
안녕하세요.
최근 1~2주동안 계속 산자부 OCR 작업을 수행하는 중인지라 논문을 거의 읽지 못했는데요, 그럼에도 불구하고 내일부터 3일간 KCCV 학회에 가기 때문에 논문을 좀 읽고 리뷰를 써야겠다는 생각이 들었습니다.
그래서 KCCV에 구두, 포스터로 발표되는 논문 리스트를 한번 훑어봤는데요,
제 개인적인 생각으로 논문 리스트에 가장 많이 포함된 키워드는 아래 3가지였습니다.
- Multi-modal (Vision + \alpha)
- 생성 모델을 활용한 something (Difussion,,,,)
- Contrastive
과제 일정이 끝나고 조금 여유로워 지면 개인적으로 multi-modal 논문도 한번 읽어보고 싶은 생각이 있지만, 지금은 그 정도의 여유는 없는지라 아무래도 익숙한 분야의 논문을 읽게 되었습니다.
오늘 리뷰 할 논문은 UDA(Unsupervised Domain Adaptation)을 통한 Semantic Segmentation을 수행하는 논문에 Contrastive Learning 기법을 한 스푼 첨가한 논문입니다. 연세대학교 cv lab에서 작성한 논문이네요.
제가 Contrastive Learning 쪽에 대해서 deep하게 알지 못해서 논문 제목에 contrastive 라는 키워드가 있으면 조금은 기피하는 경향이 있었는데요, 제가 실험&연구하고 있는 환경이 unsup(or self-sup) 이다 보니 언제까지 피할 수만은 없다는 생각이 들었습니다.
마침 KCCV 논문 리스트에 contrastive 라는 키워드가 많이 있기도 했고, 제가 오늘 리뷰 할 논문도 이번 KCCV 포스터 세션에서 발표되는 논문이기 때문에 이참에 contrastive 분야에 대해서 읽어보게 되었습니다.
그럼 리뷰 시작하도록 하겠습니다.
1. Introduction
Semantic Segmentation 는 다들 아시다시피 pixel level로 class를 예측하는 task 입니다. 그렇기 때문에 이를 supervised 방식으로 학습하기 위해서는 pixel-level로 라벨링이 되어있는 데이터셋을 사용해야 합니다.
하지만 segmentation 분야 데이터셋을 라벨링 하는 데에는 정말 많은 시간적 비용이 필요합니다. 예를들어 2048 x 1024의 Cityscapes dataset 한 장을 사람이 직접 annotation을 하는데에 약 90분이 소요가 된다고 합니다.
그렇기 때문에 많은 연구자들은 GTA5 나 SYNTHIA 등의 합성 데이터셋을 사용해서 연구를 수행합니다. 물론 이런 합성 이미지들이 realistic한 이미지들로 구성되어 있긴 하지만 실제 outdoor 도메인과는 차이가 존재하기 때문에 합성 데이터셋으로 학습한 모델을 real 데이터셋에 곧장 적용했을 때 domain discrepancy(도메인 차이) 로 인한 성능 하락이 발생하게 됩니다.
아래는 GTA5 데이터셋의 일부입니다.

이렇게 두 데이터셋 (source, target) 사이의 domain discrepancy 를 줄이고자 많은 UDA (Unsupervised Domain Adaptation) 연구들이 수행이 되고 있습니다.
(Source Dataset -> Target Dataset으로 Domain Adaptation이 수행될 때 Target Dataset의 gt를 사용하지 않을 경우 UDA 라고 칭합니다.)
UDA의 핵심은 결국 target gt를 사용하지 않고 source domain과 target domain의 차이를 줄이면서 domain-invariant한 feature를 학습하는 것입니다.
그리고 현재 UDA를 수행하는 방식에는 크게 두 가지가 존재합니다. adversarial training 구조를 사용하는 방식과, self training을 사용하는 방식입니다.
저자는 앞선 두 방식들 모두 문제점이 존재한다고 주장하면서 새로운 UDA 기법을 제안하게 됩니다. 각각에 대한 정의와, 저자가 제시한 문제점에 대해서 간략하게 살펴보도록 하죠.
UDA 1: Adversarial Training
많은 UDA 수행 논문들에서 사용하고 있는 방식입니다.
해당 방식의 핵심은 discriminator 를 속이는 방향으로 학습해서 source domain과 target domain의 feature 분포를 최대한 유사하게 만드는 것입니다. 그러면 source domain의 decoder 를 target domain에서도 사용할 수 있게 되겠죠.
저자는 여기서 adversarial training 방식이 보통 global 한 domain discrepancy를 줄이는 데에 초점을 두고 있기 때문에 pixel-level의 의미론적인 정보를 유지하는 데에 실패한다고 주장합니다. 아무래도 discriminator를 속이려면 이미지 한장의 전체적인(global) 분포를 유사하게 만들어야 하기 때문에 local한 pixel-level이 각각 담고있는 의미적인 정보까지는 반영하지 못한다는 의미입니다.
저자는 이에 대해
car와 bus라는 클래스는 local한 정보는 확연히 다르지만, 도로 위에서 움직이는 moving object라는 관점으로 global 한 정보는 비슷하기 때문에 이 두 클래스에 대한 feature 분포가 유사해진다는 문제가 있다고 언급합니다.
UDA 2: Self-Training
그렇다면 self-training 방식을 사용한 UDA는 어떻게 동작할까요?
우선 source 데이터셋으로 학습된 모델로 target 데이터셋의 segmentation map을 예측합니다. UDA가 수행되지 않은 채 source로 학습된 모델로 단순하게 target을 예측했기 때문에 domain gap으로 인한 성능 하락이 꽤나 존재하겠죠. 그리고 여기서 예측한 segmentation map에서 confidence가 특정 threshold 값 이상인 픽셀을 초기 pseudo label로 설정하게 됩니다.
thresholding 과정에 대한 이해를 위해선 장황한 글 보다는 그냥 아래의 그림 한장으로 정리할 수 있을 듯 합니다. 그냥 단순하게 pixel-wise로 confidence를 thresholding 해서 정의된 threshold 값 이하의 confidence를 가지는 pixel은 그냥 0으로 채워버리는 겁니다.

그 다음엔 source domain의 gt와 target domain을 위한 pseudo label을 사용해서 iterative 하게 반복적으로 모델을 학습해나가게 됩니다.
