안녕하세요 여덟 번째 X-Review입니다. 금주 리뷰할 논문은 ECCV 2018에 게재된 <Mask TexSpotter: An End-to-End Trainable Neural Network for Spotting Text with Arbitrary Shapes>입니다. 바로 리뷰 시작하겠습니다. ?
1. Introduction
OCR은 크게 문자가 있는 영역을 검출하는 text detection 과정과, 그 검출된 영역의 문자를 인식하는 text recognition 과정으로 구분할 수 있습니다. 이 두 과정을 end to end로 한번에 수행하는 모델들이 나오기 시작했고 이를 text spotting이라고 부릅니다. scene text spotting에서 이전 많은 연구들은 localizing과 recognizing을 동시에 하는 것에 초점을 맞춰왔지만, 사실 대부분의 방법론들은 text detection과 recognition을 분리해서 다뤄오고 있었습니다. 미리 학습한 detection을 가지고 먼저 text region을 검출한 다음 그 검출된 영역이 recognition module로 들어가는 형식으로 말이죠. 이런 과정은 단순하고,, 자연스러워 보일 수 있지만 detection과 recognition 둘 다에서 성능이 떨어질 수 있게 되는데 이는 두 task가 굉장히 상관관계가 높고 서로 상호보완적인 관계이기 때문입니다. detection의 성능은 recognition의 정확도에 크게 영향을 미치고, recognition의 결과는 detection의 fp를 줄이는데 feedback을 제공하는 식으로 말입니다.
본 논문의 저자는 [towards end-to-end textspotting with convolutional recurrent neural networks]과 [Deep textspotter]에서 제안된 end-to-end text spotting 방법론은 detection과 recognition이 서로 상호보완적인 이익을 가져옴으로써 기존 방법론보다 성능이 좋았지만, 두 가지 주요한 한계점이 있다고 합니다.
- 위 두 방법론은 완전히 end-to-end로 학습가능하지 않다.
- 먼저 [toward end-to-end ~~] 방법론은 학습할 때 curriculum learning paradigm을 적용하여 학습 초기에서 text recognition과정을 수행하는 sub-network를 잠궈두고 각 학습 구간에 대한 data를 미리 선정해 두었습니다. 또, [Deep textspotter]같은 경우도 detection과 recognition 네트워크를 분리하여 각각 미리 학습시키는 과정이 존재했죠.
- 이렇게 두 방법론이 end-to-end로 학습하지 못한 데에는 두 가지 이유가 있습니다.
- text recognition 과정은 학습시에 정확한 location을 필요로 하는데, 학습 초기에는 보통 detection이 예측한 location이 부정확하기 때문이다.
- LSTM이나 CTC loss가 general한 CNN보다 학습하기 어려웠다.
- 두 방법론은 오직 horizontal과 oriented된 text에만 초점을 맞춘 방법론이다.
- 하지만 real-world 이미지에 존재하는 text instance들은 다양한 모양을 가지고 있습니다.
이런 단점들을 극복하는 모델 Mask TextSpotter를 본 논문에서 제안합니다. 즉 mask textspotter는 arbitrary shape을 가지는 text instance들을 detect하고 recognize할 수 있는 모델이죠. 여기서 arbitrary shape이라 함은 현실 세계에서 text instance들이 가지는 다양한 형태를 의미하는 것입니다.
Mask TextSpotter는 object shape의 마스크를 생성할 수 있는 Mask R-CNN에서 영감을 받았으며, 이전 sequence 기반 recognition 방법론들은 1차원 sequence들을 다뤘지만, mask textspotter에서는 2차원 공간에서 semantic segmentation을 통해 text recognition을 수행합니다. 이로써 불규칙한 text instance들을 읽을 때 생기는 이슈를 해결할 수 있었죠…
Mask textspotter의 또 다른 이점으로는 recognition을 위한 정확한 location이 필요하지 않다는 점입니다. 이 점은 아까 저자가 완전한 end-to-end가 아니라고 지적한 논문들의 한계점을 해결한 것이었죠. 이로써 detection과 recognition task를 완전히 end-to-end로 학습할 수 있게 되었습니다.
본 논문의 main contribution은 다음과 같습니다.
- end-to-end 학습가능한 모델 제안 (게다가 간단하고,, 스무스하게 학습가능함)
- 다양한 모양을 가지는 text를 detection recognition 할 수 있음
- 이전 방법론들과 다르게, semantic segmentation을 통해 정확한 text detection, recognition을 할 수 있음
- SOTA 달성 (detection & text spotting 둘 다 !)

[Fig1]은 다른 textspotting 방법론과 mask textspotter를 비교한 것인데, 왼쪽 방법론은 수평적인 bbox만 그릴 수 있는 horizontal text spotting method이고, 가운데는 oriented text spotting 방법론입니다. 마지막으로 오른쪽이 본 논문에서 제안한 mask textspotter로 앞의 두 방법론에 비해 recognition 결과가 정확한 것을 확인할 수 있습니다.
