이번 주차 X-Review에서는 23년도 CVPR에 게재된 논문 <Decomposed Cross-modal Distillation for RGB-based Temporal Action Detection>에 대해 소개해드리겠습니다.
해당 논문의 저자는 연세대학교 박사 분이신데, 21년도부터 Weakly-Supervised Temporal Action Localization 관련 논문을 국제 학회에 다수 제출한 이력이 있는 분입니다. 대부분 단독 저자로 논문을 쓰시는게 대단하네요.
- [2020 AAAI] Background Suppression Network for Weakly-Supervised Temporal Action Localization
- [2021 AAAI] Weakly-supervised Temporal Action Localizaiton by Uncertainty Modeling
- [2021 ICCV Oral] Learning Action Completeness from Points for Weakly-supervised Temporal Action Localization
이외에도 다양한 분야의 논문 작업에 참여하셨는데, 이번 KCCV 때 본 리뷰에서 다룰 논문과 관련된 주제로 세미나를 진행하실 예정인 것 같습니다. 저자분의 세미나가 정말 기대되네요.
아무튼 논문의 제목에서 알 수 있듯 제가 항상 다루던 Weakly-Supervised Temporal Action Localization(WTAL)은 아니고, 비디오의 temporal annotation을 모두 활용하는 Fully-Supervised Temporal Action Localization(TAL) 관련 방법론입니다. 기본적으로 TAL에선 RGB feature와 optical flow feature를 함께 사용하는데, optical flow는 computational cost가 너무 크다는 단점이 있습니다. 저자는 이러한 문제점을 해결하고자 학습 시에는 optical flow teacher로부터 RGB 기반 student를 학습시키고, inference할 때는 비디오의 RGB feature만 사용해도 TAL을 수행할 수 있는 프레임워크를 제안합니다.
1. Introduction
비디오에서의 Temporal Action Localization task는 마치 영상 분야의 Object Detection과 같은 기본적인 task로, untrimmed 비디오를 자동으로 분석하는 데에 있어 널리 사용되고 있습니다. 학계에서 연구되던 대부분의 방법론들은 기본적으로 비디오로부터 RGB와 optical flow feature를 추출해 사용하고, 둘을 모두 사용해 성능을 올리는 것을 주 목적으로 삼아왔는데요, 우선 두 모달의 feature는 서로 상호보완적인 정보를 담고 있습니다. 일반적으로 RGB feature는 appearance 정보, flow feature는 motion 정보를 담고 있다고 이야기 합니다.
아무래도 Action을 찾아야 하는 task이다보니 flow feature의 중요성이 더욱 두드러질 것 같은데, 이를 정량적으로 확인해보겠습니다.
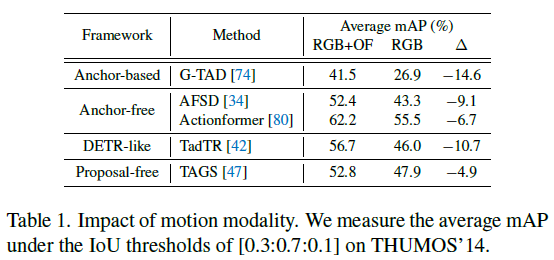
표 1은 기존 TAL SOTA 방법론들에 RGB feature만을 사용한 경우의 성능을 보여주고 있습니다. 매년 갱신되는 SOTA 방법론들의 평균 mAP 향상이 1.5~3% 정도임을 감안했을 때, 최소 5%에서 10%의 성능 하락은 굉장히 큰 타격이라고 볼 수 있습니다.
제가 최근 WTAL 방법론들에 대해 이런저런 실험을 해보았을 때도, RGB feature만을 사용하면 두 모달을 모두 사용할 때의 성능보다 9~11% 하락하는 것을 볼 수 있었습니다. 반면 논문에는 나와있지 않지만 flow feature만을 사용했을 때에는 모두 사용하는 경우보다 1.5~2% 정도의 상대적으로 좁은 하락폭을 보여주며, task 수행에 motion 정보가 훨씬 큰 기여를 하고 있음을 알 수 있었습니다. 물론 두 모달의 feature를 모두 사용할 때 가장 성능이 높기에 서로 complement 한 정보를 담고 있다고 이야기하는 것입니다.
이렇게 상호보완적인 RGB와 flow 정보를 잘 사용하여 정확한 localization을 수행하는 것도 중요하지만, optical flow의 추출 시간이 굉장히 오래걸린다는 점을 감안했을 때에는 TAL의 real-world application적 특성과 잘 맞지 못하게 됩니다. 논문에 따르면 1분 짜리 30fps, 224\times{}224 비디오의 optical flow feature를 추출하는 데엔 1.8분이 걸린다고 하네요.
이러한 특성 때문에 optical flow feature는 실시간성을 갖지 못하게 되는데, 저자처럼 실시간성과 효율성에 집중해보자는 방법론들에서는 optical flow feature 대신 단순 frame difference를 사용하기도 합니다. Frame difference는 단순히 연속되는 프레임의 차이값을 motion 정보로 대체하는 것인데, 이런 경우 optical flow에 수반되는 computational cost는 확실히 줄일 수 있겠지만 마찬가지로 two-stream이기 때문에 두 개의 forwarding process를 거쳐야하는 점에서 효율성이 떨어질 수 있습니다.
위와 같은 문제점을 바탕으로 저자는 RGB 기반의 action detection framework를 설계함으로써, two-stream 방법론들과의 성능 차이를 줄이는 효율적인 프레임워크를 제안하게 됩니다.
사실 RGB 단일 모달만을 사용하는 경우, 두 모달을 모두 사용했을 때와 성능 차이가 크다는 점은 예전부터 드러난 문제점이었을텐데, 저자가 설계하고자 하는 cross-modal knowledge distillation 프레임워크는 기존에 존재하지 않았을까요?