그런데 여기서 iterative하게 self-training을 진행할 때 위 그림의 초기 pseudo label을 계속해서 사용해도 될까요? 물론 되긴 합니다만 성능의 upper가 매우 낮겠죠. 그렇기 때문에 iterative한 학습을 진행하면서 pseudo label을 update 하는 과정이 필요합니다.
물론 끊임없이 매 iteration마다 pseudo label을 update하는게 젤 좋지만, computational overhead로 인해 많은 연구들에선 특정 iteration (ex. 10000) 을 수행한 후 pseudo label을 update 한다고 하네요. 저자가 이에 대해서 “very occasionally” 라고 표현한 것으로 보아 아주 가끔씩 pseudo label이 update 되나 보네요.
아무튼 이렇게 반복적으로 target domain을 위한 pseudo label을 점차적으로 update 해 나가면서 동작하는 self-training 방식도 최근 많이 제시되고 있습니다.
해당 방식에선 pseudo label 을 source dataset에서 학습한 모델을 통해 생성하게 되고, 모델의 예측을 통해 생성되는 것이기에 저자는 이를 parametric approach 라고 표현합니다.
하지만 여기서 저자는 이런 parametric approach 를 통해 pseudo label을 얻는 과정에서 2가지 치명적인 문제점이 있다고 주장합니다.
- 신뢰도 높은(reliable) pseudo label을 얻기 위해 낮은 confidence를 가지는 pixel에 대해선 thresholding 과정을 통해 버려지기 때문에 매우 sparse 하다는 문제가 발생합니다. 이는 제가 첨부한 위 그림만 봐도 알 수 있겠네요.
- computational overhead 로 인해 학습과정에서 few epochs동안 pseudo label 이 고정된 상태로 학습이 진행되기 때문에 고정된 pseudo label에 target 모델이 overfitting 되게 됩니다.
하지만 thresholding을 통해 confidence가 높은 pixel만을 사용했다고 할지라도 pseudo label에 오류가 존재할 경우 이에 대한 error가 few epochs 동안 계속해서 중첩되겠죠?
정리하자면, 부정확한 pseudo label에 overfitting될 뿐만 아니라 잘못된 pseudo label로 인해 최종적인 예측이 큰 bias와 variance를 가지는 문제가 발생합니다.
이렇게 UDA를 수행하는 대표적인 두가지 방식에 대한 문제점을 제시하면서 저자는 새로운 UDA 방식을 제안하게 되고, 이를 bi-directional pixel-prototype contrastive learning framework 라고 명명합니다.
앞서 저자가 말하길,
기존 adversarial 방식의 UDA 는 이미지 전체적인, global한 feature 분포의 align을 맞추는 데에 초점을 두기에 local한 pixel-level의 의미적인 정보에 대한 고려는 잘 하지 못한다고 주장하였습니다.
이를 위해서 저자는 source 와 target 양방향으로 pixel-prototype contrastive learning을 수행하게 됩니다.
prototype이란 few/zero shot learning 에서 등장한 개념이고, 이는 contrastive learning 에서도 활용되고 있습니다.
저희가 아는 보통의 contrastive learning 은 anchor를 기준으로 다른 instance와의 positive, negative pair를 정의하고 학습을 진행하게 됩니다.
prototype은 contrastive learning을 instance 단위로 하는것이 아니라, instance들을 clustering해서 prototype을 정의한 뒤 prototype 단위로 contrastive learning을 하는 것을 의미합니다. 아래 그림에서 이를 잘 나타내 주고 있습니다.
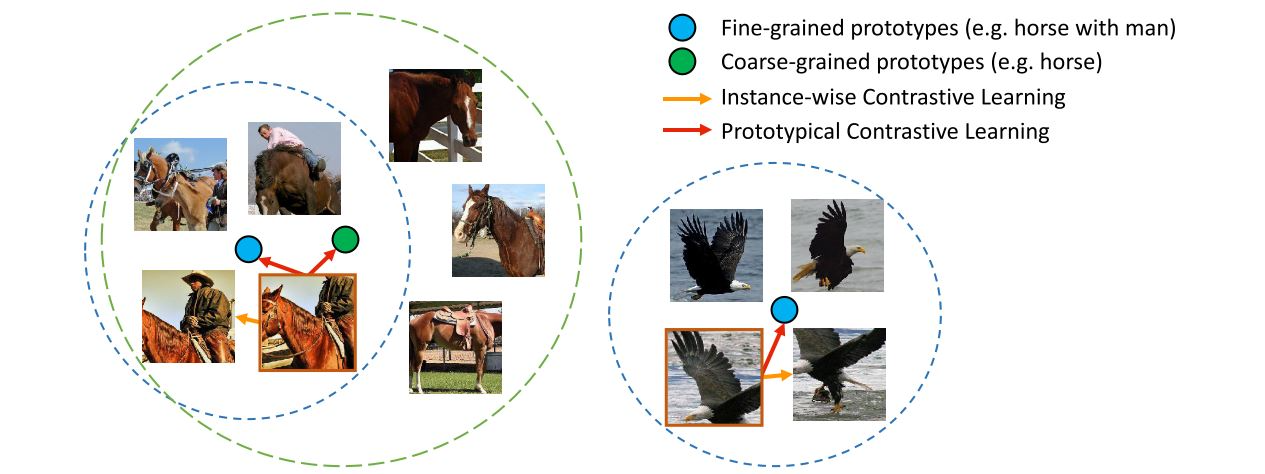
기존 방식 중 PANet 에서 few-shot semantic segmentation 을 위해 prototype 개념을 사용했다고 합니다. 저자들은 해당 논문과 유사한 방식을 사용했음을 인정하면서도, 이를 UDA를 위한 contrastive learning을 수행하는 framework에 적용시켰다고 하네요.
아래의 그림이 source 와 target 양방향으로 pixel-prototype contrastive learning 를 수행하는 본 논문의 방식을 잘 나타내 주고 있습니다.
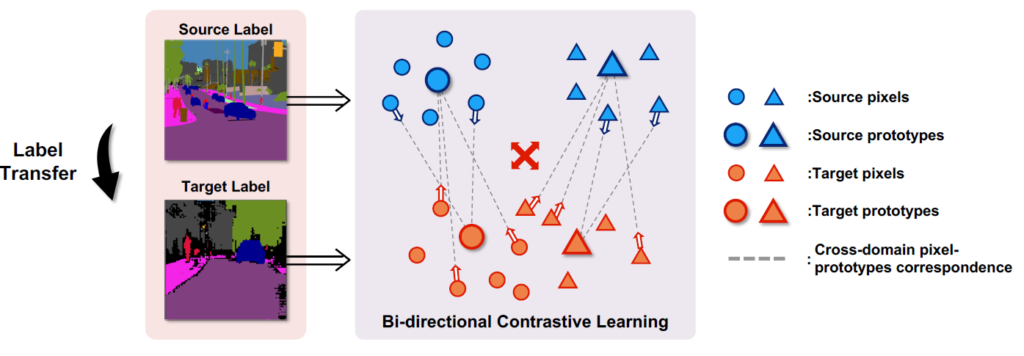
여기선 prototype이 어떻게 정의될까요?
