제가 이번에 리뷰할 논문은 T-LESS라는 6D Pose Estimation관련 논문으로, 해당 데이터 셋은 생산 과정에 필요한 CAD모델과, texture 정보를 포함하도록 reconstruction을 수행하여 얻은 3D 모델을 제공합니다. Toy 6D 데이터 셋을 구축하고자 하고 있으며, 데이터 셋을 구축하기 위해 어떤 것들을 고려해야하며, reconstructed 3D 모델은 어떻게 생성하는 지 정리하기 위해 해당 논문을 리뷰하게 되었습니다.
Abstract
해당 논문은 industry와 관련된 30개의object로 구성된 6D Pose Estimation 데이터 셋 입니다. T-LESS 데이터 셋 카메라로부터 object의 pose정보(translation, rotation)를 GT로 가지고 있으며, 해당 데이터 셋의 경우 기존의 데이터와 다르게 몇 가지 object는 다른 object의 일부분이라는 점에서 독특한 구성을 가지고 있습니다. 2개의 RGB-D 센서와 1개의 고화질 RGB 센서로 데이터셋을 촬영하였으며, 검정 배경에서 하나의 object에 대해 촬영한 39K개의 학습 이미지와 배경이 다양하며 여러 object를 모아둔 약 10K의 test 이미지를 가지고 있습니다. 이렇게 train과 test 데이터를 다르게 한 이유는 정돈된 환경에서 수집된 데이터를 이용하여 6D Pose Estimation이 가능하도록 학습시켰을 때, 해당 모델이 실제 활용이 될 경우 얼마나 잘 작동하는 지를 알 수 있도록 두 subset의 도메인을 다르게 구성한 것으로 보입니다. 또한, 위에서 설명한 것처럼 물건을 생산하기 위헤 만들어진 CAD모델(texture-less)과 반자동방식으로 texture 정보를 포함하도록 reconstruction 된 3D 모델을 제공합니다.


Introduction
실제 세계에는 Texture-less한 강체가 많고, 이러한 object에 대한 pose 정보를 파악하는 것은, 로보틱스와 증강현실 관점에서 중요합니다. texture-less한 객체의 외관은 전체 모양과 색상, 주변 빛등에 의해 크게 영향을 받습니다. texture가 없다는 것은 local한 영역의 descriptor를 이용하는 전통적인 방식에서 잘 작동하기 어렵다는 것을 의미하며, 이에 당시의 최근 방법론은 윤곽과 depth에 의존하는 local한 3D 특징과 global한 영역의 descirptor를 이용하는 연구에 초점을 맞추고었습니다. 따라서 RGB-D 센서를 이용하는 데이터가 중요하게 되었고, 저자들도 RGB-D 센서를 이용하여 데이터를 취득하였습니다.
본 논문에서는 texture-less한 강체에 대한 데이터 셋을 제안합니다. 2개의 RGB-D 센서(Primesense Carmine 1.09와 Microsoft Kinect v2)와 하나의 RGB 센서(Canon IXUS 950 IS)를 이용합니다. 센서들은 동기화를 맞추어 비슷한 view-point에서 촬영하였다고 합니다. 이미지들은 object를 기준으로 반구에 해당하는 영역에서 샘플링하여 획득하였으며, 이때 train 데이터는 깔끔한 배경에서 단일 물체에 대해 촬영하였고, test 데이터는 복잡한 배경에서 여러 object들을 모아두고 촬영하였습니다. 또한, CAD 모델을 그려 생성한 3D 모델과 RGB-D 이미지로부터 반자동 방식으로 구한 3D 모델 두가지를 제공합니다.
The T-LESS Dataset
T-LESS 데이터의 특징은 다음으로 정리할 수 있습니다.
