Abstract
모델의 정확도가 중요한 도메인에서는 보다 깊고 넓게 레이어를 쌓는 방향으로 진행된다. 그러나 이러한 방식의 접근은 문제점이 있는데 바로 복잡한 모델 구조에 의해 연산량과 필요 메모리가 기하급수적으로 증가한다는 것과 응답 시간이 느려진다는 것이다. 이에 저자들은 self-distilatin이라는 training framework를 제안하는데, 이는 네트워크의 크기를 키우는 대신 축소시키는 방향으로 성능을 향상시키는 방법이다. 기존 Knowledge Distilation은 네트워크 간의 knowledge transform method로써, 사전 학습된 teacher의 softmax output을 예측하는 방향으로 student를 학습시킨다. 그러나 self distilation은 이러한 distilation이 하나의 내트워크 내부적으로 진행된다. 먼저 하나의 네트워크를 여러 구역으로 나누어 깊은 구역의 knowledge가 얕은 부분으로 점점 squeeze된다. 이러한 기법을 기존 모델에 적용했을 때 평균적으로 2.65%의 정확도 상승이 발생하였고, 논문의 실험에서 가장 상승폭이 적었던 모델은 0.61%의 ResNext 이고, 가장 상승폭이 큰 모델은 VGG19로 약 4.07% 의 정확도가 향상되었다.
Introduction
저자들은 intro에서 CNN의 발전과 이에 따른 application연구가 활발히 진행되고 있음을 언급하였는데요, 요즘 관련 학회에서도 논문이 쏟아지는 것을 보면 classification, detection, segmentation같은 cnn application들이 전례없는 속도로 발전하고 있는 것을 알 수 있습니다. 그 중 자율 주행 및 의료 영상 분석과 같은 application에서는 정확도의 향상 뿐 아니라 computational storage와 response time을 줄이는 것 또한 중요하며 이를 위한 model compression 관점에서의 approach도 연구되었다고 합니다.
가장 대표적인 compression approach로는 Knowledge distilation이 있으며 KD는 large pretrained teacher 모델의 지식을 student 모델로 전달하는 방법으로, student 모델들은 상당한 성능 향상을 기대할 수 있게 됩니다.
논문의 저자들은 기존 KD의 두 가지 문제점을 지적하였는데요, 하나는 teacher 모델의 knowledge를 student 모델이 제대로 활용하지 못하는 것입니다. KD자체가 teacher가 가지는 예측의 분포를 student가 따라가도록 학습하는 것이므로 이미 많은 파라미터를 가진 teacher 모델의 뛰어넘는 student가 거의 없었다고 합니다. 다른 하나는 student를 학습시킬 적절한 teacher 모델을 설계하고 학습하는 것이 어렵다는 것입니다.
이러한 문제점들을 개선하기 위해 저자들은 one-step 방식, 즉, student 모델을 scratch부터 학습하는 방식인 Self-distillation(SD)을 제안하였습니다. [그림1]은 기존 KD와 저자들이 새롭게 제안하는 SD의 framework입니다.
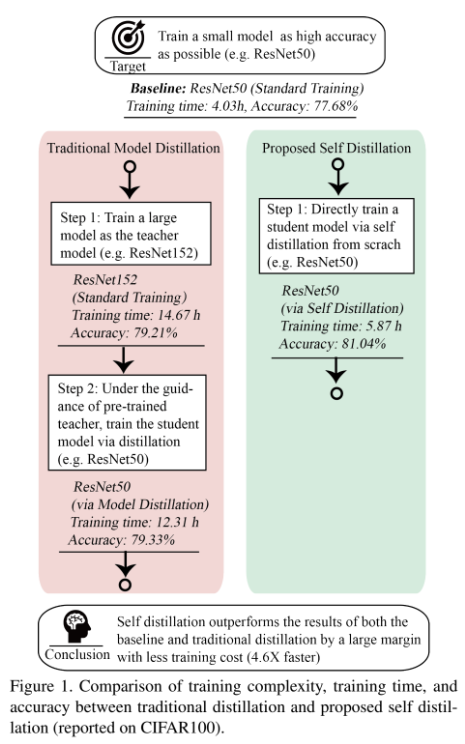
논문의 contribution은 크게 아래와 같은 세 가지로 정리할 수 있습니다.
- Self distillation improves the performance of convolutional neural networks by a large margin at no expense of response time. 2.65% accuracy boost is obtained on average, varying from 0.61% in ResNeXt as minimum to 4.07% in VGG19 as maximum.
- Self distillation provides a single neural network executable at different depth, permitting adaptive accuracy-efficiency trade-offs on resource-limited edge devices.
