본 논문은 3d point cloud를 voxel로 처리하여 mae를 적용한 논문을 찾다 알게되어 읽어보게되었다. 기존의 indoor환경에서 mae를 적용했던 point-mae와 비슷하지만 본 논문에서의 voxel-mae는 outdoor환경에서 평가하였다. 저자는 3d object detection을 위한 annotation을 하기 어려운 automotive dataset에 self-supervised learning을 적용하는 것이 적절한데 지금까지 많은 연구가 synthetic데이터나 indoor데이터에 focus되었다고 한다. 본 논문에서는 sparse하고 같은 scene에서도 point density가 다양하게 나타나는 outdoor환경에서의 automotive setting에서 point cloud에 masked autoencoding을 적용한 voxel-mae를 제안한다. outdoor dataset인 nuScenes dataset에서 좋은 결과를 보였고 voxel-MAE를 통해 40%만 annotation된 데이터만으로도 좋은 결과를 보일 수 있었다고한다.
Introduction
self-supervised learning은 사람의 annotation없이도 데이터로부터 풍부한 feature를 추출할 수 있도록 한다. 따라서 self-supervised model은 NLP와 Computer Vision분야에서 좋은 성과를 보여주었다. 그 중 masking방식이 간단하고 효과적인 pre-train방법으로 사용될 수 있음을 보였다. model이 sentense나 image를 input의 masking되지 않은 일부분만 보고 학습하여 원래 input을 reconstruction하는 것이다. 해당 masking방식은 기존의 supervised learning보다 좋은 결과를 보이기도 한다. 저자는 자율주행 분야가 self-supervised pre-training전략을 적용하기 적합하다고 주장한다. 자율주행 domain에서는 object detection, tracking, semantic segmentation 등 task를 수행하기위한 annotation을 하는 것이 많은 cost를 필요로 하고 시간도 오래필요하다. 특히 outdoor scene의 경우 더 복잡할 것이다. 또 3d LiDAR나 Radar data는 sparse하기 때문에 labeling이 노동집약적이고 모호한 부분이 있다. 따라서 self-supervised pre-training방식이 사람이 직접 annotation하는 필요성을 줄여줄 수 있는 대안으로 더 robust하고 general한 표현이 가능하다고 한다. 최근에 많은 연구들이 masking방식을 통해 encoder를 사전학습시키는 방식을 제안했다. 해당 방식들은 shape classification, shape segmentation, few-show classification, indoor 3d object detection 등 다양한 downstream task에서 좋은 결과를 보였다. 