제가 이번에 리뷰할 논문은 6D Pose Estimation 논문으로, 6D Pose Estimation의 경우 pose 정확도를 높이기 위해 refinement를 수행하는 단계가 일반적으로 포함되는 데, 이러한 전체적인 파이프라인은 많은 연산량이 요구됩니다. 본 논문은 효율적으로 feature를 추출하고 refinement가 가능하도록 하고자 한 논문입니다. 리뷰 시작하겠습니다.
Abstrct
학습 기반의 6D Pose Estimation 방법론들은 정확도를 높이기 위해 rendering등의 과정을 통해 반복적으로 초기 pose를 개선하는 파이프라인을 사용하였습니다. 본 논문에서는 새로운 Cascaded Pose Refinement Transformer(CRT-6D) 파이프라인을 제안하였습니다. 이는 dense한 representation을 대체하여 OSKFs(Object Surface Keypoint Features)라고 하는, feature pyramid로 부터 샘플링한 sparse한 feature를 이용하는 방법론으로 OSKFs를 이용하여 반복적으로 pose의 refinement를 수행합니다. 이를 통해 2배로 빠른 inference가 가능하였고, Linemod-Occlusion과 YCB-Video 데이터셋에서 real-time으로 동작하는 방법론들과 비교했을 때는 inference 시간이 조금 떨어지지만, SOTA를 달성하였습니다.
Introduction
객체의 6D Pose(Translation과 Rotation)를 추정하는 연구는 자율주행과 로보틱스, 증강현실에서 중요한 연구로 occlusion과 조도 및 대칭과 같은 challenge함을 극복해야 한다는 어려움이 있습니다. 단안 카메라를 이용하는 방법론이 depth를 함께 이용하는 방법론보다 성능이 조금 떨어지는 경향이 있고, 최근 연구들은 CNN을 활용하여 좋은 성능을 보여주고 있습니다. 이러한 방법론의 파이프라인은 크게 3가지로 나눌 수 있습니다.
- object detection
- 객체 영역으로 크롭된 영상으로부터 Feature extraction
- PnP등의 알고리즘을 이용하여 intermediate representation으로부터 pose 추정
불필요한 연산을 대체하고, object의 pose를 추정하는 과정에 정보가 없는 영역을 제거함으로써 저자들은 feature를 효율적으로 뽑고자 하였습니다. 또한, 반복적으로 pose를 개선하는 프로세스는 실시간 응용에 적합하지 않으므로 이를 해결하고자 하였습니다.
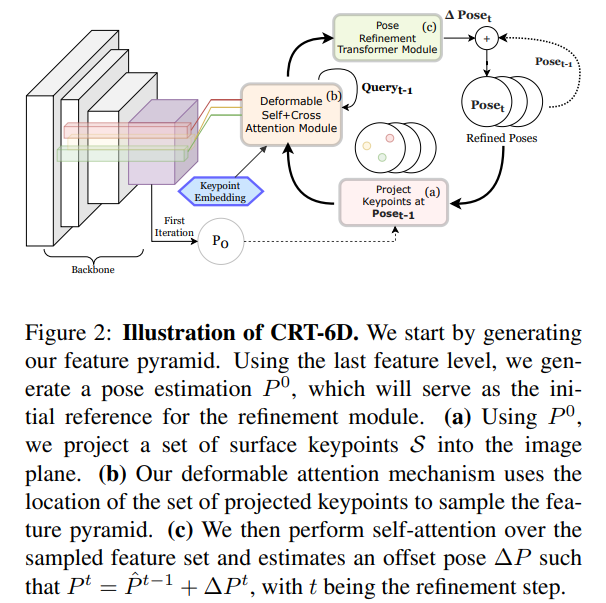
본 논문에서는 객체가 존재하지 않는 영역의 중복적인 계산을 제거하고, 객체가 있는 영역은 oversampling하는 새로운 방법론을 제안하였습니다. 초기 pose가 주어졌을 때 객체 표면의 keypoint를 이미지 평면에 투영하고, 각 keypoint의 2D 위치에서 feautre pyramid로부터 얻은 feature를 샘플링하여 OSKFs(Object Surface Keypoint Features)라는 offset representation을 생성합니다. 또한, 초기 pose의 경우 정확도를 보장할 수 없으므로, 오차를 줄이기 위해 원래의 2D 위치에서 deformable attention을 이용하여 샘플링 과정에 정보를 제공합니다. 이러한 방식, OSKF-PoseTransformers(OSKF-PT)을 제안하였으며 비교적 적은 연산비용이 드는 OSKF를 이용하여 Cascaded Pose Refinement라는 새롭게 제안된 refinement를 수행합니다.
