안녕하세요, 아홉번째 x-review 입니다. 이번 논문은 ECCV 2020에 게재된 EPNet으로 3D point cloud와 2D image를 fusion하는 방법론 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
이미지는 물체의 semantic한 색상과 texture 정보를 포함하고 있지만 depth 정보가 부족한 반면, LiDAR 센서로 얻는 point cloud의 경우 depth 정보와 기하학적인 구조를 알 수 있는 정보를 가지고 있지만 sparse하고 순서가 없으며 point 자체가 3D scene 안에서 골고루 분포되어 있지 않다는 단점이 존재합니다.
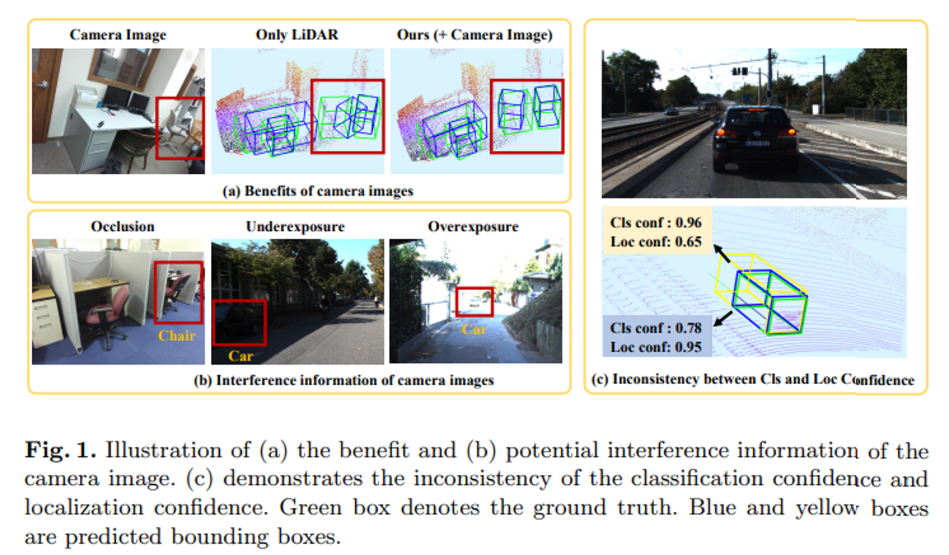
Fig 1 (a)의 좌측 상단처럼 노란색과 흰색의 의자가 가까이 붙어서 배치되어 있을 경우 point cloud 만으로는 두 개의 의자를 제대로 분리해서 검출하지 못하고 있지만 image 정보를 함께 사용할 경우에 두 의자를 따로 더 정확하게 검출하는 것을 확인할 수 있습니다. 이렇게 이미지 데이터는 더 정확하게 3D Object의 위치를 검출하기 위해 필요한 데이터이기 때문에 활용해야 한다는 생각이 이미지와 포인트 클라우드를 합쳐 정확도 높은 3D Object Detector를 만들겠다는 저자의 motivation이 되었다고 합니다. 그러나 fusion을 하는데 있어서 두 가지 고려해야할 사항이 있었는데, 첫번째는 두 개의 데이터가 너무 다른 도메인에 존재한다는 것이고 두번째는 Figure1의 (b)에서 확인할 수 있듯이 이미지는 조도 변화나 occlusion 환경에 민감하여 그러한 환경에서는 되려 방해가 되는, interference 정보를 제공할 수도 있습니다. 그래서 이전의 방법론들에서는 보통 2D bounding box 정보, 즉 이미지 어노테이션의 도움을 받아 두 개의 센서로부터 얻은 데이터를 합치는 방향으로 연구가 되었습니다. 연구 방향을 두 개의 갈래로 나누어 생각해보면 먼저 1) 두 개의 데이터를 각각 다른 단계에서 input으로 받아서 처리하는 cascading 방법이거나, 2) 두 데이터를 동시에 입력값으로 받아서 처리하는 방식이 존재하였습니다. 두 가지 방식에는 각각 단점이 존재하였는데, 먼저 1)은 아무래도 두 데이터를 따로 입력값으로 받아 처리하다보니 서로 상호보완적인 관계를 제대로 형성하지 못하여 성능을 끌어올리기에는 다소 제한적이었습니다. 2)는 데이터를 동시에 처리하기 위서 point cloud를 projection하거나 복셀 형태 변환하여 BEV 데이터로 만들어야 했기에 그 과정에서 정보 손실이 발생하게 됩니다. 게다가 voxel 형태의 3D feature와 이미지 feature 사이의 동일한 특징에 대해 정확한 대응관계를 형성하기 어려웠다고 하니다.
