Before Review
새로운 분야에 대해서 리뷰를 하게 되었습니다. Video Event Extraction 이라는 방법입니다.
우선 저는 Video Scene Segmentation 이라는 분야에 대해서 본격적으로 연구를 하려고 합니다. Scene Segmentation 연구를 위해 가장 해결해보고 싶은 문제점은 semantic information understanding 입니다.

Scene Segmentation에서 제일 중요한 것은 장면에 대한 구분이 단순한 visual clue의 변화 뿐만 아니라 semantic information에 따라서 결정되기 때문입니다. 기존의 연구들은 단순히 Transformer 구조를 사용하여 이러한 semantic information 문제를 해결하고 있었습니다.
저는 Transformer 구조가 semantic information 문제를 해결해줄 수 있는 optimal 이 아니라고 생각합니다. 이번에 준비한 논문이 바로 그러한 고민에 대해서 하나의 방향을 제시해줄 수 있는 논문이라 생각되어 이번에 리뷰 하게 되었습니다.
리뷰 시작하도록 하겠습니다.
Introduction
The ability to comprehend a video requires a structured understanding of events, including what is happening, the objects involved, as well as their semantic roles.
Introduction 첫 부분에 나오는 문장인데, 비디오를 이해하는 작업은 어떤 일이 발생했고, 어떤 객체들이 존재하고 그들의 의미론적 역할은 무엇인지 파악하는 것이라 볼 수 있습니다. 저도 몰랐는데 Situation Recognition이라는 작업이 있다고 합니다. 이미지에서 발생하는 중요한 사건이 무엇인지 파악하고 각각의 사건과 관련된 객체들을 예측하는 작업이라고 하네요.
단순히 이미지 사진 하나 보고 강아지인지 고양이인지 분류하는 작업보다 훨씬 더 고차원의 작업이라 볼 수 있습니다.
21년도부터는 Image Situation Recognition이 아니라 Video Situation Recognition으로 확장되었다고 합니다. 사건의 semantic structure를 이미지 레벨이 아닌 비디오 레벨에서 이해해보자는 것이죠.

위의 상황을 보면 황소가 남성을 들이받고 있습니다. 정확히 사건과 관련된 객체(황소, 남성)이 존재하며 이때 남성이 도망가며, 황소가 쫓고 있고 그 둘이 도망가는 방향은 왼쪽에서 오른쪽 이네요. 간단하게 서술했지만 Video Scene Recognition은 특히 temporal dynamics와 rich visual feature 때문에 파악하기 더 어려운 실정 입니다.
사건이라는 것에 대한 정의는 다양하게 할 수 있지만 본 논문에서는 비디오 장면을 구성하는 argument의 visual state change로 정의하고 있습니다.
그래도 argument의 visual state change라 함은 방금처럼 남성이 왼쪽에서 오른쪽으로 황소를 피해 달리고 있는 그 상황에 대한 change라 이해하면 될 것 같습니다. 이렇게 비디오를 구성하는 장면들에서 argument들의 visual state를 잘 tracking하여 변화를 모델링하는 것이 저자가 제안하는 Video Event Extraction 작업 입니다.

우선 기본적으로 argument들은 저렇게 bounding box를 통해 tracking 됩니다. Object Tracking 자체는 저자들이 제안하는 것이 아니라 VidVRD라는 object tracking sota 모델을 사용하였다고 하네요.
저자는 이러한 argument들의 visual state를 모델링하기 위해 아래와 같은 4가지 모듈을 제안합니다.
- Object State Embedding(OSE) : 하나의 프레임 상태를 정의하기 위해서 저자는 bounding box들의 픽셀 값 변화와 박스 좌표 이동을 고려합니다. 위의 그림에서 남성은 box 안에서 달리고 있다가 넘어지는 상태의 픽셀 값으로 변화하고 있습니다. 또한 박스의 위치가 왼쪽에서 오른쪽으로 이동하고 있네요. 이러한 상태를 모델링할 수 있도록 OSE를 제안합니다.
- Object Motion-aware Embedding (OME) : 하나의 프레임 상태에 대해서는 위에서 정의한 OSE를 통해서 모델링이 됩니다. 이제 연속된 프레임 속에서 Object의 상태 변화를 모델링할 수 있는 OME를 제안합니다. 뒤에서 살펴보겠지만 굉장히 간단합니다. 바로 OSE를 시간 축에 대해서 평균 내주어 처리하고 있습니다.
- Multi-Object Interaction Embedding : 단순히 하나의 Object가 아니라 프레임 내에 존재하는 모든 Object들이 만들어내는 Interaction을 모델링할 수 있는 모듈입니다. 사실 OSE와 동일합니다. 입력을 하나의 Object에 대한 박스가 아니라 Multi-Object가 들어있는 Box를 바탕으로 처리를 하게 되는 것이죠.
- Argument Interaction Encoder : 마지막으로 event를 이해하는 과정에서 상대적으로 더 연관이 있고 더 중요한 object들이 있을 것 입니다. 이렇게 object들을 contextualizing하여 집중해야 하는 부분을 알려주는 모듈이 있습니다.
제안하는 방법론 자체는 위에서 정의한 4가지 모듈 입니다. 제안하는 방법론에 들어가기 앞서 낯선 Task이다 보니 Problem Formulation에 대해서 알아보고 가도록 하겠습니다.
Methodology
Problem Formulation
주어진 비디오 클립이 있을 때 \left\{ f_{i}\right\}^{F}_{i=1} 를 입력으로 넣었을 때 우리는 event의 집합을 출력(\left\{ f_{i}\right\}^{F}_{i=1} \rightarrow \{ e\})으로 내놓는 모델을 만들려고 합니다. 이때 event e는 아래와 같이 정의 됩니다.
- e=\left\{ v,\left< r^{0},a^{0}\right> ,\left< r^{1},a^{1}\right> ,\ldots \right\}
여기서 v, r, a가 등장합니다.
동사(verb) v 사전에 정의된 verb set \nu에서 sampling 됩니다. 그리고 하나의 동사 v마다 사전에 정의된 역할 집합 R(v)가 존재합니다.
예를 들어 KNOCK이라는 동사에 대해서는 아래와 같이 역할 집합 R(v)가 정의 됩니다.
