임근택 연구원님이 최근에 리뷰하긴 했는데, 저도 비슷한 논리로 실험을 수행중인 부분이 있어 참고차 읽어봤습니다. 제가 재밌게 읽었던 UBoCo 저자분 논문이더라고요.
Introduction
이 논문에서 다루는 분야는 Temporal Action Localization입니다. 현우님이 최근 WTAL 관련 논문들을 읽고 있으니, 관심 있으신 분들은 그쪽 리뷰를 읽어보시면 도움이 될 것 같은데요. TAL에서 기본적으로 필요한 부분은 관계가 없는 백그라운드 프레임에서 중요 프레임을 구분하는 역할을 하기 때문에, 복잡한 영상을 이해할 때의 기본으로 생각되는 TASK입니다.
영상의 특성상 길이가 길다는 특징이 있는데요. 이러한 문제 때문에 TAL에서는 긴 영상을 처리하기 위해, 영상을 겹치지 않는 짧은 단위의 스니펫 단위로 쪼개서 처리하고 있다고 합니다. 그래서 학습 구조가 아래와 같이 되는데요.
- (1단계) Kinetics400과 같은 대용량 행동 분류 데이터 셋으로 snippet encoder 학습
- (2단계) 추출된 Snippet feature로 Localization과 같은 downtream task를 수행하는 head 학습
이러한 구조 때문에, 결국은 snippet feature는 TAL과는 관계가 없는, 액션 분류 작업으로 학습이 되고 있는 실정입니다. (Localization을 위한 feature로 학습되지 않아 표현력이 떨어진다는 뜻)
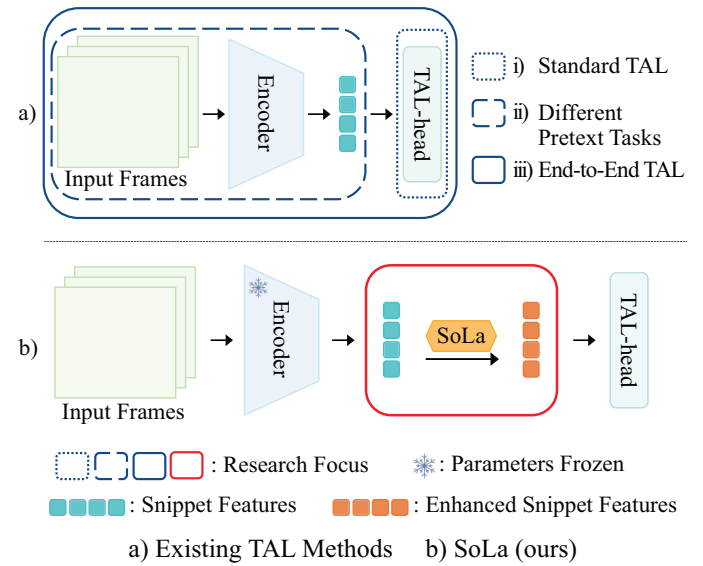
그럼에도 불구하고 기존의 논문들은 대용량 데이터셋의 학습 성능에 기인하여 좋은 성능을 내고 있었던 상황인데요. 최근 연구에서는 이러한 two-staged 접근에서 기인하는 Task discrepancy 문제를 지적하고 있다고 합니다. “Task discrepancy” 문제는 동일 액션 클래스에 대해 서로 다른 snippet의 민감도가 떨어지는 문제라고 하는데요. 이건 정리하면 시각적으로 유사한 프레임에 대한 구별력이 떨어지는 문제가 있다고 합니다. 이러한 문제를 해결하기 위한 방법이 snippet encoder에 “temporally sensitive pretext task”를 적용하거나, [그림 a]같이 end-to-end frame를 이용하는 방식이 있다고 하네요.