본 논문에서는 기존 연구에서의 이러한 2가지 문제점을 해결하기 위해서 raw level의 포인트 클라우드와 이미지 사이의 정확한 대응관계를 찾을 수 있는 LI-Fusion module을 제안하게 됩니다. LI-Fusion module은 우선 포인트 클라우드 데이터를 BEV 형태로 만들지 않아도 되기에 변환 과정에서 발생했던 정보 손실을 막을 수 있습니다. 또한 2D 이미지의 occlusion과 같은 원래의 정보를 얻기에 방해가 되는 요소들에 대한 해결책을 제시해주며, 이미지 어노테이션 정보를 사용하지 않습니다. 추가적으로 저자는 fusion 과정에서 classification confidence와 localization confidence 사이의 inconsistency, 즉 불일치가 발생한다는 문제점을 정의하게 됩니다. Figure1의 (c)와 같이 localization confidence와 classification confidence가 어느 한 개의 confidence가 높다고 하더라도 무조건적으로 다른 하나의 confidence가 높지 않다는 것 입니다. 이러한 confidence 사이의 불일치는 NMS 과정을 처리할 때 낮은 성능을 도출하게 되는 원인으로 이어질 수 있습니다. 논문에서는 두 confidence 사이의 불일치를 해결하기 위해서 consistency enforcing loss (CE loss)를 새롭게 도입하게 되는데 이는 아래에서 더 자세하게 다루도록 하겠습니다. 여기서 introduction을 마무리하면서 본 논문의 main contribution을 정리하면 아래와 같습니다.
- 이미지 어노테이션 정보에 의존하지 않고 point cloud와 image feature를 효과적으로 fusion할 수 있는 새로운 LI-Fusion module 제안
- classification과 localization confidence의 일관성을 보장하여 더 정확한 검출 결과를 도출할 수 있도록 추가적인 CE loss 제안
- LI-Fusion module과 CE loss를 합친 새로운 네트워크인 EPNet을 제안하며 KITTI, SUN RGB-D 데이터셋에서 SOTA 달성
2. Method
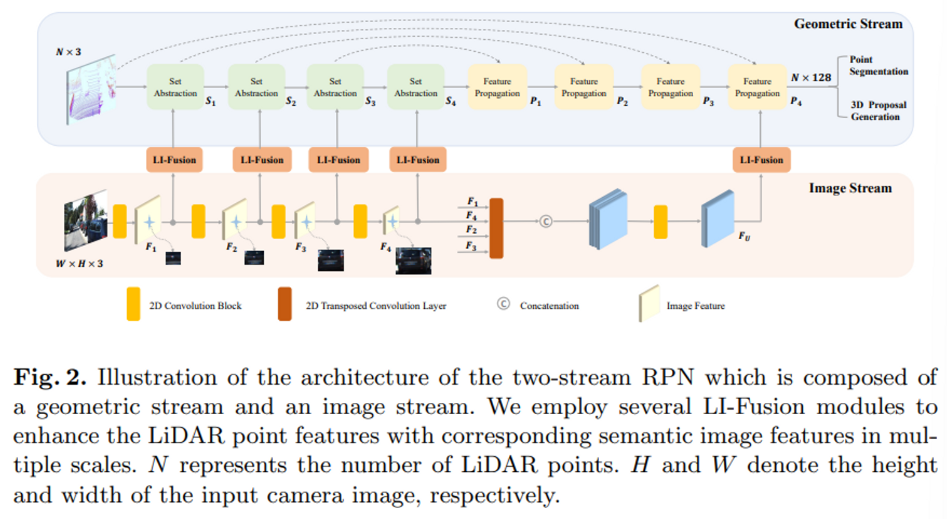
2.1 Two-stream RPN
RPN은 Geometric stream과 Image stream으로 나뉘는데, Fig 2에서 볼 수 있듯이 각 stream은 포인트 클라우드, 이미지에서 각각 특징을 추출하고 있습니다. 두 stearm 사이를 LI-fusion module로 연결여 포인트 클라우드에 대응하는 이미지 feature map으로 더 향상된 point feature을 얻을 수 있도록 하였습니다. 이제 두 스트림을 나누어 더 자세하게 살펴보도록 하겠습니다.