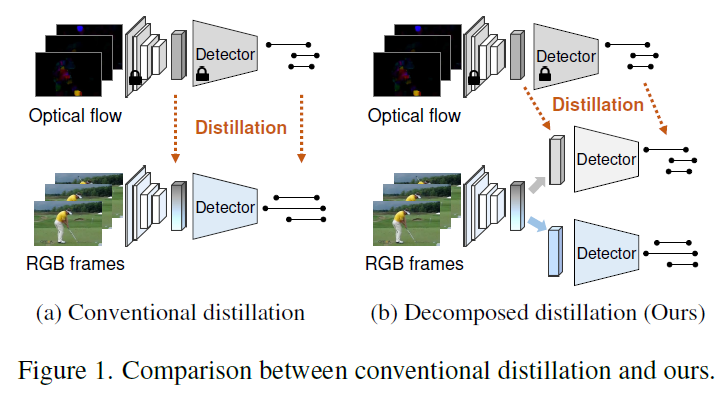
기존에도 그림 1-(a)와 같은 knowledge distillation 방식은 존재했습니다. Optical flow만을 사용하는 경우 성능이 더 높기 때문에 사전 학습된 motion teacher network로부터 RGB student network에게 knowledge distillation을 수행하는 모습을 볼 수 있습니다. 이 때 저희는 RGB와 optical flow feature 각각의 정보가, 상하 관계가 아닌 상호보완적 관계라는 점을 되짚어보아야 합니다.
결국 RGB feature에서 집중하는 정보가 따로 있고, flow feature에서 집중하는 정보가 따로 있다는 것입니다. 하지만 이 둘을 강제로 혼합하며 두 모달이 뒤섞여있는 상태에서 예측을 내뱉는 (a)와 같은 방법론은 최적의 성능을 내지 못한다는 것이 저자의 관찰입니다. 만약 두 모달이 동일한 정보를 보면서 teacher network가 우세했다면 (a)와 같은 방식이 유효했겠죠.
따라서 저자는 (b)와 같이 RGB 기반의 student 네트워크를 motion branch와 appearance branch로 나누어 teacher network로부터의 distillation은 motion branch가 받고, RGB가 보는 정보는 appearance branch에서 잘 보존되도록 설계합니다.
이제 Contribution을 정리한 뒤 knowledge distillation 관련 연구와 저자가 제안하는 프레임워크의 자세한 구성 요소와 특징들을 알아보겠습니다.
Contribution
- We propose a decomposed cross-modal distillation framework, where motion knowledge is transferred in a separate way such that appearance information is not harmed
- We design a novel attentive fusion method that is able to exploit the complementary of two modalities while sustaining the local discriminability of features
- Our method is generalizable to various backbones and detection heads, showing consistent improvements
2. Related Works
2.1 Cross-modal Knowledge Distillation
다들 아시겠지만 knowledge distillation이라는 개념은 기본적으로 대용량 teacher 모델의 지식을 작은 student 모델에게 전달해준다는 컨셉을 가지고 있습니다. 일반적으로 어떤 지식을 distill 해주는지에 따라 responses, features, relations와 같은 3가지 그룹으로 나눌 수 있습니다.
Responses 기반의 프레임워크는 student 모델이 teacher 모델의 예측값을 따라가도록 학습하는 방식이고, feature 기반의 프레임워크는 teacher 모델과 student 모델의 중간 layer 출력값을 유사하게 만들어주는 방식입니다. 마지막으로 felation 기반 프레임워크는 teacher 모델에서의 샘플 간 관계와 student 모델에서의 샘플 간 관계를 유사하게 만들어주는 방식이라고 하는데, representation 관점에서 샘플 간 관계를 모델링하는 graph 등이 유사해지도록 만들어주는 방식으로 보입니다. 물론 3가지 방식 중 하나만 적용할 수 있는 것은 아니고 적절히 조합하여 여러 단계에서 distill을 수행할 수도 있겠죠.
위와 같은 knowledge distillation 방식의 일부 cross-modal knowledge distilation도 존재하는데, 한 모달의 지식을 다른 모달로 전이시켜주는 것이겠죠. 일반적으로는 하나의 도메인이 다른 도메인보다 우세한 성능이나 표현력을 가져 두 모달 모두의 성능을 끌어올리는 방향으로 학습을 수행하게 됩니다. 하지만 action에서 RGB와 flow feature의 경우, 둘 중 하나의 모달이 우세하다기보단 상호보완적 정보를 담고 있기 때문에 서로에게 도움이 될만한 정보를 전달해주는 것이 중요합니다.
하지만 지금까지 action localization에서의 knowledge distillation은 이러한 점을 간과한채로 일반적으로 성능이 높은 flow에서 rgb로의 학습이 수행되었습니다. 이렇게 되면 앞서 언급한 것처럼 RGB 모달만이 보는 정보가 흐려져 표현력 측면에서 손해를 보게 됩니다. 저자는 이런 문제에 대응하고자 RGB만을 입력받되 이후 motion branch와 appearance branch로 나누고, motion branch는 flow의 distillation을 받지만 appearance branch에선 RGB의 온전한 정보를 유지할 수 있는 효율적인 프레임워크를 설계합니다.
3. Method
Problem formulation
T개의 프레임을 갖는 비디오 V \in{} \mathbb{R}^{T \times{} 3 \times{} H \times{} W}가 존재하고, V의 연속적인 feature로부터 optical flow map F \in{} \mathbb{R}^{T \times{} 2 \times{} H \times{} W}를 추출합니다. 각 픽셀 별로 x, y축의 변위를 추정하기 때문에 2차원으로 구성되는 것입니다. 학습 시에는 motion teacher를 사용하기 때문에 optical flow feature F를 추출하는 것이고, 실제 inference시에는 RGB 비디오인 V가 입력됩니다.
