안녕하세요, 여덟번째 x-review 입니다. 이번 논문은 transformer를 기반으로 한 3D Object Detection 방법론인 3DETR 입니다. 그럼 바로 리뷰 시작하겠습니다 !

1. Introduction
irregular하고 sparse한 포인트 클라우드를 처리하기 위해 voxel이나 mesh 형태로 변환할 경우 그 과정에서 정보 손실이 발생할 수 있습니다. 그래서 포인트 자체를 입력으로 하는 3D Object Detection 연구가 진행되고 있었는데 저자는 그 중 VoteNet에 주목하였습니다. VoteNet은 endcoder-decoder 구조로 encoder에서 PointNet++을 통해 입력 포인트를 특징을 가진 포인트 집합으로 변환합니다. 그럼 decoder로 그 집합이 입력으로 들어가게 되고 3D bounding box를 만들 수 있게 됩니다. 저자는 이러한 방식이 효과적이긴 하나, inductive bias나 집합을 만들기 위한 기준이 되는 반경 등을 hand-encoding 해야 하기에 detection 구조를 만들 때 많은 신경을 써야 한다고 말합니다. 그러나 포인트 집합에 대해 set-to-set encoder-decoder 구조로 모델링하는 것 자체가 효과적인 것은 자명하기에 2D detection에서 사용하는 DETR을 encoder-decoder 모듈에 활용하고자 하였습니다. 트랜스포머의 self-attention은 permutation invariant 하기에 순서가 없는 3D 포인트 클라우드 데이터를 다루기에 적합하지 않을까라고 예측하게 됩니다. 그러나 트랜스포머를 위에서 언급한 hand crafted inductive bias에 의존하지 않고 3D object detctor로 사용할 수 있을까요? 본 논문에서는 이에 대한 해답으로 적은 hand crafted decision을 사용하면서 detection을 set-to-set 문제로 끌고오는 3D detection transformer 일명 3DETR을 제안하게 됩니다. 기존 DETR과 VoteNet이 모두 encoder-decoder 구조로 되어있다는 공통점을 기반으로 VoteNet의 encoder인 PointNet++을 trasformer 구조로 변경하고, decoder의 경우 3D detection이라는 task에 맞게 변형한 구조가 바로 3DETR 입니다. DETR과 달리 3DETR은 ConvNet을 백본으로 사용하지 않고 오로지 트랜스포머 기반으로 학습하며 구조를 다른 모듈로 쉽게 대체할 수 있는 유연성을 가집니다. 해당 방법론은 3D indoor dataset인 ScanNet과 SUN RGB-D에서 기존의 VoteNet 성능을 최대 mAP 9.5% 이상의 차이를 두고 뛰어넘는 실험 결과를 보였다고 합니다.
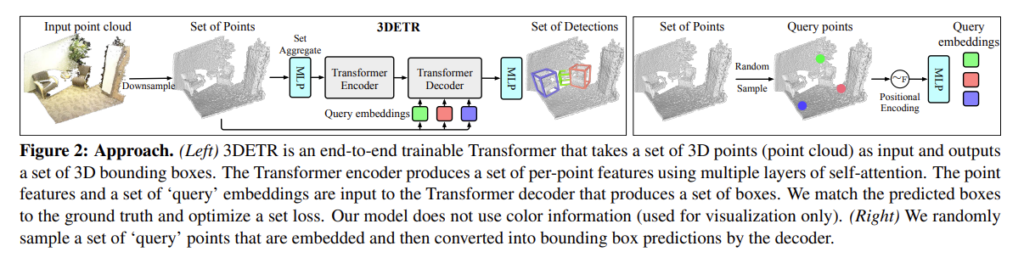
2. Approach
2.1. 3DETR: Encoder-decoder Transformer
이제부터 3DETR의 구조에 대해 살펴볼텐데요, 우선 3DETR은 포인트 클라우드를 입력으로 받아 3D bounding box를 형성하여 물체의 위치를 예측하게 됩니다. 포인트 클라우드는 3차원 xyz 좌표를 가지고 순서가 없는 형태로 N개의 포인트가 입력으로 들어오게 된다고 가정하겠습니다. 이 N이라는 숫자는 매우 많은 양의 포인트를 의미하기 때문에 PointNet++의 방식을 이용하여 N’차원으로 downsampling 하고 각 포인트에 대한 feature을 aggregation하게 됩니다. encoder에는 해당 feature을 입력으로 하고 별도의 downsampling 없이 출력으로 같은 차원의 feature을 출력합니다. 그럼 decoder로는 set 형태의 point feature가 입력으로 들어가서 bounding box를 예측하게 되는 것이죠. encoder와 decoder을 나누어 더 자세하게 알아보도록 하겠습니다.
