본 논문에서는 위치 정보 유출, 불균일한 information density를 포함하는 point cloud의 특성이 제기하는 문제를 해결하기 위해 point cloud self-supervised learning을 위한 masked autoencoder구조의 방식을 제안한다. 이게 22년도에 나온 논문인데 글을 작성하는 시점에 인용수가 113인 것으로 보아 많은 관심을 받고 있다고 할 수 있겠다. masked autoencoder를 알면 방법은 그리 복잡하지 않은데 간단히 설명하자면 input point cloud를 point patch로 나누고 높은 비율의 masking ratio로 masking을 한다. 그리고 standard transformer구조의 encoder를 통해 masking되지 않은 patch에 대한 high-level feature를 추출하여 masking된 patch를 복원하기 위한 task를 수행한다. 해당 논문이 point cloud에 mae를 적용한 첫 번째 방법은 아니지만 기존의 방법들보다 간단한 구조이며 효율적인 pre-training과정으로 다양한 task에서 좋은 결과를 보였다고 한다.
Introduction
self-supervised learning은 labeling되어있는 데이터에 덜 의존하고 데이터의 서로 다른 부분이 상호작용하는 방식을 관찰하여 latent feature를 학습한다. 해당 방식은 목적에 맞게 model을 사전학습하기 위해 pretext task라는 것을 정의하고 downstream task에서 fine-tunning하여 사용한다. 여기서 self-supervised learning의 pretext task라는 것이 어떤 것인지 명확히 받아들여지지 않아 주위에 물어보고 찾아보았는데 간단히 추가설명을 하자면 computer vision에서 self-supervised learning을 사용하는 task의 pipeline은 크게 pretext task과 downstream task로 나눌 수 있다. downstream task는 classification이나 detection을 하는 부분으로 이때 data의 annotation된 sample이 충분하지 않을 수 있다. pretext task는 downstream task에서의 시각적 표현을 학습하기 위한 self-supervised task이다. 각 pretext task에는 일부는 숨겨진 데이터가 존재하며 숨겨진 데이터의 속성을 예측하도록 학습한다. 의미만 듣고는 이해가 어려우니 예를 들자면 이미지를 patch로 나누어 어떤 patch가 어느 위치에 들어가야하는지 상대적 위치를 예측하는 task, 이미지가 얼마나 회전했는지 예측하는 task, 이미지에서의 색상을 예측하는 task 등이 해당될 수 있겠다.
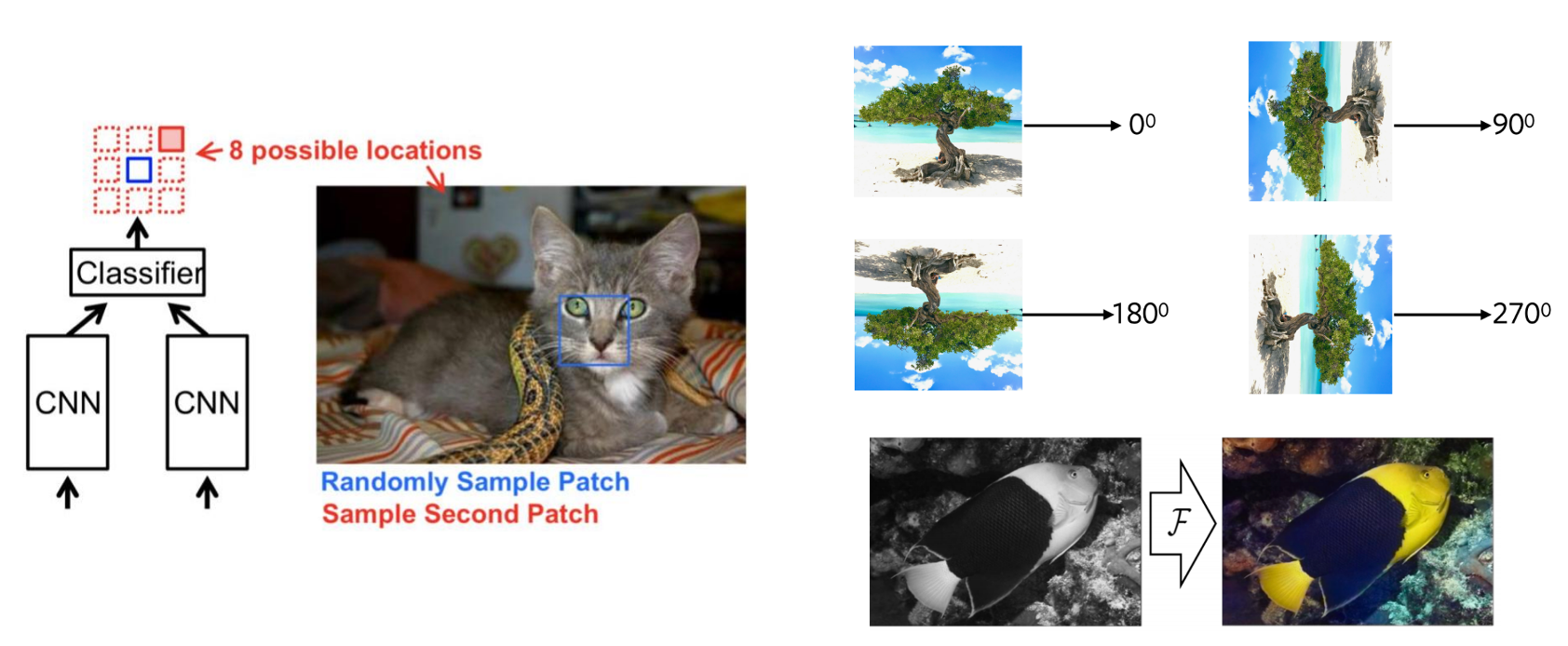
self-supervised learning은 NLP을 거쳐 computer vision에서도 많은 발전을 이뤄내고 있다. 그 중 masked autoencoding이 자연어와 image부분에서 주목받는다. 아래 Fig 1에서 보면 masked autoencoder에 대한 그림인데 input data를 random하게 masking하고 autoencoder를 통해 원래 원본에서 masking된 부분의 content에 상응하는 pixel이나 token을 복원한다.