TAL 학습을 수행하기 위한 annotation \Psi{} = \{(\varphi{}_{m}, y_{m})\}_{m=1}^{M}이 존재합니다. 이 때 m번째 action instance에 대한 temporal annotation \varphi{}_{m} = (t_{s_{m}}, t_{e_{m}})과 클래스 라벨 y_{m} \in{} \mathbb{R}^{C}가 주어집니다. C는 데이터셋에 존재하는 전체 클래스 개수입니다.
Motion modality

앞선 설명에서도 그렇듯 TAL에서는 일반적으로 motion modality로서 optical flow를 사용합니다. 하지만 최근 연구에선 cost가 많이 요구되는 optical flow를 대체하기 위해 temporal gradient G를 사용하기도 하는데요, 이는 단순히 연속되는 RGB 프레임 간의 차이 V_{t} - V_{t-1}을 의미합니다. 이는 환경 변화나 카메라 움직임과 같은 noise에 강인하지 못하기 때문에 motion 관점에서는 optical flow의 하위 호환이라고 생각하시면 됩니다.
저자는 기본적으로 optical flow F를 사용하지만, 제안하는 방법론의 일반성을 보여주기 위해 실험 부분에서 temporal gradient G를 사용했을 때에 대한 성능도 보여줍니다.
3.1 Motion Teacher Training
가장 먼저 motion teacher에 대한 학습을 해줘야 해당 teacher로부터 student 모델들을 학습시킬 수 있을 것입니다. Motion teacher는 optical flow F를 입력으로 받아 C채널짜리 motion feature z^{mot} \in{} \mathbb{R}^{T/r_{T} \times{} C}를 추출합니다. r_{T}는 downsampling rate로 backbone 구조에 따라 달라지겠죠.
이렇게 추출한 motion feature z^{mot}는 action detection head로 들어가 N개의 action localization 예측 \hat{\Psi{}}^{mot} = \{(\hat{\varphi{}}_{n}, \hat{y}_{n}^{mot})\}_{n=1}^{N}을 만들어냅니다. 여기까지의 설명만 보면 teacher 모델의 구조나 학습이 너무 추상적이라고 생각하실 수 있는데, 실제 backbone이나 action detection head의 경우 어느 모델이나 활용될 수 있기 때문에 저자가 의도적으로 추상적인 서술을 했다고 합니다.
이후에는 가지고 있는 GT를 활용해 각 방법론에 적용되는 loss로 학습을 수행하는데요, 기본적으로는 GT와의 IoU값을 이용해 positive set \Psi{}_{P}^{mot}, negative set \Psi{}_{N}^{mot}을 먼저 만들어줍니다. 이후 3가지 loss를 통해 학습합니다.
1 – Classification loss \mathcal{L}_{cls}
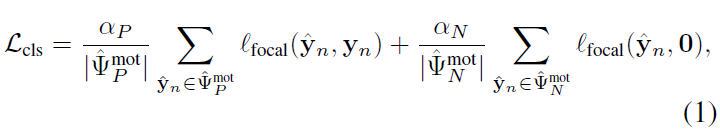
수식이 복잡해보이지만 \alpha{}는 balancing hyperparameter이고, 결국 positive set에 대해서는 GT label로 focal binary CE loss, negative set에 대해서는 모든 클래스에 0을 할당한 label로 focal binary CE loss를 적용해주는 꼴입니다. Binary인 이유는 예측값과 라벨이 각 클래스의 존재 여부에 따라 0 또는 1로 구성된 이진벡터이기 때문입니다.
2 – Regression loss \mathcal{L}_{reg}
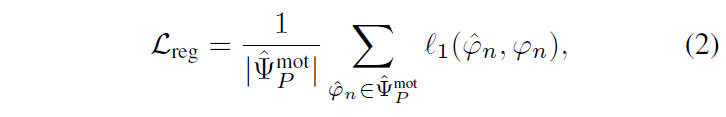
\mathcal{L}_{reg}는 정의한 positive set 내 proposal들에 대해 매칭된 GT와의 시작, 끝 지점의 L1-distance를 최소화하는 역할을 수행합니다.
3 – Completeness loss \mathcal{L}_{comp}
\mathcal{L}_{comp}는 positive set 내 proposal들에 대해 GT와 1에 가까운 IoU를 갖도록 아래와 같이 설계됩니다.
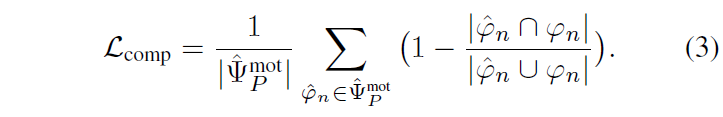
위와 같은 3가지 loss는 TAL에서 일반적으로 사용되는 loss입니다. 최종적으로 motion teacher model \mathcal{M}^{mot}은 아래 loss들을 통해 RGB를 입력받는 motion branch에 전달해줄 optical flow의 motion 정보를 잘 학습하게 됩니다.
- \lambda_{cls}\mathcal{L}_{cls} + \lambda_{reg}\mathcal{L}_{reg} + \lambda_{comp}\mathcal{L}_{comp}
3.2 Decomposed Cross-modal Distillation
이제 teacher model \mathcal{M}^{mot}과 GT label로부터 RGB를 입력받는 모델의 두 branch를 학습시켜야 합니다. 우선 raw video V를 backbone에 태워 RGB feature z^{RGB} \in{} \mathbb{R}^{T/{r_{T}} \times{} C}를 추출하고 이를 motion branch와 appearance branch에 각각 넣어줍니다.