Image Stream
Image stream은 camera 2D image를 입력으로 받아 semantic한 이미지 정보를 출력하게 됩니다. 총 4개의 가벼운 convolutional block을 거치게 되는데, 각 block은 3×3의 convolution layer 2개와 batch norm, ReLU로 구성되어 있습니다. Fig2에서 F_i가 모두 다른 scale을 가지면서 더 풍부한 point feature을 가질 수 있도록 제공하는 semantic한 이미지 정보가 되는 것 입니다. 또한 모두 다른 scale을 가진 F_i에 대해서 4개의 다른 stride를 지정한 병렬적인 transposed convolution layer를 거침으로써 feature map을 원래의 이미지와 사이즈를 동일하게 만듭니다. 그리고 모든 feature map을 concat하여 기존 fusion 네트워크에서보다 의미있는 이미지 정보로 구성된 feature map F_U를 생성할 수 있습니다. 최종 F_U 또한 이전의 F_i과 마찬가지로 포인트 클라우드의 특징을 더 향상시키기 위해 활용합니다.
Geometric Stream
Geometric Stream은 raw level의 point cloud를 입력으로 받아 3D bounding box를 예측하게 되며 4개의 Set Abstracion (SA) 모듈과 Feature Propagation (FP) 모듈로 구성되어 있습니다. 하나의 SA를 거친 출력값을 S_i, FP를 거친 출력값을 P_i로 정의하도록 하겠습니다. S_i는 SA에서 포인트 클라우드 특징을 추출한 결과로, semantic image feature인 F_i와 LI-Fusion module로 합쳐집니다. 마지막 P_4에서 최종 이미지 feature map인 F_U와 합쳐지면서 더 간결하고 특징적인 feature representation을 얻을 수 있게 되고 해당 representation을 foreground point segmentation과 3D bounding box를 예측하기 위한 detection head에 전달하게 됩니다.
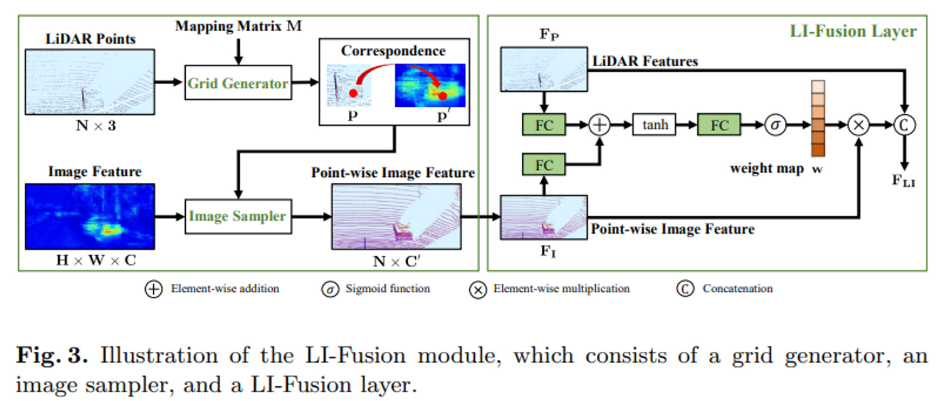
두 개의 Stream을 살펴보았을 때 핵심이 되는 것은 결국 semantic image feature을 point feature로 전달해주는 LI-Fusion module이라고 생각이 드는데, 그렇다면 LI-Fusion module은 어떤 구성을 가지고 어떻게 동작하는 것일까요?
