이번 X-Review 또한 올해 CVPR에 게재된 Weakly-Supervised Temporal Action Localization (WTAL) 논문 중 하나로, 제목은 <Distilling Vision-Language Pre-training to Collaborate with Weakly-Supervised Temporal Action Localization>입니다.
제목을 통해 WTAL을 수행할 때 거대 Vision-Language 사전학습 모델의 지식을 가져와 사용하는 방법론인듯한 느낌을 받을 수 있는데요, 자세한 내용을 하나씩 파헤쳐보겠습니다.
WTAL은 비디오 일부 구간에서 발생하는 action의 temporal annotation 없이 video-level label만을 가지고 학습하여 action의 클래스와 발생 구간을 찾아내는 task에 해당합니다.
1. Introduction
비디오 분야의 WTAL이라는 downstream task는 학습 시 backbone 모델은 고정한 채로 feature를 추출해 이후 자신들만의 방법론을 적용하여 수행합니다. Backbone 모델은 I3D 네트워크이고 이는 Trimmed Action Classification(TAC) task로 사전학습되어 있는 상태입니다.
TAC는 비디오에서 실제 action 구간만 잘 편집해놓은 Kinetics400이라는 대용량 trimmed video 데이터셋을 활용해 해당 비디오가 어떤 action을 나타내고 있는지 분류하는 것인데요, 이러한 task로 사전학습한 backbone 네트워크로부터 추출하는 untrimmed video의 feature를 바탕으로 classification도 아닌 localization을 수행하는 것은 예전부터 짚어오던 큰 문제에 해당합니다.
또한 이렇게 sub-optimal한 feature를 바탕으로 WTAL을 수행할 때, temporal annotation마저 사용할 수 없기 때문에 기존 방법론들은 “Localization by Classification” 방식을 선택합니다. 이는 하나의 비디오가 저희가 갖고 있는 유일한 label인 video-level label로 분류되는 데에 큰 영향을 미친 snippet들을 action 구간이라 보고 localization을 수행하는 방식인데요, 당연히 사람이 판단하는 action의 구간과 모델이 비디오를 분류하기 위해 살펴보는 snippet의 범위는 다르기 때문에 최적의 구간 예측을 만들어낼 수 없게 됩니다.
저자는 위와 같이 Classification을 바탕으로 task를 수행하는 방법론들을 Classification-Based Pre-training(CBP)라고 부릅니다. CBP는 제가 앞서 말한 분류를 기반으로 사전학습 되었거나 task를 수행하기 때문에 sub-optimal하다고 말씀드렸는데요, 저자는 일반적으로 CBP 방법론들이 구별력있는 snippet만을 action으로 칭하기 때문에 “Action Incompleteness” 문제가 존재한다고 이야기합니다.
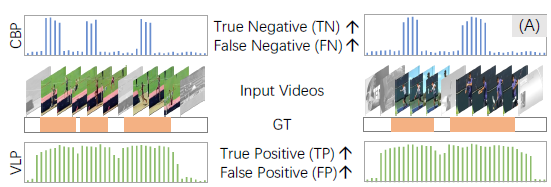
그림 1-(A)의 CBP 예측값을 보시면, 입력 비디오에 대해 온전한 주황색 GT구간이 아닌 앞뒤로 부족한 예측 결과를 보이는 것을 알 수 있습니다. 이는 분류로 사전학습한 feature를 또 다시 분류하는 과정에서 결정적인 snippet들에만 집중하기 때문에 발생하는 현상에 해당합니다. 이에 따라 전체적으로 negative 예측값이 많아지기 때문에 TN과 FN의 비율 또한 높을 것이라고 생각할 수 있습니다.
사실 기존 방법론들도 모델의 Action completeness의 부족함과 관련하여 보통 더 넓은 범위를 예측하는 over-completeness와 지금같이 좁은 범위만을 예측하는 incompleteness 문제가 모두 존재한다고 지적하는 것이 일반적이었는데, 본 논문에서는 incompleteness 문제만을 이야기하는 것이 좀 특이하네요.
이전에도 action completeness 문제를 완화하고자 여러 방법론들이 제안되었었습니다. 여러 방법론들엔 사실상 이전의 모든 방법론들이 포함된다고 볼 수도 있을 것인데요, 저자는 근본적으로 Weakly-Supervised 상황이기 때문에 이전 방법론들처럼 “barren category label“만을 활용해서는 Fully-Supervised 방법론들과의 성능 격차를 줄이기 어렵다는 이야기를 합니다. Barren은 ‘불모지’라는 뜻인데 궁극적으로 localization 수행을 위한 정보를 video-level label만으로는 애초에 얻을 수가 없다는 말인 것이죠.
WTAL에서 Fully-Supervised의 성능을 당장 따라잡을 수 없는 가장 큰 이유가 temporal annotation이 없기 때문인데, temporal annotation을 활용하면 그것은 더 이상 WTAL이 아니게 되는 것입니다. 이렇게 딜레마적인 상황 속에서 저자는 스스로에게 한 가지 질문을 던집니다.
