안녕하세요. 백지오입니다.
열 번째 X-REVIEW는 Knowledge Distillation 기반의 Video Retrieval 방법인 DnS입니다. 저널 논문은 이번에 처음 읽어보았는데, 투 컬럼 22 페이지의 압도적인 분량에 그만 정신이 아득해지고 말았으나, 그래도 악으로 깡으로 버티니 어찌 읽어지기는 한다는 자신감(?)을 얻을 수 있는 논문이었던 것 같습니다…
이번 리뷰부터, 평소에 Video나 제가 리뷰하는 분야에 잘 관심이 없으시더라도 이 논문에서 얻어갈 만한 것이 있는지 알려드리고, 소중한 주말을 할애해 읽을 만한 리뷰인지 판단하기 편하시도록 가볍게 리뷰의 리뷰를 하고 X-REVIEW를 시작하려고 합니다. (rhyme 미쳤다…?) 리뷰를 읽기 전 참고하시면 좋을 것 같습니다!
이런 분들께 이 논문을 추천드립니다.
- Video 혹은 Retrieval에 관심이 있으신 분
- Knowledge Distillation, 특히 unlabeled dataset을 추가로 활용한 distillation에 흥미가 있으신 분
- 입력 데이터에 따라, 복수의 모델 중 특화된 모델을 선정하여 처리하는 방식에 흥미가 있으신 분
이 논문을 깊게 이해하려면 다음 지식이 필요합니다.
- L3-iMAC feature에 대한 이해 (Video Retrieval 리뷰)
- ViSiL에 대한 이해 (ViSiL 리뷰)
- TCA에 대한 이해 (TCA 리뷰)
- NetVLAD에 대한 이해 (윤서님의 NetVLAD 리뷰)
그럼, 리뷰 시작하겠습니다!
Video Retrieval은 일반적으로 다음의 세 단계로 수행됩니다.
- 가변적인 해상도, 길이(프레임 수)를 갖는 영상을 고정된 크기의 descriptor tensor로 변환하는 서술자 생성 과정
- 쿼리 영상과 DB 영상들의 유사도를 계산하는 과정
- 쿼리 영상과 유사도가 높은 순서대로 DB를 정렬하는 과정
Video Retrieval의 정확도는 결국 유사한 영상들의 유사도가 높게, 그렇지 않은 영상들의 유사도가 낮게 나오도록 서술자를 잘 만드는 것에 달렸다고 할 수 있는데요. 이때, 서술자를 영상에 포함된 각 프레임 단위로 만들어, frame-level로 descriptor들을 비교하는 frame-level 방법과, 영상 전체를 하나의 서술자로 만들어 video-level로 descriptor들을 비교하는 video-level 방법이 있습니다.
Frame-level 방법은 영상에 포함된 정보의 손실이 적고, 영상에 포함된 프레임들을 각각 비교하기 떄문에 상대적으로 정확도가 높지만, 비교할 두 영상 $q, p$의 프레임 수 $N, M$에 대하여 $N\times M$회의 비교를 수행해야 하기 때문에 연산량이 매우 방대하고, 그만큼 검색 시간이 오래 걸리게 됩니다. 또한, descriptor 자체의 크기도 프레임 수에 비례하여 증가하기 때문에, DB의 용량도 커지게 됩니다.
한편 video-level 방법은 영상 전체를 하나의 벡터로 만들어 비교하기 때문에, 유사도 계산을 1회만 수행하면 되어 매우 빠른 검색 속도를 가지며, 저장 공간도 적게 요구됩니다. 그러나 그만큼 손실되는 정보의 양이 많아 정확도가 떨어지게 됩니다.
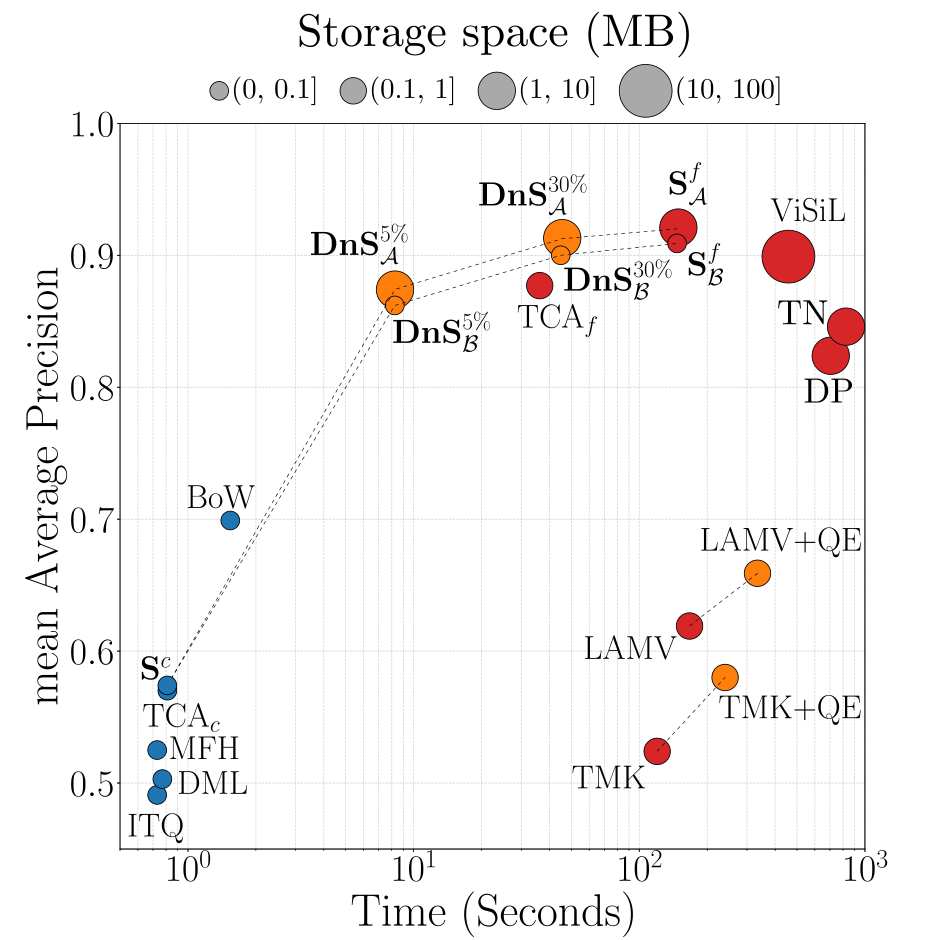
DnS, Distill and Select 모델은 frame-level 방법이자 기존의 SOTA 모델인 ViSiL이 너무 느리다는 단점을 극복하기 위하여 Knowledge Distillation과 Selector Network를 도입합니다. DnS의 contribution은 아래와 같습니다.
