안녕하세요. 열 일곱번째입니다. 이번에 리뷰할 논문은 이전의 Aerial Images 관련 object detection을 리뷰와 세미나를 통해 소개하였으며 해당 아이디어를 Pedestrian detection에 적용하고자 실험을 진행했으나 풀고자 하는 데이터 도메인의 차이로 성능 향상이 어려움을 알고서는.. 멘탈이 많이 흔들리는 한 주입니다. 그래도 실험 진행 도중 읽은 논문 중 하나를 리뷰하며 다른 도메인에서의 아이디어를 내 실험에 적용할 수 있을지를, 다음부터는 한번 더 생각해보자는 의미로 글을 시작합니다. 또한 지금은, 그럼에도 불구하고 실험은 진행 중에 있습니다. 그럼 시작하겠습니다.
Introduction
2-stage, 1-stage에 이은 object detection은 주로 MS COCO, Pascal VOC dataset을 대상으로 연구를 진행해오고 있었습니다. 위의 두 dataset에 대해서는 괄목할만한 성능을 보여주었으나 VisDrone과 같은 High pixel resolution 이미지에 대해서는 성능이 좋지 못합니다. 아래 VisDrone dataset은 Aerial image, 즉 항공 view point에서 촬영된 이미지로 저자는 다음의 두 요소로 인해 해당 dataset에서의 성능이 좋지 않음을 말합니다. (1) Aerial viewpoint로 인해, 영상에서 보여지는 객체들의 크기가 매우 작습니다. 이는 Aerial object detection의 숙명이자 Aerial 관련 모든 방법론은 이에 초점을 맞춥니다. (2) viewpoint 외에도 항공에서 촬영하다 보니 영상 내 객체들의 위치 분포가 sparse하며, 일정하게 분포되어 있지 않습니다.

scale challenge에 대해 다시 말하자면, 동일한 object임에도 다른 scale로 보여지며 그 중에서도 small object는 feature representation이 약하므로 그 성능이 하락될 것 입니다. 물론 object detection에서도 small object는 아직 난제의 영역이지만, Aerial object detection에서는 더욱 난제입니다. 해당 문제를 풀고자 이전 연구들에서는 partition, 이미지를 random / uniform crop을 통해 큰 해상도의 이미지를 몇 부분으로 자르는 방법을 사용했습니다. 굉장히 naive한 방법이지만 2019년 이전까지도 딱히 이렇다할 방법이 없었습니다.
저자는 이 부분에서 의문점을 품고 문제점을 말하는데, 예를 들어 2000×1000이미지를 4등분한다면, 하나의 이미지 당 500×250 정도 되며 small object도 detector 내에서는 일종의 reasonable한 수준으로 보일 것입니다. 그렇지만 잘릴 시 object가 잘릴 수도 있으며, 이는 large scale object는 잘릴 확률도 커지겠죠. 즉, small object를 찾고자 잘 찾고 있던 large object를 못 찾게되는 아이러니한 상황에 빠집니다. 아래 Figure 1을 보면, 이미지를 Evenly (uniform)하게 잘랐을 때의 또 다른 단점을 보여주는데, 객체들이 sparse한 영역과 dense한 영역이 구분지어진 경우가 많아, 잘랐을 때의 영상 (Grid, 아래 Figure의 회색 바)이 Sparse한 Chip들이 많아집니다. 물론 Multi-class object detection의 경우 배경을 학습하는 것이 모델의 일반성에 좋다는 의견이지만, 평가까지 생각한다면 10장의 영상을 평가할 때 9개의 영역으로 자른다면 90장의 영상이 되는데, 그 때의 computation resource, FPS 등을 생각한다면 아쉬운 방법임은 분명합니다.