- R(KNOCK)=\left\{ AGENT,TARGET,SCENE,\ldots \right\}
즉 여기서 r^{k} \in R(v)는 동사 v의 k번째 역할을 의미합니다. 그리고 a^{k}는 해당하는 argument의 속성, 단위를 의미합니다.
예를 들어 KNOCK이라는 동사에 대해서는 아래와 같이 main argument 들이 정의가 됩니다.
- AGENT \rightarrow \left< AGENT\left(ARG_{0}\right),gray bull\right>
- TARGET \rightarrow \left< TARGET\left(ARG_{1}\right),midget in gray hoodie\right>
- PLACE \rightarrow \left<PLACE\left(ARG_{scene}\right),ground\right>
그래서 우리 모델은 e=\left\{ v,\left< r^{0},a^{0}\right> ,\left< r^{1},a^{1}\right> ,\ldots \right\} 이러한 출력을 반환 할 수 있도록 방법론이 설계가 되어야 합니다.
Object Visual Tracking
운동학에 따르면 object의 motion은 transitional 과 rotational movement로 분해할 수 있다고 합니다. 이러한 관점에 따라 저자도 object의 motion을 bounding box의 이동과 box안의 pixel 변화로 정의하고 있습니다.

이를 위해서는 Object를 Detection하고 Tracking하며 이를 기본적으로 embedding 시켜줄 백본이 필요합니다.
우선 object tracklet은 VidVRD라는 SoTA 방법론을 사용한다고 합니다. 비디오 원본 데이터를 입력으로 넣으면 object tracklet 들의 리스트를 \left\{ {}o_{j}\right\}^{O}_{j=0} 반환합니다.
하나의 object tracklet은 [t^{-}_{j},t^{+}_{j}]이라는 구간 동안 bounding box들을 반환 합니다.
- b_{ji}=\left<\left( \left(b^{0}_{ji},b^{1}_{ji}\right),\left(b^{2}_{ji},b^{3}_{ji}\right)\right)\right>
위의 그림 처럼 남성이 4개의 프레임에서 bounding box로 tracking 되고 있는 모습을 볼 수 있습니다.
저자는 3D convolutional neural network의 우수한 성능을 이용하기 위해 SlowFast 라는 백본을 활용하여 high-level의 grid feature를 사용한다고 합니다. 간단하게 설명하면 low frame rate를 이용하는 Slow pathway를 사용하여 spatial semantics를 추출하고 high frame rate를 이용하는 Fast pathway를 사용하여 temporal 축에 대한 motion 정보를 추출합니다.
SlowFast encoder는 두가지 입력을 처리합니다. 바로, f^{slow}\in \mathbb R^{F_{1}\times W\times H\times 3} 그리고 f^{fast}\in \mathbb R^{F_{2}\times W\times H\times 3} 입니다. 여기서 F_{1}는 slowpath를 위한 sampling rate 이기 때문에 F_{1}<F_{2}이 성립합니다. 즉, slowpath에서는 sampling 간격을 넓게 주어서 프레임을 더 적게 샘플링하는 것이죠.
- \left[ g^{slow},g^{fast}\right] =\mathbf{SlowFast}\left( f^{slow},f^{fast}\right)
이때, g^{slow}\in \mathbb{R}^{F_{1}\times W^{\prime }\times H^{\prime }\times d_{1}} 그리고 g^{fast}\in \mathbb{R}^{F_{2}\times W^{\prime }\times H^{\prime }\times d_{2}}로 정의 됩니다. 이 Grid feature g^{slow}와 g^{fast}로 이제 다양한 Object 들의 상호작용을 모델링하게 됩니다.
Proposed Method
Single Frame : Object State Embedding
우선 단일 프레임에서의 상황부터 고려해보도록 하겠습니다.
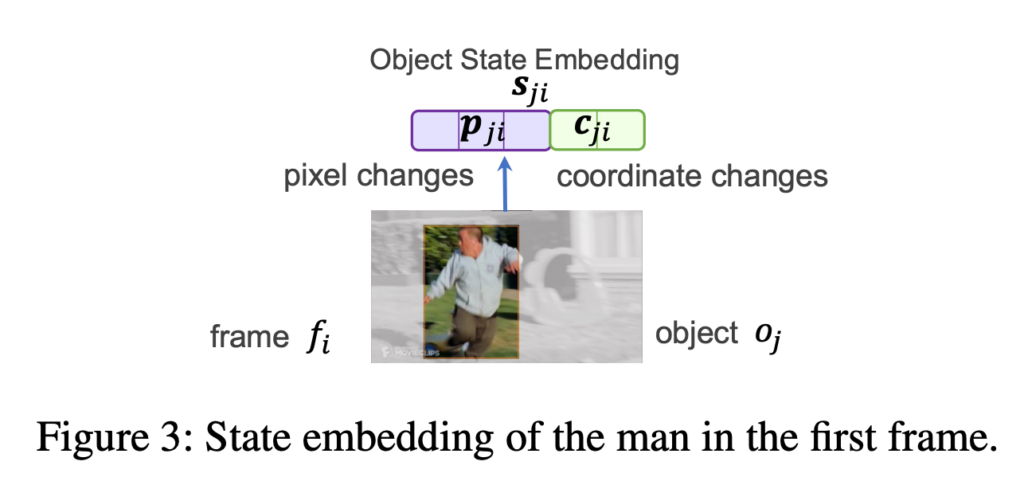
위의 그림 처럼 우리는 탐지된 object의 상태를 visual tracking을 위해 bounding box내의 pixel change를 처리하고 displacement tracking을 위해 bounding box의 coordinate change를 처리합니다.
우선 b_{ji}=\left< \left( \left( b^{0}_{ji},b^{1}_{ji}\right),\left( b^{2}_{ji},b^{3}_{ji}\right)\right)\right> 는 raw video에서 처리된 박스 좌표 입니다. 이를 feature level로 처리하기 위해서는 좌표들을 feature space로 projection 시켜줄 필요가 있습니다.
말이 어려워보이지만 그냥 normalize(H,W\rightarrow H^{\prime },W^{\prime }) 시켜준다고 보시면 됩니다. 처음 입력 해상도와 feature의 해상도가 다르니 상대적인 값을 사용하여 grid feature에서 object에 해당되는 부분만 sampling하기 위함입니다.