2. Methodology
2.1 Framework
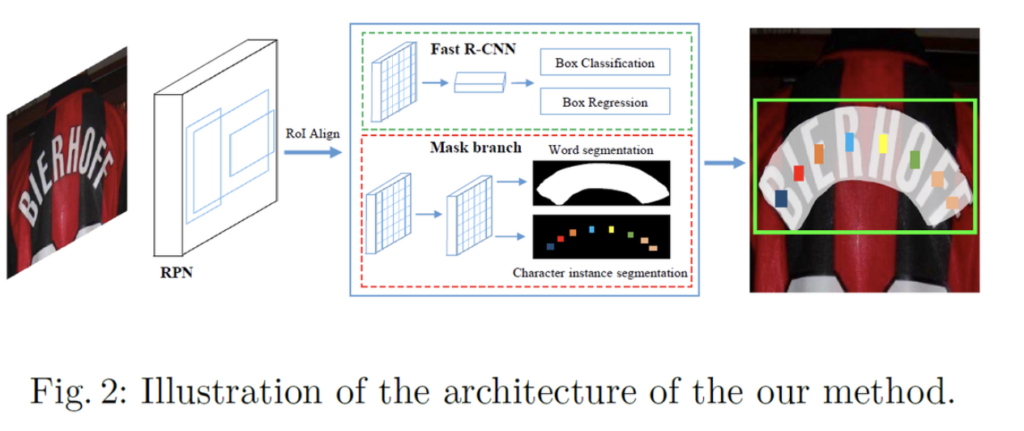
본 방법론의 전반적인 구조는 위 그림과 같으며, 크게 4가지 모듈로 구성되어 있습니다.
- feature pyramid network (FPN) ⇒ 백본으로 사용
- Region Proposal Network (RPN) ⇒ text RoI 생성
- Fast R-CNN ⇒ BBox regression
- mask branch ⇒ text instance segmentation & character segmentation
Mask TextSpotter가 Mask R-CNN 모델을 착안해 온 것으로 4가지 모듈 모두 우리가 잘 알고 있는 모듈입니다. 물론 mask branch단은 기존 Mask R-CNN의 mask branch와 다르게 구성되어 있긴 합니다.
학습 과정은 굉장히 단순합니다. 먼저 RPN으로부터 수많은 text RoI가 생성되게 되고, 이 RoI에 해당하는 RoI feature들이 Fast RCNN branch와 Mask branch로 들어가게 되면서 정확한 text 후보 박스들과, text instance segmentation 맵, character segmentation 맵이 생성되는 것입니다.
Backbone
이미지에 있는 text의 size는 굉장히 다양합니다. 그렇기에 모든 scale에서 higt-level의 semantic feature map을 갖기 위해서 feature Pyramid 구조를 적용한 ResNet50을 백본으로 사용하였습니다.
RPN
RPN은 Fast RCNN과 Mask Branch의 입력으로 들어갈 text proposal을 생성합니다. ResNet-FPN 백본 네트워크에 이미지를 넣으면 feature pyramid {p2, p3, p4, p5, p6}을 얻게 되는데, 이를 RPN에 넣어 region proposal을 출력하도록 하는 것입니다. 이 5가지 stage feature pyramid {p2, p3, p4, p5, p6} 각각에 대해 anchor 크기는 {32, 64, 128, 256, 512}로 설정되었습니다. 또 각 stage에서 Faster RCNN과 같이 aspect ratio를 {0.5, 1, 2}로 설정하였습니다. 이렇게 함으로써 RPN은 다양한 크기와 비율을 가진 text를 다룰 수 있게 되겠죠.
그 다음 RPN에서 만들어낸 text proposal의 region feature를 추출하기 위해 RoI Align을 사용하였습니다. 기존 Fast R-CNN에서는 RoI Pooling을 사용하였는데, 이 RoI Align은 Mask R-CNN에서 제안된 것입니다. Fast R-CNN은 object detection을 위한 모델이기에 RoIPooling과정에서 정확한 위치정보를 담는 것이 별로 중요하지 않았습니다. RoIPooling과정은 그저 quantization한 후 pooling을 하는 방식이었는데 이렇게 하면 RoI가 소수점 좌표를 가지고 있을 때 quantization을 수행함으로써 feature와 RoI 사이가 어긋나는 misalignmnet문제가 발생하기에 정확한 위치 정보를 얻지 못하게 된다는 단점이 있었습니다. Mask R-CNN은 instance segmentation 방식이기 때문에 pixel별로 detection을 수행해야 했고 그로 인해 기존 RoI Pooling보다 더 정확한 위치 정보를 얻을 수 있는 RoI Align을 제안한 것입니다. RoIAlign은 qunatization을 수행하지 않고, bilinear interpolation을 사용함으로써 정확한 위치 정보를 가져올 수 있습니다.
Fast R-CNN
Fast R-CNN branch에는 classification task와 regression task가 포함되어 있습니다. 이 branch의 주 목적이라 함은 detection을 위한 더 정확한 bbox를 제공하는 것이겠죠. Fast R-CNN으로 들어가는 input은 RPN에서 생성된 proposal을 가지고 RoI Align과정을 거친 후 나온 7×7 RoI feature가 되겠습니다.
Mask Branch
mask branch에서 수행되는 작업은 두가지로, global text instance segmentation task와 character segmentation task입니다.