“Is there free action knowledge available, to help complete detection results while maintain cheap annotation overhead at the same time?“
위와 같은 질문의 결과로 저자는 다른 연구들에서도 많이 사용되는 Vision-Language Pre-training(VLP)를 떠올리게 됩니다. VLP는 대용량의 웹 데이터로 사전학습하여 visual-textual representation과 관련된 풍부한 정보를 담고 있죠. 따라서 저자는 VLP를 WTAL에 적용해 Fully-Supervised 방법론들과의 성능 격차를 줄이고자 CBP-VLP 간의 collaborative network를 제안하게 됩니다.
앞서 그림 1-(A)를 보며 기존 CBP에는 분류로 인한 action incompleteness 문제가 존재한다고 했는데요, 다시 그림을 보면 naive한 VLP의 frame-wise classification에서는 반대로 action overcompleteness 문제가 심각한 것을 볼 수 있습니다. 존재하는 대부분의 프레임에 대해 높은 action score를 내뱉으며 많은 FP를 만들어내고 있는 상황입니다. 그렇다면 이렇게 VLP에서 overcompleteness 문제가 발생하는 이유는 무엇일까요?
먼저 저자는 VLP가 거의 대부분 image-text pairs로 학습했기 때문에 비디오에서 중요하게 여겨지는 temporal 정보 대신, 사람과 물체의 시각적인 co-occurence 정보에만 집중하여 분류를 수행했기 때문이라고 합니다. 그러니 action이 발생하지 않지만 시각적으로 유사한 background 프레임을 보고도 제대로 걸러낼 방법이 없는 것입니다.
두 번째로는 ‘run-up'(bgd)과 ‘running'(action)처럼, 몇몇 action과 background의 textual semantic이 굉장히 유사하기 때문에 representation 관점에서 혼동된다는 것입니다.
여기까지 정리해보자면 결과적으로 CBP는 분류 방식을 따르다보니 실제 action에 비해 너무나도 좁은 영역만을 예측하는 incompleteness 문제를 해결해야 하고, VLP는 image-text pairs로 사전학습 되었기 때문에 temporal 정보를 담고 있지 않아 시각적 정보만을 활용해 대부분의 프레임을 action이라고 예측하는 over-completeness 문제를 해결해야 하는 상황입니다.
저자가 이야기하기로도 운 좋게, CBP와 VLP의 action completeness 관점에서의 “Complementary property“를 발견하게 된 것입니다.
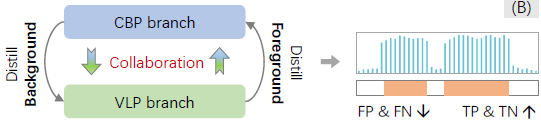
그럼 단순히 생각해보았을 때 위 그림 1-(B)와 같이, 각 브랜치의 단점을 서로가 보완하며 장점만을 살리는 distillation-collaboration framework를 구축한다면 action completeness 문제를 완화할 수 있을 것으로 보입니다.
기본적으로는 CBP의 background knowledge와 VLP의 foreground knowledge를 서로에게 distill 해주어 각각의 incompleteness와 over-completeness 문제를 완화하는 것이 궁극적 목적입니다. 물론 두 브랜치가 서로의 강점만을 상대에게 distill 해주려면 섬세한 설계가 필요할 것입니다.
이를 위해 저자는 먼저 기존의 WTAL 방식과 동일하게 video-level label만을 활용한 학습으로 CBP 브랜치를 warm-up 해줍니다. CBP가 실제 action에 해당하는 구간을 action으로 잘 잡아내지 못하고 애매하게 판단한다고 볼 수 있습니다. 이를 좀 다른 관점에서 보면 CBP는 확실한 background에 대한 정보를 가지고 있다고 볼 수 있는데요, VLP의 over-completeness 문제를 완화하기 위해 이렇게 CBP에서 얻은 confident background information을 활용할 수 있을 것입니다. 사실 저자가 첨부한 그림 1-(A)에서, CBP가 실제 action 구간임에도 실제 background인 부분과 유사한 점수 분포를 가지는 것으로 보아 저자의 가설이 정말 확실한지는 조금 의구심이 들긴 하지만, 일단은 계속해서 살펴보겠습니다.
이렇게 CBP에서 확실한 background 정보를 파악하는 시점이 오면 두 브랜치는 번갈아가며 학습하기 시작합니다. CBP의 confident background frame 정보(pseudo label)를 VLP에게 distill 해주어 over-completeness 문제를 완화하고자 하는 단계가 B-step이고, 이 단계에서 VLP는 이전보다 좀 더 나은 퀄리티의 confident foreground pseudo label을 만들어낼 수 있도록 학습될 것입니다.
이러한 B-step을 거쳐 VLP에서 조금 더 확실한 foreground 정보를 갖게 된다면, 이를 pseudo label 삼아 CBP를 학습시키며 incompleteness 문제를 완화하고 VLP를 위한 confident background pseudo label을 만들어낼 수 있게 될 것이고, 이를 F-step이라고 칭합니다.
또한 학습 중 pseudo label denoising을 위해 confident knowledge distillation과 representation contrastive learning을 수행하게 되는데, 세부 사항들은 논문의 contribution을 정리한 뒤 방법론 부분에서 알아보겠습니다.
