Introduction: Overconfidence and Uncertainty in Deep Learning
딥러닝은 일반적으로 데이터의 분포를 학습하여 데이터에 나타난 일반적인 경향성에 따른 예측을 할 수 있는 모델을 찾아내는 것이다. 딥러닝 모델이 수행하는 대표적인 태스크 중 하나인 분류(Classification)는 보통 입력된 데이터에 대해 K개의 클래스에 속할 확률을 예측하며, 이때 가장 높은 확률로 예측된 클래스가 모델의 예측 클래스가 된다.

이때 모델의 출력은 Softmax 이후의 출력이며 그 합이 1이므로 위에서 표현하였듯이 확률로 간주되곤 한다. 위의 그림의 경우 입력 데이터 X에 대해서 해당 데이터가 2번 클래스에 속할 확률이 70%라고 모델이 예측한 것이다.
그러나 데이터에 대한 모델의 예측 스코어가 모델의 확신도(certainty)를 대변하지 못하는 현상이 발생하는데 이를 Overconfidence라고 한다. 즉, overconfidence란 모델이 데이터에 대한 실제 확신도 보다 높은 스코어로 해당 데이터라고 추정하는 현상이며 이는 분류 뿐만 아니라 다양한 딥러닝 모델과 태스크에서도 문제가 되고있다. 특히 overconfidence 현상은 의학, 군사와 같은 분야에서 딥러닝 모델에 100% 의존한 선택을 할 수 없는 이유 중 하나이다.
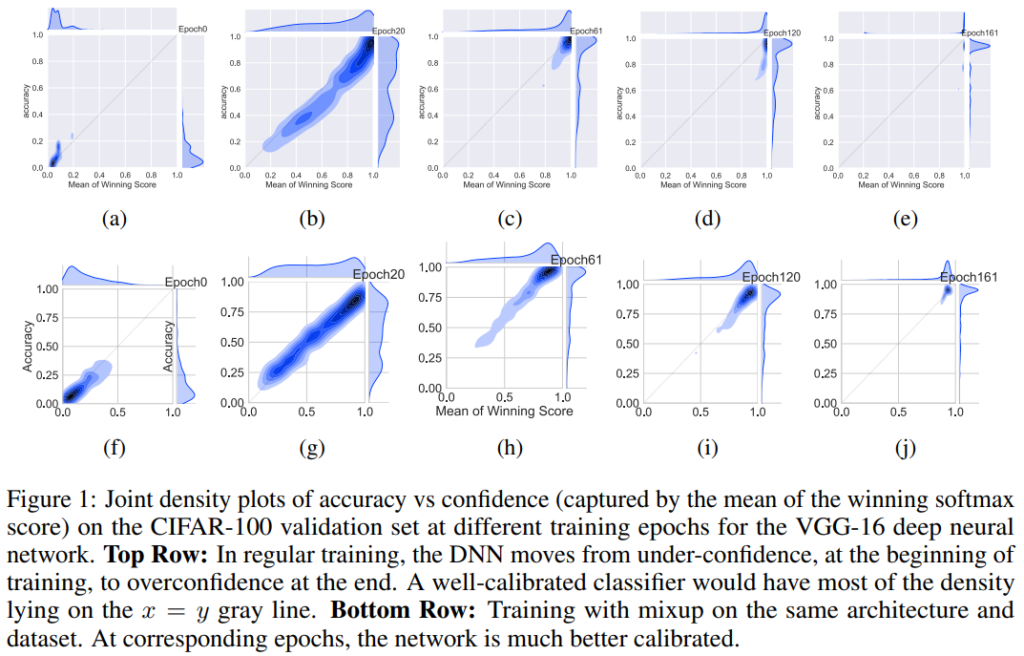
위의 Figure 1은 overconfidence 현상을 확인할 수 있는데, x축은 mean of winning score로 모델이 예측값 중 가장 높은 점수를 의미하며 y축은 실제 정확도를 의미한다. 1행은 Cifar-100에 대해 VGG-16로 학습할 때, 0epoch, 20epoch, 61epoch, 120epoch, 161epoch에서의 모델 예측 정확도와 확신도 정보이며, 2행은 동일한 환경에서 Mixup[1]을 적용하여 학습하였을 때의 결과이다. 논문의 소개에 앞서 overconfidence에 대한 일면식이 없는 독자를 위해 이에 대한 설명을 우선했으며, 논문의 본 주제는 제목에서 알 수 있듯이 Mixup[1]이 overconfidence 현상에 대해 대응할 수 있다는 것이다. 따라서 Figure 1에서는 대조군인 1행과 Mixup[1]을 적용한 결과인 2행을 동시에 확인할 수 있다. 우선 1행을 보면 학습이 진행될 수록(즉, (a)에서 (e)로 갈수록) accuracy와 score모두 높아짐을 알 수 있다. 그러나 특징적인 점은 accuracy의 경우 개선의 한계가 있으나, score의 경우 피크(peak) 형태가 나타날 때 까지 개선된다는 점이다. 학습이 진행될수록 실험 모델의 데이터에 대해 실제 성능보다 높은 값으로 신하고 있는 것이다. 그러나 2행을 보면 score 분포가 피크 형태가 아닌 accuracy와 유사한 형태로 나타남을 보임으로써 overconfidence 현상이 발생하지 않은 것을 보였다.