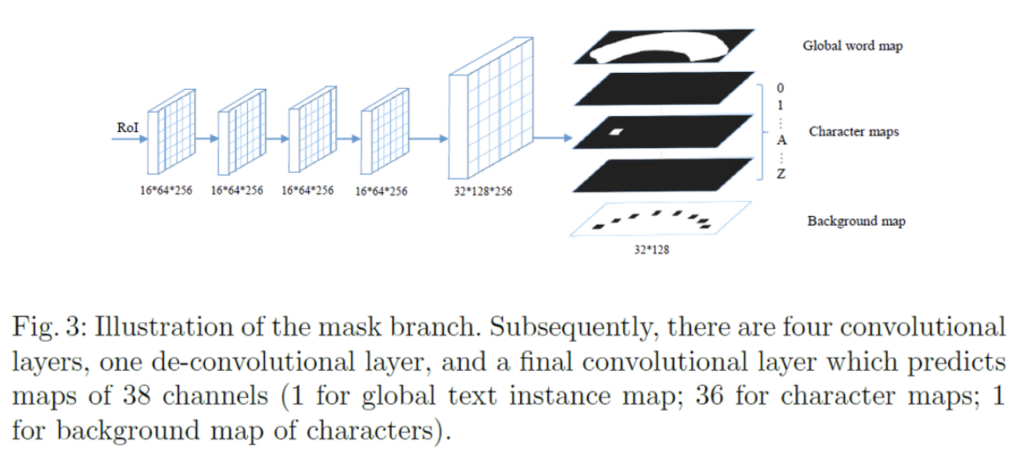
위 그림이 mask branch를 도식화 해논 것인데, 보시면 16×64로 크기를 고정한 RoI를 4개의 convoluton layer와 deconvolution layer를 통해 38개의 map(32 x 128 크기)을 예측하게 됩니다. 38개의 map이 어떻게 구성되어 있는지 알아보자면,, 먼저 한 개의 global text instnace map과 36개의 character map 그리고 마지막으로 한 개의 character의 brackground map으로 구성되어 있습니다. global text instance map은 text 영역에 대한 정확한 위치를 제공하며 그림 우상단을 보시면 [Fig2]에서 봤던 input 이미지에 있던 무지개 모양의 text의 위치를 그대로 담고 있는 map인 것을 알 수 있습니다. 또, character map은 36개라고 했었는데 이는 26개의 알파벳(A to Z)과 10개의 숫자(0 to 9)로 이루어져 있습니다. 마지막 map인 character의 background map은 후처리 과정에서 사용되게 되는데 이는 뒤에서 다시 언급하도록 하겠습니다.
3.2 Label Generation
이제 mask textspotter의 label 생성 과정을 알아보도록 하겠습니다. train과정에서 사용되는 sample은 입력 이미지와 그에 해당하는 gt로 구성되겠죠. 여기서 gt는 text region P = {p_1, p_2, ,,, p_m}과 character 정보 C = {c_1 = (cc_1, cl_1), c2 = (cc_2, cl_2), … , cn = (ccn, cln)}로 구성됩니다. p_i는 text영역의 localization을 나타내는 다각형이며, cc_j와 cl_j는 각각 character의 category와 localization 정보를 의미합니다. 모든 데이터셋이 character 단위의 정보를 가지고 있는 것은 아니기 때문에 학습 과정에서는 C는 반드시 필요한 것은 아니라고 합니다. 학습을 하려면 이 gt정보를 가지고 RPN, Fast R-CNN, mask branch에 해당하는 target(label)을 생성해야 합니다.
먼저 gt에서 제공하는 polygon 영역을 포함하는 가장 작은 면적을 갖는 horizontal 사각형으로 변환해줍니다. RPN, Fast RCNN에 대한 target을 얻어낼 땐 이렇게 변환한 사각형을 gt bbox라고 설정하여 사용합니다.
RPN을 학습할 때에는 anchor box에 대한 label이 필요하게 되겠습니다. 다시 말해서 각 anchor box에 text가 있는지 없는지에 대한 label을 의미하는 것인데, anchor box에 text가 있다고 판단하여 positive/negative로 sampling하는 것입니다. positive sample로 anchor box를 선정하는 기준은 전체 anchor box중에 gt box와 가장 큰 IoU 값을 가지는 경우와, gt box와 IoU값이 0.7이상인 경우입니다. 반면에 gt와 IoU 값이 0.3이하인 경우에는 negative sample로 판단됩니다.
다음으로 RPN에서 나온 text region proposal 중에서 Fast R-CNN을 학습시키기 위한 sample을 선택하는 과정으로는 region proposal과 gt box 사이 IoU를 계산하여 0.5이상인 경우에는 positive, 0.1~0.5사이일 경우에는 negative sample로 label됩니다.
그리고, mast branch에 해당하는 target은 두 가지가 있겠죠 ? 왜냐하면 앞에서 mask branch단에서 수행하는 task는 global text instance segmentation task와 character segmentation task라고 했으니까요. 이 target map들은 gt P(polygon 정보)와 C(character 정보), 그리고 RPN에서 생성된 proposal들과 관련 있습니다. 위에서 말했듯이 C는 존재하지 않을 수 있습니다.
positive proposal에 대한 horizontal rectangle을 얻어낸 후, 이에 맞는 polygon과 character boxes들을 추가로 얻어낼 수 있겠죠. 이 정보들을 가지고 아래 식을 통해 HxW 크기의 target map을 생성할 수 있습니다.