LI-Fusion은 LiDAR-guided image fusion module이라는 뜻으로 크게 grid generator, image sampler, 그리고 LI-Fusion layer로 이루어진 두 개의 파트로 나눌 수 있습니다. Fig3을 따라 point-wise feature을 생성하는 파트부터 살펴보도록 하겠습니다.
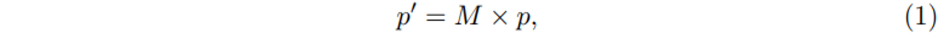
3차원의 point cloud를 Grid Generator에서 매핑 행렬 M을 사용하여 이미지로 projection 하여 두 도메인 간의 point-wise 대응관계를 출력하게 됩니다. 즉 (x, y, z) 좌표를 가진 특정 point cloud p(x, y, z)에 대해 식(1)과 같이 매핑 행렬 M을 이용하여 카메라 이미지에서 대응하는 위치인 p’(x’, y’)를 얻을 수 있는 것이죠. 대응점을 형성한 후에는 본격적으로 각 포인트에 대한 semantic feature을 얻기 위해서 image sampler을 사용합니다. image sampler는 입력값으로 대응 위치 p’와 이미지 feature map F를 받아서 모든 p’에 대한 point-wise feature representation V를 생성하는 역할을 하며 image sampler 과정을 아래 식(2)와 같이 표현할 수 있습니다.
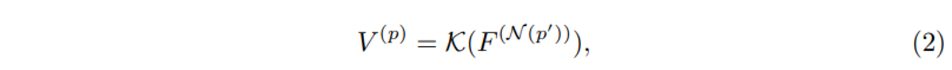
여기서 주의할 점은 p’가 인접한 픽셀 사이에 위치해 있을 수 있다는 점을 고려하여 bilinear interpolation을 사용한다는 점 입니다. K가 bilinear interpolation 함수를 뜻하고, 는 bilinear interpolation을 적용할 p’에 대한 주변 픽셀의 feature을 의미합니다. V^{(p)} 가 바로 각 포인트 p에 대응하는 image feature, 즉 image sampler의 출력값이 되는 것 입니다. Grid Generator와 Image sampler까지 거치게 되면 각 point cloud에 대응하는 semantic image feature로 point-wise Image Feature을 얻을 수 있습니다.
그럼 이제 L1-Fusion Layer로 넘어가서 geometric stream의 SA에서 추출한 point cloud feature F_P( Fig2에서는 S_i로 표현하는데 여기서는 F_P로 표현하네요 .. )와 이전 Image sampler을 거치면서 얻은 point-wise Image feature을 같은 채널로 매핑하기 위해서 FC layer을 각각 태우고 element-wise addition한 후에 하나의 FC layer을 통과함으로써 weight map w를 생성합니다.
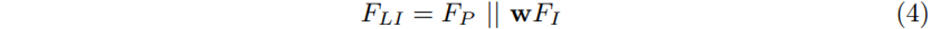
식(4)에서 표현한 것처럼 생성한 weight map과 image feature을 곱하여 각 포인트에 해당하는 이미지 feature의 중요도를 판별할 수 있게 됩니다.
introduction에서 언급하였듯이, 두 센서 데이터를 합칠 때 이미지에서 조도 변화나 occlusion으로 인해 task에 방해가 되는 정보들이 포함될 수 있기에 challenge한 요소로 여겨집니다. 따라서 이러한 문제를 해결하기 위해 point-wise 방식을 사용하여 adaptive하게 이미지 feature에서 중요한 부분을 추정할 수 있도록 LI Fusion module을 구성한 것 입니다.
