
안녕하세요. 이번에도 6D pose estimation 관련 논문 리뷰를 진행합니다. 좋은 기업들과 학교에서 참여한 논문이라 매우 신뢰도가 올라가는 것 같습니다.
이번 논문은 unseen object에 대한 pose estimation을 다루는 논문인데요. 즉, CAD 모델 없이 이러한 문제를 해결하는 접근법을 category-level 6D pose estimation이라고 합니다. 저희가 지금까지 리뷰한 논문들은 이미지에 존재하는 오브젝트와 정확하게 맞는 3D CAD 모델을 필수로 하는 것을 instance-level 6D pose estimation이라고 할 수 있겠습니다. 실제 환경에서 모든 물체에 대해 CAD 모델을 만드는 것은 현실적으로 힘들 것 같다는 생각이 듭니다. 이러한 문제를 해결하기 위해 처음으로 CAD 모델 없이 학습과 평가까지 진행하는 방법을 제안한 논문입니다. 최근에는 CAD 모델을 만들기 힘든 현실적인 문제를 해결하기 위해 self-supervised 방법론들로 연구가 진행이 많이 되고 있는 것으로 알고 있으므로 unseen object pose estimation과 관련된 논문들을 다시 서베이 할 예정입니다.
리뷰 시작하겠습니다.
Abstract
이번 논문의 목표는 RGB-D에서 unseen object instance의 6D pose와 size(dimension)을 추정하는 것입니다. 저희가 지금까지 리뷰를 했었던 논문들이 대부분 3D CAD 모델을 기반으로 다양한 방법을 통해 성능을 향상시키는 방법론들이 instance-level에서의 방법론들이라고 이해하시면 좋을 것 같습니다. 하지만 이번 논문에서 다루는 문제는 학습/평가를 진행하는 과정에서 정확한 CAD 모델을 사용할 수 없다고 가정을 하고 진행을 합니다. 주어진 카테고리 내에서 다양한 unseen object instance에 대해 Normalized Object Coordinate Space(NOCS)를 제안하여 문제를 해결합니다. region-based 신경망이 class label, instance mask와 같은 다른 객체 정보와 함께 관찰된 픽셀에서 이 NOCS representation에 대한 대응을 direct regression하도록 하고 depth map과 결합하여 clutter scene에서 여러 오브젝트의 6D pose와 size(dimension)을 추정할 수 있습니다. 모델을 학습하기 위해 완전히 annotation 된 대량의 mixed reality 데이터를 생성하는 새로운 새로운 context-aware 기법을 제안합니다.
1. Introduction
물체를 감지하고 3D 위치, 방향, 크기를 추정하는 것은 VR, AR, 로보틱스, 3D scene understanding에서 중요한 요구 사항입니다. 이러한 애플리케이션은 이전에 볼 수 없었던 객체 인스턴스가 포함될 수 있는 새로운 환경에서 작동해야 합니다. 정확한 CAD 모델과 그 크기를 미리 알 수 있는 instance-level의 6D pose estimation 문제를 살펴본 바 있습니다. 안타깝게도 이러한 기법은 대부분의 물체가 이전에 본 적이 없고 알려진 CAD 모델이 없는 일반적인 환경에서는 사용할 수 없습니다. 반면에 3D detection은 CAD 모델 없이도 객체를 분류하고 3D bbox도 추정할 수 있습니다. 이러한 3D bbox는 viewpoint에 따라 달라지며 객체의 정확한 orientation을 encoding 하지는 않습니다. 따라서 이 두 가지 방법은 unseen object의 6D pose와 3개의 비균일 스케일 매개변수(인코딩 차원)가 필요한 애플리케이션의 요구 사항을 충족하지 못합니다. 해당 논문에서는 새로운 오브젝트 인스턴스에 대한 까다로운 문제인 여러 오브젝트의 카테고리 수준 6D pose와 크기 추정을 위한 최초의 방법을 제시함으로써 이 두 가지 접근 방식 간의 격차를 해소하는 것을 목표로 합니다. 반면에 category-level의 3D object detection은 정확한 CAD 모델 없이도 객체 class label과 3D bbox를 추정할 수 있습니다. unseen object에는 CAD 모델을 사용할 수 없기 때문에 첫 번째 과제는 특정 카테고리의 다양한 물체에 대해 6D pose와 size를 정의할 수 있는 representation을 찾는 것입니다. 두 번째 과제는 학습과 평가를 위한 large 데이터셋을 사용할 수 없다는 것입니다. SUN RGB-D또는 NYU v2와 같은 데이터셋에는 정확한 6D pose와 size에 대한 annotation이 없습니다. 이러한 문제들을 솔루션으로 저자는 representation의 문제를 해결 하기 위해 Normalized Object Coordinate Space(NOCS)를 제안하고 데이터 문제를 해결하기 위해 Context-Aware Mixed Reality Approach를 제안합니다.
저자가 설명하는 main contribution을 정리하면 다음과 같습니다.