우선 sampling과 set-aggregation 통해 제공되는 d 차원 ( d= 256 ) N’개의 포인트에 대한 feature를 입력으로 하여 기존 transformer encoder 구조를 그대로 따르는 encoder을 통과합니다. 트랜스포머 안에서 downsampling 없이 여러개의 layer에서의 self attention이 이루어지기 때문에 결국 입력값의 차원 그대로 d-dimension의 feature을 출력하게 됩니다. 다만 encoder로 들어가는 입력값의 경우 포인트의 xyz 좌표에 대한 정보가 포함되어 있기 때문에 좌표에 대한 positional embedding을 생략하였다고 합니다.
decoder의 입력으로는 encoder의 출력 뿐만 아니라 이전의 sampling 된 point를 기준으로 embedding한 B개의 query를 제공합니다. 이 두가지 형태의 정보를 통해서 여러개의 transformer block가 병렬적으로 이루어진 decoder에서 bounding box를 예측할 수 있습니다. 여기서 저자는 예측되는 박스에는 특정한 순서가 없다고 이야기하는데요, 추측하기로 어떤 박스를 언제 예측하든 해당 박스가 탐지하고자 하는 물체는 바뀌지 않기에 정해진 순서 없이 박스를 예측한다고 말한 것 같습니다. 또한 박스를 예측할 때 사용되는 위치라고 함은 B개의 query embedding \{q^e_1, . . . , q^e_B\}이 되기 때문에 결국 이 query들이 object가 위채할 가능성이 있는 여러 개의 3D 공간의 지점을 뜻하게 됩니다. decoder 내에서 자체적으로 좌표를 알아낼 방법이 없기에 positional embedding을 통해서 3D 공간에서의 상대적인 위치를 사용할 수 있는 것 입니다.
계속해서 query embedding에 대하여 이야기하고 있는데, 해당 방법론에서의 embedding은 Non-parametric query embedding이라고 명시하고 있습니다. 저자는 VoteNet에서 사용하는 seed point를 기반으로 해당 embedding을 사용하였다고 합니다. N’개의 샘플링된 포인트를 VoteNet에서처럼 일명 seed point로 정의하고 어떠한 파라미터를 사용해야하는 과정을 거치지 않고 seed point의 XYZ 좌표에서 바로 embedding을 계산합니다. 다시 말해서 Farthest point sampling (FPS)로 N’차원의 입력 포인트에서 B개의 query point를 (VoteNet에서는 seed point) 샘플링 하게 됩니다. B개의 query point \{q_i\}^B_{i = 1}은 Figure2의 오른쪽처럼 Fourier positional embdding으로 변환하고 MLP를 통해 최종 query embedding vetor를 생성함으로써 decode에게 포인트의 위치 좌표를 제공할 수 있습니다.
앞선 introduction에서 hand crafted inductive bias에 의존하지 않은 3D object detector라고 언급하였는데, 이를 위해 저자는 모델의 구조를 다른 모듈로 대체하는 것이 자유자재로 가능하기 위해서 3DETR-m이라는 구조를 추가로 제안합니다. decoder와 loss는 고정한채로 encoder만을 3D data에서로 한정된 inductive biase를 포함한 구조로 변형하게 됩니다. PointNet++에 영감을 받아, 3D data에서는 global feature보다는 local feature에 집중해야 한다고 가정하면서 이러한 inductive bias는 encoder의 self-attention에 대해 masking을 도입함으로써 쉽게 이용할 수 있다고 주장합니다. 기존 3DETR은 encoder에서 별도의 downsampling을 진행하지 않았는데, 3DETR에서는 3개의 layer를 사용하여 첫번째 layer 이후에 N’ = 2048, N’’ =1024 point로 다운 샘플링하는 과정을 거치게 됩니다. 모든 layer에서 self-attention 연산에 N’’ x N’’ 이진 마스크를 적용하는데 여기서 N’’은 포인트 i에서 특정 반경 내에 포함되어 있는 N’’개의 포인트를 의미합니다. 반경 범위는 [0.16, 0.64, 1.44]로 이진 마스크를 통해 관계를 계산하는 대상을 특정 범위의 포인트로 제한함으로써 local feature에 집중해야한다는 3D의 inductive bias를 활용할 수 있게 되는 것 입니다.
2.2. Bounding box parametrization and prediction
Figure2.에서 encoder-decoder을 거친 B feature는 MLP를 지나면서 bounding box를 예측합니다. 3D bouning box는 (1)location 정보, (2)박스의 size, (3)orientation, 그리고 (4)박스 안에 포함되는 물체의 클래스 정보가 포함되어 있는데, 이제부터 위 4개 속성과 각 속성들의 parametrization에 대해 이야기해보도록 하겠습니다.