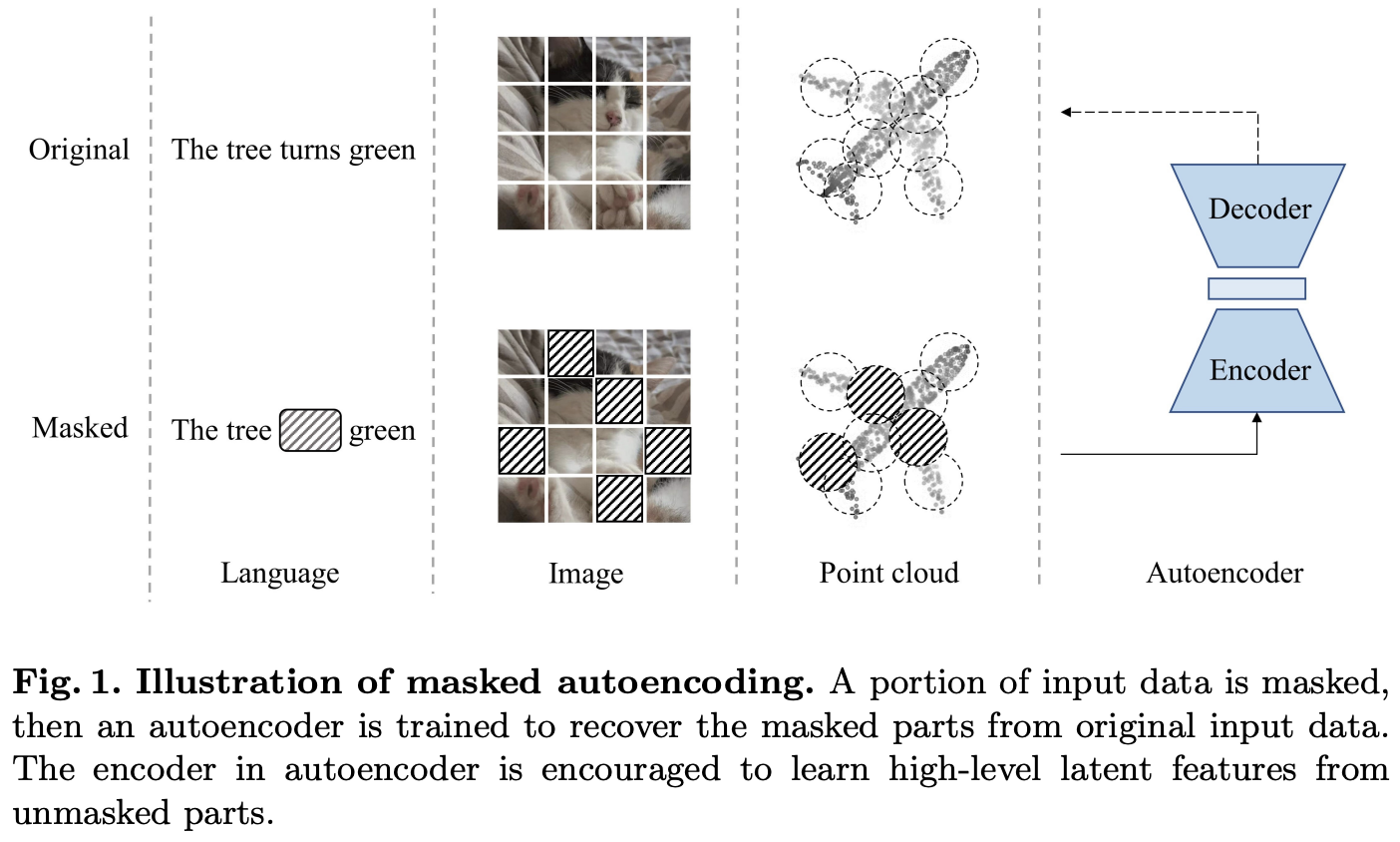
masking된 부분은 해당 데이터의 정보를 제공하지 못하기 때문에 이러한 reconstruction task는 autoencoder가 unmasked 부분으로부터 high-level의 latent feature를 학습하도록 한다. masked autoencoder의 아이디어는 point cloud self-supervised learning에서도 충분히 적용될 수 있다. language의 단어나 image의 pixel이나 point cloud의 point나 모두 독립적으로 정보를 가지는 것이 아니라 주변의 elements들이 합쳐져서 의미있는 정보를 나타내는 것이고, 이러한 local features들이 모여 또 global feature를 나타낼 수 있다. 따라서 points들도 token으로 embedding한다면 다른 language나 image와 비슷하게 처리할 수 있을 것이라는게 저자의 주장이다. 또 point cloud에 self-supervised방식을 적용한다면 autoencoder의 backbone인 transformer가 큰 데이터를 필요로 한다는 문제도 해결할 수 있을 것이다. 이전 최근에 나온 Point-BERT라는 방법론에서는 masked autoencoder를 사용하는 것과 비슷한 방법론인데 사전학습하기 전 다른 autoencoder를 추가로 학습시켜야했고 data augmentation에 큰 영향을 받았다고 한다. 또 masked token이 사전학습 시 transformer input으로 함께 들어가서 location정보가 leakage(누출)될 수 있고 많은 연산량을 요구하는 문제가 존재한다고 한다. 본 논문에서 제안하는 방법은 더 간단하고 효율적인 방법으로 masked autoencoder를 구성했다고 한다.
먼저 point cloud에 masked autoencoding을 적용하려고 할 때의 주요 challenges들을 언급한다.
1. Lack of a unified transformer architecture
NLP와 Vision Transformer와는 다르게 point cloud에서의 transformer는 많이 연구되지 않았는데 가장 큰 원인으로는 상대적으로 작은 데이터셋이 transformer의 large dataset 수요를 만족하지 못했을 것이라고 한다. 이를 해결하기 위해 복잡하거나 추가적인 transformer를 사용한 기존 방법론들과는 다르게, 저자는 standard transformer를 기반으로 autoencoder의 backbone을 구성하여 추후에 point cloud를 일반적인 multi-modality framework에도 적용 가능하도록 했다고 한다.
2. Positional embedding for mask tokens lead ot leakage of location information
masked autoencoder에서 mask된 부분은 learnable한 mask token으로 대체되고 positional embedding을 통해 location 정보를 제공한다. language나 image model에서 이렇게 location 정보를 제공하는 것은 문제가 되지 않았다. 하지만 point cloud의 경우 데이터 특성 상 poitn cloud 자체가 location정보로 되어있다보니 이렇게 location정보를 make token에 leakage(누수)하는 것이 reconstruction task를 더 쉽게 만들기 때문에 autoencoder가 high-level의 latent feature를 학습하는데 방해가 된다는 것이다. 저자는 mask token을 autoencoder의 encoder가 아니라 decoder의 input으로 shift하여 이를 해결하고자 했다. 이렇게 location정보의 누출을 늦추는 방식이 encoder가 unmasked부분에 더 집중해서 학습할 수 있다고 주장한다.