- 서로 다르지만 관련성이 있는 오브젝트가 공통으로 reference frame을 가지도록 NOCS를 제안하여 unseen object의 6D pose와 size를 추정 가능하도록 함
- RGB 이미지에서 여러 unseen 오브젝트의 class label, instance mask, NOCS map을 공동으로 예측하는 CNN 구조를 사용하여 pose fitting 알고리즘에서 depth map과 NOCS map을 사용하여 물체의 전체 메트릭 6D pose와 size(dimension)를 추정함
- 실제 이미지 내에 오브젝트를 합성하는 공간 Context-aware mixed reality 기법으로, 대규모의 annotation이 된 가상 데이터셋을 생성함. 또한, 학습 및 평가를 위해 완전히 annotation 된 real 데이터셋도 제공합니다.
2. Related Work
Category-Level 3D Object Detection:
오브젝트의 6D pose와 크기를 예측하는 것에 어려운 점 하나는 viewpoint에 따라 달라지는 것이 있습니다. 이에 따라 오브젝트의 위치를 정확하게 파악하고, 물리적인 크기를 찾는 게 중요합니다. 관련된 논문에서는 먼저 2D 이미지에서 2D 물체 영역을 제안하는 영역을 생성한 다음, 제안된 영역을 3D 공간에 projection하여 최종 3D bbox 위치를 더욱 구체화할 것을 제안합니다. 하지만 이러한 접근법은 6D pose를 예측하지는 못 합니다.
Instance-Level 6 DoF Pose Estimation:
일반적으로 저희가 지금까지 리뷰했던 논문들은 Intance-level 기반의 6D pose estimation 문제였습니다. 이러한 문제를 해결하기 위한 솔루션으로 제공된 방법은 3D CAD 모델을 사용하는 것입니다. 학습할 때와 평가할 때 이미지 내에 존재하는 물체에 대해서 정확한 3D CAD 모델이 필요하다는 의미인데요. 현실에서 모든 물체에 대한 CAD 모델을 만드는 것은 어려운 일이라고 생각합니다.
Category-Level 4 DoF Pose Estimation:
제목과 같이 Category-Level에서의 pose estimation 관련 연구가 있었지만 모두 단순화 가정을 전제로 진행을 했다고 합니다. 이러한 알고리즘은 첫 번째로 회전 예측을 중력 방향으로만 제한합니다. 수직 방향으로만 하기 때문에 총 DoF=4가 되겠네요. 두 번째로 의자, 소파, 자동차와 같은 큰 물체에 대해서만 초점을 맞추고 대칭성을 고려하지 않는다고 합니다. 이와 반대로 손바닥만한(?) 좀 작은 물체의 경우에는 pose의 변화가 커서 scale이 큰 물체들보다 더욱 pose를 추정하기 어려운 문제가 있다고 합니다.
이러한 문제를 해결하기 위해 중력방향을 가정하지 않고도 6D pose와 스케일에 대한 예측을 수행하도록 설계를 했다고 합니다.
Training Data Generation
CNN을 학습할 때 가장 큰 문제는 충분한 category, instance, pose, clutter, lighting variation이 있는 학습 데이터가 부족하다는 점입니다. 이러한 문제를 해결하기 위해 새로운 mixed reality method를 도입하여 오브젝트와 실제 배경에 합성 렌더링으로 구성된 대량의 데이터를 context-aware 방식으로 자동 생성하여 더욱 사실적으로 만듭니다.
3. Background and Overview
Category-Level 6D Object Pose and Size Estimation:

여기서는 객체의 rotation 3개, translation 3개, scale parameter 3개(차원)을 추정하는 문제에 초점을 맞춥니다. 해당 문제의 솔루션은 그림1(c)와 같이 객체 주위의 tight한 방향으로 bbox로 시각화할 수 있습니다. 테스트 시 CAD 모델을 사용할 수 없고 보이지 않는 오브젝트에 대한 6D pose가 잘 정의되어 있지 않기 때문에 이 작업은 특히 어렵습니다. 이를 극복하기 위해 저자는 share object space를 정의하여 unseen object에 대한 6D pose와 size를 정의할 수 있는 새로운 representation을 제안합니다.
Normalized Object Coordinate Space (NOCS):
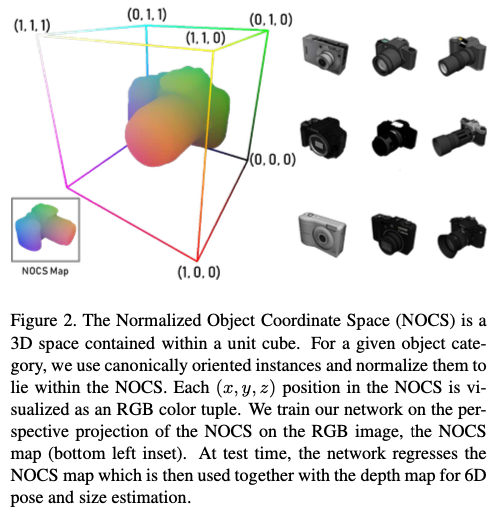
그림(2)를 보시면 NOCS는 unit cube(\{x, y, z\} \in [0, 1]) 내에 포함된 3D 공간으로 정의합니다. 각 카테고리에 대해 알려진 오브젝트 CAD 모델의 shape collection이 주어지면 tight한 bbox의 대각선 길이가 1이되고 NOCS 공간 내에서 중앙에 위치하도록 오브젝트의 크기를 균일하게 하도록 정규화를 합니다(좌측 그림). 또한 동일한 카테고리에서 오브젝트의 중심과 방향에 대해서 정렬합니다(우측 그림). 이때 합성 오브젝트는 일반적으로 사용하는 ShapeNetCore로 부터 사용하여 학습을 하고 스케일, 위치, 방향을 알아낸다고 합니다. ShapeNetCore를 찾아보니 아래와 같이 구성된 데이터셋이네요.