Contribution
- We pioneer the first exploration in distilling free action knowledge from off-the-shelf VLP to facilitate WTAL
- We design a novel distillation-collaboration framework that encourages the CBP branch and VLP branch to complement each other, by alternating optimization strategy
- We conduct extensive experiments and ablation studies to reveal the significance of distilling VLP and our superior performance on two public benchmarks
2. Related Work & Preliminary
Vision-Language Pre-training, 즉 VLP 관련하여서는 사전 지식이 없기 때문에 논문에 작성된 Related work와 본 논문에서 활용할 CLIP에 대해서 간단하게 살펴보고 실제 방법론으로 넘어가겠습니다.
Vision-Language Pre-training (VLP)
VLP는 보통 웹에서 쉽게 구할 수 있는 대용량 image-text pair를 기반으로 cross-modal representation을 학습하는 프레임워크를 의미합니다. Task마다 차이는 있겠지만 보통 영상은 비디오보다 annotation 관점에서나 computation 관점에서 훨씬 cost가 적다고 볼 수 있는데요, 이 때문에 대부분의 VLP는 영상 기반으로 수행되는 것입니다.
최근까지도 영상 기반의 VLP 모델인 Flamingo, ALIGN, Filip, OFA, CLIP 등이 활발히 연구되며 영상 분야의 detection, segmentation, HOI, synthesis, generation 등 많은 task에 활용되고 있다고 합니다. 모델들에 대해 자세한 detail까지는 보지 못했지만 보통 인공지능 관련 대기업들에서 Million 또는 Billion 단위의 cross-modal pair를 구축하고, 간단한 representation learning 방법론과 수 백개의 GPU를 통해 사전학습을 수행한 것으로 보입니다.
이러한 흐름은 비디오 분야에서도 이어지고 있습니다. 비디오와 텍스트 feature를 같은 임베딩 공간에 던져 Action recognition을 수행하거나, prompt learning을 통해 효과적인 retrieval과 detection을 수행하는 방법론들도 이미 존재했다고 하네요. 여담으로 citation 된 논문들을 보니 현재 논문의 1저자도 21년도부터 CLIP을 활용한 video-text embedding 관련 연구를 수행하고 있었던 것으로 보입니다.
하지만 위 방법론들은 Fully-supervised 상황에서 task를 수행하거나 trimmed video에서만 적용되었는데, 이번에는 처음으로 Weakly-supervised 상황에서 untrimmed video에 대한 임베딩을 다루게 되었다고 이야기하고 있습니다.
CLIP
VLP에도 많은 방법론들이 존재하지만 본 논문에서는 image-text pair를 사전학습에 활용한 CLIP을 encoder로서 사용하고 있습니다. 그렇기 때문에 CLIP이 무엇인지 간단히만 알아보고 넘어가겠습니다.
먼저 CLIP은 Contrastive Language–Image Pre-training 의 준말입니다. 무언가 Text와 Image pair를 구축하고 Contrastive learning을 통해 표현력을 학습할 것 같은 느낌이 듭니다. 사전학습에 사용된 데이터는 약 4억 개의 image-text pair를 크롤링하여 사용했다고 합니다. 텍스트 검색은 약 50만 건, 검색 당 최대 2만 개의 이미지를 가져와 쌍을 만들어냈다고 하네요. 본래의 target task는 image captioning이라고 합니다.
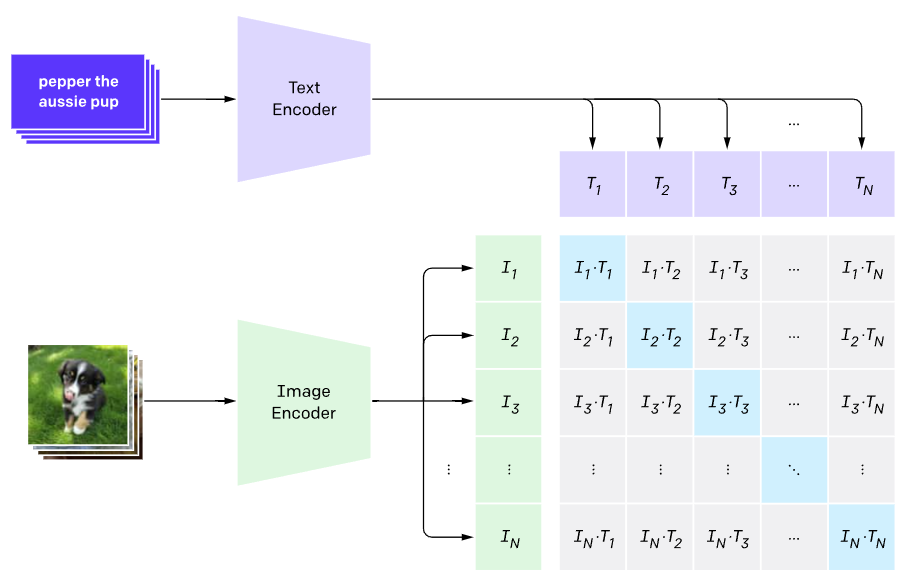
사전학습 방식은 굉장히 간단한데, 배치 내 N개의 image-text 쌍을 가지고 있을 때, 각 모달을 인코딩한 후 FC layer, l2 normalization을 거쳐 유사도 계산에 사용할 embedding \{(I_{1}, T_{1}), \cdots{}, (I_{N}, T_{N})\}을 만들어줍니다. 이후 배치 내 모든 image-text 쌍에 대한 코사인 유사도 매트릭스를 위 그림과 같이 만들어줍니다. 이 매트릭스의 대각선 원소들은 한 pair에 대한 image-text embedding 유사도이므로 커져야하고, 나머지와는 작아져야 하겠죠.