동일 class를 나타내는 pixel들 클러스터 중심이라고 생각하시면 되는데, 수식적으로 어떻게 정의되는지는 method 에서 다루도록 하겠습니다.
위 그림에서 source와 target 각각에 대해 pixel들이 존재하고, prototype들이 존재하고 있습니다. 위 예시의 경우 동그라미와 세모 두가지 class이기 때문에 prototype 또한 각각 2개씩인 것을 확인하실 수 있습니다.
그리고 source를 기준으로 봤을 때 source 의 각 픽셀들이 target의 두 class-wise prototype과 점선으로 연결되어 있는 것을 볼 수 있습니다. 그리고 이들 사이에서 contrastive learning 이 수행되게 됩니다. 동일 class 끼리 수행되기 때문에 해당 source pixel – target prototype을 positive 관계로 보고 contrastive loss를 부여하게 되는것이죠.
그리고 본 논문 제목에서도 언급되었다시피 Bi-directional(양방향) 이기 때문에 source target 반대의 관계에 대해서도 동일한 과정이 수행됩니다. target pixel – source prototype 이 되겠죠.
이미지 전체의 pixel 분포를 유사하게 만드는 기존 방식과 달리, 본 논문에선 pixel 분포를 유사하게 만드는 contrastive learning을 수행할 때에 class 단위로 수행하기 때문에 확실히 local한 의미 정보를 잘 반영하게 될 거 같습니다.
또한 위의 self-training 방식에서 언급드린 문제 중 parametric 한 pseudo label 예측에 문제가 있다고도 했습니다. 이를 해결하기 위해 Exponential Moving Average(EMA) 방식을 사용해서 nonparametric한 방식으로 pseudo label을 예측하게 됩니다.
해당 방식에 대해선 method에서 자세하게 설명 드리겠습니다.
본 논문의 contribution에 대해 정리 후 method로 넘어가도록 하겠습니다.
- domain-invariant & discriminative 한 feature representations 학습을 위해 bi-directional pixel-prototype correspondence를 사용하여 새로운 contrastive learning framework 제시
- dynamic pseudo label 생성을 위한 nonparametric 방식 제시
& source와 target domain 사이의 pixel-prototype 관계에서 domain bias 를 줄이기 위한 calibration method 제시 - SOTA 달성
(적고나니 영어가 너무 많네요 ㅎ)
2. Method
2.1. Overview
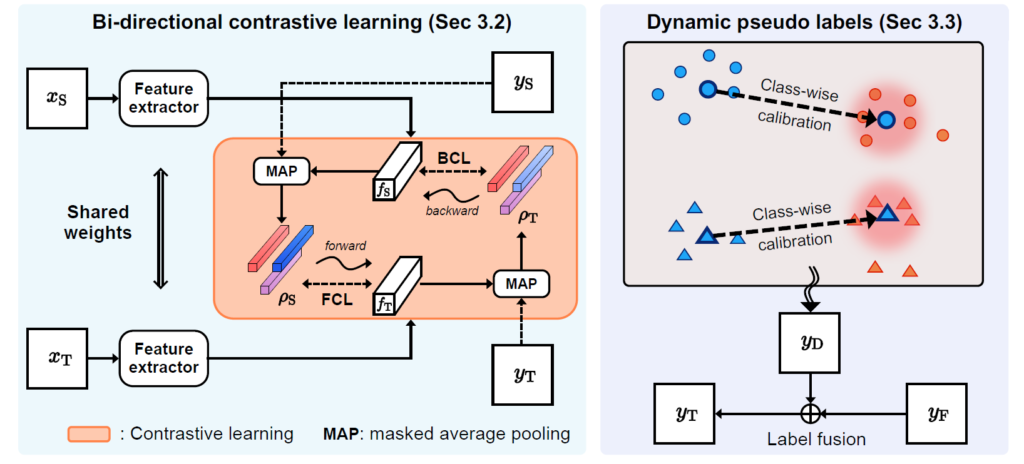
전체 모델 구조는 위와 같습니다.
본 overview 단락에서는 전체적인 동작 흐름의 틀에 대해서만 설명을 드리고 구체적인 수식, 디테일에 대해선 2.2, 2.3에서 다루겠습니다.
우선 siamese network를 사용해서 source 와 target 이미지에 대해 각각 feature map을 추출한다고 합니다.
siamese network가 뭔지 몰라서 구글링을 해 봤더니 입력으로 들어온 두 이미지를 벡터화 시켜서 유사도를 출력해주는 network라고 하네요.
이 siamese network가 위 Feature extractor 내부적으로 적용되는거 같긴 한데 어떤식으로 동작하게 되는지 구체적으로 나와 있진 않네요. 암튼 weight 를 shared 하는 feature extractor 를 사용해서 feature 를 추출한다~ 정도로 보시면 될 듯 합니다.
그리고 prototype을 정의해 줘야 합니다.
source domain의 prototype은 gt labels를 사용해서 정의하면 되고, target domain의 prototype은 pseudo label로 생성하면 됩니다.
(prototype이란 동일 class끼리의 pixel cluster 중심이라고 생각하시면 됩니다)
그리고 생성한 각 prototype을 사용해서 pixel-prototype 관계에서의 contrastive loss를 계산해줘야 합니다. 위 그림 왼쪽 부분에서 BCL, FCL 이라고 적힌 부분이 이에 해당합니다.
또한 기존 self-training의 parametric 기반 static pseudo label이 error 가 누적된다는 문제가 있다고 말씀드렸습니다. 이를 해결하고자 nonparametric label transfer 방식으로 target pseudo label을 생성하는 방식을 저자들은 고안하였고, dynamic pseudo label이라고 말합니다.
위 그림 우측 영역을 보시면, 주어진 source-target image에 대해 source domain의 prototype과 target domain의 pixel-level feature가 동일 class끼리 서로 매칭되어 있는것을 보실 수 있습니다.
그리고 학습 과정에서 생길 수 있는 domain discrepancy 를 보완하기 위한 추가적인 calibration 과정도 추가되어 있습니다.
