안녕하세요 일곱 번째 X-Review입니다. 금주 리뷰할 논문은 ICCV 2019에 게재된 <Convolutional Character Networks>입니다. 지지난번 리뷰했던 CRAFT와 동일하게 character를 기본 단위로 삼은 방법론이며, 차이점으로는 CRAFT는 text detection만 수행했었다면 본 논문은 detection과 recognition을 1 stage로 수행한 논문으로 보시면 되겠습니다. 바로 시작하도록 하겠습니다. ?

1. Introduction
이미지에서 텍스트를 검출하는 과정은 text detection, text recognition 두 가지로 분리해서 볼 수 있습니다. text detection은 이미지에서 단어가 있는 부분에 대하여 bounding box를 예측하는 것이 목표이며, 현재 방법론들은 주로 object detection이나 segmentation 프레임워크의 확장판으로 볼 수 있겠습니다. text recognition은 detection과정에서 예측한 bounding box를 가지고 문자 label의 sequence를 인식하는 것을 목표로 합니다. 일반적으로 그냥 sequence labeling problem으로 보면 됩니다.
하지만, 이 2 step 파이프라인은 몇 한계점이 존재합니다.
- detection, recognition 과정을 각각 독립적으로 학습하는 것은 sub-optimization 문제와 함께 text 자체의 잠재력을 완전히 발휘하기 어렵다.
- 예를 들어 text detection과 recognition은 서로 보충적인 정보나, strong context같은 것을 제공해줄 수 있습니다.
- 2 step 파이프라인은 여러 sequential한 단계를 거쳐야 하기 때문에 1 stage보다 더 복잡한 시스템이며, recognition의 성능은 전적으로 text detection의 결과 (예측한 bbox)에 의존하게 됩니다.
이러한 2 stage의 단점 때문에 최근에는 이 둘을 동시에 구현하는 통합된 프레임워크를 개발하는 방향으로 연구가 이뤄지고 있습니다. 예를 들어 제 저번주에 리뷰했던 [FOTS]나, [Mask TextSpotter]같은 방법론이 있겠습니다. FOTS는 recognition과정에서 RNN 기반의 branch를 추가해 사용하였고, 이를 end-to-end로 학습할 수 있게 하여 SOTA의 성능을 달성하였습니다. 이렇게 FOTS는 하나의 모델로 detection과 recognition을 동시에 수행할 수 있게 되었지만 본 논문의 저자는 FOTS를 포함한 end2end 방법론들을 여전히 2 stage 프레임워크로 보며 몇 한계점이 존재한다고 합니다.
- recognition branch에서는 보통 RNN 기반의 sequential model을 사용하는데, 이는 detection 과정과 함께 합쳐지면 최적화하기 어렵고 학습하기 위해서는 상당량의 train 데이터가 필요하게 됩니다.
- 현재 2 stage의 프레임워크는 보통 RoI cropping과 RoI pooling과정을 포함하고 있는데, 이 과정은 텍스트의 다양한 크기와 형태에는 불필요한 배경 정보를 포함한 텍스트 영역이 추출될 수도 있습니다. 이러한 점은 여러 방향을 가지거나(multi-orientation) 혹은 곡선형 텍스트(curved-text)에 대해 recognition 과정에서 성능 저하로 이어질 수 있습니다.
방금 언급한 2 stage 프레임워크에서 사용되는 RoI cropping과 RoI pooling의 한계점을 극복하기 위해서, text-alignment 레이어를 사용하거나, affinity transformation을 사용한 방법론도 많이 등장하였지만 곡선으로 된 text에서는 잘 동작하지 않았죠. 또, 많은 모델들은 word를 기반 단위로 사용하였지만, word 기반 detection은 종종 text recognition을 sequence labeling 문제로 해결해야 했고, 이를 위해서 또 추가적인 모듈을 사용해야 했습니다. 이렇게 해결을 해도 중국어와 같은 언어들에서는 word가 무엇인지 명확하게 구분되지 않는 경우가 많았습니다. 그렇기에 character가 word보다 다양한 언어에 대해 일반화하기 더 적합하다는 결론을 내릴 수 있겠습니다. 이렇게 word가 아닌 character를 기본 단위로 사용하게 된다면 RNN 기반의 sequential model이 아니라 간단한 CNN 모델을 사용하여 recognition을 수행할 수있다는 장점이 있습니다.
그렇기에 본 논문에서는 character를 기본 단위로 설정하여 text detection과 recognition을 동시에 수행하는 Convolutional Character Networks(이하 CharNet)을 제안합니다. 이 CharNet은 one stage의 CNN 모델을 처음으로 사용하였으며, 더 복잡하게 구현된 2 stage 모델들보다 더 좋은 성능을 보입니다. 이 모델은 RNN 기반의 word recognition 대신에 간단한 모델을 구현함으로써 output으로 word단위의 bbox, character 단위의 bbox, 그리고 이에 상응하는 character 라벨을 출력해냅니다. 아래 [Fig 1]을 보시면 단어 단위, 글자 단위의 바운딩 박스와 그 위에 어떤 단어인지 라벨 값까지 쓰여져 있는 것을 확인할 수 있습니다.

본 논문의 contribution은 다음과 같습니다.
- one-stage CharNet을 제안하여 text detection과 text recognition을 동시에 수행
- character를 기본 단위로 삼아 현재 RoI pooling 및 RNN 기반 recognition의 여러 한계점을 극복함
- iterative character detection 방법 개발
- 합성 데이터셋으로부터 학습한 character detection 능력을 real-world 이미지에 적응할 수 있도록 함
- ICDAR 2015 데이터셋에서 2 stage 방법론 성능 능가
- lexicon (단어 사전)이 없이도 거의 유사한 성능 얻음
2. Convolutional Character Network
2.1 Overview
introduction에서 현존하는 end-to-end 방법론들 중 text recognition을 수행하는 부분에서 RNN기반 sequential 모델을 주로 사용해왔는데, 이 부분에서 사용하는 RoI cropping이나 RoI pooling에 한계점이 존재한다고 언급했었습니다.
본 논문에서 제안하는 CharNet은 다음의 두 가지 branch로 구성된 one-stage convolutional 아키텍처입니다.
- A Character Branch
- A text Branch
Character branch는 character 즉, 글자 단위의 detection과 recognition을 하도록 고안된 branch이며, Text branch는 이미지에 있는 단어의 bounding box를 예측하도록 고안된 branch입니다. 이 두 branch들은 병렬적으로 동작하도록 하여 전체 모델은 one-stage model입니다.