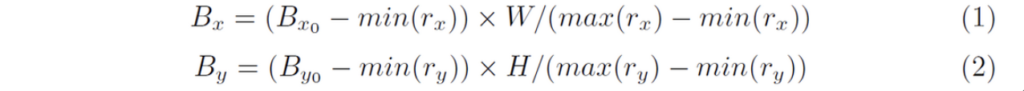
- (B_x, B_y) : polygon과 모든 character box의 업데이트 된 vertex
- (B_{x0}, B_{y0}) : polygon과 모든 character box의 원래 vertex
- (r_x, r_y) : positive proposal r의 vertex
그 후 target global map은 위 식을 통해 계산한 정규화된 polygon vertex를 이용하여 polygon을 0으로 초기화된 mask 위에 그린 후 그 영역의 값을 1로 채우는 것으로 생성됩니다.
또, target character map은 아래 [Fig4 (a)]의 우하단처럼 생성되는데 먼저 모든 character bbox의 중심점을 고정시키고 원래 변의 1/4 길이로 변형하여 축소시킵니다. 이후, 축소된 character bbox의 pixel값은 해당하는 category 값으로 설정하고 그 축소된 bbox 밖의 값들은 모두 0으로 설정됩니다. 또, character bbox의 어노테이션이 없는 경우 모든 값은 -1로 설정된다고 합니다.
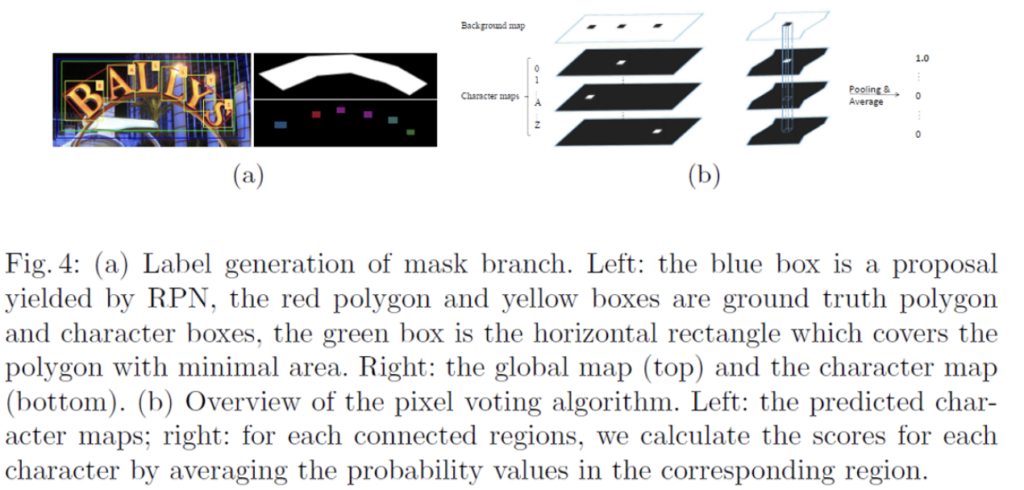
[Fig4]의 왼쪽 (a)에서 잘 안보이시겠지만,, 파란색 박스가 RPN으로부터 나온 positive proposal입니다. 이에 상응하는 gt polygon box와 character box가 각각 빨간색, 노란색 박스이고요.. 이로부터 (a)오른쪽 부분의 target map들을 생성하는 과정을 알아보았습니다.
2.3 Optimization
mask textspotter는 여러 모듈로 구성된 만큼 전체 Loss는 3개의 task에 대한 loss의 합으로 구성됩니다.
[Fig4]의 왼쪽 (a)에서 잘 안보이시겠지만,, 파란색 박스가 RPN으로부터 나온 positive proposal입니다. 이에 상응하는 gt polygon box와 character box가 각각 빨간색, 노란색 박스이고요.. 이로부터 (a)오른쪽 부분의 target map들을 생성하는 과정을 알아보았습니다.
2.3 Optimization
mask textspotter는 여러 모듈로 구성된 만큼 전체 Loss는 3개의 task에 대한 loss의 합으로 구성됩니다.
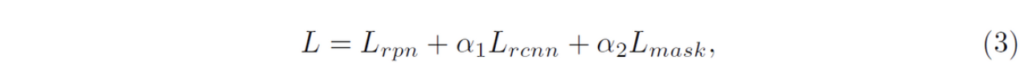
- L_{rpn} : RPN loss function
- L_{rcnn} : Fast R-CNN loss funtion
- \alpha_1 : 1
- \alpha_2 : 1
mask branch에 대한 loss는 아래와 같이 global text instance segmentation loss(L{global}와, character segmentation loss(L_{char})두 loss의 합으로 구성됩니다.
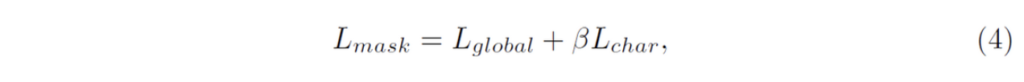
- \beta : 1
L_{global}는 average binary cross entropy loss이며, L_{char}는 weighted spatial soft-max loss입니다.
Text instance segmentation loss
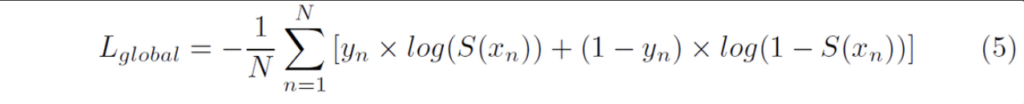
- N : global map 픽셀 수
- y_n : pixel의 label (pixel이 text일 경우 1, 배경일 경우 0)
- x_n : output 픽셀
- S(x) : sigmoid 함수
Character segmentation loss
앞에서 말했듯이 character segmentation의 output은 37개의 map으로 구성됩니다. 이는 36개의 character class와 1개의 background class로 구성되어 있죠.
