제가 이번에 리뷰할 논문은 CVPR 2022 논문으로, 6D Pose Esimation중 indirect method에 관한 논문입니다. 여기서 indirect method란 이미지로부터 직접적으로 pose를 구하는 direct method와 다르게 2D 이미지와 3D point를 매칭하여 PnP with RANSAC등의 방법론을 통해 Rt Pose를 예측하는 방법론입니다. 본 논문은 분포를 이용하여 시각적 ambiguities 를 모델에 임베딩할 수 있다는 것이 가장 큰 특징입니다.
Abstract
본 논문은 symmetry과같이 visual ambiguities에 대한 사전 지식 없이, dense하고 연속적인 2D-3D correspondence를 학습하는 방법을 제안하였습니다. 또한, 학습된 분포를 사용하여 Pose 가설을 샘플링하고 score를 구하고 pose 가설을 개선하는 새로운 방법을 제안합니다. 이때 correspondence 분포는 contrastive loss를 이용하여 학습되었으며, 해당 방법론을 통해 SOTA를 달성하였다고 합니다.
Introduction
2D-3D correspondences는 symmetricm, occlusion, lignting 변화와 같은 visual ambiguity가 없을 경우에는 2D와 3D 포인트를 식별할 수 있습니다. 그러나 visual ambiguity가 있을 경우 3D object point에는 해당 영역에 대응되는 poin가 존재할 수 있습니다. 저자들은 이러한 ambiguity 영역에서 최적의 추정이 아닌 가능한 correspondence에 대한 전체 분포가 필요하다고 이야기하며 이러한 분포는 저자들이 처음으로 제시하였다고 합니다. 또한, 어떤 visual ambiguity가 발생했는지 정보를 주지 않고 분포를 학습합니다. 정리하자면, visual ambiguity가 발생할 경우, 문제가 발생한 영역에 대해 correspondence를 추측하여 구하는 것이 아니라, 가능한 correspondence 분포를 학습하는 방식을 제안한 것입니다.
6D pose estimation 방법론 중 2D-3D correspoindences를 구한 뒤 이를 이용하여 PnP-RANSAC을 이용하여 pose를 예측하는 방법론이 있으며 이러한 연구는 어떻게 correspondences를 구할 지에 대한 연구가 이루어집니다. 이때 correspondences를 구하기 위해 keypoint 대응을 이용하거나 pixel-wise의 대응을 이용하는 연구로 구분되며, pixel-wise의 대응을 고려하는 방법론들은 visual ambiguity 중 대칭 문제는 명시적으로 처리하지만 그 외의 다른 visual ambiguity는 처리하지 못합니다. (명시적으로 처리한다는 것은 클래스마다 별도의 학습을 하는데, 이때 대칭인 클래스에 대해서는 사람이 별도의 처리를 수행하는 것을 의미하는 것으로 보입니다.)
최근 연구 중에 EPOS **는 표면을 조각으로 나누어 각 조각에 대한 확률분포를 구하는 방식을 적용하였으나 표면을 조각으로 표현하는 데 연산량이 많이 들어 표현이 제한적이라는 문제가 있습니다.
*** Tomas Hodan, et al. Epos: Estimating 6d pose of objects with symmetries. (CVPR 2020)*
또 다른 연구인 continuous surface embeddings*** 연구에서는 연속적인 표면을 embedding하 dense한 2D-3D correspondences를 구축하는 연구가 진행되었으나 해당 방법론은 픽셀당 하나의 대응만을 설정하며, 분포에 대해서는 설명하거나 효과를 보이지 않았고 분포를 pose 추정에 이용하지 않았다고 합니다.
**** Natalia Neverova, et al. Continuous surface embeddings. NeurIPSNIPS, 2020.*
본 논문에서는 dense하고 연속적인 2D-3D correspondence 분포를 contrastive learning 방식을 이용하여 학습하는 방법론을 제안합니다. key model을 이용하여 object의 좌표를 key embedding으로 매핑하고, 인코더-디코더 구조인 query model을 이용하여 이미지를 dense query embedding으로 매핑하는 두가지 모델을 이용합니다. query는 key에 대한 correspondence 분포를 나타내며 두 모델을 서로 contrastive learning 방식으로 학습됩니다.
