오늘 가져온 논문은 무려… CVPR ORAL을 받은 논문인데요. 코드 공개도 한다고 되어있어서 두근두근하고 Github을 들어갔는데…
구조가 어렵지는 않아서 짜라면 짤 수는 있을 것 같은데, 코드 자체는 저자의 장문의 편지와 함께 코드는 올라오지 않네요. 흠… ORAL 정도면 올려줄 법 싶은데… 아무튼 시작해보겠습니다.
Introduction
동영상을 활용한 SSL은 크게 영상의 변화를 인지하는 방식(pretext task 기반)과 instance discrimination을 활용하는 방식(contrastive learning)이 있습니다. 이 논문에서는 RecogTrans와 InstDisc라고 부르고 있는데요. RecogTrans에서는 흔히 영상의 회전 변화나 크기 변화, 재생 속도 등에 변화를 주고 이를 예측하는 방식을 이용합니다. 최근 연구들에서 많은 연구들이 InstDisc가 더 좋은 성능을 보이더라는 결과들이 많은 편인데요. 논문 저자들은 이에 의구심을 가집니다.
- RecogTrans와 InstDisc로 학습되는 표현력 사이에 정말 차이가 있는가?
- InstDisc 기반의 표현력이 정말로 더 강력한가? 아니면 두 표현력이 뭔가 차이가 있거나, 각각의 장점이 있는가? 그렇다면 RecogTrans의 성능 저하의 원인이 무엇인가?
- (RecogTrans가 일반적으로 더 낮은 성능을 보이는 이유에 대해) 좋은 학습 방식이 없어서 발생하는 문제이거나, 프레임워크의 일반적인 한계인가?
이러한 질문에 대답하기 위해서 논문 저자들은 RecogTrans와 InstDisc의 비교 실험을 수행하는데요. 이를 통해서 temporal-RecogTrans(RecogTrans-T)에서 spatial-RecogTrans(RecogTrans-S)와 InstDisc로부터 학습되는 표현력과는 확실히 다른 차이가 있다는 것을 찾아냅니다.
RecogTrans-T는 video retrieval 같이 semantic한 표현력이 중요한 downstream task에서 낮은 성능을 보입니다. 하지만 action recognition 같이 temporal한 관계가 있는 task에서 적절한 finetuning만 거치면 좋은 성능을 보였다고 합니다. 결론적으로 이러한 부분들에서 RecogTrans-T의 가능성을 발견하고 이를 이용할 수 있는 모델을 제안합니다.
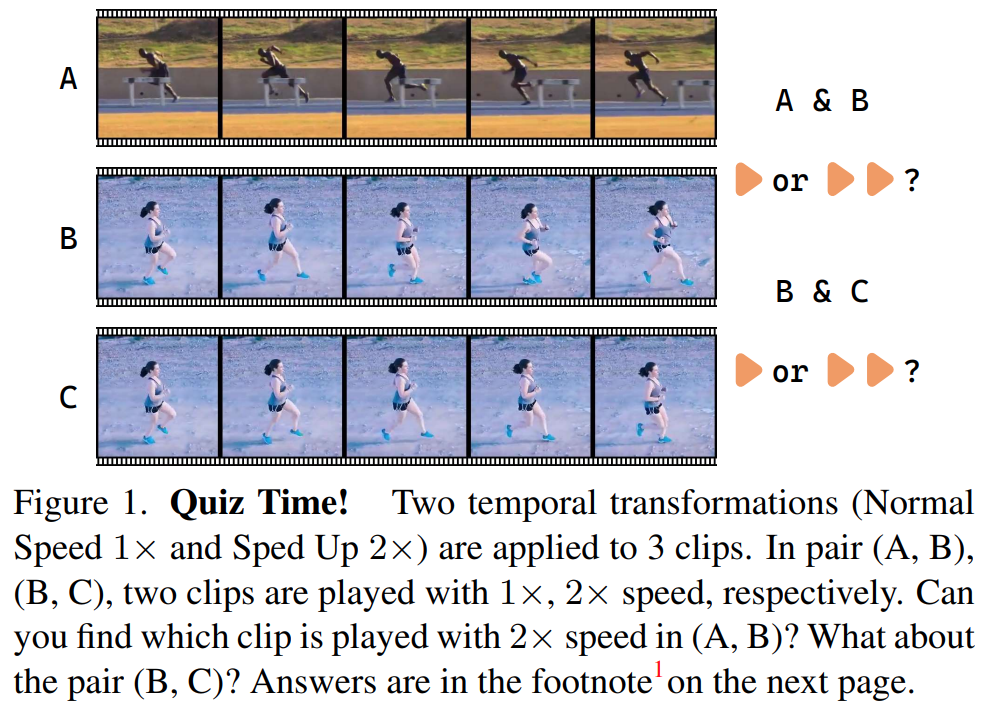
RecogTrans는 영상의 내부 특성을 무시하는 noisy한 지도학습 시그널 때문에 학습이 안되는 것이기 때문에, 제안하는 TransRank는 랭킹 수식을 통해 변형을 인식하는 통합된 프레임워크로 학습을 수행합니다. 본격적으로 시작하기 전에… 퀴즈 하나 맞추고 넘어갑시다. [그림 1]의 퀴즈를 보고 3개의 영상들이 정배속인지, 1배속인지 2배속인지 함께 맞춰봅시다. (진짜 해보세요. 쉽지않죠? 정답은 결론에 적어두겠습니다.)
영상 내에 수많은 액션이 존재하고, 사람이나 액션이 따라 속도가 달라져서 사람도 이런걸 맞출 수가 없는데 모델 입장에서 이러한 것들은 알아채기 상당히 어렵습니다. 그래서 기존의 hard-label 분류 기반(2배속 재생으로 변형을 줬으면, 2배속 재생이라는 것을 맞추는 방식)의 RecogTrans보다 더 정확한 지도학습 시그널을 랭킹 함수를 이용해서 제공하는 TransRank 프레임워크를 개발했습니다.