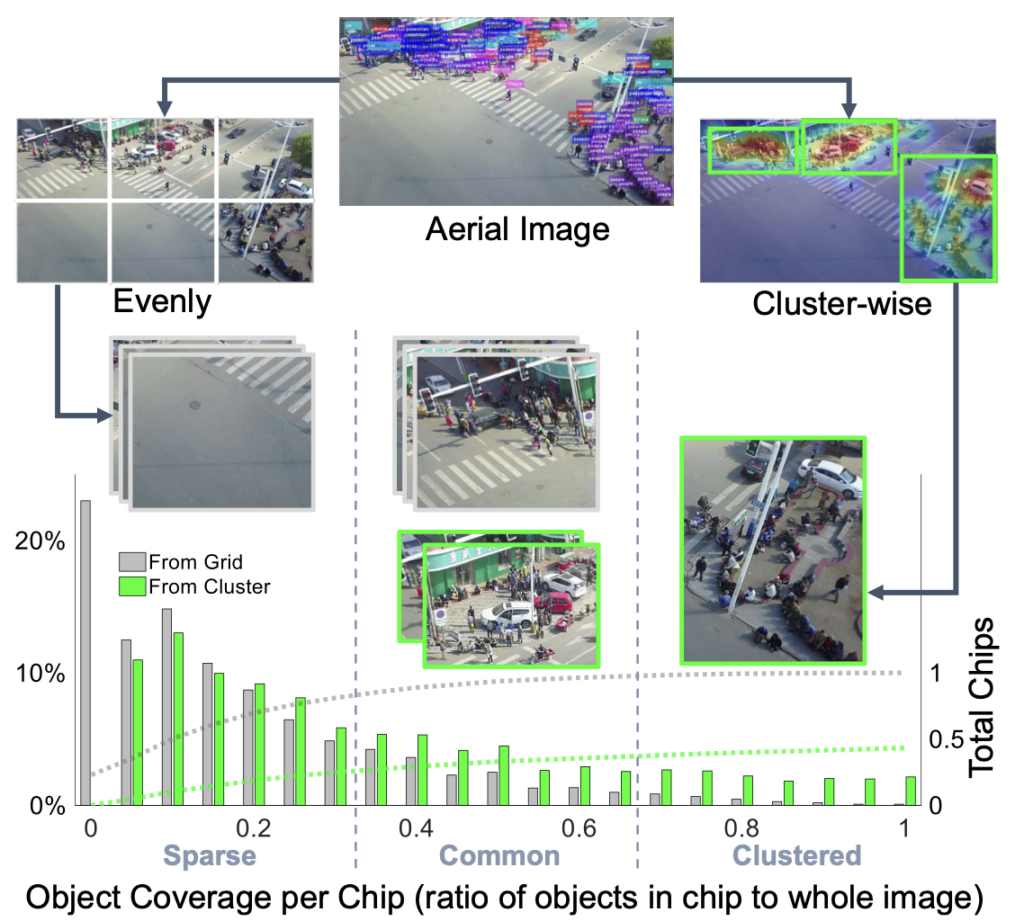
그러므로 저자는 Aerial image의 특성을 고려하여, detector가 “clustered region”, 즉 객체가 많이 분포하는 영역에 대해 집중하도록 하면 scale variation 문제와 더불어 전체적인 성능 향상을 볼 수 있을 것을 기대합니다. 이에 저자는 다음의 세 방법을 제안하는데, 순서대로 앞선 scale 문제, sparse and dense 문제 (object density distribution)를 해결하기 위해 객체를 통합할 수 있는 CPNet, ScaleNet, DetectNet입니다. 세 -Net 들에 대해서는 방법론을 살펴보며 알아보도록 하며, 우선 세 -Net 들의 역할에 대해서만 한번 짚고 넘어가겠습니다.
CPNet은 object cluster의 영역을 만듭니다. 위 Figure 1의 Cluster-wise의 초록색 박스를 만드는 역할을 담당하며, Grid에서 Cluster라는 개념으로 넘어가게 됩니다. 두 번째인 ScaleNet은 cluster chip 내 객체의 크기를 추정하여 이를 적절히 rescale해줍니다. 보통 small object를 medium-large 사이즈만큼 rescale해주며, 이는 영상 내 scale imbalance, scale invariance와 더불어 small object 자체의 부족한 feature representation을 보충해주는 역할을 담당합니다. 다음은 DetectNet 이지만, cluster chip과 global 이미지의 detection 결과를 fusion하는 것 외의 역할은 없습니다. 또한 하나의 지식으로, 지금처럼 영상을 한번만에 detection하지 않고, 일정 영역에 대해, 혹은 detect 결과로부터 다시 영상을 만드는 등의 과정을 coarse-to-fine detection이라고 명합니다.