- b_{ji}=\left<\left(\left( b^{0}_{ji},b^{1}_{ji}\right),\left(b^{2}_{ji},b^{3}_{ji}\right)\right)\right>\rightarrow \hat{b_{ji}}=\left<\left(\left(\hat{b^{0}_{ji}},\hat{b^{1}_{ji}} \right),\left(\hat{b^{2}_{ji}},\hat{b^{3}_{ji}}\right)\right)\right>
그 다음에 grid feature에서 box에 해당되는 영역에 대해서 average pooling을 적용하여 object o_{j}의 visual state(pixel changes)를 정의합니다.
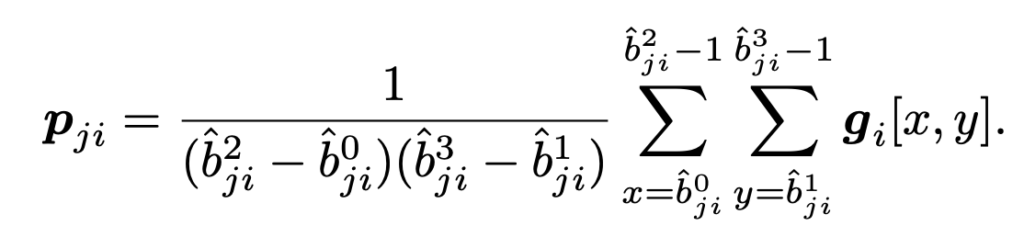
grid feature가 단일 프레임 기준으로는 g_{i}^{slow} \in \mathbb R^{H'\times W' \times d_{1}} 이고 g_{i}^{fast} \in \mathbb R^{H'\times W' \times d_{2}} 입니다.
그렇다면 box region에 대해서 average pooling을 한 pooled feature p_{i}는
- p^{slow}_{ij}\in \mathbb R^{d_{1}} 혹은 p^{fast}_{ij}\in \mathbb R^{d_{2}} 입니다.
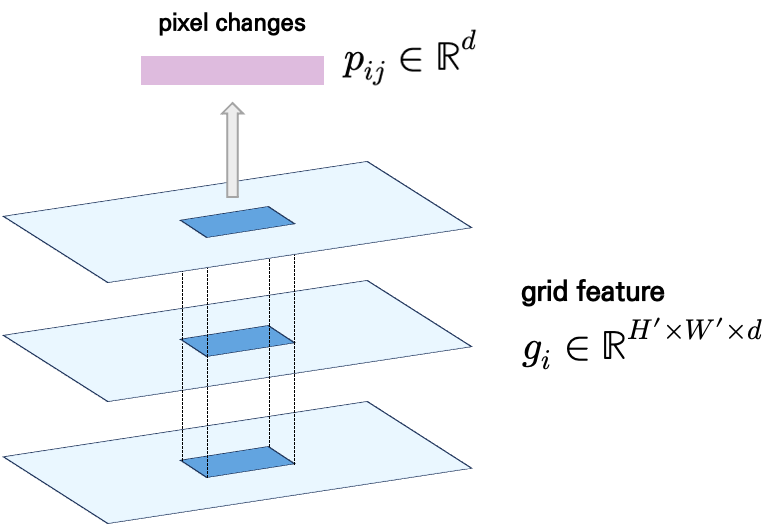
평균을 취하는 굉장히 간단한 방법으로 pixel change를 modeling 하고 있습니다.
다음으로는 coordinate change를 어떻게 처리 하는지 살펴보도록 하겠습니다. 사실 이 부분도 굉장히 간단합니다.
- c_{ij}=\mathbf{W}_{c} \hat{b_{ji}} , c_{ji} \in \mathbb R^{d_{c}} , \mathbf W_{c} \in \mathbb R^{d_{c} \times 4}
학습 가능한 linear layer를 사용하여 박스 좌표를 positional embedding으로 projection 시켜 버립니다.
최종적으로 Object State Embedding (OSE)는 s_{ji} \in \mathbb R^{d+d_{c}}로 정의 됩니다. 즉, pixel change와 coordinate change에 대한 embedding을 concat 하여 사용하겠다는 것이죠.
- s_{ji} = [p_{ji}, c_{ji}]
Multiple Frames : Object Motion-aware Embedding
단일 프레임 기준으로 임의의 객체에 대한 상태를 모델링 하였다면 이제는 다중 프레임에 걸쳐있는 객체의 변화를 모델링 해야 합니다.
- s_{ji} = [p_{ji}, c_{ji}] : 단일 프레임 기준으로 o_{ij}에 대한 상태 입니다.
이 s_{ji}를 이제 다중 프레임에 대해서 aggregate 해주는 것이 Object Motion-aware Embedding의 목적 입니다.
- m_{j}=\mathbf{StateAgg}\left( \left\{ s_{ji}\right\}^{F}_{i=0} \right)
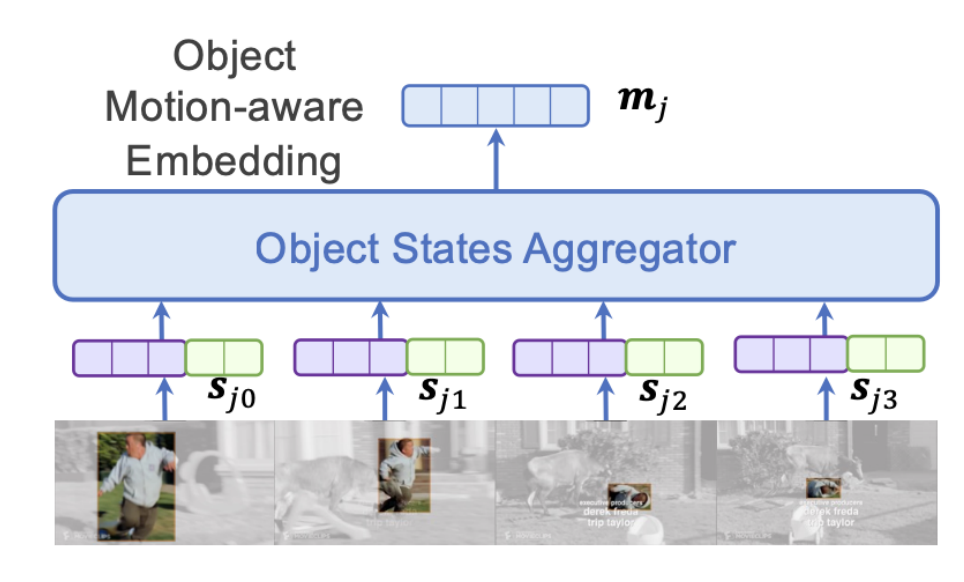
위의 그림 처럼 결국 남성이라는 object를 tracking하면서 state를 매 프레임마다 정의하고 이를 여러 프레임에 걸쳐 다시 모아주겠다는 의미입니다. 저기 Object States Aggregator는 Average Pooling을 사용하거나 LSTM을 사용하였다고 합니다.
