Before Review
오늘은 데이터 셋 및 간단한 베이스라인 논문 리뷰 입니다.
개인적으로 논문에 소개된 데이터 셋은 굉장히 맘에 들고, 향후 연구에 많이 활용이 될 것 같아서 계속 주시하고 있는데 CVPR이 끝나고도 데이터 셋 공개를 안 하고 있네요….
리뷰 시작하겠습니다.
Introduction
Temporal Video Segmentation은 Long Form Video를 smaller video content로 분할하는 작업으로 다양한 video understanding task를 위해서 중요한 연구 입니다.
기존 연구들은 주로 shot, event 그리고 scene 이라는 component 만을 고려하고 있었습니다.
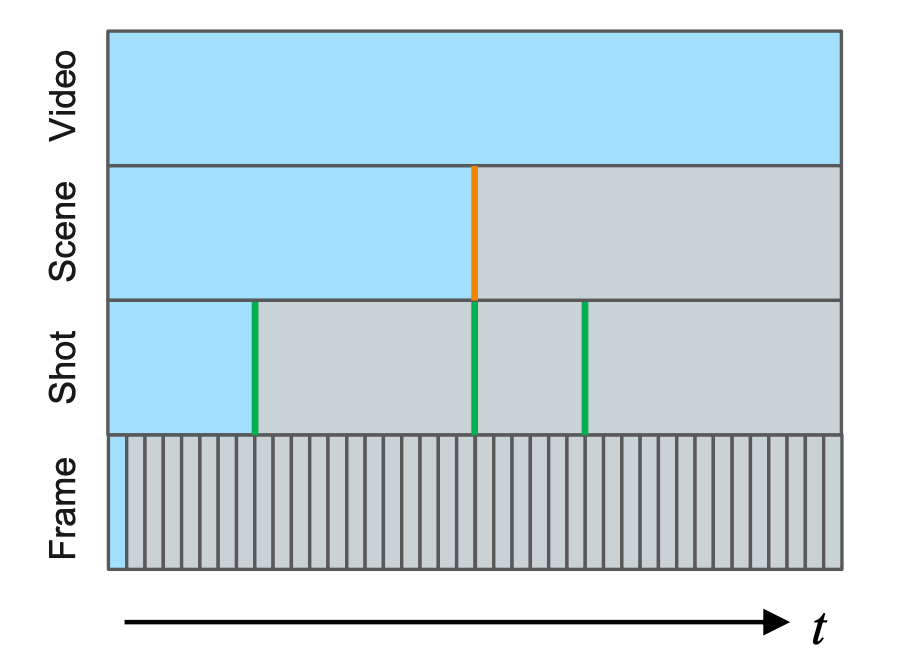
하지만 Long Form 비디오는 사실 Scene라는 Unit 보다 더 상위 계층의 Component로 구분할 수 있습니다.
바로 Story와 Topic 이죠.
본 논문은 기존 데이터 셋들이 비디오의 Story와 Topic들을 다루고 있지 않고 있는 점을 문제 삼아 새로운 데이터 셋을 공개 합니다. 바로 뉴스 영상으로 구성된 1,000개의 비디오 데이터를 제공합니다. 이 뉴스 영상 각각은 다양한 story와 다양한 topic을 담고 있으며 audio, visual, textual data에 대한 annotation을 제공합니다.
이렇게 저자가 제안하는 데이터가 short-video creation, personalized advertiesement, digital instruction 그리고 education 등등 복잡한 비디오의 이해를 요구하는 다양한 task에 도움이 될 거라고 주장합니다.