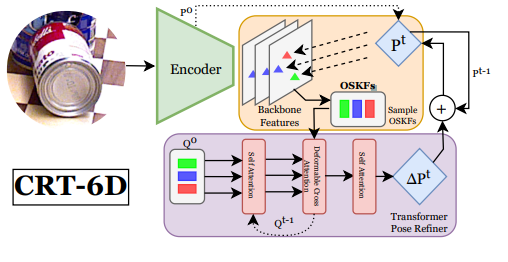
본 논문의 contribution을 정리하면,
- Object Surface Keypoint Features(OSKF)라는 경량화된 중간 representation을 제안하였으며, 이는 noise가 덜하고, 유의미한 영역의 정보에 집중하며 연산량이 적게 드는 representation임.
- OSFK-PoseTransformer(OSFK-PT)라는 반복적으로 pose를 업데이트하는 모듈을 제안하였으며, 이는 OSKF의 경량화된 특징을 이용하였 빠른 반복이 가능.(한번에 3ms미만의 시간이 소요)
- CRT-6D라는 2배가량 빠른 end-to-end의 pose estimation 모델을 제안.
Methodology
새로운 pose estimation 방법론인 CRT-6D의 각 단계에 대한 설명으로, 이미지 \mathcal{I}가 주어졌을 때, CRT-6D는 객체의 6D Pose P_i = [R_i|t_i]를 예측하는 것이 목표입니다. i는 이미지에 존재하는 N개의 object \mathcal{O}= \{ \mathcal{O}_i | i=0, .N-1 \}중 i번째 객체를 의미합니다. 그리고 기존 연구들처럼 object 영역을 찾아내기 위해 기존에 존재하는 object detector를 이용하여 객체 영역을 잘라내고 CRT-6D에 입력으로 제공합니다.
1. Coarse Pose Estimation
ResNet34를 CRT-6D의 backbone으로 이용하였습니다.(다른 6D 방법론들과 공정한 비교를 위해 resnet34를 백본으로 선택하였다고 합니다.) backbone을 이용하여 multi-scale feature pyramid \mathcal{F} = \{ \mathcal{F}_l | l=1, ,L \}를 생성합니다.( L=4일 때, size는 [s/4,s/8.s/16,s/32])
CAR-6D는 단순한 MLP: FC_{\theta}(F_3) = R^0,\tilde{t}^0를 이용하여 초기의 coarse pose P^0_{6D} = [R^0 | t^0] 를 구합니다.(\theta는 학습 가능한 파라미터) 그 다음 rotation matrix R=[R_1,R_2,R_3]를 구하기 위해, [1]**에서 제안된 6D rotation representation R_{6D}=[r_1,r_2]를 이용합니다.
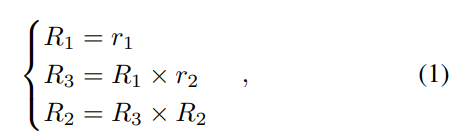
[1]**:Zhou, Yi, et al. “On the continuity of rotation representations in neural networks.” (CVPR 2019)
[1]**에서 제안된 방법론은 rotation을R_{6D}=[r_1,r_2]로 표현했을 때, 식(1)을 이용하여 rotation을 표현할 수 있다는 것으로 r_1,r_2는 단위 벡터입니다.
객체는 방향과 위치에 따라 투영된 형상이 달라지는 데, object의 잘린 영역을 이용하므로, 정확한 위치 값을 추정하기 어렵습니다.(object와 카메라 사이의 거리에 해당하는 값을 구하기 어렵다는 의미) 따라서 먼저 외부의 객체를 중심(allocentric)으로 방향을 추정하고 이후에 inference 과정에 객체 중심(egocentric)의 방향을 구합니다. (이러한 이유로 \tilde{t}^0라 표현한 것으로 보입니다.) 아래는 egocentric과 allocentric에 대한 이미지입니다.