- m_{j}^{slow} \in \mathbb R^{d_{1}+d_{c}} , m_{j}^{fast} \in \mathbb R^{d_{2}+d_{c}}
Multiple Objects : Object Interaction Embedding
이전까지는 하나의 객체에 대해서 single state 그리고 motion에 대한 embedding을 처리했습니다. 하지만 event를 궁극적으로 이해하기 위해서는 다중 객체들의 상호작용 역시 처리해야 합니다.
이를 위해 아래의 그림에서는 남성과 황소에 대해서 같이 tracking을 해주고 있습니다.

어려울 것 없이 검출된 Object들을 모아주면 되겠네요. Union Bounding Box를 찾아주는 것 부터 시작합니다.
- \hat{B_{i}} =\bigcup_{o_{j}\in O_{i}} \hat{b_{ji}}
여기서 O_{i}는 frame f_{i}에서 검출된 객체의 집합 입니다. 이렇게 Union Bounding Box를 얻었다면 마찬가지로 동일하게 pixel change와 coordinate change를 모델링할 수 있습니다.
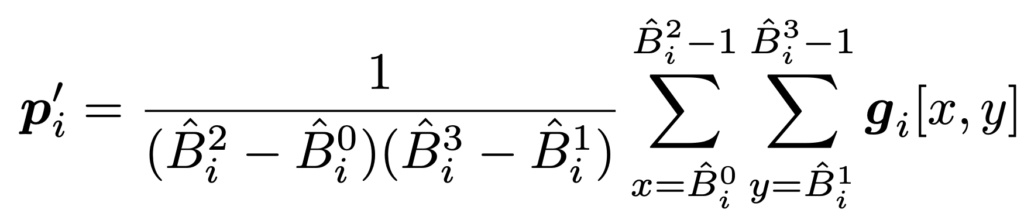
동일하게 grid feature 내에서 average pooling을 하여 pixel change를 처리하고 c^{\prime }_{i}=\mathbf{W}_{c} \hat{B_{i}} 처럼 박스의 좌표를 변환하여 positional embedding을 반환 합니다.
- \mathbf{i}_{i} =[p^{\prime }_{i},c^{\prime }_{i}]\in \mathbb{R}^{d+d_{c}}
동일하게 concat 해주어 Multiple Object들의 Interaction에 대한 Embedding을 처리해줍니다.
또한 Single Object들이 다중 프레임에서의 Motion을 처리한 것 처럼 Multiple Objects 역시 다중 프레임에서의 Motion을 처리하기 위해 Object Interaction Embedding을 실시합니다.
- \mathbf{i} =\mathbf{InterAgg} \left( \left\{ \mathbf{i}_{i} \right\}^{F}_{i=0}\right)
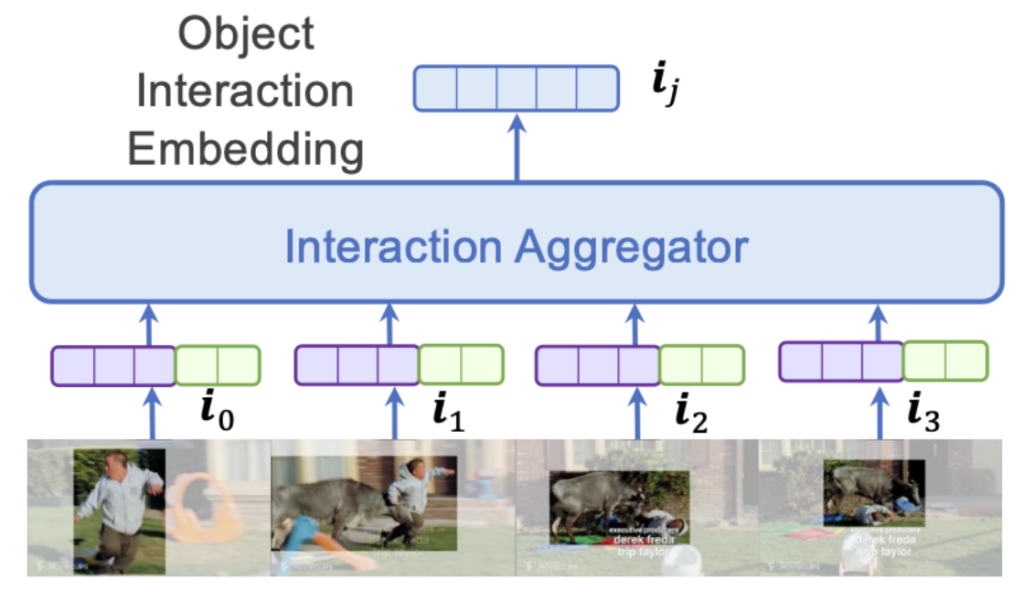
결국 구조는 단일 객체 상황과 동일하고 Bounding Box를 단일 객체로 가져갈 것인지 다중 객체로 가져갈 지에 대한 차이만 존재합니다.
Argument Interaction Encoder
비디오의 사건(event)를 이해하는 관점에서 모든 객체의 상태가 중요하지는 않습니다. 사건과 밀접하게 관련이 있는 객체가 있을 것이고 따라서 우리의 모델이 거기에 좀 더 집중할 수 있도록 처리해주면 더욱 좋겠네요.
따라서 저자는 Transformer의 Self-Attention을 활용합니다.

- e=\mathbf{Trans} \left(\left[\bar{\mathbf{g} } ; \left\{ m_{j}\right\}^{O}_{j=0} ; \mathbf{i}\right]\right)
여기서 \bar{\mathbf{g} } \in \mathbb R^{d} 는 모든 프레임에 대해서 average pooling을 거친 feature 입니다. 비디오 전체의 semantic을 다루기 위해 표현된 rough한 representation이라 보시면 됩니다.