그래서 Contribution을 정리하면…
- SSL에서 흔하게 사용되는 RecogTrans and InstDisc을 다시 돌아보고, RecogTrans의 큰 가능성에 대한 증명을 수행함
- hard-label 분류 기반으로 작동하는 RecogTrans를 통해 정확한 지도학습 신호를 제공하는 TransRank를 개발함. 이는 다양한 temporal & spatial pretext task에서 사용 가능
- RecogTrans-based video SSL의 개선을 이루었고, SOTA를 달성함
Preliminary Comparisons of InstDisc and RecogTrans
SpeedNet의 경우에는 temporal한 측면에서 비교군으로 선택되었고, 3D-RotNet은 spatial한 측면에서 RecogTrans에 대한 비교군으로 선택되었습니다. 그리고 MoCo와 SimSiam의 경우에는 InstDisc에 대한 비교군으로 선택되었고요. 이러한 방법론들은 모두 R3D-18에서 MiniKinetics에 Augmentation을 넣어가면서 실험했다고 하네요. 이 실험을 통해서 차이를 볼 수 있다고 하는데 어떤 결과가 나왔는지 자세하게 알아봅시다.
Semantic-related Task
비디오 클립의 semantic한 정보를 이해하는 것이 중요한 downstream task에는 3가지 정도가 존재하는데요. Neraest Neighborhood Evaluation(Retrieval)과 Linear Evaluation 그리고 Finetuning입니다. 어떤 Task들인지는 다들 아실테고… 실제 시나리오에서는 Downstream task들의 성능은 보통 Finetuning을 통해 이루어지기 때문에 이게 가장 중요하다고 하네요. 아무튼 3가지 세팅으로 실험을 수행한 결과가 아래의 [표 1]이 되겠습니다.
Temporal-related Tasks
비디오 클립의 temporal 패턴을 인식하는 것이 중요하다는 것으로 본 task를 정의하는데요. Downstream task로 마땅한 비교군이 있을까 싶었는데, 없어서 여러 논문에서 task를 가져온 것 같네요.
- Motion Type Prediction (Motion) : 사전 정의된 5개의 타입으로 영상의 움직임을 분류
- Synchronization (Sync) : 영상 클립의 겹침 정도의 패턴을 예측
- Temporal Order Prediction (Order) : 겹치지 않은 두 클립의 시간적 순서 예측
이 3가지 Task를 통해서, temporal modeling 능력을 평가했다고 보면 됩니다.
Analysis
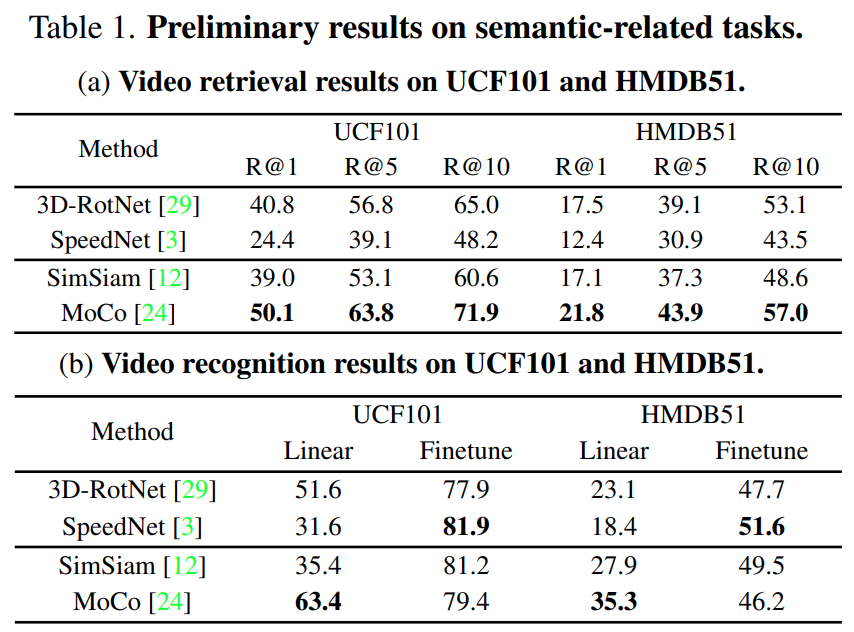
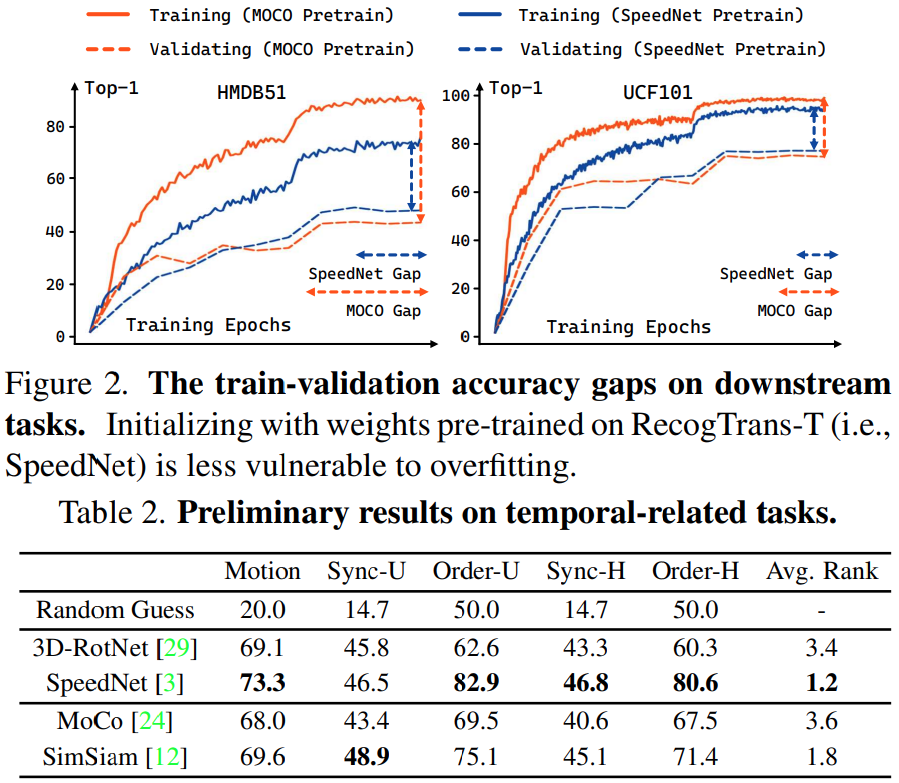
[표1]은 Video retrieval과 linear classification은 representation을 얼마나 잘 배웠는지에 대한 직접적인 성능 지표입니다. Contrastive learning 기반의 MoCo가 가장 좋은 성능을 보였고, RecogTrans으로 학습된 SpeedNet의 경우 좋지 않은 성능을 보입니다. 하지만, 실제 시나리오에서 가장 중요한 Finetuning으로 넘어가보면 상황이 반전되는데요. [표 2]와 [그림 2]를 확인해보면, Temporal-related tasks에서는 SpeedNet이 준수한 성능을 보였으며, 학습 정확도와 평가 정확도간의 차이도 가장 적었습니다. 또 학습 성능과 평가 성능의 차이가 적다는 뜻은 오버피팅이 덜 일어난다는 뜻이겠죠? 이러한 실험 결과들을 바탕으로 크게 2가지의 결론을 내리는데요.