2.2 Refinement Network
high-quality의 3D bounding box proposal을 NMS로 유지하면서 이를 refinement network로 보냅니다. 두 개의 Stream에서 전달된 정보로 3D bounding box를 예측하게 된다고 하였는데, 각각의 proposal에서 랜덤으로 512개의 포인트를 샘플링하여 feature descriptor을 생성하되 만약 512개보다 적은 포인트가 박스에 포함되어 있다면 0으로 패딩한다고 합니다. refinement network는 global descriptor을 추출하기 위해서 3개의 SA layer로 구성되어 있고, 각각의 classification과 regression을 수행하도록 2개의 subnetwork로 나누어진 구조로 이루어져 있습니다.
2.3 Consistency Enforcing Loss
앞서 말한 high-quality box를 유지하기 위해 NMS를 적용하는 것인데 저자는 어떤 high-quality 박스를 어떻게 선택할 지에 집중하고 있습니다. NMS는 먼저 classification confidence score로 박스를 한번 거르고, 예측한 박스와 GT box의 IOU를 Threshold 기준으로 평가를 합니다. 그런데 classification과 localization confidence는 inconsistent, 즉 불일치하는 경우가 흔하게 발생하는데 이는 성능에 좋지 못한 영향을 미치게 됩니다. 따라서 본 논문에서는 두 confidence 사이의 일관성을 보장하기 위해서 consistency enforcing loss (CE loss)를 도입하여 높은 localization confidence를 가진 박스가 classification confidence 필터링에서 살아남아 최종 예측 후보에 들고자 하였습니다.
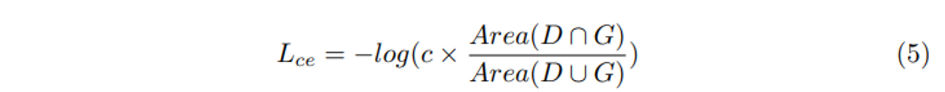
식(5)에서 D와 G는 각각 예측한 bounding box와 GT box를 의미하며 c는 D의 classification confidence score 입니다. CE Loss는 classification과 localization confidence 둘 다 가능한 높도록 계산되기 때문에 결과적으로 높은 classification을 가진 box가 localization confidence, 즉 IOU가 높기에 NMS에서 필터링 되지 않고 남아있을 수 있습니다. CE Loss의 핵심은 두 confidence의 높고 낮음에 대한 일관성을 보장하여 보다 더 정확하게 예측한 bounding box를 사용할 수 있게 되는 것 입니다.
3.4 Overall Loss Function
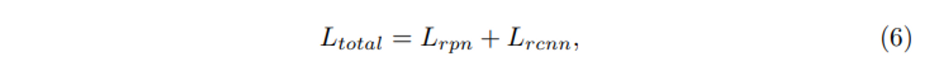
전체 Loss는 (6)과 같으며 two-stream RPN과 refinement network에 대한 loss로 구성되어 있고, L_{rpn}과 L_{rcnn} 은 모두 classification loss, regression loss, CE loss를 포함하고 있습니다.
