해 정확하게 분류되는 것을 확인할 수 있습니다.
사실 메인 실험에 대한 결과는 위의 내용이 전부였는데요, 각 벤치마크의 sota 방법론과의 비교라는 제목에 비해 비교 대상이 너무 적은데다 이 논문이 2020에 발표된 것을 감안하더라도 각 방법론들이 너무 옛날 것이 아닌가 하는생각이 들었습니다.
Ablation Experiments
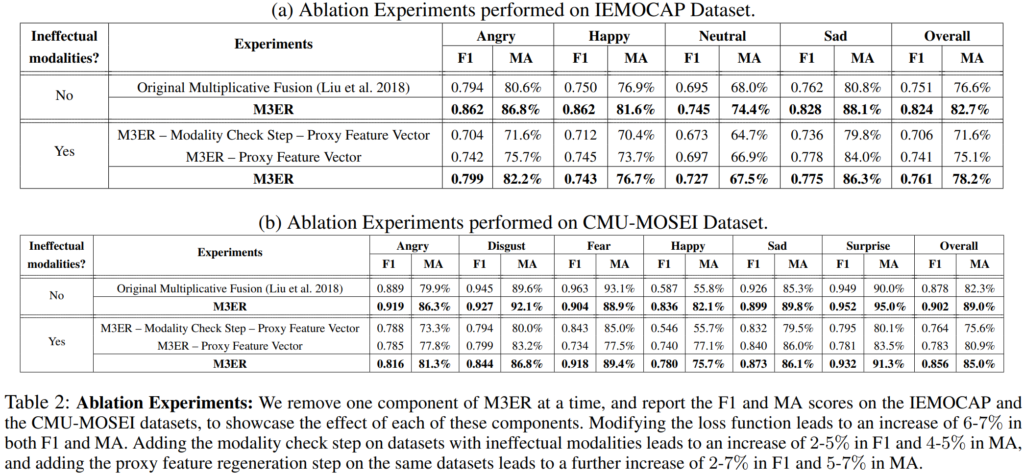
먼저 original multiplicative fusion과 저자들이 사용한 modified loss를 비교하였는데요, modified loss를 사용하였을 때 F1 score와 MA가 모두 6~7% 향상된 것을 확인할 있습니다.
다음으로 저자들은 ineffectual modality에 대한 modality check step과 proxy feature vector의 유용성을 증명하기 위한 ablation study를 진행하였습니다. 이때 실험은 전체 데이터셋의 75%에 적어도 하나의 모달리티가 노이즈를 포함하고 있도록 구성하였으며 노이즈는 SNR이 0.01인 가우시안 노이즈를 더해주었다고 합니다.
M3ER에서 modality check step과 proxy feature vector를 모두 사용하지 않은 경우, 즉, 단순히 modified loss만을 적용한 경우에는 non-ablated M3ER에 비해 overall F1 score는 4~12%, MA는 9~12% 감소하였습니다. 여기에 modality check step 을 추가하게 되면 ineffectual modality를 걸러내는 작업이 추가되는데 이때는 F1은 2~5%, MA는 4~5% 향상되는 것을 확인할 수 있습니다. 그러나 걸러진 modality가 비어 있는 채로 classification이 진행되어 non-ablated M3ER보다 F1이 2~7%, 전체 MA는 5~7% 떨어지는 것을 확인할 수 있었습니다.
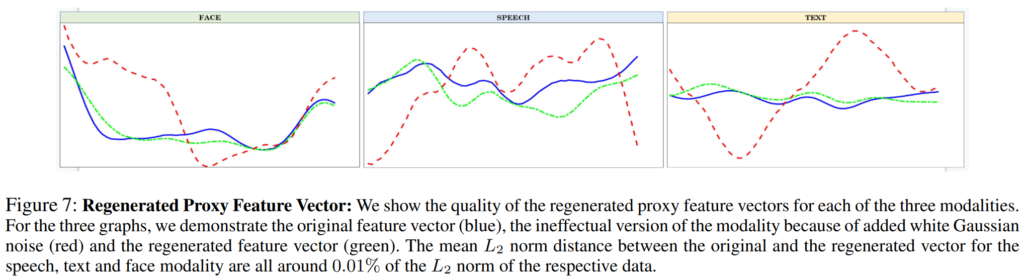
[그림7]은 proxy feature vector의 유용성에 관한 정성적 결과로 파란색이 noise가 포함되지 않은 effective feature vector, 붉은색이 gaussian noise가 포함된 ineffectual feature vector를 나타내며 녹색이 regenerated proxy vector를 나타냅니다. 논문에 언급된 바로는 regenerated proxy feature vector와 실측 데이터 간의 L2 norm distance가 각 데이터의 L2 norm distance의 약 0.01%정도로 나타났다고 합니다.