t=[t_x,t_y,t_z]는 crop된 영상을 이용하기 때문에 직접적으로 구하기 어렵습니다. 따라서 역투영을 이용하여 t를 복구하는 데 사용 가능한 t'=[O_x,O_y,t_z]를 이용합니다. 이처럼 크기 변화에 강인한 \tilde{t}=[\gamma_x,\gamma_y,\gamma_z]는 아래의 식으로 표현할 수 있습니다.
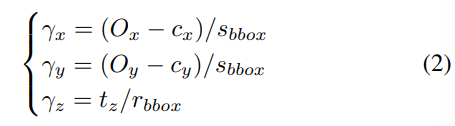
이때, s_{bbox}=max(w_{bbox},h_{bbox}), r=s_{bbox}/s 이고, s는 이미지의 원본 크기를 의미합니다.
2. Object Surface Keypoint Features – OSKF
기존의 방법론들은 refinement를 위해 별도의 네트워크를 이용하여 새로 feature를 추출하여 반복적으로 refinement를 수행하였습니다. CRT-6D는 앞서 multi-scale의 feature pyramid를 재사용하여 refinement를 수행하도록 설계하였습니다. 렌더링 단계를 제거하고, 대신 2D keypoint 위치 \mathcal{P}^t=\{ \pi(\mathcal{S}^t_k, P^t_{6D},K_{cam}) \} 에서 샘플링된 backbone feature 집합인 pose offset representation Z를 생성합니다. 이때 K_{cam}은 camera intrinsic parameter, \pi는 projection function,\mathcal{S}는 keypoint, t는 반복 횟수를 의미합니다.
모든 scale의 feature pyramid를 샘플링하여 생성된 경량화된 representation인 OSKFs Z=\{ Z_k | k=1, ..., K \}는 아래의 식으로 정의가됩니다.
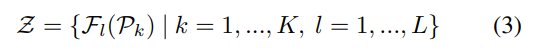
이때 l은 feature pyramid의 l번쩨 요소를 의미합니다.
object의 keypoint \mathcal{S} = \{ \mathcal{S}_k | k=1,...,K \}는 FPS알고리즘(가장 먼 점들을 고르는 알고리즘)을 이용하여 선택되며, K는 하이퍼파라미터입니다. 이러한 feature \mathcal{P}는 주변의 local 정보를 나타내며, higher 레이어일 수록 coarse하고 lower 레벨일 수록 세밀한 정보를 가지고 있습니다.
3. OSKF Pose Transformer (OSKF-PT)
OSKFs 집합 Z 는 attention 메커니즘을 이용하여 공간 및 구조적 관계를 학습할 수 있도록 합니다. CRT-6D는 Z를 해석하고 offset pose인 \Delta P를 출력하도록 설계되었습니다. refinement시 현재 t의 Pose는 이전 pose와 CRT-6D에서 구한 offset pose를 더하여 구합니다.
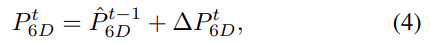
그러나 pose가 정확도와 keypoint가 occlusion된 영역이 아니라는 것을 보장할 수 없으므로 Deformable-DETR을 이용하여 keypoint의 주변 영역의 정보를 샘플링하는 방법을 도입하였습니다. 아래의 그림3에서 네트워크 구조를 확인할 수 있습니다.
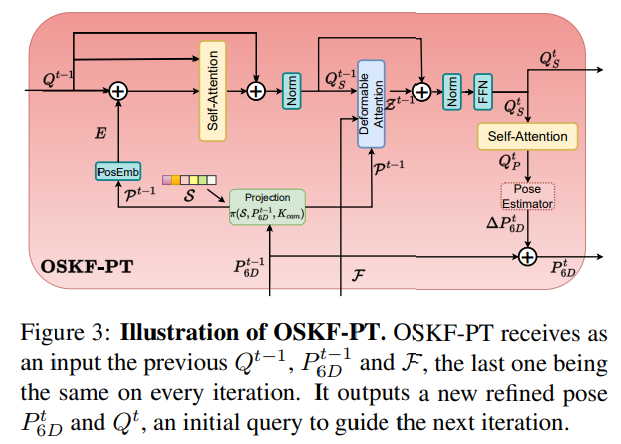
OSKF-PT는 self-attention 레이어와 deformable-self attention 레이어, pose 추정을 위한 또다른 attention 레이어로 구성됩니다. 먼저 집합 \mathcal{S}의 keypoint에 해당하는 query 행렬 Q에 대해 self-attention을 수행합니다. multi-head attention은 \hat{Q},\hat{Q},Q를 query, key, value로 이용합니다. 이때 \hat{Q}=Q+E이고, E_k=PoseEmb(\mathcal{P}_k)는 positional embedding입니다. 이후 residual과 layer normalization을 적용한 출력은 Q_S로 나타냅니다.