Mixup[1]이란 2018년 ICLR에 소개된 데이터 증강(data augmentation)관련 연구로 콜럼버스의 달걀과 같은 혁신적인 데이터 증강의 접근법을 소개했다. 적용 방법은 매우 간단한데 아래의 수식1과 같다.
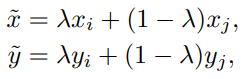
즉 랜덤 파라미터인 람다(λ)를 통해 데이터와 라벨 모두 섞어서 학습시키는 것이다. 경험적인 실제 데이터 분포가 아닌 새로운 분포를 만들어 augmentation 한다는 점(beyond empirical risk minimization)을 제목에서부터 알 수 있다. 이제 Mixup이 모델의, 특히 overconfidence 해결을 위한 calibration에 어떠한 영향을 끼치는지 다양한 실험으로 알아보자.
Setup
논문에서는 다양한 분석실험을 위해 STL-10, CIFAR-10, CIFAR-100, Fashion-MNIST 데이터셋을 사용하였으며 STL-10을 위해 VGG-16을, CIFAR-10, CIFAR-100을 위해 VGG-16과 ResNet-34를 사용하였다. Fashion-MNIST는 ResNet-18을 통해 학습을 진행하였으며 batch normalization과 weight decay 등 다양한 세팅 또한 공개되어있다.
Mixup 방법을 통한 모델의 성능 향상에 대해서는 원 Mixup 논문에서도 잘 다루었을 것이다. 본 논문은 overconfidence와 calibration이라는 주제에 맞게 calibration metrics을 추가로 사용하였다. 낯익지 않은 평가지표일텐데, 측정 방법은 간단하다.
- Expected Calibration Error(ECE)
ECE의 측정방식은 수식2와 같다. 성능을 평가할 데이터셋인 B에 대해서 실제 모델의 accuray를 의미하는 acc(B)와 가장 높게 예측한 스코어의 평균을 의미하는 conf(B)의 차이의 평균이 ECE와 같다. n은 전체 데이터 셋이고 BM은 B를 M개의 interval 로 나눈 그룹이다
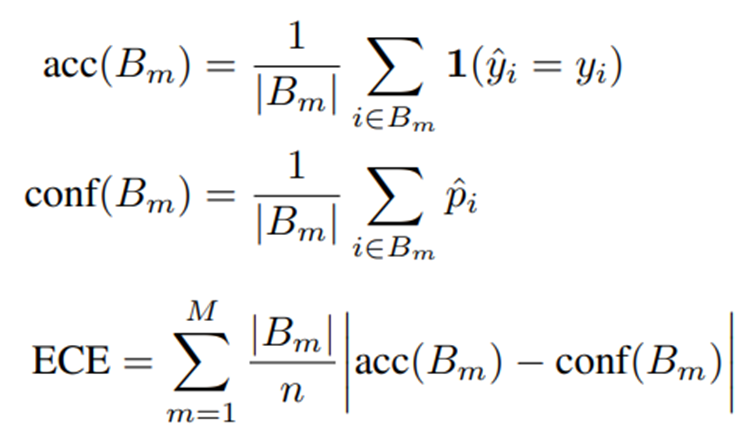
- Overconfidence Error(OE)
위의 ECE 지표가 대표적인 calibration metric이지만, 의학과 같은 high-risk applications 분야에서 해당 문제는 중요한 문제이므로 추가적인 지표를 사용한다. 그것이 OE 지표이며 측정 방식은 아래와 같다. OE는 신뢰도가 정확도를 초과하는 경우에만 신뢰도 점수로 높은 페널티를 발생시키도록 구성되었다.