이후에는 branch에 따라 다른 학습을 수행하는데, 이는 아래에서 자세히 살펴보겠습니다.
3.2.1 Motion branch
Motion branch는 시각적 정보를 담고 있는 RGB feature를 입력으로 받아 action에 필수적인 motion 정보를 추출하는 것이 목적입니다. 당연히 RGB 정보만을 보고 효과적인 motion 정보를 얻어내는 것은 어려우니, 학습을 마친\mathcal{M}^{mot}로부터 정보를 distill 받아야겠죠.
앞서 2장에서 언급했듯 knowledge distillation은 어떤 정보를 distill 해주는지에 따라 3가지 그룹으로 나뉜다고 했었는데요, 본 방법론에서는 그 중 teacher의 예측값이 student의 예측값과 유사해지도록 학습하는 response 기반 방식과 둘의 중간 feature가 유사해지도록 학습하는 feature 기반 방식을 도입합니다.
1 – Response-based distillation loss \mathcal{L}_{respon}
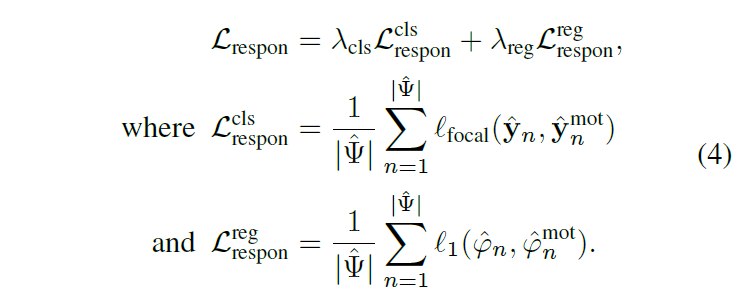
\mathcal{L}_{respon}은 예측된 proposal의 (시작, 끝 지점 loss)와 (클래스 loss)로 구성됩니다. 여기서 (\hat{\varphi{}}_{n}^{mot}, \hat{y}_{n}^{mot})은 \mathcal{M}^{mot}의 예측값이고 이를 pseudo label 삼아 motion branch의 예측값을 학습하는 것입니다. \mathcal{L}_{respon}^{cls}, \mathcal{L}_{respon}^{reg}는 수식 (1), (2)와 동일한 역할이지만 label이 GT가 아닌 \mathcal{M}^{mot}의 예측값이라는 점만 다르네요.
2 – Feature-based distillation loss \mathcal{L}_{feat}
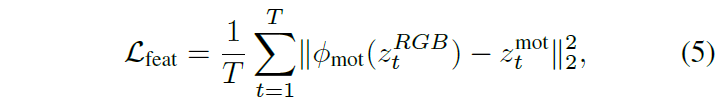
z_{t}^{RGB}는 어디까지나 RGB modal로부터 온 feature이기 때문에 바로 z^{mot}과 유사해지기에는 어려움이 있습니다. 이를 완화해주고자 다시 한 번 1D Conv로 구성된 projection layer \phi{}_{mot}를 거친 후에 유사해지도록 학습합니다. 물론 backbone feature가 아니라 detection head 구성에 따라 중간 layer의 feature가 유사해지도록 설계할 수도 있습니다.
정리하자면 motion branch에서 motion teacher \mathcal{M}^{mot}의 action 예측값과 backbone feature가 유사해지도록 학습하는 것입니다.
- \mathcal{L}_{distill} = \mathcal{L}_{respon} + \lambda{}_{feat}\mathcal{L}_{feat}
3.2.2 Appearance branch
Motion branch만 존재한다면 기존 TAL에서의 cross-modal distillation 방법론들과 다를게 없을 것입니다. Appearance branch를 통해 RGB feature로부터 얻을 수 있는 정보도 온전히 보존해주어야 두 모달 간의 상호보완성을 잘 활용할 수 있게 될 것입니다.
이 부분은 그림에서도 볼 수 있듯 굉장히 간단하게 설명할 수 있는데, 입력값이 RGB frame이라는 점만을 제외하고는 3.1의 \mathcal{M}^{mot}을 학습하는 과정과 똑같습니다. Appearance branch의 detector로 예측을 수행하고, 이를 GT와 직접 비교하며 class, regression, completeness를 학습하게 됩니다. Motion feature로부터는 얻기 힘든 RGB만의 context, visual 정보를 본 branch를 통해 보존할 수 있는 것입니다.
Appearance branch는 \mathcal{M}^{mot}과 동일하게 GT로부터 아래 loss를 통해 학습합니다.
- \mathcal{L}_{app} = \lambda_{cls}\mathcal{L}_{cls} + \lambda_{reg}\mathcal{L}_{reg} + \lambda_{comp}\mathcal{L}_{comp}
3.2절까지의 방식을 통해 수행된 것들을 architecture overview 그림과 함께 정리해보겠습니다.