- RecogTrans와 InstDisc가 어느 한쪽이 뛰어나다기 보다는 서로 다른 장점을 가지고 있다.
- 좋은 학습 방식이 없었기 때문에 RecogTrans가 더 적은 성능을 보였을 수도 있다.
사실 논문 저자들이 실험에 사용한 SpeedNet 자체도 원래 논문의 성능이 아니고 저자들이 튜닝을 한 성능인데요. SpeedNet의 구조적인 한계로 인하여 아직 개선할 점이 많아보였고, 이는 결국은 RecogTrans 자체에 더 큰 가능성이 보였다고 합니다. 그래서 본 논문 저자들이 제안하는 TransRank이 필요했고, 이제 본 모델에 대해 알아봅시다.
TransRank: Ranking-based RecogTrans
기존 방법론들이 RecogTrans를 학습하는 방식에 대한 해결책은 매우 간단한 원리로 적용됩니다. 직접적으로 해당 영상이 몇배속 재생인지를 맞추지 말고, 상대적인 속도를 맞추면 되는거죠.
- 기존 방법론 : 특정 영상에 속도를 빠르게 임의로 augmentation을 주고서, 해당 영상이 몇배속 재생중인지 예측하게 한 다음에 Cross-Entropy Loss로 계산
- 현재 방법론 : 지금 영상에 여러가지 속도로 재생되는 augmentation을 주고, 그 영상들 끼리의 유사도 matrix를 생성하고, 거기에 Ranking Loss를 적용
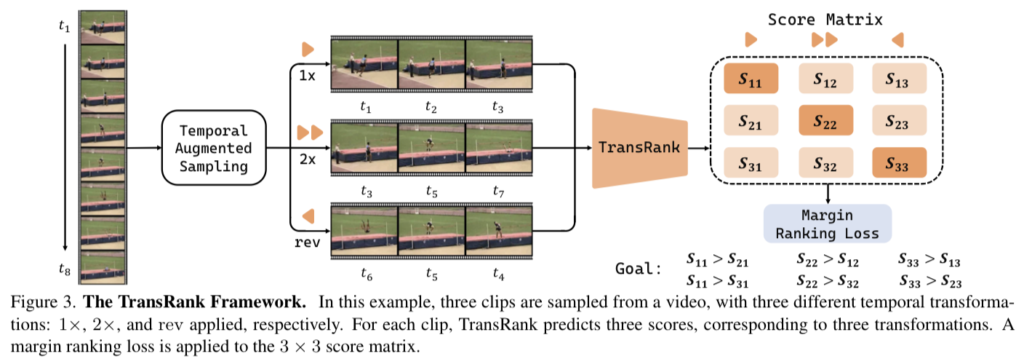
이 구조는 [그림 3]에서 확인해볼 수 있는데요. TransRank는 M개의 temporal transformation \{T_1, ...., T_M\}으로 선언될 수 있습니다. 학습 단계에서 영상으로 부터 N개의 서로 다른 클립 \{c_1,...,c_N\}을 샘플링하고, 여기에 서로 다른 temporal augmentation을 적용하여, 각각의 클립에 T_{t_i}, t_i \in \{1,...,M\}의 변형을 적용할 수 있습니다. TransRank는 transformation에 의해 변형된 클립의 확신도를 예측하고 이를 S_i = [s_{i1},...,s_{i_M}] 형태의 score vector로 만듭니다. 이 score는 유사도를 예측하는 것이 아니라, 영상 클립이 해당 Transformation으로 변형되었는에 대한 확신도를 예측합니다. 그래서 transformation에 대한 상대적인 확신도를 matrix 형태로 표현할 수도 있는거죠.
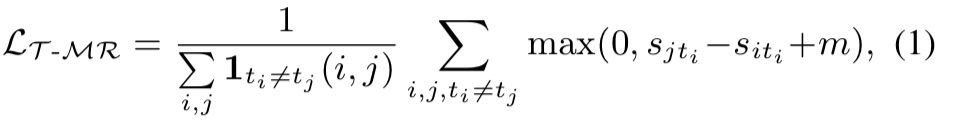
[수식 1]은 TransRank에서 사용하는 margin ranking loss인데요. (m은 margin에 해당) 같은 transformation이 적용되지 않은 클립일 경우에는 1이고 아니면 0이 되어 적용되지 않습니다. 같은 클립 내에서의 구분력을 위해서 사용하는 것 같네요.