Clustered Detection (ClustDet) Network
Cluster Region Extraction
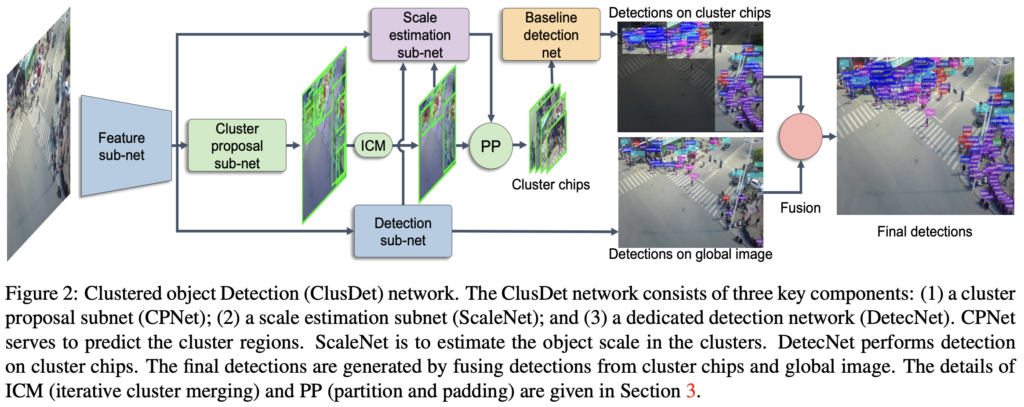
Figure 2는 ClusDet의 파이프라인을 보입니다. ClusDet은 크게 세 스텝으로 구성되는데, cluster할 영역을 추출하는 과정, cluster chip에 대해 detection 과정, cluster chip에 대한 detection과 전체 이미지에 대한 detection 결과를 fusion하는 과정입니다.
그 중 Cluster Region Extraction은 위 그림에 보이는 Cluster proposal sub-net (CPNet)을 통해 물체가 있음직한 위치를 찾아내어 chip들을 만들기 위한 과정이며, 이 과정에서 중복되는 영역이 제안될 수 있으므로 이를 제거하여 병합하는, ICM 모듈로 구성되어 있습니다. CPNet의 과정과 목적을 다시 살펴보면, high-level feature map에서 클러스터의 위치와 크기를 예측하는 것을 목표로 합니다. 이 때 볼만한 점으로는 객체의 크기가 아닌 cluster의 크기이며, 따라서 cluster의 ground-truth에 대해서는 어느 dataset에서도 제공하지 않기 때문에 이를 수제로 만드는 알고리즘이 필요합니다. supplementary에서 cluster의 ground-truth를 만드는 작업에 대해 밝히겠다고하며 이 과정이 중요한 과정이라는 생각이 들었지만.. v1-v3까지도 supplementary가 공개되지 않아 아쉽습니다. 하지만 추측할 수 있는 것은 cluster또한 결국 물체가 있는 영역이며, 따라서 object proposal과 비슷하나 cluster라는 속성을 생각했을 때 그 크기를 크게 가져가는 방법을 사용하지 않았을까 생각이 듭니다. 아마 sliding window를 하며, 해당 cluster 내에 object의 수를 세는 것으로 유효한 cluster를 선별했으리라 추측합니다.
Iterative Cluster Merging (ICM)
다음은 ICM 모듈입니다. 결국 cluster 영역을 제안했을 때, 중복된 영역이 많이 존재할 것 입니다. 아래 Figure 3을 보면 바로 알아볼 수 있는데, 이처럼 dense하고 messy한 CPNet의 결과 영역에 대해 중복을 제거하는 과정이 필요합니다. 이 과정은 아래 Algorithm 1을 통해 알 수 있는데, 이 과정에서도 NMM이라는 알고리즘이 중요한 것으로 보여지나 자세한 과정은 말하지 않습니다. 그치만 NMM, Non-Max Merging이라는 이름에서 봤을 때 cluster boundig box (B)를 순회하며, 사전에 정한 cluster score (이 부분이 위의 CPNet에서 ground-truth가 없기 때문에 원래는 작동이 안되는 부분이어야 하기에, 저자가 논문 자체에서 해당 부분을 언급하지 않은 것이 많이 아쉬웠습니다)와 비교하여 Threshold 이상이면 병합하고, 그렇지 않으면 따로 두는 마치 NMS와 유사한 느낌의 알고리즘이라는 것을 알아챌 수는 있습니다.