CNN은 색상으로 구분된 NOCS 좌표의 2D perspective projection, 즉 NOCS Map을 예측합니다. 여기서 나오는 NOCS map을 해석하는 방법은 2가지가 있습니다.
(1) 물체가 관찰되는 부분을 NOCS 형태로 reconstruction
(2) Dense pixel-NOCS correspondence
CNN은 unseen object에 대한 shape 예측을 일반화하는 방법을 학습하거나, large shape collection에 대해 학습할 때 물체의 pixel-NOCS correspondence를 예측하는 방법을 학습합니다. 이러한 representation은 물체가 부분적으로만 보이는 경우에도 작동할 수 있기 때문에 bbox 보다 표현력이 좋다고 합니다.
Method Overview:
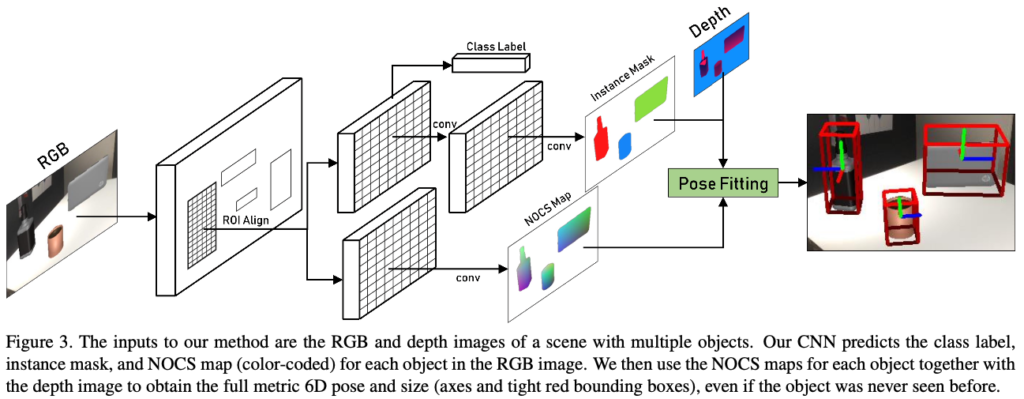
그림(3)은 RGB 이미지와 depth map을 입력으로 사용하는 것을 확인할 수 있습니다. CNN은 RGB 이미지만으로 class label, instance mask, NOCS 맵을 추정합니다. depth를 포함하지 않는 COCO 데이터셋 같은 기존 RGB 데이터셋을 활용하여 성능을 향상시키고자 하기 때문에 CNN에서 depth map을 사용하지 않았다고 합니다. NOCS map은 오브젝트의 shape과 size를 정규화된 공간에 인코딩한다고 이전에 다루었는데요. 따라서, 이후 단계에서 depth map을 사용하여 이 정규화된 공간에 대해 lifting하여 강력한 이상값 제거 및 정렬하여 6D 오브젝트 pose와 size를 예측할 수 있습니다. 여기서 리프팅이란 instance mask로부터 depth 정보를 가지고 각 픽셀에 대해 대응되는 depth 정보라고 이해했습니다. Mask R-CNN을 통해 클래스와 instance mask를 예측하도록 설계했다고 합니다. 학습에서는 새로운 Context-Aware MixEd Reality(CAMERA) approach로 렌더링한 GT 이미지를 사용한다고 합니다. ****
4. Datasets
4.1. Context-Aware Mixed Reality Approach
우리는 실제 크기의 오브젝트에 대한 GT로 large scale의 학습데이터를 쉽게 생성할 수 있도록 데이터 생성에 소요되는 시간을 줄이고 훨씬 더 cost-efficient한 새로운 Context-Aware MixEd ReAlity (CAMERA) 데이터셋을 제안합니다. 해당 데이터셋는 context-aware 방식으로 실제 background 이미지와 합성 렌더링된 foreground 오브젝트를 결합하여 구성합니다.
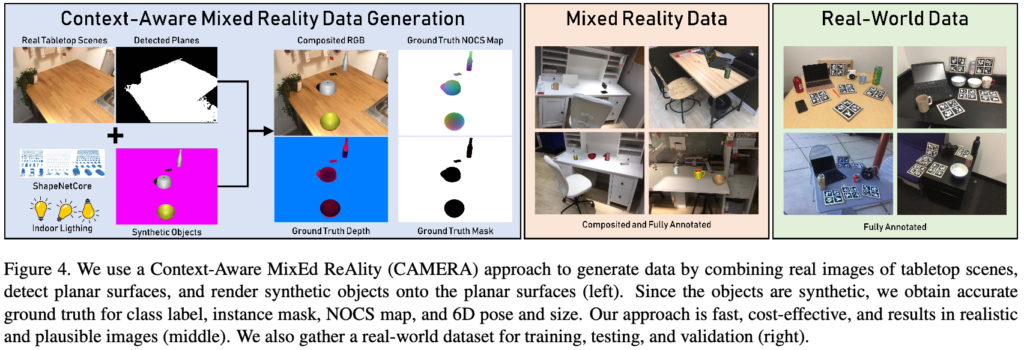
즉, 그림(4)와 같이 합성 오브젝트를 렌더링하여 실제 장면에 그럴듯한 물리적 위치, 일루미네이션 및 스케일을 사용하여 합성합니다. 이러한 CAMERA approach를 통해 더 많은 학습데이터를 생성할 수 있다고 합니다.