- Experiments for five kinds of convolutional neural networks on two kinds of datasets are conducted to prove the generalization of this technique.
Self Distilation
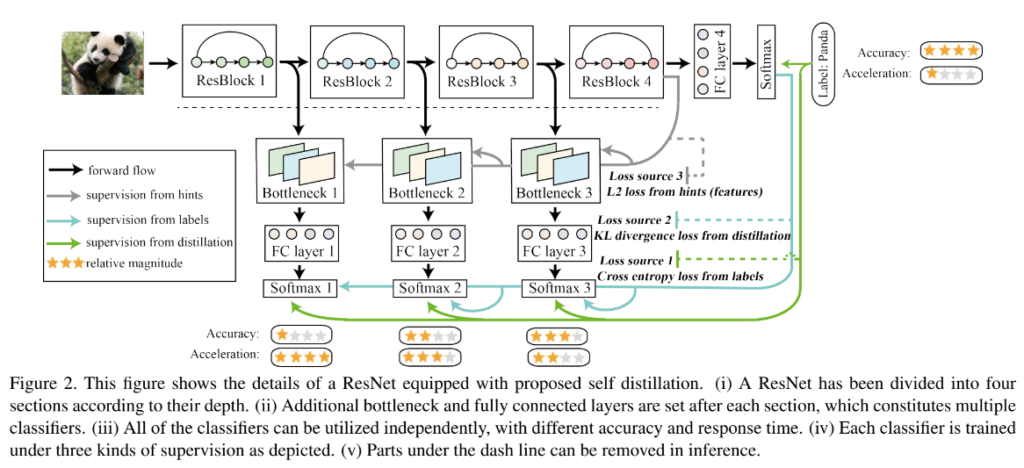
self-distilation의 pipeline은 위의 [그림2]와 같습니다.
먼저 target 네트워크를 여러 개의 section으로 나눈 후 나눠진 각 section에 bottleneck과 fc레이러로 구성된 shallow classifier를 붙입니다. 그리고 target, shallow network를 학습시킵니다.
target 네트워크, shallow classifier 등 용어가 갑자기 튀어나와 당황스러우셨을 수도 있는데요, 간단히 예를 들어보겠습니다. [그림2]가 ResNet50을 이용하여 이미지 분류를 수행하는 것이라고 할 때, 가로 방향으로 forward가 이루어지는 ResNet50 (ResBlock1~4 + FC4 + Softmax)을 original structure, target network라고 합니다. 이 target network를 depth에 따라 4 부분으로 나누면 그림과 같이 ResBlock1~4가 되고, 각 ResBlock이후에 bottleneck+FC + softmax를 추가하여 resnet50보다 작은 크기의 분류기 3개가 추가되는 것을 볼 수 있는데 이들을 각각 shallow classifier라고 합니다.
학습이 진행되면 각 section의 shallow classifier가 student처럼 학습되고 이때 가장 깊은 section인 target network를 teacher로 하여 학습을 진행하게 됩니다.
[그림2]를 보면 self distilation에는 총 세 가지의 loss를 사용하는 것을 볼 수 있으며 각각의 설명은 아래에서 진행하겠습니다.
Loss source 1은 전체 네트워크 뿐 아니라 각 얕은 분류기에도 사용되는 cross entropy loss입니다. 우리가 알고 있듯이 각 분류기의 softmax output과 gt의 차를 구하는 것으로 데이터셋의 label이 가진 knowledge를 직접적으로 각 분류기에 전달하는 역할을 수행합니다. CE에 관한 것은 알고 계시리라 생각되어 자세한 설명은 생략하도록 하겠습니다.
Loss source 2는 KL loss로, 위의 CE loss가 모델의 예측값과 gt 간의 관계를 나타낸다면 KL loss는 student와 teacher사이에 사용됩니다. KL divergence를 통해 self-distilation framework는 각 shallow classifier에 대한 teacher(deepest classifier)에 영향을 끼치게 된다고 하는데요, KL divergence는 teacher의 softmax output을 studemt의 softmax output과 비교함으로써 각 student가 teacher의 knowledge를 학습할 수 있도록 합니다. 사실상 이 KL loss가 knowledge distilation의 가장 기본적인 loss를 나타낸다고 이해하시면 될 것 같습니다.