- Knowledge Distillation을 통해 SOTA 모델인 ViSiL을 teacher 삼아 다양한 student 모델 학습
- ViSiL과 유사한 frame-level student $S^f_\mathcal{A}$
- ViSiL과 유사하지만, feature 이진화를 적용하여 획기적으로 적은 descriptor 용량을 사용하는 $S^f_\mathcal{B}$
- ViSiL보다 정확도는 떨어지지만 매우 빠른 속도의 video-level student $S^c$
- 대규모 unlabeled dataset인 DnS-100K를 제안하고, 이를 Distillation하여 student들의 성능 향상
- 모델이 상황에 따라 신뢰도가 떨어지지만 빠르게 얻을 수 있는 $S^c$의 결과를 사용할 것인지, 시간을 들여 $S^f$의 결과를 사용할 것인지 결정하는 Selector Network $SN$을 도입하여 속도와 정확도 trade-off 개선
DnS: Distill and Select 구조
DnS 모델은 다음과 같은 3개의 모델로 구분됩니다.
- 매우 빠르지만 정확도가 낮은 video-level 모델 $S^c$
- 속도는 느리지만 정확도가 높은 frame-level 모델 $S^f$
- 신뢰도가 높은 frame-level 모델을 사용해야 할 영상들을 판단하는 Selector Netowrk $SN$
(저자들은 두 가지 $S^f$ 구조를 제안하지만, 둘 중 하나의 방식을 선정하여 DnS를 구성하게 됩니다.)
각 모델 $x$의 서술자 생성 과정은 $f^x$꼴로 나타납니다. 예를 들어, video-level 모델의 경우 $f^{S^c}$와 같습니다.
$SN$은 서술자 생성 시 입력된 영상의 self similarity scalar를 생성합니다.
모든 DB의 영상들은 다음과 같은 정보들로 인덱싱 됩니다.
- $S^c$가 생성한 global 1D tensor $f^{S^c} \in \mathbb{R}^D$
- $S^f$가 생성한 spatio-temporal 3D tensor $f^{S^f} \in \mathbb{R}^{N\times R\times D}$
- $SN$이 생성한 self similarity scalar $f^{SN}\in \mathbb{R}^1$
DnS의 검색 과정은 다음과 같이 진행됩니다.
- 쿼리 영상이 입력되면, 먼저 $S^c$가 인덱싱을 수행하고, DB 속 영상들과 유사도 $g^{S^c}$를 계산합니다.
- $SN$에 쿼리 영상과 비교할 DB 영상의 유사도 $g^{S^c}$와 각각의 self similarity $f^{SN}$을 입력하여, $S^f$를 사용해야 할지 판단하는 confidence score $g^{SN}$를 계산합니다.
- confidence score가 높은 상위 $n%$의 영상들은 연산 속도가 오래 걸리지만 상대적으로 더 정확한 $S^f$를 통해 유사도 $g^{S^f}$를 계산합니다.
- DB를 정렬 합니다.
$S^f$로 보내는 영상의 비율 $n$이 높아질 수록, 정확도는 상승하지만 검색 속도는 감소하게 됩니다.
Baseline Teacher 구조
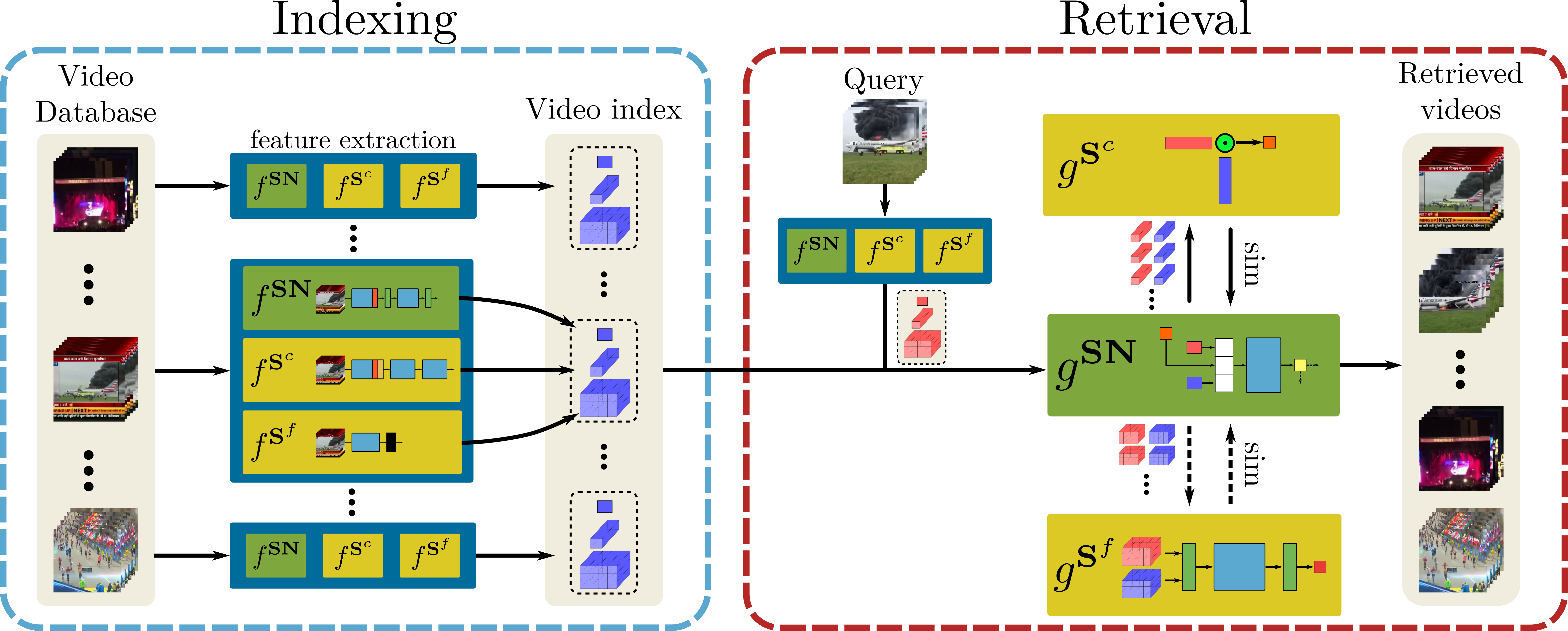
Teacher Model $T$로는 앞서 언급한 것처럼 ViSiL이 사용됩니다. ViSiL은 L3-iMAC을 추출한 후, 각 region vector에 대하여 학습가능한 unit vector를 이용한 $l^2$ 어텐션을 적용하여 중요한 영역과 그렇지 않은 영역에 가중치를 부여합니다. (위 그림에서 Modular Component로 나타난 부분) 영상의 유사도 계산에는 Tensor Dot과 Chamfer Similarity, Video Comparator Network 등을 사용하는데, DnS의 핵심 컨셉을 이해하는데 필수적인 내용은 아니라 궁굼하신 분들은 제 ViSiL 리뷰를 참고해주시기 바랍니다.