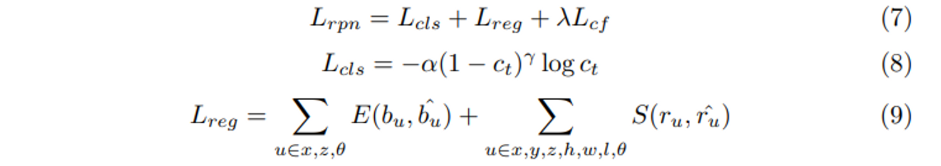
classification loss로는 positive와 negative 샘플의 균형을 맞추기 위해서 focal loss를 사용하였습니다. regression loss에서는 일단 bounding box의 중심점 좌표인 (x, y, z)와 박스의 사이즈인 (l, h, w), 마지막으로 박스의 방향인 \theta를 필요로 합니다. 여기서 Y축, 즉 vertical 축의 범위가 상대적으로 작기 때문에 Y축에 대해서는 smooth L1 loss로 GT와 offset을 직접 계산한다고 합니다. 마찬가지로 박스 사이즈에 해당하는 (l, h, w)까지는 역시 smooth L1 loss로 계산하였습니다. X축, Z축, 그리고 앵글 \theta는 bin-based regression loss를 사용하였다고 합니다. 각 foreground point에 대해서 인접한 영역을 여러개의 bin으로 나누어 우선 중심점이 속해있는 bin을 예측한 b_u를 구한 다음 b_u 내에서 잔차 offset인 r_u을 regress 합니다. bin을 예측할 때는 cross entropy loss (E), 잔차 offset을 regression할 때는 smooth L1 loss(S )를 사용합니다. 추가적으로 c_t는 예측한 클래스가 실제 라벨과 일치할 확률을 나타내고 \hat{b}_u은 GT bin, \hat{r}_u는 GT 잔차 offset을 의미합니다.
3. Experiments
실험에는 3D outdoor dataset인 KITTI Dataset과 Indoor dataset인 SUN RGB-D Dataset을 사용하였습니다. KITTI의 경우 영상에 포함된 object의 크기나 occlusion 수준에 따라서 easy, moderate, hard 3가지 단계로 나누어져 있습니다.
3.1 Experiments on KITTI Dataset
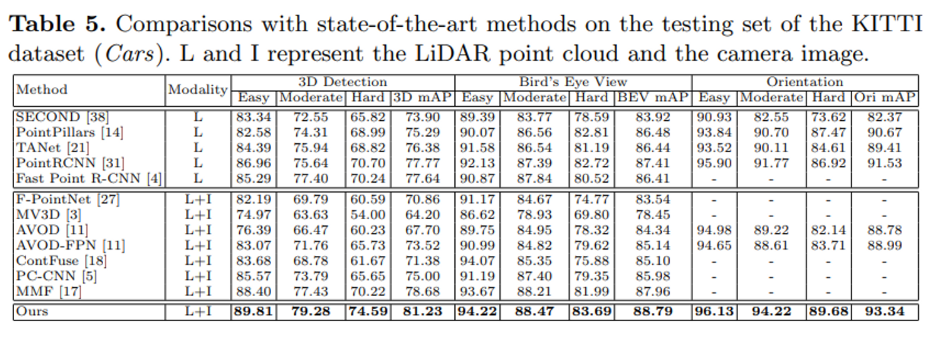
KITTI Dataset에서 기존 멀티 센서를 사용한 방법론들 대비 우수한 성능을 보이며 SOTA를 달성한 것을 확인할 수 있습니다. 특히나 당시 SOTA 모델이었던 MMF의 경우 3D detection의 성능을 높이기 위해서 2D detection이나 depth completion 등의 부가적인 task를 활용하였기 때문에 많은 annotation이 필요한 것 을 생각해보면 본 논문의 EPNet은 compact하게 더 높은 성능을 보인다는 것을 알 수 있습니다.