본 논문의 contribution을 정리하면
- visual ambiguity에도 정확도를 높이기 위해 연속적인 2D-3D correspondence 분포를 제안
- 분포를 사용하여 pose를 샘플링하고 score를 매기고 refine하여 symmetry를 포함하여 다양한 visual ambiguity를 암묵적으로 고려하여 SOTA 달성
Method
1. Overview
detection 모델을 이용하여 이미지를 object 영역에 대해 crop하여 pose 추정 모델에 입력합니다. 입력된 이미지는 저자들이 제안한 네트워크를 통과하여 dense한(pixel-wise) surface 분포와 correspondence 분포를 생성하는 mask를 구하고, correspondence 분포로부터 PnP-RANSAC 방식을 적용하여 pose 가설을 샘플링합니다. 이후 mask와 surface 분포를 기반으로 pose 가설에 대한 score를 매기고 가장 높은 score를 갖는 pose 가설에 대해 surface 분포로 refine을 수행하여 최종 pose를 구합니다.
2. Learning Correspondence Distributions
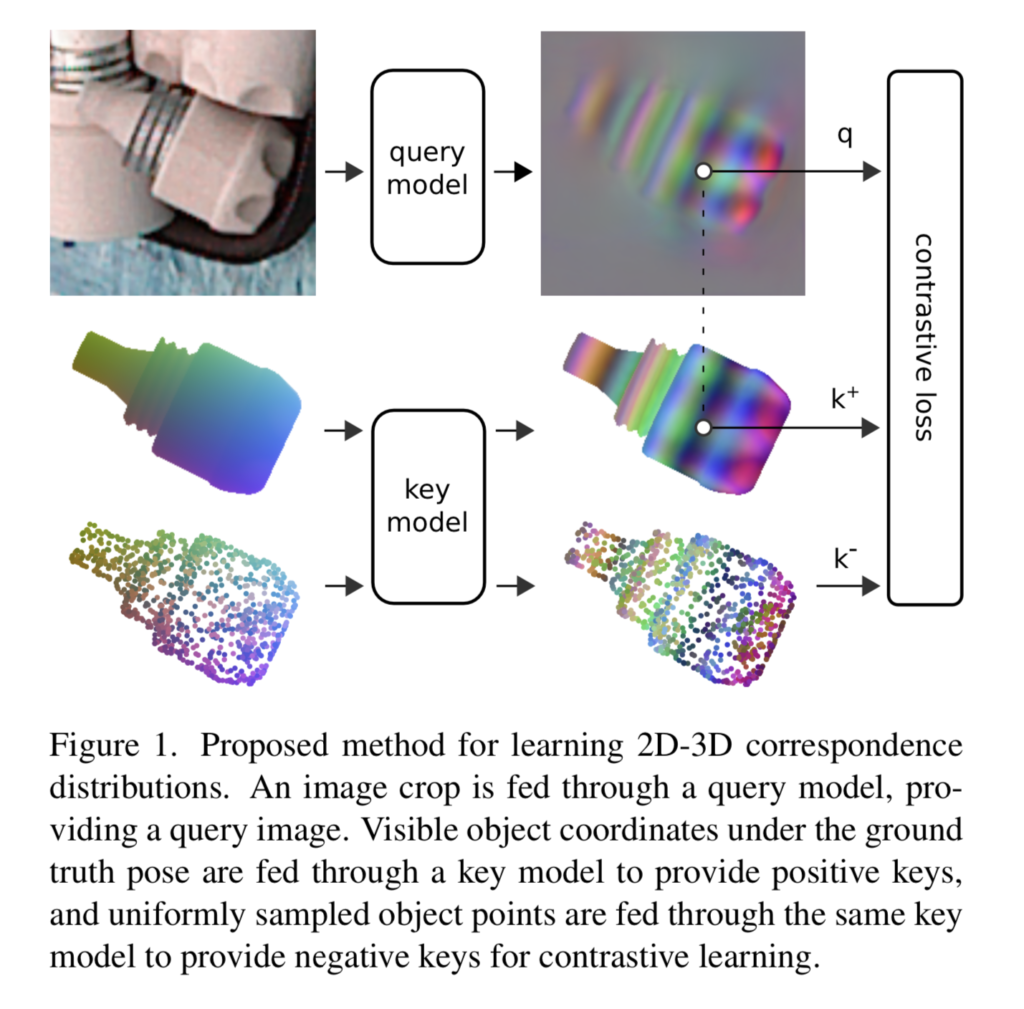
crop 된 이미지 I∈\mathbb{R}^{H⨉W⨉3}와 object에 대한 마스크내부의 이미지 좌표 u∈M가 주어졌을 때, object 표면의 어떤 point c 가 픽셀에 대응되는 지를 묘사할 수 있는 surface 분포를 학습하는 것을 목표로 합니다.
