
안녕하세요, 허재연입니다. 이번에 리뷰할 논문은 Google research team에서 2020년에 발표한 SimCLR이라는 self-supervised learning 방법론입니다. 인공지능의 대부 제프리 힌튼이 공저자인게 눈에 띕니다. 이 방법론은 MoCo, BYOL, Barlow twins, MAE 등 다른 방법론들과 함께 visual recognition의 대표적인 self-supervised learning 방법 중 하나로 꼽힙니다. 기존에 읽었던 논문들보다 복잡해서 읽고 이해하는데 애를 먹었네요. 실험과 논문 구성이 상당히 체계적이어서 배울게 많은 논문이라는 생각이 들었습니다. 한 번 살펴봅시다.
Background
일단 이 방법론이 무엇인지 바로 들어가기 전에, self-supervised learning이 무엇인지 간단하게 짚고 시작하겠습니다. 최근에 다양한 알고리즘이 개발되고 컴퓨팅 리소스가 발달하면서, GT와 예측값의 차이를 이용해 모델의 최적화를 진행하는 딥러닝 방법론은 현대사회에서 빼놓을 수 없는 연구분야가 되었습니다. 하지만 특정한 딥러닝 모델을 학습시킬 때 항상 우리의 발목을 잡는 것이 있습니다. 바로 양질의 labeled data가 절대적으로 부족하다는 점입니다. 앤드류 응 교수가 ‘모델 중심의 AI에서 데이터 중심의 AI’를 강조했듯, 성능 좋은 딥러닝 모델을 만들기 위해서는 대규모 양질의 데이터가 필요합니다. 최근 핫한 chatGPT도 방법론이 새롭다기보다는 매우 큰 데이터를 학습에 때려박아 좋은 성능을 달성했습니다. 하지만 큰 규모의, 양질의, 그것도 labeling된 데이터셋을 확보하는것은 cost가 너무 큽니다. minor한 field에서는 양질은 고사하고 해당 데이터셋이 있을지부터 걱정해야 하죠. 일반인에게 annotation을 맡기면 그나마 괜찮지만, labeling에 전문적인 지식이 필요한 field에서는(영상의학 전문의를 고용해야 한다거나) labeling cost가 더욱 커질 것입니다. 이는 아주 큰 문제입니다.
때문에 제한된 데이터를 가지고 최대한의 효율을 달성하기 위한 연구가 활발하게 이뤄지고 있습니다. semi-supervised learning(소량의 labeled data를 이용해 unlabeled data에 pseudolabeling), Active learning(라벨링 효율이 높은 데이터 선별)을 이용할수도 있고, 오늘 소개할 self-supervised learning을 사용할 수도 있습니다. self-supervised learning을 간단하게 말하자면, ‘데이터에서 label을 생성할 수 있는 다른 task를 이용해 model pretrain을 진행한 이후, 원래 목표하던 downstream task에 fine-tuning하는 방법으로 모델의 표현력을 향상시켜보자’라는 컨셉입니다. 이렇게 들으면 와닿지 않으실테니 고전적인 방법론 하나를 함께 보시죠
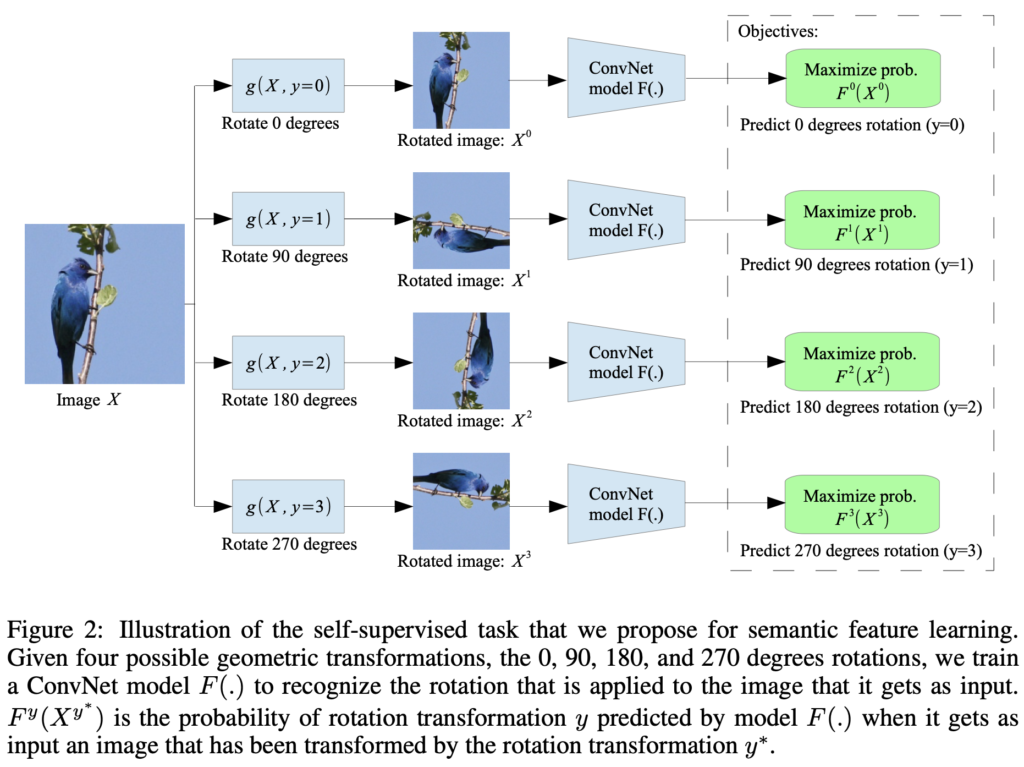
위 그림은 ICLR 2018에서 제안된 self-supervised learning 기법입니다. 컨셉은 아주 단순합니다. 그냥 이미지 데이터를 무작위로 0,90,180,270도 회전시켜서 몇 도 돌았는지 각도 맞추기 task를 진행합니다. 모델은 이 때 스스로 label(회전 각도)을 생성해 학습에 사용하므로, labeled data가 필요하지 않습니다. (스스로 라벨을 생성해 supervised learning을 진행하므로 self-supervised learning이라고 하는구나~ 정도로 생각하시면 좋을 것 같습니다) 이런 사전학습을 하는 task를 pretext task라고 하며, 대표적인 pretext task는 위의 각도맞추기, 색상을 추론하는 colorization, jigsaw puzzel 맞추기 등이 있습니다. 이런 간단한 사전학습을 통해 어느정도 데이터의 표현력을 모델이 학습하길 기대하는 것이죠. 실제로 pretrained model을 fine-tuning하면 처음부터 학습을 진행하는것보다 성능이 상당히 개선됩니다. 표현력을 미리 학습하므로 self-supervised learning을 representation learning이라고 부르기도 하며, 라벨을 스스로 생성하기에 unlabeled data를 사용할 수 있으므로 unsupervised learning으로 보는 시각도 있습니다.
contrastive learning은 self-supervised learning기법 중 하나입니다. 유사도 계산을 통해 비슷한 데이터(positive pair)끼리는 feature embedding space에서 가깝게, 다른 데이터(negative pair)를 멀리 있게 하도록 학습시키는 방법으로 pretrain합니다. negative pair가 많을수록 학습에 유리하므로, memory bank를 활용하기도 합니다. 오늘 살펴볼 SimCLR은 새로운 contrastive learning framework를 제안한 논문입니다. 이제 논문을 살펴보겠습니다.
