이런 분들께 이 논문을 추천드립니다.
- 멀티 모달, 특히 비디오를 멀티 모달(영상 + 오디오 + 텍스트)로 이해하는 것에 흥미가 있으신 분
- 뭔가 새로운 걸 보고 싶으신 분
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- Transformer에 대한 이해 (트랜스포머 리뷰)
- BERT, ViT에서 사용되는 [cls] 토큰 이해 (ViT 리뷰)
- Contrastive Learning에 대한 이해 (Metric Learning에 대해 다룬 제 블로그, 혹은 InfoNCE Loss를 다룬 TCA 리뷰)
같이 보면 좋아요.
- ImageBind [CVPR 2023] (리뷰)
유의사항
- 이 리뷰에서는 편의성을 위해 우리가 흔히 접하는 넓은 의미에서의 영상을 비디오(영상 + 오디오), 오디오를 제외한 시각적 정보만을 의미하는 영상을 영상이라 부르겠습니다.
- 즉, { 영상, 소리 } $\in$ 비디오라고 볼 수 있겠습니다.
안녕하세요. 백지오입니다.
열한 번째 X-REVIEW는 많은 분들에게 다소 생소할 주제인 Multi-Modal Video Retrieval 연구를 들고 왔습니다.
아시다시피 저희 팀은 Video to Video Retrieval 연구를 수행하고 있는데요. 이는 비디오에 포함된 오디오는 사용하지 않고 오로지 시각적인 정보, 즉, 영상 만을 사용해 비디오를 검색하는 task입니다. 한편, 이 논문에서 다루는 Multi-modal Video Retrieval은 비디오를 여러가지 모달리티를 활용해 비디오를 검색하고자 합니다.
언젠가 연구 분야를 멀티 모달 쪽으로 확장해보고 싶어, 낯선 분야이지만 정말 열심히 읽어봤습니다. 그럼 리뷰 시작해보겠습니다.
저자들은 HowTo100M이라는 유튜브에서 수집된 영상 데이터를 통해 비디오를 다음 3가지 모달리티로 정의합니다.
- 비디오에 포함된 프레임들의 시각적 정보, 영상 $v$
- 비디오에 포함된 오디오 데이터, 오디오 $a$
- 비디오에 자동 음성 인식을 활용하여 생성한 캡션 자막(텍스트) $t$
저자들은 이러한 다양한 모달리티를 통해 비디오에 대한 유의미한 임베딩을 학습하여, zero-shot retrieval, action recognition 등에 활용하고자 합니다. 이를 위해 각 모달리티들의 정보를 잘 fusion하여, 하나의 embedding space로 projection하는 트랜스포머 모델를 제안합니다.
이 multi-modal fusion transformer $f$는 한 개, 혹은 한 개 이상의 모달리티로부터 추출된 토큰을 입력받아 임베딩 벡터를 반환합니다. 이때, 한 개의 영상에서 얻어진 모달리티 $\{v, a, t\} \in \mathcal{V}$들에 대한 임베딩들이 서로 유사하도록 하고자 합니다. $f(v) \approx f(a) \approx f(v, a) \approx f(v, t)$
저자들은 이런 multi-modal fusion transformer를 설계하고 학습하는 과정에서 다음 요소들을 고려했다고 합니다.
- 각 모달이 다른 모달과 함께 사용되며, 이때 서로 간의 관계성을 학습할 수 있어야 함
- 모달리티의 조합이나 종류에 관계없이 사용 가능해야 함
- 모달리티에 따라 입력의 길이가 달라지더라도 어떤 길이의 입력이던 처리할 수 있어야 함
저자이 주장하는 논문의 contribution은 다음과 같습니다.
- 주어지는 모달리티의 조합이나 길이와 무관하게 모달 간의 정보와 상관관계를 얻을 수 있는 multi-modal transformer 제안
- 입력 모달리티 간의 모든 조합을 고려하는 combinatorial contrastive loss 제안
- 이러한 방법을 사용하여, multi-modal embedding space learning에 확연한 성능 향상을 보임
Related Works
처음 접하는 분야인 만큼, related works를 이해하기가 어려웠는데, 최대한 쉽게 정리해보겠습니다.
멀티 모달 학습
멀티 모달 학습에 대한 관심은 이전부터 있었으며, 특히 비디오는 영상과 오디오를 함께 얻을 수 있는 대표적인 데이터이지만, 이를 annotation하는 것은 어마어마한 비용이 발생하는 일이었습니다. 이러한 상황에서, HowTo100M 데이터셋이 등장하며 분야에 큰 기여를 하였지만, 이 데이터셋의 text 데이터는 자동 음성 인식으로 생성되어 노이즈가 많다는 단점이 있었습니다.
그럼에도 불구하고 꾸준한 연구가 진행되었는데, Amrani et. al., 2020은 multi-modal density estimation을 통한 noise estimation을 수행하였으며, Miech et al., 2020은 multiple instance learning과 noise-contrastive estimation을 결합하여 MIL-NCE라 하는 방법론을 제안하였습니다. (이 방법은 citation이 500회에 달하며 제 최근 리뷰 중, ImageBind에도 비교 모델로 등장합니다.)
이러한 연구들이 영상과 오디오 두 가지 모달 만을 사용한 반면, 어떤 연구들은 영상과 오디오, 나아가 텍스트까지 활용하고자 하였습니다. Aytar et al., 2017은 이미지-텍스트, 이미지-오디오 쌍을 각각 이용하여 텍스트와 오디오 모달리티를 연결하고자 하였고, Alayrac et al., 2020은 각 모달리티가 다른 임베딩 공간을 갖는 Multi-modal Versatile Network를 제안했으며, Rouditchenko et al., 2021은 세 가지 모달리티를 하나의 공통 공간(joint space)에 임베딩하는 AVLnet 방법을 제안했습니다.
트랜스포머를 이용한 멀티 모달 학습
한편, 트랜스포머의 셀프 어텐션을 통해 다양한 모달리티의 정보를 합치고자 하는 연구도 많이 진행되었는데요.
초기 연구에서는 셀프 어텐션을 통해 비디오의 영상과 오디오의 관계를 학습하고자 한 반면, Bain et al., 2021은 영상의 공간적 정보만큼이나 시간적 정보를 잘 잡아낼 수 있는 비디오 백본에 집중하였는데 이를 위해 영상과 텍스트를 별도의 트랜스포머 백본에 입력하고 선형 계층을 하나 더 쌓아 임베딩을 수행했습니다. 한편 Nagrani et al. 2021이 제안한 multi-modal bottleneck 트랜스포머는 효과적인 오디오-영상 퓨전을 지도 학습 방법으로 수행할 수 있도록 설계되었습니다.