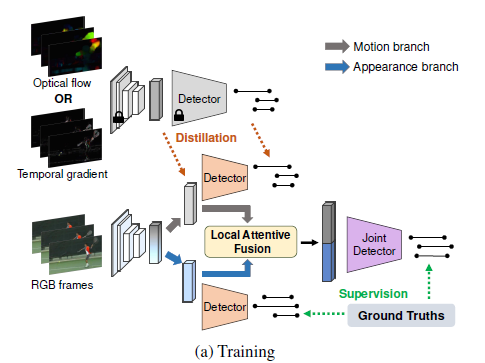
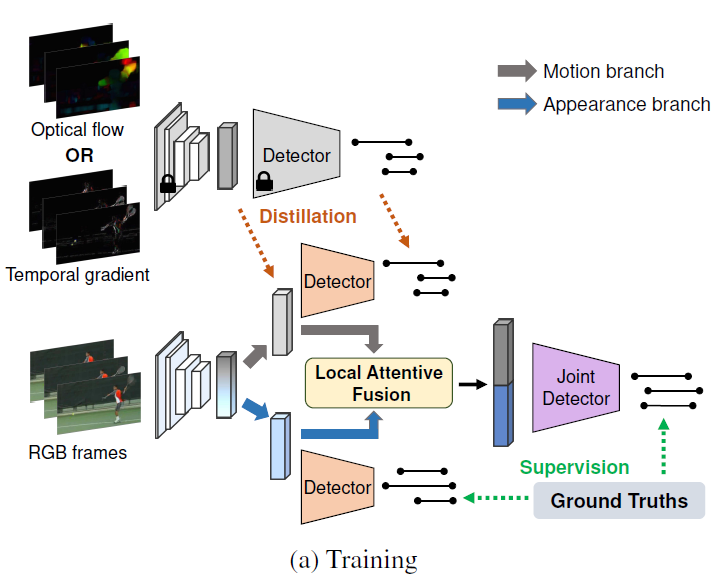
저자가 제안하는 프레임워크에서 가장 핵심적인 것은 효율성을 위해 RGB 입력만을 받는다는 것이고, TAL 수행에 있어 motion 정보와 appearance 정보는 상호보완적인 관계가 있기 때문에 둘 다 잘 모델링해주어야 합니다. 이를 위해 Motion branch와 Appearance branch가 존재하여 각 branch에 속한 Detection head(살구색)에서 각 모달의 특성을 살린 action proposal을 예측해내게 됩니다. 이 때 Motion branch에서의 backbone feature와 예측값은 미리 학습시켜놓은 Motion teacher로부터 학습되고, Appearance branch에서의 예측값은 실제 GT를 보며 학습하는 비대칭적 학습 전략이 사용되는 것입니다.
위와 같은 비대칭적 학습 상황에서 저자는 각 branch에서의 예측 proposal이 해당 모달에서만 보는 정보를 잘 담아낸다고 판단하지만, 이러한 특성이 feature encoder가 아닌 성능 좋은 Detection head로부터 만들어진다는 것도 관찰합니다. Feature encoder까지만 태우면 각 모달의 특성을 잘 살리지 못하고 유사한 representation을 만들어낸다는 것입니다. 따라서 저자는 그림 상 2개인 살구색 Detection head가 가중치를 공유하도록 설계하여, 각 feature encoder가 모달 별 특징을 잘 살리도록 책임을 부과해주게 됩니다.
3.3 Local Attentive Fusion
두 branch의 feature encoder로부터 각 모달에 맞는 feature를 만들어냈다면, 다음으로는 양질의 proposal을 만들기 위해 motion과 appearance를 어떻게 잘 합쳐야 할지 고민해야 합니다. 둘을 합치기 위한 가장 naive한 방법은 concat일텐데요, 단순 concat은 하나의 모달이 잘못된 정보를 담고 있었다면 이를 상대 모달에게 그대로 전파해줄 수 있기 때문에 다양한 오류가 생길 수 있다고 합니다. 이러한 상황을 방지하기 위해 각 모달의 장점을 상대에게 전파해줄 수 있는 조화로운 방식이 필요하겠죠.
두 모달의 정보를 적절히 합치는 대표적 방식으로 cross-attention을 떠올리신 분들이 많을텐데, 이는 실험적으로 그렇게 좋은 결과를 보여주지 못했다고 합니다. Cross-attention 연산 시 temporal 축을 따라 모든 snippet들이 관여하며 local discriminability가 흐려졌기 때문으로 추정하는데, 이에 저자는 local discriminability를 잘 보장하면서 두 모달을 섞을 수 있는 local attentive fusion 기법을 제안합니다.
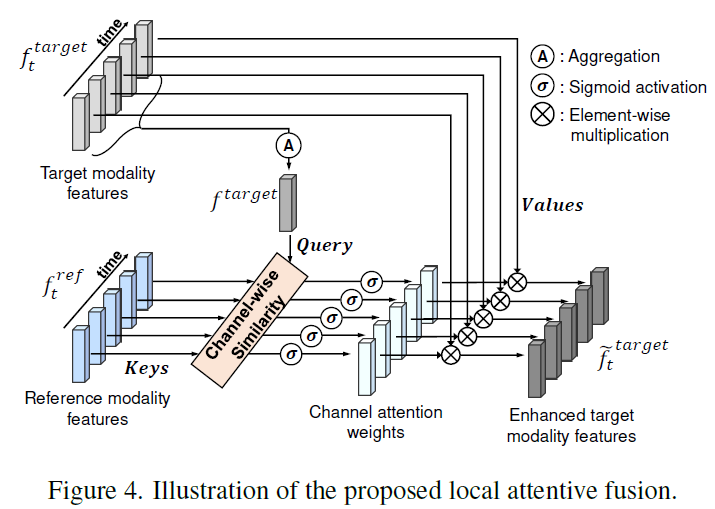
위 그림 4가 해당 기법을 직관적으로 잘 설명하고있긴 하지만, 천천히 살펴보겠습니다. 먼저 enhance할 대상 모달을 target modality, 반대 모달을 reference modality라고 두겠습니다. 한 모달씩 번갈아가면서 enhance가 수행되겠죠. 우선 아래와 같이 target 모달의 시간 축에 대해 pooling 연산 \psi{}(=max, average pooling 등)를 거쳐 representative feature를 만들어줍니다.