3. Point cloud carries information in a different density compared to languages and images
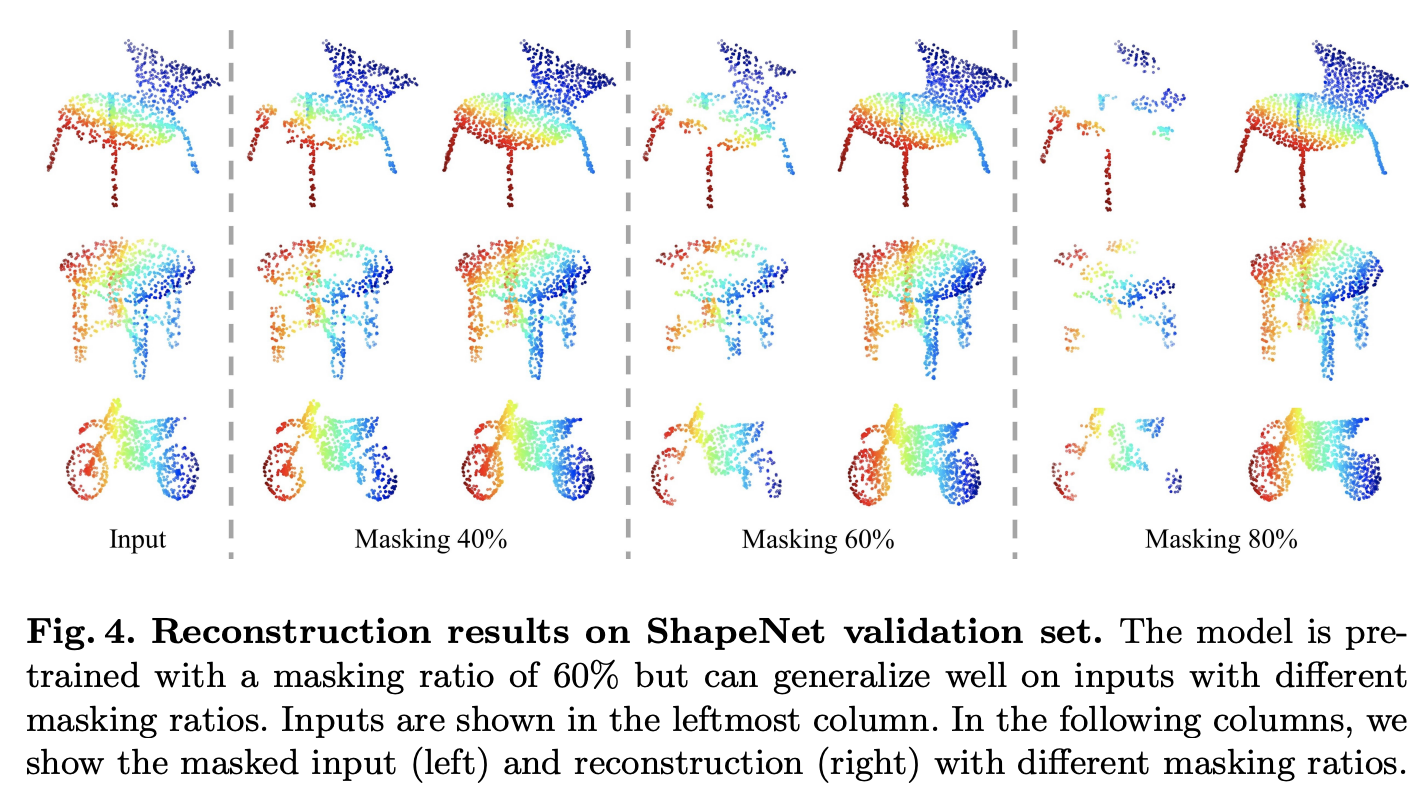
point cloud는 information density 분포가 상대적으로 고르지 못하다고 한다. 무슨 말이냐면 예를 들어 corner나 edge와 같은 key local feature는 더 높은 density의 정보를 가지지만 평평한 면과 같은 덜 중요한 local feature는 낮은 density의 정보를 가질 것이다. 다르게 말해서 만약 masking이 되었을 때 high-density information을 가지는 point가 포함되어있다면 reconstruction을 할 때 더 어려울 것이다. 아래 Figure 2에서 예시를 확인할 수 있는데 마지막 3번째 행을 보면 평평한 원형 테이블의 masking부분은 잘 복원되었지만, 오른쪽의 오토바이?에서 wheel을 보면 상대적으로 잘 복원하지 못한 것을 확인할 수 있다.
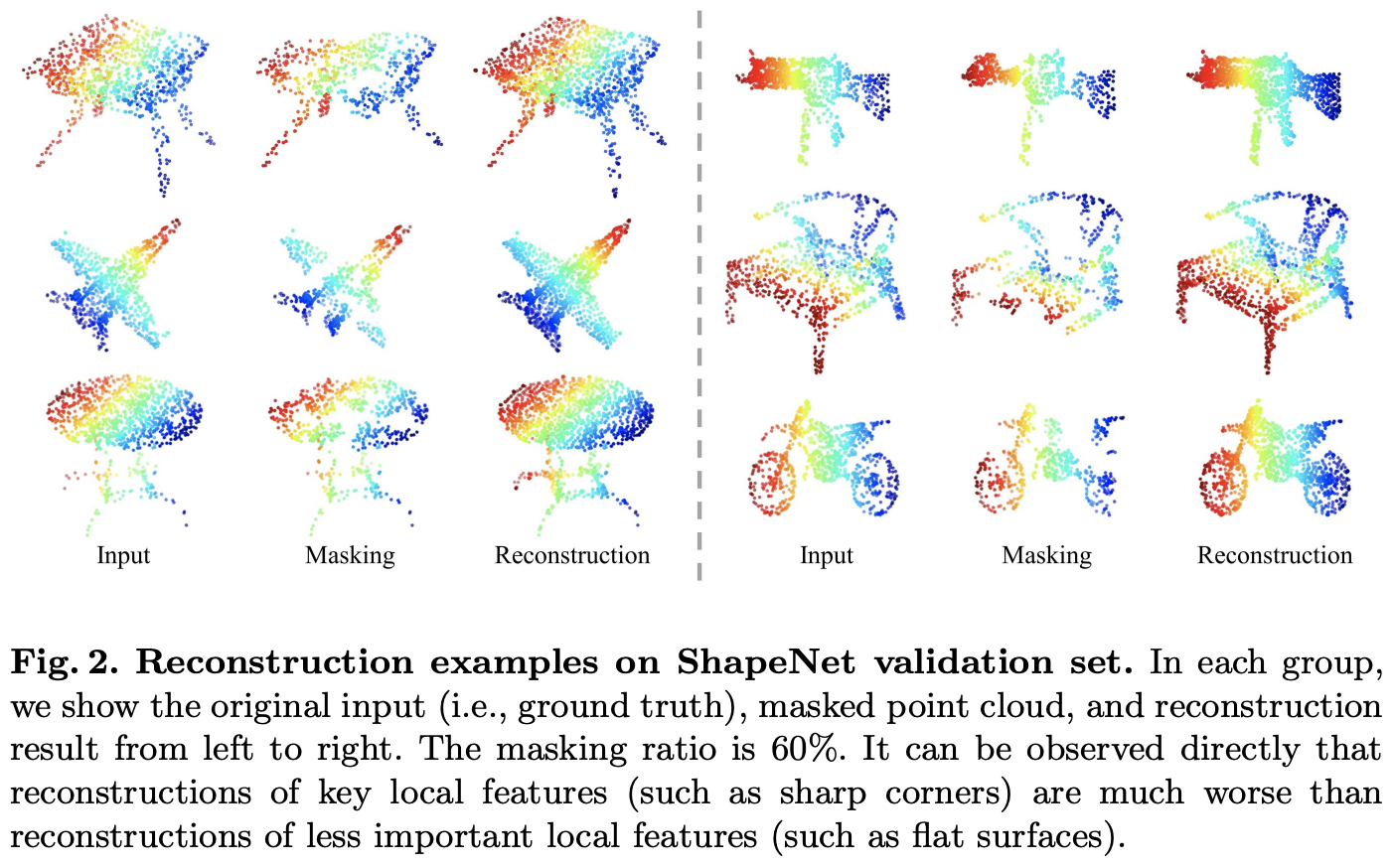
위의 그림은 60%를 masking한 것인데 random masking하는 비율이 60%~80%정도로 높은 비율일 때 잘 복원했다고 하며 이를 통해 information density에 대해서는 image에서와 비슷한 양상을 보임을 알 수 있었다고 한다.
이러한 분석결과를 토대로 Point-MAE를 제안한다. Point-MAE는 크게 point cloud masking, embedding module, autoencoder로 구성된다. input point cloud가 point patch로 나눠지며 autoencoder가 unmasked point patch로부터 high-level의 latent feature를 학습하게 된다. 여기서 autoencoder의 backbone은 standard transformer block을 사용했고 MAE와 동일하게 lightweight decoder를 사용하여 asymmetric한 encoder-decoder구조를 적용했다. 그리고 마지막에 간단한 prediction head를 통해 masking된 point patch를 복원한다.