트랜스포머를 이용하면서 세 가지 모달리티를 모두 사용하는 Akbari et al., 2021은 본 논문의 방법과 가장 유사한 방법이라 할 수 있는데요. 이 방법은 영상, 오디오, 텍스트 세 모달리티에 어텐션을 공유하는 하나의 백본 트랜스포머를 사용합니다. 학습 단계에서, 모델은 먼저 영상-오디오의 matching을 계산하고, 그다음 영상-텍스트를 계산하여 pairwise 방식으로 모달들을 fusion 합니다.
사전학습된 vision-text 모델을 사용하여 video retrieval 하는 연구도 진행된 바 있는데, Lou et al., 2021은 사전학습된 CLIP 모델을 백본으로 사용한 트랜스포머 기반의 유사도 인코더 CLIP4Clip을 만들어 좋은 결과를 보였습니다.
저자들은 이러한 연구들 중 많은 연구가 재현하기 어려운 백본을 사용하거나 아예 백본 신경망의 사전학습에 비공개 데이터셋을 사용하여 재현이 어렵기 때문에, 아예 기존 연구들에서 사용한 백본에서 추출된 feature들을 이용해 연구를 수행했다고 합니다. 확실히 Related Work들을 살펴보니, 많은 연구들이 MS나 구글 등 대기업 위주로 수행된 것을 알 수 있었습니다… 마음 아프네요.
Method
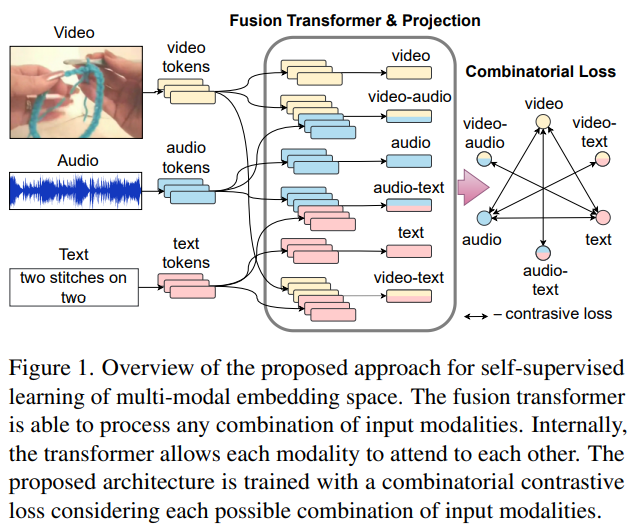
이 논문의 목표는 위 그림에서 Fusion Transformer & Projection으로 나타난, 의미론적으로 유사한 하나, 혹은 여러 개의 모달리티를 joint embedding space에 서로 가깝게 projection하는 함수를 생성하는 것 입니다.
예를 들어, 어떤 영상에 대한 텍스트의 임베딩은 그 영상의 영상-오디오 임베딩과 가까워야 합니다. 우측 그림에서 화살표 형태로 나타난 조합들을 보시면 이해하기 편합니다.
Problem Statement
$N$개의 비디오에 대한 텍스트 – 영상 – 오디오 트리플렛 $\{ (t_i, v_i, a_i) \}^N_{i=1} \in (\mathcal{T} \times \mathcal{V} \times \mathcal{A})^N $이 주어질 때, 텍스트, 영상, 오디오 세 가지 입력을 받아 $d$차원의 임베딩을 생성하는 함수 $f(\cdot, \cdot, \cdot)$를 만들고자 합니다. 예를 들어, $f(t, v)$는 $\mathcal{T} \times \mathcal{V} \rightarrow \mathbb{R}^d$에 해당하는 투영을 수행하며, 텍스트 $t$와 영상 $v$의 joint embedding을 나타냅니다. 모델의 학습 목표는 의미론적으로 유관한 같은 영상에서 출력된 모달리티들로 생성되는 임베딩 $f(t), f(v), f(a), f(t, a), f(t, v), f(v, a)$들의 닷 연산으로 구해지는 코사인 유사도가 최대화되고, 다른 영상과는 최소화되도록 하는 것입니다.
Model Architecture
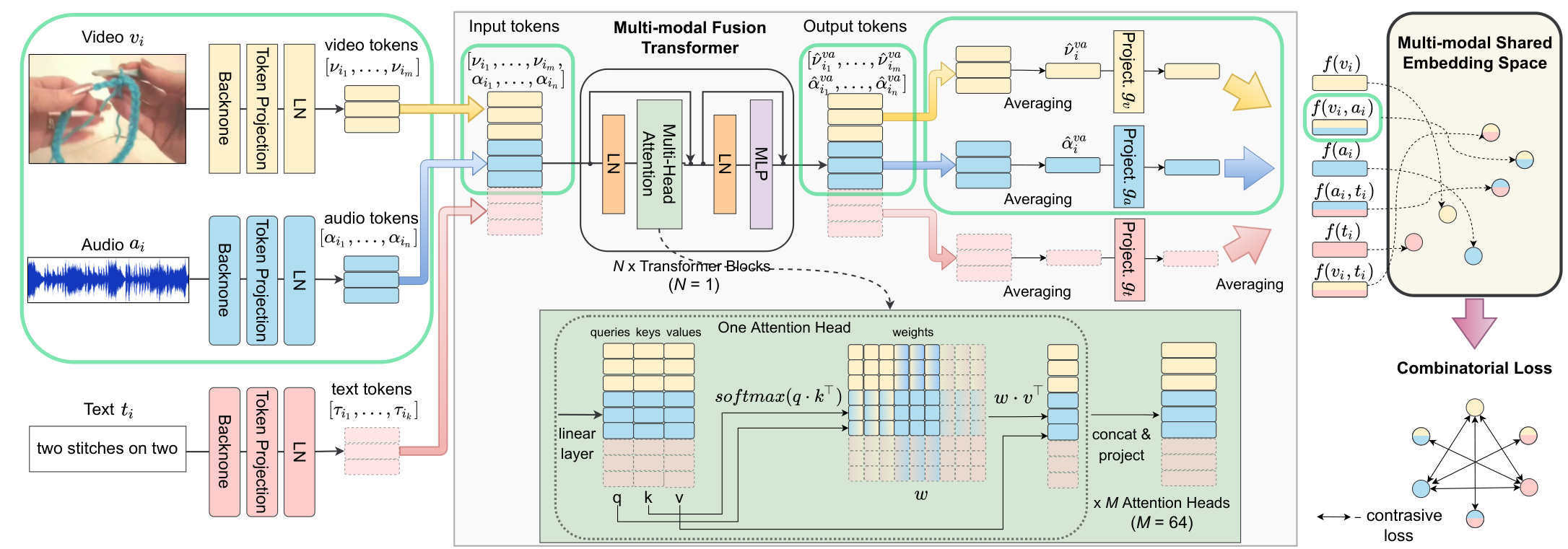
Token Creation
먼저, 각 모달리티에 따른 별도의 백본 신경망을 통해 feature를 추출합니다. 추출된 feature vector를 모달리티 별로 존재하는 projection과 normalization 계층을 통해 token space로 투영합니다. 그 결과, 입력 트리플렛 $(t_i, v_i, a_i)$를 얻을 수 있으며, 이는 각 모달리티 별로 $[\mathcal{t}_{i1}, \cdots, \mathcal{t}_{ik}]$의 텍스트 $t_i$에 대한 토큰, $[\mathcal{v}_{i1}, \cdots , \mathcal{v}_{im}]$의 영상 $v_i$에 대한 토큰, 그리고 $[\mathcal{a}_{i1}, \cdots , \mathcal{a}_{in}]$의 음성 $a_i$에 대한 토큰으로 구성됩니다. 토큰의 개수가 다르더라도 배치 처리를 하기 위해, 남는 토큰들은 마스킹 처리하였으며, 효율을 위해 학습은 고정된 길이의 영상 클립에서 수행하였다고 합니다. 그러나 이는 모델의 학습 효율을 위한 조치로, 모델은 가변적인 길이의 입력을 다룰 수 있습니다.