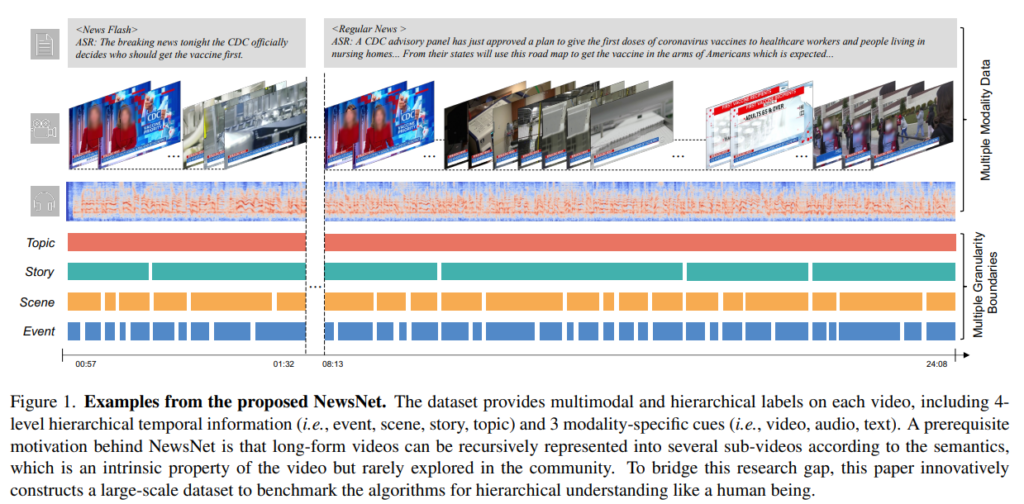
위의 그림이 본 논문이 제안하는 NewsNet이라는 데이터 셋의 example 입니다.
우선 frame 단위로 정말 dense하게 annotation이 되어 있습니다. 4가지의 semantic hierarchy에 따라서 같은 Event인지 Scene인지 Story인지 그리고 Story인지 구분할 수 있게 annotation이 되어 있습니다.
그리고 동시에 multimodal information을 제공합니다. 음성, 텍스트, 영상 정보를 함께 활용하기 때문에 Multi-modal Representation Learning이 가능합니다.
저자는 이러한 NewsNet에 기반하여 Long-Span Temporal Segmentation에 대하여 두 가지 promising direction을 주장합니다.
Infusing Multi-Modality knowledge can significantly improve the performance of long-form temporal segmentation
기존의 temporal segmentation은 visual 정보의 활용을 극대화하는 방향으로 연구가 설계되었습니다. 하지만 visual 정보 뿐만 아니라 multi-modality에 대한 활용을 잘 하면 더욱 segmentation 알고리즘을 고도화 할 수 있다고 합니다.
Although story- and topic-level segmentation is challenging, it can be benefited from hierarchical modeling with the
event- and scene-level segmentation tasks
Story와 Topic Level의 Segmentation은 어렵습니다. 굉장히 의미론적이기에 아직까지 머신이 완벽하게 학습을 할 수는 없겠죠. 하지만 이러한 hierarchical modeling이 event나 scene level의 segmentation에 도움을 많이 준다고 합니다.
마지막으로 저자는 새로운 benchmark를 제공합니다. 바로 temporal segmentation 과정 중에 hierarchical modeling 입니다. Multiple segment의 hierarchical level을 예측하는 task인 것이죠.
본 논문에서 전달하고자 하는 전반적인 내용은 다 말씀을 드렸으니 이제 제안하는 데이터 셋과 벤치 마킹 그리고 간단한 실험 및 분석에 대해서 차근 차근 알아가보도록 하겠습니다.
Dataset Summary
우선 NewsNet에서 정의되는 hierarchical semantic level의 정의와 분류 체계에 대해서 알아보고 간단한 통계에 대해서 알아보도록 하겠습니다.
Definition and Taxonomy
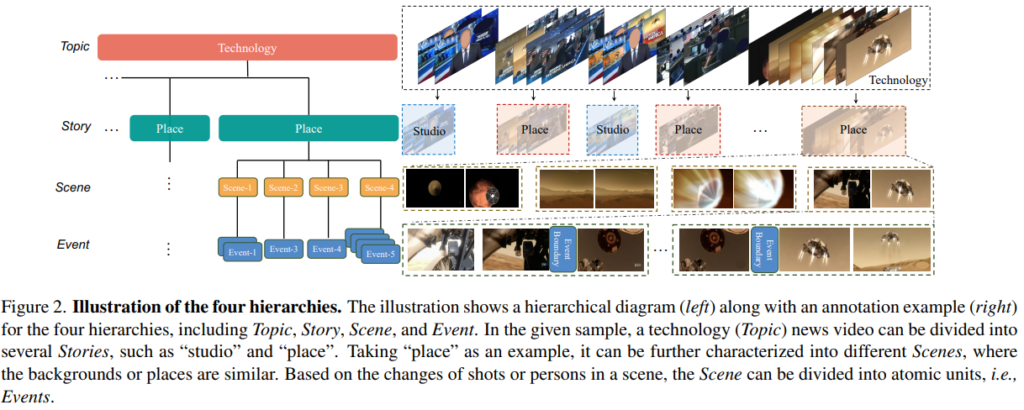
Event : the atom unit in our setting, which is defined by the switching of the shots or the changing of the person.