안녕하세요 좋은 리뷰 감사합니다.
Modality check step의 최종 ouput 산출 과정에서 F가 잘 이해되지 않는데요, 만약 A, V, T 3가지 모달이 존재할 때, rho(A, V)와 rho(A, T) 중 하나의 rho라도 threshold보다 작으면 A는 ineffective로 나오는 것인가요?
그리고 Modality check step 모듈 설명에서 감정을 정확히 예측한 경우 모달 간 적어도 하나의 상관관계가 보장되는 것을 확인했다고 되어 있는데, 이에 대한 정량적 근거가 본 논문 또는 reference에 있는지도 궁금합니다.
댓글 감사합니다.
우선 첫 번째 질문의 경우, 저는 해당 부분을 rho(A,V)와 rho(A,T)둘 다 threshold를 넘지 못한 경우에 A가 ineffective라고 이해하였는데요, modality check step부분에 effective인 모딜리티는 다른 모달리티와 적어도 하나의 correlation이 존재한다고 하였으므로 ineffective이면 다른 모든 모달리티와 연관성이 없다고 생각하였습니다. 그러나 말씀해주신 부분에 대해 코드적으로 확인해보겠습니다.
해당 부분의 reference는 이 논문으로, 본문의 ‘modality check step’ 부분에 논문 링크와 설명을 추가해 두었으니 참고하시면 될 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
감정인식 논문을 읽으면서 Modality Check Step 부분이 여타 다른 논문에 비해서 흥미로웠는데요,
1. ” 이전까지의 감정 인식 연구에서 감정을 정확하게 예측한 경우 해당 모달리티 신호 각각이 적어도 하나 이상의 다른 모달리티 신호와 상관관계가 있다는 것”이 잘 이해가 가지 않습니다. 제가 감정인식 논문을 그래도 여러개 읽어봤지만 이러한 내용에 대해서는 한번도 본 적이 없어 이 부분과 관련하여 설명 부탁드립니다.
2. 이 논문의 경우, 데이터셋의 train, test 데이터를 어떻게 가져갔는지 궁금합니다. 더 설명해서 말하면 Modality Check Step 일종의 데이터를 거르는 역할을 하는데 train에만 적용하는 것인지 아니면 test에도 적용하는 것인지 궁금합니다.
감사합니다
댓글 감사합니다.
1. 해당 부분의 reference는 이 논문으로, 본문의 ‘modality check step’ 부분에 논문 링크와 설명을 추가해 두었으니 참고하시면 될 것 같습니다.
2. [표1], [그림5]에 해당하는 실험에서는 IEMOCAP은 train(85%), test(15%) 으로, CMU-MOSEI는 train(70%), valid(10%), test(20%)로 split하였다고 하며 Modality check step은 train과 test단계 모두 적용되었습니다.
리뷰 잘 읽었습니다.
inefficient 모달리티를 filtering하는 방법인 Modality Check step 에 대한 질문이 하나 있습니다.
결국 Modality Check step에서 inefficient 모달을 찾아서 반영을 안하는 식으로 filtering 을 하는 것인가요?
그리고 감정을 정확하게 예측한 경우 해당 모달리티 신호 각각이 적어도 하나 이상의 다른 모달리티 신호와 상관관계가 있다는 것을 이전 연구들에서 발견하셨다고 작성해주셨습니다. 그런데 음.. 직관적으로 생각해보면 다른 모달과 상관관계가 없어도 단일모달 홀로 감정을 정확하게 예측하는 case 도 존재할 거 같긴 한데 이에 대한 언급은 따로 없는거죠?(이전 연구들에서 발견한 내용이라??)
감사합니다.
안녕하세요. 댓글 달아주셔서 감사합니다.