No Positional Embeddings
제가 가장 의외였던 부분입니다. 서로 다른 모달리티에서 왔으며, 서로 다른 위치를 갖는 토큰들을 한 트랜스포머로 입력하며 Positional Embedding을 전혀 수행하지 않습니다. 저자들은 그 이유를 세 가지 제시합니다.
먼저 각 토큰의 출처 모달리티를 나타낼 type embedding의 경우, 이미 각 토큰이 모달리티 별로 다른 백본에서 생성되었기 때문에, 굳이 모달리티에 대한 임베딩을 수행하지 않아도 feature 자체에 각 모달리티 백본에 의한 흔적(fingerprints)이 있기 때문에 수행할 필요가 없습니다. 두 번째로, 토큰의 위치 정보는 자연어와 같이 순차적으로 구성되는 데이터에서는 좋은 영향이 있으나, 멀티 모달 비디오 학습 관점에서 clip들은 랜덤 하게 샘플링되며 이때 shot boundary나 speech pause 등은 고려되지 않기 때문에, 학습 과정에서 clip 내부의 일관된 시간적 패턴을 배울 수 없다고 본다고 합니다. 때문에 positional embedding이 오히려 학습 과정에서 noise가 되지 않도록 아예 사용하지 않았다고 하네요. 참 bold한 생각인 것 같습니다. 또한, positional embedding이 없기 때문에, 추론 과정에서 학습 시의 positional embedding 크기에 의해 입력 길이가 제한되지 않는 장점이 있다고 하네요.
Multi-modal Fusion Transformer
앞서 얻은 각 모달리티의 토큰들을 입력받아 하나의 joint embedding space로 투영하는 $f$, 바로 Multi-modal Fusion Transformer입니다. 저자들은 이 모델을 modality agnostic하다고 합니다. agnostic은 불가지론적인이라는 뜻으로, 원래는 무신론자 중, 신이 있는지 없는지 확신이 없는 무신론자를 불가지론적인 무신론자라 한다고 합니다.
즉, modality agnostic 하다는 것은, 비디오에 포함된 세 가지 모달리티 $(t, v, a)$ 중 어떤 모달리티가 입력되던 입력되지 않던, embedding을 수행할 수 있다는 뜻입니다.
복잡하게 느껴지는 개념에 비해, 모델의 구조는 단순히 멀티 헤드 셀프 어텐션과 MLP, 두 개의 LayerNorm(LN) 계층으로 구성된 일반적인 트랜스포머 블록 구조입니다. 저자는 이러한 단순한 구조를 사용하는 이유에 대해, 이 모델과 다른 모델과의 차이점이 모델 구조에서 오는 것이 아니라, 학습 과정에서 오기 때문이라고 합니다. 역시 상당히 자신감 넘치는 모습입니다.
모델은 여러 모달리티의 combinational input을 입력받습니다. 입력된 $(t, v, a)$ 토큰들은 가능한 모든 모달리티 조합에 대하여 학습하여, 모든 모달리티가 서로 잘 의존성을 파악하며 임베딩을 생성할 수 있도록 한다고 합니다. 이때, $(t, v)$ 조합의 입력으로 생성되는 텍스트와 영상의 fused representation은 $tv$로 나타냅니다. 만약 모달리티가 3개 이상으로 늘어난다면 이러한 조합도 늘어나겠지만, 이때는 random modality dropout을 통해 학습을 진행할 수 있다고 하네요.
(굳이 모달리티를 드랍아웃하는 이유는 모달리티의 수가 늘어나면 그만큼 조합의 갯수도 늘어나기 때문인 듯 합니다.)
Fusion transformer가 modality agnostic, 즉 모달리티에 관계없이 동작하기를 원하기 때문에 각 학습 이터레이션에서 다음과 같은 모든 가능한 6가지 조합 representation을 생성합니다. ($i: t_i, v_i, a_i, t_iv_i, v_ia_i, t_ia_i$) 각 representation을 얻기 위해, 토큰들의 joint list를 생성합니다. $v_ia_i: [v_{i1}, \cdots , v_{im}, a_{i1}, \cdots , a_{in}]$과 같은 형식이다. 이 리스트는 트랜스포머를 거쳐 다음과 같은 출력 토큰들로 변환되는데요. $[\hat {v}_{i1}^{va}, \cdots , \hat{v}^{va}_{im}, \hat{a}^{va}_{i1}, \cdots , \hat{a}^{va}_{in}]$ 이때 어텐션을 거친 각 출력 토큰은 다른 토큰으로부터 온 정보를 포함하고 있습니다.
Projection to Shared Embedding Space
앞서 얻어진 출력 토큰으로부터 최종적인 임베딩을 생성할 차례입니다. 각 학습 샘플에서, 여섯 개의 출력 토큰 집합을 얻으므로, 자연히 여섯 개의 임베딩들을 얻게 되는데요. 먼저 앞선 예에서 $v_ia_i$와 같은 입력에 대해 얻어진 출력 토큰 $[\hat{v}_{i1}^{va}, \cdots , \hat{v}^{va}_{im}, \hat{a}^{va}_{i1}, \cdots , \hat{a}^{va}_{in}]$을 모달리티 별로 $[\hat{v}_{i1}^{va}, \cdots , \hat{v}^{va}_{im}], [ \hat{a}^{va}_{i1}, \cdots , \hat{a}^{va}_{in}]$와 같이 나눈다. 그다음, 이들을 각각 평균하여 모달리티 별 vector representation $\hat{v}^{va}_i = \sum^m_{j=1} \hat{v}^{va}_{ij}, \hat{a}^{va}_i = \sum^n_{j=1} \hat{a}^{va}_{ij}$를 얻습니다. 그러나 여전히 이러한 모달리티들이 서로 다른 representation을 갖기 때문에, 이들을 하나의 embedding space로 투영해 주는 함수 $g_t, g_v, g_a$를 만든다. 이 함수들로 투영을 한 후, normalization을 수행해 최종적인 임베딩 벡터를 얻는다.
$$ f(v_i, a_i) = \text{norm}(\text{norm}(g_v(\hat{v}_i^{va})) + \text{norm}(g_a(\hat{a}^{va}_i)))$$
normalization을 거치며 각 벡터의 norm이 동일해지기 때문에, 여러 embedding을 동일한 비율로 합쳐줄 수 있습니다. 또한, 최종적으로 normalization을 한 번 더 수행하여 video representation들을 dot 연산으로 쉽게 코사인 유사도를 구할 수 있게 됩니다.