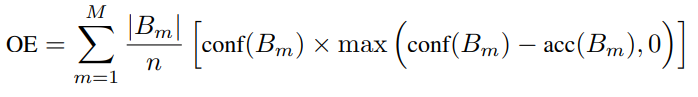
실험
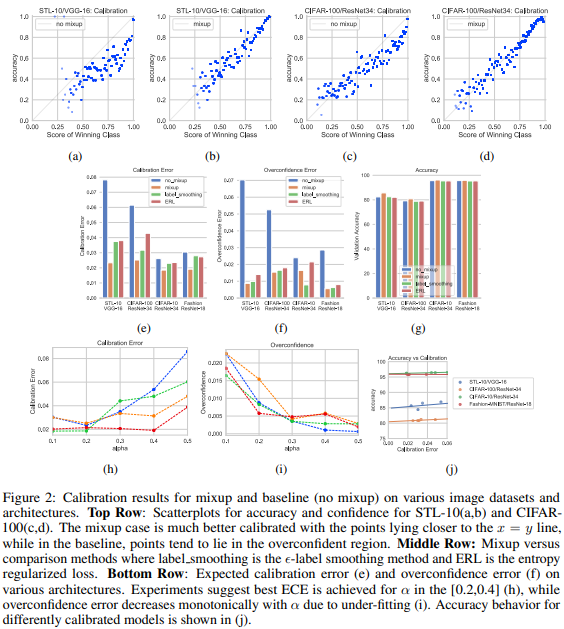
위 실험이 본 논문의 대표실험 중 하나이다. 1행에서는 STL-10과 CIFAR-100 데이터셋에서 mixup method를 통한 calibration 결과를 잘 보여주는데, mixup을 적용하지 않은 (a)와 (c)의 경우 거꾸로된 C형의 분포를 보이며 실제 accuracy보다 winning class에 대한 예측 점수가 더 높은 것을 알 수 있다. 그러나 mixup을 적용한 (b), (c)의 경우 accuracy와 winning class score가 동일한 의미를 갖도록 개선됨을 확인 할 수 있다. 2행에서는 ECE와 OE, 실제 모델의 accuracy에 대한 비교 성능을 보이는데, mixup이 baseline(no mixup)에 비해 월등하게 calibration을 수행하였음을 확인할 수 있으며 calibration을 위한 기존 연구인 label smoothing[2]과 entropy-regularized loss(ERL)[3]대비 더 높은 개선율과 정확도(acc) 성능 향상을 보임을 확인할 수 있다. 마지막 행의 경우 alpha에 따른 ECE와 OE (h, i) 값이다. (j)는 calibration error와 accuracy 간의 관계를 볼 수 있는 그래프이다. 이때 alpha란 앞서 수식1에서 데이터 혼합을 위해 사용하는 랜덤 파라미터인데, 이 파라미터가 accuracy 성능 뿐 만 아니라, calibration에도 큰 영향을 미친다는 것이다. 이때 alpha가 [0.2, 0.4]에 속할 경우 acc와 calibration에 모두 긍정적인 영향을 미친다고 하는데, 그 파라미터가 의미하는 바는 아래와 같다. alpha는 수식 1의 람다(λ)를 발생시키는 함수인 베타분포의 파라미터인데, 베타분포를 이용해 난수를 발생시킬 때, alpha가 1 이하로 작을수록 0.0 혹은 0.1에 가까운 수가 발생할 확률이 높으며 1보다 크고 수가 커질수록 중간값인 0.5에 가까운 수가 발생확률이 높다. 각 수에 대한(x 축) 발생 확률을 나타낸 그래프이다. (위상만 참고하자)
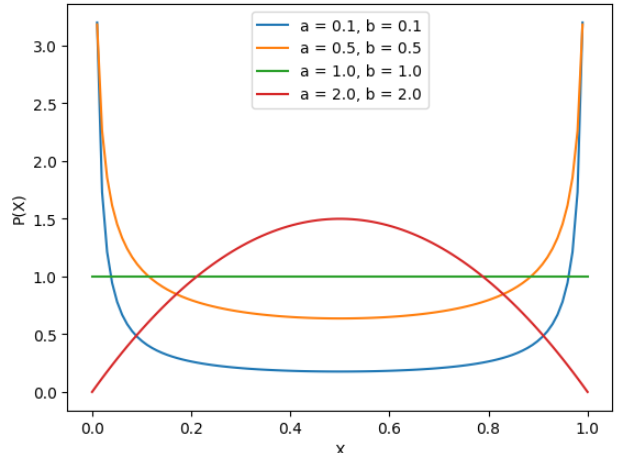
논문의 해석은 0.5에 가까운 수로 두 이미지를 혼합할 경우 원래 데이터의 분포에서 너무 벗어나기 때문에 (mixup을 통해 생성한 데이터는 원 논문의 제목에서도 드러났듯이 non-empirical data 이다.) 오히려 성능을 하락시킨다는 것이다.