본 논문의 contribution은 아래와 같다.
1. point cloud self-supervised learning을 위한 새로운 방식의 masked autoencoder제안하고 point cloud에 mae적용할 때 key issue addressing
2. standard transform기반의 간단한 architecture가 supervised learning에서 dedicated transformer model들을 뛰어넘음
3. multimodal learning 관점에서 masked autoencoder와 같은 통합 architecture가 modality specific한 embedding module과 head를 장착했을 때 point cloud에도 적용 가능하다는 것에 영감을 줌
Related Work
self-supervised learning
self-supervised learning의 main 아이디어는 1)사람의 annotation이 아니라 data자체로부터 supervision label을 생성하고 2)model이 data의 다른 부분으로부터 데이터 일부분을 예측하는 것이다. computer vision에서 기존의 contrastive self-supervised learning 방법론은 서로 다른 augmented image사이에서 유사도를 구별하는 것을 목표로 했고 최근의 generative self-supervised learning방법이 좋은 performance를 보여주는데 예를 들어 Masked autoencoder가 input patch를 랜덤하게 masking하고 masking된 patch를 recover할 수 있도록 model을 사전학습시켜 downstream task에 fine-tunning하여 사용한다.
기존에 point cloud에도 self-supervised learning을 적용하려는 시도가 있었다. DepthContrast, OcCo, IAE, point-BERT 등이 존재했다고 하는데 그 중 point-BERT가 가장 최근 방법으로 masking input token을 통해 다른 masking된 부분의 token을 예측하도록 했다. 이전 방법들과는 다르게 본 논문의 저자는 좀 더 간단한 구조를 통한 point cloud의 self-supervised learning을 시도했다.
autoencoders
일반적으로 autoencoder는 encoder와 decoder 구조를 가진다. encoder는 input을 high-level의 latent feature로 encoding하는 역할을 하고 decoder는 input을 복원하기 위해 encoding된 latent feature를 decode하는 역할을 한다.
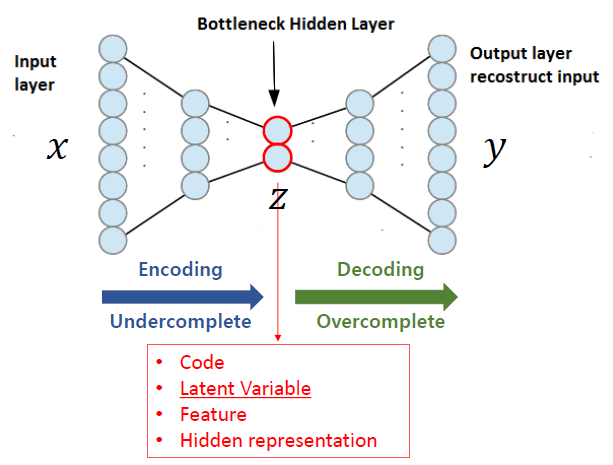
본 논문의 방식은 denoising autoencoder의 일종이라고 할 수 있는데, denoising autoencoder의 main concept은 input noise를 추가하여 model의 강인성을 향상시키고자 하는 것이다. masked autoencoder는 masking을 통해 input noise를 주는 원리하고 생각할 수 있다. masked autoencoder는 NLP, computer vision에서 image에 적용되었는데 좋은 결과를 보였고 저나는 point cloud에 masked autoencoder를 적용하였다.
transformers
transformer는 self-attention 매커니즘을 통해 input의 global dependencies를 modeling한다. transformer도 NLP에서 시작되어 computer vision에서도 큰 인기가 있다. 하지만 masked autoencoder의 backbone으로 쓰이는 transformer인데, point cloud를 위한 transformer는 연구가 잘 되지 않았었다. 저자는 standard transformer를 기반으로 전체 architecture를 설계하였다.
Point-MAE
아래 Figure 3은 본 논문에서 제안하는 Point-MAE의 전체적인 흐름 구조를 나타낸다. input point cloud가 masking과정을 거치고 embedding module을 거친다. 그리고 autoencoder와 prediction head를 통해 masking된 input point cloud를 복원하게된다.

Point Cloud Masking and Embedding
computer vision에서 image는 regular한 patch단위로 바로 나눌 수 있지만, point cloud는 3d space에서 unordered하게 구성되어있다. 이러한 특성을 고려하여 point cloud를 크게 point patches generation, masking, embedding 이렇게 3가지 stage로 처리한다.
point patches generation
먼저 point cloud를 farthest point sampling(FPS)과 k-nearest neighborhood(KNN)을 통해 point patches들로 나눈다. 수식으로 표현하면 p개의 input point cloud Xi ∈ Rp x 3 가 주어졌을 때 FPS를 통해 n개의 point patch center points CT를 sampling한다.
이렇게 뽑은 center points를 기반으로 KNN을 통해 k개의 가까운 points들을 뽑아 point patches P를 만든다.
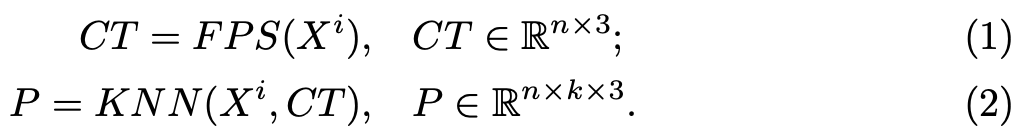
이때 각 point patch안에서 points들은 해당 patch의 center point를 기준으로 정규화된 normalizaed coordinate로 표현된다.
masking
masking ratio m으로 masking한 point patch는 Pgt ∈ Rmn x k x 3으로 나타내고 이 masked patch들이 나중에 reconstruction loss를 계산할 때 gt로 사용된다. masking을 할 때 60%~80%의 높은 비율로 random masking을 하는 것이 가장 좋은 결과를 보였음을 실험적으로 알아냈다.
embedding
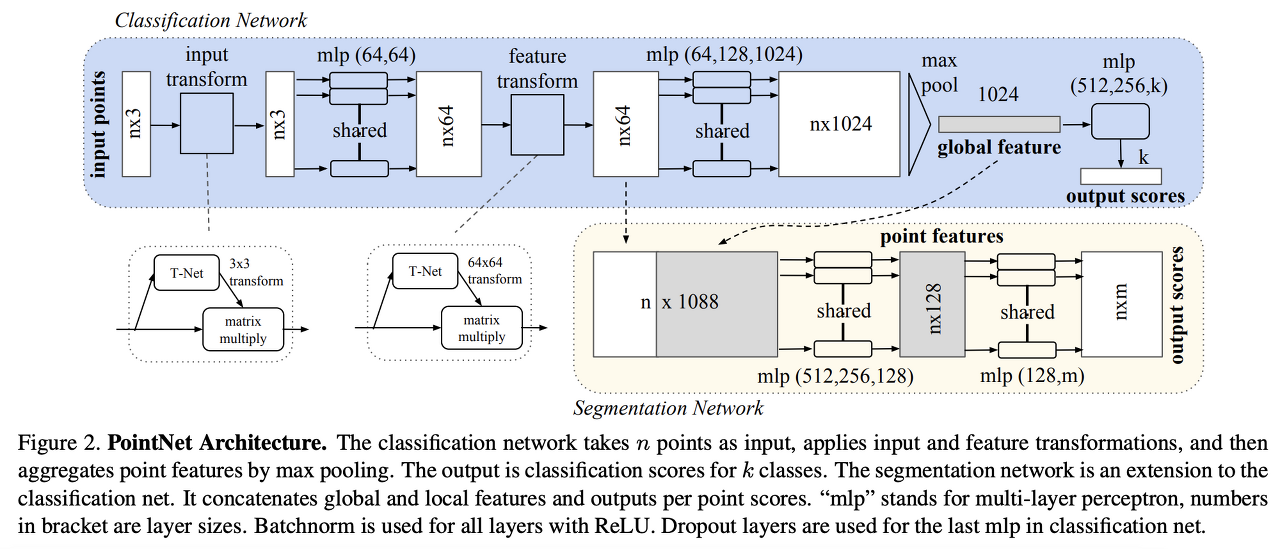
그리고 masking된 point patch의 embedding을 위해 shared-weighted의 학습가능한 mask token으로 대체한다. 전체 mask token을 Tm ∈ Rmn x C라고 할 때 C는 embedding차원을 나타낸다. unmasked point patches들에 대해서는 naive하게 flatten하고 linear projection을 통해 embedding할 수 있다. 하지만 저자는 linear embedding과정이 permutation invariance를 만족시킬 수 없다고 주장한다. permutation invariance란 입력 요소의 순서가 바뀌더라도 output이 바뀌지 않아야하는 것이다. 이 문제를 해결하기 위해 저자는 lightweight PointNet을 적용하였다. Pointnet은 MLP layer와 maxpooling layer로 되어있는데 maxpooling을 통해 어떤 순서로 input이 들어와도 동일한 output을 가지는 permutation invariance를 만족할 수 있다.