(1) Location & (2) Size
박스의 위치를 나타내기 위해서 XYZ 좌표와 박스의 중심 좌표인 c를 이용하는데, 위에서 설명하였듯이 예측된 bounding box는 모두 query point를 기준으로 만들어지는 것입니다. 따라서 query point q 위주로 bounding box가 만들어지기 때문에 박스의 중심 좌표를 query point와의 차이인 \vartriangle q를 이용하여 c = q + \vartriangle q로 표현합니다. 또한 bounding box는 대체로 직육면체 모양이며 C를 기준으로 XYZ 차원으로 사이즈를 정의합니다.
(3) Orientation
3D bounding box 중 OBB의 해당하는 경우에는 박스의 방향 또한 예측해야 합니다. 회전한 각도를 알기 위해서 우선 [0, 2\pi) 범위의 앵글을 12개의 ‘class’로 quantization을 진행합니다. 그럼 12개의 양자화된 클래스 중에서 하나를 회전한 앵글이라고 예측을 하게 되겠죠. 이 때 예측된 앵글은 discretized angle을 의미하는데, 이렇게 클래스로 예측한 각도의 경우에는 [0, 2\pi) 범위의 무수히 많은 각도 중 12개로 크게 나누어 하나를 선택한 것이기 때문에 정확한 예측이 아닐 수 있습니다. 그래서 실제 회전한 각도와 예측한 클래스 각도 사이의 차이가 발생할 수 있는데 이러한 차이가 quantization residual 입니다. 결국 discretized angle이 아닌 continuous angle a을 구하기 위해서 예측한 클래스를 구하고 실제 앵글과 예측한 클래스 앵글이 최대한 가까워지는 방향으로 quantization residual까지 예측하는 것을 통틀어 angular prediction이라고 할 수 있습니다.
(4) Semantic Class
각 박스마다 예측한 class는 one-hot vector을 통해 표현합니다. 예측된 bounding box \hat{b}는 결과적으로 [\hat{c}, \hat{d}, \hat{a}, \hat{s}]로 구성되는데 그 중 [\hat{c}, \hat{d}]는 기하학적인 정보로 \hat{c}, \hat{d} \in [0, 1]^3, 즉 박스의 중심과 각각의 차원을 의미하게 되고 \hat{a} = [\hat{a}_c, \hat{a}_r]은 각각 예측한 양자화 클래스와 잔차 앵글을 나타냅니다. 마지막으로 \hat{s} = [0, 1]^{K + 1}이 semantic 정보로 K개의 class와 background class, 총 K + 1개의 class에 대한 확률 분포를 나타내는 벡터로 확률에 따라 예측하는 class를 알 수 있겠죠. GT box b 또한 동일한 형식으로 표현합니다.
2.3. Set Matching and Loss Fuction
Bipartite Matching
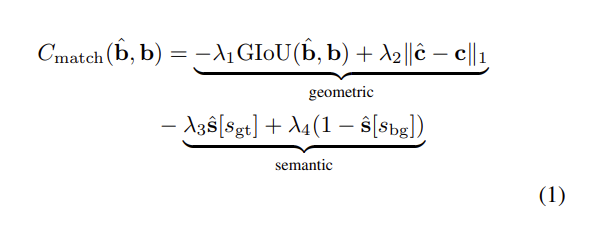
모델을 학습하기 위해서 먼저 예측한 3D bounding box의 집합인 {\hat{b}}와 GT box {{b}}을 매칭합니다. VoteNet에서는 이러한 매칭을 위해서 반경을 미리 정해놓았어야 하였지만 본 논문에서는 더 간단하고 일반성을 띌 수 있으며 NMS와 같은 알고리즘에 robust 할 수 있도록 DETR의 bipartite graph matching을 활용하였습니다. 예측된 박스와, 각각의 예측 박스와 매칭된 GT 박스를 사용하여 loss를 계산하게 됩니다. Bipartite matching에 대해 먼저 알아보자면, {\hat{b}}와 {{b}} 쌍의 3.3.절에서 정의한 geometric, semantic 정보를 통해 식(1)과 같이 매칭 cost를 먼저 정의합니다. 우선 geometric cost는 예측 박스와 GT 박스 사이의 GIOU를 구하여 overlap이 얼마나 되어있는지를 계산하고, 실제 박스의 중심값과 예측한 박스의 중심값 사이의 거리를 계산합니다. semantic cost에서 [s_{gt}]는 실제 클래스이고 [s_{bg}]는 \hat{s}에서 배경이라고 예측한 확률을 의미합니다. 따라서 \hat{s} 벡터에서 클래스 당 확률과 GT class와 비교하여 GT class에 해당하는 클래스의 확률이 높을수록 옳은 예측을 한 것을 의미하며, 또 한 가지는 물체가 있다는 판단하에 박스를 예측한 것이기에 background라고 예측하지 않은 확률, 즉 foreground로 예측한 확률을 고려하여 semantic cost를 계산하게 되는 것 입니다. semantic cost가 바로 NMS와 같은 알고리즘에 강인할 수 있음을 뒷받침하고 있는데, 물체의 클래스 예측에 대한 확률을 계산하고 박스가 background를 검출할 확률을 감소시킴으로써 물체가 over-predict 되지 않도록 컨트롤할 수 있습니다. 그렇기에 겹치는 박스들을 줄이면서 물체에 대해 정확하게 한 번만 탐지하는 방향으로 학습하면서 NMS에 강인할 수 있다고 합니다.