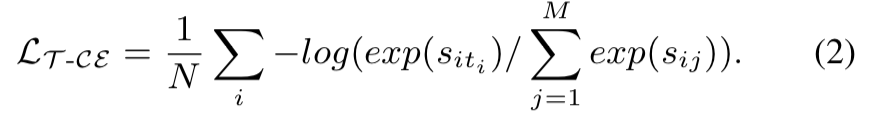
또, [수식 2]와 같이 CE Loss를 사용할 수 있습니다. 확신도 관점에서 s_{it_i}는 s_{jt_i}보다 클 수 밖에 없습니다. (i번째 transformation은 i번째 클립에 적용되었기 때문에, 다른 클립은 i번째 transformation에 대한 확신도가 낮게 나옴) 이러한 특성을 이용해서, 각각의 칸에서 상대적인 transformation을 맞췄는지 안맞췄는지를 Loss로 쓸 수 있습니다. 이건 이제 [그림 3]에서도 목표라고 예시로 적혀져있으니 참고해서 보면 좋을 것 같습니다. 결론적으로 TransRank는 영상 내의 상대적인 속도를 고려하여 더 정교한 지도학습 시그널을 통해서, 더 나은 temporal한 모델링 능력을 가집니다.
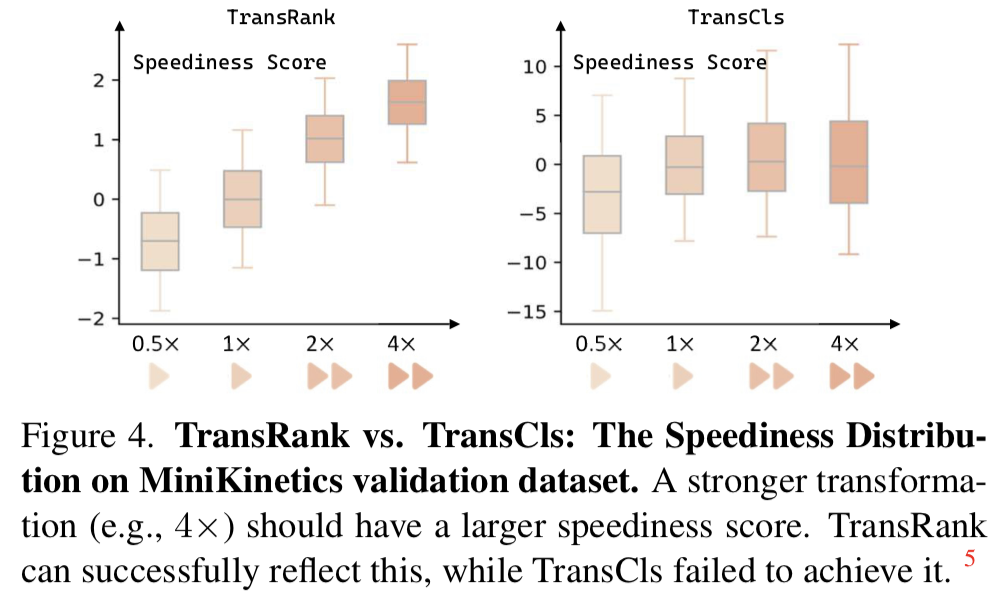
실제로 [그림 4]의 실험을 통해서, Contrastive 기반의 모델 보다 더 잘 맞추는 것을 볼 수 있습니다. 심지어 0.5배와 4배는 학습 과정에서 포함되지 않았음에도 불구하고 잘 맞추는 것을 볼 수 있습니다. 확실하게 temporal한 모델링 능력이 증가되었다는 것이죠.
On Building the Temporal Transformation Set
아무 temporal transformation을 적용한다고 해서 성능이 오르는 것은 아닙니다. 이 논문에서는 좋은 예시와 나쁜 예시를 함께 소개하는데요. 먼저 좋은 예시입니다. 위에서도 설명했던 속도와 관련된 transformation이 좋은 예시인데요. 기존 연구에서도 많이 사용해왔던 만큼 보장된 방법입니다. 이 논문에서는 프레임 간격을 2로 두고, “1배, 2배, 4배, 그리고 역방향“을 변형으로 사용합니다. 나쁜 예시로는 Shuffle이나 Palindrome(저도 처음보는데 한국어로는 회문이라고 하는데, Shuffle이랑 비슷한 것 같네요.) 이런 방법론은 영상의 temporal cue를 손상시키기 때문에 나쁜 예시라고 소개되고 있네요.
(Arxiv이긴 하지만, 이 부분에 대해 분석했던 다른 논문에서는 Shuffle 성능이 나쁘지 않기는 했습니다. 학습을 명시적으로 하는지 이 논문처럼 간접적으로 하는지에 따라 차이가 좀 있는 듯 하고,이 논문에서는 temporal cue가 중요하기 때문에 성능이 나빠지는 것 같습니다.)
The Generality of TransRank
TransRank는 temporal transformation으로만 학습 가능한 프레임워크가 아닙니다. 그래서 이를 위해 2가지의 spatial transformation을 어떻게 적용했는지에 대해 설명을 하는데요.
Estimate Aspect Ratio
이 부분은 영상에서 RandomResizedCrop을 적용하고 이를 이용하는 방식입니다. (영상에서 랜덤 비율로 자르고, 리사이즈 하는 augmentation) 영상들이 내부적인 속도가 천차만별인것 처럼 비율도 각각 다른데요. 이러한 부분을 고려해보면 그동안 직접적으로 얼마나 잘렸는지 예측하도록 하는 것 보다, TransRank의 학습 방식에 적용하는 것이 더 좋았다고 하네요.
Estimate Rotation
이 부분은 회전 정도를 예측하는 방식으로, 역시 SSL에서 많이 사용하고 있습니다. 이 부분은 프레임워크에서 사용할 수는 있지만, ranking loss를 붙여도 장점이 없었다고 하네요. 아무래도 카메라를 이상하게 뒤집고 있는 영상은 존재하지 않기 때문에, 직접적으로 예측하는 것만으로 충분히 정교한 지도학습 시그널을 줄 수 있었던 것 같네요.
Final Loss
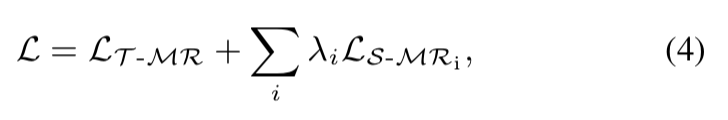
그래서 최종 Loss는 temporal TransRank 목적함수와 Spatial TransRank 목적 함수를 모두 더해서 사용하고, Spatial 목적 함수에만 weight를 조절할 수 있는 파라미터를 하나 추가해서 사용합니다.