SimCLR : A Simple Framework for Contrastive Learning of Visual Representations
Abstract
이 논문은 SimCLR(a Simple framework for contrastive learning of visual representations)를 제안합니다. 이 framework는 특수한 구조나 memory bank 없이도 당시 제안된 contrastive self-supervised learning algorithm을 단순화시켰습니다. 또한, contrastive prediction task에서 유용한 representation을 학습할 수 있게 하는 요인을 이해하기 위해 framework의 주요 구성 요소를 체계적으로 연구했습니다.
그 결과, (1) data augmentation의 구성이 효과적인 predictive task 정의하는 데 중요한 역할을 하고, (2) representation과 contrastive loss사이에 learnable 비선형 변환을 도입하면 학습된 representation의 품질이 크게 향상되며, (3) contrastive learning은 지도 학습에 비해 더 큰 배치 크기와 더 많은 training step을 통해 이점을 얻을 수 있다는 것을 보였습니다.
이러한 연구 결과를 결합하여 ImageNet의 self-supervised 및 semi-supervised learning에 대한 이전 방법보다 훨씬 뛰어난 성능을 달성할 수 있게 되었습니다. SimCLR로 학습한 self-supervised representation에 대해 훈련된 선형 분류기는 76.5%의 top-1 accuracy를 달성했으며, 이는 이전 SOTA에 비해 7% 개선된 것으로 supervision를 받은 ResNet-50의 성능과 일치합니다. 1%의 레이블에 대해서만 fine-tuning할 경우 85.8%의 top-5위 accuracy를 달성하여 100배 적은 레이블로 AlexNet보다 뛰어난 성능을 달성했습니다.
Introduction
사람의 지도(human supervision)없이 효과적인 시각적 표현(visual representation)을 학습하는 것은 오랜 문제였고, 대부분의 주류 접근법은 1. 생성적(generative) 접근 방식과 2.판별적(discrimitive) 접근 방식 중 하나였습니다.
- 생성적 접근법(Generative approaches)은 input space에서 픽셀을 생성하거나 모델링하는 방법을 학습하는 방법입니다. 하지만, 픽셀 수준 생성은 계산 cost가 높고, representation learning에는 필요하지 않을 수 있습니다.
- 판별 접근법(Discriminative approaches)은 supervised learning에 사용되는 것과 유사한 objective function를 사용하여 표현을 학습하지만, input과 label이 모두 unlabeled dataset에서 파생되는 pretext task를 수행하도록 네트워크를 훈련시킵니다. 이러한 접근 방식은 대부분 heuristic에 의존하여 pretext task를 설계해왔는데, 이는 학습된 표현의 일반성을 제한할 수 있습니다. 최근 latent space에서의 contrastive learning에 기반한 판별 접근법이 큰 가능성을 보이며 SOTA를 달성하고 있습니다.
이 논문에서 저자들은 시각적 표현의 Contrastive Learning을 위한 간단한 프레임워크(SimCLR)를 제안했습니다. SimCLR은 이전 방법론들보다 우수한 성능을 보였을 뿐만 아니라, 간단하며, 특수한 구조나 memory bank를 필요로 하지도 않습니다.
저자들은 우수한 contrastive representation learning을 가능하게 하는게 무엇인지 이해하기 위해 framework의 주요 구성 요소를 체계적으로 연구하고 다음과 같은 사항을 보였습니다 :
- 효과적인 표현을 생성하는 contrastive prediction task를 정의하는데 있어 다양한 data augmentation 작업을 구성하는 것이 중요하다. 또한, unsupervised contrastive learning은 supervised learning보다 데이터 증강을 통해 이점을 가질 수 있다
- representation과 contrastive loss 사이 learnable nonlinear transformation을 도입하는 것은 학습된 표현의 질을 크게 향상시킨다
- contrastive cross entropy loss를 활용한 representation learning은 정규화된 임베딩과 적절하게 조정된 temperature parameter로 이점을 가질 수 있다.(temperature parameter는 contrastive loss를 구성할 때 나오는 parameter입니다. simclr의 구성요소 중 하나라고 생각하시면 될 것 같습니다)
- contrastive learning은 supervised learning에 비해 더 큰 batch size와 더 긴 훈련으로 이점을 가질 수 있다. supervised learning과 마찬가지로 contrastive learning도 네트워크의 depth, width를 늘려 성능 향상을 기대할 수 있다.
저자들은 이 결과들을 조합하여, ImageNet에서 self-supervised, semi-supervised learning에서 SOTA를 달성했습니다. 다른 natural image classification dataset에서 fine-tuning했을 때, SimCLR는 12개 dataset 중 10개에서 supervised baseline보다 비슷하거나 그 이상의 성능을 보여주었다고 합니다.
The Contrastive Learning Framework
SimCLR는 latent space의 contrastive loss를 통해 동일한 data example의 differently augmented views 간 agreement를 최대화하여 표현을 학습합니다. 이게 무슨 뜻이냐면, 동일한 이미지 하나에 서로 다른 augmentation을 적용해서 두 개의 벡터를 만든 후, 이 벡터를 feature space에서 가깝게 위치시키는 방향으로 학습을 시킨다고 받아들이면 되겠습니다(반대로 서로 다른 데이터에 대해서는 멀어지는 방향으로 학습하게 됩니다)
아래 framework 사진을 보면서 주요 요소에 대해 알아보겠습니다.