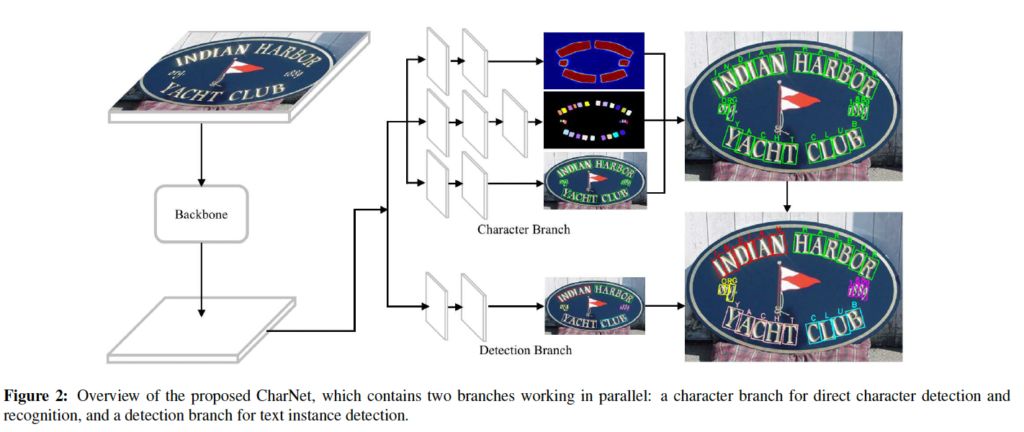
위 그림을 보면 character branch와 detection branch가 병렬적으로 동작하고 있는 것을 확인할 수 있습니다. 본 모델 CharNet을 학습하기 위해서는 두 가지 유형의 bounding box가 필요합니다. 먼저 instance level의 bounding box로, 이는 텍스트 영역을 포함하는 큰 영역의 bbox를 의미합니다. 두 번째로 character level의 bbox가 필요한데, 이는 문자 레벨로 텍스트를 분리한 작은 영역의 bbox를 의미한다고 보면 되겠습니다. 이 두가지 정보와 함께 character 라벨 정보를 이용하면 모델을 학습시킬 수 있습니다. 학습을 다 마친 후 Inference과정에서 CharNet은 instance level과 character level의 bbox를 동시에 output으로 뱉게 되며 그에 해당하는 글자 라벨값도 한번에 예측해냅니다.
하지만 많은 현존하는 text dataset은 character level의 어노테이션을 포함하지 않습니다. 이전 리뷰에서도 여러번 언급했듯이 cost가 굉장히 크기 때문인데요, 그렇기에 본 논문에서는 character detection을 하기 위해 iterative learning 방식(반복적인 학습 방식)을 개발하였습니다. 먼저 character level의 어노테이션을 가지고 있는 synthetic data(합성 데이터)로부터 character detector를 학습한 후, 이렇게 학습된 character detectior는 real world 이미지에 적응하고 적용할 수 있겠습니다. real world 이미지에 적용하는 과정을 반복적으로 수행하는 과정을 통해 character detector 모델은 점진적으로 개선되면서 real world 이미지에 대해서 character를 식별할 수 있게 되는 것입니다.
Backbone networks
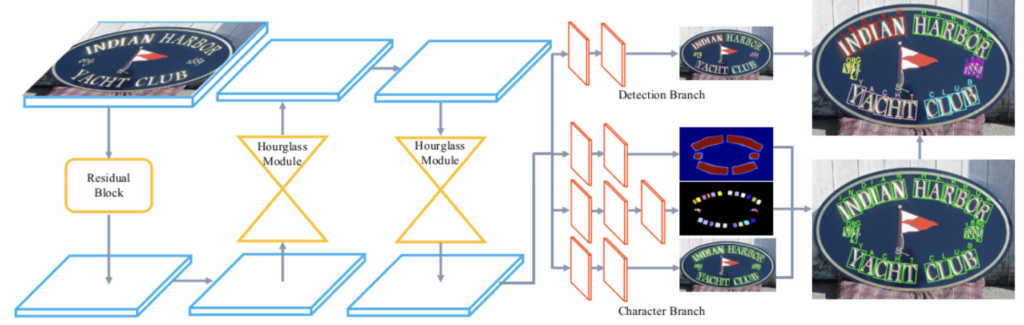
CharNet은 백본 네트워크로 ResNet-50과 Hourglass network를 사용하였습니다. 위 그림은 [Fig2]와 거의 동일한 그림으로, 아카이브에 실린 그림인데 [Fig2]보다 backbone이 자세히 그려져 있어 가져왔습니다.
ResNet50에서는 최종 convolution map으로 4배 다운샘플링된 feature map을 사용함으로써 높은 resolution을 갖는 feature map을 가지게 되고 이로 인해 이미지 내의 작은 텍스트 영역도 식별해 낼 수 있게 됩니다.
Hourglass 네크워크는 두 가지 변형된 버전인 Hourglass-88, Hourglass-57을 사용하였습니다. Hourglass-88은 Hourglass 104에서 2개의 downsampling stage를 제거하고, 마지막에 있는 layer의 수를 절반으로 줄인 것이며, Hourglass-57은 각 layer의 수를 절반으로 줄인 것입니다.
2.2 Character Branch
현존하는 RNN 기반의 recognition 방법론들은 흔히 word-level로 학습하기 위해서는 sequential model을 사용해 왔습니다. 이렇게 순차적으로 단어를 처리하는 방식은 character를 분류하는 것에 비해 더 넓은 search space를 필요로 했죠. 예를 들자면 “hello”라는 단어가 있을 때 RNN 기반 recognition 방법론은 “h”부터 “o”까지 순차적으로 처리를 해야 했지만, 문자를 분류하는 방식(character classification)은 영어 알파벳의 경우 26개의 문자만 고려하면 되기 때문이라고 할 수 있겠습니다. 이런 RNN 기반의 방식으로 인한 넓은 search space는 모델을 복잡하게 만들고, 많은 양의 train dataset을 필요로 하기 때문에 학습 시간도 오래 걸리게 됩니다.
하지만 최근 연구에서 RNN 기반 방법의 성능을 개선하기 위해서 character level의 attention을 도입하는 방법이 등장하였습니다. 이러한 attention 방식은 character의 strong한 정보들을 명시적으로 encoding할 수 있도록 도와줍니다. 즉, 각 character의 문자에 가중치를 부여해서 중요한 character를 강조하고 모델이 더 정확하게 character를 식별할 수 있도록 돕는 것이죠. 이러한 attention 방식을 도입함으로써 search space가 줄어들어 모델을 더 빠르게 학습시킬 수 있었고 성능 향상도 이뤄낼 수 있었습니다.
여기서 알 수 있는 점은 character의 정확한 식별이 RNN 기반의 text recognition에서 매우 중요하다는 것이젰죠. 본 논문의 저자들은 이 점에 영감을 받아 자동으로 character의 위치를 파악하면서, character단위로 recognition하는 방식을 가져갑니다.