Fine-grained Attention Student ($S^f_\mathcal{A}$)
저자들은 두 개의 fine-grained (frame-level) student 구조를 제안하며, 두 구조 중 DnS를 구성할 때는 하나를 선택하게 됩니다. 이 모델은 ViSiL과 구조, 유사도 계산 방식이 거의 동일하지만, 어텐션의 구조가 일부 상이합니다.
ViSiL에서는 학습 가능한 unit vector $u$를 통해 region vector $r$에 어텐션을 적용한 반면, 이 모델은 활성화 함수가 $\tanh$인 선형 계층과 context vector $c$를 활용한 $h$ 어텐션을 진행합니다. 식은 아래와 같습니다.
$$h = \tanh(r\cdot W_a + b_a)\\
\alpha = \text{sig}(u\cdot h)\\
r’ = \alpha r$$
어텐션의 수행 과정만 약간 다를 뿐, 이 모델도 ViSiL과 같은 3차원 텐서 서술자를 생성하며, 유사도 계산 역시 완전히 동일한 방식으로 수행됩니다. 때문에 이 모델의 연산량은 ViSiL과 거의 동일하지만, 후에 실험 파트에서 다룰 DnS-100K 추가 unlabeled data로 distillation을 수행한 결과, teacher model인 ViSiL 보다 높은 정확도를 달성하였다고 합니다.
Fine-grained Binarization Student ($S^f_\mathcal{B}$)
이 모델 역시 frame-level 방법을 사용하며, ViSiL과 유사한 구조를 가지고 있습니다. 그러나 큰 차이점으로 어텐션 대신 이진화를 수행하게 됩니다. 이를 통해 descriptor의 크기가 크게 감소하여, 저장공간 측면에서 이점이 있었다고 합니다. 또한, 이 모델 역시도 Distillation을 통해 ViSiL에 가까운 달성할 수 있었다고 합니다. Video Retrieval의 실제 적용을 고려하면, 저장공간 효율성도 중요하기 때문에 제안한 것이 아닌가 싶습니다.
이진화는 region vector $r$에 학습 가능한 가중치 $W_\mathcal{B}\in \mathbb{R}^{D\times L}$를 곱한 후, 이진화 함수 $\text{sgn}()$를 적용하여 $[-1, 1]$ 중 하나의 값을 갖도록 하여 수행된다고 합니다. 그런데 이진화 함수는 불연속적이라 미분이 불가하기 때문에, 학습 과정에서는 이진화 함수에 근사하는 함수 $b()$를 사용하였다고 합니다. 학습 단계에서, 이진화 모듈의 기댓값은 아래와 같습니다.
$$ \mathbb{E}[\text{sgn}(x)] = \text{erf}(\frac{\mu}{\sqrt{2\sigma^2}})$$

$\text{erf}()$는 가우스 오차 함수라 하는 에러 함수로, 미분이 가능하며, -1과 1 사이의 값을 가집니다. $\mu$는 $x$가 유도되는 단변량 가우시안 분포의 평균이며, $\sigma^2$은 고정된 분산을 의미합니다. 어려워 보이지만 결국 위 erf 함수를 통해 이진화 함수를 대신했다는 얘기입니다. 학습 단계에 사용되는 이진화 근사 함수 $b()$는 아래와 같습니다.
$$ b(r) = \text{erf}(\frac{r\cdot W_\mathcal{B}}{\sqrt{2\sigma^2}})$$
유사도 계산 과정에는 ViSiL에서 사용하는 Chamfer Similarity를 사용하는데, 이때 유사도를 코사인 유사도로 계산하는 것이 아닌, 이진 벡터의 유사도를 계산하는데 사용되는 Hamming 유사도로 구합니다.
Hamming 유사도는 두 이진 벡터에서 모두 1인 값의 수에 벡터의 길이를 나눈 값 입니다.