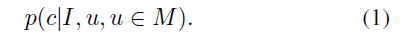
이때, 물체가 가려진 영역도 포함하여 object가 존재하는 픽셀 집합을 마스크로 나타냅니다.
q∈\mathbb{R}^E가 query이고, shared embedding sapce 에서 k∈\mathbb{R}^E가 key, 표면 위의 점 c_i가 대응되는 key를 k_i라 합니다. query가 주어졌을 때, discrete한 surface point \tilde{S}⊂S에 대해 surface 분포는 모든 query와 key 사이의 내적에 softmax를 적용한 것으로 정의하며 아래의 식으로 표현됩니다.
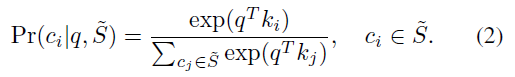
본 논문의 방법론은 key model과 query model 두개의 모델을 이용합니다.
- key model
- surface point를 key로 매핑(g: \mathbb{R}^3 → \mathbb{R}^E)
- 작은 fully connected network
- query model
- color 이미지를 query로 매핑(f: \mathbb{R}^{H⨉W⨉3} → \mathbb{R}^{H⨉W⨉E})
- encoder-decoder 구조의 CNN
객체 표면에서 균일하게 샘플링한 surface point 집합 \tilde{S}와 object의 mask 영역에서 균일하게 샘플링한 이미지 좌표의 집합\tilde{U} = \{ u_1, …, u_N \}의 embedding을 학습하기 위해 InfoNCE loss를 이용합니다.
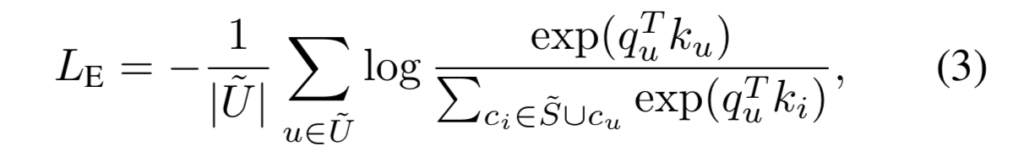
- q_u: query 이미지 u로부터 구한 query 값
- k_u=g(c_u): object의 좌표c_u로부터 구한 key 값
InfoNCE loss를 최적화 할 경우, 확률 밀도의 비율을 추정할 수 있다고 합니다.
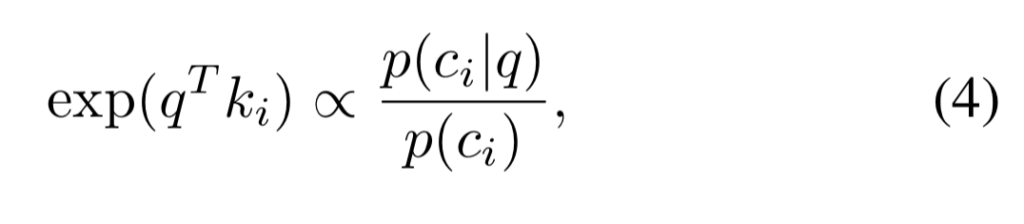
여기서 sample c_i는 표면에서 균일하게 샘플링하였으므로, exp(q^Tk_i) ∝ p(c_i|q)가 됩니다. 이는 object의 표면을 정규화하여 식(1)의 확률밀도함수를 추정한다는 의미라합니다. 따라서 식(1)은 아래의 식으로 표현됩니다.