이를 위해서 저자는 새로운 character branch를 도입했는데, 이 character branch는 character를 직접 detect하고 recognize하는 기능을 가지고 있습니다. character를 기본 단위로 사용하며, output으로는 char level의 bbox와 함께 그에 해당하는 character label가 있습니다.
구체적으로, character branch는 여러 convolution layer들로 이루어져 있으며, backbone 네트워크의 마지막 feature map 위에서 densely하게 이동합니다. 또, input feature map은 입력 이미지의 1/4 크기의 spatial resolution을 가집니다.
이 character branch는 3개의 sub-branch를 가지고 있습니다. 각 sub-branch는 아래와 같습니다.
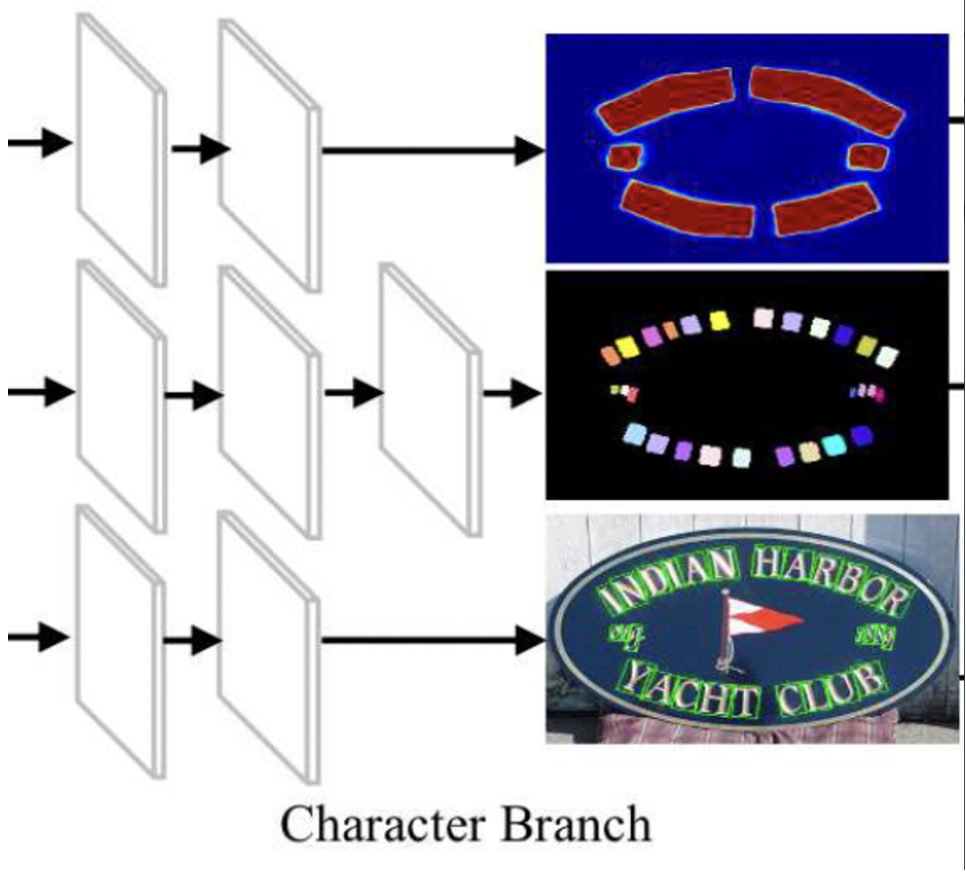
- text instance segmentation
- character detection
- character recognition
[1]text instance segmentation sub-branch와 [2]character detection sub-branch는 3개의 convolution layer를 가지며 각 filter 사이즈는 각각 3×3, 3×3, 1×1입니다. [3] character recognition sub-branch은 4개의 convolutional layer로 구성되어 있으며, 3×3 필터 사이즈를 가지는 convolution layer가 하나 더 추가된 것입니다.
각 sub-branch의 역할과 output은 다음과 같습니다.
먼저 [1]text instance segmentation sub-branch는 텍스트 영역을 바이너리 마스크를 이용해서 text 영역을 나타냅니다. output으로는 각 위치마다 text인지 text가 아닌지의 확률을 나타내는 2 channel입니다.
[2] character detection sub-branch는 character level의 bbox를 예측하는데, output으로 5 채널의 feature map이 나옵니다. 이 부분은 text detection 방법론인 EAST: An Efficient and Accurate Scene Text Detector 논문에서 소개된 방법과 같습니다.
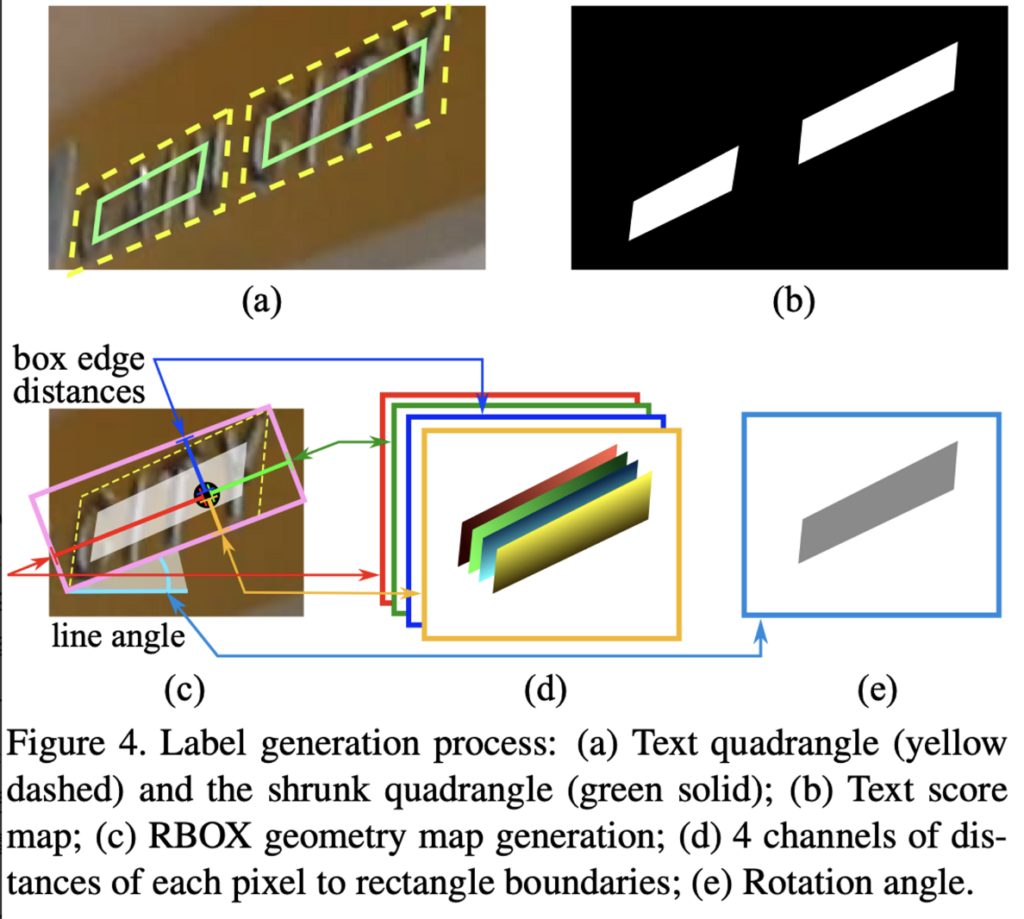
이 그림이 EAST 논문에 실려있는 그림입니다. 본 논문의 character detection sub-branch의 output으로 나오는 5개의 channel은 (d)+(e)부분입니다. 4개의 채널은 (d)에서 살펴볼 수 있는데, 이는 현재 위치에서 직사각형 경계(box의 네 변)와의 거리를 나타냅니다. 예를 들어 첫번째 채널은 character box 윗 변과의 거리, 두번째 채널은 오른쪽 변과의 거리 .. .. 가 되겠습니다. 그리고 마지막 1개의 채널은 그림(e)과 같이 rotation angle 정보를 담고 있습니다. 이는 character bbox의 orientation 정보와 같은 것으로 생각하면 되겠습니다.