하지만 shapenet, modelnet40과 같은 synthetic data나 scannet, sunrgbd와 같은 indoor data에 대해 focus되어 평가가 이뤄졌다. outdoor data에 비해 해당 데이터셋들은 object마다 표현되는 point에 수가 많기도하고 point density가 전체 scene에대해 전반적으로 constant하다고 한다.
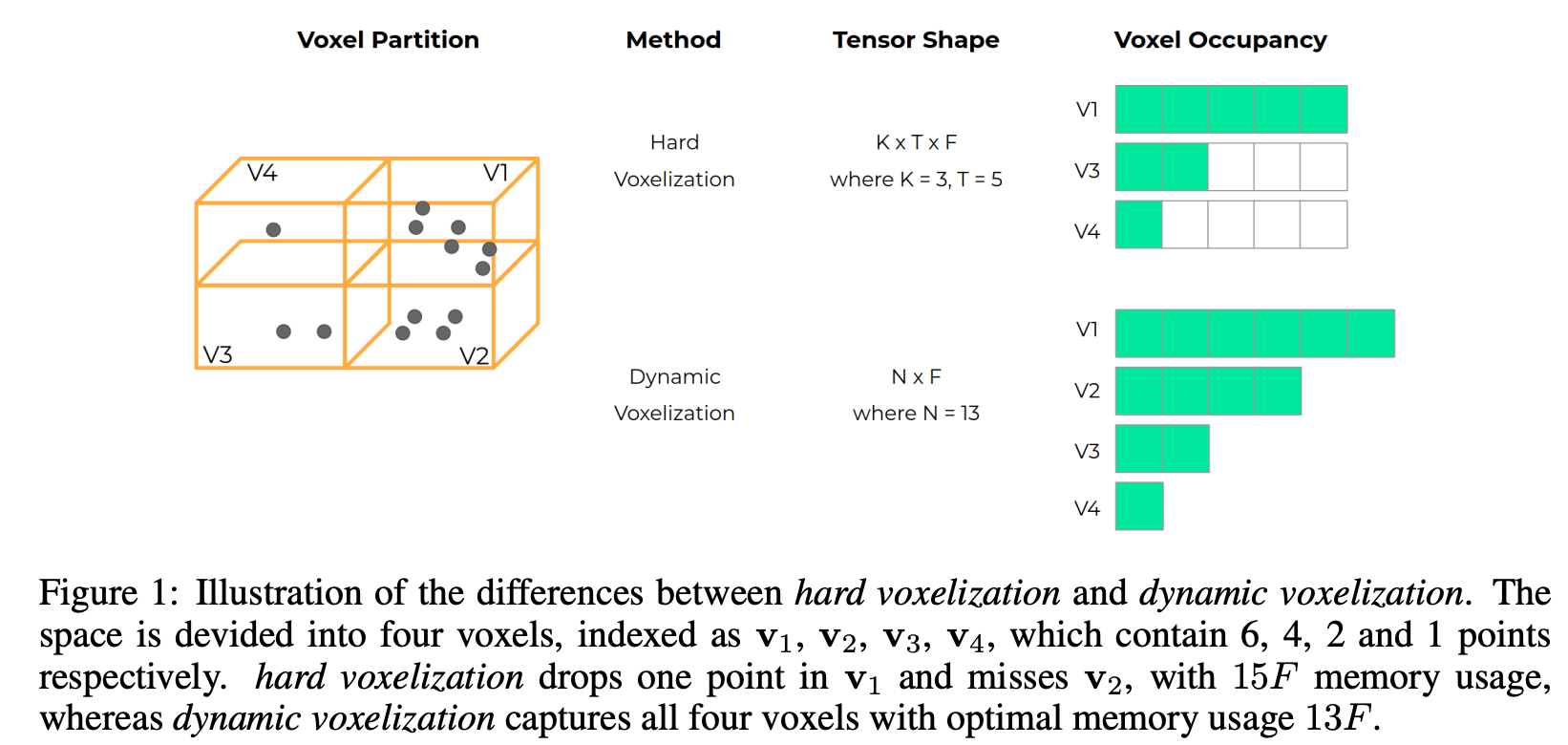
또 기존 방법론들은 FPS(furthest point sampling), knn등에 의존하여 point cloud를 subset으로 나누었다. 아래 Figure 1에서 확인할 수 있는 것처럼 point cloud가 고루 분포하거나 간단한 reconstruction구조일때는 일정한 고정된 point 수를 subset마다 정해서 모델이 예측하기 때문에 위의 방식을 적용했을 때 괜찮지만 outdoor domain에서는 이런 방식으로 downstream task를 수행하는데는 sub-optimal하다고 한다.

먼저 버리지는 points들이 있는데 가운데 부분에 비행기의 wing tip을 보면 point가 포함되지 못한 것을 알 수 있다. 이렇게 손실되는 부분에 정보들이 모여 부정확한 reconstruction이 될 수 있다는 것이다. 또 부분 집합이 중복되어 불필요한 계산 부하가 발생할 수 있어 표현이 중복된다는 문제가 있다고 주장한다.
따라서 본 논문에서는 automotive setting에서의 masked point modeling을 사용한 방법을 Voxel-MAE를 제안한다. Voxel-MAE는 point를 voxelize하고 masked autoencoder pre-training전략을 적용한 방법으로 large-scale automotive dataset인 nuscens에서 그 효과를 입증하였다. voxel-mae는 point cloud feature를 추출하기 위해 transformer를 backbone으로 사용하였고 unmasked data만 encoder에서 embedding되었다. 또 sparse oint cloud를 효과적으로 다루기위해 값이 존재하는 non-empty voxel에 대해서만 processing했다. automotive point cloud에서 transformer backbone이 몇 개 존재하긴 했지만 소수의 모델만 존재했고 self-supervised pre-training방법은 이전에 적용된 적이 없었다. 여기서는 Single-stride Sparse Transformer(SST)를 point cloud의 encoder로 사용했다. 그리고 encoder와 비슷한 구조를 가진 lightweight decoder를 사용했다.