- f^{target} = \psi{}(f_{1}^{target}, \cdots{}, f_{T}^{target}) \in{} \mathbb{R}^{D}
이후엔 reference 모달의 T개 snippet 별 query-key matching을 아래와 같이 수행합니다.
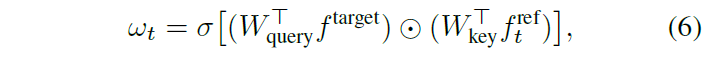
W_{query}, W_{key} \in{} \mathbb{R}^{D \times{} D}는 각각 query, key projection layer에 해당하고 \circledcirc{}는 아다마르 곱, \sigma{}는 sigmoid를 의미합니다. 이렇게 pooling 된 target 모달의 feature 하나를 쿼리로 둠으로써 모든 temporal 위치와의 연산을 하지 않게되고, 결국 cross-attention에서는 보장할 수 없었던 feature의 local sensitivity를 최대한 유지할 수 있게 되는 것입니다.
이렇게 얻은 weight \omega_{t} \in{} [0, 1]^{D}는 아래와 같이 target feature에 snippet 별로 곱해 enhanced target feature \tilde{f}_{t}^{target}를 얻을 수 있습니다.
- \tilde{f}_{t}^{target} = \omega_{t} \cdot{} f_{t}^{target}
위와 같은 과정을 거쳐 motion feature와 appearance feature를 enhance 해주었다면, 이제는 둘을 concat하여 enhanced multimodal feature를 만들어주고 이를 joint detection head(overview에서의 보라색 detector)에 넣어 예측 proposal을 만들고 GT 값으로부터 학습을 수행합니다. 사용되는 loss들은 GT로부터 학습하는 appearance branch와 동일합니다.
- \mathcal{L}_{joint} = \lambda_{cls}\mathcal{L}_{cls} + \lambda_{reg}\mathcal{L}_{reg} + \lambda_{comp}\mathcal{L}_{comp}
3.4 Joint Training and Inference
학습 과정에서의 전체 loss는 아래와 같습니다.
- \mathcal{L}_{total} = \mathcal{L}_{app} + \mathcal{L}_{distill} + \mathcal{L}_{joint}
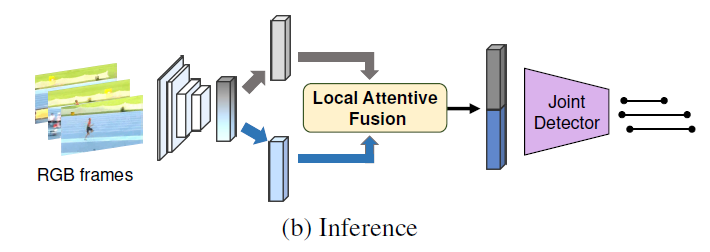
Inference 시에는 Motion teacher와 각 branch 별 detection head를 떼고, 잘 학습된 feature encoder로부터 RGB frame의 feature를 얻습니다. 이후 local attentive fusion 기법을 통해 모달별 특성을 잘 살린 enhanced multimodal feature를 생성해 joint detector에 넣어 예측을 만들어내게 됩니다.
4. Experiments
4.1 Experimental Setups
저자가 제안하는 프레임워크의 video backbone이나 detection head는 어떠한 기존 모델도 들어갈 수 있습니다. 이러한 일반성을 입증하기 위해 video backbone으로는 TSM18, TSM50, I3D, SlowFast50, detection head로는 anchor 기반 방법론 G-TAD, anchor-free 기반 방법론 Actionformer, query 기반 방법론 TadTR을 조합해가며 실험하였다고 합니다.
4.2 Analysis
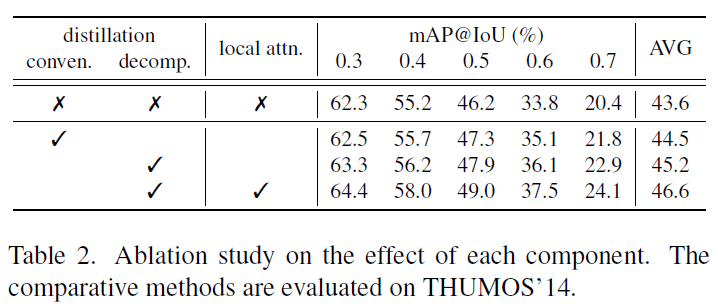
표 2는 각 모듈별 ablation 성능입니다. THUMOS14 데이터셋에서 backbone은 TSM18, detection head는 Actionformer로 고정된 상태이고, Baseline 성능은 knowledge distillation 없이 오로지 RGB feature만을 받아 TAL을 수행하는 상황입니다. 추가로 표 2는 optical flow가 아닌 temporal gradient(frame difference)를 motion 정보로 활용하여 측정된 성능입니다.
Conventional distillation은 temporal gradient teacher로부터 하나의 branch를 학습하는 경우(그림 1-(a))이고, local attention이 사용되지 않았다는 것은 두 branch의 feature를 단순 concat한 경우이겠죠.
물론 conventional distillation 방식이 temporal gradient 정보까지 활용하며 기존보다 성능이 올라가는 것은 맞지만, 2행과 3행을 비교했을 때 motion branch와 appearance branch를 따로 두어 두 모달을 따로 두는 decomposed 방식이 더욱 높은 성능을 보여주고 있습니다. 또한 local attention 기법을 사용했을 때, 1.4%라는 큰 성능 향상을 보이는 것을 알 수 있습니다.
그렇다면 다양한 fusion 기법 별 성능에 대해서도 알아보아야겠죠.