Data Augmentation
극단적인 케이스를 고려해서, A클립이 1배속 재생이고 B클립이 2배속 재생이라고 가정해보면, 두 영상은 쉽게 부분될 수 있습니다. (특정 위치에 있는 프레임이 서로 같아지기 때문) 그래서 유의미한 표현력을 학습하기 위해서, 강력한 spatiotemporal transformation의 적용이 필요합니다.
Temporal Augmentation에서는 프레임 간격에서 random jitter를 추가해서 [0.8, 1.2] 사이의 분포를 가지도록 샘플링을 수행하고, 전체 영상에서 서로 다른 offset을 가진 클립들이 샘플링 되도록 했습니다.
Spatial Augmentation은 서로 다른 region에서 spatial augmentation이 적용될 수 있도록 RandomResizedCrop을 적용하고, RandomGraySacle과 RandomColorJitter를 추가했다고 합니다. Rotation이랑 학습할때는 그것도 함께 적용되고요.
물론 이 파트는… Implementation detail 정도라서 ㅎㅎ… 꼭 안보셔도 됩니다.
Experiments
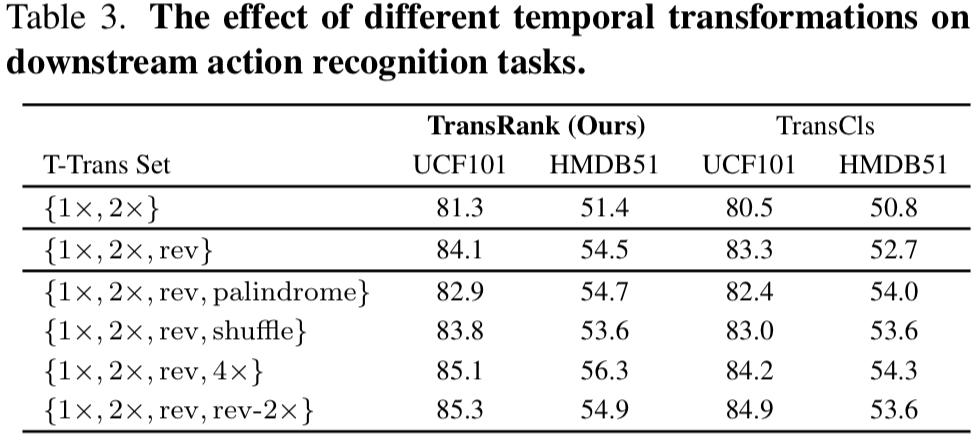
[표 3]에서 서로 다른 Temporal transformation과 Ranking Loss를 결합했을 때의 성능이 TransRank이고 직접 예측하는 것이 TransCls인데요. 다른 것들 보다 이 논문에서 말하는 것 처럼 Ranking Loss를 쓰는 것이 확실히 효율적임을 보입니다. 나쁜 예시로 소개된 Shuffle에 대한 단독 성능이 있었으면 좋았을 것 같은데, 어쨋든 붙이면 성능이 떨어지는 것에서 증명은 했다고 보이네요.
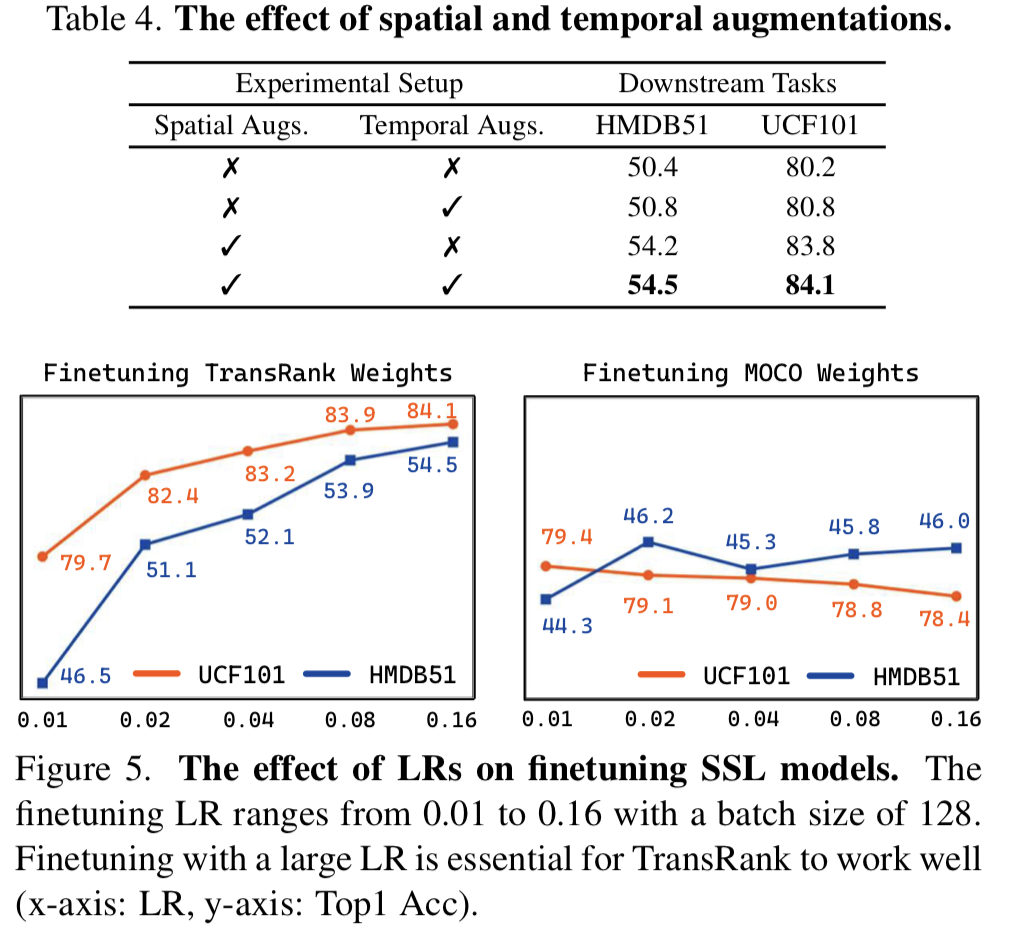
[표 4]는 augmentation 종류에 따른 성능 차이인데요. 역시 둘 다 있는 것이 좋고, Temporal augmentation의 성능 향상폭이 예상보다 적긴 하지만… 실제로 파인튜닝 하는 단계로 넘어가서 [그림 5]를 함께 보면 준수한 편임을 알 수 있습니다. [그림 5]는 파인튜닝 단계에서 TransRank weight와 MoCo weight에서 서로 다른 LR로 학습하는 케이스인데, 전반적으로 TransRank에서 파인튜닝 하는 것이 더 좋은 성능을 보입니다. 사실 이건 좀 단점(?) 같은데, 파인튜닝 단계에서 TransRank의 성능이 전반적으로 높긴 하지만 learning rate 변화에 따라 성능 차이가 좀 많이 납니다. 이것도 분석 느낌으로 제공을 하고 있네요.