Loss function
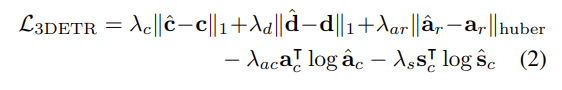
3DETR의 전체적인 Loss function은 식(2)와 같습니다. 박스의 center와 dimension에 대해서는 scale invariance를 위해 0과 1사이의 범위로 normalization한 L1 regression loss를 사용하였으며, 잔차 각도는 Huber regression loss, 양자화된 클래스 앵글을 분류하는 것과 semantic classification에는 cross entropy loss를 사용하였다고 합니다. 모든 loss는 클래스 예측을 foreground 중 하나로 예측하였을 경우에 계산하고, 박스가 background로 클래스를 예측할 경우에는 semantic classification loss만을 계산하게 됩니다.
3. Experiments
실험에는 indoor dataset인 ScanNetV2와 SUN RGB-D를 사용하였습니다.
3.1. 3DETR on 3D Detection
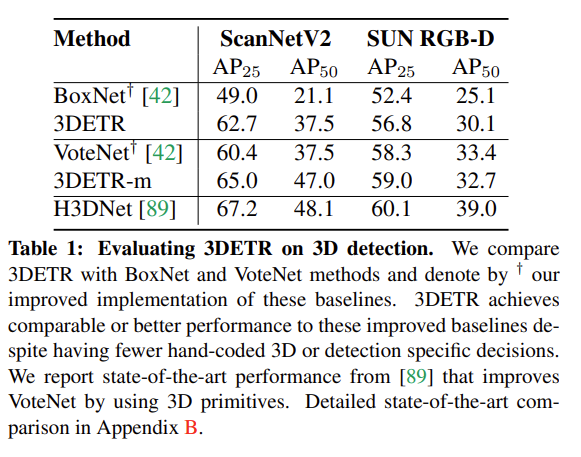
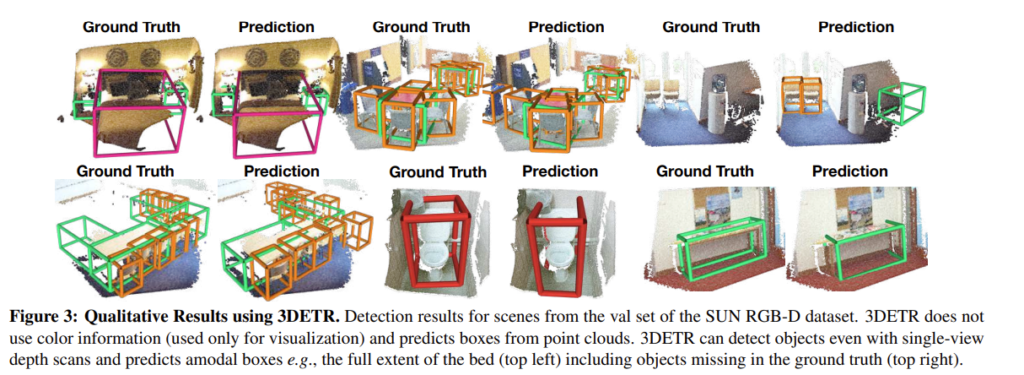
다른 3D Object Detection 방법론과 비교한 실험 입니다. BoxNet은 VoteNet에서 voting 기법을 사용하지 않고 seed point에서 바로 clustering을 진행한 모델로, VoteNet 논문에서 베이스라인으로 삼기 위해 제시했던 구조 입니다. 아무래도 3DETR이 VoteNet의 encoder-decoder 모듈을 트랜스포머로 대체한 구조이다보니 BoxNet과 VoteNet 대비 어느정도의 성능 향상이 있었는지를 보여주는 실험인 것 같습니다. 당시 sota 방법론이었던 H3DNet보다는 낮은 성능을 보이지만, 저자는 VoteNet보다 대부분 높은 성능을 보이며 transformer 구조로 변형한 것이 유의미한 성능 향상을 보여준다고 말하고 있습니다.