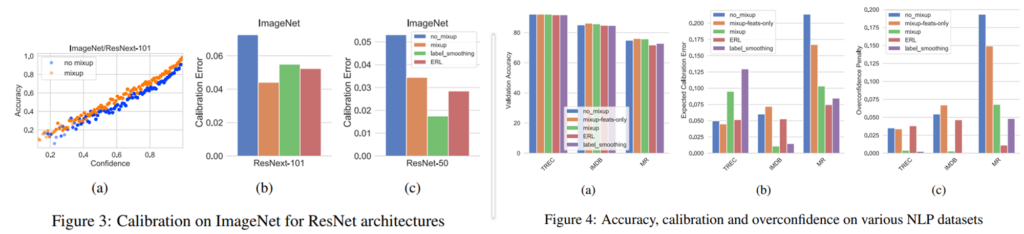
이러한 개선 효과는 위의 데이터셋 뿐 만 아니라 ImageNet 데이터에 대해서도 같은 경향을 보였다. 상대적으로 overconfidence의 발생확률이 낮은 많은 클래스를 갖는 데이터에 대해서도 calibration 작용을 할 수 있다는 것이다. 또한 Language 도메인에도 mixup을 적용하고 실험하여 mixup이 일반적으로 모델 학습에 있어 calibration 작용을 함을 실험을 통해 보였다.
그렇다면 mixup의 어느 특징이 model calibration을 가능하게 했을까? mixup의 feature mixing과 soft label로 나누어 실험하므로써 이에 대한 해답을 보였다. 아래는 주황색의 기존의 mixup과 label값을 더 가까운 점수의 라벨을 사용한 hard-coded labels을 통한 학습(파란색)의 결과이다. 시각적으로 알 수 있듯이 mixup이 soft label이 calibration 성능 향상에 큰 영향을 주었음을 예측할 수 있다.

mixup 방법론이 정확도 성능 개선에 매우 효과적인 방법론이였던 이유는, 두 개의 이미지를 랜덤 파라미터로 결함하므로써 이미 보았던 데이터에 대한 재학습 가능성이 매우 낮아진다는 점이다. 이러한 학습의 다양성이 모델의 overfitting을 막아 모델의 calibration에 긍정적인 영향을 미쳤을 가능성이 크다. 논문에서는 mixup을 적용하면 실제로 overfitting 현상이 발생하지 않는지에 대해 1,000 epoch를 학습하여 base model (alpha=0, mixing 되지 않은 이미지 분포와 거의 유사)과 mixup 방법론으로 학습된 모델의 성능을 비교하였다.
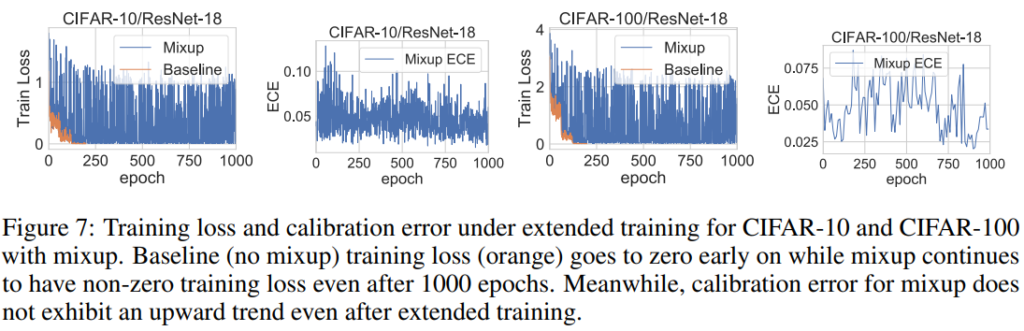
baseline 모델의 경우 CIFAR-10 데이터에 대해 1,000 epoch를 학습한 이후 train loss가 0으로 수렴하고 train accuracy가 100%에 도달해 완전한 overfitting을 보여준 반면 mixup을 사용하였을 경우 그렇지 않음을 확인할 수 있다. 즉, mixup이 overfitting을 막는 현상이 calibration 기능을 수행하는데 긍정적인 영향을 미쳤음을 알 수 있다.