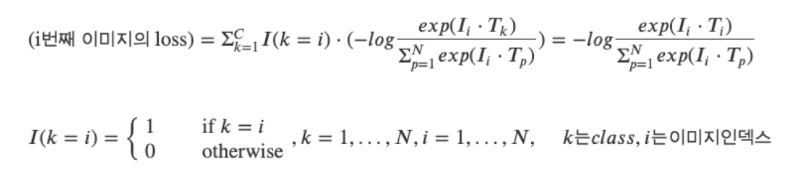
이를 위해 위 수식과 같이 InfoNCE loss를 통한 representation learning이 수행되고 위에서 말씀드렸듯 positive set은 자기 자신과 pair를 이루는 cross-modal(k=i), negative set은 이외의 샘플들임을 알 수 있습니다.
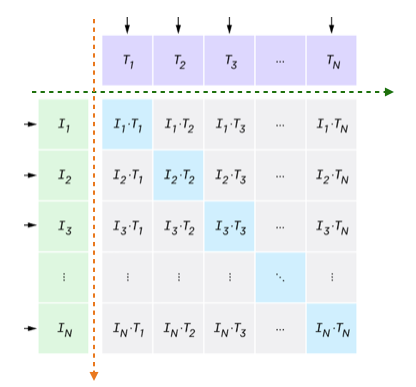
예시의 수식은 N개의 이미지 샘플들에 대한 representation learning(초록 화살표 방향)이었는데, 텍스트 샘플들에 대한 representation learning(주황 화살표 방향)도 대칭적으로 동일하게 수행해주는 방식으로 사전학습이 이루어집니다.
이렇게 사전학습된 CLIP을 WTAL에 적용하려면 Image Encoder에는 비디오 프레임들을, Text Encoder에는 저희가 가지고 있는 video-level label을 넣어주어 각 모달의 feature를 추출하고, 둘을 잘 조합하여 모달 간 특성을 고려한 Class Activation Sequence (CAS)를 만들어낼 수 있을 것입니다.
3. Method
3.1 Notation
Task Formulation
총 N개의 비디오 \{v_{i}\}_{i=1}^{N}과 그에 대한 video-level label \{y_{i}\}_{i=1}^{N}\in{} \mathbb{R}^{C}이 존재합니다. 여기서 C는 데이터셋에 존재하는 전체 클래스의 개수를 의미합니다. WTAL은 이러한 비디오와 라벨을 가지고 최종적으로 한 비디오에 존재하는 action의 시작 지점, 끝 지점, 클래스, confidence score \{(s, e, c, p)\}를 예측하는 것이 목적입니다.
Motivation
방법론의 motivation은 Introduction에서 밝힌 것과 동일합니다. 기존 방법론들과 같이 video-level label로만 학습하는 CBP의 예측은 incomplete하지만 다른 관점에서 보았을 때 양질의 True Negative(confident background)를 가지고 있고, 반대로 VLP의 예측은 over-complete하지만 양질의 True Positive(confident foreground) 정보를 가지고 있다고 볼 수 있어 브랜치 각각이 잘 보고 있는 정보를 반대 브랜치에 pseudo label로 넘겨주며 보완적으로 동작하는 distillation-collaboration framework를 설계해주는 것입니다.
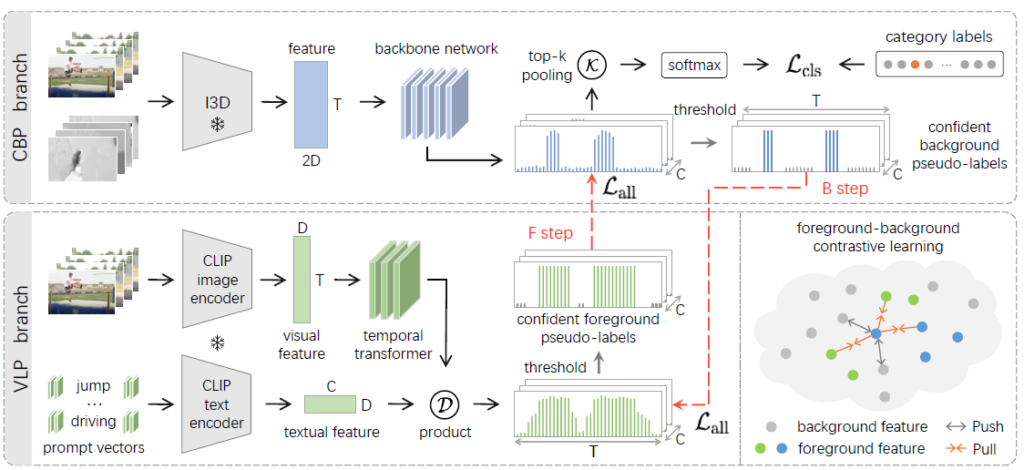
3.2 Distillation of Foreground and Background
CBP branch
CBP 브랜치의 학습은 기존 방법론들과 동일하여 간단합니다. Backbone인 I3D로부터 비디오의 RGB, Flow feature를 추출하고, Transformer encoder(그림 1에서의 “backbone network”)를 태워 Class Activation Sequence (CAS) P^{cb} \in{} \mathbb{R}^{T \times{} C}를 얻습니다. CAS는 각 snippet이 특정 클래스에 속할 확률값을 담고 있는 매트릭스입니다.