마지막 loss source 3 는 L2 loss로 network의 hint간의 distance를 줄이는 것을 목표로 하는 loss입니다. [그림2]를 보면 파란색 화살표가 KL loss를, 회색 화살표가 L2 loss를 나타내고 있는데 이러한 두 가지의 loss는 teacher와 student의 prediction(softmax output), backbone에서 추출된 feature map중 어느 것을 비교하는지만 다르고 결국 teacher network의 표현에 student가 가까워지도록 학습합니다. 논문에서는 이때의 l2 loss를 hint간의 loss라고 하며 feature map이 담고 있는 명료하지 않은 지식을 얕은 분류기의 bottleneck에 전달하는 역할을 수행한다고 표현하였습니다.
[그림2]의 ResBlock의 점선 아래 부분에 새로 추가된 레이어들은 학습할 때만 사용하고 inference할 때는 아무런 영향을 미치지 않습니다. 그러나 inference할 때 bottleneck과 shallow classifier를 추가하는 것은 edge device에서 사용할 수 있는 하나의 option을 제공함으로써 dynamic inference가 가능하게 합니다. edge device는 연산 자원이 한정되어 있어 최대한 compact하게 돌아가야 합니다. 이때 전체 모델보다 작은 shallow classifier를 사용할 수 있으면 teacher의 표현력을 가지면서도 다양한 size의 모델을 사용할 수 있게 된다는 의미입니다.
Formulation
[그림2]의 각 분류기에서 softmax의 출력은 아래의 [수식1]과 같습니다.
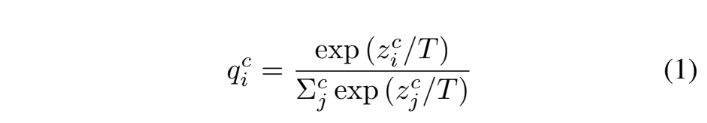
[수식1]은 입력 데이터 X에 총 M개의 클래스가 존재하고, 이를 총 C개의 분류기를 가진 네트워크로 학습을 진행할 때, 분류기 \theta_{c/Cj}에서 예측한 i번째 클래스의 확률값을 의미합니다. 이때 일반적인 soft위의 수식에 T값이 추가된 것을 확인할 수 있는데요, T는 temperature of distilation으로 T의 크기가 커질수록 softmax output이 soft 해집니다.
예를 들어, 일반적인 분류기에서 개, 고양이 새를 각각 [0.1 0.9 10^{-9}]로 예측했다면 이 모델은 입력 이미지를 고양이로 예측했음을 알 수 있습니다. 이때, 예측한 클래스 이외의 클래스들을 보면 [0.1 10^{-9}]이 모델은 입력 이미지를 개와 새 중 개에 더 가깝다고 판단한 것을 알 수 있습니다. knowledge distilation은 이러한 모델의 경향성 또한 학습에 사용하는 것으로, 이 지식을 모델 학습에 반영하기에는 그 값이 작기 때문에 T값을 통해 soft하게 만들게 됩니다. 위의 예시를 soften 하면 [0.3, 0.6, 0.1]정도로 나타낼 수 있고 이를 모델의 knowledge라고 합니다.
Training Methods
아래의 수식들은 순서대로 Cross Entropy, KL, L2 loss를 나타내며 개념적인 부분은 위의 ‘Self-distilation’에 언급하였으니 간단히 보고 넘어가겠습니다.
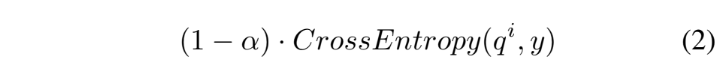
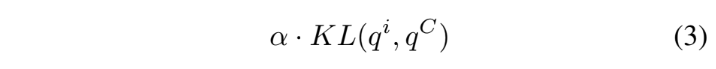
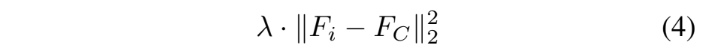
위의 세 가지의 loss를 모두 포함하는 최종 loss는 아래의 [수식 5]와 같습니다.
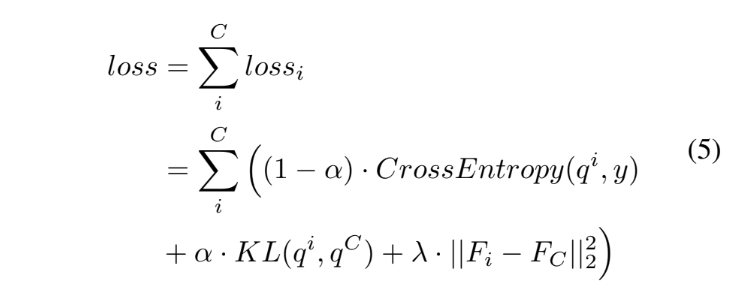
deepest 네트워크 또한 위의 loss로 학습하며 이때의 \alpha와 \lambda값은 둘 다 0으로, teacher에 해당하는 가장 마지막 분류기는 label에 의한 supervised learning만을 진행합니다.