4.2. Analyzing 3DETR
4.2.1 Modules of VoteNet and BoxNet vs 3DETR
3DETR의 장점 중에 하나로 다른 모듈로 쉽게 대체할 수 있음을 강조하였었는데, 해당 파트는 encoder와 decoder, Loss를 타 모듈로 (여기서는 VoteNet과 BoxNet 구조) 유연하게 바꾸어서 사용할 수 있으며 그에 따른 성능을 리포팅하였습니다.
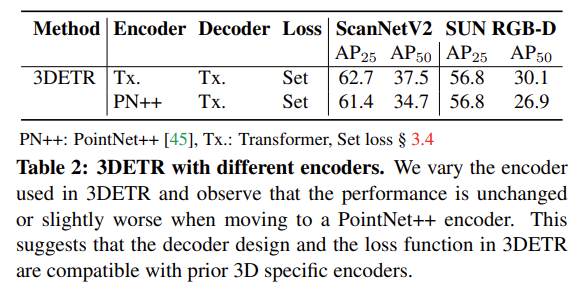
우선 Table2는 3DETR의 encoder을 PointNet++로 바꾸었을 때의 실험 결과로 기존 모듈과 PointNet++을 사용하였을 때를 비교해보면 차이가 없거나, 근소하게 하락한 것을 볼 수 있습니다. 저자는 이를 통해 3DETR이 넓은 범위의 타 방법론들과 호환되어 사용될 수 있으며 더 나은 encoder 모듈을 설계하는데 도움이 될 수 있다고 강조하고 있습니다.
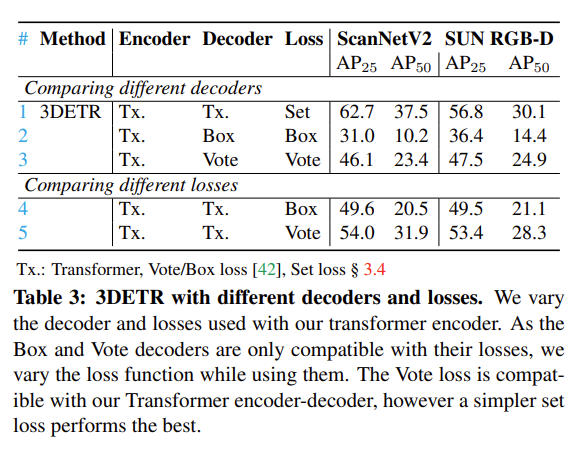
Table3은 반대로 encoder는 고정한채, Decoder와 Loss를 각각 BoxNet과 VoteNet의 decoder, BoxNet과 VoteNet의 loss로 대체하였을 때의 실험 결과 입니다. 우선 Table3에서 Decoder와 Loss를 모두 변경하였을 때는 성능이 눈에 띄게 하락한 것을 볼 수 있습니다. 저자는 이러한 결과에 대해서 원래 3DETR의 decoder는 ransformer 기반 encoder와 함께 사용하였는데, BoxNet과 VoteNet의 decoder로 변경하면서 발생한 결과라고 합니다 .. 그래서 Table3의 아래 결과를 보시면 decoder까지 transformer 기반 모듈로 고정을 하고 Loss만 타 방법론으로 변경한 결과 decodr까지 변경하였을 때 만큼은 아니지만 성능이 마찬가지로 하락한 것을 볼 수 있습니다. 이는 VoteNet의 loss의 경우 PointNet++ encoder에 사용되는 반경 파라미터에 맞게 설계되어 있기 때문에 3DETR의 encoder를 사용할 경우 성능 하락이 발생할 수 있다고 합니다. 사실 위의 실험을 통해 오히려 변경할수록 encoder-decoder-loss가 서로 적합하게 설계되어 있지 않다면 대체하더라도 성능 하락만을 가지고 오는 것 같다는 생각이 들었지만 .. 유연하게 모듈이 변경 가능함을 보여줬다는 부분만 기억해주시면 좋을 것 같습니다 ..