- 대량의 산업 관련 객체
- 학습 데이터: 정제된 환경(객체들 구분되어있고 검정 배경)에서 촬영
- 테스트 데이터: 복잡한 환경(20가지의 배경, 여러 물체들 모아두고 촬영하여 clutter 하고 occlusion한 상황 표현)에서 촬영
- 3개 센서의 동기화
- 정확한 6D Pose GT
- 2 종류의 3D 모델 제공
1. Acquisiont Setup

데이터 셋은 위의 Figure 3의 환경에서 촬영되었습니다. 턴테이블(이미지의 1번)이 있고, 그 위에 object를 올려 물체를 회전해가며 촬영합니다. 또한, 기울기를 조절할 수 있는 jig(이미지의 3번)에 센서를 부착하여 영상을 수집하였으며, marker field(이미지의 1번, 턴테이블 주변에 부착된 것)를 이용하여 카메라의 pose를 예측합니다. 이때 train 이미지는 낮은 고도에서 촬영해도 pose 정보를 추정할 수 있도록 하기 위해 턴테이블 측면에도 부착하였으며 배경을 검정색으로 하여 단일 object만 포착이 가능하도록 하였습니다. test 이미지를 촬영할 때는 다양한 배경을 제공하기 위해 marker field가 가장자리에만 있는 합판을 이용하였으며, 책과 같이 다른 물체 위에 object를 배치함으로써, 고도를 다르게 제공하기도 합니다. depth 이미지는 0.53~0.92m의 범위가 되도록 하였다고 합니다.
2. Calibration of Sensors
intrinsic과 distortion 파라미터는 OpenCV 라이브러리를 활용하여 체커보드기반의 방식으로 측정합니다. depth와 RGB 이미지의 alignment를 맞추기 위해 센서 제조사의 SDK를 이용하였다고 합니다. 센서들은 동기화를 맞추었으며, marker field를 이용하여 extrinsic calibration을 수행했다고 합니다. 특히 턴테이블로부터 얻어진 물리적인 위치 정보와 marker 감지 정보를 결합하여 2D-3D correspondences를 제공하며 PnP를 통해 카메라 위치를 찾고, reprojection error가 최소화되도록 6D 포즈를 개선합니다.
3. Training and Test Images
texture-less한 object의 경우 템플릿 기반의 접근 방식을 많이 활용하며, 이를 위해 T-LESS도 전체 view를 이산화하여 모든 view-point에서의 train 이미지를 제공합니다. 85º~-85º까지의 고도를 10º 간격으로, 전체 방위각에 대해 5º 간격으로 샘플링하여 데이터를 취득합니다. 이때, (0º~-85º)까지의 고도는 object를 뒤집어서 촬영하였으며, 상하가 대칭인 객체의 경우는 5º~85º의 고도에 대해서만 영상을 취득합니다. test데이터의 경우는 15º~75º의 고도에서 촬영하여 각 장면당 7(고도 10º 간격으로 샘플링) x 72(방위 5º 간격으로 샘플링) =504장의 테스트 이미지를 촬영합니다. 또한 train 데이터의 경우 CAD 모델을 re-projection시켜 obejct외의 영역은 모두 검정색이 되도록 하였다고 합니다.(marker field가 보일 경우 이를 지움)

train과 test 이미지 예시. 3개의 센서에서 촬영한 데이터를 나타냄.
4. Depth Correction
기존 연구에 따르면, RGB-D 센서에 의해 측정된 depth에서 오류가 포함되어 이를 제거하기 위해 marker의 모서리를 투영시켜 예상되는 depth값 d_e를 계산합니다. 저자들에 따르면 보정된 depth값d_c은 선형식을 이용하여 구할 수 있다고 합니다.
- Carmine: d_c=1.0247 · d - 5019
- Kinect: d_c=1.0266 · d − 26.88
이와같이 depth를 보정할 경우 mean absolute 오차가 12.4mm에서 2.8mm(Carmine), 7.0mm에서 3.6mm(Kinect)로 줄어들었다고 합니다.