Event는 가장 기본적인 단위로 shot이 전환되거나 새로운 사람이 등장하거나 없어지는 변화가 발생할 때를 의미합니다.
Scene : a combination of several successive shots that focus on the same place from different angles. It is defined as a taxonomy-free unit.
Scene은 Event의 연속적인 집합으로 모여서 만들어지는 단위 입니다. 주로 같은 장소를 다른 각도에서 찍을 때 같은 장면이라고 정의하는 것 같습니다.
Story : a sequence of scenes about a piece of news broadcast in a studio or outdoors. Story-level segments can be categorized into ‘Connection’, ‘Place’ , ‘Studio’, ‘Animation’, ‘Interview’, and ‘Photo’. A topic is composed of several stories.
Story는 장면의 연속으로 몇 가지의 카테고리로 구분이 됩니다. Scene과 Story의 차이는 Story는 Category-aware 하지만 Scene은 그렇지 않다는 것 입니다. Category는 data의 출처에 따라 구분이 되었다고 합니다.
Topic : it summarizes the content of a long sequence, with the following keywords: ‘Health’, ‘Politics’, ‘Entertainment’, ‘Economy’, ‘Crime’, ‘Weather’, ‘Sport’, ‘Technology’, ‘Military’ and ‘Others’. Generally, an individual news video contains several topics.
Topic은 말 그대로 뉴스 주제와 관련이 있으며 위와 같은 장르로 구분이 된다고 합니다.
Collection and Statistics
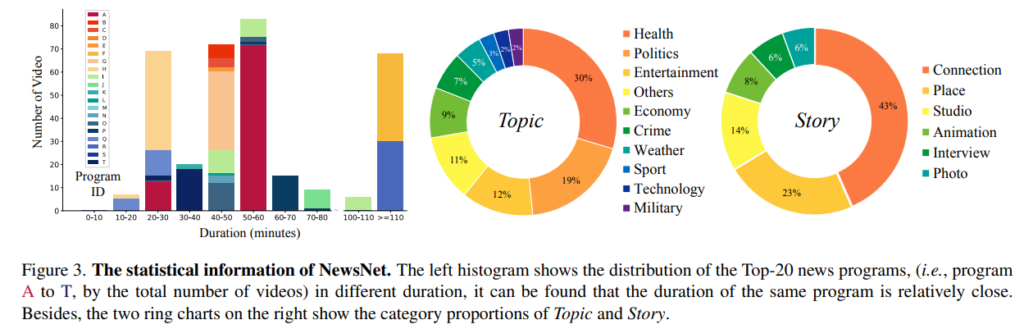
저자는 2000개의 뉴스 방송 영상을 20개의 다른 방송사에서 가져왔다고 합니다. 그리고 그 중 1,000개가 annotation 되었다고 합니다. Duration에 따른 통계를 보면 50~60분 사이의 비디오가 가장 많고 대 부분의 비디오 길이가 굉장히 길게 형성되어 있는 것을 볼 수 있습니다.
Category에 대한 분포를 보면 분포가 Long-Tail의 형태를 띠고 있는 것을 볼 수 있습니다. 나름 데이터가 어렵다고 해석할 수 있겠네요.
통계 부분은 얘기할 것이 많지 않아서 이 정도로 정리하겠습니다. 비디오의 전반적인 길이와 category 분포 정도만 가볍게 알아도 될 것 같네요.
Benchmark and Protocal Navigation
Hierarchical Temporal Segmentation
저자는 hierarchical temporal segmentation을 두 개의 카테고리로 분류 합니다. 그 전에 일단 Segmentation point라는 것에 대해서 알 필요가 있습니다.
기본적인 단위는 shot이라고 가정을 했을 때 segmentation point는 현재의 shot이 scene,story,topic의 끝 장면이고 다음 shot이 새로운 scene,story,topic의 등장인 부분인 것을 의미합니다.
Separate Modeling
Separate Modeling은 현재의 shot이 scene,story,topic 즉, 세 가지의 semantic level에 대한 segmentation point 중 한 가지 인지 예측하는 문제 입니다.