Combinatorial Loss
Contrastive Loss를 사용하여 의미론적으로 유사한 입력들이 가까이 임베딩 되도록 학습시킵니다. $(t, v)$에 대한 $L_{t\_v}$, $(t, a)$에 대한 $L_{t\_a}$, $(v, a)$에 대한 $L_{v\_a}$ 세 개의 single-modality contrastive loss들을 통해 학습하는 다른 방법들과 달리, 저자들은 토큰들이 모달리티 간에 정보를 교환하도록 강제하기 위해 추가적인 contrastive loss들을 도입합니다. $(t, va)$간에 사용되는 $L_{t\_va}$, $(v, ta)$간의 $L_{v\_ta}$, $(a, tv)$에 대응되는 $L_{a\_tv}$로, 최종적인 combinatorial loss는 아래와 같습니다.
$$L= \lambda_{t\_v}L_{t\_v} + \lambda_{v\_a}L_{v\_a} + \lambda_{t\_a}L_{t\_a} + \lambda_{t\_va}L_{t\_va}+\lambda_{v\_ta}L_{v\_ta}+\lambda_{a\_tv}L_{a\_tv}$$
$\lambda$는 손실함수의 가중치 하이퍼 파라미터이며, $L$은 contrastive Loss로 아래 식과 같이 $\tau$의 temperature와 배치 크기 $B$를 쓰는 Noise Contrastive Estimation을 사용합니다. 인용수 5600의 CPC라는 방법론에서 가져왔네요.
$$NCE(x, y) = -\log(\frac{\exp(x^Ty/\tau)}{\sum^B_{i=1} \exp(x_i^Ty_i / \tau)})$$
Experiments
Backbones. 저자들은 visual backbone으로 ImageNet에서 사전학습한 ResNet-152를 사용하였으며, 초당 하나의 (2048차원 벡터인) 2D feature를 추출하였습니다. 또한, Kinetics에서 사전학습한 ResNeXt에서 초당 1.5개의 (2048차원의) 3D feature를 추출하였습니다. 그다음, 2D feature를 nearest neighbor 기반으로 upsample 하여, 3D feature와 같은 수의 feature를 갖도록 하고 concatenate 하여 4096차원의 벡터를 얻었습니다. 텍스트 백본으로는 GoogleNews에서 사전학습한 Word2 vec 모델로 단어 당 300차원의 임베딩을 얻었으며, 이 백본들은 학습 중에는 freeze 하였다. 오디오 백본은 residual layer가 있는 학습 가능한 CNN을 사용하였으며, 마지막 두 개의 residual block에서 초당 1.5개의 4096차원 feature를 추출하였습니다.
Data Sampling. 저자들은 배치 당 224개의 영상에서 랜덤 하게 8초의 clip들을 추출하여 사용하였습니다. 만약 clip이 내레이션을 포함하고 있다면, ASR time stamp를 통해 이미지를 분할하였습니다. (95%의 영상은 나레이션이 포함되어 있었다고 하네요.) HowTo100M 데이터셋의 매우 높은 text-audio correlation을 분리하여 텍스트가 곧 오디오 나레이션으로 학습되는 것을 방지하기 위해, 저자들은 오디오 클립을 랜덤하게 4초씩 shift 시켰다고 합니다.
Projections. feature들을 common token space로 투영할 때는 gated linear projection을 사용하며, 저자들은 common token space의 차원을 4096, shared embedding space의 차원을 6144로 설정하였습니다.
Transformer architecture. 멀티 모달 퓨전 트랜스포머는 hidden size 4096, n_head=64, MLP 크기 4096을 적용하였습니다.
Loss computation. NCE의 temperature는 0.05를 사용하였고, 각 벡터의 유사도는 normalization 후 dot 연산으로 계산하였습니다. 모든 비디오 클립이 세 가지 모달리티를 가지고 있지는 않기 때문에, 존재하는 모달에 대해서만 NCE를 계산하였고, 손실 함수의 가중치는 text-visual loss에만 1로 큰 값을 주고 나머지는 0.1을 주었습니다.
Optimization. 모델은 Adam optimizer에 learning rate 5e-5, decay 0.9로 15 에포크 학습되었다고 합니다.
Datasets, Tasks, and Metrics
사전학습 데이터셋. 저자들은 100만 개의 Howto 비디오들과 자동 생성된 나레이션 자막으로 구성된 HowTo100M 데이터셋으로 학습을 진행하였는데, 텍스트 내레이션은 때때로 노이즈가 있거나, 영상의 상황을 설명하고 있지 않을 수도 있다고 합니다.
Zero-shot Text-to-video Retrieval. 저자들은 MSR-VTT와 YouCook2 데이터셋을 통해 zero-shot text-to-video retrieval 성능을 측정하였습니다. YouCook2 데이터셋은 요리 강의 영상들과 2~200초의 사람이 어노테이션 한 클립들로 구성되어 있는데, 평가에는 영상의 앞쪽 48초만 사용하였습니다. MSR-VTT 데이터셋은 사람이 어노테이션한 10~30초의 영상 클립들로 구성되는데, 다양한 주제와 자연어로 된 캡션이 제공됩니다. MSR-VTT에서의 평가를 위해, 테스트 클립 천 개를 사용하였고, YouCook2에서는 3350개의 validation 클립을 사용했습니다. 검색은 텍스트 쿼리 $t$와 융합된 $va$ representation을 통해 수행되었으며, 평가지표는 R@1, R@5, R@10, 그리고 median rank (MedR)를 사용하였습니다.
Text-to-video Retrieval after Fine-tuning. 저자들은 각 데이터셋에서 파인튜닝을 수행한 후의 성능도 확인하였습니다. 파인튜닝은 YouCook의 경우 9586개의 학습 클립에서 진행되었고, MSR-VTT에서는 오디오가 포함된 6783개의 영상에서 수행되었습니다.
Zero-shot Step Action Localization. 저자들은 CrossTask, Mining YouTube 두 개의 데이터셋에서 Zero-shot Step Action Localization을 평가했습니다. CrossTask 데이터셋은 18 개의 task에 대한 2만 7천 개의 강의 영상으로 구성되며, Mining YouTube 데이터셋은 각 action step으로 정렬된 250개의 테스트 요리 영상이 제공됩니다. step localization을 위해, 저자들은 sliding window를 적용하여 각 비디오 세그먼트의 $va$ representation과 task의 각 step(단계)의 이름 간의 유사도를 구하였습니다.