5. 3D Object Models

T-LESS 데이터 셋은 수동으로 생성한 CAD모델과 반자동 방식으로 reconstruction한 3D 모델을 모두 mesh 형태로 제공합니다. 이에 대한 예시는 위의 그림 Figure 5를 참고해주세요. reconstruction 모델은 3D 체적을 측정하는 시스템인 fastfusion**방식을 이용하여 생성하였으며 Carmine의 RGB-D 이미지와 그에 대응되는 camera pose를 입력으로 합니다. 상부에 대한 3D 모델과 하부에 대한 3D 모델을 만들어서 ICP 알고리즘을 이용하여 두 부분을 정렬시켜 Reconsturcted model을 생성합니다.
이때 플러그의 폴 부분과 같이 반사가 심한 영역에 대해서는 reconstruction을 수행하지 않습니다.
**F. Steinbr¨ucker, J. Sturm, and D. Cremers. Volumetric 3D mapping in real-time on a CPU. In ICRA, 2014.
6. Ground Truth Poses
test데이터의 GT Pose를 얻기 위해, 우선 recontructed 3D model을 생성하고, CAD object mode이 이미지에 대해 수동으로 alignmet를 맞춰줍니다. 여기에 보다 정확한 pose 정보를 제공하기 위해 RGB 센서에서의 이미지로 3D 모델을 렌더링하여 pose가 바르게 refinement 되었는지를 이미지와 비교하여 오차를 측정합니다. 이 과정을 반복하여 보다 정확한 GT pose를 구하도록 합니다.
Design Validation and Experiments
GT Pose의 정확도를 제시하고 당시의 6D loclization 방법론이 T-LESS에서 어떤 어려움이 있는지 확인합니다.
1. Accuracy of the Ground Truth Poses
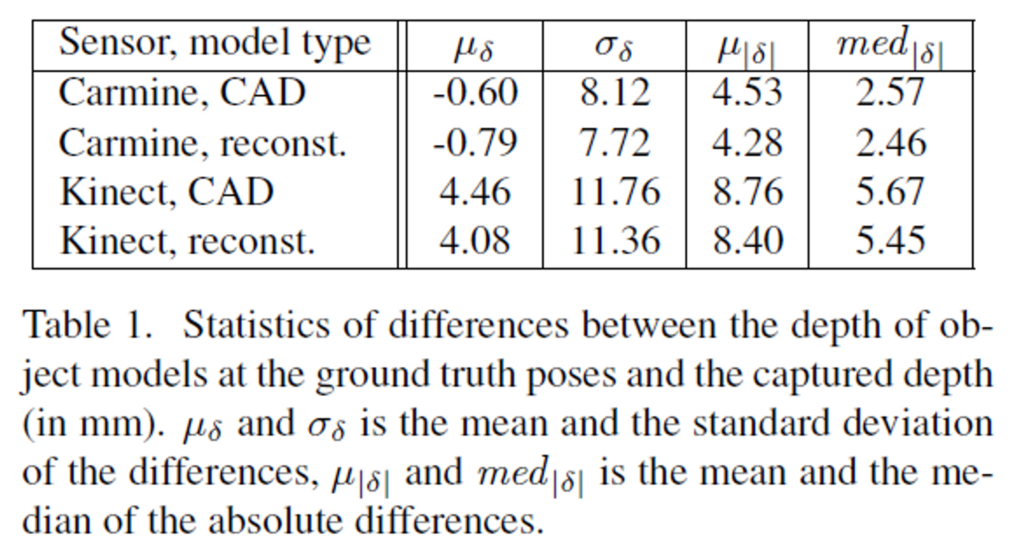
Pose 정확도 측정을 위해 depth 보정을 수행한 후, 캡쳐된 depth 이미지 d_c를 GT Pose에서 3D 모델을 렌더링하여 얻은 depth 이미지d_r와 비교합니다. train과 test 모두에 대한 두 depth의 오차δ = d_c - d_r는 Table 1을 통해 확인이 가능합니다.
Carmine 센서에 대한 오차 평균\mu_{\delta}은 거의 0에 가까우며, Kinect에 대한 오차 평균이 다소 크다는 것을 확인할 수 있습니다.