masking되지 않은 visible point patch를 Pv ∈ R(1-m)n x k x 3이라고 하면 visible token Tv로 embedding은 아래 수식으로 표현할 수 있다.
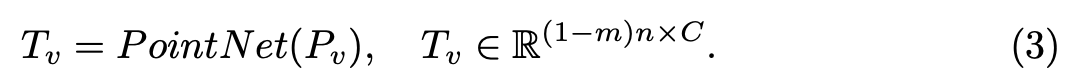
위에서 point patch마다 각 point patch center point를 기준으로 normalized된 coordinate로 표현했기 때문에 center의 위치를 embedding token에 제공해야한다. positional embedding(PE)는 간단하게 학습가능한 MLP를 사용하여 center coordinate를 embedding차원에 mapping하였다.
Autoencoder’s Backbone
encoder-decoder
Point-MAE의 encoder는 standard transformer block으로 구성되며 mask token Tm은 제외하고 visible token Tv만 encoding한다. positional embedding이 포함되어 encoding된 token은 Te로 표현한다. decoder는 encoder와 비슷하지만 더 적은 transformer block을 가지며 encoding된 token Te와 masking된 token Tm을 입력으로 한다. decoder를 통과한 output은 간단한 prediction head를 거친 후에 decoded mask token Hm을 output으로 한다.
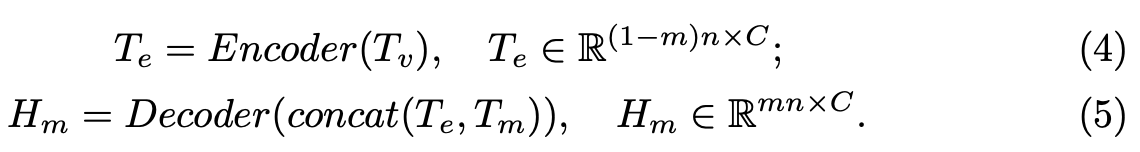
encoder-decoder구조에서 mask token을 encoder input에 포함시키지 않고 lightweight decoder의 input으로 shift했는데 두 가지 측면에서 이득이 있다고 한다. 먼저 높은 비율로 masking을 하는데 masking token을 encoder의 input으로 넣지 않다보니 computational resource를 줄일 수 있었고, 더 중요한 것은 mask token의 location정보를 encoder에 누출시키지 않을 수 있어 encoder가 latent feature를 더 잘 학습할 수 있었다는 것이다.
prediction head
backbone의 마지막 layer인 prediction head를 통해 masking된 point patch를 복원할 수 있도록 했다. prediction head는 간단히 fc layer를 사용했다. decoder output이 Hm으로 나타내고 FC layer로 projection하여 같은 dimension크기로 만들어 주고 reshape해서 예측한 masked point patch Ppre는 아래와 같이 나타낼 수 있다.
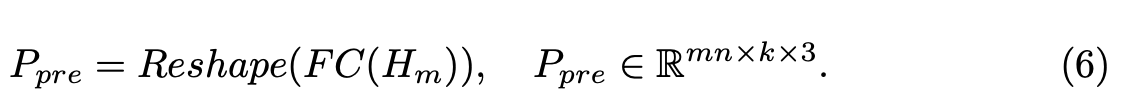
Reconstruction Target
reconsturction target은 모든 masked point patch에서 point의 coordinate를 recover하는 것이다. 예측한 point patch Ppre와 gt인 Pgt가 있을 때 reconstruction loss는 l2 chamfer distance를 통해 계산할 수 있다.
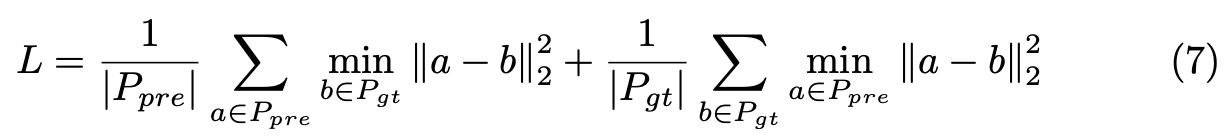
chamfer distance는 서로 다른 point cloud 2개가 존재할 때 거리값을 기반으로 그 차이를 측정하는 평가지표이다. prediction한 point와 gt point가 있을 때 Prediction point에 대해 gt 내 가장 가까운 point와의 거리를 l2 loss로 계산하고 prediction point 수로 나눠준다. 반대 과정도 동일하게 하고 모두 더한다.
Experiments
본 논문에서 제안하는 Point-MAE는 ShapeNet에서 pre-train했다. 그리고 object classification, few-shot learning, part segmentation 등의 downstream task에서 평가했다. input point cloud의 수 p는 1024로 하고 point patch n은 64로 했다. knn에서 k는 32로 했다. encoder는 12개의 transformer block을 가지고 decoder는 4개의 transformer block을 가지도록 했다. 각 transformer block에서 hidden dimension은 384로 했다.
shapenet 데이터셋은 51,300개의 clean 3D model로 구성되어있다고 한다. dataset을 train, test로 나누어 train set만 pre-training에 사용했다.
아래 Figure 4에서 masking ratio에 따른 validation결과를 시각화해놓았다. model은 60%의 masking ratio를 적용해서 pre-train했는데 다른 masking ratio를 가지는 input에 대해서도 잘 reconstruct하는 것을 확인할 수 있다. Point-MAE는 기존의 Point-BERT에 비해 사전학습시 1.7배 빠르게 학습할 수 있었다고 한다.
point cloud에 self-superised learning을 적용할 때 모델이 높은 일반화 능력을 가질 수 있도록 design하는 것을 주요하게 고려했다고 한다. 사전학습한 데이터셋인 shapenet은 아래 그림처럼 clean object model만 포함하고있어 background와 같은 context를 scene이 포함하지 않는다.