이후엔 CAS로부터 top-k mean pooling을 거쳐 video-level class score를 만들어내고, 이와 video-level label을 CE Loss \mathcal{L}_{cls}로 학습시켜 1D Conv가 분류 과정에서 큰 영향을 미치는 snippet에 집중(incompleteness 유발)하도록 학습됩니다.
이러한 CBP 과정은 아래 수식 (1)과 같습니다. \mathcal{K}는 top-k 연산, \hat{y}_{c}는 video-level class score, \sigma{}는 softmax를 의미합니다.
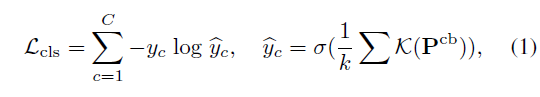
VLP branch
VLP 브랜치는 대용량 image-text pretraining 지식을 활용하고자 CLIP으로 구성됩니다. 참고로 CLIP의 image encoder와 text encoder로는 모두 ViT가 사용되었다고 합니다.
우선 비디오를 몇 개의 연속적 프레임으로 자르고 이를 freeze된 CLIP visual encoder에 태워 frame-level feature F_{vis} \in{} \mathbb{R}^{T \times{} D}를 얻습니다. 하지만 CLIP의 사전학습은 image-text pair 간의 representation learning으로 진행되었기 때문에 이를 비디오 task에 바로 적용하기엔 temporal 정보를 담고 있지 않은 상황입니다. 따라서 이후 temporal 정보를 주입해주기 위해 단순한 transformer layer \Phi{}_{temp}(\cdot{})에 태워 F_{vid} \in{} \mathbb{R}^{T \times{} D}를 만들어줍니다.
이후 text 정보와 관련해서는, 총 C개의 데이터셋 카테고리 이름 text C_{name} 각각 앞뒤에 16차원짜리 learnable prompt vector \Phi{}_{prmp}(\cdot{})를 붙인 후 freeze된 CLIP text encoder \Phi{}_{txt}(\cdot{})에 태워 textual feature F_{txt} \in{} \mathbb{R}^{C \times{} D}를 얻습니다.
이러한 video와 text feature 추출 과정은 아래 수식 (2)와 같습니다.
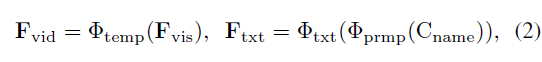
여기까지 진행하면 CLIP의 visual, text encoder와 temporal 정보를 불어넣어 주기 위한 transformer layer를 통해 각 모달의 feature F_{vid}, F_{txt}가 완성된 상태입니다.
앞서 CBP 브랜치에서 CAS P^{cb}를 만들어주었듯 VLP 브랜치에서도 video-text 상호 정보를 활용하는 CAS P^{vl}을 아래 수식 (3)과 같이 만들어줍니다.
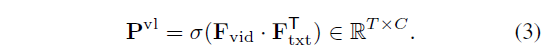
P^{vl}은 둘을 내적하여 얻음으로써 각 snippet이 text feature에 얼마나 반응하는지에 대한 정보를 담고 있다고 볼 수 있습니다.
Confident Pseudo-labels
앞선 단계에서 얻은 CBP의 CAS P^{cb}로부터 background pseudo label을 만들고, VLP의 CAS P^{vl}에서 foreground pseudo label을 만들어 각각 상대 branch에게 distill 해주려는 상황입니다.
각 CAS로부터 pseudo label을 만들기 위해 두 개의 threshold \delta{}_{h}, \delta{}_{l} (\delta{}_{h}>\delta{}_{l})을 지정해 아래 수식 (4)를 기준으로 pseudo label H \in{} \mathbb{R}^{T \times{} C}를 만들어줍니다.
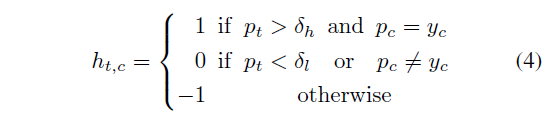
각 브랜치의 CAS 원소 p_{t, c}가 존재하는 클래스이며 score가 높다면 confident action으로 판단하여 1, 존재하지 않는 클래스이거나 존재하지만 너무 score가 낮다면 confident background로 판단하여 0, 둘 다 아닌 경우에는 uncertain하다고 판단하여 -1을 부여해주게 됩니다.
이렇게 얻은 H_{cb}에는 0이 광범위하게 분포해있을 것이고, 일부 영역에 1도 존재할 것입니다. 반대로 H_{vl}에는 1이 광범위하게 분포해있고 일부 적은 영역에 0이 포함되어 있을 것입니다. 각 브랜치에서 지정한 foreground, action snippet에 대해 contrastive feature learning도 수행한다고 하네요.
3.3 Collaborative of Dual-Branch Optimization
Temporal annotation이 없는 상황에서 추출한 pseudo label에는 분명 noise가 존재할 것이기 때문에 두 브랜치의 collaborative optimization을 위해 번갈아가며 학습하는 전략을 취합니다.