O는 하이퍼 파라미터로 object detector로 검출된 object들을 confidence score에 따라 최대 몇개까지 사용할 것인지 나타내는 값 입니다.
이렇게 됐을 때 Transformer의 입력으로 들어가는 feature의 dimension은 어떻게 될까요?
- \bar{\mathbf{g} } \in \mathbb{R}^{d} , m_{j}\in \mathbb{R}^{d+d_{c}} , \mathbf{i} \in \mathbb{R}^{d+d_{c}}
이때 우리는 slowpath와 fastpath를 동시에 고려하기 때문에 d=d_{1} 혹은 d=d_{2} 입니다. 따라서
- e\in \mathbb{R}^{3d_{1}+3d_{2}+2d_{c}}
최종적으로 추가적인 linear layer를 사용하여 e\in \mathbb{R}^{3d_{1}+3d_{2}+2d_{c}} \rightarrow e\in \mathbb{R}^{d_{1}+d_{2}} 로 처리해주고 있습니다.
slowpath에 대해서 embedding이 하나 나오고 fastpath에 대해서 embedding이 하나 나오고 있네요. 자 이렇게 Argument Interaction Encoder 까지 거쳐서 나온 embedding은 결국 object들의 state 변화와 그들간의 interaction을 고려하여 만들어진 embedding 입니다.
이 embedding을 활용하여 이제 다양한 task를 수행하게 되는 것이죠.
Experiments
DownStream Task
Verb Classification
Verb Classification이라고 해서 motion-related video understanding 분야에서 가장 기초적인 task라고 합니다.
저자가 제안하는 event-aware visual embedding e는 argument 들의 상태 변화를 capture 하기에 적합한 feature 이기 때문에 최종적인 embedding e를 사용하여 Verb Classification 수행하는 것이죠.
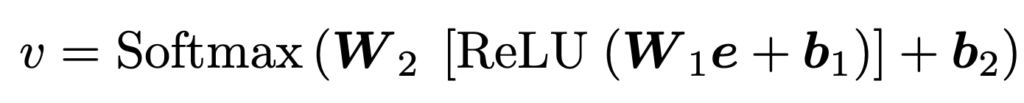
두개의 Linear Layer와 ReLU로 구성된 MLP Layer를 사용하였다고 합니다.
- \mathbf{W_{1}} :\mathbb{R}^{d_{1}+d_{2}} \rightarrow \mathbb{R}^{\frac{1}{2} (d_{1}+d_{2})} , \mathbf{W}_{2} :\mathbb{R}^{\frac{1}{2} (d_{1}+d_{2})} \rightarrow \mathbb{R}^{\left| \nu \right| }
\left| \nu \right|는 사전에 정의된 동사의 갯수라고 합니다.
Semantic Role Prediction
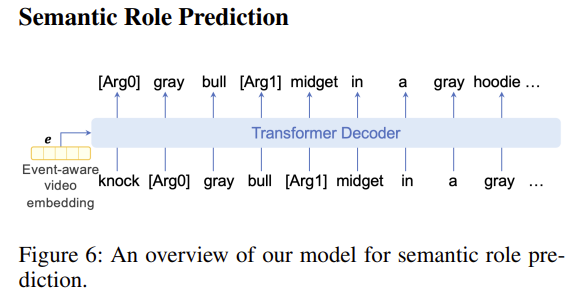
사건의 semantic structure를 추출하는 과정에서 가장 어려운 부분은 관련된 객체를 인식하는 것과 그들의 semantic role을 이해하는 것이라고 합니다.
사실 저도 처음 보는 task라 정확히 어떻게 수행되는지 감이 잘 안 잡히네요. 일단 입력이 순차적(sequence-to-sequence)으로 들어간다고 합니다.
r^{k}나 a^{k}가 무엇인지 예측하는 작업인 것 같습니다.
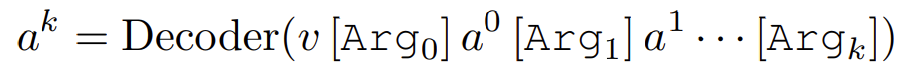
semantic role prediction task에 대해서는 cross entropy loss를 통해서 학습이 진행됩니다. Ground-truth sequence와 generated sequence간의 비교를 통해 loss를 계산하는 것 같습니다.
Dataset
데이터는 처음 보는 Task다 보니 처음 보니 Dataset을 사용하고 있습니다. 데이터 셋 자체는 [2021 CVPR] Visual Semantic Role Labeling for Video Understanding 여기서 제안하고 있네요.

위의 그림 처럼 비디오에 verb와 argument 구조를 annotation 시킨 VidSitu라는 데이터 셋을 활용하고 있습니다. 하나의 비디오 클립은 대략 2초 정도로 구성이 됩니다. 학습 데이터 셋에는 하나의 verb를 예측하도록 하고 평가 데이터 셋에서는 10개의 verb를 예측한다고 합니다. 데이터 전체에는 2154개의 verb가 존재하고 하나의 verb는 적어도 3가지의 semantic role를 포함한다고 합니다.
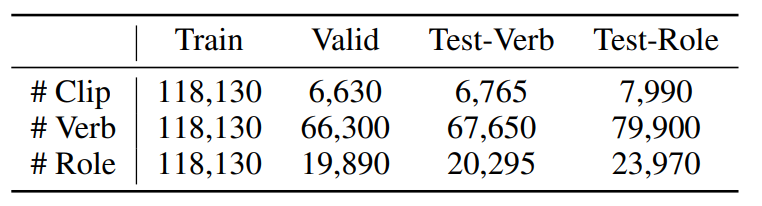
위의 테이블은 VidSitu라는 데이터 셋이 가지는 통계라고 합니다. 뭐 봐도 잘 모르겠네요. 참고로 평가 데이터 셋에 대한 annotation은 공개되어 있지 않고 리더보드에 제출하는 것으로 성능을 확인할 수 있다고 합니다.
Quantitative Analysis
우선 정량적 지표 먼저 살펴보도록 하겠습니다.
- OSE-pixel은 OSE에서 pixel change만을 고려한 것 입니다.
- OSE-pixel/disp는 OSE에서 pixel change와 displacement를 고려한 것 입니다.