5. Method
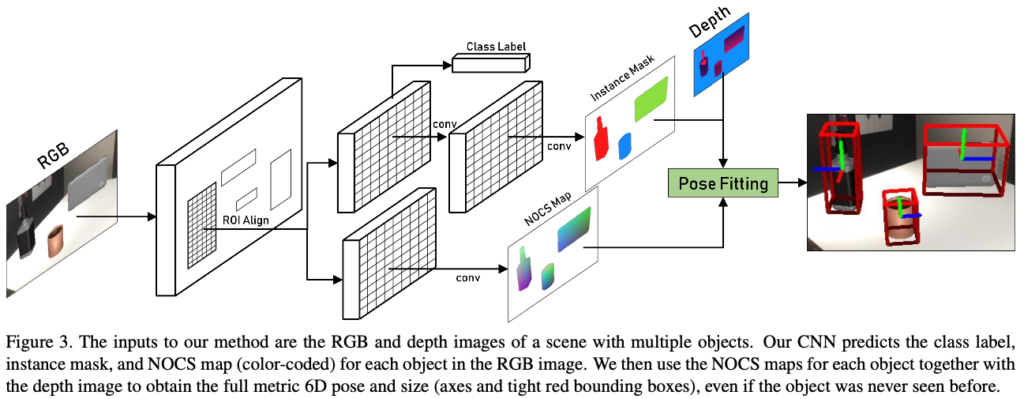
다시 그림(3)을 보면 RGB-D 이미지에서 이전에 여러 unseen object의 6D pose와 size를 추정하는 방법을 보여줍니다. CNN은 오브젝트의 class label, mask, NOCS map을 예측하고, NOCS map과 depth map을 사용하여 물체의 메트릭 6D pose와 size를 추정합니다.
5.1. NOCS Map Prediction CNN
NOCS Map은 어떻게 만들어지는지 알아보겠습니다.
5.1.1. NOCS Map Head
Mask R-CNN은 다들 아시는 Faster R-CNN 아키텍처를 기반으로 객체가 존재하는 가능성이 높은 영역을 제안하는 모듈과 영역 내에서 객체를 detect하고 classification하는 두 가지 모듈로 구성이 되고 영역 내 물체의 instance mask를 예측합니다.
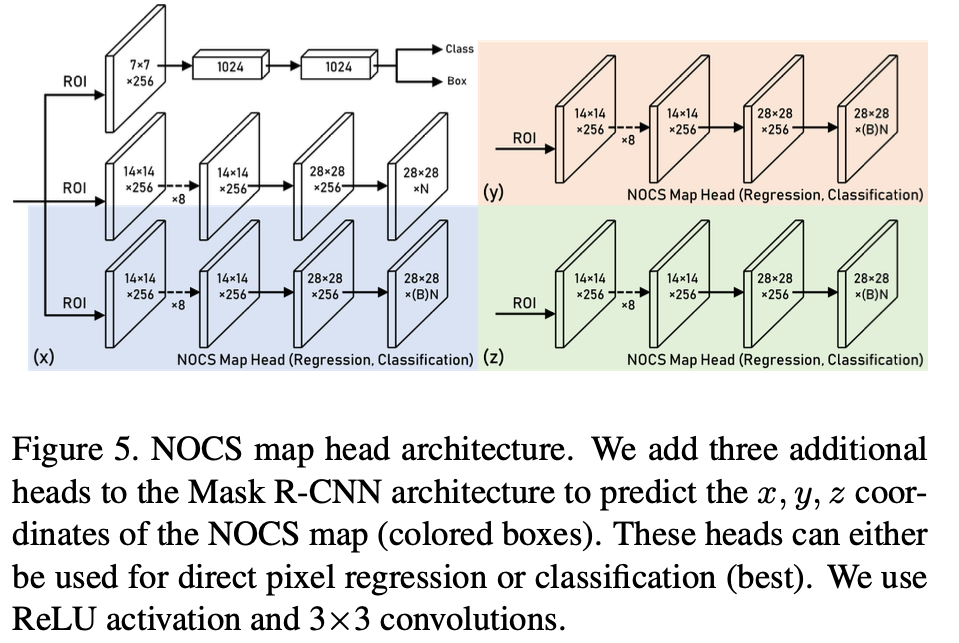
그림(5)를 보시면 해당 논문의 contribution을 알 수 있는데요. NOCS map의 구성요소인 x, y, z를 예측하기 위해 3개의 head를 사용하는 Mask R-CNN에 추가한 것을 알 수 있습니다(파랑, 주황, 초록). 제안된 각 ROI에 대해 head의 출력은 28 \times 28 \times N를 가지고 여기서 N은 카테고리의 수와 해당 카테고리에서 감지된 모든 객체의 x또는 y 또는 z좌표를 포함하는 각 카테고리를 나타냅니다. Mask head와 마찬가지로 테스트 중에 해당 예측 채널을 찾기 전에 오브젝트 카테고리를 사용합니다. 학습 중에는 GT 오브젝트 카테고리의 NOCS map 구성 요소만 손실 함수에 사용됩니다. 여기서는 백본으로 ResNet50 + FPN(Feature Pyramid Network)를 사용했다고 합니다.