3.2 Experiments on SUN RGB-D Dataset
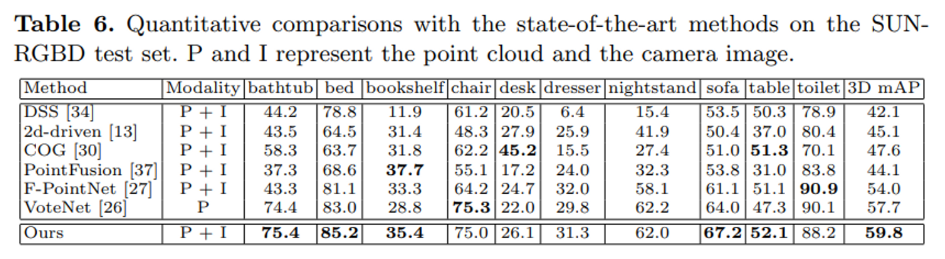
SUN RGB-D에서 역시 가장 높은 성능을 달성할 것은 확인할 수 있습니다. 저자는 여기서 멀티 센서 기반의 PointFusion과 F-PointNet과의 비교를 강조하고 있는데요, 먼저 두 방법론 2D detector을 활용하여 2D bounding box를 만든 다음에 cascading 방식으로 3D box를 예측하게 됩니다. F-PointNet의 경우 3D box를 예측할 때는 point cloud만을 활용하고, PointFusion은 이미지 feature와 point cloud feature을 단순 concat하는 방식을 사용합니다. 이와 비교하여 3D EPNet은 point cloud feature와 이미지 feature 사이의 직접적인 대응관계를 형성함으로써 더 정밀한 representation을 제공할 수 있다고 합니다.
4. Ablation Study
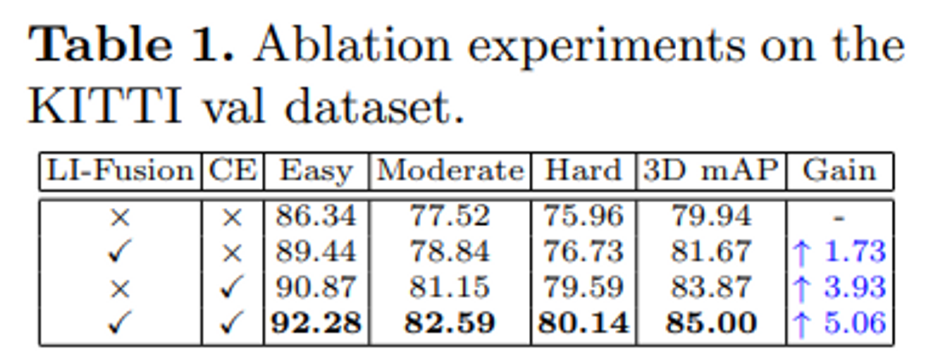
KITTI validation dataset에서 LI-Fusion과 CE Loss가 얼마나 성능에 영향을 주는지에 대한 Ablation Study를 진행하였습니다. 먼저 Table1의 1, 2행과 같이 동일하게 CE Loss를 사용하지 않는 조건에서 LI-Fusion의 사용 유무만으로 성능을 빅해보았을 때 Easy, Moderate, Hard 세가지 level에서 모두 성능이 향상한 것을 확인할 수 있습니다. 이번에는 1, 3행을 비교해서 CE Loss 유무가 성능에 얼마나 영향을 주는지 보면, 마찬가지로 CE Loss를 사용하지 않았을 때보다 사용하였을 때 유의미한 성능 향상을 보이고 있습니다.
좋은 리뷰 감사합니다.
위에서 이미지 annotation을 사용하지 않는다고 했는데, 그 말은 3d point cloud를 LI-Fusion module을 통해 mapping matrix로 상응하는 image feature를 찾아서 3d annotation을 사용한다고 이해하면 되나요?
그리고 뒤에서 weight map과 point-wise image feature를 곱한다고 하셨는데 channel축으로 곱하는게 맞나요?
감사합니다.
안녕하세요 ! 댓글 감사합니다.
먼저 첫번째 질문에 대해서는 도경님이 이해하신 것이 맞습니다. 2D bounding box에 의존하지 않고 3D annotation만 사용합니다.
두번째 질문은 저도 weight map과 point wise image feature를 곱할 때 element-wise multiplication을 사용하여 channel 축을 기준으로 곱한다고 이해하였습니다.