Experiments
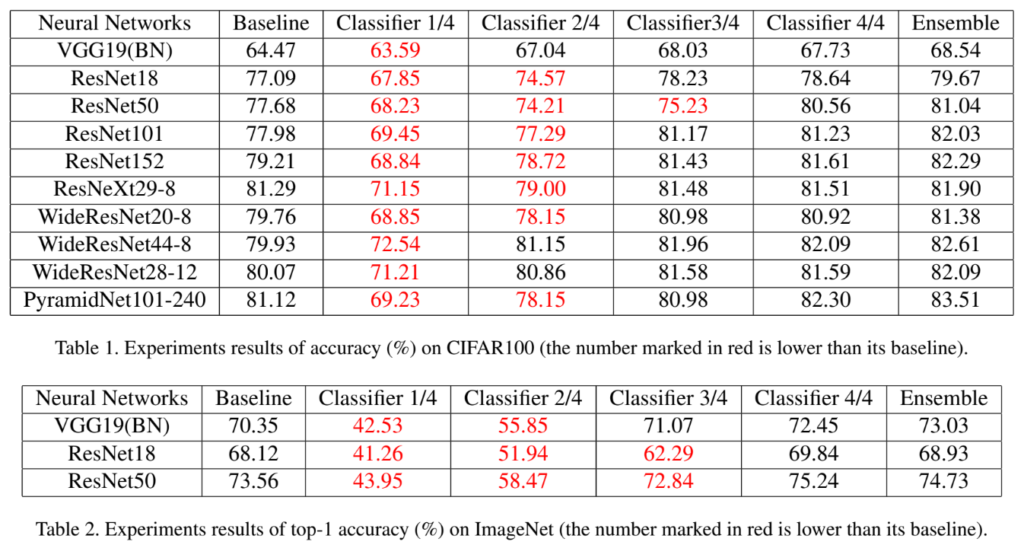
실험에는 Cifar100, ImageNet 데이터셋이 사용되었으며, 총 5개의 네트워크(ResNet, WideResNet, Pyramid ResNet, ResNext, VGG)를 4개의 section으로 분할 후 self distilation을 적용한 결과를 비교하였습니다.
Compared with Standard Training
아래의 [표1]과 [표2]가 메인 실험 결과입니다. 앙상블의 경우 각 분류기의 softmax output을 더해주는 방식으로 진행하였다고 합니다. baseline과 classifier4/4를 비교하였을 때, 동일한 모델 구조를 사용하였음에도 학습 시 self-distilation의 사용 여부에 따라 성능 향상이 일어난 것을 확인할수 있으며, 모델의 깊이가 깊을수록 그 향상폭이 큰 것을 확인할 수 있습니다.
Compared with Distilation
[표3]은 다른 distilation 방법론들과의 비교를 수행한 결과입니다. 각 실험은 Student Model의 성능을 리포팅하였습니다.

저자들은 Student모델이 동일한 연산량, 메모리를 가지는 환경에서 학습 방법의 차이에 의해 성능 차이가 발생하는 것에 주목하며 distilation방법론 자체에 대해 설명하였는데요, Baseline은 student 모델을 단순 학습시킨 것으로 모든 경우에서 teacher 모델의 knowledge를 distilation하는 것이 더 좋은 성능을 보이는 것을 확인할 수 있습니다.
그러나 다른 distilation 방법론들은 사전 학습된 Teacher Model이 필요하지만 our apprach인 self-distilation은 Student만으로도 좋은 성능을 낼 수 있음을 강조하였습니다.
좋은 리뷰 감사합니다.
혹시 그림 2에서 acceleration은 무엇을 의미하나요? 추상적으로는 얼추 이해가 가는데 저자들이 직접 해당 용어에 대해 설명하고 있는 부분이 있는지 궁금합니다.
그리고 loss3이 network hint간의 distance를 줄이는 역할이라고 해주셨는데, hint라는것은 결국 각 block의 feature map인 것인가요? Block 간 feature를 l2 loss로 유사하게 만들어준다면 각 block이 보는 표현력 관점에서 부작용도 있을 것 같다고 생각하는데, 논문에 loss별 ablation 성능은 없는지도 궁금합니다.
안녕하세요 댓글 감사합니다.
질문에 대해 하나씩 답변 드리자면
1) Acceleration은 baseline대비 training time의 향상율을 의미합니다. [그림2]의 경우 전체 네트워크의 학습 시간을 별 4개로, 각 분류기의 training time을 상대적으로 표현하였으며 논문의 실험 부분에서는 ResNet50기준 classifier1~3이 각각 3.11x, 1.87x, 1.30x의 acceleration이 발생하였다고 합니다.