일단 scene, story, topic이 변하는 지점이라면 상관 없으니 일단 semantic level 변하는 지점이라면 1 아니면 0으로 예측하는 문제를 푸는 것이죠.
결국에는 shot classification 문제를 푸는 것이고 이 때 semantic level에 대한 계층적인 구조에 대한 고려는 하지 않고 일단 semantic level 바뀌는 지점을 찾는 작업 입니다.
Hierarchical Modeling
Hierarchical Modeling은 말 그대로 Segmentation Point를 각각 찾는 것 입니다. 단순히 Semantic Level이 바뀌는 지점만 찾는 것이 아니라 그 지점의 Semantic Level이 무엇인지 구분하는 것이죠.
위에서는 막연하게 바뀌는 지점만 찾았다면 이제는 바뀌는 지점이 장면이 바뀌는 것인지 주제가 바뀌는 것인지 구분하는 것 입니다. 확실히 더 어려운 task로 이러한 semantic level의 계층적인 구조에 대한 이해 없이는 잘 수행할 수 없겠죠.
이러한 Hierachy를 Modeling 하기 위해 두 가지 패러다임을 이용하여 학습 합니다. 어려운 것은 아니고 Multi-Label 혹은 Multi-Task 입니다.
결국 핵심은 공통적인 백본에서 multi label은 하나의 헤드를 multi label로 optimization 시키는 것이고 multi-task는 여러개의 헤드를 각각의 task로 optimization 시키는 것 입니다. 워낙 많이 쓰이는 방법이라 그냥 이렇게 했구나 정도로 넘어 가시면 될 것 같습니다.
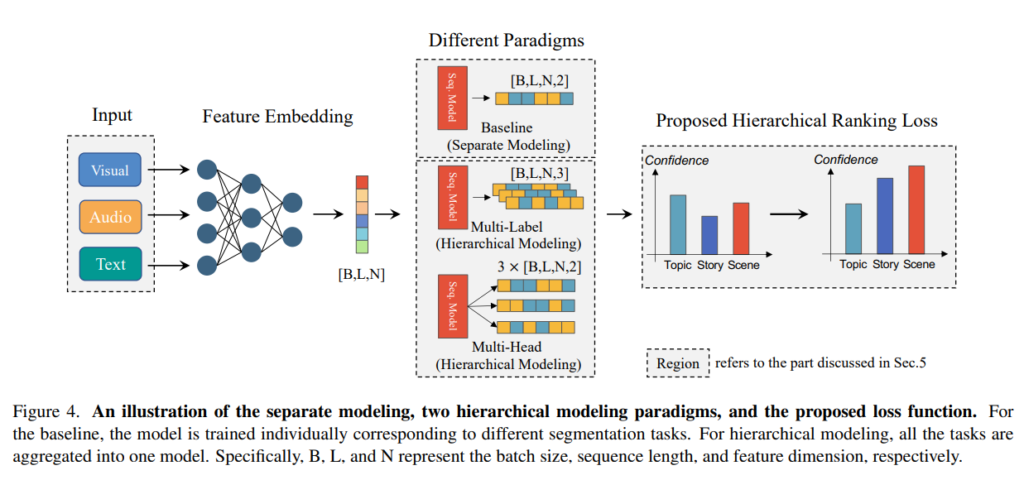
이때 저자는 hierarchy를 더욱 잘 modeling 하기 위해 새로운 loss function을 제안합니다.
바로 Hierarchical Ranking Loss 입니다.

위의 그림을 보면 higher level task의 boundary 경계에 있는 positive segment들은 lower level task의 경계이기도 합니다. Story의 전환 지점은 Scene과 Event의 전환 지점이기도 한 것이죠. 즉, segmentation confidence score는 high level task에서 low level task로 내려갈 때 score는 더 올라가야 하는 것이죠.

이를 위한 pair loss를 제안합니다.
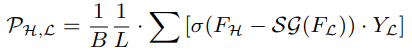
어렵게 보일 수도 있는데 결국 핵심은 Higher Task에 대한 Confidence Score를 낮추는 방향으로 학습 시키는 Loss 입니다. 시그모이드의 값으 0으로 수렴시키기 위해서는 입력값이 작아져야하는데 이때 작게 만들기 위해 Higher Task에 대한 Confidence Score를 낮추는 것이죠.