- OME는 Object-Motion Embedding 입니다. 본 실험에서는 항상 고려했는데 가장 중요한 요소이기 때문에 제거할 수 없었다고 합니다. 이렇게 강조할 정도면 빼고 실험 했을 때 성능도 리포팅 해줬으면 더 좋았을 것 같네요.
- OIE는 Object Interaction Embedding 입니다.
Verb Classification
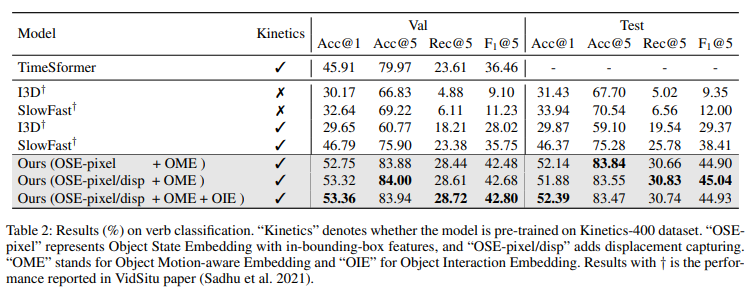
I3D, SlowFast에 대한 성능은 저자가 내놓은 결과가 아니라[2021 CVPR] Visual Semantic Role Labeling for Video Understanding 에서 제안된 베이스라인 성능이라고 합니다.
다만 TimeSformer의 경우는 원래 베이스라인 성능이 아니기 때문에 저자가 직접 실험한 성능을 리포팅 하였고 논문에 따르면 본인들이 할 수 있는 최선을 다해서 가장 최적의 파라미터를 가지고 실험을 진행했다고 합니다.
결과적으로 저자가 제안하는 방식이 Verb Classification Task에서 꽤 높은 폭으로 기존의 베이스라인들을 상회하는 성능을 보여주고 있습니다.
Argument들의 change를 명시적으로 modeling하는 최초의 방법이면서 성능 에서도 우수함을 보여주고 있습니다.
Semantic Role Prediction
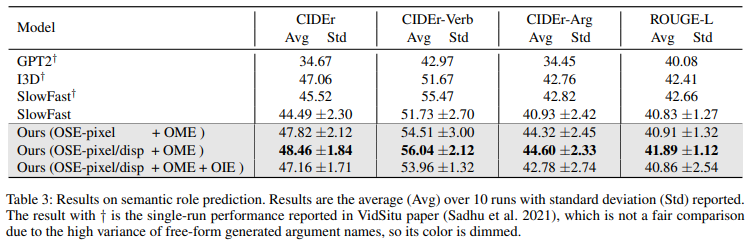
Semantic Role Prediction의 경우는 저도 자세히는 모르지만 Task 자체가 Generation이다 보니 랜덤성(?)이 있는 것 같습니다. 저자는 10번 돌려서 평균을 낸 성능을 리포팅 하고 있습니다. 더불어 편차도 같이 리포팅을 하고 있습니다.
우선 정량적 성능 기준으로도 차이가 그렇게 크지는 않지만 기존의 베이스라인 대비 더 좋은 성능을 보여주고 있습니다.
또한 SlowFast를 저자가 직접 10번 돌렸을 때 발생하는 편차 대비 저자가 제안하는 방법의 편차가 더 작은 것을 보여주면서 robust 함을 주장하고 있습니다.
Pixel Changes vs Displacements
위에 테이블에서 OSE-pixel 와 OSE-pixel/disp 을 비교하면서 보도록 하겠습니다.
- OSE-pixel은 OSE에서 pixel change만을 고려한 것 입니다.
- OSE-pixel/disp는 OSE에서 pixel change와 displacement를 고려한 것 입니다.
OSE-pixel/disp의 경우는 displacement까지 고려한 것이기 때문에 객체의 상태를 특정화 하는 과정에서 중요합니다. 즉, semantic role prediction에서 더 중요하다는 것이죠.
이러한 것이 바로 semantic role prediction 실험에서 나타나고 있네요. 테이블에서 OSE-pixel/disp의 성능이 OSE-pixel 보다 조금 더 높은 것을 볼 수 있습니다. Semantic Role Prediction에서는 객체 각각의 상태를 모델링 하는 것이 중요하기 때문에 displacement change를 고려하는 것이 더욱 효과적이다 보여주고 있고 반대로 displacement change를 모델링 하는 것이 객체 각각의 상태를 파악하는 데 중요한 역할을 하는 것으로 볼 수 있습니다.
Effect of Object Interaction Embedding
OIE는 아무래도 영상의 전반적인 정보를 모델링하는 것으로 fine grained level인 semantic role prediction 보다는 verb classification에서 더 좋은 모습을 보여주고 있습니다.
Effect of Object Number
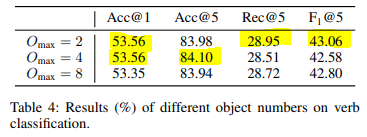
Object의 갯수에 따른 ablation 입니다. 이 파라미터에 민감하지 않고 개수에는 별 상관없이 비슷한 성능을 보여주고 있습니다. 저자는 Object 개수가 많아져도 결국에는 Object Interaction Module에서 중요한 Object들을 걸러내기 때문에 별 차이가 없다고 하네요.
State Aggregator Operation in OME
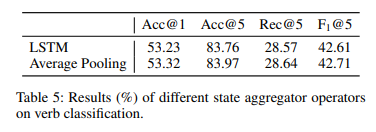
여기서는 Aggregator를 LSTM혹은 Average로 했을 때의 차이를 보여주고 있습니다. 평균으로 가져가는 것이 미세하지만 더 좋은 성능을 보여주고 있습니다.
어차피 평균 연산은 아무런 파라미터를 필요로 하지 않기 때문에 굳이 LSTM을 사용할 이유는 없어 보입니다.
Qualitative Analysis
마지막으로 정성적 결과 입니다.

첫번째 예시 입니다. 사람 두 명이 나와서 대화하고 있는 것 같습니다.
하지만 픽셀 값들의 변화가 많이 일어나고 있지 않습니다.
그럼에도 저자들이 제안하는 방법은 서로 바라보고(LOOK) 얘기하고 (SPEAK, TALK)와 같은 event를 잘 예측하고 있습니다.