저자들은 이러한 문제점을 해결하기 위해서 Soft-Landing(SoLa) 전략을 이용하였다고 합니다. 기존의 방식과 가장 큰 차이점은 Encoder에 대한 학습은 Freeze 상태로 진행하고, 모델 자체도 매우 간단해서 적은 메모리와 계산량으로 학습이 된다는 점인데요. 제안하는 SoLa는 [그림 b]와 같이 미들웨어 처럼 작동해서, snippet feature를 projection 시켜 Localization Task에서 강인하게 작동하도록 합니다.
또한, Similarity Matching이라는 비지도 학습 방법론을 제안하는데요. 이건 SSL에서 많이 사용되고 있는 contrastive learning 방식의 학습 방식을 여기에 사용했는데요. “가까운 snippet feature는 유사할 것이고, 먼 snipper feature는 구분되어야 할 것이다”라는 전제 조건을 만족시키는 새로운 Loss를 제안해서 Localization에서 좋은 성능을 보였다고 합니다.
그래서 Contribution을 정리해보면…
- Soft-Landing 학습 전략을 제안
- SoLa의 학습 전략에 알맞은 SSL 학습 알고리즘인 Similarity Matching 제안
- 많은 연산량을 필요로 하는 다른 방법 대비 좋은 성능 향상폭을 보임
Method
Problem Description
소문자 L개의 프레임으로 구성된 영상 V :=v^l_{\psi=1}이 있다고 가정할 때, a개의 Snippet feature f \in \R^m을 추출하게 됩니다. 그런 다음 이 Snippet feature를 L = [l/a]의 서로 겹치지 않는 snippet feature sequence f^L_{\tau=1}로 만듭니다. 그런 다음 SoLa의 모듈에 태우게 되는데요. SoLa(\cdot) : \R^{L \times m} \to \R^{L \times m}, where \space F^{L}{\tau=1} = SoLa(f^L{\tau=1}) \space and \space F^L_{\tau=1}가 됩니다. 수식을 요약하면 특정 크기를 가진 feature를 refinement하는 개념으로 접근하는 모듈이라 같은 크기를 가진 output을 반환합니다.
Overview of Soft-Landing Strategy
SoLa의 학습 전략은 사전학습된 encoder와 downstream head 사이에 SoLa 모듈을 끼워넣는 것이 핵심 아이디어 입니다. 이런 간단한 구조로 기존 프레임워크에 수정 없이 끼워 넣을 수 있다는 것도 장점입니다.
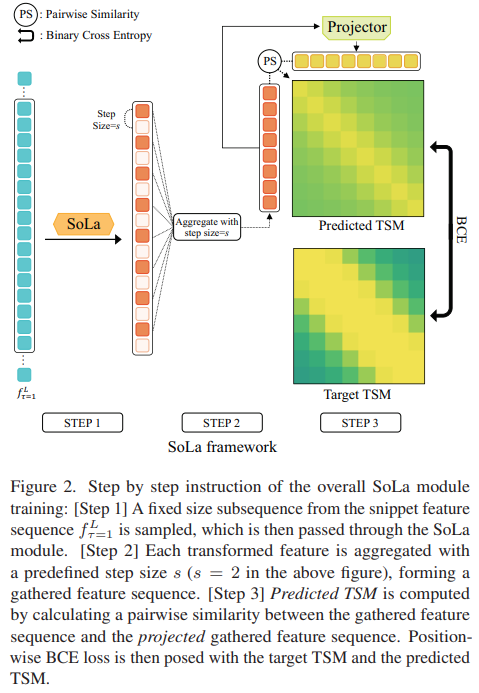
학습 과정은 [그림 2]에서 볼 수 있는데요. 그림이 간단한 만큼 엄청 간단합니다. Snippet feature를 뽑고, 지정된 step 크기만큼 샘플링을 수행하고, 샘플링 결과를 기반으로 Temporal Similarity Matrix(self-similarity matrix)를 만들고, 이 predicted TSM을 Target TSM과 BCE Loss를 해주는 과정이 끝입니다. 그렇기 때문에 Target TSM을 만들어주는 과정이 중요한데요…
Similarity Matching
이 Target TSM을 만들기 위해서는 현재의 가정을 이해할 필요가 있습니다. 가장 큰 전제조건은 라벨이 없는 self-supervised 학습을 해야한다는 점입니다. 대부분의 SSL 방법론들이 사실상 data augmentation의 확장이라는 점을 고려해봤을 때, 이러한 부분을 도입해야하지만… SoLa의 학습 구조상 snippet feature가 뽑혀진 상태에서 학습을 하기 때문에 사용할 수 없습니다.