본 논문에서 contribution은 아래와 같다.
1. voxelize point cloud에 MAE-style self-supervised pre-training을 사용한 Voxel-MAE 제안. automotive point cloud에 최초로 transformer backbone을 사용한 self-supervised pre-training적용한 방법론
2. voxel representation에 맞게 수정하고 voxelize point cloud에 맞는 특성을 capture
3. annotated data의 필요를 줄인 data-driven한 방법으로 40%의 annotaed data를 통해 사전학습하여 supervised보다 좋은 성능 보임
4. 기존 다른 self-supervised learning방법보다 좋은 성능 보임
Related Work
BERT, GPT와 같은 masked language modeling(MLM)은 NLP에서 좋은 성공을 거뒀다. 이 방법들은 input sentense에서 masking을 하고 학습된 모델이 masking된 부분을 예측하도록 했다. 이런 방식에서 착안하여 다양한 방법들이 image domain에도 비슷하게 적용되었다. 최근에 MAE의 저자 Kaiming He는 2d image에서 random하게 patch를 masking하고 각 pixel value를 reconstruction target으로 하였다. 이때 asymmetric한 encoder-decoder구조를 사용하였고 visible patch만 encoder에서 embedding되었고 decoder에서 reconstruction되었다. MAE는 downstream task에서 좋은 결과를 보였고 supervised learning보다 좋은 결과를 보이기도 했다. 본 논문에서 제안하는 Voxel-MAE는 MAE 구조를 따라 sparse point cloud를 voxelize한 형태에 적용가능하도록 했다.
기존에 point-BERT는 BERT style로 point cloud를 사전학습했는데 point cloud를 patch로 tokenize하는 discrete Variational Autoencoder(dVEA)에 의존한다는 단점이 있었다. 이후에 Point-MAE는 tokenizer를 없애고 direct하게 point patch를 reconstruction하도록 했다. MaskPoint는 더 속도를 높인 모델이다. 하지만 outdoor 3d detection분야에서는 self-supervised learning을 통한 연구가 많이 수행되지 않았다고한다. 본 논문에서는 기존 outdoor에서의 방식보다 더 간단한 방식을 통해 모델이 사전학습하고 downstream task를 위해 fine-tunning하는 방식을 적용했다고 한다.
Methodology
voxel-mae는 point cloud를 voxelize하여 MAE방식으로 사전학습한 방법론이다. encoder를 통해 풍부한 latent representation을 추출하고 decoder에서 original input을 reconstruct한다. 아래 Figure 2에서 전체 pipeline을 확인할 수 있다.

masking and voxel embedding
image에서 겹치지않는 patch로 나누는 것과 비슷하게 point cloud도 voxel형태도 나누어주어 효율적으로 처리할 수 있도록 한다. 하지만 voxel은 image patch와 비교했을 때 challenge한 요소가 존재한다. 먼저, scene에서 occlusion과 sparse한 LiDAR data의 특성상 많은 voxel들이 비어있는 경우가 존재한다. 이런 voxel들을 모두 사용하지 않고 본 논문에서는 empty voxel은 버리고 non-empty voxel에 대해서만 처리하여 불필요한 연산을 줄이고자했다. pre-training시 non-empty voxel에 대해 70%의 높은 비율로 masking을 하여 visible token에 대해서만 encoder처리하여 연산 효율성을 높이고자 했다. 또, point density가 다양하기 때문에 하나의 voxel에 할당되는 point의 수가 하나부터 수백개로 다양할 수 있다. 각 visible voxel에 존재하는 모든 points들을 하나의 feature vector로 embedding하기 위해 여기서는 dynamic voxel feature encoding을 사용했다고 한다. dynamic voxel feature encoding은 “End-to-end multi-view fusion for 3d object detection in lidar point clouds, CORL2020″이라는 논문에서 제안된 방법으로 간단히 보았을 때 더 적은 메모리로 voxel내 모든 point를 포함시킬 수 있는 방법이라고 이해할 수 있다.
masking되지 않은 visible token과 달리 masked voxel은 shared하고 학습가능한 mask token으로 embedding된다.
Encoder
본 논문에서 encoder로는 아래 그림과 같이 Single-stride Sparse Transformer(SST)의 encoder를 사용했다.