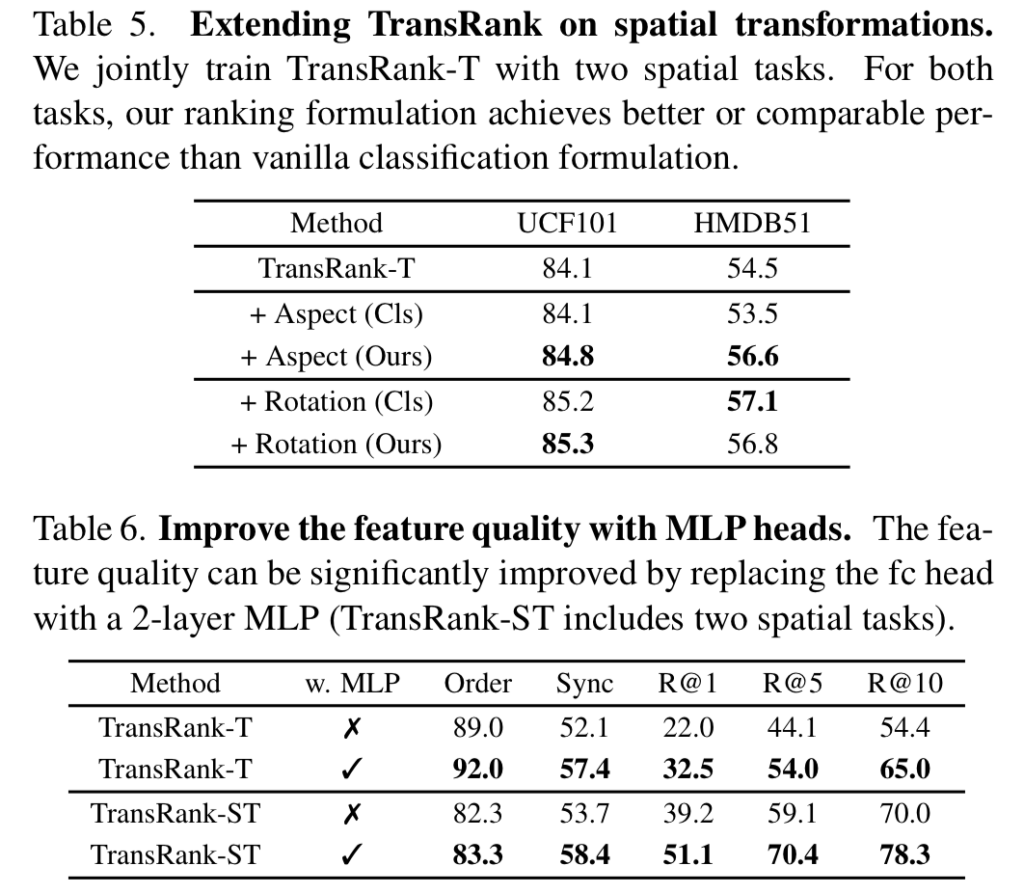
아까 Rotation의 경우에는 Ranking Loss를 적용해도 이점이 없었다고 했는데, 그에 대한 증명은 [표 5]를 통해 수행됩니다. 실제로 Rotation의 경우에는 성능 차이가 그렇게 나지 않은데, 다른 transformation의 경우에는 큰 성능 향상을 보입니다. 이건 뭐… 아까 설명드렸다시피 Rotation 자체의 특성 때문인 것 같네요. [표 6]은 FC레이어가 아니라, MLP를 써보면 성능이 개선이 얼마나 되는지를 보입니다. 분류 Head 설계에 따라 성능이 떨어지지는 않는다는 것을 보이는 것 같네요.