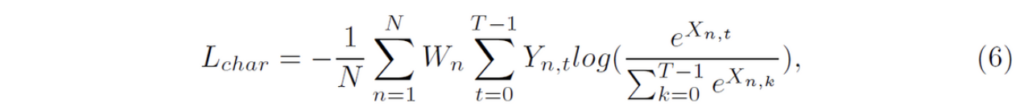
- T : class 수
- N : 각 character map의 pixel 수
- X : character maps
- Y : X(character maps)에 대한 GT
- W : weight
W(weight)는 positives(character class)와 background class간의 균형을 맞추는데 사용됩니다. background pixel 수를 N_{neg}라고 나타내고, background의 class 인덱스를 0이라고 했을 때 weight는 아래와 같이 계산될 수 있습니다.
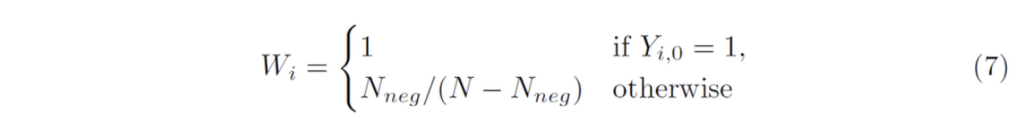
2.4 Inference
모델을 학습할 때 mask branch의 input으로 들어가는 RoI는 RPN으로부터 생성한 것이었습니다. 하지만, inference과정에서는 RPN으로부터 생성한 text proposal을 사용하여 mask branch를 학습하는 것이 아닌 Fast R-CNN의 output을 text proposal로 사용하여 mask branch의 input으로 넣음으로써 global map과 character map을 생성합니다. 이에 대한 이유로는 Fast R-CNN의 output이 더 정확하기 때문이라고 하네요.
inference 과정은 다음과 같습니다.
- 먼저 test image를 input으로 넣어 Fast R-CNN의 output을 얻습니다.
- 이후, NMS(Non-Maximum Suppression)을 사용하여 중복되는 candidate box들을 걸러냅니다.
- NMS를 거쳐 남은 region proposal들은 Mask Branch의 input으로 사용되어 global map과 character map을 생성하게 됩니다.
- 마지막으로 global map을 가지고 text region의 경계를 계산하여 polygon을 예측할 수 있습니다. 또한 character map을 기반으로 pixel voting 알고리즘을 수행하여 character sequence를 얻어내게 됩니다.
Pixel Voting
pixel voting 알고리즘은 mask branch에서 생성된 character map을 가지고 character sequence로 디코딩하는 알고리즘입니다.
character map에는 1개의 background map이 있었죠. 이 background map을 먼저 이진화하여 이진맵으로 만들어냅니다. background map의 pixel 값은 0에서 255 사이의 값을 가지고 있을텐데 threshold를 192로 설정하여 이진맵으로 만들었습니다. 이를 통해 background와 character 영역을 분리한것입니다. 이렇게 이진화된 background map에서 연결되어 있는 region이 character region입니다.
이렇게 얻어낸 character region에 대해서, 모든 character map들 (background를 제외한 36개의 map)에서 해당 영역에 있는 pixel 값들의 평균을 계산합니다. 이 평균 값들은 해당 영역의 character class의 확률로 볼 수 있겠죠. 해당 chracter region에 대해 가장 큰 평균 값을 가지는 character class가 할당되게 되고, 이렇게 class를 할당한 character region들을 왼쪽에서 오른쪽으로 묶음으로써 character sequence를 구성하게 됩니다.
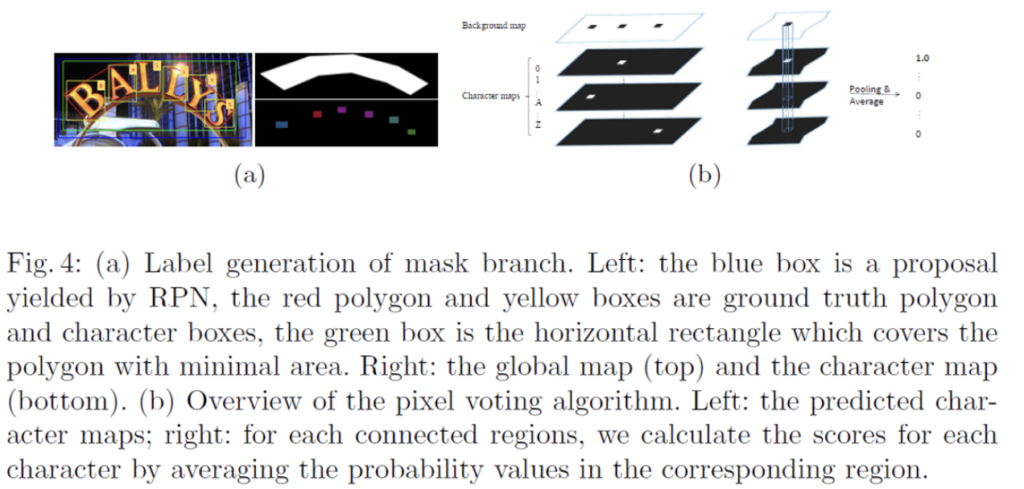
말을 조금 어렵게 한 것 같은데 위 그림 (b)부분이 pixel voting 알고리즘을 나타낸 것입니다. 왼쪽에 있는 4개의 map이 mask branch단에서 예측한 chracter map에 해당합니다. 실제로는 37개의 map으로 구성되어 있겠죠. 오른쪽에 있는 것은 background map을 이진맵으로 만들고 연결되어 있는 것들을 한 region이라고 보았을 때, 각 character map에서 이 영역에 해당하는 pixel값들의 평균을 계산함으로써 높은 값을 가지는 character map의 class를 할당하는 것입니다.