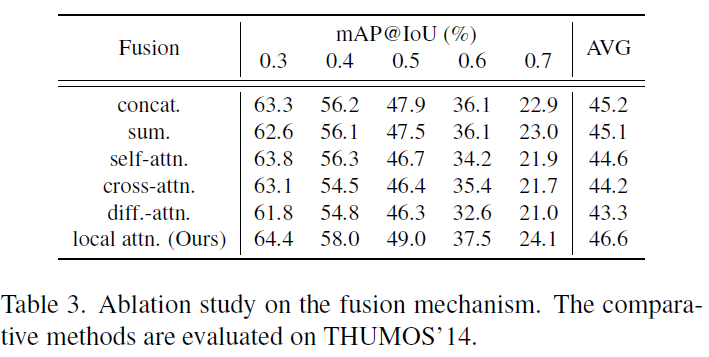
표 3은 표 2와 동일한 실험 조건 하에, fusion 방식만 변경해가며 측정한 성능입니다. 우선 local attention이 다른 fusion 기법에 비해 월등히 높은 성능을 보여주고 있네요.
신기한 점은 self-, cross-, difference-attention 기법이, 굉장히 naive한 concat이나 sum 기반의 fusion보다 성능이 떨어진다는 것입니다. 이에 대해 저자는 앞서 언급한 것과 같이 attention 연산 시 모든 snippet의 정보를 종합하는 과정에서, local하게 구별력을 가져야 하는 action boundary 영역이 smoothing되는 현상 때문일 것이라고 분석하고 있습니다. 추가로 difference-attention은 처음 들어보았는데, query는 decoder에서, key, value는 encoder에서 가져와 attention 연산을 수행하는 방식이라고 합니다.
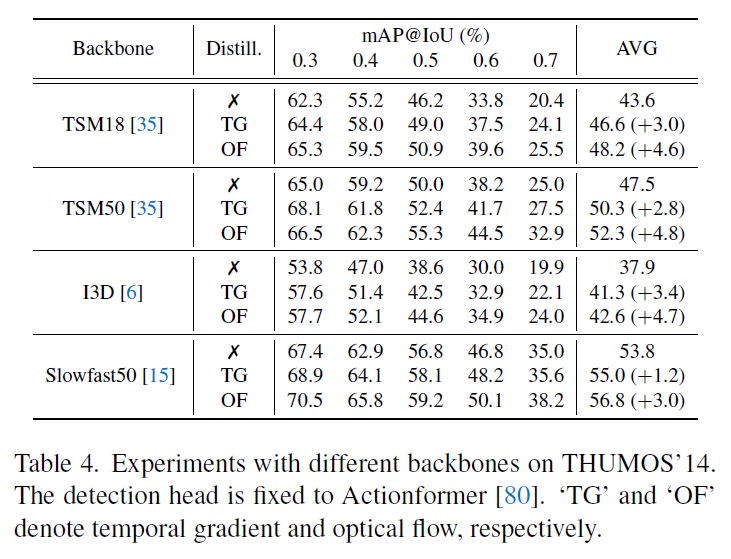
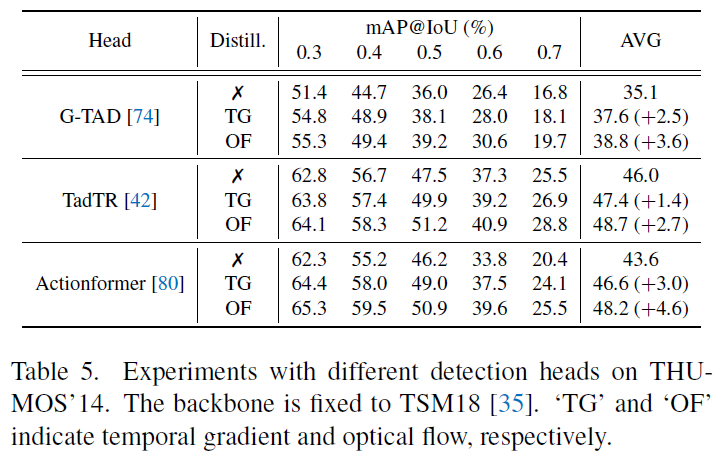
다음으로 표 4는 video backbone에 따른 성능 향상 폭입니다. Detection head는 앞에서와 마찬가지로 Actionformer로 고정한 상태입니다. 반대로 표 5는 backbone을 TSM18로 고정한 상태에서 detection head 별 성능 향상 폭입니다.
저자가 제안하는 프레임워크는 어떠한 backbone이나 detection head를 붙였을 때에도 RGB feature만 사용하는 상황 대비 유의미한 성능 향상을 보여주고 있습니다. 개인적으로는 inference 시에 optical flow도 사용하는 방법론들에 비해 성능 하락폭이 얼마인지가 가장 궁금한데, 이는 아래 벤치마크 표 부분에서 알아보겠습니다.