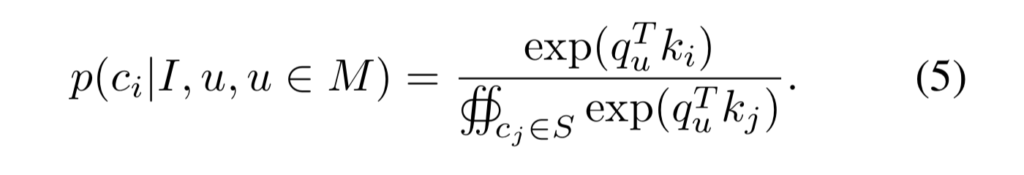
위의 내용은 픽셀이 object 영역 안에 있다는 가정하에 surface 분포를 구하였습다. correspondences p(c,u|I)를 구하기 위해, 동일 채널을 갖는 CNN으로 구성된 query model을 추가합니다. query model은 object mask를 예측하고, 이미지 좌표에 대한 이산분포 Pr(u|I)이 객체가 픽셀 u에 존재할 것으로 추정되는 확률에 비례하도록 합니다.
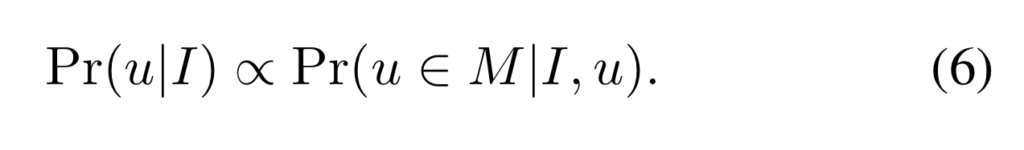
따라서 correspondences 분포는 다음과 같이 모델링됩니다.
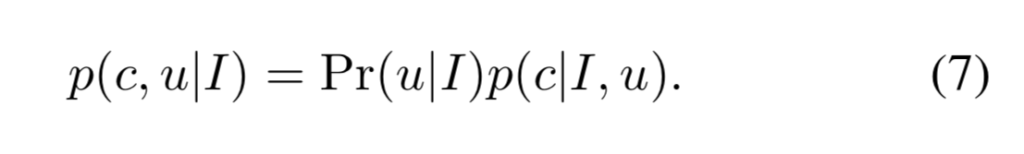
또한 마스크에 대해서는 binary cross-entropy loss를 이용하여 마스크에 대한 오차 L_M를 측정하며, total loss는 surface point에 대한 loss 식(3)과 object 영역에 대한 loss L_M를 합쳐 구하게 됩니다.
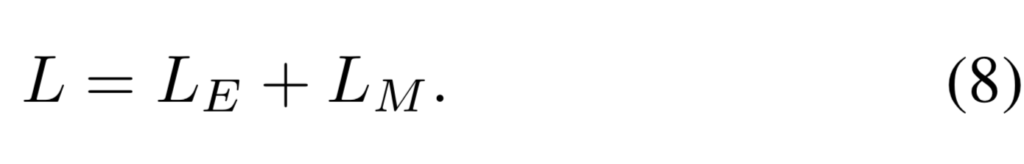
3. From Embeddings to Pose
Inference시 2D-3D correspondences는 식(7)로부터 추정된 correspondences 분포를 기반으로 구할 수 있습니다. correspondences는 추정된 mask와 correspondences 분포와의 일치를 기반으로 score를 매겨 pose 가설을 생성하며, 가장 높은 점수를 가지는 가설을 surface 좌표의 확률의 최대화를 통해 refinement를 수행합니다.
Sampling Pose Hypotheses.
2D-3D correspondence 분포는 모든 점에 대한 평가가 가능하므로 연속적이지만 Meshlab** 툴을 이용하기 위해 object surface에서 \hat{S}⊂ S, |\hat{S}| ≈ 75.000가 되도록 균일하게 샘플링한 point 집합을 선택합니다.