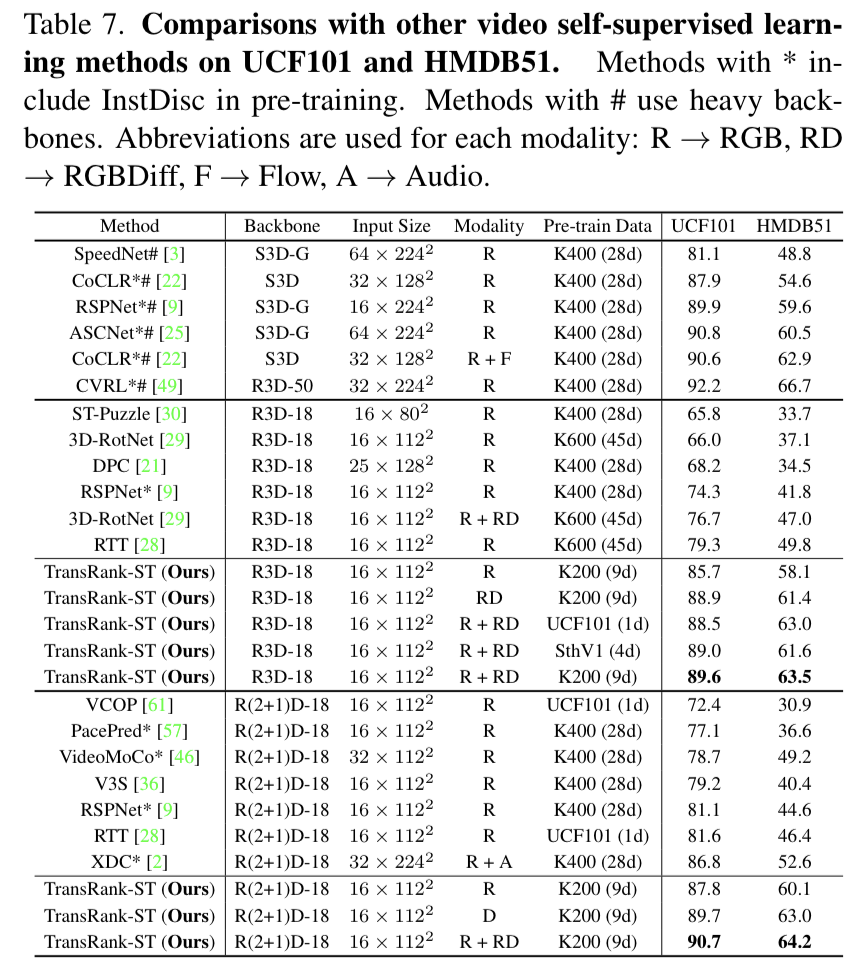
기존의 SOTA 방식들과 비교에서도 높은 성능을 보입니다. 사실 백본도 다르고… 학습 데이터 크기도 달라서 보기 어려울 수 있는데요. 제안하는 방법론이 대게 더 작은 백본, 더 작은 이미지 크기, 더 작은 학습 데이터 셋을 가지기 때문에 이러한 부분을 감안하면 더 좋은 성능임을 알 수 있습니다. K400을 학습 데이터 셋으로 많이 사용하는데 굳이 왜 K200을 선택했는지도 궁금하지만… 설명이 따로 없어서 알수가 없네요. 하나의 Contribution으로 가져가려고 한 것 같긴 한데 궁금하긴 하네요.
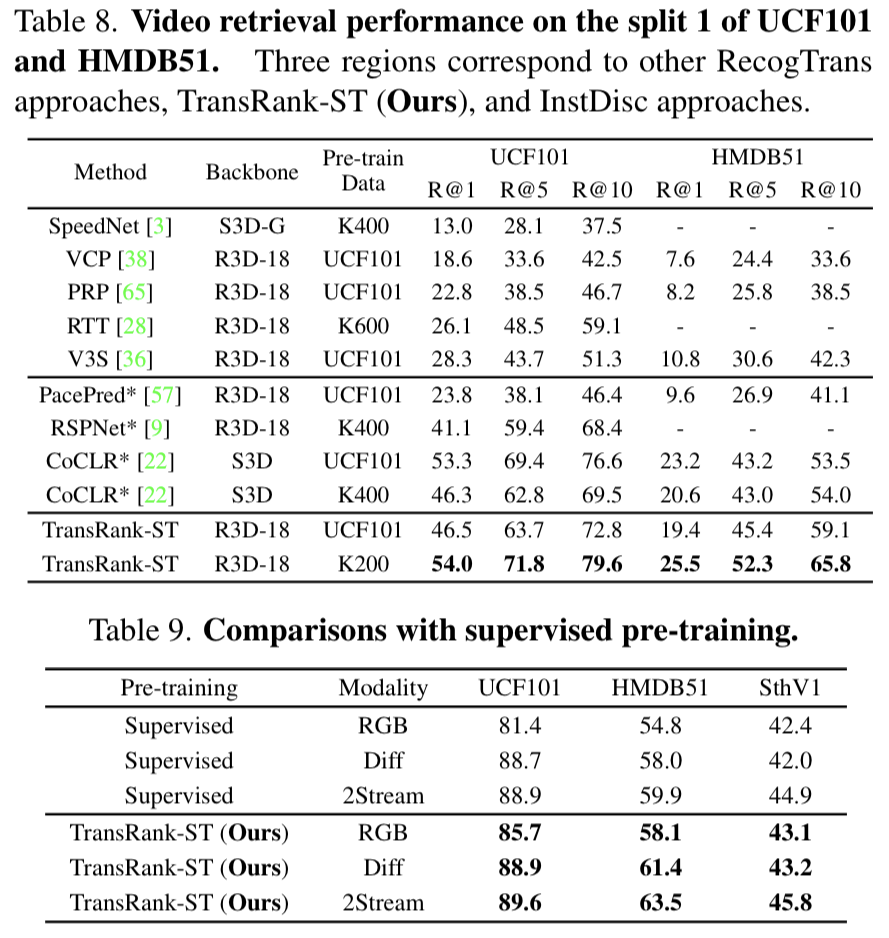
[표 8]은 검색 성능의 우수함을 보여주는 표인데요. 기존 CoCLR랑은 경향성이 좀 다르게 UCF-UCF로 학습하는 것 보다 K200-UCF로 하는 것이 더 좋은 성능을 보이긴 하는데요. 학습 데이터 셋의 크기가 어느정도 있어야 학습이 잘 되는 것 같기도 하고… 그런 점은 제쳐두고 어쨋든 제일 좋은 성능을 보입니다. [표 9]에서는 지도학습과 각종 모달리티에서의 비교인데요. 제안하는 세팅이 제일 좋았다고 합니다.
Conclusion
퀴즈에 대한 정답은 A와 C는 정배속이고, B는 2배속입니다. 틀리셨다면 논문의 학습 방식에 대해 동의하신 겁니다. 저도 틀리고 이해해버렸습니다. 실험에서 살-짝 아쉬운게 있는데, 실험 시간이 부족해서 이렇게 마무리 한 느낌도 들어서 이해가 됩니다. 좋은 논문이네요.
안녕하세요. 리뷰 잘 보았습니다.
궁금한 점이 있어 질문 남깁니다.
확신도 관점에서 s_{it}가 s_{jt}보다 클 수 밖에 없으며 그 이유로 i번째 transformation은 i번쨰 클립에 적용되었기 때문에, 다른 클립은 i번째 transformation에 대한 확신도가 낮게 나오기 때문이라고 하셨습니다.
그렇다면 이 transformation이라고 함은 항상 순서가 정해져있는 것인가요?