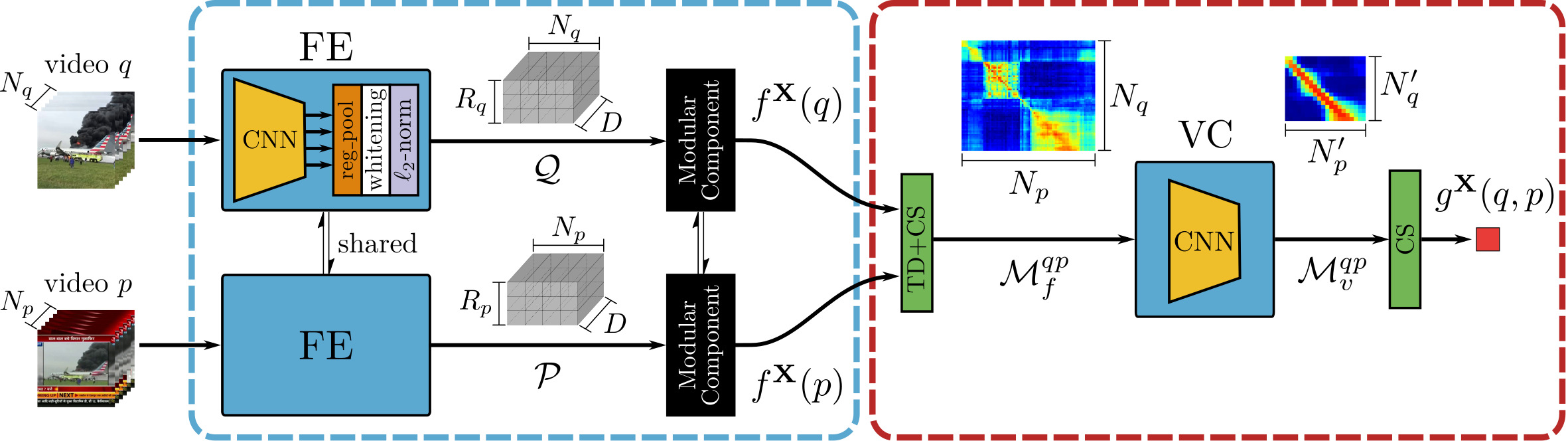
Coarse-grained Student ($S^c$)
이 모델은 video-level 방법으로 retrieval을 수행하여, teacher 모델이나 fine-grained student 대비 정확하지는 않지만 매우 빠른 속도를 가집니다. 정확하지 않다고는 하지만, 저자들은 이 모델에 TCA, NetVLAD와 같은 방법들을 결합하여 빠른 속도를 가지면서도 최대한 정확도를 확보하고자 했습니다.
$S^c$의 서술자 생성 $f^{S^c}$는 다음과 같이 수행됩니다.
- $S^f_\mathcal{A}$와 같은 방식으로 $h$-어텐션을 부여한 L3-iMAC feature 추출 ($N\times R\times D$ 크기)
- 공간 축으로 average pooilng을 수행하여 각 프레임에 대한 feature가 $D$차원의 벡터가 되도록 변환 ($N\times D$)
- 트랜스포머 인코더 구조를 이용해 frame-level feature들의 long-term dependency들을 병합 (TCA)
- NetVLAD 모듈을 통해 전체 frame-level feature를 하나의 벡터로 병합
이렇게 생성된 1D 벡터 형태의 video descriptor들은 닷 연산을 통해 쉽게 유사도를 구할 수 있습니다.
Selector Network ($SN$)
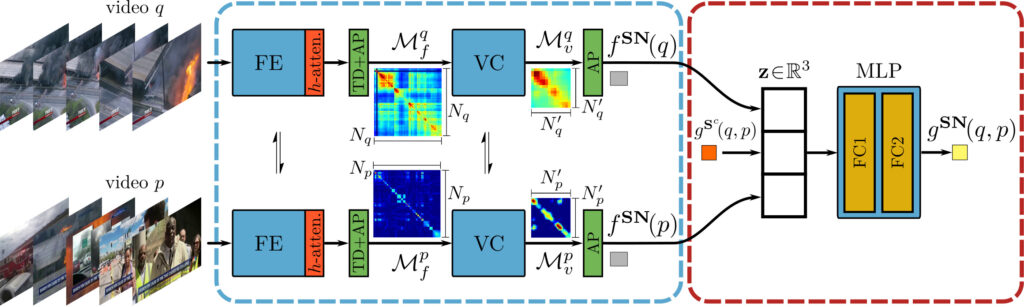
Selector Network는 입력된 영상에서 L3-iMAC을 추출하고, $h$-어텐션을 수행한 후, ViSiL의 유사도 계산과정과 유사한 방법을 통해 Self-Similarity를 구합니다. 이때, ViSiL에서는 Tensor Dot과 Chamfer-Similarity를 사용하였는데, Chamfer Similarity 대신 Average Pooling을 수행한다고 합니다.
이렇게 구해진 Self-Similarity는 한 영상에 포함된 각 프레임들이 얼마나 서로 유사한지를 나타냅니다. Self-Similarity가 높다는 것은 영상에 포함된 프레임들의 다양성이 낮다는 것이고, Self-Similarity가 낮다는 것은 프레임들의 다양성이 높다는 것이죠.
Selector Network는 만약, 다양성이 낮은 영상이라면 굳이 프레임들을 각각 비교하지 않고, Video-level descriptor만 비교하여도 충분할 것이라는 가정에서 설계되었습니다.
$SN$은 비교할 두 영상의 self-similarity와 $S^c$가 계산한 유사도 $g^{S^c}$를 입력받아, MLP 구조의 신경망을 통해 $S^f$를 사용할지를 판단합니다. 이 MLP는 학습 단계에서, coarse-grained student로 계산한 유사도 $S^c$와 fine-grained student로 계산한 유사도 $g^{S^f}$가 임계값 0.2 이상으로 큰 영상들을 분류하도록 이진 크로스 엔트로피로 학습됩니다.
학습 과정
DnS의 학습은 다음과 같은 순서로 진행됩니다.