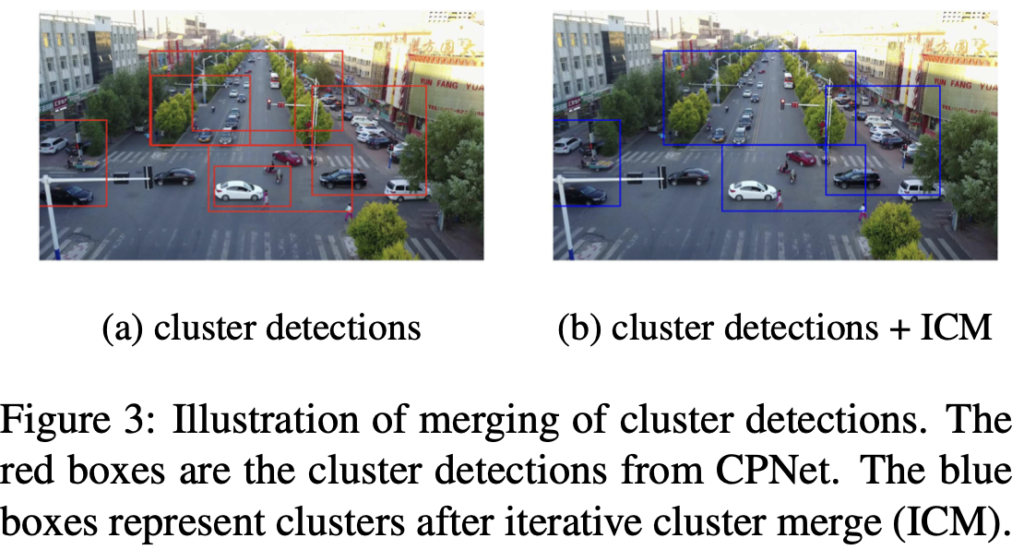

해당 ICM Algorithm은 이전에 리뷰한 UFPMP-Det의 FRG, Foreground Region Generation과 유사한 역할을 하지만 정반대의 순서를 가지고 있다고 볼 수 있는데, FRG에서는 중복된 영역을 제거하고자 작은 크기의 bounding box를 찾고 해당 박스 (cluster)로 부터 IoU가 일정 이상을 만족하는 cluster 영역을 병합하는 방법을 사용한 반면, ICM Algorithm에서는 한 영역, 보통은 큰 영역에 대해 내부에 포함되는 작은 영역들을 병합하는 과정을 담고 있습니다. UFPMP-Det이 3년 뒤의 논문이긴 하지만, 어느 방법이 더 좋을지는 때에 따라 다를 수도 있습니다. 결과적으로 ICM 모듈 이후, CPNet의 dense하고 overlapped된 cluster들은, 적절히 병합되어 각각이 유의미한 cluster로 취급받을 수 있습니다.
Scale Estimation Sub-network (ScaleNet)
cluster chip을 얻은 이후 해당 chip에 대해 detection합니다. 이는 small object의 scale을 조정하는 과정을 포함합니다. 위에서 언급한 바와 같이 small object는 그 자체만으로도 이미 feature representation이 약하다는 단점이 존재하는데, 마치 이미지를 resize하여 증가하고 보간법으로 pixel value를 채워주는 바와 같이, small object를 rescaling해줍니다. 이 때 사용되는 PP알고리즘이 흥미로운데, 아래에서 다시 살펴보겠습니다.
우선 ScaleNet에서는 scale을 추정하는 과정이 필요하며, 저자는 object의 scale을 추정하는 과정이 regression 문제로 간주하여 FC layer들을 통해 cluster 내 object의 scale offset을 regression합니다. Scalenet은 backbone으로 부터 추출한 feature map과, cluster bounding box (ICM 모듈의 결과), global image에서 detection한 결과를 입력으로 받으며, cluster chip 내의 object 들의 상대적인 크기를 내뱉습니다. 상대적인 크기라는 점이 뒤의 PP 모듈에서 다시 쓰일테니, 지금은 절대적인 크기인 bounding box의 크기가 아닌 (사실 생각해보면 절대적인 크기로 인해 상대적인 크기가 자명해지므로 아니라고 할 수는 없지만) 상대적인 크기의 개념이 나오겠구나만 생각하면 좋겠습니다. 위에서 이를 회귀문제로 푼다고 하였는데, 아래 식 (1)을 통해 계산됩니다.
식 (1)에 대해 짚고 넘어가면, t_i^, t_i^* 는 각각 scale offset 값으로, (p_i - s_i^*) / {p_i} 로 계산되며 이 때의 p_i, s_i^* 는 각각 object의 bounding box 크기 (실제), i 번째 cluster 내의 bounding box들의 ground-truth의 평균이며, 이를 통해 t_i^, t_i^* 는 각각 추정한 상대적인 offset (3개의 input으로부터 나온 output), custer 내 상대적인 scale offset을 의미함을 알 수 있습니다. 이 때의 regression loss는 smooth L1 loss로 설계하였으며, M은 cluster의 총 수를 의미합니다. 정리하자면, 위에서 말한 세 input으로부터 나온 object의 상대적인 크기를 회귀 문제로 풀어 해당 object의 크기가 작을 시, 혹은 클 시 어떠한 작업을 해줄 의도로 보입니다.