2. 6D Localization
템플릿 매칭 방식을 이용하는 방법론***에 대하여 6D Pose를 추정하여 T-LESS 데이터의 성능을 확인해본 결과입니다. misalignment에 대한 오차는 모델 \mathcal{M}에 대한 GT Pose ( \bar{\mathbf{R}},\bar{\mathbf{t}} ) 와 예측된 Pose ( \hat{\mathbf{R}},\hat{\mathbf{t}} ) 에 대해 아래의 식으로 정의됩니다.
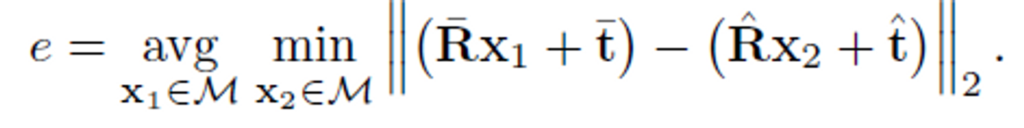
***T. Hodaˇn, X. Zabulis, M. Lourakis, ˇ S. Obdrˇz´alek, and J. Matas. Detection and fine 3D pose estimation of textureless objects in RGB-D images. In IROS, 2015.
측정된 error e는 물체의 정점들 중 가장 먼 거리의 0.1만큼을 threshold로 삼아 threshold 이하일 경우 정답으로 보는 방식으로 recall을 이용하여 평가합니다. 아래의 Figure 6이 object별로 recall을 그래프로 표현한 것입니다.
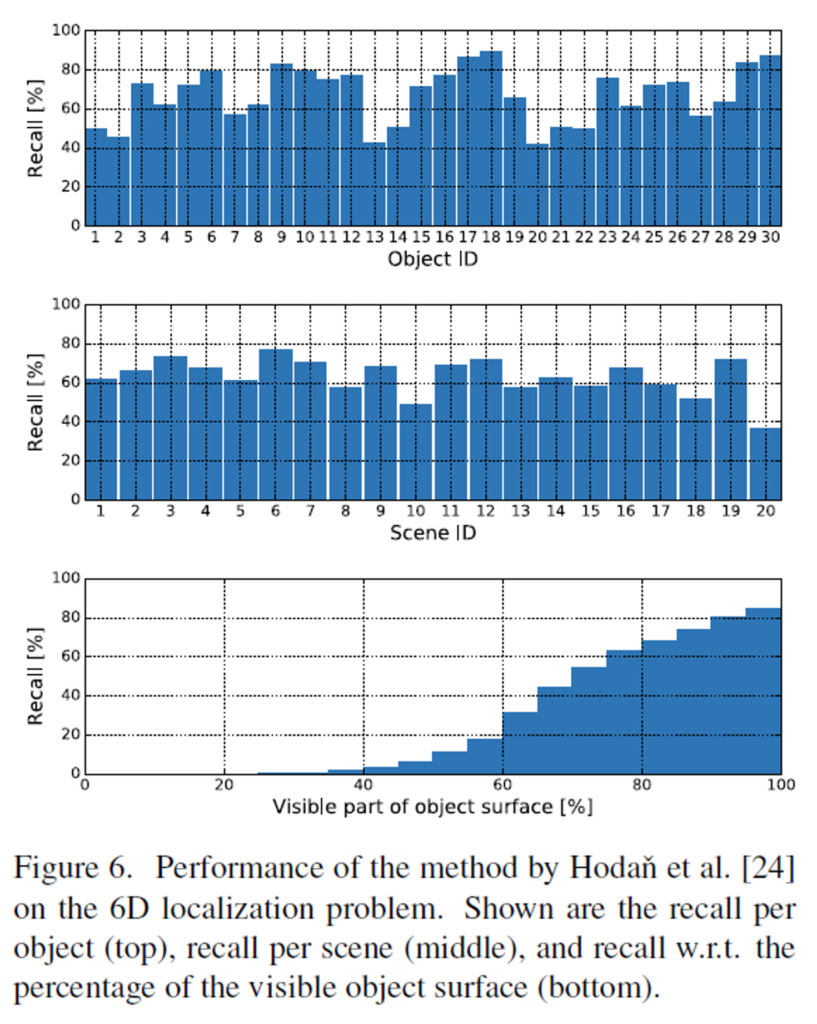


이때 Figure 6의 첫번째 그래프에서 낮은 recall을 기록한 object들은 다른 object와 유사한 object들입니다. (object 1& 2, object 20 & 21 & 22가 유사한 object들로, Figure 7에서 확인할 수 있습니다.) 또한 두번째 그래프에서 낮은 성능을 보이는 장면들은 유사한 object들이 있을 때와 occlusion이 심한 경우로, Figure 8에서 확인이 가능합니다. 또한, 세번째 그래프에서 보이는 영역이 늘어날수록 recall 성능이 비례하여 좋아지는 결과를 확인할 수 있고, 이를 통해 occlusion이 T-LESS 데이터에서 큰 문제라는 것을 확인할 수 있습니다.