- Teacher Model인 ViSiL을 VCDB와 같은 labeled dataset에서 학습
- Student Model들을 DnS-100K와 같은 대규모 unlabeled dataset을 이용해 Knowledge Distillation을 통해 학습
- Selector Network 학습
이때, student network의 학습 시에는 teacher model로 DnS-100K의 모든 영상 쌍들의 유사도를 다 계산해 사용하기에는 비용이 많이 발생하므로, 한 양성 쌍에 대하여 다른 앵커에 대응되는 영상 50개와 아무 쿼리와도 관련이 없는 방해자 영상 50개를 선정하여, 이들의 유사도를 계산해 놓고 사용하였다고 합니다.
Experiments
Retrieval Performance of Individual Networks
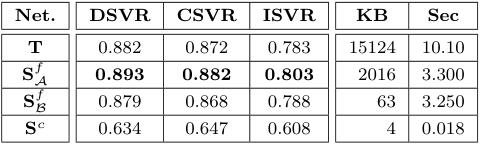
각 신경망을 단독으로 사용하였을 때, Teacher model ViSiL $T$와 유사한 구조를 가지면서 DnS-100K에서 distillation된 $S^f_\mathcal{A}$가 가장 좋은 성능을 보였으며, 속도도 ViSiL보다 빨랐습니다.
이진화를 사용하는 $S^f_\mathcal{B}$는 훨씬 적은 저장공간을 사용함에도 $T$와 거의 유사한 성능을 보이며, 심지어 ISVR에서는 $T$보다 높은 성능을 보였다고 합니다.
$S^c$는 역시 가장 부족한 성능을 보였지만, 압도적으로 적은 저장공간을 사용하고 의도한 대로 검색 속도도 매우 빠른 모습입니다.
Distillation vs Supervision
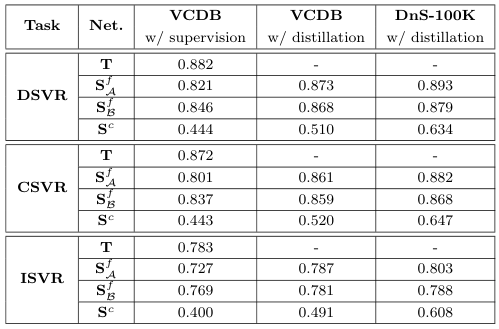
저자들은 각 모델을 teacher와 동일하게 VCDB에서 지도학습하는 경우와, VCDB 혹은 DnS-100K에서 distillation한 경우의 성능을 비교하였는데요. 전반적으로 Distillation을 사용하는 것이 성능을 향상했으며, 특히 VCDB의 near-duplicate보다 더 다양하고 많은 데이터를 포함한 DnS-100K에서 distillation을 수행하는 것이 성능을 크게 향상시켰다고 합니다.
Impact of dataset size
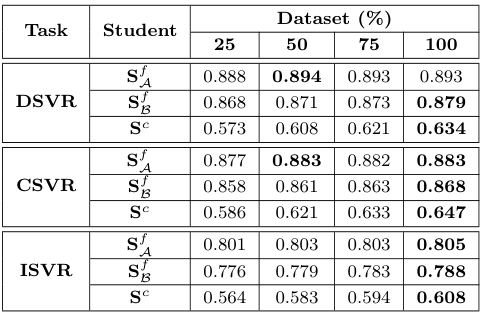
저자들은 Knowledge Distillation 과정에서 사용되는 DnS-100K 데이터셋의 비율을 조절하며, 데이터의 양과 성능의 관계를 분석하였다. $S^f_\mathcal{B}$와 $S^c$의 경우, 학습 데이터의 양에 따른 성능의 차이가 크게 나타난 반면, $S^f_\mathcal{A}$는 학습 데이터의 양이 변화하여도 결과가 비교적 안정적이었는데, 이는 입력 feature를 변형하지 않고 사용하는 $S^f_\mathcal{A}$가 다른 모델들에 비해 더 강건하게 학습한 것으로 생각된다고 합니다.
Student performance with different teachers
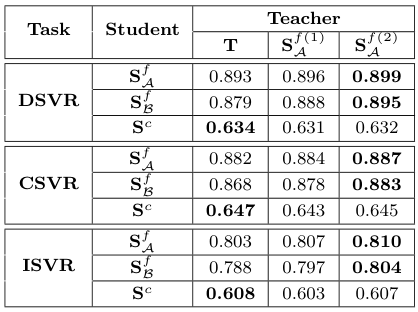
앞서, Student 모델들이 Teacher 모델인 ViSiL에 비해 한층 성능이 높은 모습을 보였는데, 이렇게 $T$로 학습한 모델 $S^{f(1)}_\mathcal{A}$과, 이 모델로 다시 학습한 모델 $S^{f(2)}_\mathcal{A}$를 사용해 Distillation을 수행해 보았습니다.
신기하게도, fine-grained student들의 성능은 이에 따라 꽤 크게 상승하였으나 $S^c$는 성능이 상승하지 않았다.
Student performance with different settings
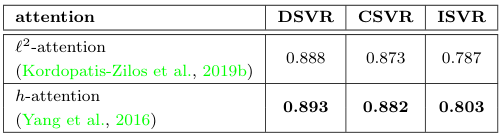
$S^f_\mathcal{A}$에 적용하는 어텐션을 기존 ViSiL이 사용하던 $l^2$ 어텐션과 h 어텐션 사이에서 비교해 보았습니다. h 어텐션의 성능이 전체적으로 더 높았기에, 논문에서는 h 어텐션을 사용하였다고 합니다. ViSiL에서는 어텐션에 대해 꽤 자세히 설명하였던 저자들인데, 이번에는 깊은 고찰이 없어 조금 아쉬웠습니다.