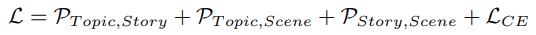
최종 Loss 입니다. \mathcal{L}_{CE}는 segmentation에 대한 Loss 이고 나머지는 ranking loss 입니다.
Experiment and Analysis
저자는 단순히 데이터 셋을 제공하는 것에 그치지 않고 제안하는 데이터 셋을 활용하여 현재의 연구들은 어떠한 경향성을 보이고 어떠한 문제점을 가지고 있으며 이를 통해 어떤 방향으로 나아가야 하는 지를 제안합니다.
Results against Increased Temporal Span
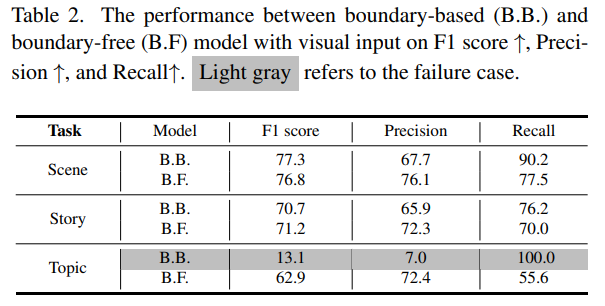
기존의 벤치마킹 방법들을 이용하여 boundary based 의 가장 대표적인 방법과 boundary free 의 가장 대표적인 방법을 활용하여 제안하는 NewsNet에서의 실험을 진행하였네요.
기존의 연구들은 Scene이라는 비교적 짧은(?) range를 커버 하는 segmentation만을 수행하다가 Story나 Topic과 같이 Temporal Span이 길어졌을 때도 잘 작동하는 지를 확인하는 실험을 진행 하였습니다.
확실히 Scene -> Story -> Topic으로 Semantic Level이 올라갈 수록 성능이 하락하고 있으며 기존의 work은 story나 topic level 처럼 고수준의 semantic understanding을 요구로 하는 상황에서는 일반화가 잘 되고 있지 않습니다.
특히 boundary based는 고정된 window size를 가정하기 때문에 temporal span이 길어지는 상황에서 특히나 topic level에서는 아예 검출을 못하고 있습니다.
이로써 첫번째 질문인 Can existing methods also perform well on longhorizon temporal segmentation tasks, such as topiclevel and story-level segmentation? 에 대한 답은 No가 되겠네요.
Performance using Multi-Modalities
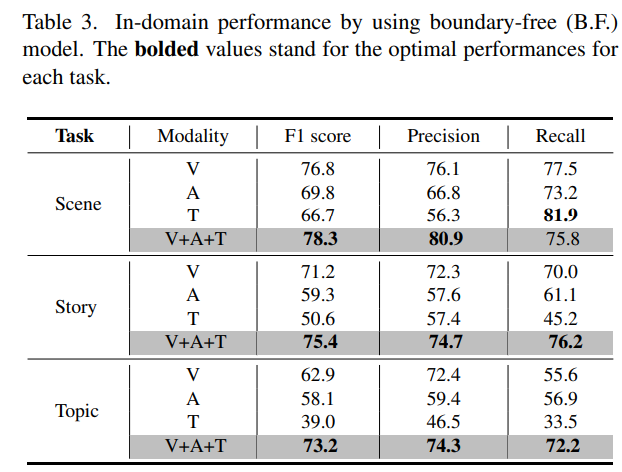
다음으로는 Multi Modality에 대한 실험 입니다. 흥미로운 점이 두 가지가 보입니다. Semantic Level이 낮아질 수록 Visual Information이 중요하게 작용하지만 Semantic Level 높아질 수록 Visual 뿐만 아니라 다른 Modality도 중요하게 작용하는 것 입니다.
이를 통해 저자는 segmentation을 하는 데 있어 복잡한 semantic level의 구조를 이해하기 위해서는 visual 정보 뿐만 아니라 audio, text 등 multi-modal에 대한 정보도 같이 처리해주면 도움이 된다는 것 이었습니다.
정리하면 semantic level의 understanding을 처리하기 위해서는 multi-modal representation도 하나의 방향이 될 수 있을 것 같습니다.
Performance based on Hierarchical Modeling
다음으로는 How could the model benefit from hierarchical annotations? 에 대한 답을 하기 위한 실험을 내놓습니다.