2) hint라는것은 결국 각 block의 feature map인 것인가요? → 넵 맞습니다. 추가로 hint learning이라는 방법론 자체는 FitNet이라는 기존 논문에서 가져온 기법으로 관련 ablation study는 해당 논문을 참고하시면 좋을 것 같습니다. 이 논문에서는 별도의 loss별 ablation은 실험하지 않은 것 같습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
loss source 3에서 feature map이 담고 있는 명료하지 않은 지식을 얕은 분류기의 bottleneck에 전달하는 역할을 수행한다고 말씀해주셨는데 bottleneck은 student 모델의 한 부분이고, backbone에서 추출된 feature map이 teacher가 되는 것일텐데 명료하지 않은 feature map이라고 정의되는 이유가 궁금합니다. teacher 구조에서 추출한 feature map representation 과 student 간에 발생하는 distance를 줄이고자 L2 loss를 적용하는 것이 아닐까요 .. ? 그런데 애초에 teacher의 feature map이 명료하지 않은 지식이라고 정의된다는 것이 매칭이 되지 않고, 만약 그러한 feature map을 전달한다면 서로 간의 distance를 줄일 때 오히려 성능이 떨어질 수도 있겠다고 생각하는데 loss source 3과 관련된 실험은 없었는지 궁금합니다 !
좋은 리뷰 감사합니다.
해당 방법론은 target 네트워크 자체가 teacher가 되고, shallow classifier들이 가장 마지막 classifier의 분포를 따라가도록 학습하는 것으로 이해하였습니다. 즉, 기존 방법론들은 분리된 teacher와 student가 있었으나, teacher의 학습이 어렵고, 파라미터가 많은 teacher를 student가 따라가기 어렵다는 문제를 해결하고자 하나의 네트워크에 teacher와 student를 도입한 것이라 이해하였습니다.이와 관련하여 몇 가지 질문이 있습니다.
우선 학습이 어렵다는 문제는 하나의 네트워크로 통일하여 학습하면서 deeper 분포를 따라가도록 한 것으로 이해하였는데, 그렇다면 teacher 자체도 student의 영향을 받아 성능이 개선 된 것인가요??
또한, 파라미터가 더 많기 때문에 student가 teacher를 따라가기 어렵다는 문제도 하나의 네트워크를 이용하는 것으로 해결할 수 있는 것인가요?? 만약 그렇다면 어떻게 해결하였는지 조금 더 설명해주실 수 있나요??
마지막으로 Table3의 our approach는 저자들이 제안한 방식의 앙상블 결과를 의미하는 것인가요?
안녕하세요 ! 좋은 리뷰 감사합니다.
loss source 3을 설명해주실 때 network의 hint간의 distance를 줄이는 것이 목표인 loss라고 이어 설명해주셨고, 또, , , 실험에서 앙상블이 각 분류기의 softmax output을 더해주는 방식이라고 하셨는데, 이 두 부분이 잘 이해가 안가서 좀 더 구체적으로 설명해주실 수 있을까요 ?
또, 실험 파트에서 총 5개 네트워크를 가지고 실험을 진행했는데 table2에서는 3개의 네트워크 실험 결과밖에 없는 이유도 궁금하네요. . 이 table3개가 실험의 전부인가요 ?
감사합니다.
질문 감사합니다.
우선 Loss 3은 hint learning에 사용되는 loss로 여기서 hint란 backbone에서 나온 feature map을 의미합니다. 그리고 hint learning은 [그림 2]를 예시로 들자면 ResBlock1,2,3 + bottleneck의 각 feature map이 ResBlock4의 feature map과 유사해지도록 학습하여 결과적으로는 resblock1~4의 표현력을 그보다 적은 네트워크가 가져갈 수 있도록 하는 것이라고 이해하시면 될 것 같습니다.
다음으로 앙상블에 관한 것은 classification시 weight를 모두 1로 하여 soft voting을 사용했다는 의미입니다.
[표2]의 경우 질문해주신 대로 세 가지의 실험만이 리포팅되어있으며 별도의 언급은 없었는데요, 제 생각에는 [표1]은 Cifar100데이터셋으로 [표2]는 ImageNet데이터를 사용한 것으로 보아 메모리 자원의 한계로 Large Model에서 ImageNet으로는 실험을 진행하지 못 한 것이 아닐까…? 라는 생각이 들었습니다만… 논문에는 별다른 언급이 없어 잘 모르겠습니다.