맨 처음에는 CBP가 classification-based 방식으로 학습을 하며 incomplete한 pseudo label을 만들어낼 수 있도록 warm up 단계를 거칩니다. 이후 학습은 B step과 F step을 번갈아가며 수행됩니다. B step은 어느정도 warmup된 CBP의 Background Knowledge를 VLP 모듈에게 넘겨주는 단계이고, F step은 CBP의 pseudo label을 받아 어느정도 학습한 VLP의 Foreground Knowledge를 CBP 모듈에 넘겨주어 다시 CBP가 학습하는 단계입니다.
물론 학습 중 I3D와 CLIP encoder는 freeze 된 채로 아래 Conv module이나 trasnformer layer만 갱신됩니다. 이렇게 번갈아가며 수행하는 학습 방식을 통해 각 브랜치가 자신의 단점을 보완해나갈 수 있을 뿐만 아니라 서로의 supervision이 되어 정확하고 complete한 localization을 수행할 것을 기대할 수 있습니다.
각 step마다 서로의 브랜치를 supervision 하기 위한 Knowledge Distillation loss \mathcal{L}_{kd}와 foreground-background contrastive loss \mathcal{L}_{fb}가 아래 수식 (5)와 같이 사용됩니다.
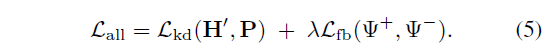
수식 (5)에서 Knowledge Distillation loss \mathcal{L}_{kd}는 아래 수식 (6)과 같습니다.
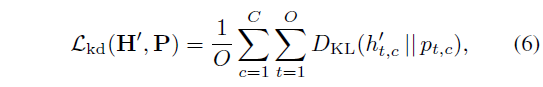
D_{KL}(p(x) || q(x))는q(x)로부터 p(x)의 KL Divergence 값을 의미합니다. 또한 O는 confident frame의 index, 즉 수식 (4)로부터 pseudo label H를 생성할 때 1 또는 0으로 할당된 snippet을 대상으로만 optimization이 이루어지는 것입니다.
앞서는 계속 CBP의 background, VLP의 foreground 정보를 다른 브랜치에게 넘겨준다고 했지만 실제로는 모델이 한 종류의 클래스만 보고 자명해로 빠지는 상황을 막기 위해 confident snippet에 대해서는 모두 학습해주는 것을 볼 수 있습니다. 정리하자면 \mathcal{L}_{kd}를 통해 CAS의 confident snippet score p_{t, c}가 상대 브랜치에서 나온 pseudo label h'_{t, c}를 정답 삼아 따라가도록 분포를 학습한다고 볼 수 있습니다.
다음으로 untrimmed video에선 시각적으로 유사하지만 action이 아닌 프레임들이 연속적으로 존재합니다. 따라서 이러한 pseudo background frame의 representation을 구별해주기 위해 \mathcal{L}_{fb}를 통해 feature contrastive learning도 수행해주는데요, 이는 아래 수식 (7)과 같습니다.
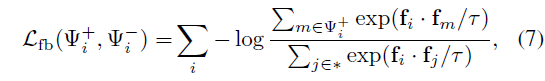
수식 (7)은 InfoNCE loss로 볼 수 있는데, 차이점은 positive sample이 여러 개이면서 cosine 유사도를 학습하는 것이 아닌 feature의 내적값을 최대화하거나 최소화한다는 것입니다. 결국은 어떤 샘플들이 positive set \Psi{}^{+}와 negative set \Psi{}^{-}로 할당되는지가 중요할 것입니다.
Positive set \Psi{}^{+}는 같은 action category에 속하는 모든 confident action snippet으로 구성되고, negative set \Psi{}^{-}는 confident background snippet으로 구성됩니다. 쉽게 말하면 positive set은 수식 (4)에서 1로 지정된 snippet들, negative set은 0으로 지정된 snippet들인것입니다. 위와 같은 contrastive learning을 통해 foreground와 background에 대해 구별력을 갖도록 layer들이 학습된다면, 현재는 -1로 지정되어 학습에 관여하지 않았던 snippet들도 추후에는 foreground 또는 background로 뚜렷하게 구분되는 효과도 기대할 수 있을 것입니다.
여기까지 하여 학습과 관련된 부분의 설명은 마치고, Inference는 어떻게 수행되는지 알아보겠습니다.
3.4 Inference
Inference는 CBP만을 활용하고, freeze한 I3D로부터 RGB, Optical flow feature를 추출해 CAS를 생성해냅니다. 이후 클래스 별 top-k mean pooling을 통해 video-level class score를 만들어낸 뒤 threshold 이상의 action은 비디오에 존재한다고 판단하여 CAS 원소에 multiple threshold를 적용해 여러 redundant한 proposal을 만들어냅니다. 마지막으로 Soft-NMS를 적용해 최종 proposal을 얻고, GT와 비교하여 성능을 측정하게 됩니다.
4. Experiments
4.1 Comparison with State-of-the-art Methods
벤치마크는 THUMOS14 데이터셋과 ActivityNet v1.2 데이터셋을 대상으로 진행하였습니다.