넵 맞습니다. 결국 modality check에서 모달리티가 ineffeciency로 판단되면 0을 곱함으로써 뒤의 분류 모델에 반영되지 못하도록 하는 것입니다.
단일 모달만으로 감정을 예측하는 경우에 관한 언급은 없었습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
“modality check step에서 하나 이상의 모달리티가 ineffectual하다고 간주된 경우, 해당 부분은 0으로 바뀌게 되는데요”라고 말씀해주셨는데 이는 fi, fj의 correlation score가 threshold를 넘지 못하면 f_i = 0이 되는 것이 맞는 것이죠 ? ? 그렇다면 missing modality의 feature vector을 다시 근사해준다는 것은 threshold를 넘지 못하여 0이 되는 feature vector을 다시 임계값이 넘도록 생성한다로 이해해도 될까요? 아니면 새롭게 근사된 feature vector로 새롭게 correlation score을 매기는 것인가요 ?
감사합니다.
댓글 감사합니다.
ineffectual한 모달리티는 I(f)=0이 되므로 뒷부분의 fusion/classification에서는 고려하지 않으므로 0이 된다고 생각하신 것이 맞습니다.
이때 missing modality의 feature vector를 근사한다는 것은 threshold를 넘지 못하는 feature vector를 임계값이 넘는 feature vector로 재생성하는 것으로 이해하시면 될 것 같습니다. 즉, 어떤 modality가 missing일 때, 다른 modality의 정보를 토대로 해당 modality가 정상적으로 입력되었을 때의 데이터를 생성하는 것입니다.
안녕하세요. 좋은 리뷰 감사합니다.
proxy feature vector 계산을 여러 모달리티에 대해 각각 생성하도록 확장할 수 있다고 하셨고, 이 경우에는 결과들의 평균값을 사용한다고 하셨는데 더 잘 생성된 것이 아닌 평균을 사용하는 이유가 있을까요 ?
또,, inefficient 모달리티를 filtering하는 modility check step에서는 Canonical score를 계산하고, thresholding을 진행하여 filtering하는 과정으로 이해했는데, 보통 이 CCA를 적용하여 많이들 inefficient 모달리티를 필터링하는지 궁금하네요 . ..
감사합니다.
댓글 감사합니다.
해당 이유에 관해서 논문에 언급된 것은 없지만 제 생각에는 여러 모달리티를 고려한 proxy vector를 생성하기 위해서가 아닐까 싶습니다. Audio가 inefficient일 때, Text를 기반으로 생성된 audio proxy vector와 Video를 기반으로 생성된 audio proxy vector는 기반이 되는 모달리티의 특성을 포함하게 될 것이기 때문에 두 proxy vector를 다시 한 번 합쳐주는 방식을 택한 것이 아닐까요… 물론 더 잘 생성된 쪽에 높은 가중치를 주면서 결합하는 것을 고려할 수도 있으나 그러한 실험은 별도로 수행하지 않은 것으로 보입니다.
좋은 리뷰 감사합니다.
우선 correlation score를 구할 때 \sigma 값은 무엇을 의미하는 지 궁금합니다.
그리고 test과정에는 보다 높은 정확도를 위해 proxy feature vector를 생성하였다고 하셨는데, 학습 과정에 0이 아닌 이 proxy feature vector를 이용하지 않는 이유가 무엇인지 혹시 설명해주실 수 있나요? 학습 과정에 proxy feature vector를 사용하는 실험은 없는 지 궁금합니다.
또한, 선형 변환을 나타내는 T는 A도메인의 값이 missing일 경우 B 도메인으로 변환해줄 수 있고, 이를 여러 모달리티로 적용 가능하다고 이해하였는데, 이에 대한 실험 결과가 무엇인지 궁금합니다.(proxy feature vector의 효용 검증 결과가 아닌, 여러 모달리티의 missing 상황에 대한 실험이 없었는지 궁금합니다.)
댓글 감사합니다.
학습 과정에서 proxy 벡터를 사용하지 않은 이유를 설명드리자면, proxy vector는 inference시 missing modality를 채워주기 위한 방법론으로 이 논문에서는 training데이터가 missing인 상황을 가정하지 않았기 때문이라고 생각합니다. 따라서 동일한 학습 데이터로 학습시킨 것을 test에 noise를 추가하여 proxy vector를 사용한 경우의 실험을 진행한 것 같습니다.