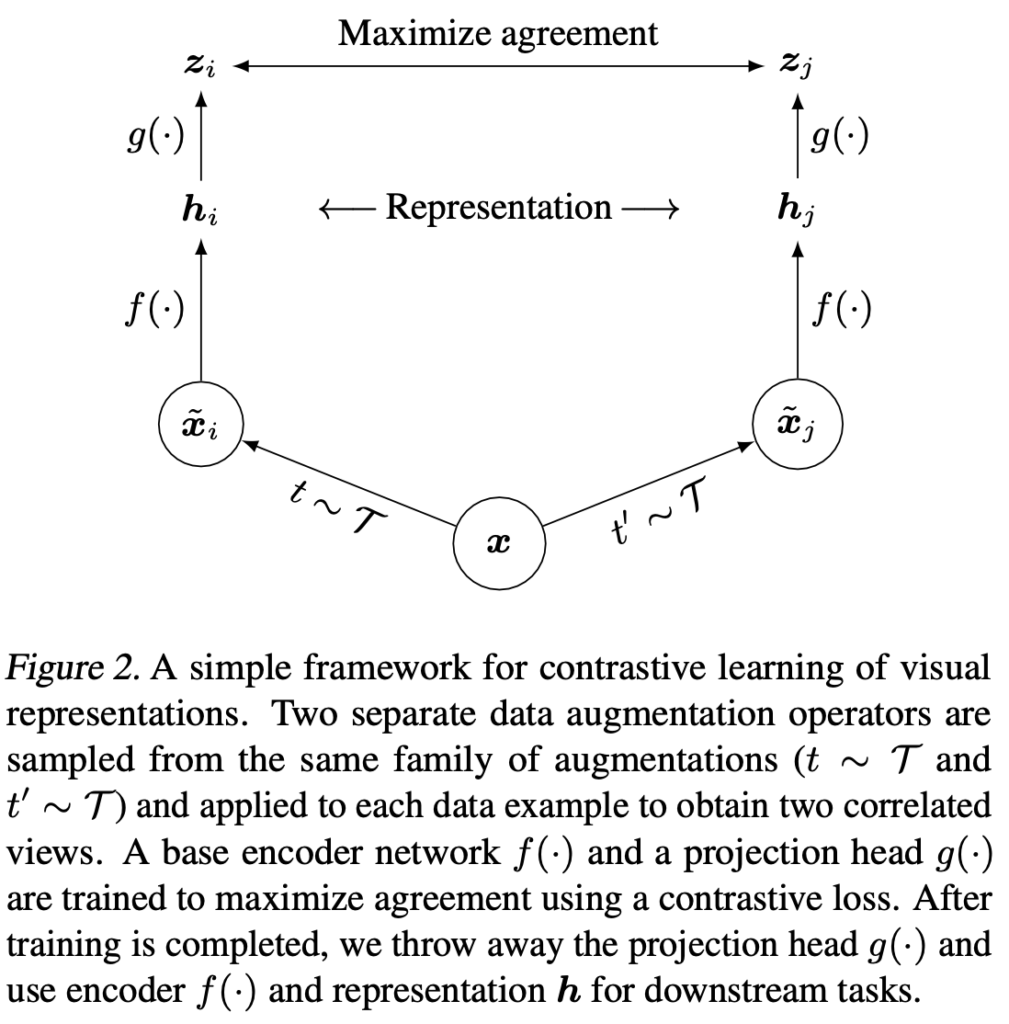
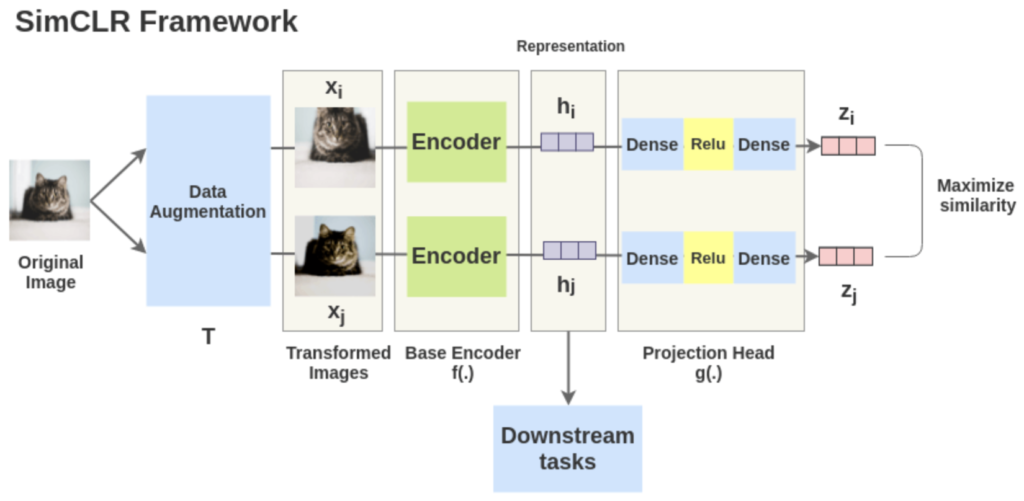
framework의 구조를 나타낸 것으로 논문에서 핵심적인 그림입니다. framework는 크게 다음의 4가지 요소로 구성됩니다.
1. Data Augmentation(t∼τ, t’~τ) : 하나의 image에서 stochastic data augmentation을 통해 두개의 서로 다른 augmented image를 생성하고, 이를 positive pair로 정의합니다. 그 외의 (minibatch 내부의)나머지 augmented image들은 negative pair로 정의합니다. data augmentation은 random cropping 후 resize, random color distortion, random gaussian blur를 순차적으로 적용하는 방식으로 하는데, 실험 결과 특히 random crop과 color distortion의 조합이 좋은 성능을 달성하는데 결정적인 역할을 했다고 합니다.
2. base encoder network f(·) : augmented data examples에서 representation vector를 추출합니다. base network로는 무엇을 사용해도 되지만, 저자들은 간단히 자주 사용되는 ResNet을 실험에 사용했습니다. 위 그림의 hi, hj는 ResNet의 global average pooling 이후 output입니다.
3. projection head g(·) : 두개의 linear layer 사이에 ReLU를 넣은 구조로 구성된 작은 신경망입니다. f()에서 추출한 representation을 contrastive loss공간에 매핑시키는 역할을 하는데, 앞서 구한 hi, hj를 g(·)에 태워서 vector zi, zj를 추출하여 contrastive learning을 진행하게 됩니다.
4. contrastive loss function : contrastive prediction task를 정의하는 loss입니다. contrastive prediction task는 주어진 positive pair를 최대한 같게 만들어주려고 합니다.