암튼 이런 과정을 통해 target domain의 dynamic pseudo label인 y_D를 만들어 내게 되고, static label y_F와의 fusion을 통해 최종적으로 target pseudo label y_T 를 만들게 되고, 이 y_T가 위 그림 좌측의 학습 과정에 사용되게 되는 것입니다.
이에 대한 자세한 설명은 2.3절에서 설명드리겠습니다.
2.2. Bi-directional Contrastive Learning
저자들의 목표에 대해 잠시 한번 짚고 넘어가자면,
주어진 source와 target image에 대해서 domain에 관계없이 동일한 class에 대한 pixel-level feature 를 aggregate 해서 결국 domain-invariant 하고 discriminative한 feature representation을 학습하는 것입니다.
이를 위해서 pixel-prototype 관계를 통한 contrastive learning 기법을 설계하였습니다.
그렇다면 prototype이 어떻게 정의되는지 알아야겠죠?
수식은 아래와 같으며,
좌측은 source domain prototype, 우측은 target domain prototype에 대한 식인데, 과정은 동일합니다.
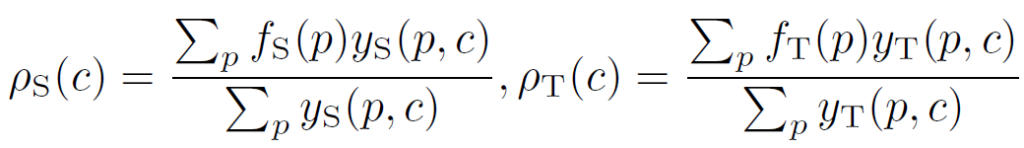
- S, T: Source, Target Domain
- p: pixel position
- c: class 정보
- f(p): pixel-level features (encoder 통과한 feature)
- y(p,c): p 위치에서 class c에 대한 one-hot label 정보 (0 or 1)
y(p,c)의 경우, 만약 pixel p에서의 class label이 c라면 1을, 아니라면 0을 return합니다.
그런데 여기서 스스로에게 든 의문점이 있습니다.
f(p) 는 추출된 feature 이기 때문에 원본 이미지 대비 해상도가 downsampling된 형태일것입니다. 그런데 y(p,c) 는 (pseudo) label에 대한 one-hot 정보이기 때문에 원본 이미지와 해상도가 동일할 것이라 생각했습니다. 그 말은 즉슨 f(p)와 y(p,c)는 shape이 다른데 어떻게 p 라는 동일 위치에서 계산이 가능하지?? 라는 생각이 들어서 github 코드를 까보니 y(p,c)를 feature map f(p)의 size에 맞게 interpolation으로 downsampling 하는 과정이 있더군요. //
위 모델 그림을 보시면 one-hot label y_S 와 pixel-level feature f_S가 합쳐져서 prototype p_S 가 생성될 때 MAP(Masked Average Pooling) 가 적용되는 것을 볼 수 있습니다.
논문에서 딱히 디테일한 설명이 없길래 뭘까,… 라고 고민을 해 봤는데 그냥 pixel level feature f_S를 y_S 라는 binary mask를 씌운 뒤 모든 pixel에 대한 평균값을 구한 것이기 때문에 MAP 라는 표현을 쓴 거 같습니다.
그리고 이렇게 source, target domain에서의 prototype 을 각각 정의했다면 이제 pixel-prototype 관계에서의 contrastive loss를 계산해야겠죠?
위 모델 그림의 FCL과 BCL이 이에 해당합니다.
모델 그림에서 보시면 forward와 backward라는 단어가 보이실겁니다. 이 때문에 ‘하나는 forward할 때 계산되고, 나머지는 backward 할때 계산되나…?’ 등등 모델의 forward, backward 관점으로 생각하실 수 있는데 아닙니다.
그냥 이름을 그렇게 명명한 것이고, 둘 다 매우 유사하게 동작합니다.
pixel-prototype 관계에서 contrastive loss가 양방향으로 계산되기 때문에 하나는 FCL, 나머지 하나는 BCL로 정한 것입니다.
동일 class인 경우 contrastive loss에서 positive로 결정됩니다.
둘 다 계산 과정은 동일하기에 FCL을 기준으로 먼저 설명드리겠습니다.
이는 target feature – source prototype 의 관계에서 계산됩니다.
수식은 우선 아래와 같습니다.
아래 식에서 s(x,y) 는 x와 y의 cosine similarity를 의미합니다.
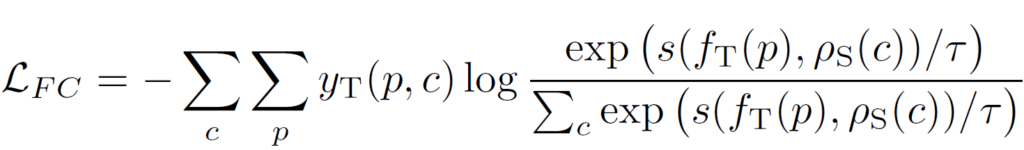
주어진 target pixel-level feature f_T(p) 에 대해 class c에서의 source prototype p_S(c)와 유사도를 계산 하는 것입니다. 앞에 one-hot label y_T(p, c) 가 곱해지는 것으로 보아 유사도 계산에 class c 만 남기고 다 0으로 masking 하는 것이고, 결국 동일 class c 끼리만 positive pair로 보고 유사도 계산을 하는 것입니다.
log 식 앞에 – 부호가 붙어있기 때문에 loss가 최소화가 되는 방향은 결국 pixel-prototype 관계에서 positive pair 의 similarity 가 최대화 되는 방향입니다.
아래 BCL 도 동작 과정은 동일합니다.
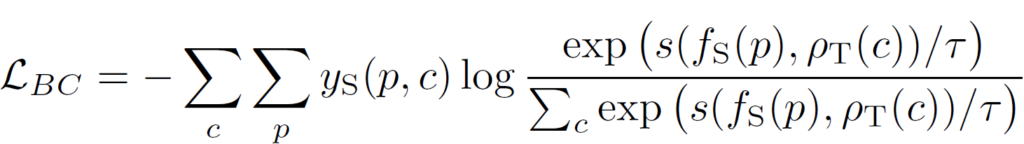
FCL, BCL에 대해 최종적으로 정리해보면 아래와 같습니다.