5. Ablation
Effect of NMS
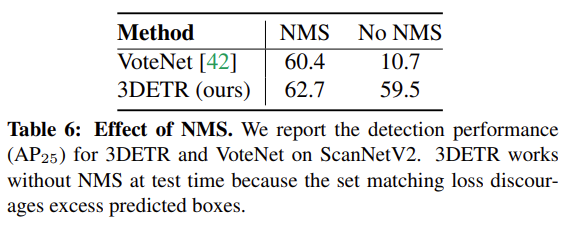
본문에서 Bipartite Matching을 사용함으로써 NMS에 더 강인할 수 있다는 주장을 뒷받침하는 ablation study 입니다. VoteNet과 비교하여 NMS를 적용하였을 때와 사용하지 않았을 때를 비교한 결과, VoteNet은 NMS 사용 유무에 따라 AP가 거의 50% 하락하는 반면 3DETR은 미세한 차이만 있을 뿐 극단적으로 성능이 떨어지지 않음을 보여주면서 NMS에 강인하다는 사실을 입증하고 있습니다.
안녕하세요, 좋은 리뷰 감사합니다.
Introduction section에서 질문이 하나 있습니다.
“트랜스포머의 self-attention은 permutation invariant 하기에 순서가 없는 3D 포인트 클라우드 데이터를 다루기에 적합하지 않을까라고 예측하게 됩니다.”
라고 작성을 해주셨는데 3D detection을 위해 point cloud를 대부분 사용하여 task를 해결하려는 추세인 것으로 이해를 하고 있습니다. 순서에 따른 불변성을 self-attention이라는 방법을 통해 해결하는 것에 중요한 역할을 할 것 같은데, 해당 self-attention이라는 방법론을 필수적으로 사용을 하나요? 아니면 다른 방법을 통해 permutation-invariant하도록 하나요?
감사합니다.
안녕하세요 ! 댓글 감사합니다.
해당 방법론은 self-attention을 사용하고 있기는 하나 .. 저도 아직 3D Object Detection에서 transformer 기반의 논문은 해당 논문이 처음이라 타 방법론에서 self-attention을 필수적으로 사용하는 지까지는 잘 모르겠습니다 .. . . 추후 transformer 기반 논문을 좀 더 읽어보고 추가 답변 드리도록 하겠습니다 !
좋은 리뷰 감사합니다.
approach에서 “다만 encoder로 들어가는 입력값의 경우 포인트의 xyz 좌표에 대한 정보가 포함되어 있기 때문에 좌표에 대한 positional embedding을 생략하였다고 합니다.”라고 하셨는데 앞에서 입력을 pointnet++에 태워 얻은 feature로 사용한 것으로 보이는데 그럼 original x,y,z 정보를 어떻게 활용하는건가요?
그리고 3Detr-m의 경우는 실험부분에서 3%정도나 좋은 결과를 보이는데 downsampling시 self-attention을 할 때 local한 부분에 집중하기 위해 binary masking을 한 것이 차이의 전부인지 궁금합니다.
감사합니다.
안녕하세요 ! 댓글 감사합니다.
먼저 제가 알기로 pointnet++을 거친 출력값에는 각 point의 feature 정보와 더불어 xyz 좌표 정보가 포함되어 있는것으로 알고 있습니다.
다음 질문에 대한 대답으로는 3DETR과 3DETR-m의 차이는 masking self-attention의 사용 유무만 존재하는 것이 맞습니다.
안녕하세요. 리뷰 잘 읽었습니다.
DETR을 3D object detection에 적용한 방법론이군요.
1. 우선은 위의 희진님의 질문에 이어 먼저 질문하자면, transformer의 self-attention 개념이 permutation-invairant를 만족하며 3D point cloud는 2D pixel image에 비해 수가 워낙 많다보니 PointNet++의 downsampling 방법을 사용한다고 했는데, 그럼 PointNet++의 downsampling 방법은 무엇인가요? 우려했던 점인 computational resource가 높은 지적을 downsampling을 통해 극복한 것으로 보여, PointNet++의 downsampling 방식이 어떤 것인지는 정확히 모르나 그럼 단순히 하나의 Point를 잡고 반지름을 정해 반경 내 점들은 하나의 점군의 집합으로 만들어 self-attention 연산을 하는 것 같은데, 이는 아래 질문에 연이은 부분으로 오히려 global feature에 집중하고자 local feature들을 마스킹하는 것이 아닌지 궁금합니다. 이처럼, 이는 왜 self-attention이 3D에서 유용한지에 대한 고찰이 우선적일텐데, 단순히 transformer가 NLP, 2D에서 좋았다니 3D에서 적용해봐야지였는지, 혹은 3D라는 데이터 도메인에서 transformer만의 장점이 있는지 궁금합니다.