모든 object에 대한 평균 recall은 67.2%로, 6D Pose Estimation에서 많이 사용되는 LineMOD가 당시에 95.4%의 평균 recall을 달성하였던것과 비교하였을 때, 여전히 6D Pose Estimation 분야의 연구가 필요하다는 것을 시사합니다.
리뷰 잘읽었습니다!
본문 내용 중 ‘ test데이터의 GT Pose를 얻기 위해, 우선 recontructed 3D model을 생성하고, CAD object mode이 이미지에 대해 수동으로 alignmet를 맞춰줍니다. 여기에 보다 정확한 pose 정보를 제공하기 위해 RGB 센서에서의 이미지로 3D 모델을 렌더링하여 pose가 바르게 refinement 되었는지를 이미지와 비교하여 오차를 측정합니다. 이 과정을 반복하여 보다 정확한 GT pose를 구하도록 합니다.’ 에 대한 구체적인 방법이 궁금합니다.
1. 어떤 방법을 이용하여 수동으로 정렬을 수행했는지
2. 3d 모델을 어떻게 영상으로 렌더링?하여 오차를 측정했는지
3. 위 방법이 보편적으로 많이 사용하는 방법이 맞는지
댓글 감사합니다.
우선 해당 부분에 대한 설명은 제가 잘못 이해하였습니다.
다시 해당 파트에 대한 설명을 드리자면,
1. 턴테이블을 이용하여 GT pose를 가지고 있음
2. CAD 모델과 reconstructed 모델의 align을 맞춰주어야 함. 이는 사람이 수동으로 진행함(30개의 object에 대해서 수동 조정)
3. Pose의 정확도를 높이기 위해 1에서 설명한 GT Pose를 이용하여 모델을 렌더링 한 후, 사람이 적절히 정렬되었는지 확인하고 조정하는 과정을 반복함.
1. 우선 해당 부분에서 scene model이라는 용어가 있어 제가 잘못 이해한 것 같습니다. 3D Reconstruction을 이용하여 복원한 모델을 scene model로 표현한 것으로 보이고, 이렇게 reconstruction을 통해 구한 3D 모델과 CAD 모델이 align이 맞도록 조정한 것을 의미하는 것으로 보입니다.(CAD 모델은 기준이 있으나 Reconstruction model은 이미지들을 모아 3D 모델을 복원한 것이므로, 임의의 기준을 가지므로 두 3D 모델의 align을 맞춰주는 과정이 필요함) 그리고 GT Pose는 턴테이블로 구성된 장치 자체에서 얻은 정보인 것으로 보입니다.
2. 3D 모델을 고해상도 영상을 촬영한 Canon에 이미지를 몇 개를 선택합니다. 그리고 나서 3D 모델을 GT Pose를 이용하여 랜더링을 한 후, 그 이미지와 비교하여 align이 맞지 않을 경우 사람이 조금씩 수동으로 조정해주는 과정을 반복하였다고 합니다. (오차를 측정한다는 말은 값이 아닌 두 이미지의 align을 비교한다고 표현하는 것이 적절한 것 같아 수정하도록 하겠습니다.)