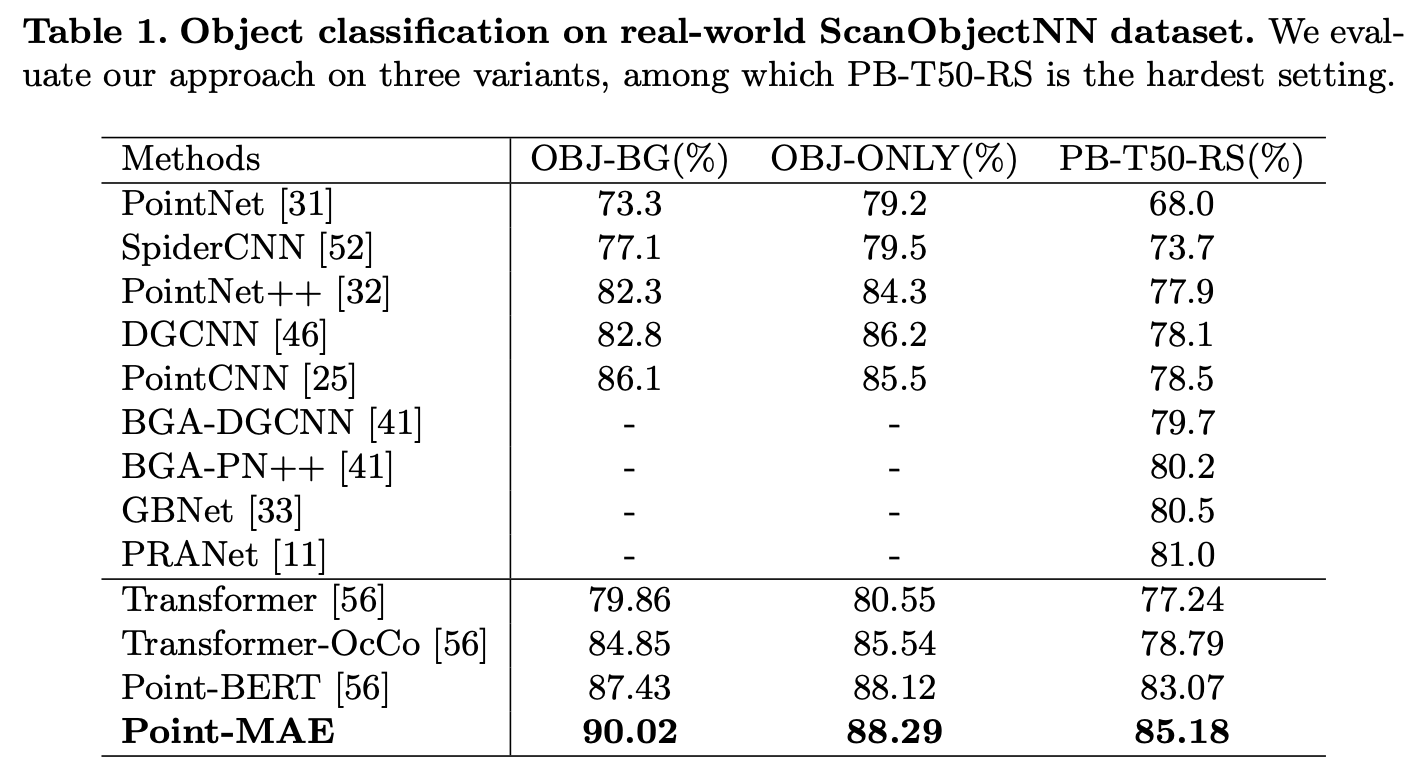
따라서 저자는 generalization capability를 확인하기 위해 좀 더 challenging한 real-world dataset인 ScanObjectNN에서도 평가를 했다. ScanObjectNN은 15,000개의 object로 구성되어있는 Real-world indoor scene을 scan한 데이터셋이라고 한다.

아래 Table 1에서 결과를 확인할 수 있다. OBJ-BG, OBJ-ONLY, PB-T50-RS 3가지로 평가했다. 각 평가기준에 대한 설명은 appendix에 있다고 하는데 논문에 appendix를 찾아볼 수 없었다… OBJ-BG는 object와 background가 있는경ㅇ, OBJ-ONLY는 object만 존재하는 경우 같은데 PB-T50-RS는 무엇을 의미하는지 모르겠다. PB-T50-RS가 가장 hard한 기준이라고 한다. 결과를 보면 다른 방법론들에 비해 Point-MAE가 좋은 결과를 보이는 것을 알 수 있다. baseline인 일반 transformer와 비교했을 때 최대 10%이상의 차이를 보인다. 이 결과를 통해 clean object로 pre-train되었지만 Point-MAE가 real-world data에서도 genera하게 잘 동작하는 것으로 받아들일 수 있다. 가운데 가로선 아래 방법론들이 transformer기반 방법론들이다. 전반적으로 transformer기반 방법론들이 좋은 성능을 보이는 것으로도 이해할 수 있다.
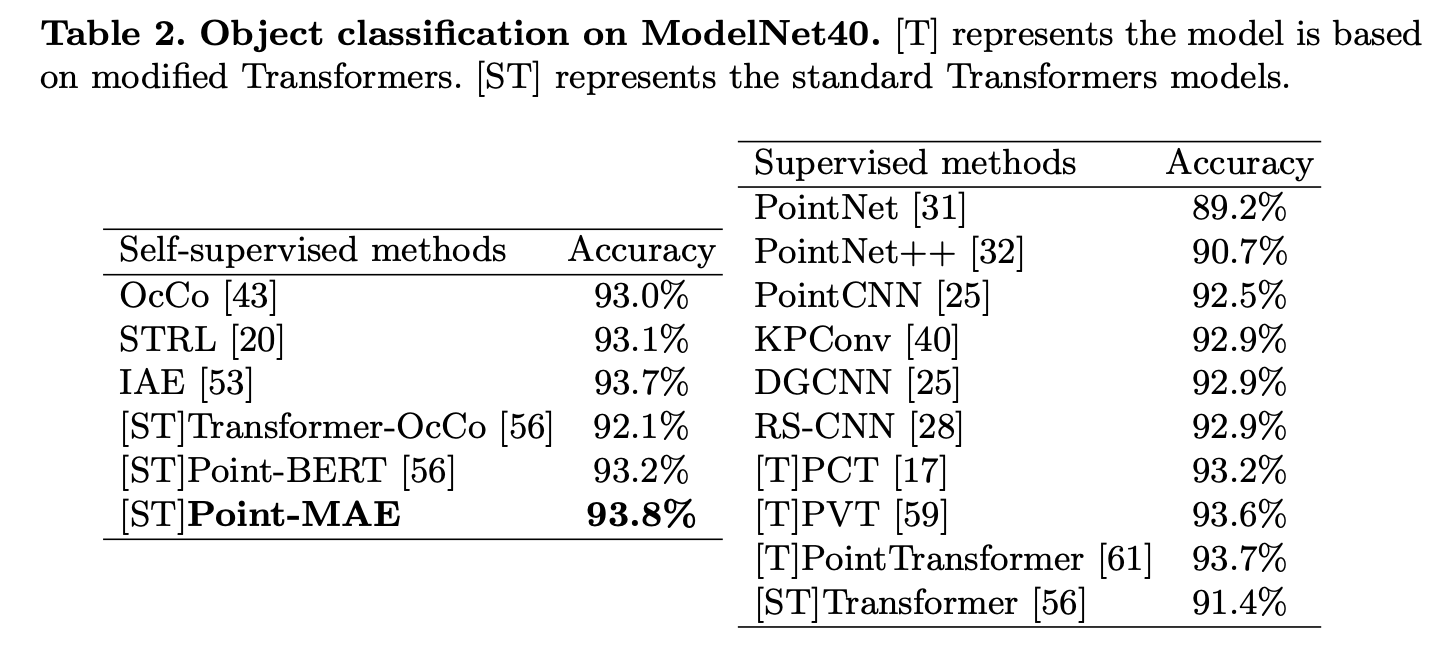
다음으로는 clean object dataset에 대해서도 object classification을 평가했다. 여기서는 사전학습된 모델을 ModelNet40에서 평가했다. ModelNet40은 12,311개의 clean 3D CAD model dataset이다. standard protocol에 따라 평가했다고 한다.