SST는 transformer기반의 voxel을 처리하는 3d object detector로 pre-train된 backbone weight를 downstream task를 위해 쉽게 전달할 수 있다. SST encoder는 multiple transformer encoder layer가 쌓인 구조로 되어있으며 input으로 들어가는 voxel token 각각은 voxel의 위치에 따라 positional embedding을 함께 가진다. SST는 swin transformer의 shifted window에서 착안하여 regional grouping과 regional shift를 도입했다. shifted window를 통해 hierarchical transformer를 통해 여러 scale의 물체를 볼 수 있고 이것이 field of view가 겹치지 않는(non-overlap) 3d 영역을 볼 수 있다고 주장한다.
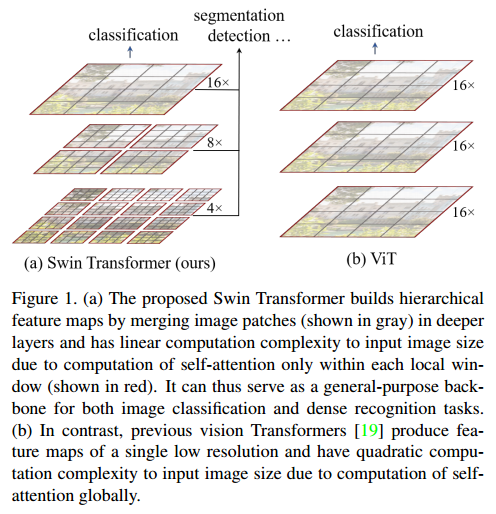
각 window내에 여러 patch로 구성되고 이 window에 대해서만 self-attention이 계산되기 때문에 전체 영역에 대한 attention이 아니라 window영역만 attention을 하므로 많은 연산량을 필요로 하는 global self-attention에 비해 연산량을 줄일 수 있다라고 생각할 수 있을 것이다. 서로 다른 영역에서의 voxel과 상호 작용을 활성화하기위해 영역은 다른 encoder layer마다 shift되고 voxel은 shift된 새로운 영역에 따라 grouping된다.
Decoder
visible voxel을 encoder에서 encoding한 후 decoder에서 latent representation을 통해 original point cloud를 reconstructiong하게 된다. deocder는 pre-training시에만 사용되고 downstream task를 수행하기위해 fine-tunning할 때는 사용되지 않는다. Figure 2에서 보면 encoded voxel과 masked voxel말고도 empty masked voxel도 포함되는 것을 확인할 수 있다. empty voxel에 대해 random하게 sampling하여 masked voxel과 동일한 과정으로 embedding한다고 한다. 이렇게 empty voxel을 포함하는 이유는 empty masked voxel을 포함함으로써 reconstruction task를 더 어렵게 만들어 encoder가 더 좋은 학습을 하도록 할 수 있다는 주장이다. decoder가 non-empty voxel과 empty masked voxel을 구별할 수 있음을 학습하도록 하여 empty voxel을 reconstruction에 활용하지 않도록 하기 위함이다. empty voxel 중 10%정도 sampling해서 사용했을 때 가장 좋은 성능을 보였다고 한다. decoder는 encoder와 비슷한 구조이지만 더 적은 layer를 가진다. pre-training 시간을 줄이기 위함도 있고 encoder가 downstream task에서 더 좋을 결과를 보이기 위해 보통 더 적은 layer를 사용한다. decoder가 더 깊어지면 downstream task성능이 decoder에서 잘 학습한 것일수도 있기 때문이다.
Reconstruction target
decoder는 3개의 서로 다른 reconstruction task를 통해 supervised된다. 각 task에서 loss를 적용한다.
먼저 처음에 voxel마다 서로 다른 수의 points를 포함한다고 했었다. reconstruction을 위해 각 voxel마다 서로 다른 수의 point를 예측해야하는 prediction head를 필요로한다. 본 논문에서는 n개의 fix point를 예측하여 해당 point를 예측하기 위한 간단한 linear layer를 사용한다. reconstruction은 서로 다른 집합의 크기를 가지는 두 point set사이의 거리를 측정하는 Chanfer distance로 supervised된다. masked point cloud를 N개 voxel 나눈 것을 Pgt = {Pi gt}i=1 N 으로 표현하자. 각 voxel Pi gt = {xj}j=1 ni 은 그럼 ni개의 point를 포함하고 있는 것이겠다. 이때 ni는 voxel에 따라 서로 다를 것이다. 그리고 N개 voxel을 가지는 predicted point cloud를 Ppre = {Pi pre}i=1 N 으로 표현하면 예측된 각 voxel은 Pi pre = {x^j}j=1 n 으로 n개의 고정된 point를 가지는 voxel이 될 것이다. 이때 아래와 같이 Chanfer distance를 구할 수 있다.