마지막으로 character recognition sub-branch는 input feature map위에서 densly하게 character 라벨을 예측하는 부분이며, output으로는 68채널의 확률 map을 출력합니다. 68개의 확률 map은 각각 68개의 문자 클래스에 대한 확률 맵입니다. (영어 – 26개, 숫자 – 10개, 특수 기호 – 32개)
이 세 가지 sub-branch에서 출력된 feature map들은 모두 같은 resolution을 가지고 있고, 입력 feature map과 동일한 크기 (input image의 1/4)를 가집니다. 마지막으로 character detection sub-branch에서 생성되는 bbox는 confident value가 0.95 이상인 bbox만을 남기고 이렇게 남겨진 bbox에는 해당하는 라벨이 다 있습니다. 이 label은 character recognition sub-branch에서 output으로 나오는 68개의 channel에서 문자가 있는 해당 위치에서 softmax를 계산했을 때 가장 큰 값이 나오는 것으로 선택되겠습니다.
이 character branch를 학습할 때는 char-level의 bbox와 그에 상응하는 character label이 함께 필요하게 됩니다. 계속 말해왔듯이 word-level의 어노테이션과 비교했을 때 char-level의 라벨을 얻는 것은 굉장히 힘든 일이죠. 이 추가적인 cost를 피하기 위해서 저자들은 iterative character detection 방법을 개발하였습니다. 이는 아래에서 자세히 다루도록 하겠습니다.
2.3 Text Detection Branch
방금까지 character branch의 구조를 알아봤으며, 이제 이와 병렬적으로 수행되는 text detection branch에 대해 알아봅시다.
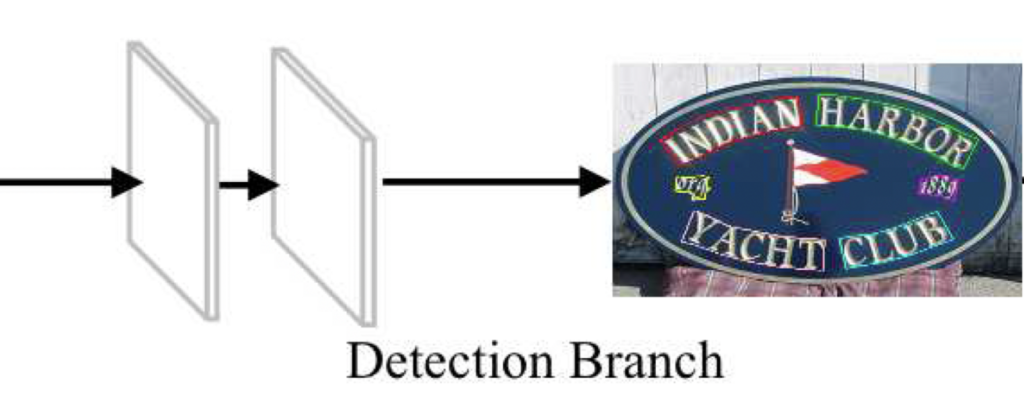
Text detection branch는 단어 혹은 text line과 같은 text instance를 식별하는 데 사용됩니다. 이는 detect된 character를 하나의 text로 그룹화하는데 사용되는 강한 context 정보를 제공하는데, 여러 text들이 가깝게 위치한 경우나, 다양한 방향을 가지거나, 곡선 모양일 경우에는 character만을 이용해서 그룹화하기에는 복잡하기 때문이죠. 이 text detection branch는 text의 유형에 따라 (multi-orientation text인지, curved text인지에 등에 따라) 다른 형태로 구성됩니다. multi-orientation word나, curved된 text line을 검출하는 예시를 아래에서 알아봅시다.
Multi-Orientation Text
여러 방향을 가지는 text를 검출할 때입니다. 앞에서 잠깐 언급했던 EAST detector를 여기서도 수정하여 사용하였습니다. 이 EAST detector는 두 개의 sub-branch를 포함하고 있는데, 첫 번째 sub-branch는 text instance segmentation sub-branch와 IoU loss를 이용한 instance level의 bbox regression입니다. 예측된 bbox에 대해서 위에서 말한 4가지의 거리 정보와 1가지의 방향 정보를 담고 있는 output을 얻을 수 있겠죠. 이를 얻기 위해서 2개의 3×3 convolution layer를 거친 뒤 1×1 conv layer를 거칩니다. 이를 거친 후에 text detection branch의 output으로는 텍스트인지 텍스트가 아닌지에 대한 확률을 담고 있는 2채널의 feature map이 나오게 되며, 방향 각도를 포함한 bbox에 대한 정보를 담고 있는 5채널의 detection map이 나오게 됩니다. 검출된 bbox중에서는 confident value가 0.95이상인 것만 선택하여 최종 text 영역을 얻어냈다고 합니다.