Weighted Edit Distance
ocr dataset에서는 lexicon(dataset에 대한 단어 사전)을 제공하는 경우가 있습니다. Edit distance, 즉 편집 거리는 주어진 lexicon과 예측된 sequence 사이에서 잘 맞는(best – matchied) 단어를 찾는데 사용됩니다. 여기서 편집 거리라는 것은 두 문자열이 주어졌을 때 얼마나 유사한 지 알아낼 수 있는 알고리즘으로써 두 문자열이 같아지기 위해 몇 번의 추가(insert), 편집(replace), 삭제(delete)가 이뤄져야 하는지 최소 개수를 구하는 것입니다. 하지만, minimal 편집 거리를 갖는 단어가 여러 개 있는 경우에는 어떤 단어가 최적의 단어인지 판단하기 어려울 수 있겠죠. 이런 문제의 주된 원인으로는,, 기존 eidt distance 알고리즘의 모든 operation(delete, insert, replace)가 동일한 cost를 가지기 때문에 실제로 의미가 없다는 점입니다.
기존 편집 거리 알고리즘의 이러한 단점을 언급하면서 본 논문의 저자는 weighted edit distance 알고리즘을 제안하였습니다.

[Fig5]에 weighted edit distace를 보면 기존 edit distace와 달리 다른 operation에 서로 다른 cost를 할당하고 있음을 확인할 수 있습니다. 이 weighted edit distace의 cost는 pixel voting에 의해 생성된 character 확률인 p^c_{index}에 따라 달라지게 됩니다. 수학적으로, 두 문자열 a, b의 weighted edit distace는 각 길이가 |a|, |b|라고 하였을 때 D_{a,b}(|a|, |b|)로 계산될 수 있습니다.
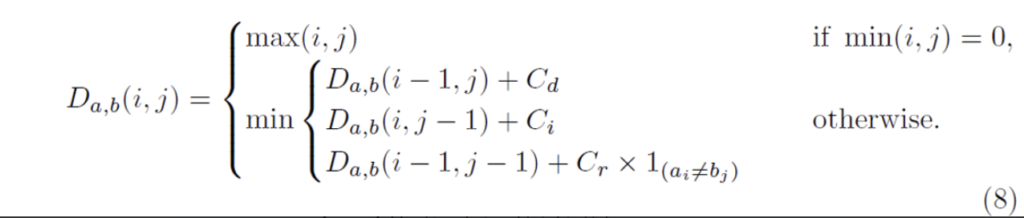
- C_{d} : delete cost
- C_{i} : insert cost
- C_{r} : replace cost
위 식에서 1_{(a_i ≠ b_j)}는 a_i와 b_j가 같으면 0이고, 같지 않으면 1인 함수를 의미합니다. D_{a,b}(i, j)는 문자열 a의 앞에서부터 i개 문자와 문자열 b의 앞에서부터 j개 문자 사이의 거리를 나타냅니다. 일반적인 edit distance에서는 delete cost, insert cost, replace cost가 다 1입니다.
식을 조금 해석해보자면,, 만약 min(i, j)가 0인 경우 즉, 문자열 a 혹은 b의 길이가 0이라면 두 문자열 중 하나가 비어있는 상태이기 때문에 D_{a,b}(i, j)는 max(i, j)로 계산되게 됩니다. 다시 말해 두 문자열 길이 중 더 긴 길이가 edit distance가 되는 것이죠.
그 외의 경우에는 (두 문자열 길이가 모두 1 이상인 경우) 3가지 경우 중 가장 작은 값으로 계산되게 됩니다.
- D_{a,b}(i-1, j) + C_{d} : 문자열 a의 마지막 문자를 삭제한 경우의 distance
- D_{a,b}(i, j-1) + C_{i} : 문자열 b의 마지막에 문자를 추가하는 경우의 distance
- D_{a,b}(i-1, j-1) + C_{r} : 문자열 a의 마지막 문자와 문자열 b의 마지막 문자가 서로 다른 경우의 distance
weighted edit distance 알고리즘은 pixel voting알고리즘을 통해 얻은 character 확률 정보를 사용하여 cost를 지정한 후 계산되기 때문에 일반적인 edit distance 알고리즘보다 문자 간의 유사성을 더 반영함으로써 더 정확한 recognition결과를 얻을 수 있는 것으로 이해하면 될 것 같습니다.
3. Experiments
실험단에서는 ICDAR2015, Total-Text, ICDAR 2015 세 데이터셋을 사용하였습니다.
Datasets
SynthText
약 800000장의 합성된 이미지로 구성되어 있습니다. SynthText dataset의 대부분의 text instance들은 multi-oriented이며, word단위의 어노테이션과 character 단위의 어노테이션이 둘 다 존재합니다.