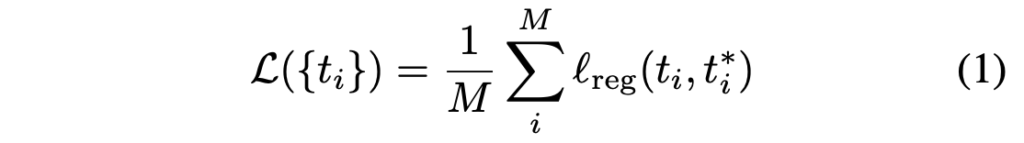
Partition and Padding (PP)
직전의 어떠한 작업이 지금 소개할 PP입니다. PP의 목적은 결국 object의 scale이 reasonable한 range로 들어오게끔 만드는 것으로, cluster bounding box B_i 와 위에서 추정한 object의 상대적인 scale인 S_i , detector의 입력 사이즈 S_{in} 의 값을 통해, detector의 input space 내에 object가 가질 상대적인 크기를 추정합니다. 수학적으로는 S_i^{in} = B_i \times S_{in} / S_i 로 계산될 것이며, S_i^{in} 이 특정 범위보다 크면 object들을 비례하여 Padding해주며, 그렇지 않다면 두 chip으로 나눕니다. 이 부분이 헷갈릴 수는 있으나, 아래 Figure 5를 보면, 큰 cluster에 대해서는 상대적으로 작은 cluster의 bounding box를 padding하여 chip으로 구성하는 반면 chip의 크기가 작다면 partition, 분할하여 chip을 다시 만들어주는 과정을 통과합니다. 이를 통해 small object의 chip들을 reasonable하게끔 증가하고자한 과정을 알 수 있습니다.
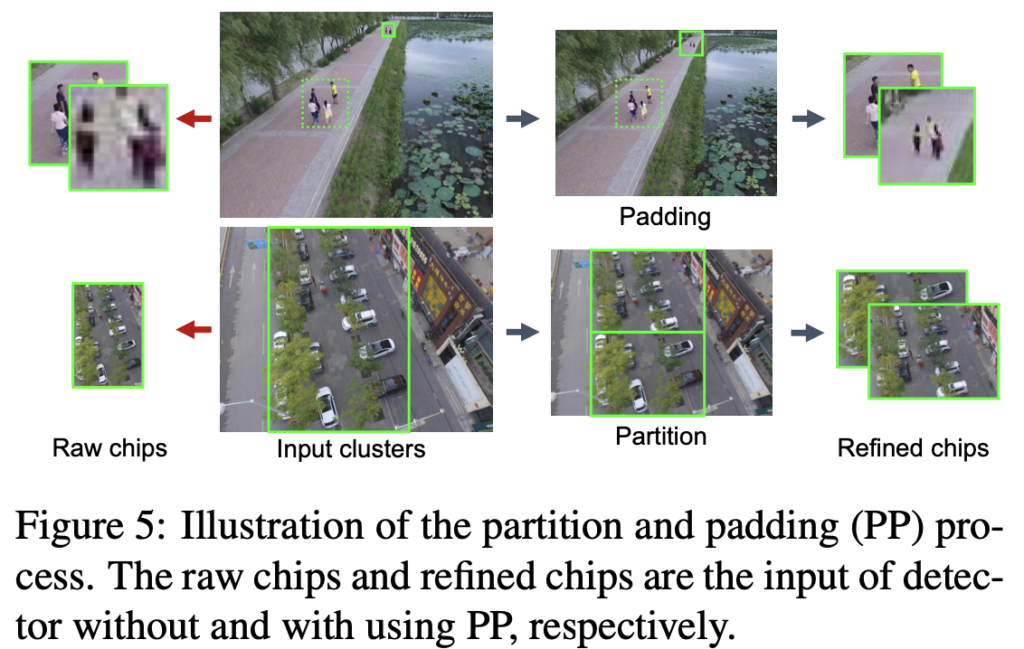
이제 마지막으로는 DetecNet, cluster chip들에 대해 detection을 수행합니다. 처음 해당 clustering 방법을 토대로 실험을 진행 중이라고 말했는데, 지금의 DetecNet이 왜 이 실험을 진행한지에 대해 말할 수 있는 부분입니다. 한 문장으로 끝나는, “어느 SoTA 모델을 써도 된다.”라고 하는 DetecNet은 결국 coarse-to-fine detection 과정 중의 중간, 이미지를 refine할 수 있는 방법을 소개한 것일뿐 detector 자체를 건드린 것은 아니죠. 즉, 이전 주에 리뷰한 ProbEn과 같이 object detection에서의 detector들을 사용하되, Module 느낌의, 혹은 파이프라인 느낌의 방법론을 사용하면 성능 향상을 보일 수 있음을 저자도 말합니다.