하지만 SoTA 모델은 픽셀 변화가 없다 보니, STOP과 같은 잘못된 예측을 보여주고 있습니다.

두번째 예시 입니다. 사람이 나오고 있고 사람의 입 주변 픽셀 값이 변화하고 있습니다.
단순히 입 주면 픽셀 값이 변화하고 있는 사실만 집중하면 TALK나 CHEW와 같은 event와 일반적으로는 관련이 있습니다. TALK는 맞는 예측이지만 SoTA 모델은 CHEW라는 잘못된 예측을 하고 있습니다. CHEW라는 event가 등장하기 위해서는 단순히 입 움직임에만 집중하는 것이 아니라 무엇을 먹고 있는 지에 대해서도 집중을 해야 하지만 기존의 방법들은 서로 다른 객체들의 Interaction에 대해서 다루지 않았기 때문에 이러한 상황에서 잘못된 예측을 하고 있습니다.
하지만 저자의 방법은 입을 움직이고 있지만 먹고 있는 객체가 없기 때문에 CHEW가 아니라 YELL이라는 예측을 잘 수행하고 있습니다.
이를 통해 Object-level의 fine-grained interaction을 모델링 하는 것에 대한 중요함을 나타내고 있습니다.

세번째 예시는 사람들이 싸우고 있는 장면입니다.
본 예시에서 Our Model은 tracking을 통해 pixel change를 잘 파악하여 사람의 팔 동작 변화가 감정적으로 변화하는 것을 알아차리고 이를 싸움(FIGHT,HIT)으로 올바르게 인식하였습니다.
기존의 SoTA 모델은 Pixel Change를 명시적으로 모델링 하지 않았기 때문에 이러한 상황에서도 잘못된 예측을 하고 있습니다.
Conclusions and Future Work
근래 읽은 논문 중에서 가장 맘에 들었던 논문인 것 같네요. 저의 논문 연구인 Scene Segmentation 과의 접점도 많이 보이고 해서 앞으로의 연구에 많은 참조가 될 것 같습니다.
코드도 깔끔하게 공개되어 있어 더욱 맘에 드는 것 같습니다. GPU도 V100 4장이면 가능하다고 하니 원복 실험을 돌려봐야겠네요.
저자는 본 논문의 Future Work로 제안하는 event-aware embedding이 비단 verb classification, semantic role prediction 뿐만 아니라 다양한 down stream taks로 확장 시키는 것이라 얘기하네요. 또한 이러한 argument tracking을 사전 학습 단계에 Self-Supervised 방식으로 넣는 것도 고려를 해볼 수 있겠네요.
간만에 재밌게 읽은 논문이라 리뷰가 조금 길어졌습니다. 리뷰 읽어주셔서 감사합니다.
안녕하세요. 리뷰 잘 보았습니다.
방법론에 들어가는 개념들도 많고 분야도 생소하다보니 간단히 보고서는 리뷰를 이해하기 힘들군요 허허.
질문을 몇개 좀 드리자면 먼저 첫번째 질문으로, bounding box의 좌표를 처리하는 부분에서 raw video의 좌표값을 feature space로 투영시킨다는 의미가 raw video의 해상도 기준 좌표를 feature space의 좌표 기준으로 바꿔준다는 것인가요?
그러면 여기서 feature space는 해상도가 어느 정도 수준이 되는건가요?
그리고 grid feature에서 box에 해당하는 영역에 대해 average pooling을 적용하여 visual state를 정의한다고 해주셨는데, 지금 단일 프레임 기준으로 박스를 구했으니 grid feature에서도 특정 프레임에 대해서만 이 pooling 작업이 진행되는 것으로 이해하면 되나요?
즉 소개해주신 Object State Embedding이 먼저 F1 길이를 가지는 grid feature의 각 프레임 축에 대해 개별적으로 모두 수행이 되었다면 그 이후에 Object Motion-aware Embedding이 처리되어 object들 간에 모션 정보를 쭉 처리하는 것이구요?
그렇다면 object state aggregator로는 average pooling이나 LSTM을 사용해주셨다고 했는데 왜 Transformer를 사용하지는 않는 건가요?
사실 가장 큰 궁금점은 리뷰의 시작부터 나온 얘기지만 왜 transforemr가 semantic information을 잘 고려할 수가 없다고 생각하는지 잘 모르겠습니다. 결국 해당 논문의 저자도 Argument Ieration Encoder를 구현할 때는 transformer를 활용하는 것으로 보아 Transformer가 대상들간에 관계를 고려하는 측면에서는 매우 잘 동작한다고 볼 수 있는데, 결국 transformer의 입력으로 semantic information이 잘 담겨있는 embedding 정보만을 잘 전달해주기만 한다면 transformer가 이를 토대로 그들간에 중요도 및 관계를 잘 구축해서 더 좋은 정보로 변환해줄 수 있지 않나요?
연산량 측면에서 transformer보다 pooling이 더 단순하여 좋다 라는 주장이면 쉽게 이해할 수는 있으나 transformer가 semantic information을 잘 고려하지 못해서 결과적으로 pooling이나 lstm을 사용했다는 것이 이 논문의 흐름이라면 무언가 보충 설명이 필요할 것 같아보여요.
가령 기존 방법론들이 그냥 비디오에서 추출한 특징을 transformer에게 전달한 뒤에 semantic information 알아서 구”해줘”. 이런 방향이 문제였기에 저자가 4가지 모델링을 통하여 semantic information을 잘 정의하고자 한다. 라는 내용이라면(맞는지는 모르겠지만 이게 맞나요?), 결국 그렇게 정의하고 구현하는 과정에서 transformer를 사용하는 것이 더 좋을수도 있을 것 같다는 것이 제 생각인데(예를들어 object state aggregator과 interaction aggregator를 구현할 때 트랜스포머의 활용) 이에 대해서 택근님의 의견이 궁금하네요.
p.s. 리뷰 내 그림1 설명하실 때 황소가 남성을 들이받고 있습니다 라고 해주셨는데, 아무리봐도 흑우?회색소?인데 황소라고 하는 것은 마치 흑인을 보고 백인이라고 하는 것이 아닌지…? 이에 대하여 해명 부탁드립니다(ㅋㅋ)
첫번째 질문으로, bounding box의 좌표를 처리하는 부분에서 raw video의 좌표값을 feature space로 투영시킨다는 의미가 raw video의 해상도 기준 좌표를 feature space의 좌표 기준으로 바꿔준다는 것인가요?