multi-scale deformable attention인 OSKFs는 아래의 식(5)로 정의됩니다.
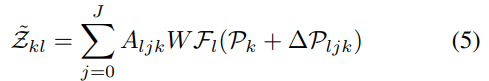
\Delta \mathcal{P}_{ljk}는 공간 레벨 l의 keypoint k에 대한 j번째 deformable position으로, J는 deformable에 적용되는 샘플링 포인트의 수를 나타내고, \Delta \mathcal{P}_{ljk}와 A_{ljk}는 Q_S의 linear transformation을 통해 구해집니다.
\tilde{Z}에 self-attention을 적용하여 long distance 정보인 Q_P를 구하고, CLS-token(class 토큰) 대신 Q_P에 global pooling을 적용합니다. 이후 MLP를 통과시켜 offset 정보인 [\Delta R, \Delta \gamma_x, \Delta \gamma_y,\Delta \gamma_z ] 를 얻고 아래의 식(6)을 적용하여 pose를 업데이트합니다.
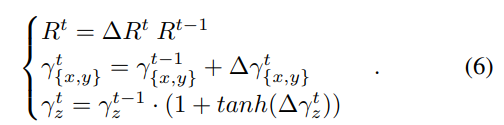
- 참고로 tanh를 이용하는 것이 \Delta \gamma_z를 구할 때 잘 작동하였다고 합니다.
본 논문에서는 3개의 OSKF-PT를 연결하여 실험을 진행하였다고 합니다.
4. Objective Function
CRT-6D는 이미지의 feature를 추출하고 객체의 6D Pose를 구하는 것이 목표입니다. 또한, 반복적으로 refinement를 수행할 수 있도록 하는 것이 목표입니다. 따라서 학습시 pose에 대한 오차는 아래의 식(7)을 이용하여 구합니다.
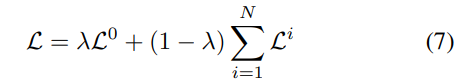
i는 refinement 반복 횟수를 나타내며, N=3으로 설정하였고 \mathcal{L}^0는 초기 coarse pose에 대한 오차입니다. loss에 대해 세분화해보면 아래의 식(8)로 나타낼 수 있습니다.
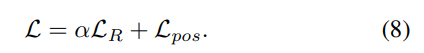
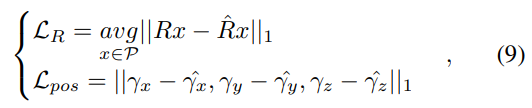
- \hat{.}는 GT
refinement 모듈은 offset을 출력하지만 식 4를 통해 transformation을 구할 수 있고, 식 4는 미분가능하여 CRT-6D를 직접적으로 최적화 할 수 있습니다.
Experiments
Linemod-Occlusion(LM-O)과 YCB-V 데이터 셋에 대해 실험을 진행하였습니다. 실험을 통해 반복적인 refinement를 통해 성능 개선과 짧은 inference 시간으로 높은 정확도를 달성할 수 있다는 것을 보여주었습니다.