Final Detection with Local-Global Fusion
마지막으로는 DetecNet 결과와 영상 전체에 대해 detection한 결과를 NMS하여 합치는 과정을 포함합니다. 아마, global image에서의의 detection 결과는 좋지 않을테나, 이러한 chip들을 만드는 과정 속에서도 잘리는 부분, 예를 들면 위 Figure 5의 Partition Refined chips에서도 잘리는 부분에 대해서도 탐지하고자 NMS 알고리즘을 사용하지 않았을까 생각듭니다. 이 과정은 아래 Figure 6을 통해 보이며, 방법론은 마쳤습니다. 지금까지의 과정을 위 Figure 2의 순서와 함께보며 따라오다 보면 어렵지 않게 이해할 수 있을 것 입니다.

Experiments
실험은 VisDrone, UAVDT, DOTA dataset에서 이뤄졌습니다. 세 dataset 모두 Aerial detection dataset에 포함되며, 순서대로 2000×1500, 1080×540, 4000×4000 수준의 고해상도로 이루어져있습니다. 저자는 DetecNet을 소개하며 어떠한 SoTA 모델을 사용해도 문제되지 않는다고 하였으며, 그렇기에 RetianNet과 FRCNN에 FPN을 붙인 detector (backbone은 ResNet으로 정했습니다)를 토대로 실험을 진행했습니다.
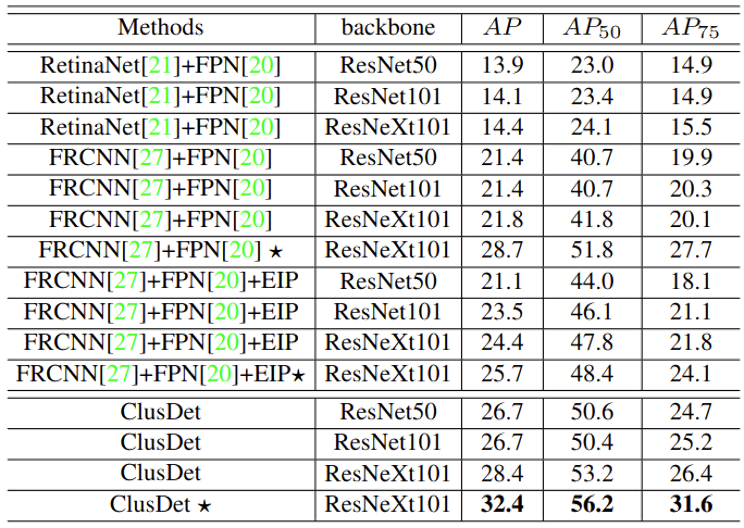
위 실험은 VisDrone dataset에서의 실험 결과를 보입니다. 별표 (*)는 multi-scale inference와 bounding box voting 기법을 사용한, 일종의 detection trick을 사용한 방법이며 해당 trick을 제외하고서도 성능이 많이 높아짐(24.4 AP -> 28.4 AP)을 알 수 있습니다. 이때의 EIP는 clustering 방법이 아닌 앞서 말한, 균등하게 자른 방법을 의미합니다 (Evenly cropped)
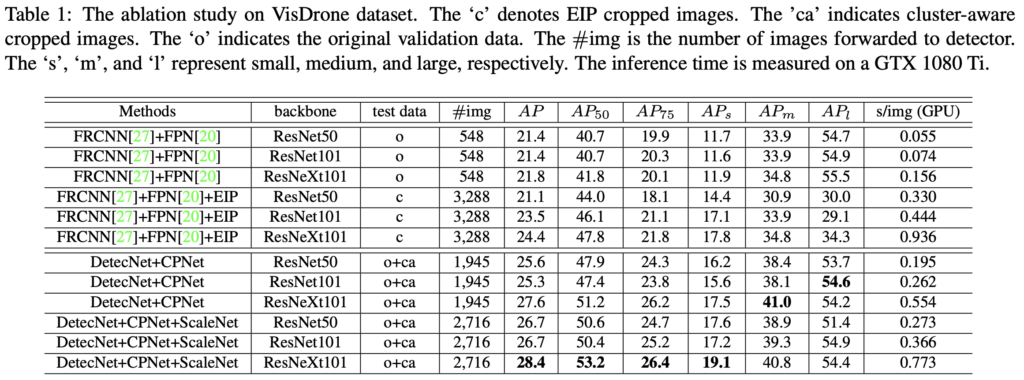
위의 Table 1 또한 VisDrone dataset에서의 결과입니다. ‘o’는 원본 평가 이미지, ‘c’는 앞서 말한한 EIP 결과 이미지를 (Evenly cropped하여, 영상을 6등분하여 #img가 6배 늘어난 것을 알 수 있습니다.), ca는 clustering cropped 이미지를, AP의 s, m, l은 차례로 small, medium, large object애서의 성능을 의미합니다. APs에서의 성능이 ScaleNet을 통해 비약적으로 상승한 것을 알 수 있으며, ScaleNet을 통해 Partition하는 과정이 있기에, #img의 수가 다소 늘어나긴 했지만 그래도 ‘c’, EIP에 비해서는 작은 수임을 알 수 있습니다. 하지만 ScaleNet을 통해 s/img, 추론 시간이 늘어남을 알 수 있는데, 이것이 단순 이미지의 수가 늘어났음에 기인했을지는 의문입니다.