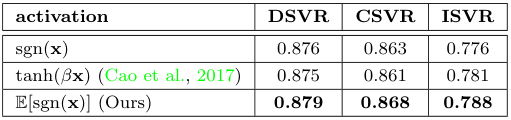
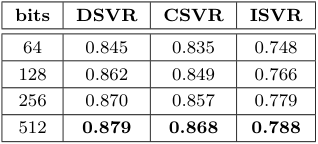
$S^f_\mathcal{B}$의 이진화 계층에 사용하는 활성화 함수의 비교를 진행하였습니다. 그 결과, 저자들이 사용한 함수가 가장 좋은 성능을 보였으며, 어찌보면 당연히도 이진화에 사용되는 비트 수를 비교하였을 때, 비트가 많을수록 성능이 향상됐다고 합니다.
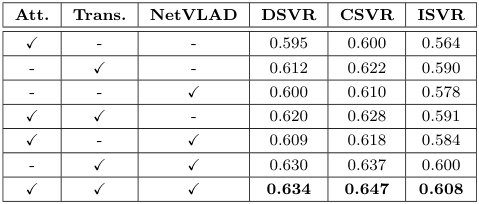
Coarse-grained Student $S^c$의 각 모듈에 대하여 Ablation Study를 실시한 결과, 모든 모듈이 존재하는 것이 가장 높은 성능을 보였습니다. 위 표에 아무 모듈도 없는 경우도 있었으면 좋았을 것 같은데, 없는 이유는 의문이네요….
Selector Network Performance
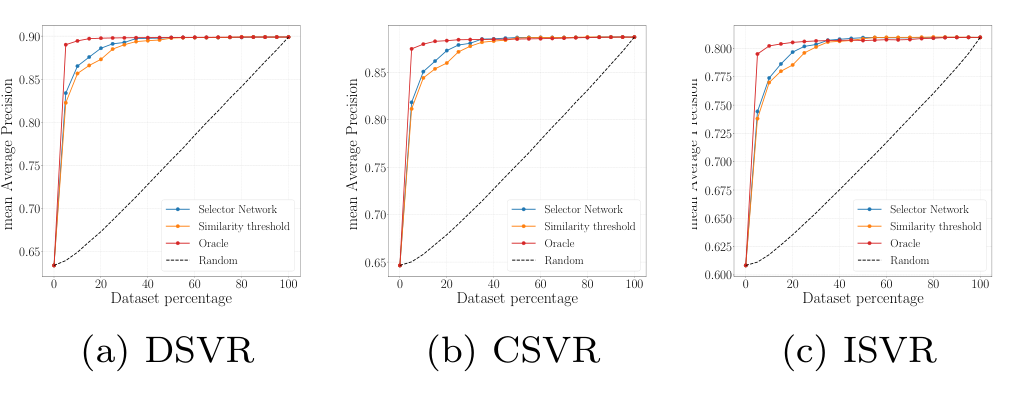
정확도가 낮은 $S^c$를 사용할지, $S^f$를 사용할지 판단하는 기준에 따른 성능을 분석하였습니다. $S^c$와 $S^f$가 생성하는 유사도를 알고 있는 경우를 의미하는 당연히도 Oracle이 가장 높은 정확도를 내었고, selector network를 사용하는 방법이 뒤를 이었네요. 단순히 유사도 thresholding을 진행하는 경우, 가장 안 좋은 성능이 나타났습니다.
Impact of threshold on the selector performance
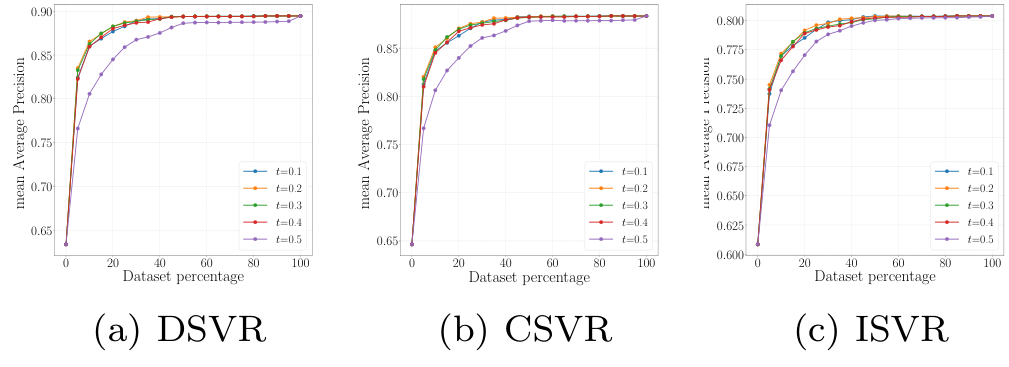
Selector Network 학습에 사용되는 threshold 값 설정에 따른 성능 비교를 수행하였습니다. t=0.2로 설정한 경우가 가장 성능이 좋았으나, 0.1~0.4 사이의 성능이 사실 대부분이 비슷하다가 t가 0.4를 넘자 성능이 급격히 하락하였습니다.