Regression vs. Classification:
그림(5)에서 맨 마지막 레이어에 B라고 표시되어있는 부분이 있습니다. NOCS 맵을 예측하기 위해 각 픽셀 값을 regression하거나 픽셀 값을 discretize하여 classification 문제로 처리할 수 있습니다. direct regression는 아마도 학습 중에 불안정성을 유발할 가능성이 있는 더 어려운 작업일 것입니다. 마찬가지로, 클래스 수가 많은 픽pixel classification(예: B = 128, 256)는 더 많은 파라미터를 도입하여 direct regression보다 학습이 더 어려울 수 있습니다. 실험 결과, B = 32를 사용한 pixel classification가 direct regression보다 더 나은 성능을 보였습니다.
Loss Function:
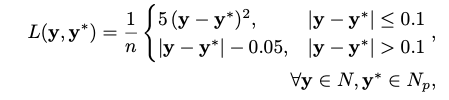
class, bbox, mask head는 기존의 Mask R-CNN에서 사용하는 손실함수와 동일하게 사용하고, NOCS Map의 경우, softmax 손실함수와 L1 loss 손실함수로 2가지의 손실함수를 사용한 위와 같은 식을 사용했다고 합니다. \mathbf y는 GT NOCS map의 픽셀값이고 \mathbf y^*는 예측된 NOCS map 픽셀값입니다. n은 ROI 내부의 마스크 픽셀 수입니다. N, N_p은 GT NOCS map과 예측된 GT NOCS map입니다.
Object Symmetry:
지금까지 보았던 NOCS representation은 대칭성을 고려하지 않습니다. 이러한 문제를 해결하기 위해 손실 함수에 변형을 가했다고 합니다. 학습 데이터의 각 카테고리에 대해 대칭 축을 정의합니다. 이 축을 중심으로 사전에 정의된 회전은 동일한 손실 함수값을 생성하는 NOCS map을 생성합니다. 예를 들어, 윗면이 정사각형인 직육면체는 수직 대칭 축을 갖게 됩니다. 이 축에서 각도 \theta = \{0^\circ , 90^\circ , 180^\circ, 270^\circ \}로 회전하면 동일한 NOCS 맵이 생성되므로 손실이 동일하게 됩니다. 대칭하지 않는 물체같은 경우는 \theta=0로 고유한 각도만 존재할 것입니다. 대칭 축을 따라 |\theta|만큼 회전하는 GT NOCS map \{\tilde y_{1}, ..., \tilde y_{|\theta|}\}를 생성하여 |\theta|회 회전합니다. 실험을 통해 6번정도만 해도 모든 물체에 대해 커버가 가능하다고 하네요.
그런 다음 대칭 손실 함수를 L_{s} = \min_{i=1,...,|θ|} L (\tilde y_i , y^*)로 정의하며, 여기서 y^∗는 사전의 정의된 NOCS map 픽셀 (x, y, z)을 나타냅니다.
5.2. 6D Pose and Size Estimation
우리의 목표는 NOCS map과 입력으로 depth map을 사용하여 detect된 오브젝트의 전체 메트릭 6D pose와 size(dimension)를 추정하는 것입니다. 이를 위해 RGB-D 카메라 extrinsic 및 intrinsic matrix를 사용하여 depth 이미지를 컬러 이미지에 정렬합니다. 그런 다음 예측된 오브젝트 mask를 적용하여 detect된 오브젝트의 3D 포인트 클라우드 P_{m}을 얻습니다. 또한 NOCS 맵을 사용하여 P_{n}의 3D representation을 얻습니다. 그런 다음 P_{n}을 P_{m}으로 변환하는 스케일, 회전 및 변환을 추정합니다. 이때는 사용되는 7차원 rigid transformation estimation 문제에는 Umeyama 알고리즘을 사용하고, 이상값 제거에는 RANSAC을 사용한다고 합니다.
Umeyama 알고리즘은 데이터 포인트들 간의 유사도를 측정하는 문제에서 사용되는 알고리즘 중 하나라고합니다. 특히, 두 개의 데이터 집합 간의 최적의 회전, 확대 및 이동 변환을 찾는 데 사용된다고 하네요.
6. Experiments and Results
Metrics:
3D detection에 대해서는 IoU를 사용하며 threshold=0.5로 설정을 합니다. 6D pose estimation의 경우, error가 translation의 경우 m cm, rotation의 경우 n^\circ 미만인 오브젝트 인스턴스의 AP(Average Precision)를 리포팅합니다. object detection과 6D pose 평가를 각각 분리하는 이유는 성능을 더 명확하게 파악할 수 있기 때문입니다.
6.1. Category-Level 6D Pose and Size Estimation
Test on CAMERA25:
해당 데이터셋은 가상 환경에서 만든 합성데이터셋이라고 생각하시면 되겠습니다.