각 query에 key들에 대한 확률 분포를 계산하고 mask 확률을 곱하여 inversion sampling을 이용하여 샘플링하여 효율적으로 데이터를 샘플링할 수 있는 correspondence 확률(식 7)을 얻습니다. 이 분포를 샘플링하면 추정된 mask 내부에서 고르게 sampling이 수행됩니다. 낮은 entropy로 이미지 좌표를 더 자주 샘플링하기 위해 Pr(c,u|I)^{\gamma}에 비례하는 샘플링을 통해 correspondences 분포를 sharp하게 만들고, 이때 \gamma는 실험적으로 1.5로 설정하였다고 합니다. Pose 가설은 PnP계열의 알고리즘을 이용하여 생성했다고 합니다.
또한, Occlusion이 되지 않지 않는 영역에 대해서만 correspondence를 설정하기 위해 pose 가설을 생성할 때 사용되는 correspondences는 pose 가설에서 확인이 가능해야 하고, 따라서 위의 조건에 맞지 않는 pose 가설들은 폐기됩니다.
Pose Hypothesis Scoring.
pose에 대한 점수는 train loss를 이용하여 구합니다. Train loss는 두 부분으로 이루어져 있으며, 첫 번째 부분은 추정된 마스크와의 일치도를 나타내고, 두 번째 부분은 추정된 대응 분포와의 일치도를 나타냅니다. Mask에 대한 점수는 pose 가설 mask에서 추정된 평균 log likelihood로 정의됩니다.
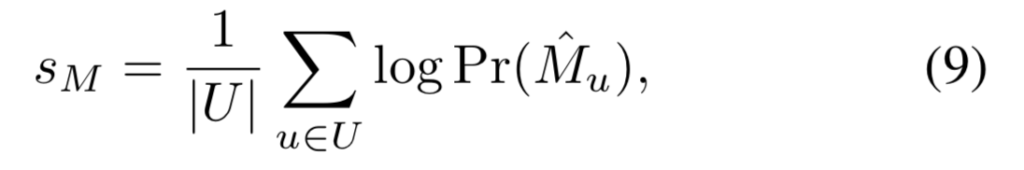
- U: 이미지의 모든 픽셀 좌표 집합
- \hat{M}_u: pose 가설에서 object가 존재하는 지
correspondence score는 visible한 surface 좌표의 평균 log likelihood로정의됩니다.
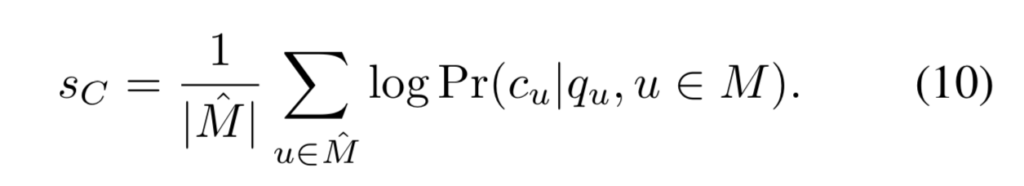
두 점수를 연관시키기 위해, 최대 entropy를 이용해 정규화합니다.
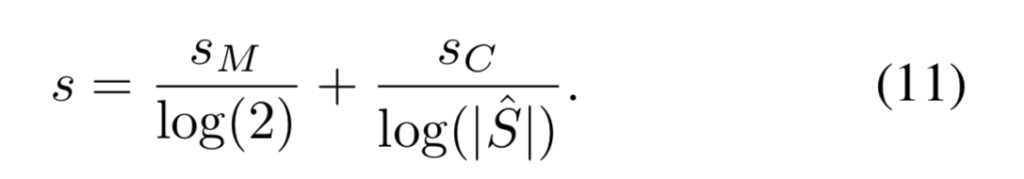
Pr(c|q)는 모든 query-key 쌍에 대해서 한번씩 계산되며, inversion sampling에 사용되는 table l∈R^{H×W×|\hat{S}|} 를 구하고, 여기에 인덱싱을 하여 식(10)에 대한 계산을 수행합니다.
Refinement.