Curved Text
다음으로 곡선으로 되어 있는 text입니다. Textfield 방법론에서 소개한 방법론에 direction field라는 것을 더해서 사용했다고 하는데, 사실 textfield논문을 읽지 않아 해당 모델 동작 과정같은 것은 잘 모르겠습니다만 . . 아무튼 여기서 direction field라는 것은 이미지에서 픽셀의 방향 정보를 나타내는 것이며, text 경계에서 멀어지는 방향정보를 인코딩 하여 두 인접한 text instance들을 분리하는데 사용된다고 합니다. 또,,, 아까 text detection branch와 character branch를 병렬로 수행할 수 있다고 했는데,마찬가지로 이 direction field도 병렬처리가 가능하다고 하네요.. 이 branch는 두 개의 3×3 conv layer와 1×1 conv layer로 구성되어 있습니다.
Generation of Final Results
이 text detection branch에서 예측된 instance level의 bbox들은 character branch에서 생성된 character들을 text instance로 그룹화하는데에 사용됩니다. 이 과정에서 간단한 룰이 적용되는데, 만약 character의 bbox가 instance level의 bbox와 겹치는 부분이 있다면(IoU > 0) 그 문자를 해당 text instance에 할당하는 것입니다. 이렇게 하면 최종적으로 CharNet의 output으로는 text instance와 그에 대항하는 문자들의 bbox, 그리고 character label들로 이루어지게 되겠습니다.
2.4 Iterative Character Detection
본 모델을 학습하기 위해서는 char-level, word level의 bbox 그리고 그에 상응하는 character label까지 필요합니다. 하지만 char-level의 bbox를 얻기에는 너무 힘들고 ICDAR2015, Total-Text같은 데이터셋도 이를 제공하고 있지 않습니다. 그래서 본 저자는 Synth800k와 같은 합성 데이터셋을 이용하여 model이 character를 감지할 수 있는 능력을 반복적으로 학습하는 방법(iterative character detection)을 개발하였습니다. 합성 데이터를 활용하면 char level의 정보든, word level의 정보든 제한없이 생성할 수 있기에 실제 real world 이미지의 text instance(word-level)의 어노테이션만을 이용하여 weakly supervised 방식으로 학습할 수 있게 됩니다.
일반적인 방법으로는 합성 이미지를 사용해서 모델을 직접 학습한 후, real world 이미지를 가지고 inference를 수행하는 것인데, 이렇게 하게 된다면 합성 이미지와 실세계 이미지 간의 큰 도메인 차이가 발생하게 됩니다. 그렇기에 합성 데이터셋으로부터 학습한 모델을 real world 이미지에 직접적으로 사용하기는 어렵습니다.
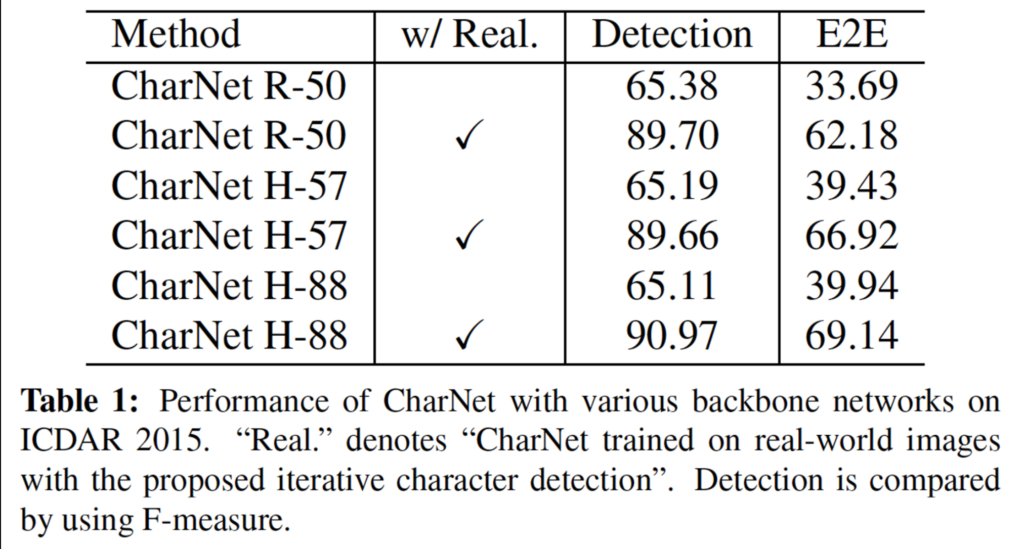
위 [Table1]을 보시면, w/Real에 체크표시가 되어있는 부분이 저자가 제안한 iterative character detection으로 real-world image를 학습에 사용한 경우입니다. 체크표시가 되어 있지않은, 즉 real-world 이미지는 학습에 사용하지 않고 inference에 직접적으로 적용하게 된 경우는 Detection과 E2E 둘 다에서 성능이 많이 낮은 것을 볼 수 있습니다.
본 논문에서는 text detector가 recognizer보다 일반화 능력이 상대적으로 강한 것을 관찰하였는데, 예를 들어 영어와 중국어 데이터만 사용하여 학습한 text detector가 다른 언어에서도 상당히 잘 작동하는 것을 볼 수 있었습니다. 이를 바탕으로 본 논문에서는 text detector의 일반화 능력을 real world image와 synthetic 이미지 간의 도메인 차이를 줄이는데 사용하고자 하였습니다.
그러기 위해서, 처음에는 char-level의 어노테이션을 제공하는 합성 데이터셋을 학습을 한 후에, real world 이미지에서도 점차 “correct”한 character level의 bbox를 예측할 수 있도록 모델 자체를 학습하는 과정을 거칩니다.
이를 위해 간단한 rule을 사용하는데, text instance 내의 character bbox수가 instance level의 text label 수와 정확히 일치하는 경우 해당 character level의 bbox 그룹을 “correct”한 bbox로 판단합니다. 예를 들자면 “hello”라는 5개의 글자로 구성된 단어가 있을 때 이를 5개의 character box로 예측을 했다면 correct한 경우라고 판단할 수 있겠죠.
정리하자면, 본 논문에서 제안하는 iterative한 character detection 과정은 아래와 같습니다.
(1) 먼저, 합성 데이터셋에서 초기 모델을 학습합니다. 합성 데이터에는 char-level과 text instance level의 어노테이션이 모두 제공되고 이를 가지고 CharNet을 학습합니다. 그 다음 학습한 모델을 real-world 이미지에 적용합니다. 이렇게 하면 모델이 real-world 이미지에서 character level의 bbox를 예측하게 되겠습니다.
(2) 다음으로, 좀 전에 언급한 Rule을 활용하여 real-world 이미지에서 검출한 “correct”한 char-level의 bbox를 모읍니다. 이렇게 모든 “correct”한 bbox를 가지고 모델을 더 학습시키게 됩니다. 이 때, 완전히 “correct”하지 않은 것들은 성능 저하를 가져오기 때문에 학습에 사용하지 않습니다.