Comparison with SOTA
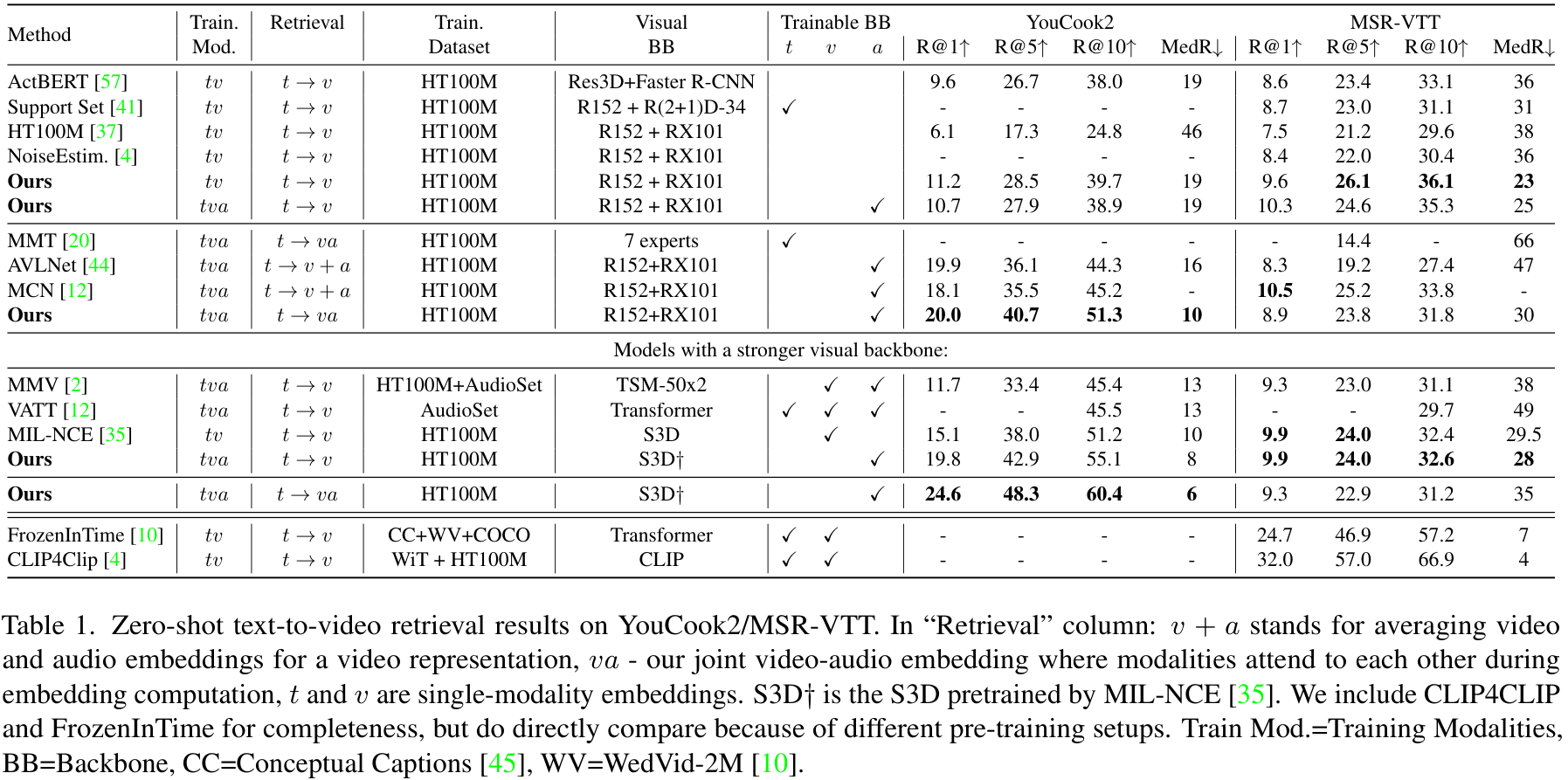
Zero-shot Text-to-video Retrieval. 먼저, 모델이 처음 보는 YouCook2, MSR-VTT 데이터셋에서 text to video retrieval을 수행한 결과입니다. 저자들의 방법이 두 데이터셋 모두에서 SOTA를 달성하였습니다. 특히, 동일한 visual, text, audio 백본을 사용하는 AVLnet과 MCN를 YouCook2에서 큰 차이로 앞섰습니다. 한편, MSR-VTT에서는 영상과 오디오 모달리티를 모두 사용하는 것보다 오히려 영상 모달리티만 사용한 결과가 성능이 더 좋았다고 합니다. 저자들은 이러한 문제가 학습을 진행한 HowTo100M과 MSR-VTT의 도메인 차이로 인한 것으로 보았는데, HowTo100M은 대부분 오디오가 대화로 구성되며, 텍스트는 대화의 대본과 같은 형태인 반면, MSR-VTT는 오디오가 텍스트 표현과 다른 편입니다. 이러한 가정은 MSR-VTT에서 가장 좋은 성능을 보이는 모델이 FrozenInTime이나 CLIP4Clip이 학습 과정에서 HowTo100M을 전혀 사용하지 않는 것에서 더욱 설득력을 보인다고 하네요. 또한, 저자들은 모델의 백본을 더욱 좋은 HowTo100M에서 MIL-NCE에 의해 학습된 S3D와 같이 더 좋은 백본으로 바꿀 경우, YouCook2에서 한층 더 높은 성능을 달성할 수 있었다고 합니다.
Text-to-video Retrieval after Fine-tuning.