가장 좋은 점수를 가진 pose 가설은 식 (10)의 correspondence 점수의 최소화를 통해 pose 가설에 refinement를 수행합니다. 먼저 Pose 가설을 보이는 영역의 좌표를 초기의 pose 가설을 이용하여 렌더링합니다. 최적화를 위해 object 좌표를 현재 pose로 이미지에 투영하며 bilinear interpolation과 식(2)의 분자를 평가하여 query 이미지를 샘플링합니다. 분모는 연산량이 너무 많이 들기 때문에 분모에 대해 계산을 하지 않고, 사전에 모든 query에 대해 계산하고 bilinear interpolation을 통해 분모 이미지들을 샘플링합니다.
Usin Depth Imagegs.
단일 color 이미지만을 이용할 경우 정확도 높은 pose 예측이 어려우므로, 저자들은 depth 이미지를 이용하여 pose를 조정하였다고 합니다. 본 논문에서는 query norm이 전체 query norm의 80% 이상인 이미지 좌표의 집합을 찾고, query norm값이 큰 경우 확실한 모델임을 나타내므로 해당 좌표들이 object중 보이는 영역에 해당한다고 보고 depth 이미지와 pose 가설을 이용하여 각 좌표에서 추정된 depth의 차이를 찾고, 차이들의 중앙값을 이용하여 조정합니다.
Experiments
bop challenge에서 사용하는 7개의 밴치마크 데이터(LM-O, T-LESS, YCB-V 등)에 대해 평가를 진행하였습니다. 단일 이미지에 다양한 object가 존재하는 영상들에 대해 pose를 추정하며, 아래의 3가지 기준을 이용하여 recall 성능을 측정하고 평균 recall은 3가지 recall의 평균 나타냅니다.
- MSSD(Maximum Symmetry-Aware Surface Distance)
예측 pose와 GT Pose에 연결된 mesh들의 point사이의 거리 중 최대 유클리드 거리 - MSPD(Maximum Symmetry-Aware Projection Distance)
예측 pose와 GT Pose에 연결된 모든 point 사이의 최대 re-projection오차 - VSD(Visible Surface Discrepancy)
예측 pose와 GT Pose에서 렌더링된 Mesh 사이의 depth 불일치로, 모델의 모든 point가 아닌, 이미지에서 보이는 픽셀에 대해서 측정
Inference시 합성 이미지에 대해 훈련된 모델인 CosyPose***에서 사용한 detection crops 방식을 사용합니다. 또한, 입력을 0, 90, 180 및 270도 회전하고, 모델을 통해 피드백하고, 다시 회전하고, 평균화하는 간단한 테스트 데이터 증강 기법을 이용하였다고 합니다.
***Labbé, Yann, et al. “Cosypose: Consistent multi-view multi-object 6d pose estimation.” (ECCV 2020)
추론 시간은 크롭된 이미지당 약 2.2s입니다.(query model을 통과할 때 약 20ms, PnP-RANSAC을 수행할 때 1.2s, pose refinement시 1.0s) 또한 PnP-RANSAC을 수행할 때 고정적으로 20회 반복합니다.
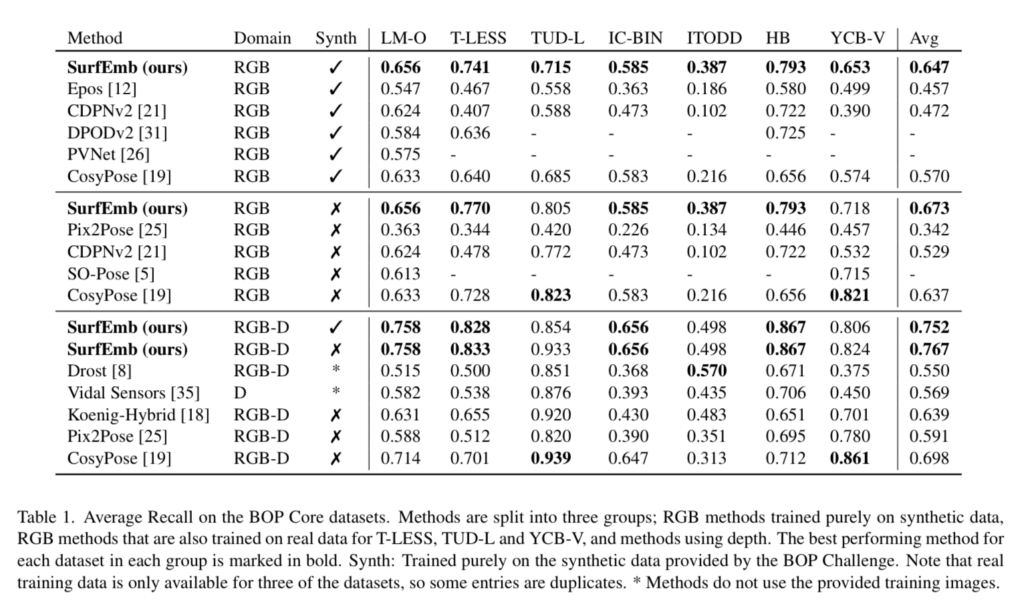
Main Results.