(3) 앞의 과정들을 반복적으로 수행합니다. 이를 통해 character detection 성능이 점진적으로 향상됩니다. 학습해 나갈수록 더 많은 “correct”한 char-level의 bbox가 생성된다는 것이겠죠.

위 그림에서 점진적인 성능 향상을 확인할 수 있습니다. 빨간색 박스들이 rule에 의해 결정된 “correct”한 박스들이며, 파란색은 correct하지 않은 것들입니다. 왼쪽에서 오른쪽으로 가면서 반복적인 학습을 수행한 결과인데, 보시다시피 처음에는 파란색 박스들로 잘 box 예측을 못하다가 점진적으로 잘 해나가는 모습을 볼 수 있습니다.
3. Experiments, Results and Comparisons
실험단에서는 ICDAR2015, Total-Text, ICDAR MLT 2017 세 데이터셋을 사용하였습니다.
- ICDAR 2015
- 1000개 학습이미지, 500개 테스트 이미지
- multi-orientated, 아주 작은 텍스트가 데이터셋에 많이 존재함
- Total-Text
- 1255개 학습 이미지, 300개 테스트 이미지
- 수평, 다중 방향 및 곡선 형태의 다양한 텍스트 유형이 들어있음
- ICDAR MLT 2017
- 대규모 다국어 텍스트 데이터셋 (9개 언어)
- 7200개의 학습 이미지, 1800개의 테스트 이미지
CharNet은 학습할 때 합성 데이터와 real-world 데이터를 모두 사용합니다. 본 CharNet이 제안한 iterative character detection은 4번의 반복적인 단계를 이용하여 구현되었습니다. 첫 번째 단계에서는 CharNet을 합성 데이터인 Synth800k로 5 epoch동안 학습하였습니다. 나머지 세 단계는 real-world 데이터를 사용하여 각각 100, 400, 800 epoch동안 학습합니다. 이러한 방식으로 합성 데이터와 실제 세계 데이터를 반복적으로 사용하여 학습하면 각 단계에서 성능을 점진적으로 향상시킬 수 있습니다.
3.1 On Iterative Character Detection
iterative character detection은 text instance-level의 어노테이션만 가지고 있는 real-world 이미지로 학습을 가능하게 합니다. 여기서는 character를 정확히 식별하는 것이 성능에 영향을 많이 미치게 됩니다. 본 논문에서는 다양한 backbone Network를 사용하여 ICDAR2015에서 CharNet의 iterative character detection 능력을 평가하였습니다.
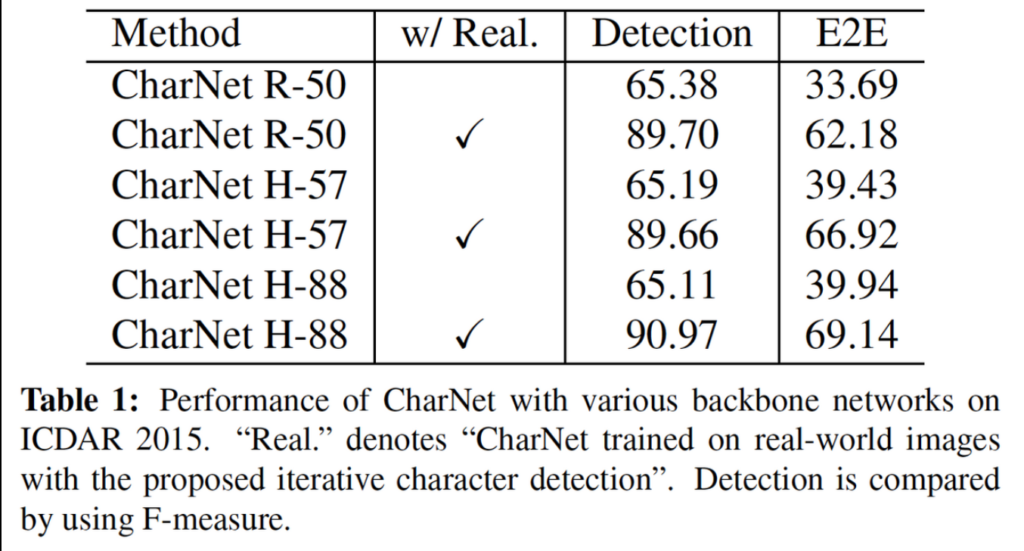
위에서 한 번 언급했던 표입니다. 가볍게 다시 보자면, 합성 데이터로 직접 학습한 모델을 바로 ICDAR 2015 테스트 이미지에 적용하면 text detection과 E2E 둘 다에서 성능이 낮습니다. 이는 두 데이터셋 간의 큰 도메인 간격 때문이죠.
또한 논문에서는 모델이 rea-world 이미지에서 “correct”한 character를 식별하는 능력에 관한 실험을 TotalText 데이터셋에서 추가적으로 진행하였습니다. 이 실험에서 “correct”한 character들은 단어로 묶이고, 각 iterative 단계에서 식별된 “correct” 단어의 수를 계산합니다.
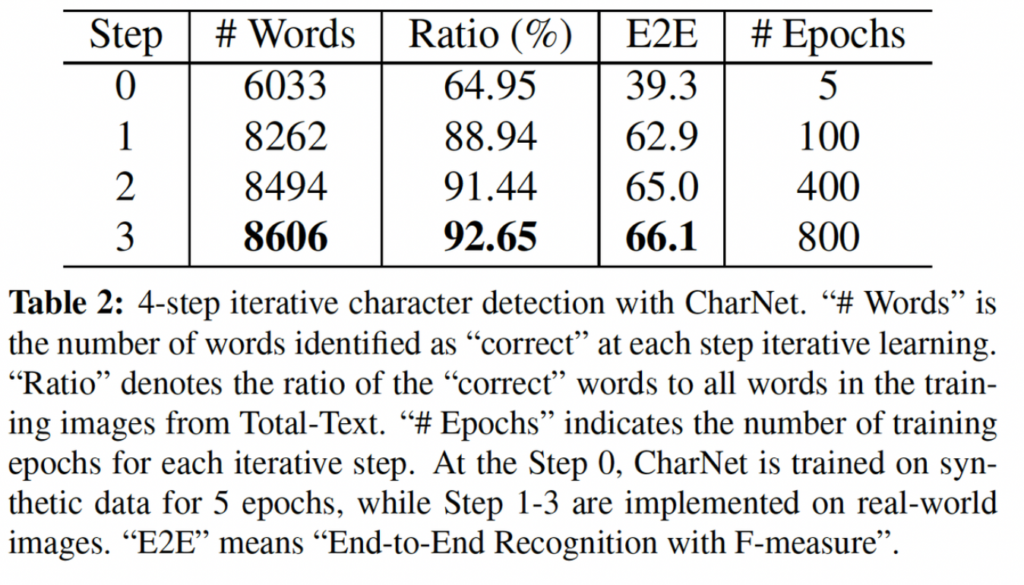
[표 2]에 나타난 바와 같이, step 0에서는 CharNet이 합성 데이터만을 사용하여 학습한 경우인데, real-world의 64.96%의 단어만이 “correct”하게 식별되었습니다. 여기서 흥미로운 점은 real-image도 학습에 사용하는 step 1에서 바로 64.95%에서 88.94%로 “correct”하다고 판단된 단어들이 상당히 늘어난다는 점있니다. 마찬가지로 E2E에서도 39.3에서 62.9로 늘은 것을 확인할 수 있죠. 마지막 4단계의 iterative을 통해서 92.65%의 “correct” 단어를 얻을 수 있습니다. 이 결과를 통해 모델이 학습할 때 스스로 생성한 character 수준의 어노테이션 수가 CharNet을 학습하는데 충분하다는 결론을 내릴 수 있겠습니다.