Comparison with SOTA
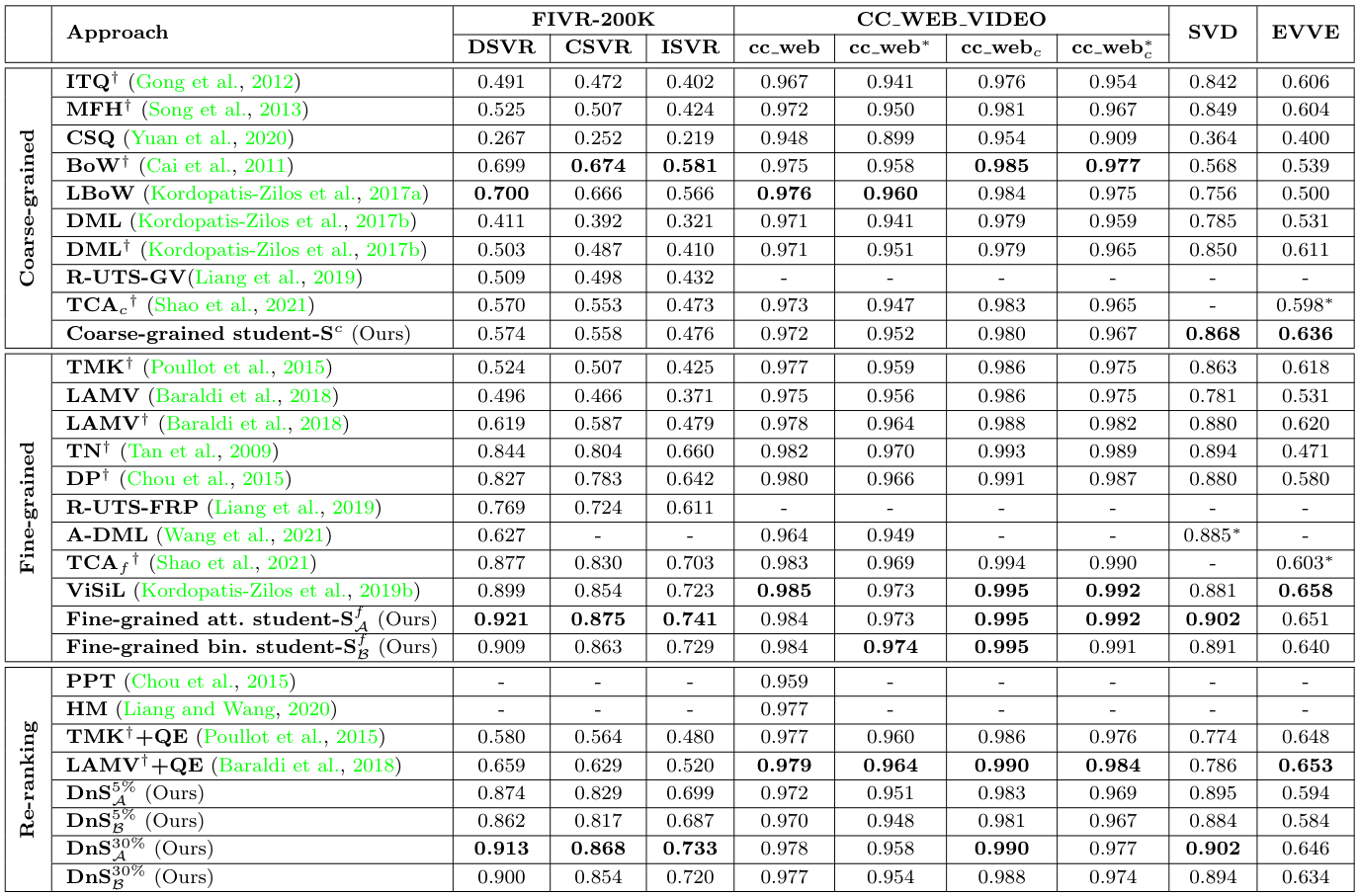
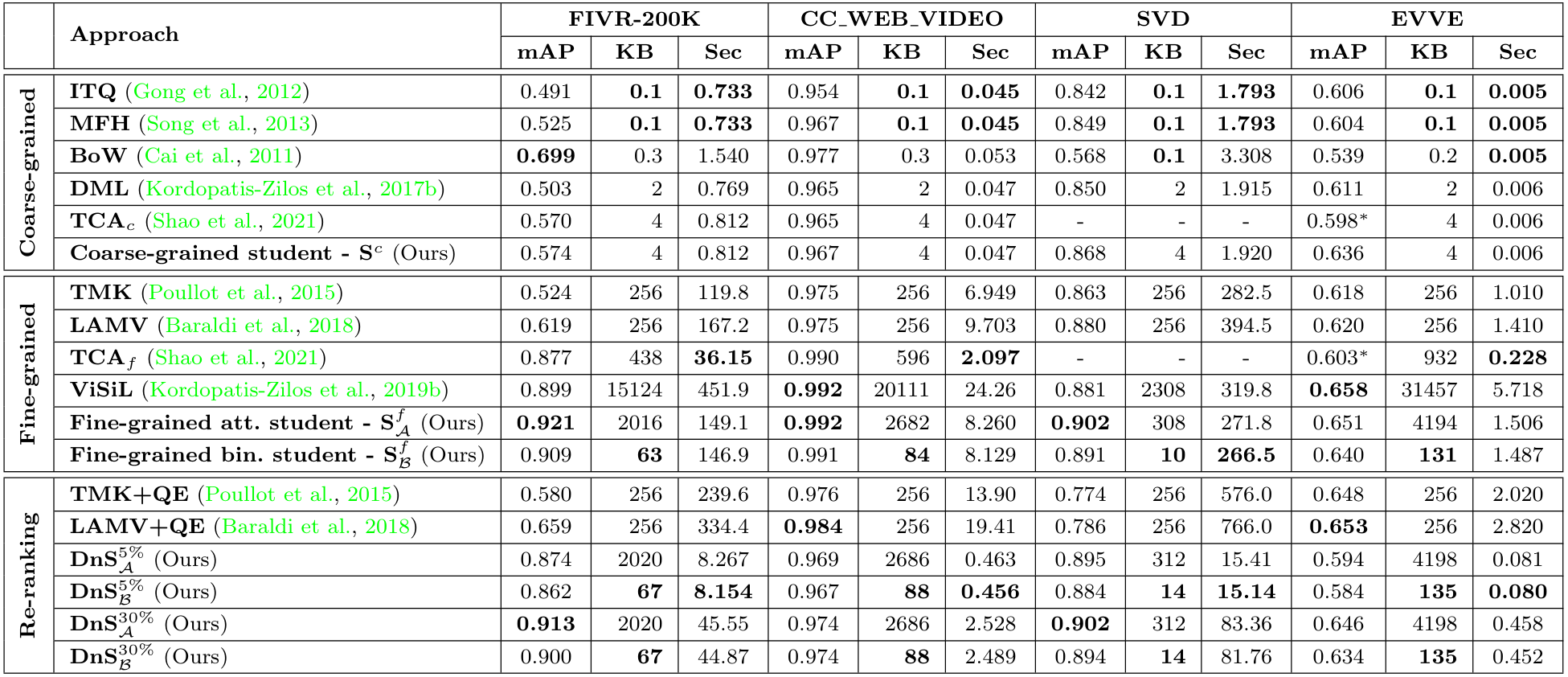
저자들은 여러 SOTA 모델들과 FIVR-200K, CC_WEB_VIDEO, SVD, EVVE 데이터셋에서 비교를 수행하였습니다. 지표는 mAP, 영상 서술자의 용량, 쿼리 당 검색 시간을 비교하였습니다.