2. PointNet++에 영감을 받아, 3D data에서는 global feature보다는 local feature에 집중해야 한다고 가정한다고 되어있는데, 이에 대해 왜 그런지 궁금합니다. 사실 Point cloud라함은, 점 하나하나 혹은 확대해서 보면 어떤 객체인지 확정할 수 없으나 오히려 global적으로, 쉽게 생각하면 축소해서 보면 어떤 객체인지 오히려 눈에 잘 띄는데 왜 local feature에 집중하는 것이 좋은지 의문입니다.
3. 다음으로는, Bipartite matching에서 geometric cost와 semantic cost의 과정과 의의에 대해서는 이해가 가지만, 이 둘을 빼주는 이유는 무엇인지 궁금하네요. 원본 DETR에서의 Bipartite matching은 학습을 하지 않는, 즉 backpropagation이 없는 그래프 상의 최적의 매칭을 구하기 위한 알고리즘으로 사용되었는데 지금은 마치 학습을 하는 것 처럼 보여, 이 bipartite matching이 실제 어떻게 사용되는지 궁금합니다.
4. 3D object detection에서 OBB 형태의 bounding box가 있음은 처음 알았는데 (물론 아직 해당 분야의 논문을 몇 개 읽어본 적이 없지만), 이를 위해 잔차 각도를 계산함을 이해했습니다. 그렇다면 실제 3D 상의 OBB bounding box는 잔차 각도가 있다고 할 때, AABB 형태의 bounding box에서 어떤 방식으로 계산되는지 궁금합니다. 2D에서는 단순히 Affine 변환을 하면 되지만, 3D에서는 생각해야할 점이 조금 더 있을 것 같은데.. 궁금하네요.
5. 실험 파트에서 abaltion study의 ” Bipartite Matching을 사용함으로써 NMS에 더 강인할 수 있다는 주장”을 뒷받침 하는 실험이 왜 본 실험인지 궁금합니다. Bipartite Matching + NMS를 사용하면 더 좋다는 의미인가요?
3D detectioin, 어렵네요. 좋은 리뷰 감사합니다.
안녕하세요 ! 댓글 감사합니다.
1. 우선 PointNet++의 downsampling이라고 함은 제가 생각했을 때 N x 3 차원으로 들어오는 입력 포인트를 N’ x 3 차원의 포인트로 샘플링하는 것을 다운 샘플링으로 지칭하여 사용하는 것 같습니다. 저자가 transformer을 point cloud에 적용하려고 했던 이유는 나이브하게 transformer에서 self-attention이 permutation invariant한 속성을 가지고 있기에 순서가 없는 3D Point cloud data에 사용하기 적합할 것이라는 가정에서 시작된 것 입니다.
2. PointNet++의 경우 기존 PointNet이 global feature에 집중한 부분을 지적하며 local feature에 가중치를 둠으로써 포인트의 메트릭 정보를 통해 얻을 수 있는 local feature을 확보하지 못한다는 단점을 보완하여 작은 패턴에 대한 인식 능력이나 복잡한 scene에 대한 일반성을 높이고자 만들어진 방법론이기에 .. 그런 contribution을 따온 것이 아닐까 생각합니다.
3. Bipartite matching 앞의 계수를 weight를 부여해주는 정도로 이해를 했어서 정확히 두 cost가 어떤 연산이 된다고는 생각하지 못했네요. 그러나 논문에서도 두 cost를 빼는 것에 대한 설명은 없었던 것 같습니다. .. 그리고 Bipartite matching의 사용은 DETR과 동일하게 진행됩니다.
4. bounding box가 OBB 형태로 주어질 경우 (예를 들어 SUN RGB-D) annotation 정보에서 실제 orientation인 앵글 값이 주어집니다. 그래서 예측한 앵글 값과 gt 값의 차이에 따라 예측하게 되는데요, 아직까지 AABB→OBB로 변환하는 과정에 대해 다루는 방법에 대해 접해본 적이 없지만 .. 질문해주셔서 찾아본 결과, AABB의 중심값 좌표를 구하고 박스 내부의 포인트들에 대한 공분산 행렬을 구하면 중심점을 기준으로 해당 점들이 어떤 방향으로 분포하고 있는지를 알 수 있을 것 입니다. 그렇다면 공분산 행렬에 대한 PCA를 통해 주성분을 구하게 되면 OBB의 방향을 나타낼 수 있을 것이라고 생각됩니다 .. 하지만 이는 논문이나 공식적인 자료에서 찾은 것이 아니라 정확하지 않을 수 있어 추후에 좀 더 정확한 과정을 알게 되면 추가적으로 전달해드리도록 하겠습니다
5. 해당 실험이 NMS에 강인함을 입증할 수 있다고 한 이유는 본문에서 Bipartite matching을 사용함으로써 물체의 클래스 예측에 대한 확률을 계산하고 박스가 background를 검출할 확률을 감소시킴으로써 물체가 over-predict 되지 않도록 컨트롤할 수 있기에 겹치는 박스들을 줄이면서 물체에 대해 정확하게 한 번만 탐지하는 방향으로 학습하면서 NMS에 강인할 수 있기 때문이라고 적어놓았는데요, 때문에 Bipartite matching이 포함된 3DETR이 Bipartite matching을 적용하지 않은 VoteNet에 비해 NMS 적용 유무와 상관없이 유사한 성능을 보이며 성능 변화에 있어서 NMS가 큰 영향을 끼치지 않음을 보였기 때문이라고 할 수 있습니다. 말씀하신 Bipartite Matching이 NMS와 함께 사용하면 더 좋다는 의미는 약간 다르게 해석된 것 같으며, 사용할 때/사용하지 않을 때의 영향을 받지 않으며 강인한 성능을 보인다고 이해해주시면 좋을 것 같습니다.