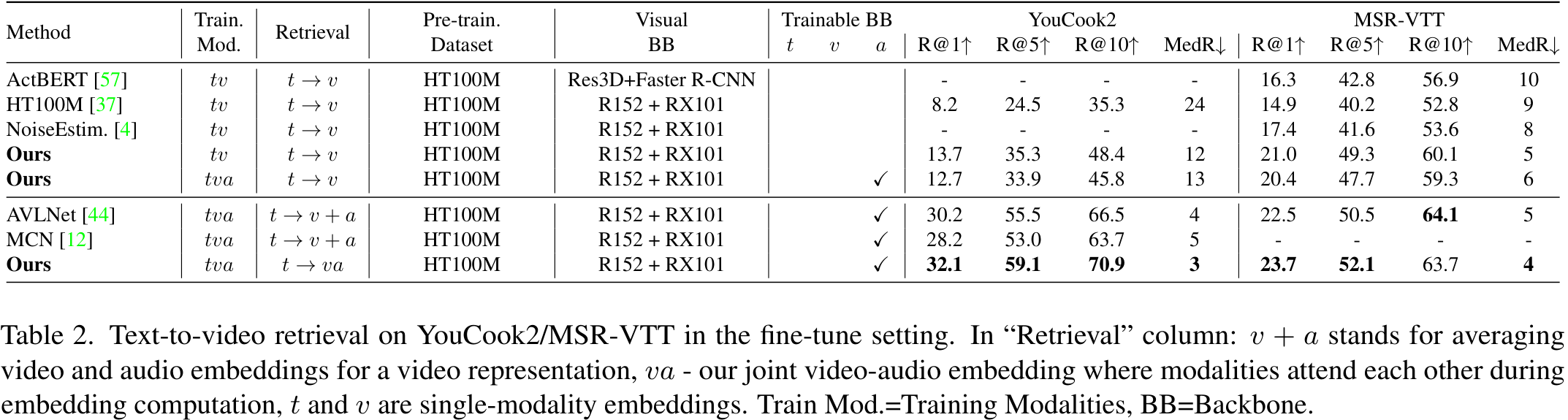
fine-tuning을 거친 후의 성능 또한 비교하였습니다. 역시 저자들의 모델이 가장 좋은 성능을 보였으며, 특히 앞선 실험에서 pretrain 데이터와 오디오-텍스트 도메인 불일치로 성능이 안 좋은 것으로 의심하였던 MSR-VTT에서의 성능이 확실하게 개선되었습니다. 다만, 본 논문과 같은 embedding 관련 논문의 경우 fine-tuning을 진행한다는 것이 말이 안되는 것이라… 일반화 성능이 아쉬운 것 같습니다. 그러나 이러한 실험을 통해 앞서 도메인 불일치의 가능성을 더 잘 드러냈으니 좋은 실험인 것 같습니다.
Zero-shot Step Action Localization.
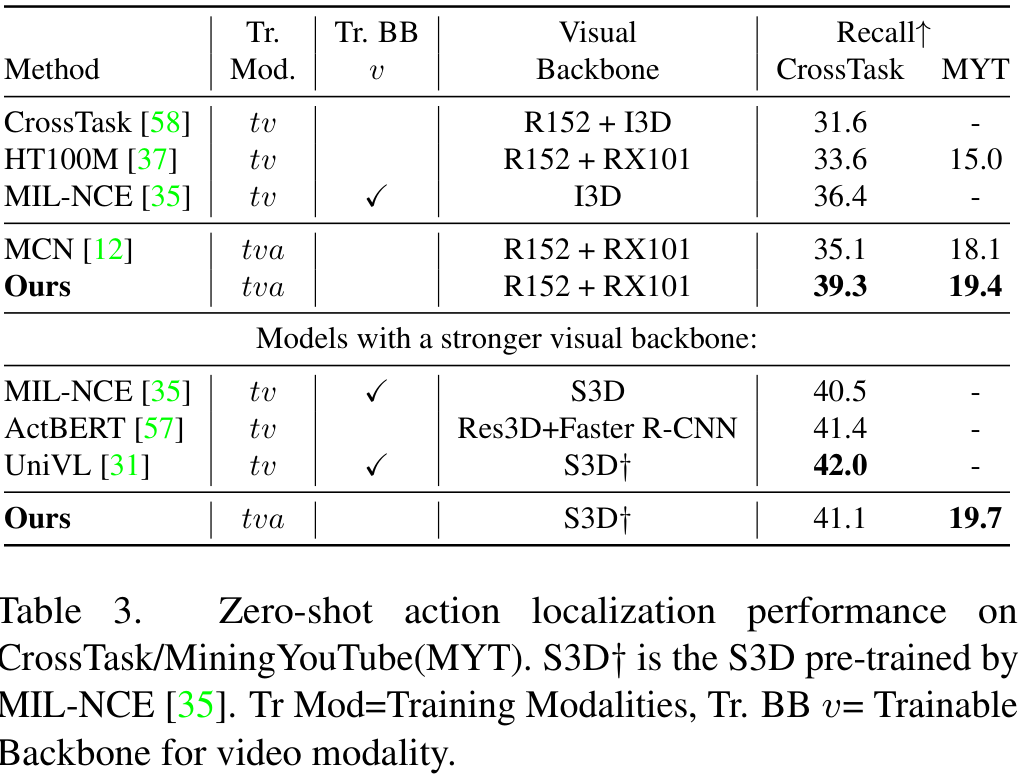
Step Action Localization에서도 제안한 모델은 좋은 성능을 보였습니다. 특히, 앞선 첫 번째 실험과 마찬가지로 강력한 S3D 백본을 사용할 경우 학습 가능한 백본을 사용하는 MIL-NCE나 Faster R-CNN 기반의 추가 region based 백본을 사용하는 ActBERT보다도 높은 성능을 보였습니다.
Ablation Studies

먼저 저자들은 fusion 과정의 각 요소들에 대한 비교를 진행했는데요. 표 4. 의 1) no transformers는 제안한 모델에서 트랜스포머와 pairwise contrastive loss들이 없는 버전이며, 2) single modality transformer는 세 개의 모달리티 별 트랜스포머 계층을 통해 각각의 투영 함수를 학습하는 버전입니다. 3) fusion transformer는 제안된 모델과 같이 modality agnostic 한 transformer를 사용하지만, fused modality component 없이 세 개의 모달리티에 대한 loss로만 학습된 버전이고, 4) fusion transformer + comb. loss는 제안된 방법과 동일한 방법입니다.
Retrieval 방법에 따른 차이는, 각 모달리티의 representation을 따로 구하여 더한 방법 $(v+a)$과, 두 모달리티의 fused representation을 한 번에 구한 방법 $(va)$을 비교하였습니다.
비교 결과, 각 모달리티 별로 트랜스포머를 추가해주기만 해도 성능이 상당히 향상되며, loss function, fusion 방법과 모델 구조가 성능에 영향을 주는 것을 확인하였습니다. token fusion은 일반적으로 성능을 향상하였으며, fusion transformer만 사용할 경우 성능이 각 모달리티별 transformer를 사용하는 것보다 하락하였으나, combinatorial loss를 통해 transformer가 각 모달리티에서 온 토큰들을 합치는 방법을 학습하도록 하자 다른 방법들을 앞서는 성능을 보였습니다.