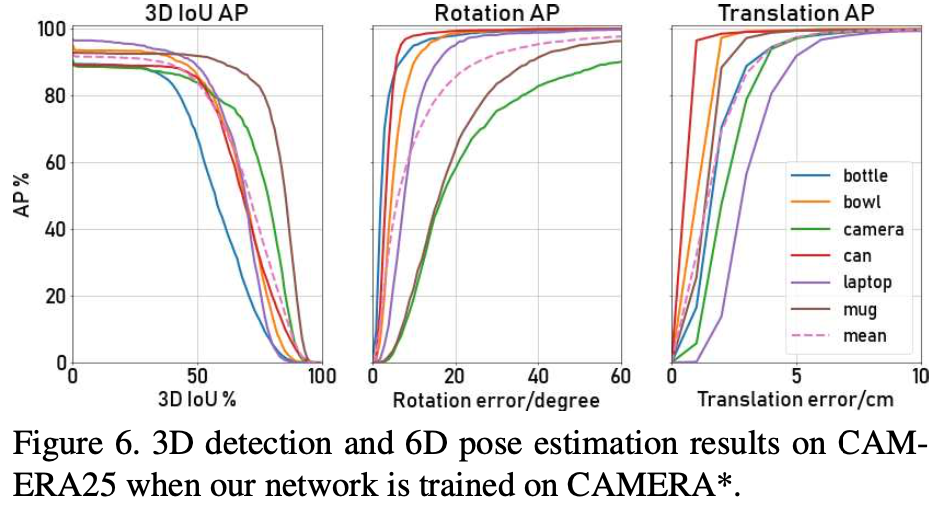
그림(6)을 보면 학습할 때 사용했던 데이터에 대해서 완전히 unseen인 데이터를 테스트 데이터로 사용했음에도 불구하고 3D IoU가 83.9% mAP를 달성했고, 6D pose의 평가지표인 5^\circ 5 cm에서는 40.9 mAP를 달성하였다고 합니다.
Test on REAL275:
해당 데이터셋은 실제 환경(COCO 데이터셋을 배경으로 사용)에서 만든 합성데이터셋이라고 생각하시면 되겠습니다.
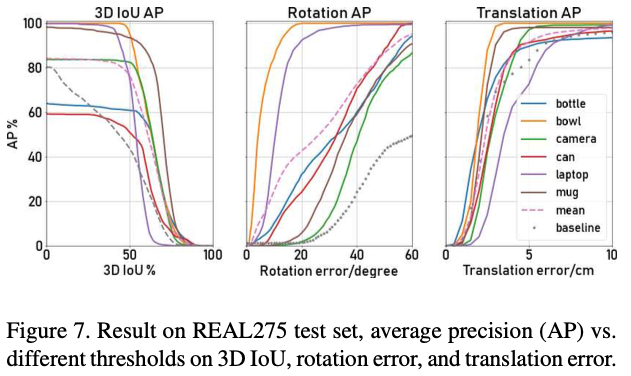
real 데이터셋에서는 이전의 실험결과보다 조금 낮은 결과를 보여주는데요. 3D IoU가 76.4% mAP, pose는 10.2% mAP(5^\circ 5 cm), 23.1% mAP(10^\circ 5 cm)를 달성했다고 합니다. 이 실험을 통해 dense NOCS map을 예측하는 학습을 통해 저자가 제안한 알고리즘이 물체의 6D pose와 estimation를 정확하게 추정하는 데 중요한 물체의 shape, part 및 visibility에 대한 추가 세부 정보를 제공할 수 있음을 보여주는 가능성을 보여줬다고 생각합니다.
6.2 Ablation Studies
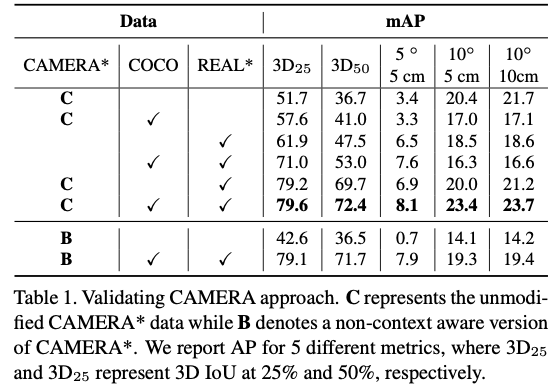
전체적인 실험을 보여줍니다. 이미지가 컨텍스트를 인식하지 않는 방식으로 합성되는 변형 CAMERA 데이터셋도 만들어서 평가를 진행했다고 합니다. B로 표시된 부분을 의미합니다.
7. Conclusion
해당 논문을 요약하면 입력 RGB 영상으로부터 물체에 대한 instance mask, class label을 찾고 depth 정보를 추가하는 branch와 NOCS map을 만드는 brach로부터 3D detection(P_{m}과 P_{n}에 대한 pose fitting)을 수행하고 이를 토대로 6D pose와 size estimation하는 논문이었습니다.