- FCL: source의 class별 prototype에 대한 target feature의 contrastive learning 진행
- BCL: target의 class별 prototype에 대한 source feature의 contrastive learning 진행
- <최종목표>
FCL을 통해 target feature가 source의 특성을, BCL을 통해 source feature가 target의 특성을 공유(?)하는 방식으로 학습이 진행되면서 domain discrepancy 줄이게 됨
2.3. Dynamic Pseudo Labels
이번 리뷰에서 꽤나 반복적으로 언급하는 말이긴 합니다만,
기존 self-training 기반 UDA에서 parametric 방식으로 생성한 static pseudo label의 경우 few epochs 동안 pseudo label이 고정(static) 되기 때문에 pseudo label에 오류가 있을 경우 해당 error가 반복적으로 누적되게 됩니다.
그리고 특정 threshold를 기준으로, 그리고 이 threshold의 기준치를 매우 높게 잡 pixel-wise confidence thresholding을 진행하게 되는데 신뢰도 있는 pixel만 선별할려고 하다 보니 매우 sparse 하다는 단점도 존재합니다.
이러한 두 문제점을 해결하고자 본 논문은 새로운 dynamic pseudo label을 생성하는 방식을 소개합니다.
(dynamic이라는 단어가 붙은 이유는 아래에서 설명드리겠습니다)
해당 방식은 source-target 이미지의 pixel-prototype 을 사용해서 nonparametric 방식으로 pseudo label을 생성해내는 것입니다. 조금 다르게 말하자면, 모델의 예측이 아니라 source와 target 이미지 쌍을 가지고 pseudo label을 생성한다는 뜻입니다.
이는 결국 모델 학습 과정에서 source 이미지가 변경될 때마다 target 이미지를 위한 pseudo label을 동적으로, 즉 dynamic 하게 예측할 수 있게 됩니다. 매 epoch마다 하나의 target 이미지를 기준으로 쌍이 이루어지는 source 이미지는 매번 바뀌게 되니 매번 상이한 pseudo label을 생성하게 되는 것이지요.
이것이 본 논문에서 생성하는 pseudo label 앞에 ‘dynamic‘ 이라는 글자가 붙는 이유이자, 기존 self-training based UDA 방식에서 생성하는 static pseudo label 문제를 해결해 줄 수 있는 것이지요.
이제 생성 방식에 대해서 구체적으로 알아봅시다.
source 이미지와 target 이미지가 주어졌을 때 source 이미지의 prototype과 target 이미지의 pixel-level feature 사이의 domain correspondence 관계를 생성할 수 있게 됩니다. 동일 class c 끼리 말이죠.
그리고 좀 더 relible한 domain correspondence 관계를 얻기 위해서는 source domain과 target domain의 domain biases를 완화해야 합니다. 사실 직관적으로 두 domain 사이의 domain biases를 완화하기 위해서는 모든 source 이미지와 모든 target 이미지를 사용해서 class별로 feature들의 평균을 계산해서 biases를 계산하면 되겠지만, 이는 computational cost가 많이 소모되죠.
그래서 본 저자들은 이를 위해 source 이미지와 target 이미지 prototype을 사용합니다. (이는 2.1. overview의 우측 그림과도 연관이 있습니다.)
먼저 아래 수식처럼 momentum parameter \lambda로 EMA(Exponential Moving Average) 방식을 활용해서 학습 과정에서 source 와 target domain의 prototype을 점진적으로 update 하게 됩니다.
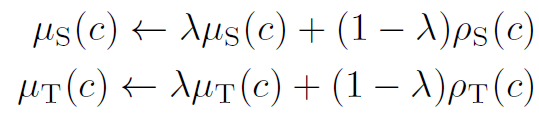
\mu_S(c), \mu_T(c) 는 특정 class c에 대한, 새롭게 update된 source, target prototype을 의미하고,
{0.99, 0.999, 0.9999} 중에서 grid search 방식으로 선정되는parameter \lambda 를 적용해서 초기 prototype의 가중을 줄여나가면서 점차적으로 prototype을 update 하게 됩니다.
그리고 아래 수식을 통해 class-wise domain biases 인 \xi(c) 를 구하고 이를 통해 source domain prototype을 새롭게 calibration 할 수 있게 됩니다.
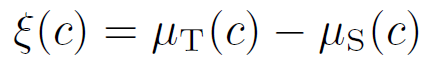
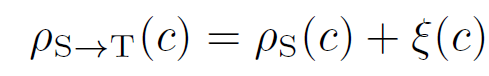
calibration된 prototype을 사용하게 되면 상호 domain 간의 더 정확한 correspondence 관계를 설정할 수 있게 되고, 이를 활용해서 아래 식을 통해 Dynamic Pseudo Label을 만들 수 있게 됩니다.
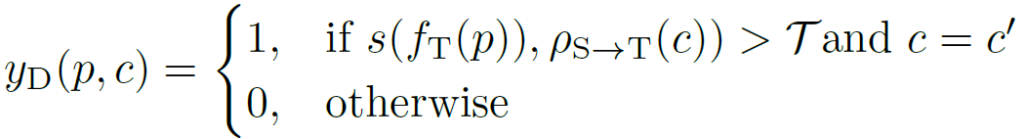
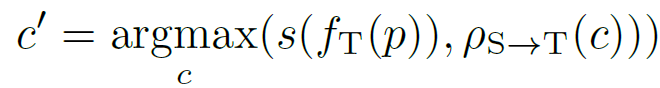
pixel level feature map인 f_T(p)와 calibration된 prototype p_{s->T}(c) 간의 cosine similarity가 미리 정의된 threshold 보다 높으면서, similarity 의 argmax가 c와 같다면 (c=c’)
pixel p에서 class c에 대한 Dynamic Pseudo Labely_D(p,c)을 1로 설정하고, 그렇지 않다면 0으로 채워버리게 됩니다.
여기서 사용되는 threshold 값인 \tau는 {0.5,0.6,0.7,0.8,0.9} 중 grid search 방식으로 선정된다고 합니다.
그럼 마지막으로 정성적인 결과를 보면서 최종적으로 사용할 Hybrid Pseudo Label에 대해서도 설명 드리도록 하겠습니다.