이러한 실험에서 베이스라인은 하나의 specific level의 annotation만을 참고할 수 있는 실험으로 준비했습니다.
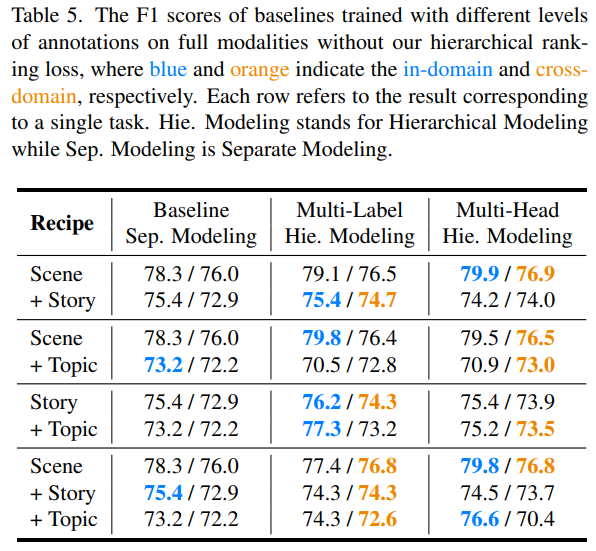
위의 실험을 보면 일반적으로 multi-label annotation을 활용하면 더 좋은 성능 향상을 얻을 수 있는데 항상 그런 것은 아닙니다. multi-laebel의 semantic gap이 커지는 예를 들면 Scene + Topic 같은 경우는 성능이 떨어지고 있습니다.
이러한 경우는 또 다른 질문을 만들고 있네요.
How to jointly train with various granularities toward hierarchical modeling of long form videos?
이 질문에 대한 대답은 아래의 실험을 통해 답하고 있습니다.
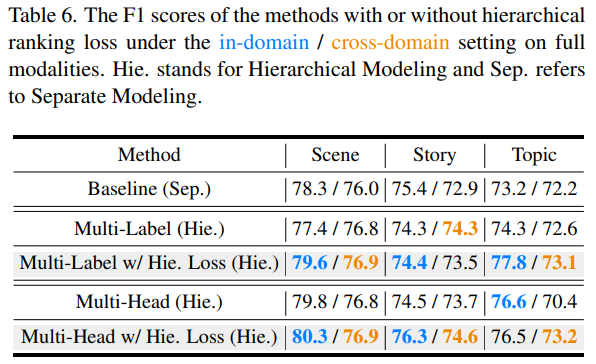
결국 제안하는 Ranking Loss를 통해 문제를 해결합니다. Topic Segmentration에서 Multi-Head setting인 70.4에서 73.2까지 F1 score를 높이고 있습니다.
Conclusion, Limitation and Future Work
좋은 데이터 셋 논문인 것 같습니다. 빨리 공개가 되어서 저의 실험에도 사용이 될 수 있기를 희망해봅니다.
저자가 밝히는 Limitation과 Future Works는 이러한 계층적 구조의 Segmentation을 위한 데이터 셋이고 요즘 또 연구가 활발하게 되고 있는 Visual Reasoning, Question Answering에 사용될 수 있는 데이터 셋은 아니라고 하네요.
뭐 그렇다고 해서 본 논문의 Contribution이 결코 적다고는 생각하지 않기 때문에 좋은 논문이라 생각이 듭니다.
안녕하세요. 임근택 연구원님.
좋은 리뷰 감사합니다.
데이터셋과 더불어 새로운 loss와 실험까지 알찬 논문인 것 같습니다.
데이터셋만 빨리 공개해주면 좋을텐데 아쉽네요..
혹시 이 데이터셋의 text는 어떤 텍스트인지, 예를 들어 영상에서 나오는 대화의 자막인지, 영상을 설명하는 글 형태인지 궁굼합니다.
감사합니다!
좋은 리뷰 감사합니다.
표 5와 관련된 몇 가지 질문이 있습니다.
1. caption에서 설명하고 있는 in-domain과 cross-domain이 무엇인지,
2. 한 칸마다 들어가있는 4개의 숫자가 무엇무엇을 의미하는지,
3. 실험에서 하나의 level에 대한 annotation은 참고할 수 있다고 해주셨는데 행 별로 그게 어떤 level인지가
궁금합니다.