평가지표는 6D pose Estimation에서 많이 사용하는 ADD(-S)와 BOP challenge에서 사용하는 평가지표 AR(VSD/MSSD/MSPD)를 이용하였습니다. (자세한 설명은 지난 x-review를 참고해주세요. ADD(-S), AR(VSD/MSSD/MSPD))
Accuracy comparison to the State of the Art
- LM-O
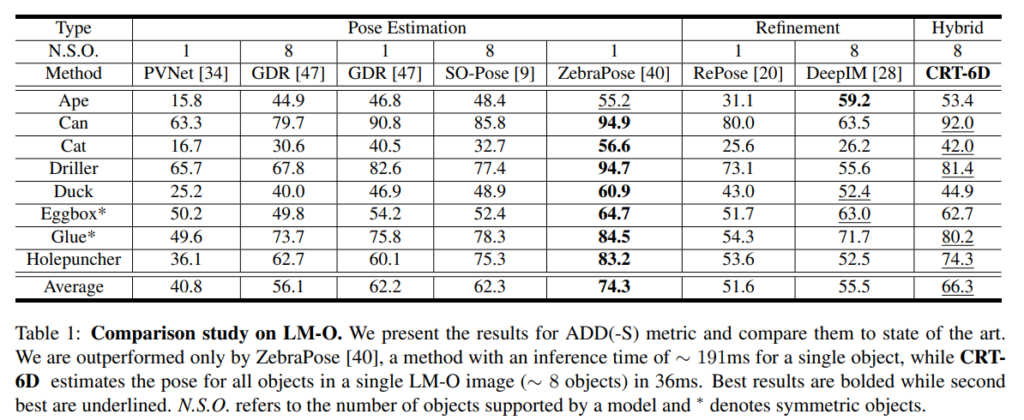
- 아래의 Table 1을 통해 확인할 수 있음.
- ZebraPose방법론 다음으로 2번째로 좋은 성능을 보임. (경쟁력 있는 성능 달성)
- real-time 방법론에서 비교했을 때, real-time에서 SOTA였던 SO-Pose보다 6.4% 개선된 성능을 보임.
- 이에 대해서는 keypoint가 가려졌을 때(oclcusion) deformable attention을 이용하여 멀리 떨어진 영역의 정보도 확인할 수 있기 때문이라고 분석.
- 아래의 Figure5를 참고.

- YCB-V
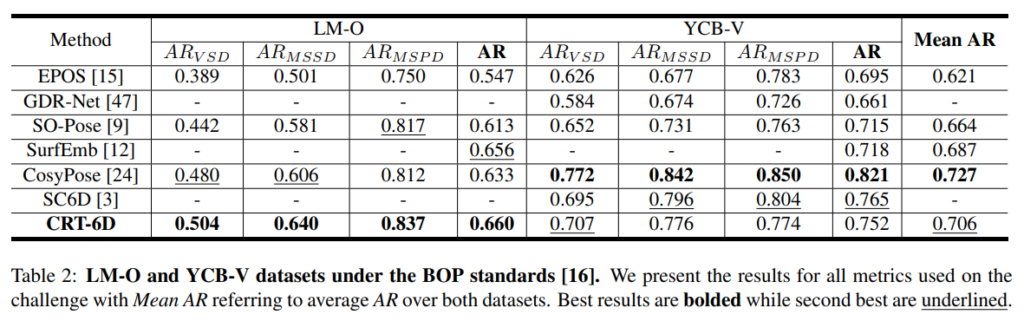
- 각각 72.1%와 87.5의 ADD-(S) 및 AUC를 달성하여 경쟁력 있는 결과를 보임.
- GDRNet과 SO-Pose보다 ADD(-S) 지표에서 46%와 27%, ADD(-S)의 AUC에서 9%와 4% 더 좋은 성능을 보임
- 훨씬 느리게 작동하는 ZebraPose에서만 CRT-6D가 조금 낮은 성능을 보임.
아래의 표는 BOP challenge 평가 기준으로 LM-O와 YCB-V 성능을 나타낸 것입니다.
Ablation studies
- number of OSKFs
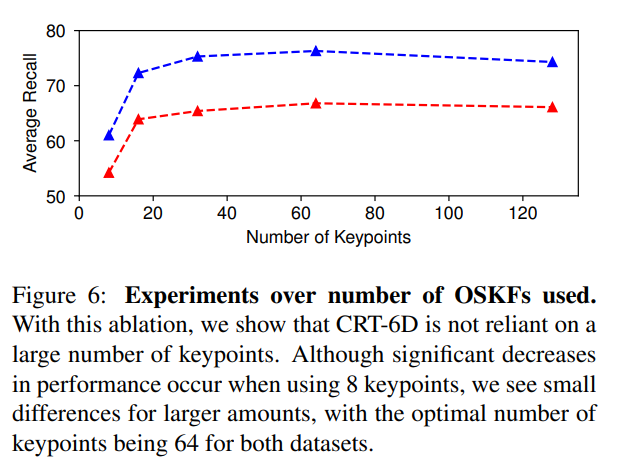
- 아래의 Figure 6에 OSKF 수에 따른 성능을 나타냄.