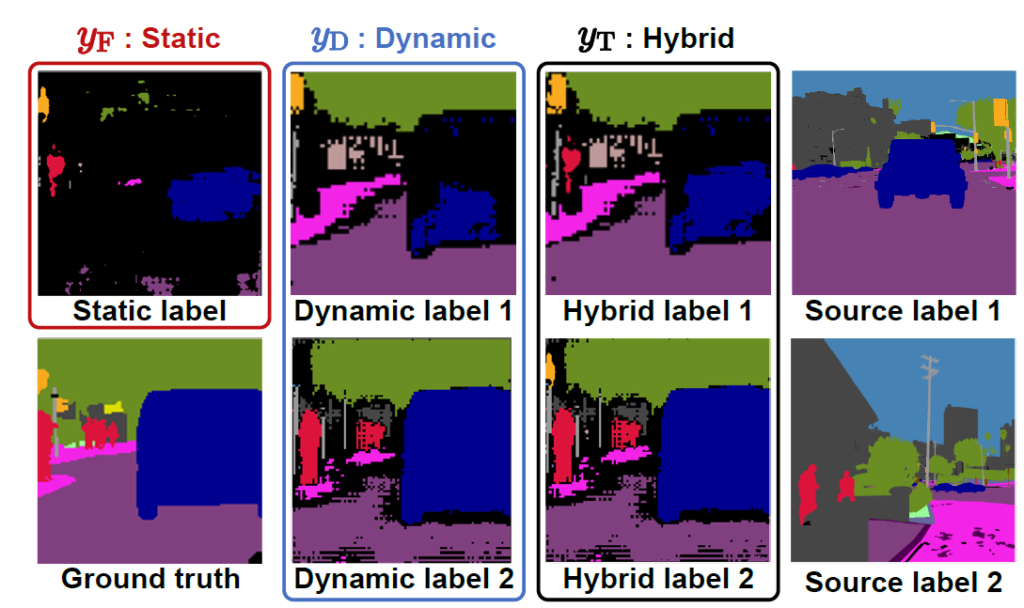
1번째 열 아래 gt 그림은 target 이미지의 gt 입니다.
다만 UDA 방식에서는 학습때 이를 사용하지는 않기 때문에 그냥 생성하는 pseudo label들과의 비교 용도로만 봐 주시면 됩니다.
그리고 1번째열 위에 있는 static label은 기존 self-training based UDA 방식들에서 생성하게 되는 pseudo label로써, parametric한 모델을 통해 예측한 결과를 높은 confidence 값을 기준으로 thresholding한 결과입니다. 앞서 말씀드렸다시피 confidence가 높은 pixel 만을 pseudo label로 사용하고자 한 것이기에 reliable하다는 장점은 있지만, 매우 sparse 한 것을 볼 수 있네요.
그리고 2번째 열은 생성한 Dynamic pseudo label의 결과입니다.
여기서 주목해야 할 점은 4번째 열의 source label이 변경됨에 따라서 생성되는 Dynamic Pseudo label도 변경된다는 점입니다.
nonparametric 방식으로 pseudo label이 예측되기 때문에 cost가 적어서 pseudo label을 자주자주 update해 줄 수 있을 뿐만 아니라, source label이 변경되면 이에 따라 예측되는 Dynamic pseudo label도 변경되기 때문에 static한 기존 pseudo label의 문제점을 해결할 수 있겠네요.
그리고 두 domain의 pixel-prototype 간 연관성을 통해 pseudo label을 예측하는 것이기 때문에 domain간 correspondence가 더 높다는 장점도 존재하겠네요.
그리고 3번째 열은 최종적으로 Target domain 학습 시 사용하게 될 Hybrid Pseudo label로써 Static label과 Dynamic label을 아래 수식을 사용해서 합친 결과입니다.
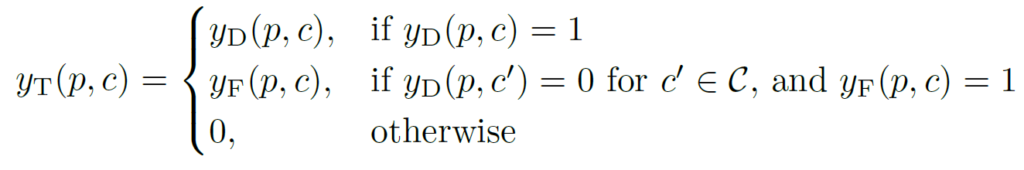
static label의 reliable하다는 장점과, Dynamic label의 domain correspondence가 높다는 장점을 모두 가지는 최종적인 target pseudo label입니다.
이때까지 논문, 실험에서 접했던 pseudo label의 생성 과정과는 전혀 다른 느낌의 pseudo label 생성 방식이라 매우 신기했습니다.
2.4. Traning Loss
우선 아래 수식은 total loss 설계 전에 기존 segmentation task에서 주로 사용하는 2가지 loss를 결합한 base loss 수식입니다.
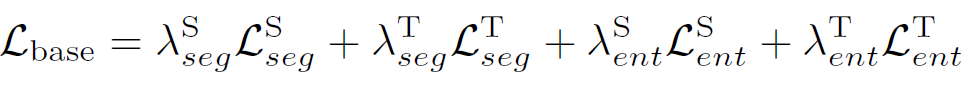
source와 target 각 domain에 대해 pixel-wise 분류를 위한 cross entropy loss와 entropy loss가 결합된 형태입니다.
각 loss에 대해 1과 0.4의 hyperparameter를 사용했다고 하네요.
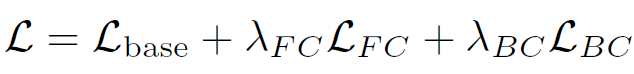
그리고 위 수식은 2.2절에서 설명드린 FCL과 BCL에 대한 loss 를 결합한 최종 loss 입니다.
두 hyperparameter는 {0.1 0.3 0.5 0.7} 중에서 grid search 방식으로 선정되었다고 하네요.
3. Experiment
3.1. Training Details
모델은 imagenet 데이터셋으로 사전학습 된 ResNet-101 백본을 활용한 DeepLab-V2 모델을 사용하였습니다.
그리고 우선 source dataset으로 모델을 미리 학습 시킵니다. 그리고 source + target으로 함께 본 논문에서 제안하는 UDA를 수행하게 됩니다.
그리고 본 논문에서 target pseudo label로 사용하는 Hybrid Pseudo Label은 static label과 dynamic label을 결합한 형태라고 말씀 드렸었는데, static label는 10000 iteration에 한번씩 update 시킨다고 합니다.