ICDAR2013
229장의 학습 이미지와 233장의 테스트 이미지로 구성되어 있으며, bbox와 어노테이션 모두 word-level과 character level로 제공됩니다.
ICDAR2015
1000장의 학습 이미지와 500장의 테스트이미지로 구성되어 있으며, 모든 학습 이미지는 word 단위의 사각형 박스 좌표로 구성되어 있습니다. 오직 word level의 어노테이션만 학습에 사용할 수 있습니다.
Total-Text
horizontal text와 oriented text말고도 curved된 text도 포함하고 있습니다. 1255장의 학습 이미지와 300장의 테스트 이미지로 구성되어 있으며, 모든 이미지의 어노테이션은 word-level의 polygon 형태입니다.
전체 학습 과정은 두 단계로 이뤄집니다. 먼저 합성 데이터셋인 SyntheText으로 pre-training을 한 후, real world dataset으로 fine-tuning을 하는 식입니다. real world dataset의 크기가 굉장히 작은 편이기 때문에 fine-tuning을 할 때에는 data augmentation과 multi scale을 사용하여 학습하도록 하였습니다.
Horizontal text
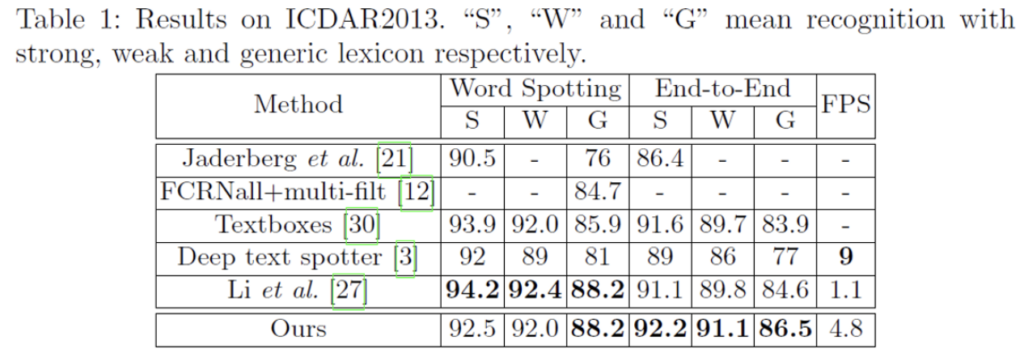
표에 보이는 S, W, G는 각각 Strong, Weak, Generic입니다. ICDAR2013 dataset은 lexicon(단어 사전)을 제공하는 데이터셋인데, 이 lexicon을 구성하는 단어 수에 따라 S, W, G가 구분되게 됩니다. Strong은 이미지당 100개의 단어를 제공하며 이미지에 나타나는 모든 단어를 포함한 사전이며, Weak는 전체 test set에 있는 모든 단어가 포함되어 있습니다. 마지막으로 Generic은 9만개의 단어를 가지고 있습니다.
ICDAR2013 dataset을 가지고 실험 결과를 보시면, End-to-End 단에서 SOTA를 달성한 것을 볼 수 있습니다. 이는 horizontal text만 포함한 dataset에 대한 성능에서 SOTA를 달성하였다고 보면 되겠습니다.
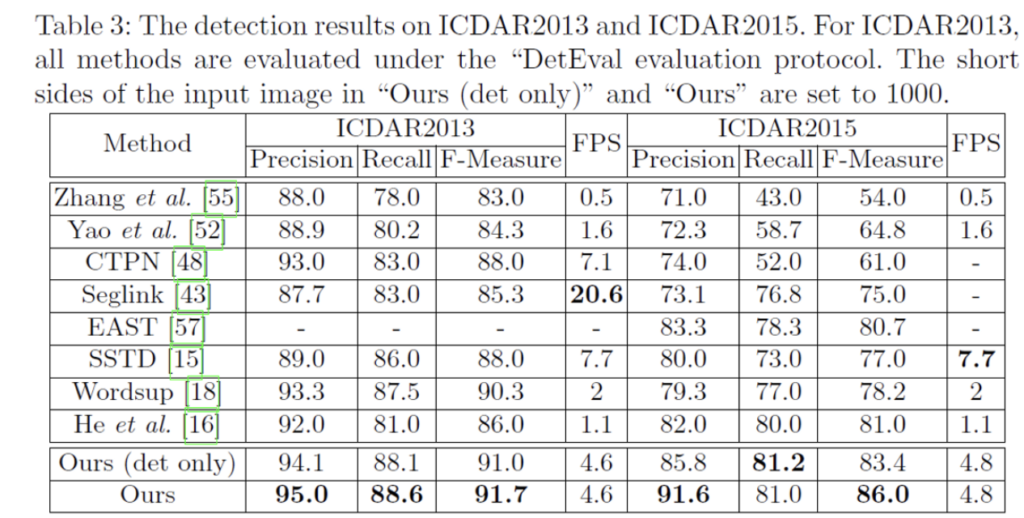
[Table3]은 detection 성능만을 측정한 것인데 보시면 [18],[16]은 multi-scale로 수행되었음에도 불구하고 single scale인 mask textspotter(ours)가 성능이 더 높은 것을 확인할 수 있습니다. (F measure: 91.7% vs 90.3%)
Oriented text
ICDAR2015 데이터셋으로 oriented text에 대한 성능 결과를 확인할 수 있습니다. 위 [Table 3]의 오른쪽 ICDAR2015 datase에 관한 실험 결과를 보시면, F-Measure이 84%정도로 이전 multi scale에서의 성능인 SOTA[16]보다 약 2.4%의 성능 향상을 이뤄냈습니다.