학습을 진행할 때, minibatch 내부의 데이터들 중 positive pair를 제외한 데이터를 negative pair로 정의하고 학습에 사용합니다. 일반적으로 contrastive learning 방식으로 학습을 진행할 때, 1. 좋은 퀄리티를 가지며 2. 충분의 많은 양의 negative pair가 필요한데, 학습이 batch 단위로 진행되기 때문에 많은 양의 negative pair를 구성하기 위해 큰 batch size를 이용하여 학습해야 합니다. SimCLR는 기본적으로 4096의 batch size(pairing 하므로 총 8192개의 sample)를 이용하여 학습 진행하게 됩니다(엄청 큽니다 ..)
positive pair (xi, xj)에 대한 loss function은 다음과 같이 정의됩니다 :

sim(u,v) : cosine 유사도 / τ : temperature parameter(0.1, 0.5 등등 값 사용) / 최종 loss는 mini batch에서 모든 positive pair((i,j) 및 (j,i) 둘 다)에 대해 계산합니다. 저자들은 이 loss를 T-Xent loss(the normalized temperature-scaled cross entropy loss)라고 합니다.
학습 알고리즘은 다음과 같습니다.

(위의 Figure2와 함께 보시면 이해가 수월할 것입니다)
알고리즘의 동작 과정을 살펴보면, N개(batch size)의 데이터가 들어오면 이미지 한 장당 서로 다른 augmentation(t~τ)을 태워서 2N개의 sample을 만들고, 서로 다른 augmented data 각각에 1.base encoder f() (논문에서는 ResNet50)를 태워서 representation을 얻은 뒤에, 2. projection head g() (MLP 기반의 작은 네트워크인데, 논문에서 learnable nonlinear transformation이라고도 표현합니다)를 태운 후 나온 2개의 output에 대해 3. pairwise similarity를 계산합니다. 유사도를 계산한 이후 positive pair에 대해서는 서로 가까워지게(유사도가 높아지게), negative pair에 대해서는 서로 멀어지게(유사도가 낮아지는 방향으로) 학습을 진행합니다. pretrain이 완료된 후 fine-tuning을 할 때는 projection head를 제거하고 base encoder를 거친 representation을 바로 이용합니다(Ablation experiment를 진행했을 때 제거하는게 좋았다고 하며, 저자들은 이 이유로 projection head는 data transform에 invariant하게 학습되었으므로, 물체의 방향이나 색상 정보 등 downstream task에 유용할 수 있는 정보를 제거하는 효과가 있기 때문이라는 가설을 제시합니다)
일반적으로 contrastive learning으로 pretrain을 진행할 때, 좋은 퀄리티의 충분히 많은 양의 negative pair가 있어야 훈련이 효과적으로 이루어질 수 있다고 합니다. 이를 위해서 기존 모델을은 특수한 구조를 추가하거나 memory bank를 이용하기도 했는데, SimCLR에서는 프레임워크의 단순화를 위해 batch size를 매우 크게 하는 방법을 사용합니다. batch size N을 256부터 8192까지 실험에 사용하였는데, N=8192일 때는 negative pair가 16382개까지 늘어납니다 (positive pair는 두개이죠). training resource가 엄청나게 많이 필요할 것 같습니다. 실제 실험에서는 Cloud TPU로 학습을 진행했고, 32개부터 최대 128개의 core를 사용해 분산 학습을 시켰다고 합니다. 이렇게 큰 배치단위의 학습에서는 일반적인 SGD/Momentum으로 학습하는건 학습이 불안정해 질 수 있다고 하며, 실험에 LARS optimizer라는것을 사용했다고 합니다. 처음 보는 optimizer였었는데 pytorch에도 구현되어있지 않고 그냥 대규모 배치 단위 학습을 진행할 때 안정적으로 학습하기 위해 제안된 방법론이라고 생각하시면 될 것 같습니다.
실험 대부분은 ImageNet dataset으로 진행되었으며, CIFAR-10 이외에 다양한 데이터셋에 대해서도 진행되었다고 합니다. 학습된 representation은 linear evaluation protocol로 평가하는데, 이는 학습된 network는 freeze 시키고 그 위에 linear classifier만 달아서 test accuracy를 비교하는 방법입니다.
Data Augmentation for Contrastive Representation Learning
Data Augmentation은 이 framework에서 특히 핵심적인 부분입니다. data augmentation 자체는 간단하고 우리에게 익숙하지만, 저자들은 이 간단한 방법을 체계적으로 도입함으로 기존 모델들의 복잡성을 간단히 처리했습니다. 개인적으로 논문을 읽으면서 이 부분이 인상깊었습니다. 나중에 저도 이렇게 쉽고 깔끔하게 기존 문제점들을 해결하는 방법론을 고안해보고 싶네요. 살펴 보겠습니다.
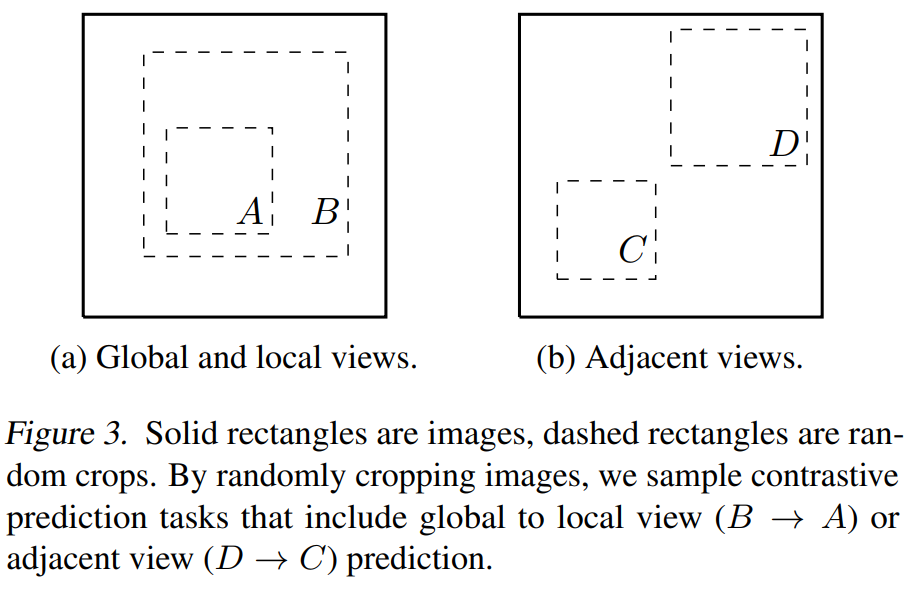
Data augmentation이 supervised learning과 unsupervised representation learning에 널리 이용되고 있지만, contrastive prediction task를 정의하는데 체계적으로 고려된 적은 없었다고 합니다. 기존의 많은 방법론들은 모델의 구조를 바꿈으로 contrastive prediction task를 정의했었습니다. 네트워크 구조의 receptive field를 제한해서 global-to-local view prediction을 구성하거나, fixed image splitting splitting을 이용해서 인접 이미지 view를 예측하는 task를 고안했었습니다. 하지만 저자들은 단순히 data augmentation만을 이용해 간단하게 이를 재연했습니다(Figure3 참고).