아래 Table 2에서 평가 결과를 확인할 수 있다. fair comparision을 위해 모든 방법론들은 1024개 points만을 사용했다고 한다. 왼쪽이 self-supervised 결과이고 오른쪽이 supervised방법론의 결과이다. 방법론 앞에 [ST], [T]는 각각 standard transformer model과 modified transformer model을 의미한다. 결과를 보면 Point-MAE가 기존 다른 self-supervised방법론들 뿐만 아니라 supervised 방법론들보다 좋은 결과를 보이고 있다. 특히 더 powerful한 backbone을 사용한 IAE보다 standard transformer backbone을 사용한 Point-MAE가 더 좋은 결과를 보인다. 여기서 point 수를 1024에서 8192개로 늘렸을 때 94.04% 정확도를 보여주었다고 한다. large dataset에서 더 좋은 결과를 보일 수 있을 것이라는 생각이 든다.
아래는 ablation study이다. 먼저 masking전략에 대해 보면 두 가지 masking전략이 사용되었다. block masking과 random masking인데 random masking이 조금 더 좋은 정확도를 보여준다. 그리고 Masking ratio도 다양하게 실험했는데 60%일 때 Loss가 가장 낮고 정확도도 가장 높아 60%의 masking ratio를 설정했다고 한다.

아래 Figure 5에서는 서로 다른 masking 전략과 비율에 따른 결과를 시각화해놓았다. block masking의 경우 주변 patch들이 다 masking되기 때문에 주변정보를 활용해서 Reconstruction하는 task에서 더 어려움을 느끼는 것 같다. 그래서 40%가 60%보다 더 잘 복원한 것처럼 masking ratio도 너무 높으면 좋은 결과를 보이지 못하는 것 같다.
random masking의 경우에는 결과론적으로 봤을 때 block masking보다 더 좋은 결과를 보여주었고 masking비율도 60%~80%로 높은 비율로 했을 때 더 좋은 결과를 보여주었다.

또 mask tokens들을 encoder의 input이 아니라 decoder input으로 shifting하는 것에 대해 pre-train 후 loss가 2.51, 2.60으로 mask token을 decoder로 shift한 Point-MAE가 더 높게 나왔다고 한다. 하지만 fine-tunning 후 downstream task에서 정확도는 92.14%, 93.19%로 오히려 Point-MAE가 더 좋은 결과를 보였다고 한다. 이러한 결과를 통해 encoder의 input으로 positional embedding을 통해 mask token의 localization 정보를 함께 주게되면 해당 정보가 누출되어 encoder가 reconstruction을 위한 latent feature를 학습하는게 더 쉬워지고, 결국 최종적으로 더 안좋은 성능을 보인다고 주장한다.
Conclusions
본 논문에서는 point cloud의 self-supervised learning을 위해 masked autoencoder를 이용한 새로운 방식인 Point-MAE를 제안한다. Point-MAE는 간단하고 효율적인 구조로 point cloud의 특성을 잘 활용했다. 또 기존 self-supervised learning기법들보다 좋은 결과를 보였고 standard transformer구조가 supervised learning에서 dedicated transformer 모델을 능가하는 성능을 보였다. 또 language나 image에서의 unified architecture를 point cloud에도 적용할 수 있겠다는 feasibility를 보였다고 주장한다.
안녕하세요, 좋은 리뷰 감사합니다.
여가서 언급하는 standard transformer는 ViT를 말하는 게 맞는지 궁금합니다.
그리고 ‘point cloud의 수 p는 1024로 하고 point patch n은 64로 했다. knn에서 k는 32로 했다.’ 의 해당 부분은 ablation study를 통해 얻은 파라미터인지 궁금합니다.
감사합니다.
댓글 감사합니다.
네. vision transformer도 Attention is all you need에 나오는 standard transformer에 이미지를 넣어주는 형태이므로 말씀하신대로 Vision Transformer가 standard transformer라고 하는 것도 맞는 것 같습니다.
point cloud의 수나 patch의 수, k의 수에 대한 ablation은 없습니다만, point cloud의 수는 pointnet에서도 1024개의 point를 sample했었고 논문에서 더 많은 point를 sampling했을 때 더 좋은 성능을 보였다고도 언급한 것으로 보았을 때 fair comparison을 위해 설정했을 수도 있을 것이라는 생각이 듭니다.
안녕하세요. 리뷰 제목이 흥미로워보여 읽게 되었습니다.
전체적으로 재미있는 내용이네요. 당연히도 Point cloud, 3D object detection에서도 MAE가 곧 사용되겠다 싶었는데, 몇 가지 문제점이 있는지 몰랐습니다. 따라서 이에 따른 궁금증이 생겨 질문합니다.
1. Masked token이 transformer의 input으로 들어감에 따라 location 정보가 leakage된다고 하는데, location 정보가 leakage되는게 마치 cheating과 같은 역할을 하여 latent feature를 학습하는 것에 방해가 된다는 의미일까요? location 정보가 leakage된다는 것의 의미를 샘플 예시와 더불어 다시 설명해주실 수 있으실까요? 연이어, 이를 해결하고자 mask token을 decoder의 input으로 넣는다고 하였는데, 그럼 encoder에서는 정확히 어떤 Task를 학습하고자 하나요? Reconstruction Task에서 Rotation 등의 다양한 Task를 말씀해주셨는데, 현재 Point cloud에서는 input point를 Reconstruction하는 것이, detection에서 어떤 측면에서 효과적일지가 가장 궁금합니다.
위 질문이 제가 적어도 다소 헷갈릴여지가 있다고 생각이 드는데, 이것이 제가 MAE 개념은 알지만 논문은 읽지않아서일 수도 있겠네요..ㅎㅎ. 그래도 self-supervised learning, MAE 등에 대해 자세한 preliminaries를 말씀해주셔서 너무 잘 읽었습니다. 감사합니다!
댓글 감사합니다.
최근에 논문을 follow up하다보니 point cloud에도 mae를 적용한 연구가 많이 이루어지는 낌세를 확인해서 호다닥 관심을 갖고 보게되었습니다ㅎㅎ
1. 말씀하신 것처럼 model이 학습하는데 cheating이 될 수 있다고 이해했습니다. image에서는 masking된 위치의 pixel값을 복원하는 것을 목적으로 하지만, point cloud의 경우에는 masking된 부분의 point를 복원하는 것을 목표로 하는데 이 point cloud데이터 자체가 사실 위치 값이기 때문에 정답 정보를 흘린다라고 한 것 같습니다.