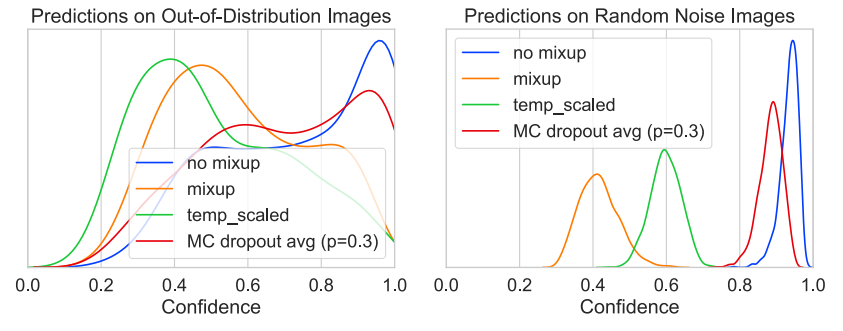
마지막으로 out-of-distribution 데이터나, random noise 데이터에 대한 예측을 보았는데, 많은 dnn 모델들이 노이즈에 대해 높은 확신도로 특정 클래스라고 예측하는 현상이 overconfidence를 관찰 할 수 있는 대표적 현상이다. 그러나 mixup이나 temperature scaling[4](softmax 함수에 적용하여 모델 예측값을 스무딩 하는 방법론)과 같은 model calibration을 적용하였을 때에는 이상데이터에 대해 0.4~0.6에 속하는 점수를 예측하며 이러한 overconfidence 현상이 크게 개선되었음을 확인할 수 있다.
이상으로 다양한 실험을 통해 overconfidence에 mixup 방법론이 미치는 영향에 대해 알아보았다. 정말 간단한 방법론처럼 보이는데, accuracy 측면 뿐 만 아니라 많은 개선을 발생시키는 것이 인상깊었으며 이후 augmetation 방법론인 cutmix(ICCV 2019, oral talk)에서도 적용되는지 궁금하다.
참고
[1] mixup: Beyond Empirical Risk Minimization [arXiv] (Hongyi Zhang:MIT, Moustapha Cisse:FAIR, Yann N. Dauphin:FAIR, David Lopez-Paz:FAIR)
[2] Rethinking the inception architecture for computer vision
[3] Regularizing neural networks by penalizing confident output distributions.
[4] On calibration of modern neural networks
황유진 연구원님, 좋은 리뷰 감사합니다.
리뷰를 읽다보니 궁금증이 생겨 질문 남깁니다. 리뷰 초반에 overconfidence에 대한 문제점을 언급해주셨습니다. 이는 데이터에 대한 실제 확신도보다 높은 confidence socre로 해당 class로 추정하는 것이라고 이해했습니다. 하지만 일반적으로 분류를 수행할 때 결국 가장 높은 confidence score의 class를 one-hot encoding하게 되어 해당 class의 확신도 수치에 무관하게 가장 높은 스코어의 class로 할당되게 되어 결국 중요한 것은 socre의 순위인 것으로 보이는데, 수치 자체가 중요한 이유가 무엇인지 알고싶습니다 !
감사합니다.
예를 들어 공장에서 부품 분류에 인공지능 모델을 사용할 때, 높은 정확도가 중요하므로 인공지능 모델이 어떠한 부품 A를 ‘나사’라고 80%의 확신도 이상으로 분류할 때 만 판매를 위해 포장을 진행한다고 합시다. 이러한 경우 모델의 예측 확신도는 매우 중요한 정보가 되겠지요?
그러나 딥러닝 모델은 보통 one-hot 형식으로 학습되는 경우가 많아 확신도에 대한 정보가 예측에 출력값에 반영되지 않는 경우가 많고 보통 실제 데이터의 난의도 보다 과신하게 되는 overconfidence가 발생합니다. overconfidience 문제를 해결할 수록 딥러닝 모델이 블랙박스가 아닌 이해가능한 방식으로 작동된다고 볼 수 있으며 따라서 high-risk applications 분야에서 인공지능 모델을 사용할 수 있게 됩니다.