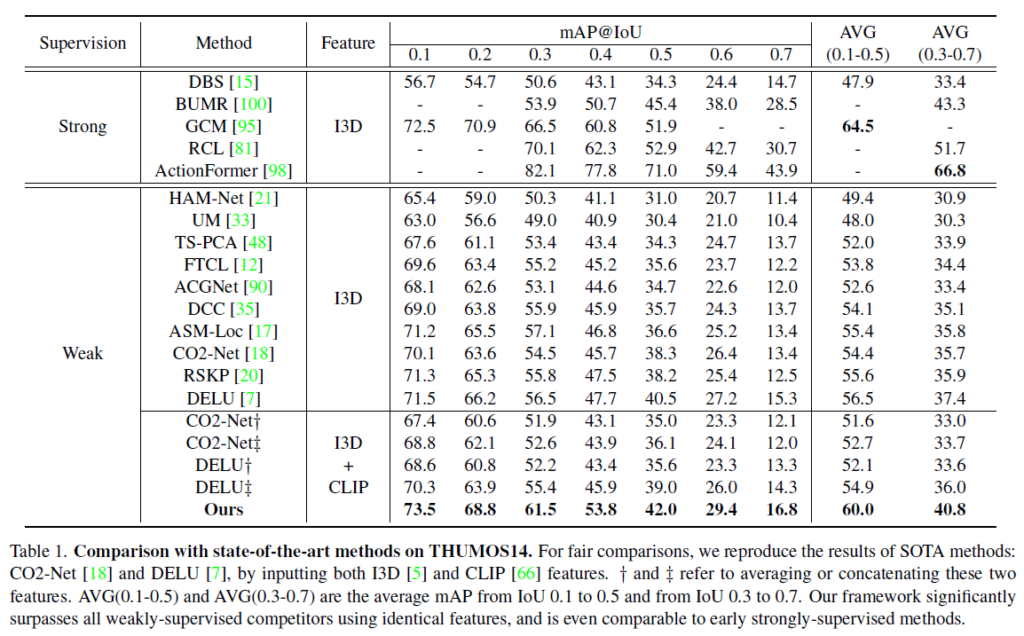
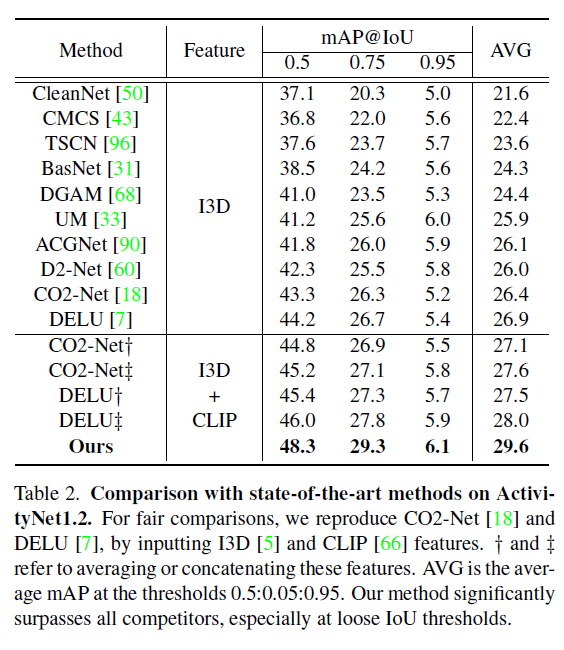
표 1과 2가 각각 THUMOS14, ActivityNet v1.2 데이터셋에 대한 벤치마크 성능입니다.
특이한 점은 각 표에서 Feature로 I3D + CLIP을 사용한 경우의 성능을 볼 수 있는데요, 이는 기존 SOTA인 CO2-Net과 DELU 방법론 학습 시 I3D로부터 얻은 RGB, Flow feature와 CLIP의 encoder에서 얻은 feature를 average 또는 concat하여 사용하는 경우의 성능입니다. Ours는 average나 concat 방식이 아닌 지금까지 설명한 CBP, VLP 간의 distilling 방식이겠죠.
표 1에서는 I3D + CLIP feature를 사용하는 경우 CO2-Net과 DELU의 성능이 I3D feature만을 사용하는 것보다 떨어지고, 표 2에서는 오르는 것을 볼 수 있습니다. 우선 THUMOS14 데이터셋은 학습, 테스트 비디오의 개수는 상대적으로 적지만 한 비디오당 포함하는 action의 개수가 15.5개, ActivityNet v1.2의 경우 한 비디오당 action의 개수가 약 1.5개정도 됩니다.
이를 바탕으로, THUMOS14 데이터셋에서 CLIP feature를 함께 사용하는 경우 비디오에서 action 구간이 빈번하게 발생하기 때문에 overcomplete한 action을 예측하게 되면 성능이 아무래도 떨어지게 되며, ActivityNet v1.2의 경우 action의 개수가 적으며 하나의 action 지속 시간이 길기 때문에 오히려 overcompleteness 성질이 도움이 되었을 것이라고 이야기하고 있습니다. 반면 저자의 방법론은 두 데이터셋 모두에서 기존보다 훨씬 높은 성능을 보여주며 두 브랜치의 collaborative distilling framework 효과를 입증하였습니다. 추가적으로 높은 IoU threshold에서 높은 mAP를 보여주는 것을 통해 저자가 다루고자 한 action completeness 문제에도 꽤나 효과적이었음을 알 수 있습니다.