3.2 Results on Text Detection & E2E
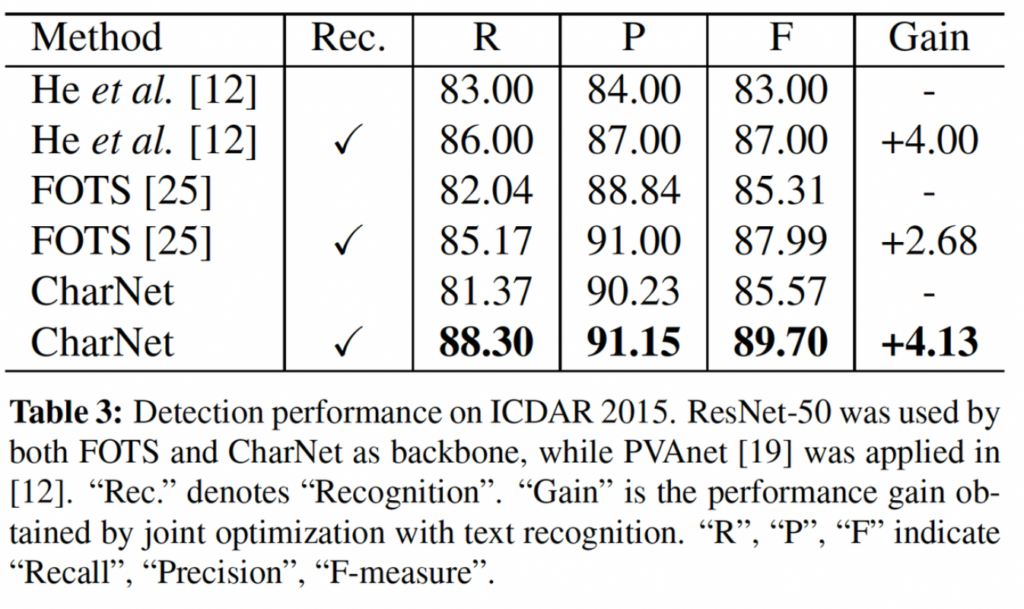
FOTS와 공정한 비교를 하기 위해 동일한 백본인 ResNet50을 사용하였습니다. R, P, F는 각각 Recall, Precision, F-measure입니다. 여기서 볼 점은,, Rec부분이 recognition과 함께 모델을 학습시킨 것인데, Recognition을 학습에 사용했을 때 CharNet은 F-measure가 85.57%에서 89.70%로 4.13%향상된 점을 볼 수 있는데, 이는 FOTS의 2.68%의 성능 향상보다 더 크다는 점입니다. 이 점은 본 1 stage 모델 CharNet이 text detection과 recognition을 더 효과적으로 협력하며 작동하고 있다고 볼 수 있겠습니다.
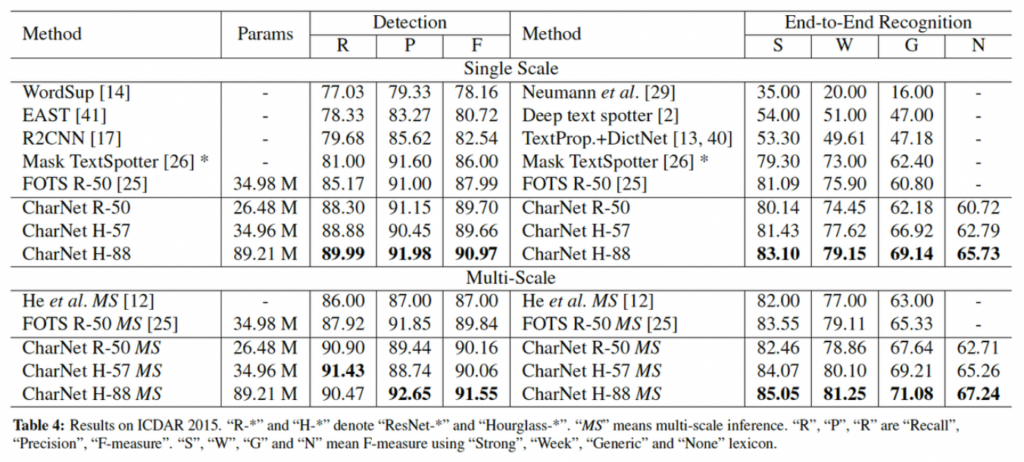
ICDAR 2015 데이터셋에 대해 SOTA를 달성하였습니다.
E2E에서 S, W, G의 의미는 각각 Strong, Weak, Generic인데, 이 데이터셋은 “Strong”, “Weak”, “Generic”이라는 3가지 사전(lexicon)을 제공합니다. “Strong”은 이미지당 100개의 단어를 제공하며 이미지에 나타나는 모든 단어를 포함한 사전이며, “Weak”는 전체 test set에 있는 모든 단어가 포함되어 있습니다. 마지막으로 “Generic”은 9만개의 단어를 가지고 있습니다.
E2E에서 CharNet은 Mask TextSpotter와 거의 비슷한 성능을 보이는데, 하지만 Mask Textspotter은 real-world 이미지에 대해 weighted edit distance를 적용하여 성능을 향상한 결과입니다. 또 CharNet은 FOTS에 비해 Generic에서 1.38%의 성능 향상을 보이는데, FOTS는 6.31M의 parameter를 사용하는 무거운 모델이지만 CharNet은 그에 비해 가벼운 모델입니다.