6D Pose estimation을 위한 Category-level에서의 문제를 해결하는 방법을 알아봤습니다. 저희의 연구 목표는 기존의 CAD 모델이 있어야 수행가능 했던 문제를 해결하는 것이 아닌, unseen object로 문제를 풀어가야 한다고 생각을 합니다. 이번 논문을 읽으면서 생각했던 문제를 해결하기 위한 feasibility를 알 수 있었던 논문이었던 것 같습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
Fig2에 “동일한 카테고리에서 오브젝트의 중심과 방향에 대해서 정렬한다”고 말씀해주셨는데
정렬을 하는 이유가 정확하게 무엇인가요 .. ? 오브젝트의 CAD 모델의 shape collection을 얻기 위한 처리 과정이라고 생각하는데 정확하게 와닿지 않아서 질문 드립니다. 그리고 중심과 방향은 각 카테고리마다 정해져 있는것인가요 ? 같은 카메라 카테고리에 속해있는 오브젝트라고 하더라도 중심 좌표는 다를 거라고 생각이 드는데 여기서 중심과 방향이라는 것은 어떤 기준으로 정해지는 지 궁금합니다.
안녕하세요, 손건화 연구원님
논문에는 다루지 않는 내용이라 생각을 해보면, 다양한 CAD 모델을 학습해서 평가를 진행할 때 unseen object에 강인하도록 동작하게 하려는 일반화 작업으로 저는 이해를 했습니다. 중심과 방향에 대해서는 기하학적 방법론으로 중심좌표나 방향을 구할 수 있을 것 같고, 또한 중심좌표에 대해서는 [0, 1]의 범위로 정규화를 한다면 중심의 차이가 미소할 것이므로 중심에 대해 정렬을 할 수 있고 회전 같은 경우는 어떤 기준점이 있을 것 같습니다. 기준점을 중심으로 어느정도의 회전을 해야 하는지 학습을 통해 파라미터를 추정하는 것으로 추측합니다.
감사합니다.
양희진 연구원님 좋은 리뷰 감사합니다.
해당 논문에서 NOCS를 생성할 때, ShapeNetCore 데이터를 이용하였다고 하셨는데, 이 데이터들의 경우 서로 다른 외관을 가진 동일 class들을 어떻게 align을 맞추었는 지 궁금합니다.해당 데이터셋이 합성 데이터라 기본적으로 align이 맞춰진것으로 보아야하나요??
또한, related work에서 Category-level 4D pose Estimation에 “이러한(대칭성을 고려하지 않는 경우) 문제를 해결하기 위해 중력방향을 가정하지 않고도 6D pose와 스케일에 대한 예측을 수행하도록 설계를 했다고 합니다”라고 하셨는데, 이 부분은 object symmetry에서 설명하신, |θ|회 회전을 통해 대칭적인 객체의 rotation을 고려하셨다고 하셨는데, 이외의 다른 축으로의 회전은 고려하지 못하는 것인지 궁금합니다.
안녕하세요, 이승현 연구원님
Q. 해당 논문에서 NOCS를 생성할 때, ShapeNetCore 데이터를 이용하였다고 하셨는데, 이 데이터들의 경우 서로 다른 외관을 가진 동일 class들을 어떻게 align을 맞추었는 지 궁금합니다.해당 데이터셋이 합성 데이터라 기본적으로 align이 맞춰진것으로 보아야하나요??
A. 합성 데이터라 기본적으로 맞춰진 것은 아니라고 생각합니다. 제가 이해한 바로는 여러가지의 CAD 모델들의 shape collection을 통해 [0, 1]로 normalization을 수행하게 되는데 물체의 크기는 다르지만 정규화를 통해 어느정도의 align이 맞추어졌다고 이해를 했습니다.
Q. 또한, related work에서 Category-level 4D pose Estimation에 “이러한(대칭성을 고려하지 않는 경우) 문제를 해결하기 위해 중력방향을 가정하지 않고도 6D pose와 스케일에 대한 예측을 수행하도록 설계를 했다고 합니다”라고 하셨는데, 이 부분은 object symmetry에서 설명하신, |θ|회 회전을 통해 대칭적인 객체의 rotation을 고려하셨다고 하셨는데, 이외의 다른 축으로의 회전은 고려하지 못하는 것인지 궁금합니다.
A. 회전에 대한 질문은 related work에서 말하는 4 DoF에서의 회전에 대한 문제점을 말씀하시는 것 같습니다. 저자는 한 축으로의 회전을 고려하는 것이 아닌 pitch, yaw, roll과 같이 저희가 아는 6DoF로 대칭성 문제, 스케일에 대한 문제를 해결한 것으로 알고 있습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
category-level에서의 pose estimation에서는 작은 물체의 경우에는 pose 의 변화가 가서 큰 물체보다 pose를 추정하기 어렵다고 하셨는데 pose에 변화가 간다는게 무슨의미인가요 ?
또, 본 논문이 CAD를 사용하지 않고 6d pose estimation을 수행하겠다..는 것으로 introduction에서 이해했었는데, normalized object coordinate space 설명해주신 부분을 보면 각 카테고리에 대해 알려진 오브젝트 CAD모델의 shape collection이 주어지면 , 이라고 하셔서 헷갈려서 질문드립니다. 여기 CAD모델의 shape collection을 사용하는 것은 위에서 언급해온 CAD모델을 사용하는 것과는… 다른 것인가요 ?
또 NOCS설명 부분에서 합성 오브젝트는 일반적으로 사용하는 ShapeNetCore로부터 학습을 하셨다고 했는데, 이 합성 오브젝트가 NOCS 공간 내에 object를 위치하는데 사용하는 것인가요 ? 그럼 이 합성 데이터셋은 CAD 모델의 shape collection과 동일한 것인가요 ?