저자들은 매우 다양한 Data Augmentation을 고려했고, 결국 SimCLR에는 1. Random crop(with flip&resize) 2. color distortion 3.Gaussian blur가 적용되었습니다. 저자가 고려했던 Augmentation에는 cropping, resizing, horizontal flip, rotation, cutout과 같은 데이터의 공간적/기하학적 변환과, color distortion(color dropping, brightness, contrast, saturation, hue), gaussian blur, sobel filtering과 같은 외형 변환이 있습니다. 다음 그림을 참고하시면 될 것 같습니다.

각각 augmentation의 효과와 구성을 이해하기 위해서, 저자들은 각 augmentation에 대한 실험을 진행했습니다(위의 framework를 사용합니다)
Experiments
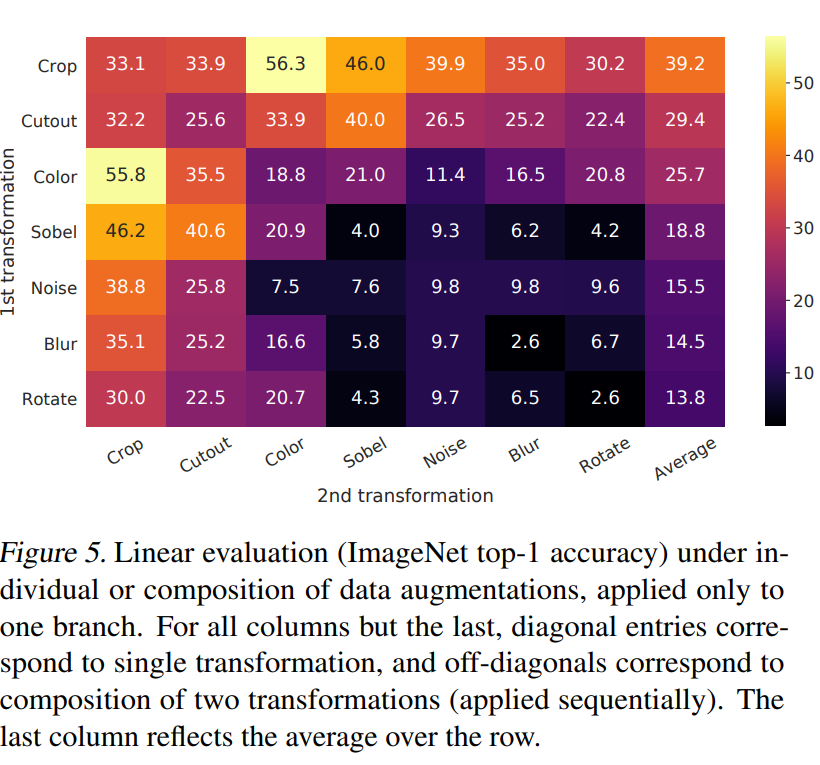
각 data augmentation의 조합을 Linear evaluation한 표 입니다. 대각선은 단일 변환을 적용한 것이고, 나머지는 2개의 augmentation을 순차적으로 조합한 것입니다. 마지막 열 Average는 행 전체의 평균입니다.
표를 보면, model이 contrastive task에서 positive pair를 거의 완벽히 identitfy 할 수 있음에도 불구하고 단일 변환이 표현을 학습하기에 부족함을 확인할 수 있습니다. Augmentation을 조합하면 contrastive prediction task가 어려워지지만 representation의 질이 상당히 개선됩니다.
colorization은 제가 기존에 잘 보지 못했던 증강 기법인데, 상당히 중요함을 확인할 수 있습니다. 단순히 cropping만 하면 결국 픽셀별 색상 값 분포는 계속 유지되는데, color distortion을 통해 이 부분을 개선할 수 있다고 합니다.
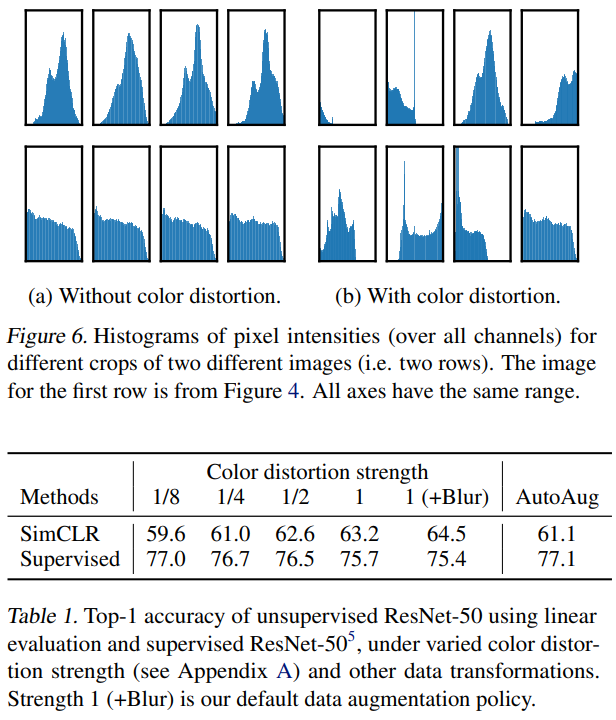
Table 1는 SimCLR와 supervised learning에서 color distortion 강도가 얼마나 성능에 영향을 미치는지 나타내는 표입니다. supervised model과 비교를 해보면 정작 supervised learning에서는 color distortion의 강도를 높여도 성능 개선이 그다지 일어나지 않습니다. 이 실험은 통해서는 ‘supervised learning보다는 contrastive learning에서 data augmentation이 더 중요하다!’는 결론을 도출해 냅니다. 왜 기존 augmentation에서 colorization이 잘 등장하지 않았는지 여기를 보면서 납득했습니다. supervised learning과 contrastive learning을 비교한 실험은 더 있습니다.