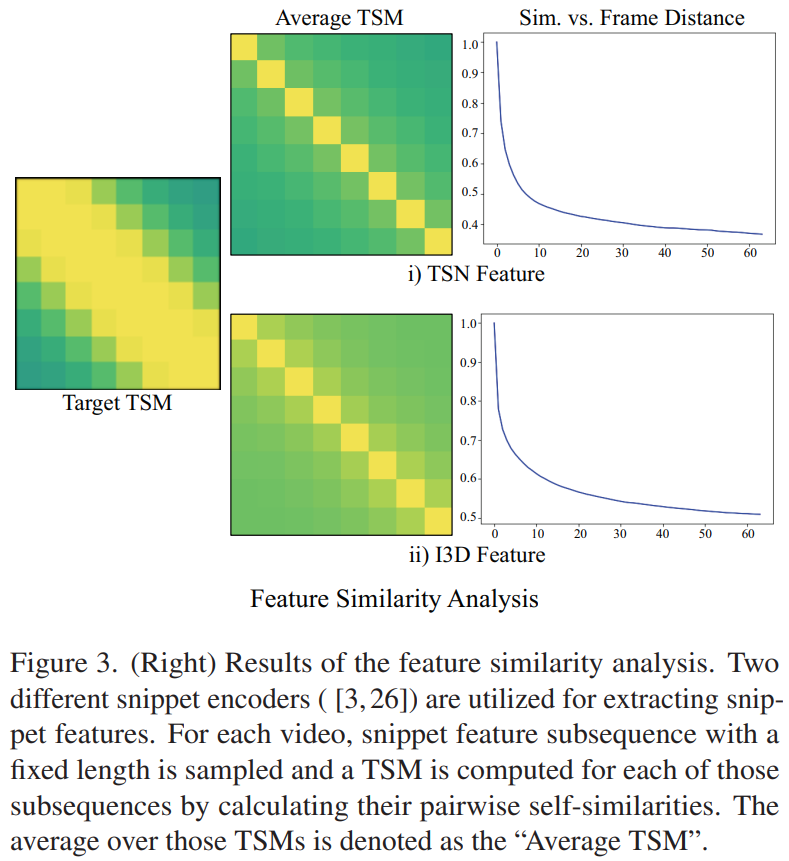
따라서 논문의 저자들은 “가까운 프레임은 유사하고, 먼 프레임은 다르다”라는 비디오의 일반적인 특성에 기인한 전제조건을 기반으로 하여 “temporal similarity 구조”에 좀 더 집중했는데요. [그림 3]은 영상 내의 TSM의 평균을 시각화한 결과입니다. 어떤 백본을 사용하는지와 상관없이 프레임간 거리가 멀어지면 멀어질수록 유사도가 낮아지고, 가까우면 유사도가 높은 경향성을 확인할 수 있습니다. 이러한 분석 결과를 통해, 프레임 간의 간격만을 활용하는 Similarity Matching이라고 불리는 feature 단위 학습 방법론을 제안합니다. (간단하게 목표만 설명드리면, 특정 알고리즘이 적용된 similarity matrix를 target TSM으로 만들어 학습하는 방식입니다.)
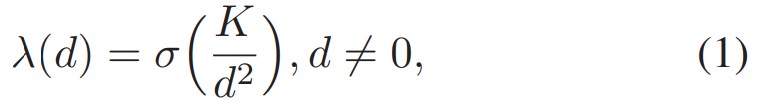
그래서 TagetTSM을 만들기 위해서 이 논문에서는 [수식 1]의 함수를 사용하는데요. K는 상수인데, Refinement 정도를 결정하는 상수라고 보시면 되고요. d는 프레임 간의 거리를 뜻합니다. \sigma는 sigmoid 함수를 뜻하는데요. 결론적으로 거리와 특정 상수 값에 Sigmoid를 취한 만큼 Target TSM의 값을 변경해준다고 보면 됩니다.