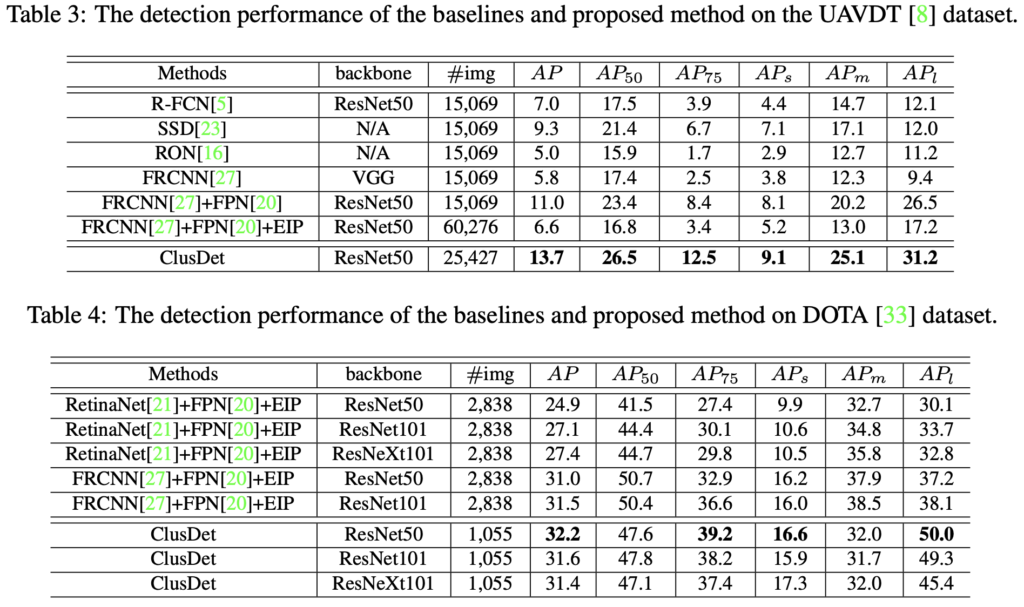
정량적 결과에 대한 분석은 위 Table 1에서 다 살펴보았으니, 이제 UAVDT와 DOTA dataset에서도 ClusDet이 SoTA다!라는 주장만 살펴보고 마치겠습니다. 이러한 clustering 방법은 Aerial image에서는 다소 사용되는 모습이 보이는데, 이를 다른 도메인인 pedestrian detection에 적용하는 것도 다양한 제약 조건을 고려했을 때 쉽지는 않았는데.. 왜 성능이 안나올지에 대해서도 다시 고민해봐야할 것 같습니다. 그럼 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
CPNet에서 공개되지는 않았지만 cluster의 gt를 만드는 작업이 존재한다고 말씀해주셨는데요, 그 gt cluster라는 것이 결국 사람이 존재하는 cluster 공간에 대한 정답 정보가 되는 것이라고 이해하였습니다. 그렇다면 cluster 내에서의 detection 결과 뿐만 아니라 global image에서의 detection 결과를 fusion하는 이유라고 함은 배경을 학습하여 모델의 일반성을 높이기 위함일까요 ? 말씀해주신 것처럼 global image에서의 detection 결과는 좋지 않을 거라고 생각하는데, 단순히 detection 결과를 합친다는 부분에서 이해가 잘 되지 않았던 것 같습니다.
그리고 또 하나 궁금한 점은 local-global fusion을 할 때의 NMS 한다는 것은 어떤 cluster에서의 detection 결과인지, global image에서의 detection 결과인지와는 상관없이 모두 동일한 bounding box 후보로 두고 일반적인 NMS 과정을 거치는 것인가요??