마지막으로, depth map을 사용하여 정규화된 공간에 lifting하여 이상값을 제거하고 정렬하여 6d pose, size를 예측할 수 있다고 하셨는데 이상값을 정렬을 왜 하는 건가요 ? 이상값이 pose, size를 추정하는데 사용되나요 ? ?
정말 마지막으로, NOCS Map head구조가 Mask R-CNN에 3개의 head를 추가한 것으로 보이는데, 주황 초록의 y z coordinate를 예측하는 head부분이 어떻게 동작하는지 모르겠습니다. x와 같이 병렬적으로 동작하는 것인가요 ?
감사합니다. !!!
안녕하세요, 정윤서 연구원님
Q. category-level에서의 pose estimation에서는 작은 물체의 경우에는 pose 의 변화가 가서 큰 물체보다 pose를 추정하기 어렵다고 하셨는데 pose에 변화가 간다는게 무슨의미인가요 ?
A. 변화가 크다라고 적어야 하는데 오탈자가 있어서 혼동이 있으셨겠네요. 덕분에 글 수정하였습니다.
Q. 또, 본 논문이 CAD를 사용하지 않고 6d pose estimation을 수행하겠다..는 것으로 introduction에서 이해했었는데, normalized object coordinate space 설명해주신 부분을 보면 각 카테고리에 대해 알려진 오브젝트 CAD모델의 shape collection이 주어지면 , 이라고 하셔서 헷갈려서 질문드립니다. 여기 CAD모델의 shape collection을 사용하는 것은 위에서 언급해온 CAD모델을 사용하는 것과는… 다른 것인가요 ?
A. 엄밀히 말하면 CAD 모델을 전혀 안 쓴다고 보기에는 어려운 게 맞습니다. 하지만, 저희가 지금까지 리뷰한 논문들은 이미지 내에 존재하는 물체가 완전히 fitting된 CAD 모델이 있어야만 학습이 가능한 논문들을 다루었습니다. 예를 들어 LINEMOD에 있는 cat이라는 클래스에 대해서 이미지 내에 cat 클래스가 있고 해당 cat과 정확하게 맞는 CAD 모델이 있고 그 상태에서 Direct/Indirect method로 나누어져 학습 및 평가를 진행하였다고 이해하시면 되겠습니다. 해당 논문과 같은 경우는 처음 보는 즉, unseen object인 55개의 카테고리에 해당하는 51300개 정도의 CAD 모델들을 학습을 통해 평가도 unseen object로 하는 것으로 알고 있습니다.
Q. 또 NOCS설명 부분에서 합성 오브젝트는 일반적으로 사용하는 ShapeNetCore로부터 학습을 하셨다고 했는데, 이 합성 오브젝트가 NOCS 공간 내에 object를 위치하는데 사용하는 것인가요 ? 그럼 이 합성 데이터셋은 CAD 모델의 shape collection과 동일한 것인가요 ?
A. 질문의 대답은 둘 다 맞습니다. 좀 더 말을 정리하자면 shape collection이 주어진다는 것은 특정 카테고리에 대한 CAD 모델이 주어진다는 것이고 NOCS 내에 해당 물체에 대해 align을 맞추는 것에 사용하는 것이라고 이해하시면 될 것 같습니다.
Q. 정말 마지막으로, NOCS Map head구조가 Mask R-CNN에 3개의 head를 추가한 것으로 보이는데, 주황 초록의 y z coordinate를 예측하는 head부분이 어떻게 동작하는지 모르겠습니다. x와 같이 병렬적으로 동작하는 것인가요 ?
A. 제가 코드를 직접 뜯어보지는 않았지만, 정윤서 연구원님 말씀대로 병렬적으로 동작하고 맨 마지막에 concat을 통해 NOCS map을 만드는 것으로 추측됩니다.
감사합니다.
좋은 리뷰 감사합니다.
우선 기존의 CAD model을 필요로 했던 것과 다르게 unseen object에 대해서도 해결할 수 있도록 하는 것이 큰 contribution같은데, rgb기반으로 3d공간에서 NOCS를 정의할 때 shapenetcore데이터셋으로 합성 오브젝트를 만들었다고 하였습니다. 저는 이걸 codebook처럼 사전에 정보를 가지고있고 NOCS에서 얻은 정보와 합성 오브젝트정보를 비교하여 align을 맞추고 scale이나 위치까지 알아낸다고 이해했는데 맞나요? 만약 그렇다면 unseen data를 처리하기위해 사전에 많은 합성오브젝트 정보를 가지고있어야하기 때문에 unseen data를 처리한다고하기에 의미가 떨어진다는 생각이 들어서 질문드립니다.
감사합니다.
안녕하세요, 김도경 연구원님
김도경 연구원님 말씀대로 codebook을 가지고 clustering을 통해 align을 맞추는 것도 좋은 방법 중 하나라고 생각합니다. 하지만, 해당 논문에서는 codebook을 따로 만들어서 사용한다는 그런 설명보다는 여러 개의 카테고리 내에 속하는 물체를 학습하는데 이때 normalize를 통해 카테고리에 속하는 모든 물체들에 대해 기하학적인 요소를 고려하여 중심좌표와 scale을 먼저 처리하고 방향까지 align을 맞춰줬을 것이라고 이해를 했습니다.
감사합니다.