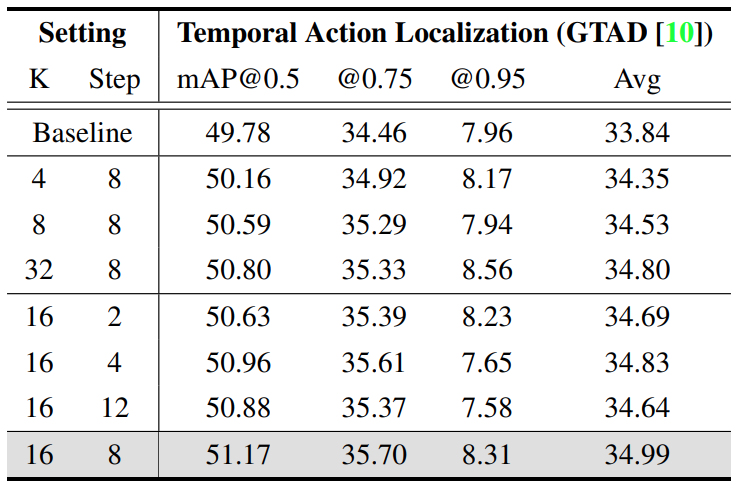
여기서 사용하는 K값에 대한 실험 결과도 있는데요. K가 너무 커도 성능이 좋지는 않고, 적당한 값이어야 한다고 하는 것 같네요. 이 targetTSM은 학습 기반으로 생성되는 것이 아니기 때문에, 최초 similarity matrix에서 적당한 값이 필요해서 그런 것 같습니다.
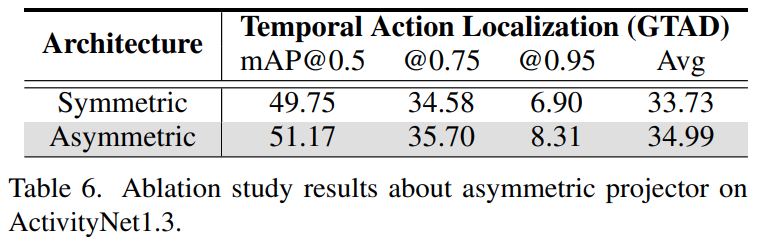
또 하나의 고민거리는 predictedTSM을 만들 때의 과정인데요. [그림 2]를 보면 특정 영상에 대한 Self-similarity matrix를 계산하는데, 한쪽 열에만 projection을 수행합니다. 이 구조는 Simsiam과 같은 방법론에서 따왔다고 하는데요. 실제로 [표 6]을 보면 비대칭일 경우 성능이 높은 것을 확인할 수 있습니다. 그래서 projector network Proj(\cdot) : \R^m \rightarrow \R^m은 두개의 FC 레이어로 구성되고, z_i = SoLa(f^L_{\tau=1})[i], z_j = Proj(SoLa(f^L_{\tau=1})[j])와 같이 비대칭 구조입니다.
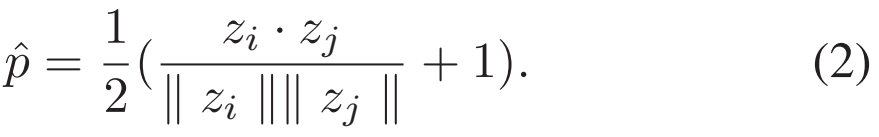
우선 유사도 관점에서 코사인 유사도는 -1에서 1로 나오기 때문에, 이를 0에서 1로 맞춰주기 위해서 [수식 2]와 같이 rescaled cosine similarity를 사용하고요.