Pose 추정 결과를 위의 table 1에서 확인할 수 있습니다. T-LESS와 HB 데이터에 대해 합성 데이터를 이용한 학습시 SOTA를 달성하였으며, real 데이터만을 이용하며 depth도 함께 사용할 경우에도 SOTA를 달성하였습니다. 또한 7가지 데이터에 대해 평균 성능을 확인해 보았을 때도, 합성 데이터를 이용하거나 이용하지 않은 경우, depth 데이터를 이용할 경우 모두 가장 좋은 성능을 보였습니다.
Qualitative Results.

Figure 3을 통해 대칭으로 인해 시각적으로 유사한 surface point들이 유사한 embedding을 가진다는 것을 확인할 수 있습니다. 물체에 대한 key embedding이 물체에 암묵적으로 학습이 되었다는 것을 확인할 수 있습니다.

또한, Figure 4 합성 데이터에 대해 학습된 모델이 real 이미지에서 정확한 분포를 만들 수 있다는 것을 보였습니다. Occlusion된 query의 분포(왼쪽 위, 노란색)가 높은 entropy를 가지며(노란색 query에 해당하는 분포 다른 영역과 비교했을 때 넖은 분포를 보임), 시각적 ambiguities가 없는 경우(오른쪽 아래, 노란색 & 빨간색, 가려지는 부분도 없고, 대칭적인 객체도 아님) 부정확한 분포를 보이지만, 시각적으로 유사한 부분에 분포가 나타나므로 유의미하다고 할 수 있습니다.
Failure Cases.
합성 데이터에 대해 훈련된 저자들의 방법론은 CAD 모델이 실제 객체를 잘 나타내는 경우에 잘 작동합니다. YCB-V의 bowl과 cup과 같은 일부 객체들은 CAD 모델을 생성할 때 반사로 인해 부정확한 모델이 생성되고, 이러한 부정확한 모델에 의존하므로 정확도가 떨어졌다고 합니다.
또한, LM-O, TUD-L, IC-BIN, YCB-V의 GT가 상당히 부정확하였고(아래의 Figure 6에 나타냄) 이러한 경우 모델이 잘못된 정보를 포함하므로 정확도가 떨어지는 경향이 있다고 합니다.

안녕하세요 이승현 연구원님 좋은 리뷰 감사합니다.
EPOS라는 연구를 언급하시며, 연산량이 많이 들어 표현이 제한적이라고 하셨는데 해당 논문에는 이런 연산량에 대한 리포팅은 따로 없을까요? 그리고 마지막에 보여주신 Failure Cases 는 그럼 어떻게 처리하는지도 궁금합니다.
우선, 본 논문에는 EPOS의 연산량에 대한 리포팅은 따로 없었습니다. 해당 내용에 대해 추가적으로 설명을 드리자면, EPOS는 object의 표면을 n개의 조각으로 표현하고, 이에 대한 offset을 구하는 방식입니다. 할 수 있습니다. 그런데 n이 커지면 연산량이 너무 많아지고, n이 작아지면 표현력이 작아지기 때문에 이렇게 표현한 것으로 보입니다.
두번째로 Failure Cases에 대한 내용은, 저자들이 성능이 일부 데이터에서 성능이 낮은 이유를 분석한 것으로 보입니다. 그중, GT가 부정확한 경우에는 recall을 구할 때 threshold를 낮추어야 한다고 이야기합니다.