- 8개에서는 낮은 성능을 보였으나 16~128개 사이의 성능 차는 크지 않음.
- K=64로 설정하였을 때 가장 좋은 성능을 보임.
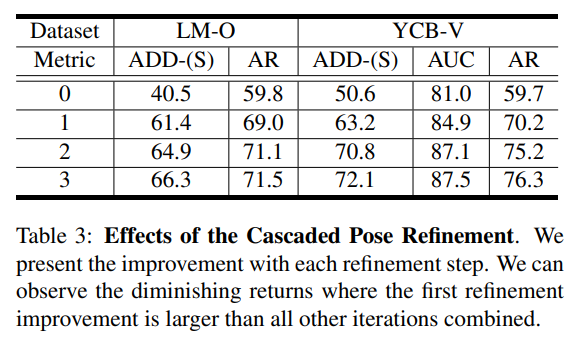
- Cascaded Pose Refinement
- Table 3에서 반복에 따른 정확도를 확인할 수 있음.
- 여러번 세분화를 할 때 개선 효과가 점차 적어지는 것을 확인할 수 있음.
- Effect of coarse pose accuracy
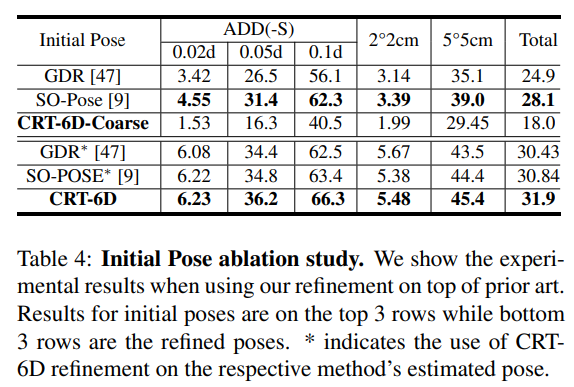
- 초기 pose에 따른 성능을 Table 4에서 확인할 수 있음.
- 위의 결과 3개를 통해, 다른 방법론에 적용하여도 성능이 개선되는 것을 확인할 수 있음.
- 아래의 결과 3개를 보았을 때, 연산 비용이 많이 드는 방식을 적용하는 것 보다 간단한 MLP로 구한 coarse한 초기 pose가 더 좋은 결과를 얻은 것을 통해 중복적이고 불필요한 작업이 필요 없음을 확인함.
안녕하세요, 좋은 리뷰 감사합니다.
맨 마지막 실험의 그림(5)에 대해 잘 이해를 못 해서 질문을 드립니다.
아래의 두 행의 그림에서 self 또는 외부 occlusion으로 인해 빨간점(keypoint)를 흰색점(sample positions)으로부터 가져와서 윤곽 정보를 파악한다고 이해를 했는데, 이해한 게 맞는지 궁금합니다.
하단에서 맨 우측에 있는 그림과 같은 경우는 keypoint가 benchvise에 있는 것 같은데 sample point가 ape 쪽에 분포가 되어있는 것으로 보이는데 이런 케이스는 어떻게 윤곽정보를 파악하는지 궁금합니다.
감사합니다.
질문 감사합니다.
먼저 첫번째 질문에 대해서는 제대로 이해하신 게 맞습니다. 빨간점이 FPS로 선택한 keypoint에 해당하고, 흰 점들이 deformable sample position에 해당합니다. 이처럼 keypoint 영역이 가려진 경우, 샘플링된 주변 영역 정보를 활용하여 pose를 추정하게 됩니다.
또한, 두번째 질문에 대해서도 설명을 드리자면, 우선 keypoint는 benchvise에 속해있다기보다도, ape 클래스의 keypoint가 benchvise객체에 의해 가려진 occlusion 상황입니다. 이러한 경우, 위의 질문에 대한 대답과 동일하게 흰색으로 표시된 주변 sample point의 정보를 이용하게 됩니다. 이게 가능한 이유는, attention 매커니즘을 이용하였기 때문으로, attention을 통해 long distance의 정보들을 활용할 수 있게 되었기 때문입니다.