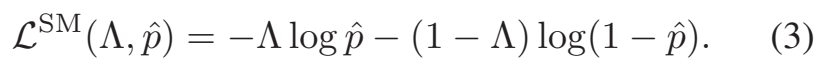
L^{SM}은 일반적은 BCE Loss인데요. predicted TSM의 similarity matrix와 [수식 2]를 통해 생성된 TagetTSM의 similarity matrix가 일치해지도록 학습합니다.
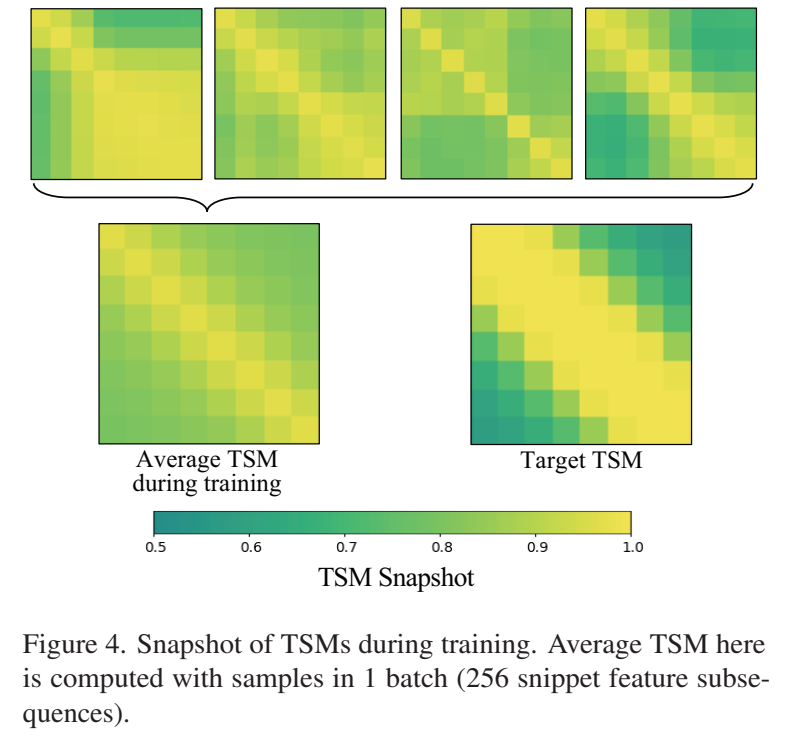
마지막으로 논문 저자들은 결국은 고정된 알고리즘으로 Target TSM을 생성하기 때문에, 학습 자체가 단조로워지는 문제가 없을까 싶은 의심에 대한 부연 설명도 붙이는데요. 배치 단위로 학습을 하기 때문에, [그림 4] 처럼, 배치 내에서 다양한 패턴이 등장하기도 하고, 실제로 학습 결과의 평균을 봐도 분명하게 개선된 것이 보이는 것을 보아 이러한 문제가 없음을 보입니다.
Experiments
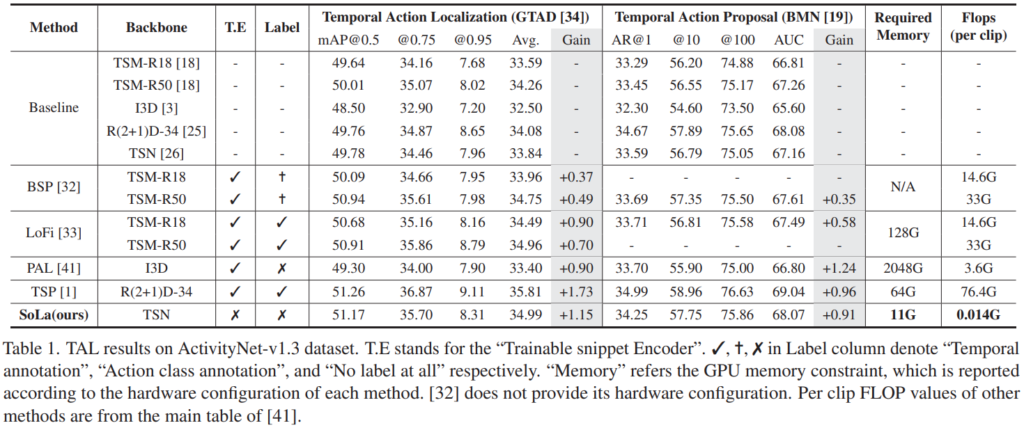
우선 주요 벤치마크 성능이 나와있는 [표 1]을 먼저 보겠습니다. 제안하는 방법론의 가장 큰 특징 중 하나는 가볍다인데요. 기존 방법론 대비 매-우 가볍습니다. 이는 표에 “T.E”표시가 encoder 학습 유무인데요. 백본 학습을 안하기 때문에 가벼운 특징을 가집니다. 거기에 라벨도 안쓰는데… 성능이 매우 준수하네요. 기존 TSP 대비 조금 낮은 성능인데, 속도와 라벨 사용 유무를 감안해보면 준수한 성능으로 보입니다.