4.3 Ablation Study and Comparison
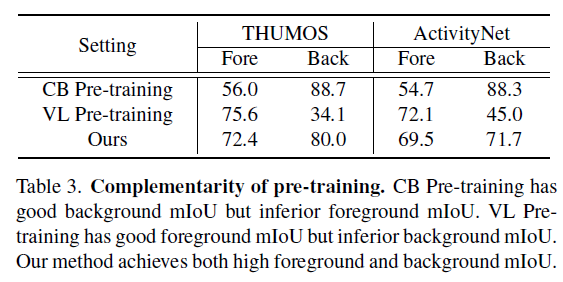
표 3은 두 데이터셋에서 mean IoU 값을 통해 본 방법론에서 생성한 pseudo label의 정교함을 보여주고자 합니다. 이에 앞서 CBP와 VLP 브랜치 각각만을 사용했을 때 생성된 pseudo label로 학습했을 때 얻은 proposal의 mIoU를 볼 수 있는데요, 저자가 관측한 문제와 동일하게 CBP는 incomplete한 pseudo label을 생성하며 foreground mIoU가 상대적으로 낮고, VLP는 over-complete한 pseudo label을 만들어내어 background mIoU가 상대적으로 낮게 나오는 것을 볼 수 있습니다.
이후 저자의 방식대로 CBP와 VLP가 서로 distill하며 학습했을 때의 proposal은 foreground와 background 모두 어느정도 complete하게 대응되는 것을 볼 수 있습니다.
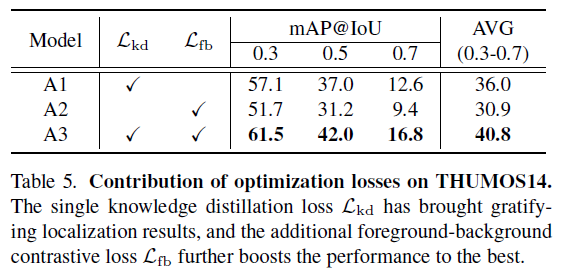
다음으로 표 5는 각 loss 적용 여부에 대한 ablation 성능입니다. A1은 \mathcal{L}_{kd}만 적용한 상황임에도 준수한 성능을 보이는 것을 알 수 있습니다. 다음으로 A2는 \mathcal{L}_{fb}만 적용한 경우의 성능인데, 각 브랜치 간 knowledge distillation 없이 confident snippet에 대한 feature contrastive learning만 수행했음에도 꽤나 높은 성능을 보이고 있네요. 마지막으로 두 loss를 함께 적용하는 경우 큰 성능 향상을 일으키는 것을 알 수 있었습니다.
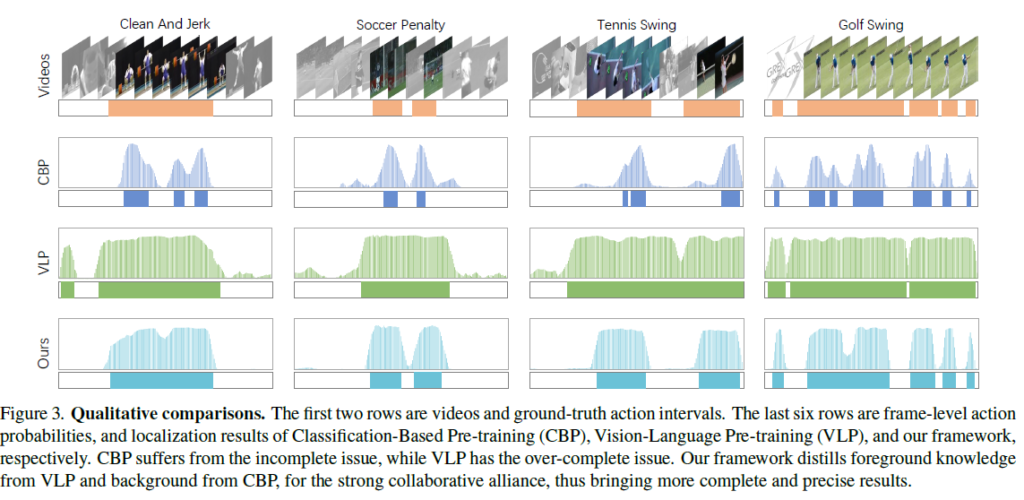
그림 3은 정성적 결과입니다. CBP와 VLP의 예측 결과를 통해 저자가 지적한 incompleteness, overcompleteness 문제가 있음을 알 수 있고 두 브랜치를 잘 조합하는 저자의 방법론이 GT와 가장 유사한 예측을 만들어내고 있네요.
Conclusion
이전에 리뷰했던 23년도 CVPR 논문에도 클래스의 text를 GloVe embedding하여 video feature와 함께 활용했을 때 높은 성능을 보이는 방법론이 존재했습니다. 해당 방법론은 학습 과정 중 사용되는 feature가 기존과 달랐다면 본 논문은 CLIP과 Knowledge distillation 프레임워크를 함께 적용하여 더욱 정교하게 설계함으로써 훨씬 높은 성능을 보여주고 있습니다.
이상으로 리뷰 마치겠습니다.