3. 우선 2 종류의 3D 모델을 제공한 것은 이 논문이 처음인 것으로 보입니다. 따라서 두 3D 모델의 align을 맞춰주는 과정은 보편적이라고 하기 어렵다고 생각합니다. 그리고 1번에서 설명드렸 듯이 GT Pose는 턴테이블로 구성된 장치 자체에서 얻은 정보인 것이므로 GP pose로 사용하는 데 적절하다고 생각합니다. 마지막으로 더 정확한 GT를 얻기 위해 렌더링하여 수동조정하는 것은 너무 시간과 비용이 많이 들 것 같아 보편적이라 하기는 어렵고 여러 물체가 occlusion되어있기 때문에 사람이 수동으로 조정할 필요가 있었던 것이 아니까 합니다.
안녕하세요 좋은리뷰 감사합니다.
Train 데이터와 Test 데이터의 분포가 매우 다른것이 특이하네요.. 해당 분야에서는 종종 이러한 구성이 많은 듯 합니다..
제가 드리고 싶은 질문은 Depth Correction 부분인데요, RGB-D 센서에 의해 측정된 값의 오류를 제거하기 위해 marker의 모서리의 depth값을 이용했다고 이해했습니다. marker가 figure1의 판을 의미한다면, 센서의 오류는 픽셀 단위(RGB-D 센서에서도 픽셀 단위라고 표현하나요? ㅎㅎ)의 에러일 것 같은데, 픽셀 에러와 전체 판의 depth간의 어떠한 정보로 이를 보정하는지 궁금합니다.
다시한번 좋은 리뷰 감사합니다~
댓글 감사합니다.
저자들에 따르면, RGB-D 센서로부터 측정된 값은 시스템적으로 error가 포함되어있다고 합니다. 따라서 이러한 error를 제거하기 위해 알려진 마커의 좌표를 이용하여 보정하였다고 합니다. 즉, figure 3에서 확인할 수 있듯이 장치를 이용하여 pose 정보를 알 수 있으므로, 마커의 모서리가 센서까지 얼마나 떨어져있는지 depth 정보를 구할 수 있고, 이를 측정값과 비교하여 시스템적으로 얼마나 오차가 있는지를 파악하여 선형식을 통해 이를 보정하였다는 것으로 이해하였습니다.
안녕하세요, 좋은 리뷰 감사합니다.
3. Training and Test Images의 내용을 fig(4)로 설명을 하는 것 같습니다. top이 train, 아래가 bottom이 test로 되어있는데, 해당 부분에 대해 질문이 있습니다.
top 부분의 왼쪽(left), 중간(mid) 이미지의 마스킹된 영역과 depth를 각각 45도 정도로 나눈 경계가 보이는데 저렇게 각 도메인에 대해서 경계를 주는 기준(?)은 설명에서 어디에 해당하는지 궁금합니다. 또, 해당 이미지는 마스킹된 물체에 대한 정보와 depth 정보를 함께 사용하기 위한 학습 데이터 구성 방법인 게 맞는지 궁금합니다.
댓글 감사합니다.
우선 Figure 4에 대한 설명이 부족했던 것 같습니다. 45도로 나뉜 경계는, depth 이미지와 RGB 이미지를 함께 보여주기 위한 것으로 각 센서에서 캡쳐한 정보들을 콜라주하여 시각화 한 것입니다. 저렇게 절반 경계를 나누어 데이터를 구성하지는 않습니다.
또한, train 데이터의 경우 마스킹을 한 것이 아니라 촬영할 때 배경을 모두 검정색으로 하여 촬영한 것으로, figure3을 보시면 뒤에 배경도 지우기 위해 검정 판을 가져다 촬영한 것을 확인할 수 있습니다.