CharNet은 lexicon 즉, 단어 사전 없이도 신뢰성 있게 작동하며, 60.72%의 성능을 보이는데 이는 generic한 lexicon을 사용하는 FOTS의 성능과 비교가능한 수준으로 볼 수 있습니다. 이러한 점은 lexicon을 항상 사용할 수 없는 real-world에서의 응용에 더 적합하다고 보면 됩니다.
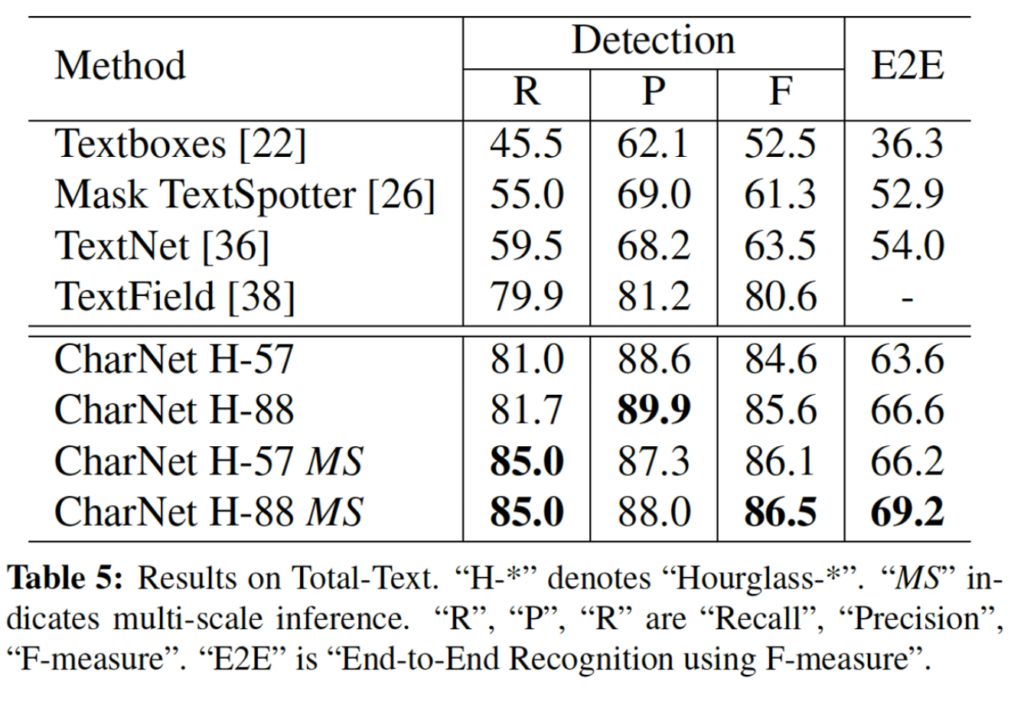
CharNet은 character를 기본 단위로 사용하도록 하였기 때문에 곡선 텍스트에 쉽게 적응할 수 있습니다. 보시면 여러 다양한 형태의 text를 포함하고 있는 total-text dataset에 대해 detection, E2E 둘 다에서 성능이 가장 좋은 것을 확인할 수 있네요.
리뷰 잘 읽었습니다.
우선 시작 전에 2.1 Overview 에서 글자, 단어, 문자, 텍스트, Instance, Character, word 등 뭔가 유사한 의미를 지니는 듯한 단어들이 서로 다르게 표기되어서 읽을 때 헷갈렸던 거 같습니다. 다음부터는 하나로 (영어면 좋을듯!) 통일 부탁드립니다.
그리고 질문이 몇가지 있는데
1. instance level 의 bounding box라는게 어떤걸 말하는건가요? 제가 아는 word gt bbox 라고 생각하면 되나요??
2. 또한 Hourglass 를 처음 들어보는데 무슨 역할을 하는 녀석인가요? 백본인가요 아니면 특정 모듈인가요?? 구조와 역할이 궁금합니다.
3. S, W, G가 lexicon을 구성하는 word의 수에 따라 다르게 구성되는건 알겠습니다. 그런데 이 lexicon 이라는 녀석이 평가 시에 어떻게 적용되는지 설명해주실 수 있나요??
++ 부가적으로 2.2 Character Branch 의 그림 중 EAST 에서 가져온 그림-(b) 의 binary mask에 대해서 한가지 말씀드리고 싶습니다. 윤서님의 FOTS 리뷰를 읽어보니 text quadrangle과 이를 축소시킨 shrunk quadrangle, 그리고 이 둘 사이 영역을 칭하는 “NOT CARE” 영역에 대한 설명이 조금 잘못 적혀져 있었습니다. 제 리뷰를 참고 하시거나, EAST 논문에 해당 부분을 자세하게 읽어보고 다시 짚어보시길 바랍니다.
댓글 감사합니다.
1. 넵 다음부터 영어로 통일하도록 하겠습니다.
2. 찾아보긴 했지만, 정확히 잘 나오지는 않아 확실하지는 않은데,, text instance는 word라고 바로 보기보다는 word를 포함하고 있는 것이라고 보면 될 것 같습니다. 단어나,, 혹은 문장으로 구성된 텍스트 데이터를 의미하는 것이 text instance인 것 같네요.
3. hourglass network는 백본으로 사용된 것입니다. hourglass 모듈은 최소 resolution을 갖도록 down sampling을 거친 후, 최소 resolution에 도달했다면 upsampling하여 원래 입력 크기로 복원하는 모듈입니다. 마치 모래시계와 같이 생겼다고 하여 hourglass라고 불리는 것으로 알고 있습니다.
4. 모델이 예측한 결과 중에 lexicon에 속하는 단어를 찾은 다음 이 단어가 gt와 일치하는 것인지 확인함으로써 평가에 사용될 수 있습니다. 제가 알고 있는 metric같은 경우에는 WEM과 1-NED가 있는데, WEM같은 경우는 Word based Exactly Matchin의 약자로 모델이 예측한 단어가 lexicon에 있는 단어와 완전히 일치하는 경우에만 맞은 것으로 판단하는 것입니다. 글자 하나라도 틀리게 된다면 0, 모두 일치한 경우에만 1의 score를 가져갑니다.
또, NED는 Normalized Edit distace의 약자로 edit distance 기반으로 모델이 예측한 단어와 lexicon에 있는 단어 간의편집 거리(변경, 삽입, 삭제.. 등)를 계산하여 얼마나 적은 획수의 편집으로 gt에 도달할 수 있는지 최소 거리를 측정한 후, 긴 단어의 길이 (gt or pred 중 긴거로) 정규화하여 이 score를 1에서 뺀 값을 사용하는 것입니다. 간단하게 두 문자열 사이의 유사도를 판별하는 방법이라고 생각하면 되겠습니다.
5. 넵 ! 참고하여 다시 읽어보도록 하겠습니다.