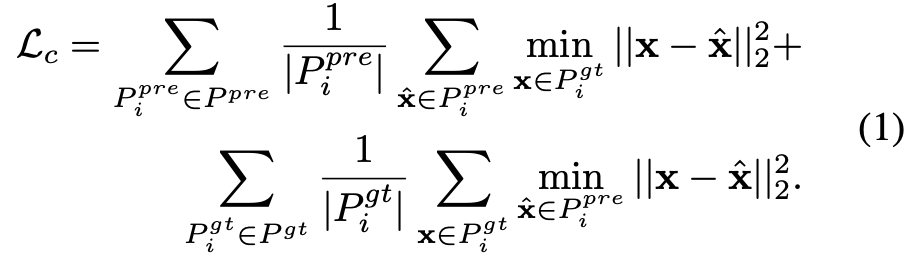
만약 예측한 point수 n이 실제 point 수 ni보다 큰 경우에는 같은 위치에 point를 복제하여 사용한다고 한다. 반대로 예측한 point수가 더 적은 n < ni인 경우에는 mismatch한 상황에서도 chamfer loss가 실제 point cloud에서 detail한 정보를 잘 예측할 수 있다는 연구가 있어 그대로 사용한다고 한다.
두번째로 모델이 point 의 분포를 명시적으로 학습하도록 non-empty masked voxel마다 point 수 ni^을 함께 예측한다. target이 되는 ni는 하나에서 수백개까지 point를 포함할 수 있다고 했었다. 따라서 smooth L1 loss를 통해 supervise한다.

마지막으로 각 masked voxel마다 empty인지 non-empty인지도 supervised해준다. 여기서는 간단하게 binary cross entropy loss를 적용했다.
이렇게해서 총 3개의 reconstruction loss를 합해서 최종 total loss로 사용한다.
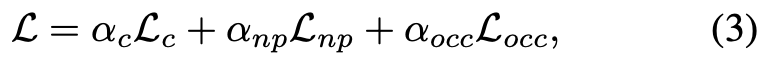
Experiments
실험부분에서는 outdoor driving scene dataset인 nuScenes를 사용했다. nuScenes는 1000개의 sequence로 되어있다.

masking ratio는 70%로 했고 non-empty voxel은 random하게 uniform sampling하였다. chamfer distance loss를 계산할 때 연산량을 고려하여 100개 미만의 point를 사용하도록 제한하였다. downstream task로는 3d object detection을 수행하였다.
self-supervised learning을 사용하는 것 중 annotated data의 필요를 줄일 수 있다는 것이 큰 benefit인데 이것에 대해 실험을 보였다. Voxel-MAE의 사용 유무에 따라 dataset size를 다르게하여 실험을 진행하였다. {0.2, 0.4, 0.6, 0.8, 1.0}이렇게 나누었는데 각각 전체 데이터셋에서 사용한 비율을 나타낸다. Table 1을 보면 사용한 annotated 데이터 비율과 사전학습 여부에 따른 성능을 보여준다.

평가지표에 NDS는 nuScenes데이터셋 논문에서 제안하는 평가 metric으로 아래 수식과 같이 나타낸다. 수식을 간단하게 설명하면 nuScenes에서 다양한 방식으로 평가를 진행하는데 여러가지 error type을 하나의 scalar값으로 나타내기 위한 지표이다. ATE, ASE,AOE, AVE, AAE 이렇게 5가지 True positive 평가방식을 합친 것을 mTP로하여 mAP와 함께 나타낸 지표이다. detection 성능에 관한 지표와 detection의 품질(orientation, size, velocity 등)에 대한 지표가 함께 포함되어있다고 할 수 있다.