모든 DnS 모델의 Teacher로는 $S^{f(2)}_\mathcal{A}$이 사용되었으며, 입력 데이터 중 5%, 혹은 30%의 데이터를 fine-grained student에게 보내 재분석하도록 하였네요.
비교 결과, $S^f_\mathcal{A}$가 FIVR-200K, CC_WEB의 cleaned 버전, SVD에서 Video Retrieval 모델 중 가장 높은 mAP로 SOTA를 달성하였습니다만, 이미 SOTA인 ViSiL 구조에 DnS-100K라는 추가 데이터셋을 사용한 결과이기에 어찌보면 당연한 것 같습니다.
DnS 모델들은 이 논문에서 제안한 $S^f$를 제외한 모델들 중 가장 높은 mAP를 달성하였으며, 검색 속도는 frame-level 방법 중에는 가장 낮은 수준을 달성하였습니다. 그러나 여전히 video-level 방법에 비해서는 매우 많은 시간이 소모되는 모습을 보여 실용적이라고 하기에는 조금 아쉬운 모습을 보이는 것 같습니다.
이 논문에서는 기존 Video Retrieval의 검색 속도 – 정확도 tradeoff를 해결하기 위해 다음과 같은 방법을 활용하였습니다.
- Knowledge Distillation을 이용해, 정확하면서 속도는 teacher 모델보다 빠른 student model 학습 (Distill)
- 속도가 빠르지만 상대적으로 부정확한 coarse-grained student로 먼저 예측하고, 필요에 따라 느리지만 정확한 fine-grained student로 예측하도록 하는 selector network 학습 (Select)
Student의 경우에도, 단순히 fine-grained / coarse-grained만 설계한 것이 아니라, 저장공간을 아낄 수 있는 이진화 모델을 설계하거나, fine-grained model의 어텐션을 개선하고, coarse-grained의 경우 TCA와 NetVLAD를 적용하는 등 다양한 개선을 시도하였던 점이 인상 깊었습니다.
이를 통해 일반적으로 쿼리 당 수백초의 검색 시간이 요구되는 frame-level 방법론들보다는 빠른 8초대, 45초대의 검색속도를 가질 수 있었으나, 여전히 1초 미만의 검색 속도를 갖는 video-level 검색 방법들에 비해서는 많이 느린 상황이라 조금 아쉽습니다.
그러나 distillation을 통해 unlabeled data를 학습에 활용하여 모델의 정확도가 상당히 향상되어 이 점도 주목할 만하다고 생각하며, video-level, frame-level 모두 검색 속도가 더욱 발전되었을 때 유사한 방식의 re-ranking 모델이 사용된다면 실용적이리라 생각됩니다.
저널 논문은 처음 읽어봐서 긴 논문에 꽤 놀랐는데, 읽는 데는 오래 걸려도 설명이 상세하여 나쁘지만은 않았던 것 같습니다.
요즘 열대야에 주말인데도 푹 쉬기가 쉽지 않던데, 다들 건강히 좋은 주말 보내시기 바랍니다.
감사합니다. ?
안녕하세요. 백지오 연구원님 리뷰 잘 읽었습니다.
왜 DnS에서는 ViSiL의 구조를 동일하게 가져가면서도, Attention 모듈만큼은 수정했을까요? 이에 대한 이유가 나와있나요? 그리고 수식 보다가 생각난건데, 이미 ViSiL에서도 동일하게 적용… 되어있는 것 같은데 왜 차이라고 하는걸까요? (pytorch 버전 코드 가서 보시면 됩니다.)
그리고 coarse-grained ablation에서 Attention 까지 없으면 학습 안한 성능이라서 굳이 가져오지 않은 것 같네요.
안녕하세요. 댓글 감사합니다.
제가 찾아본 바로는 논문에서는, 단순히 attention student가 teacher 모델인 visil보다 더 복잡한 attention 구조를 가져감으로써, 추가 데이터에서 학습되었을 때 visil의 성능을 뛰어넘을 수 있어 사용했다고만 되어있었습니다. ablation study에서 이에 대한 실험을 진행하기는 하였지만, 딱히 깊은 고찰은 없이 그냥 성능이 더 올랐다고만 되어있네요…
두 방식의 차이는 다음과 같습니다.
ViSiL의 l2 attention
– 각 D차원 region vector r에 학습 가능한 unit vector u를 곱하여 가중치 생성
– 두 유닛 벡터의 곱인 가중치는 [-1, 1] 범위를 가지므로 2로 나누고 0.5를 더하여 범위를 [0, 1]로 조정
DnS의 h-attention
– r을 선형 계층에 입력하고 tanh를 적용하여 D차원 weight h 생성
– h에 학습 가능한 vector u를 곱하고, sigmoid 함수를 적용하여 범위를 [0, 1]로 조정
l2 어텐션은 u를 초기화 후 l2 normalization을 수행하여 unit vector로 만들어 주는 반면, h 어텐션은 이 과정을 수행하지 않습니다. 또한, r과 u를 곱하기 전 r을 선형 계층에 입력하여 한번 변환하여, 한층 복잡한 구조를 갖는다고 볼 수 있겠습니다.
coarse-grained는 생각해보니 그렇군요… 부끄럽습니다.
댓글 감사합니다!