=> 정규화된 박스 좌표를 다시 높은 차원의 latent vector로 임베딩 시키는 것 입니다. 단순한 4차원 벡터보다 더 풍부한 표현을 가질 수 있도록 포텐셜을 부여하는 것이죠.
그리고 grid feature에서 box에 해당하는 영역에 대해 average pooling을 적용하여 visual state를 정의한다고 해주셨는데, 지금 단일 프레임 기준으로 박스를 구했으니 grid feature에서도 특정 프레임에 대해서만 이 pooling 작업이 진행되는 것으로 이해하면 되나요?
= 검출된 객체가 없다면 진행되지 않습니다. 고로 맞게 이해하셨습니다.
즉 소개해주신 Object State Embedding이 먼저 F1 길이를 가지는 grid feature의 각 프레임 축에 대해 개별적으로 모두 수행이 되었다면 그 이후에 Object Motion-aware Embedding이 처리되어 object들 간에 모션 정보를 쭉 처리하는 것이구요?
=> 네 맞습니다.
그렇다면 object state aggregator로는 average pooling이나 LSTM을 사용해주셨다고 했는데 왜 Transformer를 사용하지는 않는 건가요?
=> 그건 모르겠네요..
결국 transformer의 입력으로 semantic information이 잘 담겨있는 embedding 정보만을 잘 전달해주기만 한다면 transformer가 이를 토대로 그들간에 중요도 및 관계를 잘 구축해서 더 좋은 정보로 변환해줄 수 있지 않나요?
=> 세미나에서 답변 드린 것 처럼 Transformer의 포텐셜을 부정하는 것이 아니라 기존의 연구들이 막연하게 Transformer를 가져다 사용하는 상황을 비판한 것 입니다. 본 논문 처럼 명시적으로 object를 detect하고 그들간의 관계를 modeling 해줄 수 있다면 Transformer를 통해 context modeling이 더욱 좋아질 수 있다고 생각하지만 이렇게 추가적인 장치 없이 modeling 자체를 Transformer에게만 맡긴다면 좋은 성능을 기대하기 어렵기 때문에 위와 같이 생각했습니다.
결국 그렇게 정의하고 구현하는 과정에서 transformer를 사용하는 것이 더 좋을수도 있을 것 같다는 것이 제 생각인데(예를들어 object state aggregator과 interaction aggregator를 구현할 때 트랜스포머의 활용) 이에 대해서 택근님의 의견이 궁금하네요.
=> 저도 그렇게 생각합니다. Transformer를 최대로 활용할 수 있는 정보의 투입이 중요한 것이죠.
p.s. 리뷰 내 그림1 설명하실 때 황소가 남성을 들이받고 있습니다 라고 해주셨는데, 아무리봐도 흑우?회색소?인데 황소라고 하는 것은 마치 흑인을 보고 백인이라고 하는 것이 아닌지…? 이에 대하여 해명 부탁드립니다(ㅋㅋ)
=> 인종차별적인 발언은 삼가해주시길 바랍니다.
안녕하세요. 임근택 연구원님.
좋은 리뷰 감사합니다. 새롭고 흥미로운 연구 분야라 어려웠지만 재밌게 읽었습니다.
리뷰를 읽고 소소한 궁굼증이 생겨 질문드립니다.
Tracklet이란 것이 무엇인지 약간 헷갈리는데, 단순히 tacking하고 있는 객체의 object detection 예측의 집합인 것인가요? (즉, Bounding box 오프셋과 객체 예측으로만 구성된 것인지)
감사합니다.
tracklet은 저도 처음 보는 개념이라 자세하게는 모르지만 output 자체는 detection box의 집합이라 보시면 됩니다. 이를 반환해주는 매개체 정도로 이해했습니다 저는
안녕하세요 임근택 연구원님. 리뷰 잘 읽었습니다.
Pixel change는 어떤 변화량일까요? 일단 특정 바운딩 박스 내에서의 변화량을 계산하는 것 까지는 이해했고, 정보를 활용하는 것 까지 이해했습니다. 이때, 픽셀 내부의 변화량을 이용하는 것인지, 이 변화량을 embedding해서 tracking 정보와 결합해서 temporal한 정보까지 같이 활용하는 목적인가요?
리뷰에서 이 Pixel change를 안봐서 기존 모델들이 잘 못봤다 라고 하고 있는데, 이 pixel change가 이미 이미지에서 pooling을 수행하면서 feature를 뽑기 때문에 고려하고 있는 부분 아닌가요? 이 부분에서는 이 방법론은 명시적으로 특정 물체내에서 pooling을 수행하기 때문에 다른 점으로 보는 건가요?
Pixel change는 어떤 변화량일까요?
=> 동일한 객체에 대해서 box에 대한 state embedding을 정의하고 이것이 시간에 따라 어떻게 변화하는지를 생각하시면 될 것 같습니다.
이 부분에서는 이 방법론은 명시적으로 특정 물체내에서 pooling을 수행하기 때문에 다른 점으로 보는 건가요?
=> 네 기존 방법론 대비 해당 연구는 명시적으로 detection 후 relation을 정의하고 있기 때문에 다르다고 볼 수 있습니다.
안녕하세요 좋은 리뷰 감사합니다.
위와 같은 방법론으로 학습된 feature를 사전학습하기 위해선 결국 장면에 대한 세부 상황을 담고 있는 동사와 역할집합 R(v)가 필요할 것 같은데, 해당 task를 self supervised나 weakly로 잔행한 연구도 존재하나요?
그리고 transformer encoder를 태워 몇 개의 물체를 볼것인지 결정하는 하이퍼파라미터 O에 따라 성능도 많이 변할 것으로 생각되는데, 실제 볓으로 사용되었는지와 왜 그런 값을 선택했는지에 대한 내용이 있는지도 궁금합니다.
1. 아뇨 아직 없습니다. Task 자체가 21년도에 처음 제안된터라 아직까지 그런 연구는 없네요. 저자 역시 이러한 방향이 향후 future work라고 보고 있습니다.
2. 해당 실험에 대해서는 위에 내용이 나와있습니다. 결론적으로는 Object 개수의 차이에 따른 성능 변화는 크지 않습니다.