2. encoder에서는 masking된 영역의 point를 복원할 수 있도록 주변 unmasked point patch를 기반으로 high-level의 latent feature를 찾는 것을 목적으로 합니다. 그리고 encoder에서 encoding된 feature를 통해 decoder에서 masking된 영역의 정보를 복원하는 역할을 할 수 있도록 합니다. encoder에 masking patch를 입력으로 하지 않으므로써 조금이나마 정답에 가까운 정보를 알리는 것을 방지하고자했다라고 이해하시면 도움이 될 것 같습니다.
3. 그리고 point cloud에서 masking point를 reconstruction하는 것이 detection에 어떻게 적용이 될 수 있나라고 질문주신거 같은데요 역시…날카로우시네요… 저도 이 질문에 대해 계속 고민을 해봐야하는데요, 일단 현재 task는 downstream task로 object classification을 하는 목적으로 사용했는데, 이전에 pointnet을 보면 역시 point cloud 내에서 의미있는 feature를 추출하여 classification하는 task에 적용했었습니다. 그리고 지금 많은 3d object detection 방법론들에서 pointnet을 backbone으로 두어 point cloud 내 의미있는 정보들을 추출하는데 사용하고 있습니다. 이처럼 MAE를 통해 input point cloud를 masking하고 복원하는 행위 자체가 point cloud의 표현력을 높히는데 도움이 된다고하면, 또 전체 3d scene에 대해서도 적용 가능한 scalablity를 가진다고 하면 object detection을 하는데 input point cloud에서 의미있는 정보를 추출하기 위한 방법으로 사용할 수 있지 않을까 하는 생각을 막연히 가지고 있습니다. 현재 point cloud에 MAE를 적용했다는 것으로 많은 관심을 받고 있고 관련된 연구가 등장하고 있는 것으로 보아 머지않아 detection에도 사용되지 않을까 하는 생각이고 관련된 연구가 있는지 더 찾아볼 계획입니당.
저도 MAE에 대한 개념을 접한지 얼마되지않아 완벽히 이해가 되지는 않았을 수 있다고 생각됩니다. 좋은 질문해주셔서 감사합니당ㅎㅎ
좋은 리뷰 감사합니다.
introduction 부분에서 Lack of a unified transformer architecture라는 문제를 해결하기 위해 standard transformer를 기반으로 autoencoder의 backbone을 적용하셨다고 했는데, standard transformer는 어떤 점에서 데이터 부족 문제를 해결할 수 있는 것인지 설명해주실 수 있나요??
본 논문에서 정리한 MAE를 point cloud에 적용할 때 challenge한 점이 흥미롭습니다. positional embedding을 통해 localization 정보를 줌으로써 모델이 쉽게 학습을 하게 되어 성능에 결과적으로 안좋은 영향을 준다는 것은 본 논문이 처음 보인 것인가요?? 그 외의 다른 challenge한 점들도 해당 논문에서 처음 발견한 것인지 궁금합니다.
댓글 감사합니다.
음… 아마 standard transformer를 적용했기떄문에 데이터 부족 문제를 해결할 수 있다라기보다는, masked autoencoder를 통한 self-supervised learning을 통해 데이터 부족 문제를 조금이나마 해소할 수 있다고 하지 않았을까 하는 생각입니다. 3d data를 labeling하는 것은, 특히 large scale의 데이터를 labeling하는 것은 많은 cost가 드는데 데이터 자체만으로 특징을 뽑아 labeling을 할 수 있다는 점이 데이터 부족 문제를 해결할 수 있다고 하지 않았나 싶습니다. standard transformer를 적용하여 추후 다른 modality를 함께 활용하는 방법을 통해 데이터 부족 문제를 해결할 수 있도록 여지?를 남겨주는 의미인 것 같습니다.
제가 아직 point cloud에 mae를 적용한 방법들을 많이 보지 않아서 아는 선에서 말씀드리자면, 최근에 point cloud에 mae를 적용한 방법들이 소개되었고 아직 깊은 연구가 이루어지지 않은 분야로 보입니다. 말씀하신 것처럼 기존 방법론에서는 encoder에 masking patch도 함께 입력하여 positional 정보를 주었는데 본 논문에서는 decoder input으로 shift한 것으로 보아 해당 문제를 issue rising한 것은 본 논문이 처음인 것으로 보입니다.
감사합니다.
김도경 연구원님, 좋은 리뷰 감사드립니다.
point cloud의 masked autoencoding할 때 challenges 중 3번의 point cloud가 information dentisity 분포가 상대적으로 고르지 못하다고 말씀해 주셨는데, local feature의 density라는 개념이 잘 와닿지 않습니다. 저수준 feature는 density가 낮다는 뜻인가요? point cloud를 학습할 때 feature의 density가 어떻게 분포되는지 설명해주시면 감사드리겠습니다.
감사합니다.
댓글 감사합니다.
음 아마 local이랑 lower를 헷갈리신 것 같은데요, 예를 들어 corner나 edge와 같은 key local feature는 더 높은 density의 정보를 가지고 평평한 면과 같은 상대적으로 덜 중요한 local feature는 낮은 density의 정보를 가질 것
입니다. 그니까 해당 local영역에서 가지는 정보의 밀도 == 정보의 퀄리티? 엔트로피?가 다르다고 받아들이시면 이해가 좋을 것 같습니다. 아래 그림에서 평평한 면은 잘 복원되었지만 edge나 corner같은 주요한(key) local 영역은 상대적으로 잘 복원하지 못한 것을 알 수 있습니다.
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
masking된 patch들이 나중에 reconstruction loss를 계산할 때 gt로 사용된다고 말씀해주셨는데 reconstruction을 한다는 것은 decoder에서 input을 복원하기 위함이라면 가려진
masking path를 GT로 사용하는 이유에 대해 이해가 잘 되지 않습니다 .. 혹시 decoder input에서부터 masking token을 input으로 넣음으로써 mask token의 location 정보를 encoder에 노출시키지 않을 수 있다는 점에서 해당 location 정보를 gt로 사용하는 것인가요 ? ? ?
그렇지만 Fig3에서 보아도 GT로 가려지지 않은 본래의 point patch를 사용하고 있다고 이해했는데 이 부분에 대해 추가적으로 설명해주시면 감사하겠습니다 ㅎ ㅎ ..
댓글 감사합니다.
masking을 하는 이유가 masking을 한 부분을 잘 복원하기위해 encoder가 학습하도록 하기 위함입니다. 이때 masking한 부분을 복원했다면 원래 masking하기 전 masking된 영역의 point들과 비교해서 얼마나 잘 복원했는지 비교해야하기 때문에 가장 명확한 gt인 masked patch를 gt로 씁니다. masked token을 decoder input으로 하는 것과는 아마 관련이 없다고 생각됩니다.
Figure 3에서 encoder에는 masked patch가 입력으로 들어가지 않습니다. 왜냐면 encoder는 어짜피 unmasked patch만을 가지고 masking 영역에 대해 복원할 수 있는 의미있는 정보를 학습하기 때문이죠. 그리고 decoder에서 이제 encoder에서 학습한 결과와 실제 정답인 masked 영역을 가지고 복원하는 과정을 거치게 됩니다. 그리고 얼마나 잘 복원했는지 비교하게 됩니다. downstream task에서는 decoder는 버리고 encoder만 fine-tunning하여 사용하기 때문에 실제로는 encoder가 noise로 여길 수 있는 masking된 영역을 제외한 부분에서 masking된 영역을 복원하기 위한 의미있는 정보를 얼마나 잘 학습하는지가 중요하다고 생각합니다.
감사합니다ㅏ.