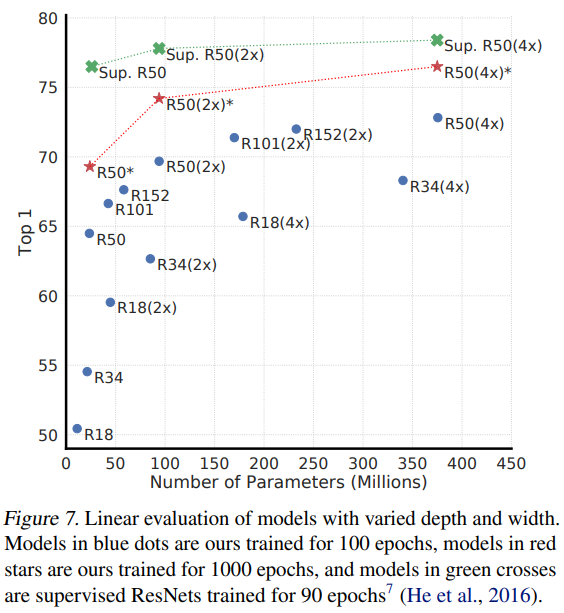
이 표는 model의 depth와 width에 대한 실험으로 supervised ResNet과 비교한 실험입니다. 초록색의 supervised와 빨간색의 contrastive에 집중하면 되는데, 모델을 키워 parameter가 증가할수록 둘 다 성능이 오르긴 하지만, 저자들의 방법론이 더 가파르게 상승합니다. 여기 표에서도 supervised보다 contrastive learning이 비교적 모델 크기를 키워 성능 향상을 기대할 수 있다는것을 보여줍니다.
다음 실험은 linear projection head에 대한 실험입니다. 보면 실험과 표가 정말정말 많이 등장하는데.. SimCLR 저자들은 최적의 framework를 제안하기 위해 정말 많은 실험을 수행했고, 어째서 SimCLR를 이렇게 구성할 수 밖에 없었는지 분석적으로 보여줍니다. 보면서 이렇게 치밀하게 실험을 하는구나 .. 하면서 감탄했습니다.
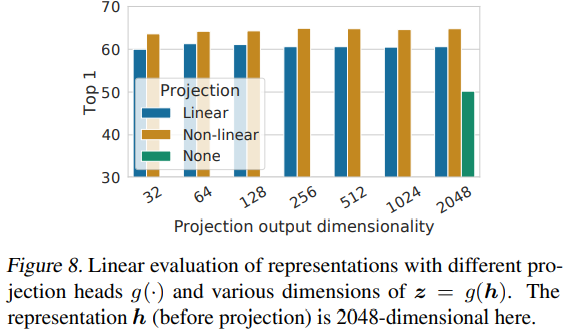
위의 framework 그림에서 projection head는 base encoder 이후에 위치하며, pretrain에서만 사용하고 fine-tuning할때는 버린다고 했습니다. representation learning에서는 중요한 영향을 미치기 때문입니다. 없을 때보다는 붙였을때가, linear transformation보단 nonlinear transformation을 하는 형식으로 구성하는것이 성능이 좋았습니다.
훈련을 어떻게 구성하는것이 최적이었는지에 관한 실험도 있습니다. 아래 표를 함께 보겠습니다.
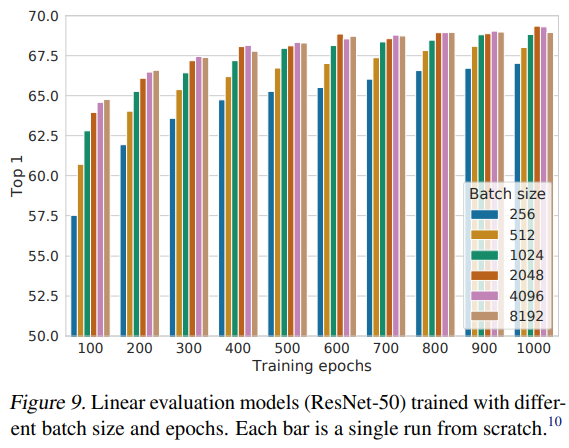
framework 구성이 완료된 후에는 다양한 epoch와 batch size에 대한 실험이 진행되었습니다. 해당 실험에서는 길게 훈련할수록, 그리고 batch size가 충분히 커야지 좋은 성능을 달성할 수 있다는것을 보였습니다. 이는 supervised learning과는 상당히 다른 양상이라고 언급합니다(supervised learning과 비교하면 epoch과 batch size가 너무 크죠)
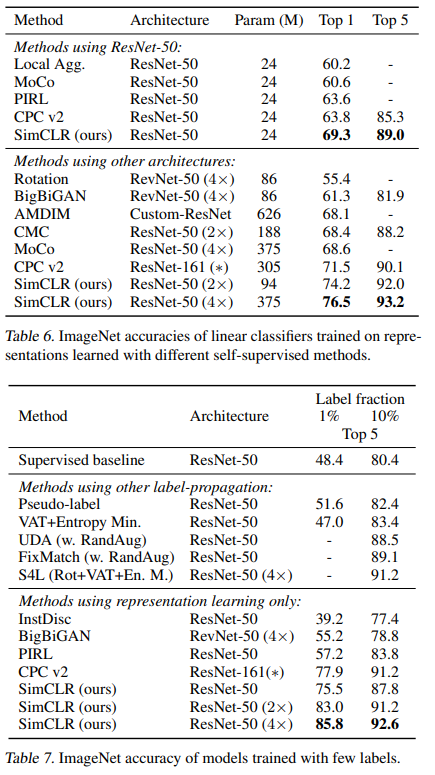
SOTA 방법론들과의 비교 실험입니다. 기본 모델로는 ResNe50이 사용되었습니다(1x,2x,4x는 hidden layer widths라고 합니다. Figure7에서 확인할 수 있듯 크기가 다릅니다). 학습은 1000epoch만큼 진행되었다고 합니다. 기존의 SOTA 방법론들을 찍어 누르는 성능을 보여줍니다. 논문의 하이라이트는 바로 다음 표에 있습니다.
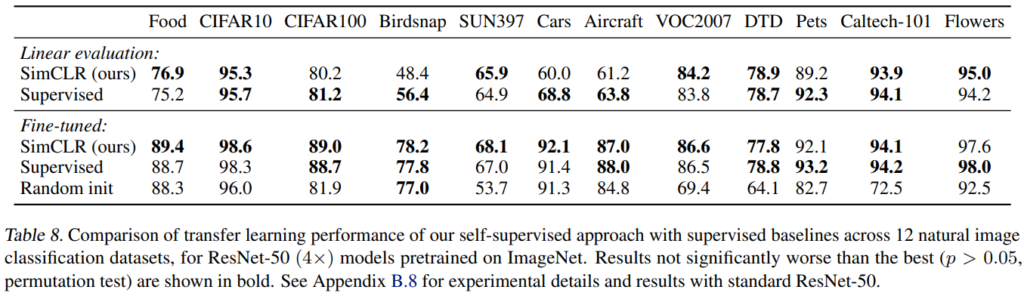
저자들은 transfer learning 성능을 12개의 natural image dataset에 대해 linear evaluation 방법과 fine-tuning 방식으로 평가했습니다. 이 표에서는 저자들의 self-supervised ResNet50(4x)모델이 fine-tuned 됐을 때 5개의 dataset에서 supervised baseline을 능가하는 성능을 보입니다. supervised baseline은 오직 Pets, Flowers 2개에서만 우세하고, 나머지 5개 dataset에 대해서는 비슷한 성능을 보였습니다.