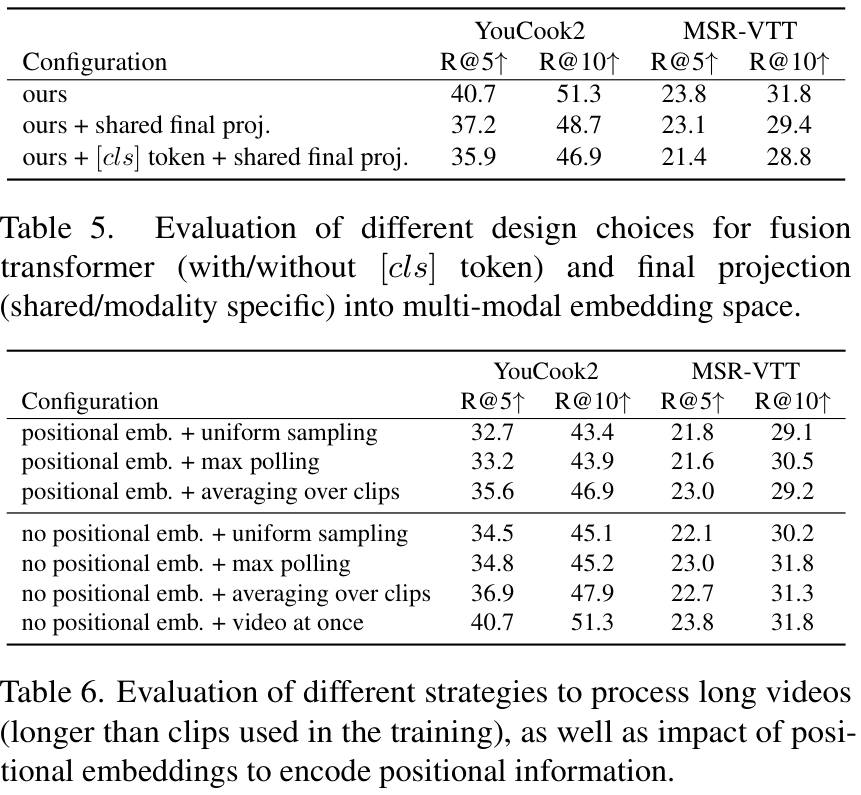
저자들은 [cls] 토큰을 이용해 출력을 처리해 주는 것이 어떠한 영향을 주는지 실험하였다. BERT와 유사한 방식으로 입출력에 추가적인 [cls] 토큰을 적용하여, 출력 시 [cls] 토큰에 각 모달리티의 fusion 된 representation이 나오도록 하는 것이죠. 그러나, 표 5. 의 결과처럼 이러한 방법은 성능에 도움이 되지 않았다고 합니다.
다양한 길이의 입력을 받는 것이나 positional embedding에 대한 실험을 진행하였습니다. 표 6. 을 보면, 1) uniform sampling은 백본에서 얻은 초기 local feature들에서 uniform 하게 최대한 많은 토큰을 추출하는 방식이며, 2) max-pooling은 local feature들을 adaptive max-pooling을 통해 고정된 크기의 토큰들을 추출하는 방식입니다. 3) averaging over clips는 긴 클립들을 학습 단계에서 사용하는 작은 클립 크기로 잘라 처리한 후, representation들을 평균하여 축소하는 방식이고, 4) video at once는 모든 feature를 한 번에 처리하는 방식입니다. 앞선 세 가지 방법의 경우, positional embedding을 적용하는 것이 도움이 되는지도 각각 실험해 보았는데요. 이때 embedding은 일반적인 학습 가능한 임베딩을 사용하였습니다. 실험 결과, positional embedding을 사용하는 것은 성능 저하를 일으켰고, 긴 영상의 처리 방법은 긴 클립들을 짧은 클립들로 잘라 평균하거나, 아예 긴 영상도 한번에 처리하는 것이 좋았습니다. 특히, 비디오 전체를 한번에 처리하는 방법이 성능이 가장 좋았다고 합니다.
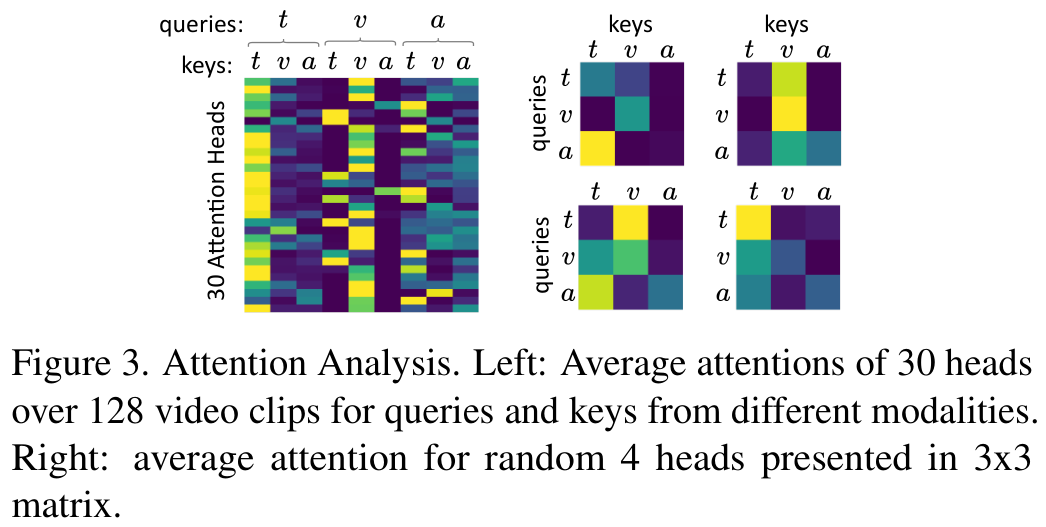
저자들은 어텐션 가중치의 정성적 분석을 수행하였습니다. 그림을 보면 각기 다른 모달리티에서 온 query-key pair의 평균 어텐션 가중치가 나타나 있는데, 일부 어텐션 헤드가 single modality fusion에 강한 어텐션을 보이는 반면, 일부는 다른 모델에 어텐션을 보이고 있음을 알 수 있습니다.
Limitations and Conclusion
이 논문에서, 저자들은 멀티 모달, modality agnostic 한 fusion 트랜스포머를 통하여 비디오에 포함된 영상, 오디오, 텍스트 모달리티 간의 정보를 교환하고 통합된 multi-modal representation으로 만드는 모델을 제안했습니다. 이 모델은 가능한 모달리티들의 조합들에 대한 combinatorial loss로 fusion 트랜스포머가 강건한 multi-modal embedding을 생성할 수 있도록 학습됩니다.
그런 이 모델의 한계는 두 개의 다른 데이터셋에 대한 downstream task에서 드러나는데, 모델은 영상-오디오-텍스트의 멀티 모달을 다룰 수 있도록 학습되었으나, MSR-VTT의 일부 모달리티가 학습한 모달리티와의 성격이 다름으로 인해 성능이 하락하여, 일반화 성능이 좋지 않음을 알 수 있었습니다.
따라서 향후 연구는 멀티 모달 임베딩을 학습하면서도 domain adaptation이나 일반화를 잘할 수 있도록 하는 기법이 연구되어야 할 것이라 제안합니다.