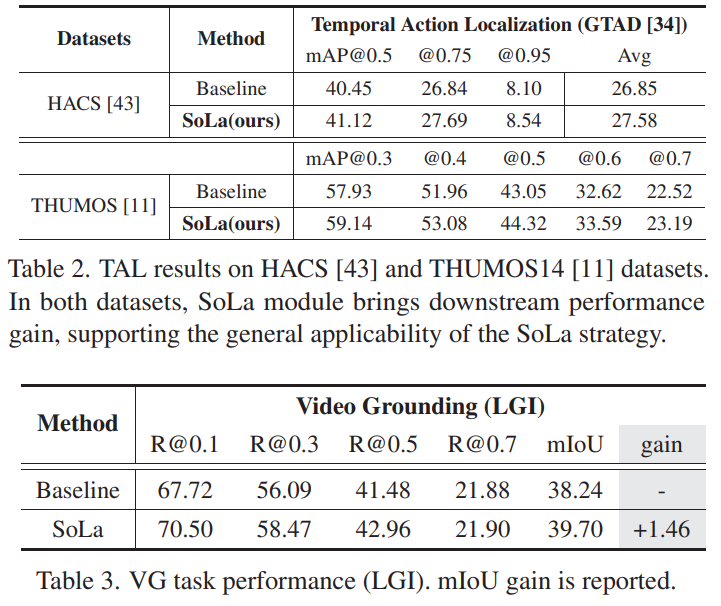
다른 데이터 셋에서의 성능은 [표 2]에서 확인할 수 있습니다. ActivityNet 뿐만 아니라, 다른 데이터 셋에서도 동일하게 성능이 오르는 것을 확인할 수 있습니다. 이를 통해서 일반적으로 잘 통하는 방법임을 증명합니다. 또한, 다른 Task (Localizatoin이랑 그래도 유사한 점은 있는 Video Grounding)에서도 SoLa의 학습 방식이 성능을 향상시킴을 보입니다.
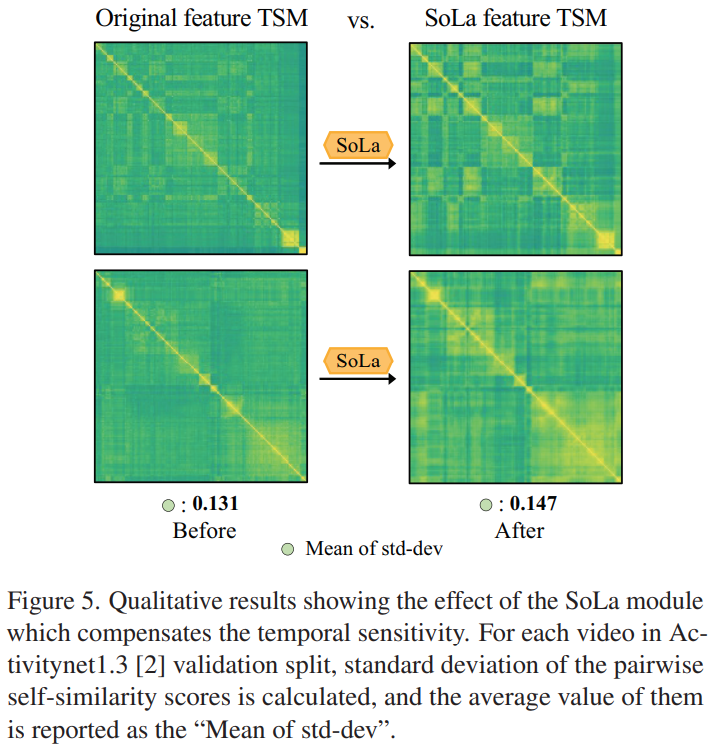
제가 중점적으로 보고싶었던 부분이 바로 이 [그림 5]인데요. 실제로 SoLa가 유사도 관점에서 개선을 수행하는지를 확인할 수 있는지를 확인할 수 있습니다. 실제로 패턴이 좀 더 두드러지는 것을 확인할 수 있습니다. 근데 원래 색이 옅었던 부분도 색이 진해진 결과도 있긴한데… 코드가 없으니 확인할 방법은 없네요.