감사합니다.
안녕하세요. 리뷰 읽어주셔 감사합니다.
우선 첫 질문은 “Clsuter의 detection 결과만 내면 되지 않느냐”로 번역할 수 있겠는데, 건화님이 말씀하신 것과 같이 모델의 일반성을 높이기 위함도 맞습니다만, clustering된 결과에 100% 신뢰할 수 없음도 맞습니다. 이에 대해서는 clustering이 모든 영역의 객체를 잘리지 않게끔 할 수 있느냐하면, 아니기 때문입니다. 잘릴 영역도 존재하겠죠. 그렇다면 해당 객체는 “최대한 피하려 했음에도 그러지 못한, 잘려버린 객체”가 되고 이를 보충하기 위해 global image의 결과를 NMS합니다. NMS의 특성 상, global image의 detection 성능이 좋지 않아도 (실제로는 global image와의 성능이 2-3 AP 차이나는 수준이지만) 합치고 나면 더 좋은 성능을 보여줄 수 있기 때문입니다.
두 번째 질문은 NMS 때 가중치 없이, 두 이미지의 결과를 토대로 일반적인 NMS를 진행하느냐인데, 넵. 그렇습니다. 사실 생각해보면, 그렇게 하지 않는 편이 좋을 수도 있지만, 사실 clustering을 하지 않았다고 해서 성능이 처참한 수준은 아닙니다ㅎㅎ
안녕하세요 이상인 연구원님 좋은 리뷰 감사합니다.
왠지 제목이 익숙해서 클릭하게 되었는데, 세미나 때 소개해주신 논문이었군요 기억이 납니다.
Clustering과 PP (Partition and Padding) 가 거의 핵심 기술 같은데요. 본 기술들이 이상인 연구원 실험에 적용된 결과가 궁금해졌습니다.. aerial 과 PD는 다른 경향성의 데이터 분포를 가져서 잘 동작할까 궁금한데, 만일 PP는 적용해보셨다면, (작은 객체를 찾기 위해 스케일 업 하는 과정이라 할까요?) 제대로 동작할지 궁금합니다.
안녕하세요. 세미나를 기억해주셨다니, 감동입니다.
우선 실험에 대해 말씀해드리자면, clustering 아이디어를 가져갔지만 본 논문의 PP가 아닌 예전 세미나 때 비교한 2022 AAAI의 UFPMP-det이라는 아이디어를 토대로 실험을 진행했습니다. PP도 좋은 아이디어로 보였지만, Padding을 준다는 아이디어가 너무 Naive하게 느껴졌습니다. 실험 결과는.. 우선 실험을 진행함에 있어 PD 도메인에 활용하고자 많은 난관을 겪었으며 Kaist PD에서도 clustering 이미지를 만드는데는 성공했으나, 성능이 나오지 않아 이 점에 대해 분석한 점을 말씀드리겠습니다.
우선 (1) Kaist dataset이 resolutioin이 낮아 cluster 이미지내 사람이 실제 사람의 눈에도 흐릿할정도로 Feature representation이 떨어지는 점
(2) 영상 내 사람의 수가 적기에, cluster 수가 적고 cluster 내에 주로 사람만 존재하기에, 모델에게는 너무 Easy한 Task로 읽혀지는 문제점
(3) cluster 내에 다수의 사람이 존재하지 않고 하나의 사람만 존재하는데, 모델 (SSD baseline, Feasibility를 위함)은 해당 이미지에 대해 원래보다 많은 수준의 Bounding box를 그림
(4) 하지만 좋은 점으로는, 첫 번째 detector에서 IoU 0.5를 넘지 못해 TP로 취급되지 못하거나, 혹은 FP 부분이 clustering되었을 때 두 번째 detector에서 Bounding box 미세 조정과정을 돕거나 혹은 FP 부분을 FP라고 판단해줌.
(5) 위 (4)의 장점이 존재함은 확인되었으나, 첫 번째 detector에서 객체를 찾지 못했을 시, 두 번째 detector는 clustering되지 않고 이미지 전체가 입력으로 들어가므로, 이전 학습한 clustering과는 다른 도메인으로 판단하여 bounding box를 잘 치지 못함
이 중 (5)의 문제점이 가장 핵심적인 것 같습니다. 보통의 Aerial image에서는 적어도 객체가 하나는 존재하므로, 이런 문제점을 겪을 일이 없었던 것이죠.. 하지만 그래도 (4)를 새로이 찾았으니 이를 토대로 계속 진행하면 좋을 것 같지만.. 슬픕니다..