Conclusion
저자들은 contrastive visual representation learning을 위한 간단한 framework인 SimCLR를 제안했습니다. 이를 어떻게 구성해야 하는지 아주 자세히, 체계적으로 연구하였고 각각 요소에 대한 설계 방법에 따른 차이를 보였습니다. 이런 실험을 바탕으로 조합해서 기존의 self-supervised, semi-supervised learning보다 개선된 결과를 보였습니다.
안녕하세요! 좋은 리뷰 감사합니다.
동작과정에서 pairwise similarity를 계산하는 부분이 있는데 유사도를 계산하는 대상이라고 함은 Figure2.의 z_i, z_j가 되는 것인가요? 실제 positive pair (x_i, x_j)를 contrastive loss 공간에 매핑시킨 것이 z_i, z_j가 되기 때문에 z_i, z_j를 positive pair loss function 안에서 유사도를 계산하고 학습을 진행하는 것이라고 이해하는 것이 맞을까요? 아니면 pairwise similarity를 계산하는 별도의 과정이 존재하는 것인가요?
감사합니다.
contrastive learning 과정에서 pairwise similarity는 손건화 연구원님이 말씀하신 대로 projection head를 거친 zi, zj에 대해 계산됩니다. positive pair (xi, xj)는 base encoder, projection head를 거쳐 128차원 등의 벡터 zi, zj로 기술되고 이 벡터간의 cosine 유사도를 계산해서 positive pair간의 agreement를 최대화시키는 방향으로 학습을 진행시킨다고 생각하시면 됩니다.
안녕하세요. 허재연 연구원님.
좋은 리뷰 감사합니다.
읽고 나서 궁굼증이 생겨 질문드립니다.
메모리 뱅크 방식 또한 negative pair를 최대한 늘리는 방식으로 알고 있는데, 이를 사용하지 않는 SimCLR 방식이 memory bank 대비 좋은 점이 구현의 단순성 외에 또 있는지 궁굼합니다!
감사합니다!
contrastive learning에서 memory bank를 사용하는 이유는 negative pair를 늘려 학습에 이점을 가져가기 위함으로 알고 있습니다. SimCLR 논문에서는 memory bank를 사용하지 않음으로 프레임워크를 단순화시켰다 이외에는 별다른 언급이 없습니다. 메모리 뱅크 없이도 배치 사이즈를 늘려주는 것으로 충분한 양의 negative pair를 확보할 수 있었고, 프레임워크 단순성을 위해 이런 선택을 했다고 생각하시면 될 듯 합니다.
안녕하세요 좋은 리뷰 감사합니다.
그림 6과 표 1을 통해 self supervised learning에서 colorization이라는 augmentation 기법의 효과를 보여주셨는데, 정확히 어떤 수식이 적용되어 그림 6과 같은 픽셀 분포를 갖게 되는 것인가요? 또 표 1에서 AutoAug 열의 성능은 무엇을 의미하나요?
혹시 저자가 왜 supervised 상황에서, colorization 적용 강도가 강해질수록 성능이 하락하는지에 대해 이야기한 것이 있는지도 궁금합니다.
그리고 NT-Xent loss에서 temperature 값 타우가 커지거나 작아질 때 각각 어떤 방향으로 영향을 미치게 되나요?
감사합니가.
color distortion에는 여러가지가 있지만, 해당 표의 (b)에서는 brightness, contrast, saturation, hue에 대한 random color jittering가 적용된 것으로 보입니다(정확히 어떤것이 적용되었다 라고 정확히 나오지 않고 color distortion이라는 표현만 쓰였습니다). 해당 augmentation에 대해 관심 있으시다면 PyTorch의 torchvision.transforms.ColorJitter 문서를 참고하시면 도움이 될 것이라 생각합니다.
Table 1에서, 왜 supervised learning에서 colorization 적용 강도가 강해질수록 성능이 하락하는지에 대해서는 별다른 언급이 없습니다. 그냥 ‘SimCLR은 supervised보다 color distortion으로 더 많은 이점을 가져갈 수 있다’ 라는 주장의 비교군으로 언급됩니다. AutoAug도 비슷한 맥락으로 강한 Color distortion과 비교하기 위해서 잠깐 언급만 되어서 별다른 설명이 없습니다. AutoAug보다 강한 color distortion이 좋더라 비교하고 넘어가는데, 당시 주목받던 color augmentation 방법과 비교한 것이라 생각했습니다. AutoAug(AutoAugment:Learning Augmentation Strategies from Data)에 대해 검색해보니 CVPR 2019에 개제된 논문이네요. 1900에 가까운 citation이 달려있습니다.
temperature parameter는 loss 연산 과정에서 너무 값이 튀지 않게 하기 위한 하이퍼파라미터입니다 similarity 함수는 consine이기에 정규화된 벡터가 -1~1의 값을 가지는 반면, result range는 1/e ~ e까지 확장됩니다. 이런 range 차이 때문에 tau값을 활용해 조정하지 않으면 loss 계산 과정 중 negative pair간 연산에 불리하기 때문에 tau를 활용한다고 합니다.
안녕하세요 허재연 연구원님 좋은 리뷰 감사합니다.
수식1을 보면 temperature parameter \tau를 통해 cosine similarity를 scaling하는 것으로 보이는데 구체적으로 temperature parameter는 어떤 역할을 하는 것인지 궁금합니다.
temperature parameter는 loss 연산 과정에서 너무 값이 튀지 않게 하기 위한 하이퍼파라미터입니다 similarity 함수는 consine이기에 정규화된 벡터가 -1~1의 값을 가지는 반면, (similarity 함수가 exponential에 지수로 올라가 있기에)result range는 1/e ~ e까지 확장됩니다. 이런 range 차이 때문에 tau값을 활용해 조정하지 않으면 loss 계산 과정 중 negative pair간 연산에 불리하기 때문에 tau를 활용한다고 합니다. 지수함수로 인해 값이 튀는 것을 잡아주는 역할이라고 생각하시면 될 것 같습니다. training setting에 따라 0.05~1 사이의 값 중 하나를 취해줍니다.
안녕하세요 리뷰 잘 봤습니다.