안녕하세요. 좋은 리뷰 감사합니다.
헷갈려서 질문 드리는데, 3DETR은 포인트 클라우드를 입력으로 받는다고 하셨는데, 굉장히 많은 포인트가 존재하기에 N’차원으로 downsampling하고 각 point feature를 aggregation하였다고 하셨습니다. 근데 또, encoder의 입력으로는 sampling과 set aggregation을 통해 256차원의 N’개의 포인트가 입력으로 들어간다고 하셨어서 ,, 위에 N’차원으로 downsampling한 것과 N’개의 포인트를 입력으로 넣는데 N’은 256인가요 .. ?
또, decoder를 통해 예측되는 박스에는 특정한 순서가 없다고 하셨고, 이에 대한 이유를 추측하기로는 어떤 박스를 언제 예측하든 해당 박스가 탐지하고자 하는 물체는 바뀌지 않기에 정해진 순서 없이 박스를 예측한다고 말한 것 같다고 하셨는데,, 이보다는 기존 DETR이 direct set prediction에서 object detection 문제를 해결하려 했던 것처럼,, 이와 마찬가지로 3D object detection을 set prediction problem으로 해결하려 했던 건 아닌지,, 궁금하네요.
마지막으로 “기존 3DETR은 encoder에서 별도의 downsampling을 진행하지 않았는데, 3DETR에서” 이 문장에서 두 번째로 언급되는 3DETR은 3ㅇDETR-m을 의미하는 것인가요 ? 여기서 N’’xN’’ 이진 마스크를 적용할 때 N’’을 결정하는 특정 반경 범위 [0.16, 0.64, 1.44]는 어떻게 정해진 것인가요 ? 실험적으로 정해진건지.. 아니면 통상적으로 해당 task에서 원래 사용하던,, 것인지.. 각각 x, y, z축 거리로 보면 될까요 ?
감사합니다 !!!
안녕하세요 ! 댓글 감사합니다.
N’이 256차원이 되는 것이 아닌, feature을 뽑게되면 N x 3 차원 → N’ (포인트 수 ) x 3 x C (feature 차원) 으로 표현할 수 있는데 여기서 d는 feature차원인 C를 의미하게 됩니다.
두번째로 3D object detection을 set prediction problem으로 해결하려 했던 건 아닌가라는 질문에 대해서는 .. 맞습니다. 논문의 contribution 자체가 3D Object Detection을 set-to-set problem으로 다루겠다는 것입니다. 제가 말씀하신 것처럼 본문에 적은 이유는 하나의 집합으로 들어가는 포인트 안에서 정해진 순서 없이 포인트들이 차례대로 박스가 만들어짐을 얘기하고 싶었던 것 입니다. 결과적으로는 윤서님이 말씀하신 것과 같은 맥락으로 말한 것인데 제가 조금 .. 헷갈리게 적어놓은 것 같네요.
마지막으로 3DETR-m을 의미하는 것이 맞습니다. 오타가 있었네요 ㅎ ㅎ .. 특정 반경 범위에 대한 것은 저자가 임의로 설정한 값을 사용합니다.
손건화 연구원님 안녕하세요, 좋은 리뷰 감사합니다.
Table 1과 그 이후의 표에서 성능 수치가 나와있는데, 이게 구체적으로 어떤 성능의 수치이고 무엇을 의미하는지 궁금합니다. AP옆의 25, 50은 무엇인가요?
감사합니다.
안녕하세요 ! 댓글 감사합니다.
AP 옆의 25, 50은 각각 IOU threshold 0.25, 0.50으로 지정하는 것을 의미합니다.