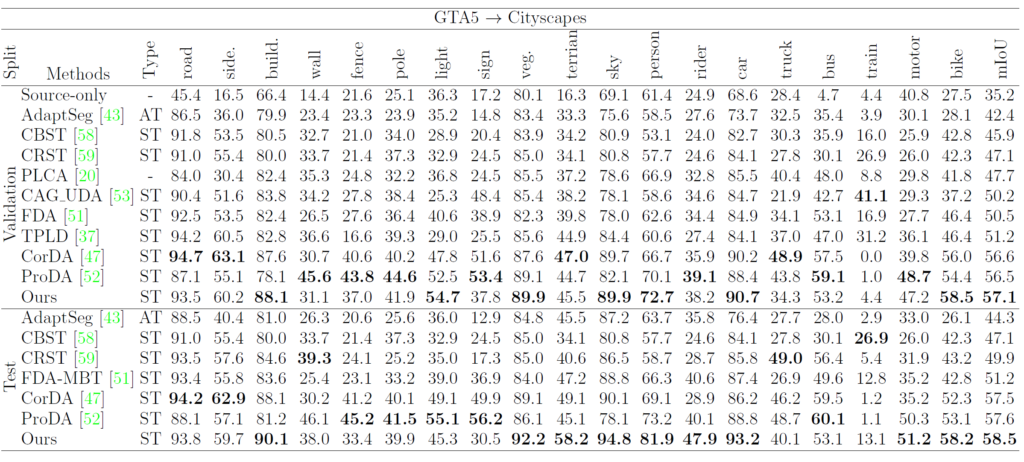
우선 3번째 column 의 Type에서 AT는 UDA 기법 중 Adversarial Training 방식을, ST는 Self-Training 방식을 의미합니다. 아무래도 최근 UDA 에서 Self-Traning 방식이 많이 사용되는 추세이다 보니 대부분의 비교 대상군이 ST 네요.
그리고 fair한 비교를 위해 모든 UDA 기법들의 모델로 ResNet-101 백본을 활용한 DeepLab-V2 을 사용하였다고 합니다.
타 기법들 대비 mIOU의 향상 폭이 1% 혹은 그 이상인 것으로 보아 본 논문에서 핵심적으로 주장하는 pixel-prototype 기반의 domain correspondence 가 잘 동작함을 확인할 수 있습니다.
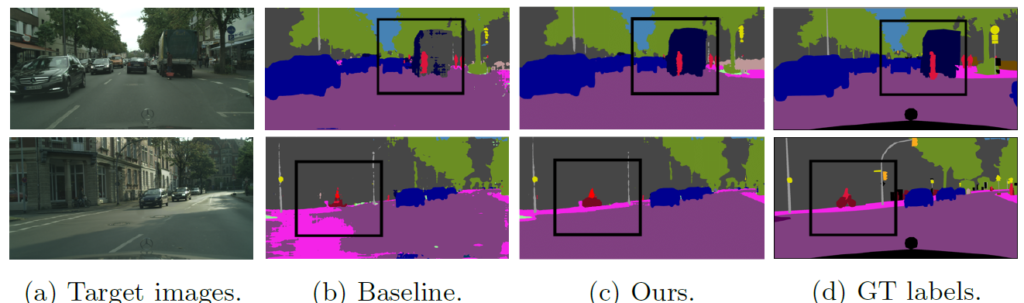
위의 정성적 결과에서는 bus class에 대한 결과가 눈에 띄네요.
단순하게 이미지 전체의 pixel distribution을 유사하게 만드는 기존 baseline 과는 달리 pixel level의 의미적인 정보에 직접적으로 집중하는 본 논문의 방식이 잘 동작함을 보여줍니다.
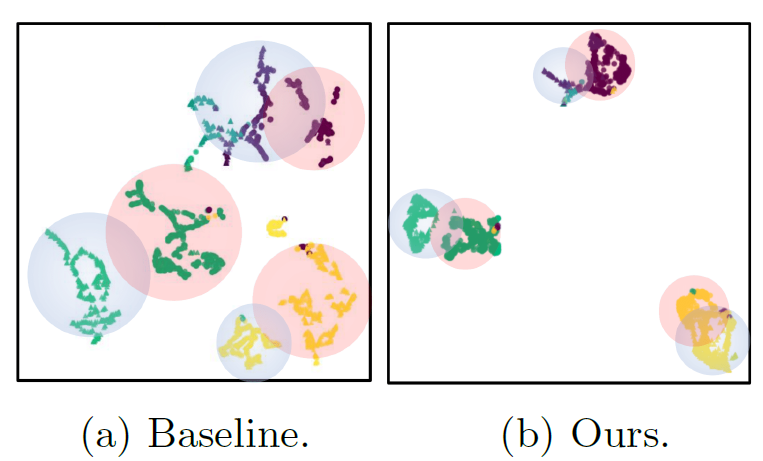
그리고 위 그림은 t-SNE 시각화 결과입니다.
Baseline 대비 ours의 결과에서 intra-class variations 을 최소화 함과 동시에, inter-class variations는 최대화 하는 방향으로 학습이 진행되었음을 알 수 있네요. class 단위로 pixel-prototype correspondence를 고려한 본 논문의 방식이기에 위 시각화 결과가 가능한 듯 합니다.
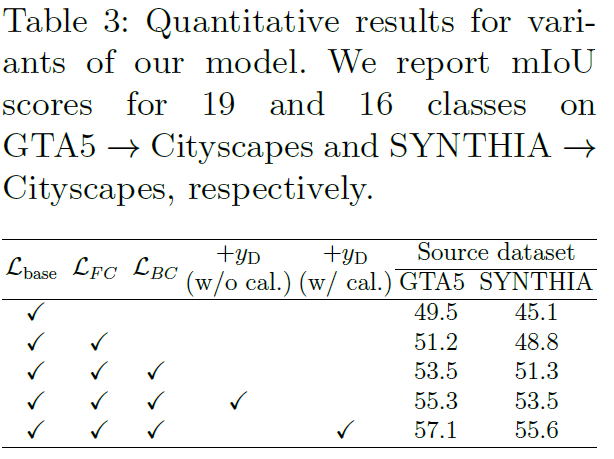
그리고 마지막은 ablation 결과입니다.
1번째 행 -> 3번째 행으로 가면서 본 논문에서 핵심적으로 제안한 class wise pixel-prototype 끼리의 양방향 contrastive learning에 따른 성능 향상 gap을 알 수 있습니다. 향상 폭이 매우 인상적이네요.
또한 static pseudo label을 사용하는 것이 아니라, 최종적으로 calibration을 적용한 Dynamic Pseudo label을 결합해서 함께 사용함으로써 domain discrepancy를 줄이면서 UDA를 잘 수행되었음을 알 수 있습니다.