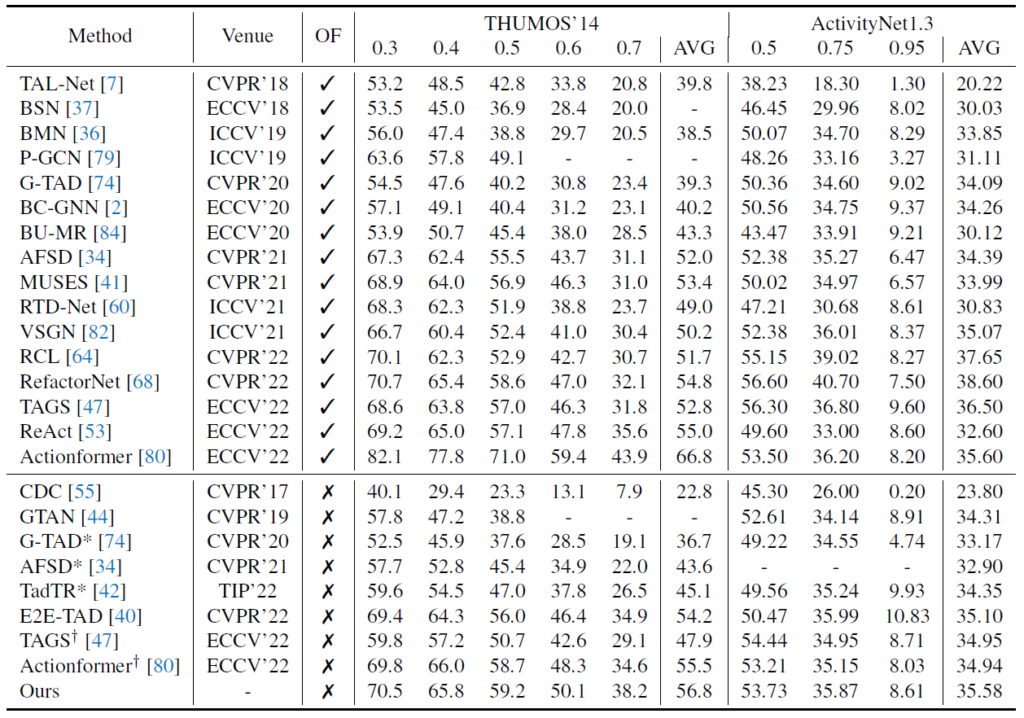

표 6은 THUMOS14와 ActivityNet v1.3에서의 벤치마크 성능입니다. Ours의 backbone은 Slowfast50, detection head는 Actionformer를 사용한 경우의 성능입니다. Inference 시 RGB만을 입력으로 받는 모델 중에서는 두 데이터셋 모두에서 성능이 가장 높은 것을 볼 수 있습니다.
방법론과 데이터셋 별 inference 시 OF를 함께 사용하는 경우와 사용하지 않는 경우 성능 차이가 너무나도 다양한데요, Ours에서 사용한 Actionformer의 RGB만 사용하는 경우 대비 THUMOS14에서는 1.3%, ActivityNet에서는 0.6% 정도의 성능 향상이 일어나는 것을 볼 수 있습니다. 하지만 THUMOS14 데이터셋 기준, inference 시 optical flow까지 사용하는 Actionformer보다는 아직 성능이 많이 부족한 것을 알 수 있습니다. Inference 시 optical flow를 사용할 때의 cost도 정량적으로 함께 보여줄 수 있었다면 효율성 대비 성능 향상 폭의 정도를 비교해볼 수 있었을 것 같은데, 그게 없다는 점이 살짝 아쉽습니다.
5. Conclusion
저자분께서 기존 방법론에 덧붙일 수 있는 새로운 방식을 제안하시기도 하지만, 본 논문에서와 같이 새로운 결의 프레임워크를 자주 제안하시는 것이 참신하면서도 대단하다고 느껴집니다. 예전에 RGB만 사용하는 경우 성능 하락폭이 큰 것을 보고 효율적 inference를 위해 어떻게 할 수 있을지 고민해본 적이 있었는데, 이를 실제로 다루기 위해 치밀한 설계와 실험을 보여준 것이 인상깊었던 논문이었습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요. 김현우 연구원님.
좋은 리뷰 감사합니다. 저도 이 저자분의 BaS Net 논문을 보고 상당히 인상깊었는데, KCCV가 기대되네요.
논문에 대하여 간단한 질문이 있습니다.
RGB backbone에서 추출된 feature가 motion branch와 appearance branch로 각각 입력되는데, 이들이 각각의 feature encoder를 거쳐, 가중치를 공유하는 detection head 혹은 joint detector에서 예측을 수행하는 것으로 이해하였는데요. 그렇다면 feature encoder는 단순한 MLP나 CNN 구조인 것인가요?
그리고 마지막의 성능 비교를 보니, Optical Flow만 사용하는 ActionFormer와 정확도가 유사한 것처럼도 보이는데, 혹시 ActionFormer 모델이 많이 복잡하고 무거운 모델인가요? 이 모델에서도 Detection Head로 ActionFormer를 사용하였다고 하셨는데, 혹시 이 모델과 ActionFormer의 cost가 대략적으로라도 어느 정도 차이인지, 궁굼합니다!
감사합니다.
feature encoder는 여러 개의 1D Conv들로 구성되어 있습니다.
또한 actionformer는 트랜스포머의 일반적인 구조를 바탕으로 action localization을 수행하기 위해 특화된 detector인데, 제가 아는 한 tal 또는 wtal task 자체에서 inference time이나 모델의 사이즈와 같은 효율성을 크게 따지지는 않고 있는 상황이라 이에 대한 정량적인 정보를 드리긴 어려울 것 같습니다.
좋은 논문 리뷰 감사합니다.
비슷한 컨셉의 논문인 SoLA 와의 비교도 본 리뷰에 따로 추가하여 적어주었으면 더욱 좋았을 것 같습니다.
확실히 복잡한 헤드를 연구하는 것 보다 이렇게 좋은 아이디어 바탕으로 앞단의 feature representation을 고도화해주는 것이 훨씬 좋아보입니다.
해당 논문과 SoLA를 베이스 삼아 앞으로의 연구 방향을 고민해볼 생각이 있으신가요??
위 논문과 같이 효율성을 위해 RGB만을 사용하는 모델의 성능을 올리는 것도 좋은 방향일 것 같습니다. 이를 위해 이전에 한 분석을 토대로 RGB feature에 motion 정보를 불어넣어줄 수 있는 모델링을 한다면 많은 도움이 될 것 같습니다
정확한 실험을 통해 빨리 feasibility를 보는 것이 중요할 것 같네요