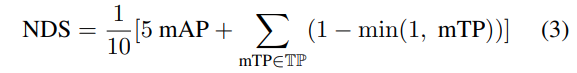
다시 위에서 결과를 보면 맨 마지막 행에서 전체 데이터를 사용해 학습한 pre training을 하지 않은 모델의 경우 49.08 mAP, 60.75 NDS를 보이는데 40%의 annotated 데이터만 사용하여 pre-training한 모델의 경우 50.02 mAP, 61.01 NDS로 사전학습하지 않은 모델의 성능을 뛰어넘은 것을 확인할 수 있다. 1%정도 mAP가 더 높은것으로 보아 사실 40%보더 적은 데이터로 사전학습해도 비슷한 성능을 보일 수 있다는 것이다. 그리고 annotated data사용 비율에 따라서도 다른 결과를 보이는데 사용되는 annotated data의 수가 많아질수록 사전학습된 모델을 사용하는 것과 그렇지 않은 모델을 사용할 때의 성능 gap이 줄어드는 것을 알 수 있지만 pre-training한 모델이 항상 더 좋은 결과를 보이는 것으로 보아 본 논문에서 제안하는 pre-training방식이 general하게 효과적이라는 것도 알 수 있다.
아래 그림은 다른 self-supervised learning방법론들과 비교한 것이다. [S]는 self-supervised leanring을 위한 pre-training을 한 모델을 나타낸 것이고 PP는 맨 위에 행에 있는 PointPillars를 의미하고 V는 voxelnet을 추가했다는 것을 의미한다. SST*은 SST보다 더 높은 밀도의 point cloud를 사용한 것을 의미한다. 4번째 행에서 가장 좋은 결과를 보이는데 해당 방법은 voxel기반의 cnn backbone을 사용한 방법이다. 본 논문에서 사용한 Single-stride Sparse Transfomer backbone에 voxel-MAE를 추가한 방법이 cnn기반의 backbone과 견줄만한 좋은 결과를 보임을 알 수 있다.

아래 table이 흥미로웠는데 transformer기반의 backbone이 3d point cloud(LiDAR data)에서 CNN기반의 방법론들보다 아직 더 낮은 성능을 보이는 것을 확인할 수 있었다. 기존에 cnn기반의 방법들이 많이 사용되었고 transformer기반의 방법론들이 등장한지 얼마되지 않았고 아직 많은 연구가 이뤄지지 않아서 성능에 큰 gap이 발생하는 것이라고 한다. 앞으로 transformer기반의 point cloud를 처리하는 방법론에 대한 연구가 더 활발히 이뤄져서 성능 향상이 될 여지가 있다고 생각된다.