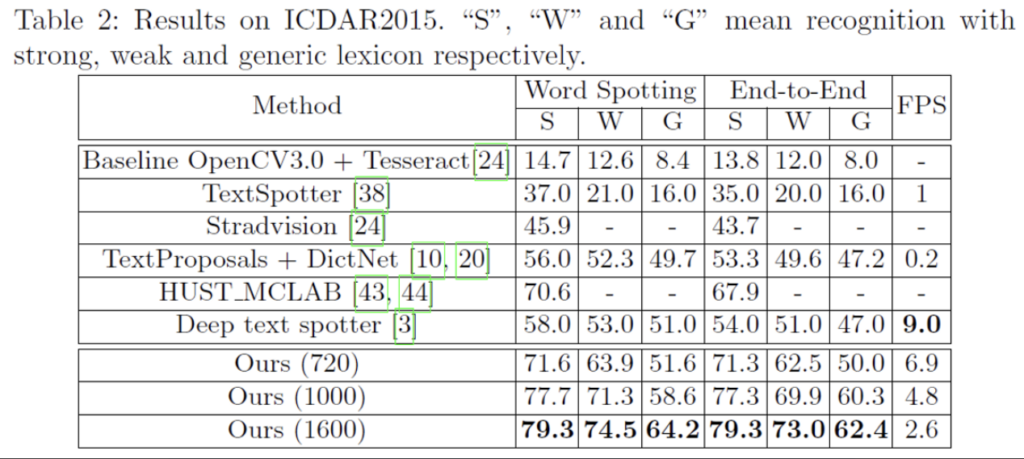
[Table2]의 mask textspotter옆에 720, 1000, 1600이 붙은 것은 scale을 나타낸 것으로 이미지를 세 가지 다른 scale로 처리하여 실험한 것입니다. 원래 기존 scale은 (720 x 1280)이었는데, 이를 이미지의 짧은 변이 1000, 1600이 되도록 조정한 것입니다. 이렇게 scale을 조정한 이유로는 ICDAR2015 dataset에는 비교적 작은 텍스트가 많기 때문이라고 합니다.
결과를 보시면 SOTA와 비교했을 때 13.2%에서 25.3%의 성능 향상을 이뤄낸 것을 볼 수 있습니다.
아래 그림은 ICDAR2013, 2015에 대한 정성적 결과입니다.

Curved Text
다음은 arbitrary text(예 : curved text)에 대한 성능을 확인하기 위해 Totaltext에서 실험한 결과입니다. test image의 짧은 변 길이를 1000으로 resize한 후 모델에 넣어주었습니다.

정성적 결과부터 보자면, 위에 있는 그림이 [TextBoxes]의 결과이고 아래쪽이 Mask TextSpotter의 결과입니다 보시면 textboxes같은 경우는 box를 사각형으로 치게 되기 때문에 curved된 데이터셋에 강인하게 동작하지 못하고 있음을 확인할 수 있죠. 반면에 mask textspotter같은 경우에는 curved text에 대해 detection, recognition 모두 잘 동작합니다.
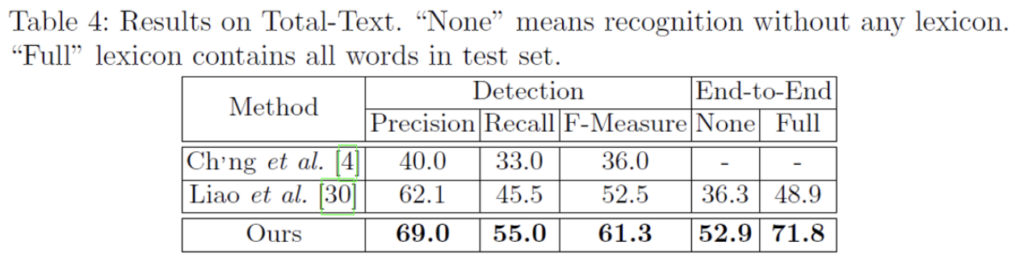
[Table4]에서 End-to-End부분에 None이라고 적혀 있는 부분은 recognition을 수행할 때 어떠한 lexicon(단어 사전)을 사용하지 않았다는 것이고, Full은 test dataset에 있는 모든 단어를 포함한 lexicon(단어 사전)을 사용한 것입니다. 당현하게도, Full인 경우가 None보다 성능이 훨씬 높은 것을 확인할 수 있습니다. detection, end-to-end에서 둘 다 SOTA를 찍게 되었습니다. detection 부분의 성능은 좀 비슷하다고 할 수 있지만, end-to-end에서 엄청난 성능 향상을 이룰 수 있게 되었는데 이에 대한 이유로는 recognition을 수행하는 영역을 직사각형이 아닌 polygon으로 둘러싸게 하여 더 정확한 위치 정보를 얻을 수 있기 때문이라고 생각해볼 수 있겠습니다. 또,, mask textspotter는 2차원 공간에서 sequence를 처리한다고 하였는데 [30]같은 경우는 1차원에서 sequence를 처리하였는데 이에 대한 차이로 생겨난 성능 차이로도 볼 수 있겠네요.