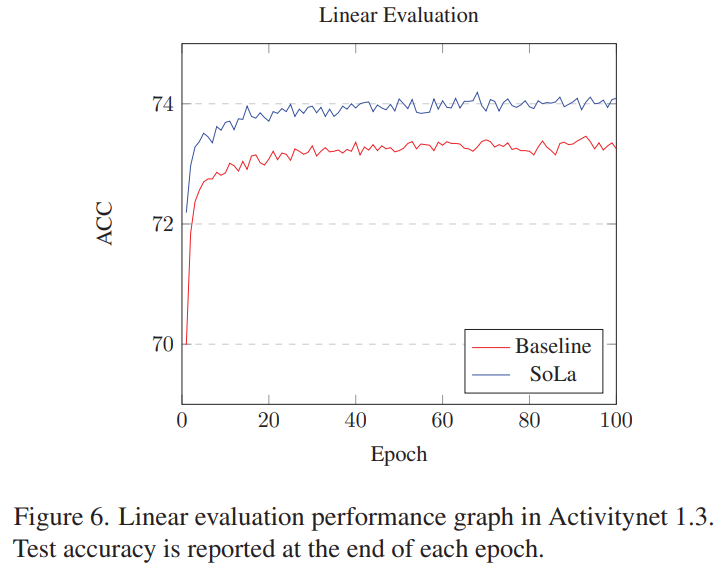
Feature의 표현력을 측정하는 방식으로 흔하게 쓰이는 Linear evaluation 결과에서도 SoLa의 feature가 베이스라인 대비 높은 성능을 보입니다. 분류 기준은 Action 분류는 아니고요. Temporal한 정보를 많이 담았는지를 측정하기 위해서 영상 내의 스니펫이 foreground/background인지를 구분하는 평가를 진행했다고 합니다. 실제로 성능이 올랐으니, 구분력이 생겼다는 것이겠죠?
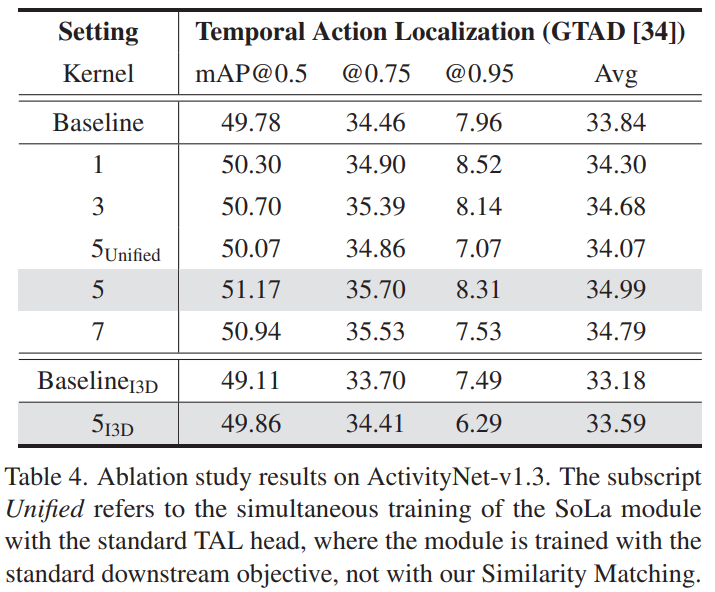
[표 4]는 Ablation 표인데, Unified 가 표시된 위 아래만 딱 보면 좋을 것 같습니다. Similarity Matching 없이, TAL head까지 같이 학습했을 때의 성능이 Unified인데요. 왜 따로 했을까 궁금하긴 하지만, 아마도 Similarity Matching으로 Temporal Action Localization을 충분히 학습할 수 있다는 점을 보이고 싶었던 것이 아닐까… 하네요.