주말에 급하게 읽은 논문인지라 깊이가 많이 부족할 수도 있습니다…ㅎ
매번 contrastive 라는 키워드를 보면 저도 모르게 피하기 쉽상이였는데 이번 논문을 통해 그래도 좀은 contrastive 라는 친구와 더 가까워 진 거 같습니다.
그리고 pseudo label은 당연히 특정 model의 예측으로만 생성되는 줄 알았는데, EMA 방식을 적용하여 nonparametric 한 방법으로 pseudo label을 생성해내는 방식 또한 처음 접해봐서 개인적으로 신기하고 새로웠습니다.
그럼 리뷰 마치도록 하겠습니다. 감사합니다.
권석준 연구원님, 좋은 리뷰 감사합니다.
Adversarial training에 대해서 설명해 주실 때, discriminator를 속이는 방향으로 학습해서 source domain과 target domain의 feature 분포를 최대한 유사하게 만드는 방식으로 학습한다고 말씀해 주셨는데, discriminator가 무엇인지 궁금합니다! 서로 다른 domain간의 차이를 구별하는 것 같은데, 추가적인 설명을 해 주신다면 감사하겠습니다.
그리고, static label이 computation 자원때문에 가끔씩 업데이트한다고 하셨는데, 혹시 iteration 횟수 결정 기준(10000번에 1번?)에 관련된 추가적인 언급이 있는지 궁금합니다.
감사합니다.
아,
discriminator는 생성 모델 GAN에서 등장한 개념입니다. 생성자(generator)가 이미지 혹은 3D 모델 등 목적으로 하는 결과물을 생성하게 되는데, 이때 discriminator를 속이는 방향으로 만들어집니다. 학습이 진행되면서 생성자(generator)는 discriminator를 속이기 위해 점점 더 real한 생성물을 생성해내고, discriminator는 그것이 real인지 fake인지를 열심히 구별하려고 하죠.
사실 제 간략한 설명 보다는 “GAN discriminator” 등을 키워드로 구글링해보시면 더 많은 정보를 알 수 있으실듯 합니다.
(참고 : https://process-mining.tistory.com/169)
그리고 iteration 횟수 결정 기준은 기존의 static self-training 방법론들이 일반적으로 사용되는 횟수인지라 딱히 추가적인 언급은 없네요.
감사합니다.
안녕하세요, 좋은 리뷰 감사합니다.
Domain adaptation에 대해 궁금해서 리뷰를 읽게 되었는데 자세한 리뷰 감사합니다.
간단한 질문이 하나 있습니다. 해당 UDA 라는 것은 annotation을 하기 힘든 문제에 대해 해결하기 위해 하는 것으로 이해를 했습니다. 이러한 UDA는 보통 segmentation task에서만 사용되는 방법론인지 궁금합니다.
감사합니다.
넵,
DA는 gt label이 부족하고 annotation cost가 비싼, 우리가 target으로 하는 dataset에서의 성능을 끌어올리고자 gt labeling이 되어있는 큰 규모의 source dataset으로 부터 정보를 받아오는 방향으로 학습이 진행되는 것입니다. 이 때 soucre domain dataset 의 gt를 사용하지 않는다면 UDA 가 되는 것이죠.
또한 UDA는 segmentation 뿐만 아니라 classification, detection, 3d 등등 수 많은 분야에 적용 가능하고 많은 연구들이 진행되고 있습니다.
감사합니다.
안녕하세요. 리뷰 잘 봤습니다.
prototype은 pixel cluster의 중심이라고 하셨는데, 실제로 어떻게 계산할 수 있나요? 리뷰에서는 단순히 source domain은 GT label로, target domain은 pseudo label를 통해서 prototype을 구한다고만 나와있는데, 구체적으로 어떻게 구할 수 있는지 궁금합니다.
가령 일반적인 contrastive learning에서는 영상을 하나의 global vector로 만들다보니 여러 벡터들에 대한 군집으로 이해할 수 있었는데, 여기서는 pixel level의 prediction이다보니 contrastive learning을 어떻게 할 수 있을까 감이 잘 안잡히네요.
그리고 리뷰 초반부 내용 중 “이미지 전체의 pixel 분포를 유사하게 만드는 기존 방식과 달리, 본 논문에선 pixel 분포를 유사하게 만드는 contrastive learning을 수행할 때에 class 단위로 수행하기 때문에 확실히 local한 의미 정보를 잘 반영하게 될 거 같습니다.” 라고 적혀있는데, 기존 방법론도 영상의 pixel 분포를 유사하게 만들고 제안하는 방법론도 픽셀 분포를 유사하게 만든다는 의미 아닌가요..? 저 말만 보면 해석이 잘 안되는데 설명해줄 수 있나요?
prototype이 cluster의 중심이라고 표현한 것은 이해를 돕기 위해 해석한 말입니다.
prototype 은 class별로 하나씩 구해지는 것이며 ‘2.2. Bi-directional Contrastive Learning’ 의 계산식을 보면 명확하게 이해할 수 있습니다. 식을 통해서 알 수 있다시피 HxW의 feature map에서 각 class별 feature vector의 평균을 구한 것입니다. feature map의 채널이 256, 그리고 class 수가 19개라고 가정했을 때 prototype의 shape은 19 x 256 이라고 할 수 있습니다.
그리고 constrastive learning을 위한 positive negative 세팅은,
같은 class의 prototype 끼리는 positive, 서로 다른 class라면 negative로 세팅해서 학습을 진행합니다.
음 그리고 마지막 질문에 대해선 제가 표현을 좀 모호하게 한 감이 없지않아 있는 거 같네요.
기존 영상은특정 constraint를 적용하지 않고 그저 image 전체의 pixel 분포를 유사하게 만들게 됩니다. 반면 본 논문의 방식은 class 별로 prototype을 따로 구해서, class 별로 pixel 분포를 유사하게 만든다는 점에서 기존과 차별성이 존재하게 되는 것입니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다.
동일 클래스를 나타내는 픽셀의 중심을 prototype이라고 설명해 주셨는데 gt가 없는 target도메인에서는 어떻게 prototype이 정해지는지 궁금합니다. 단순히 psudo 라벨을 사용해서 정해지는 건가요? 그렇다면 본문에 설명된 dynamic psudo labeling을 사용하면 매 epoch마다 label이 달라지는 것이 prototype생성에 반영된다는 것으로 이해하면 되는 것일까요?
넵 이해하신 부분이 맞습니다.
‘2.3. Dynamic Pseudo Labels’ 을 다시 봐주시면 될 듯 합니다!
감사합니다.