Contrastive Learning에서 보통은 배치 사이즈가 중요하다고 하는데 그 이유에 대해서 좀 더 자세히 설명해줄 수 있을까요?
contrastive learning에서 큰 배치 사이즈를 가져가려고 하는 이유는 negative pair 개수를 최대한 많이 가져가려고 하기 위함입니다. negative pair가 많을수록 학습에 유리하기 때문이죠. 학습을 진행할 때, Batch size B에 대해서 2*B by 2*B similarity matrix를 만들어 loss 구성에 이용합니다. 이 때 행렬의 주대각선은 positive pair, 나머지는 negative pair 값으로 채워지게 됩니다. 학습을 진행할 때 negative pair는 contrastive learning에 중요한 정보를 주는데, 이런 negative pair가 많을수록 정보가 많아져 loss의 학습에 유리하게 되고, negative pair를 많이 확보하기 위해서는 (batch 내부 positive pair 1개 이외는 전부 negative pair로 취급하니)필연적으로 batch size가 커지게 된다는 흐름으로 이해하시면 좋을 것 같습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
한가지 궁금한 점이 있는데,, 본 논문이 data augmentation을 contrastive learning에 처음으로 사용한 논문으로 이해했습니다. 기존에는 네트워크 구조상에서 receptive field를 제한해서 global to local view prediction을 구성하는 방식을 사용해왔다고 하셨는데요, ,, 생각해봤을 때 두 sample을 만들 때 하나는 local한 정보 위주로 추출하고 하나는 global정보를 추출해서 positive pair로 보는 것 같은데 이는 단순히 crop을 하는 것과 동일한 효과를 보이는 것 같습니다. 그렇다면,, data augmentation을 사용한 SimCLR의 등장 이후로는 global to local view prediction 방식은 사용하지 않는 방향으로 연구가 이뤄졌나요 ?
감사합니다 !
음 약간 정정하자면, 이 논문이 data augmentation을 contrastive learning에 처음으로 사용했다기 보다는 contrastive prediction task 정의를 data augmentation으로 한 것이 최초라고 생각하시면 됩니다. global->local view prediction이나 context matching같은 경우 기존에는 모델 구조를 이용해서 해당 task를 구현했는데, SimCLR같은 경우는 이런 방법을 활용하지 않게 되었다기 보다는 해당 모델 부분을 삭제하고 data augmentation을 통해 똑같은 기능을 프레임워크 안에 통합시켰다고 생각하시면 될 것 같습니다. 따라서 global->local view prediction은 계속 활용되고 있으며, 이제는 네트워크 구조로 구현되는게 아닌, augmentation을 통해 이루어지게 통합되었다고 볼 수 있습니다.
안녕하세요 허재연 연구원님. 좋은 리뷰 감사합니다.
제목과 간단한 개념만 아는 논문이였는데, 읽어보니 재밌네요. 전체적으로 설명을 잘 해주셔서 읽는 것에 큰 어려움이 없었습니다.
간단한 질문 하나만 하자면, 그렇다면 해당 방식은 pretext task를 통해 downstream task를 진행하는 것이 최종 목적일텐데, 그렇다면 downstream task에서는 단순히 pretext task를 통해 획득한 representation power를 활용하는 것 이외의 의의는 따로 없을까요? 이를테면 detection, segmentation, 혹은 아예 다른 도메인의, time을 필요로하는 video 등에서도 가능할지, 가능하다면 어떻게 쓰이는지 궁금합니다!
음.. 제가 아직 contrastive learning을 포함한 self-supervised learning이 실제 field에서 어떻게 활용되는지까지는 follow-up하지 않아서 정확한 답변을 드리기 어려울 수 있을 것 같긴 하지만, 나름 제 생각을 말씀드려보겠습니다. self-supervised learning 자체가 unlabeled data로 다른 task를 정의해 학습을 진행함으로 (downstream task에 온전히 fit하지 않더라도) 어느정도의 표현력을 모델이 미리 학습하게 하는 것에서 비추어 봤을 때, 결국 핵심은 downstream task에 사용할 representation을 최대한 확보하자는것으로 생각됩니다.
domain과 task에 대해서 생각해보자면, 결국 contrastive learning이 vector간 유사도를 이용해 학습하기 때문에 feature extraction을 통해 벡터로 기술할 수 있는 data에 대해서는 광범위하게 사용될 수 있을 것이라 생각됩니다. 말씀드린 video로 예시를 들어보자면, video를 1024차원의(고정된 크기의) 벡터로 기술할 수 있다면 비디오 역시 contrastive learning을 통해 모델이 어느정도의 비디오에 대한 표현력을 갖출 수 있을 것으로 보입니다. task에 대해서 생각해보면 pretrain을 통해 데이터 자체에 대한 표현력을 모델이 학습하기 때문에 classification, localization, segmentation, detection 등 어느 task에 대해서도 활용할 수 있을 것으로 생각됩니다. 특정 task에 fit하게 학습된게 아니라 데이터 전반의 표현 자체를 학습하였기 때문입니다.
pretrain을 활용한 방법론의 본질에 대해 고찰하게 만드는 질문이었습니다. 좋은 질문 감사합니다.
첨언하자면, 관련 논문을 몇 편 보았을 때 pretext task와 contrasitve prediction task는 서로 분리해서 사용하는 개념으로 보입니다. 1.pretext task란 본 리뷰의 background에서 말씀드렸듯 각도 맞추기, 직소 퍼즐 풀기, 색상 맞추기 등 사람이 직접 설계한 pretrain task를 지칭하고(머신러닝에서 고전적인 handcrafted feature engineering과 비슷한 느낌일 수 있죠. 일반성이 떨어질 수 있습니다. 사진 각도 맞추기 task로 자연어 데이터를 학습시킬 수는 없을 것입니다), 2.contrastive learning은 벡터의 유사도를 측정해 positive/negative pair를 feature space에 적절히 위치시키게 학습하는 방식을 지칭하는 것이라 생각하시면 좋을 듯 합니다.
재연님 좋은 리뷰 감사합니다!!
self-supervised learning이 궁금하던차에 관련 내용을 정리해주신게 있어서 읽어보게 되었습니다.
pretext와 증강의 본질적 차이는 정확히 무엇인가요? 뭔가 본질적으로는 비슷하다고 느껴지는데 pretext라는게 잘 와닿지가 않아서 질문 드립니닷
범주와 목적이 다릅니다. 증강은 아시다시피 기존 데이터를 다른 형태로 변형을 주는 것이고, pretext task는 raw data만 있고 명시적 annotation이 없는 상황에서 데이터 자체만을 가지고 학습을 진행할 수 있도록 task를 구성하여 우회적으로 데이터 표현력을 학습하는 것입니다. 따라서 augmented 된 데이터를 가지고도 pretext task를 구성하여 학습을 진행할 수 있습니다. pretext task를 구성하는 방법에 따라 augmentation을 활용할수도 있겠죠.