Conclusion
본래 자주 읽던 분야가 아니라 필요한 부분만 볼까 하다가 그냥 리뷰로 썻습니다. 어쩌다보니 비슷한 컨셉으로 실험을 진행하고 있는데, 열심히 해봐야겠네요 ㅎㅎ…
안녕하세요. 리뷰보고 댓글 남깁니다.
영상이 너무 길어서 겹치지 않는 짧은 단위인 snippet으로 쪼개여 사용한다고 해주셨는데, 이 snippet이라는 용어는 clip이라는 용어랑 어떤 차이가 있나요? 긴 동영상을 클립으로 쪼개고 이러한 클립들에서 또 snipper으로 쪼개는 듯한 느낌인가요? 혹은 그냥 둘이 같은 표현인가요?
그리고 target TSM을 만들어주기 위하여 프레임 간에 거리라는 개념을 사용했다고 하셨는데 컨셉은 이해가 가지만 실제로 어떻게 적용했는지를 이해하기가 힘드네요.
수식 1번의 개념을 어디에 적용했다는 것인가요? Predicted TSM에다가 수식1번을 적용해서 target tsm으로 만든 다음에 둘 사이에 consine similarity를 계산하여 이를 줄이는 방식으로 학습했다는 것인가요?
클립과 스니펫은 어떤 연구에서 쓰느냐에 따라 이름이 조금 바뀌는 느낌입니다. 고정된 크기로 feature를 만든다는 점에서 동일합니다.
실제 적용 사례가 간단해서 저도 간단하게 설명하고 넘어갔는데 비디오를 잘 모르면 어려울 수도 있겠네용… 부연 설명을 조금 붙여보자면. 특정 알고리즘(수식 1)을 모든 target TSM의 원소에 적용해줬다고 보면 됩니다. [그림 3]이랑 같이 보시면 이해가 조금 될텐데요. 원래 Self-similarity matrix에서 대각선은 자기 자신이니까 1이고 그 대각선 주변으로 희미하게 유사도가 존재하는데, 이걸 [수식 1]을 적용해서 [그림 3]의 Target TSM처럼 높은 유사도로 변화시켜줍니다.
Predicted TSM에 수식 1을 적용해서 refinement된 target TSM을 만들고 consine similarity를 계산하여 이를 줄이는 방식으로 학습하는 것이 맞긴 한데, TSM(similarity matrix)를 만들기 위해 쓰는게 cosine similarity고 학습할 때는 그 matrix 끼리 BCE Loss를 통해 최대한 유사해지게 만들면서 학습합니다.
안녕하세요 리뷰 잘 봤습니다.
지금 하고 계신 실험의 방향과 같은 것으로 알고 있는데 제가 알기론 SoLA의 구현이 Lienar Layer 하나만 짜주면 되는 것으로 알고 있어서 따로 해보실 생각은 없으신가요?
비슷한 방향이긴 한데, 저랑은 살짝 달라서 고민은 하고 있는 부분이고요.
구현 방법이 사실 제 실험 구조에서 Matrix 만들어주는 부분만 고치면 되는거라, 시간이 나면 검색 성능에서 향상이 있는지 확인 해볼 생각이 있습니다.