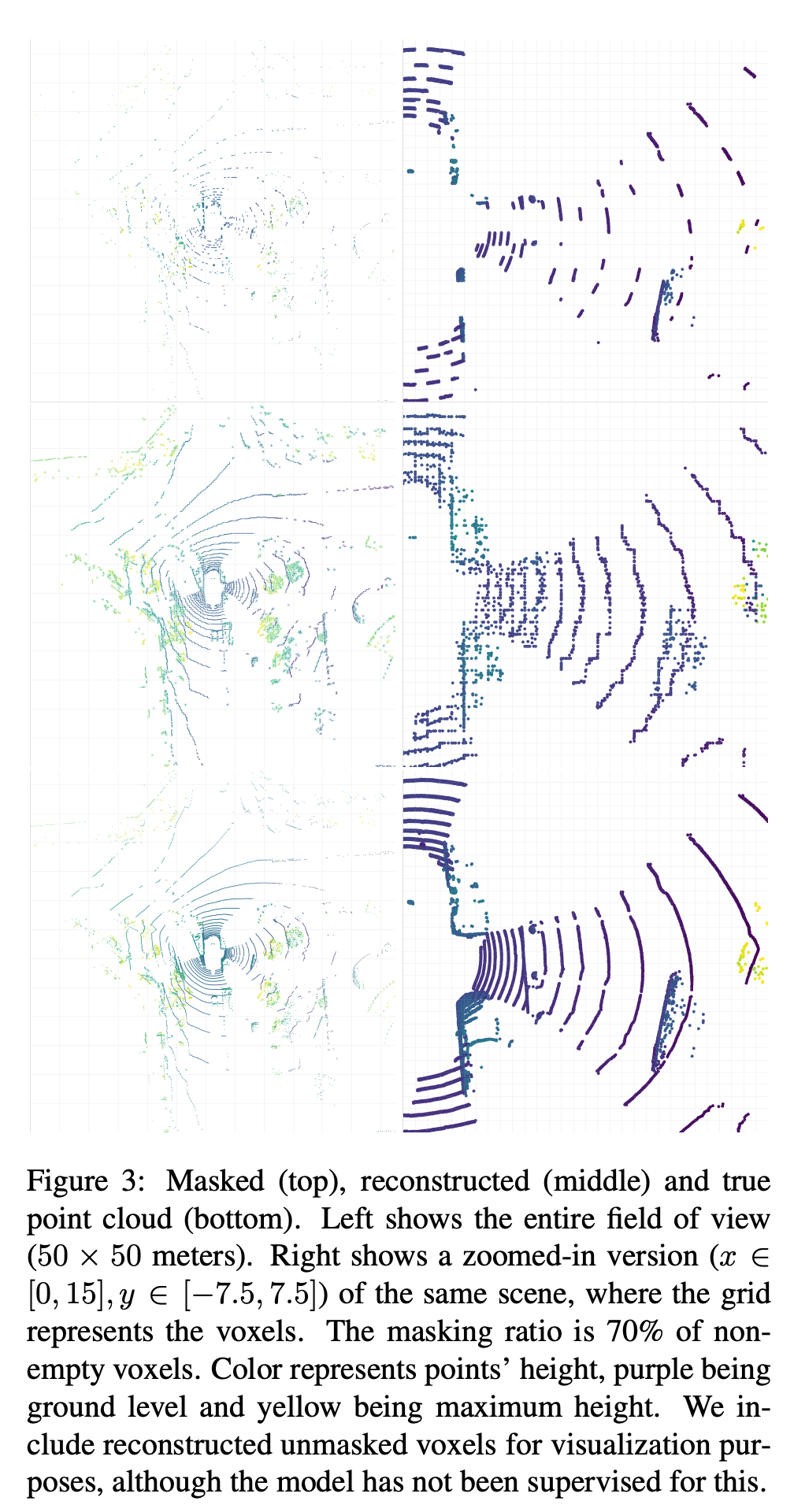
아래 그림은 reconstruction 결과이다. 맨 위가 masking한 그림이고 가운데가 masking된 부분을 복원한 부분이고 마지막이 gt이다. outdoor lidar data라서 다른 방법론대비 얼마나 잘 복원한 것인지 정성적 평가로는 판단이 어려운 것 같은데 정량적으로 비교했을때 타 방법론대비 좋은 결과를 보여 아래 그림정도면 잘 복원했다고 할 수 있을 것 같다.
Conclusions
본 논문에서는 voxelize한 point cloud를 masking을 통해 pre-training기법을 적용한 Voxel-MAE을 제안한다. large-scale automotive dataset인 nuScenes에서 평가를 통해 raw lidar point cloud에서 voxel-mae가 잘 동작함을 입증했다. 해당 방식은 다른 transformer기반 3d object detector와 비교했을때 좋은 performance를 보여주었고 annotation이 없는 데이터의 경우에도 annotation이 있는 데이터셋 대비 경쟁력있는 결과를 보여주었다.
리뷰 잘봤습니다.
몇 가지 질문이 있습니다.
1. x도 n도 voxel 내 point 갯수를 의미하는 것으로 파악이 됩니다.
근데 x와 n의 차이가 무엇인지 잘 와닿지가 않네요…
2. 3번째 loss는 예측해야하는 voxel~maksed voxel의 포인트 유무를 예측하도록하는 loss가 맞을까요?
3. 그럼 입력되는 값은 BEV에서 사전 정의된 voxel grid를 가진 2차원 정보로 보이는데 맞을까요?
아니라면 추가적인 정보가 있어야만 할 것 같습니다.
댓글 감사합니다.
1. x는 실제 gt에서 voxel 내 point 수이고, n은 사전에 정의하며모델이 복원한 voxel 내 point 수 입니다.
2. 네 ,voxel 내 point의 유무를 예측하도록 하는 loss입니다.
3. 네. suppplementary상으로 (200,200,1)의 voxel grid shape을 가집니다.