이 논문을 읽으며, 몇 개월 전 CVPR 2023에 게재되었으며 저도 한 번 리뷰한 ImageBind가 계속 떠올랐습니다. 해당 논문을 읽을 때도 느낀 거지만 정말 Multi-modal 쉽지는 않은 분야인 것 같습니다.
이미지나 비디오 한 모달리티에 존재하는 spatial, temporal한 정보와 context에 대해 이해하기도 힘든데, 복잡한 모델들 간의 context를 이해하려니 직관적으로 이해도 안 되고, 때때로 엄청난 모델의 복잡도나 크기, 혹은 “요즘 핫한 분야” 특유의 어질어질한 피인용수를 보며 압도되기도 했습니다.
그러나 최근 읽은 OpenAI의 한 논문에서, Multi-modal neuron에 대해 이야기한 한 문장을 보고 그만 낭만이라는 것이 불타오르고 말았습니다. 저는 조금만 더 multi-modal 파보겠습니다.
You are looking at the far end of the transformation from metric, visual shapes to conceptual… information.
https://distill.pub/2021/multimodal-neurons/
기초 교육 과정을 마치고, 팀에서 부여되었던 task도 지난주에 어느 정도 완료되서, 모처럼 오랜만에 하고 싶은 공부를 할 시간이 생겼습니다. 그런데, 막상 한동안 선배들이 골라주는 맛있고 영양가 있는(?) 논문만 보다가, 스스로 논문을 찾아보자니 생각보다 쉽지 않았습니다.
몇 주전 같았으면 그냥 커뮤니티에서 재밌다는 논문 읽었을 것 같은데, 이제 한 분야를 파고 들어야 하는 연구자로서 이게 올바른 자세인가 싶어 그만두었습니다.
그렇게 논문 탐색에만 며칠을 써서 찾은 논문이 이 논문입니다. 그래도 역시 한 편을 다 읽고 나니, 이제 이 논문 related work부터 시작하면 되겠다 싶기도 하고, 새로운 용어들도 좀 익숙해지고 자신감이 생기네요.
아무튼 다들 행복한 연구하시기 바랍니다. 화이팅입니다.
읽어주셔서 감사합니다!
안녕하세요. 좋은 리뷰 감사합니다. 멀티모달 retrival이라니 저도 흥미가 많이 가는 분야이네요. 간단하게 질문이 있습니다.
1. 백본의 경우 텍스트 백본은 word2vec 모델을, 오디오 백본의 경우도 residual layer가 있는 모델을 가져갔는데, 저는 여기에서 이해가 가지 않은 부분이 왜 이렇게 간단하게 백본을 가져갔는지 잘 이해가 가지 않습니다. 특히 text의 경우 bert나 albert와 같은 유명한 백본이 있는데오 굳이 word2vec을 사용한 이유가 있을까요? 오디오의 경우도 이미 wav2vec2와 같은 유명한 백본이 있는데 굳이 간단한 모델을 백본으로 사용했는지 모르겠네요.
2. No positional embedding 부분에서 질문인데요. “학습 과정에서 clip 내부의 일관된 시간적 패턴을 배울 수 없다”고 하는 것이 무슨 말인지 잘 모르겠습니다. 분명 동영상 Clip 자체가 sequence data로 생각이 되어지는데 왜 shot boundary나 speech pause 등은 고려되지 않는다고 해서 시간적 패턴을 배울 수 없는 건가요??
안녕하세요. 김주연 연구원님.
댓글 감사드립니다.
1. 논문에 따로 텍스트 백본 선정 이유가 담겨 있지 않고, 제가 아직 이 분야를 잘 아는 것도 아니라 저자들의 정확한 의도는 아직 답변드리기 어려울 것 같습니다. 다만 언급하신 트랜스포머나 버트 등은 본 논문의 메인 task가 아닌 텍스트에 사용하기에 큰 모델이기도 하고, 다른 방법론들과 fair comparison을 위해 뭔가 이 분야에 일반적으로 사용되는 백본이 있지 않았을까 하는 추측이 듭니다.
2. 본 모델에서 동영상을 입력할 때, speech나 shot boundary를 고려하여 영상의 clip을 나누지 않기 때문에, 클립의 첫 부분이 꼭 어떤 고정된 의미 (장면의 시작 등)를 강하게 나타내지 않아서 일부러 이런 positional한 정보를 약하게 가져간 것으로 이해하였습니다.
감사합니다.
리뷰 잘 읽었습니다.
이번 KCCV 구두, 포스터 발표 논문 리스트를 보며 제일 많이 보였던 keywords 중 하나가 multi-modal 이였던지라 지오님의 리뷰에 홀리듯 들어온 거 같네요.
전체적으로, 그리고 특히 related work 쪽을 자세하게 적어주셔서 처음 접하는 분야인데도 원활하게 읽혔던 좋은 리뷰였던 거 같습니다.
개인적인 궁금증이 있는데요, HowTo100M 데이터셋의 text 에 노이즈가 많다고 하셨는데 그럼 해당 분야의 벤치마킹 데이터셋으로 다른 대안은 없는 상황인건가요?
또한 멀티 모달 학습에 대한 related work을 보니 서로 다른 modal feature를 최종적으로 서로 다른 임베딩 공간을 가지도록 하는 방식도 있고, 공통 임베딩 공간을 가지도록 하는 방식도 있는 거 같습니다. 본 논문의 경우 후자인 거 같구요.
뭔가 제 개인적인 생각으로 multi-modal (혹은 저희 lab에 맞게 multi-spectral) data를 가지고 최종적으로 fusion 등의 작업을 하기 위해선 공통 임베딩 공간으로 보내야 이상적이라는 생각이 드는데, 그런 관점에서 서로 다른 임베딩 공간을 가지도록 하는 방식인 ‘ Alayrac et al., 2020의 Multi-modal Versatile Network’ 를 설계한 저자의 의도나 목적성이 더더욱 궁금해지는 상황이네요ㅎㅎ.
혹시 해당 논문에 대해 related work에서 한 줄 추가적인 설명이 있다거나, 혹은 지오님께서 앞으로 읽을 논문 리스트에 해당 논문이 읽는지 궁금합니다.
(만약 다음에 리뷰하시게 된다면 저한테 말씀 해 주시면 감사하겠습니다 ㅎ)
감사합니다!
안녕하세요.
댓글 감사드립니다.
1. 저도 이 분야의 논문을 많이 보지 않아 정확하지는 않지만, 영상에 대한 텍스트를 얻는 것이 매우 costly한 작업인 만큼, HowTo100M 만큼 대량의 데이터를 가지면서 noise가 없는 대안은 아직 없는 것으로 보입니다.
2. Multi-modal Versatile Network에 대한 설명은 제가 리뷰에 작성한 정도로 간단하게 되어 있어 이 논문만 봐서는 모르겠습니다… 다만 석준님의 댓글을 읽고 나니, 저도 궁굼해져서 조만간 읽고 가능하다면 리뷰까지 해보겠습니다.
감사합니다.