가령 temporal transformation이 M개가 있다고 했을 때 항상 이 {T_{1},…,T_{M}이 고정되어 있어서 N개의 clip에게 일정한 인덱스 순서대로 변형을 가하는 것인가요?
(즉 1번째 clip은 T_{1}번째 transformation을, i번째 clip은 T_{i}번째 transformation으로 변환)
근데 그렇게 되면 왜 clip은 N이고 transformation은 M개가 되버려서 1대1 매칭은 안될 것 같고.. 결국은 Clip보다는 transformation의 길이M이 더 작을 것 같으니 변형이 중복되는 상황이 발생할 것 같은데, 이 경우에 제일 처음에 얘기한 i번째 변환이 i번째 클립에 적용되었기에 j번째 클립은 i번째 변환에 대한 확신도가 낮게 나온다 라는 가정이 틀리게 되지 않나요?
아니면 clip의 개수 N이 transformation의 길이 M보다 더 작아서 각 클립별로 고유의 transformation을 적용해줄 수 있기에 위의 가정이 성립되는 것인가요?
그리고 추가적으로 이러한 transformation은 매 배치마다 무작위하게 변형이 되는 것이지요? 즉 1번째 transformation이 2배속이었다면 다음번 배치에서의 첫번째 transformation은 4배속으로 시작한다는 등..
그리고 temporal 관점에서 transformation은 단순히 영상 speed말고 또 다른 것은 없는지 궁금합니다.
마지막으로 spatial transformation에 대하여 aspect ratio와 rotation을 예측한다고 하셨는데, 사실 영상 도메인에서는 이러한 pretext task가 매우 단순하고 17~19년도 사이에 나왔던 오래된 기법들이어서.. 왜 저자는 아직도 이런 단순한 기법들을 본인들의 loss에 사용했던 것일까요? 비디오 도메인에서는 이러한 pretext task를 아직도 많이 사용하는 편인가요?
우선 Trasnformation 자체의 순서는 고정되어 있습니다. [표 3]을 보면, 어떤 Transformation이 적용되는지 확인해볼 수 있고요. 근데 구조상 순서가 바뀐다고 할지언정 학습에 방해가 될 부분은 없는 것 같습니다. 무작위 변형이라고 할지언정, 확신도 관점에서는 바뀔 부분이 없는 것 같네요.
문제는, 가정이 틀리게 되냐는 질문인데요… 정민님이 질문해주신 부분에 대한 자세한 설명이 없네요 ㅎㅎ;; 구현 디테일의 부분이라 코드를 봐야 알겠는데 코드도 없어서… 제가 답변 드릴 수 있는 내용이 없네요. 근데 정민님이 말씀하시는 것과 같이 N==M이어야 기대한 효과를 얻을 수 있어보입니다.
Temporal Transformation에서 Speed 말고 원래는 다른 종류가 몇개 있는데요. 여기서 쓰는 Ranking Loss가 상대적인 차이만 발생해야하는거라 적합한게 없었나봅니다. (Shuffle 같은게 있는데 이 논문에서는 성능 떨어져서 사용 안함)
영상 기반에서 aspect ratio와 rotation을 아직도 많이 씁니다. 오래되긴 했는데, 사실 제가 이미지 단위 논문을 안읽어서 ㅎㅎ;; 더 좋은게 있는지 모르겠습니다. 그리고 무엇보다 이 논문이 “학습 방식”에 대한 논문이라서 transformation의 독창성이 있을 필요는 없어서 다루지 않은 걸수도 있습니다.
안녕하세요. 이광진 연구원님.
좋은 리뷰 감사합니다. pretext task 기반의 방법이 성능이 낮지만, contrastive learning 기반의 방법과는 다른 장단점이 있지 않을지 의심하고 접근한 것이 흥미로운 논문이네요…
약간 헷갈리는 부분이 있어 질문드립니다.
TransRank에서 영상이 절대적으로 몇 배속인지가 아니라, 어떤 영상에 비해 상대적으로 몇배속인지 맞춘다고 하셨는데, 그럼 [그림3]과 같이 세가지로 변형된 영상이 입력되었을 때, 각 영상이 무조건 그림과 같이 1배속 하나, 2배속 하나, 역재생 하나가 있어서 분류를 수행하는 것인가요? 혹은 같은 변환이 적용된 영상이 여러 개 존재할 수도 있는 것인가요?
감사합니다.
여러개 있으면 안될 것 같은데, 논문에 관련 내용이 없네요. 자세한 부분은 정민님 질문과 제 답변 같이 보시면 좋을 것 같습니다.
안녕하세요 좋은 리뷰 감사합니다.
기존 방법론에서는 일반적인 정보와 인스턴스간의 차이를 통해 변환 정보를 예측했다면, 해당 방법론은 대조군으로 인스턴스 영상 스스로를 사용하여 예측을 더 명시적으로 진행할 수 있게 도운것으로 이해했습니다. 그렇게 했을 때 성능이 개선되었다니 정말 흥미롭네요.
혹시 레퍼런스 등으로 이러한 방식 (명확한 대조군을 제시한다던가, self information 참조) 관련하여 도움을 받은 논문, 인사이트의 출처등이 공개가 되어있는지요?
감사합니다
이 학습 방식으로 하자는게 contribution이라, 출처가 없습니다.
안녕하세요 좋은 리뷰 감사합니다.
이전에 해당 분야를 follow-up 했을 때 22년도 방법론부터는 거의 전부다 contrastive learning scheme이라 완전히 넘어온 줄 알았는데, 새로운 시각의 논문이 등장한 것이 인상깊네요.
혹시 그림 3과 관련된 설명을 해주실 때, 매트릭스에는 유사도가 아니라 각 transformation에 대한 확신도가 들어간다고 말씀해주셨는데, 이전에 다른 방법론 중 유사도를 활용하는 방식이 있었나요?
또한 K200 데이터셋으로, 규모가 좀 작긴 하지만 본 방법론의 경우 학습 시간이나 GPU 개수가 공개되어있는지도 궁금합니다.
제가 못봤을 수도 있긴 한데요 유사도로 하는 방식도 없었고, 이렇게 하는 방식도 없었습니다. 보통은 그냥 CE Loss 쓴다고 보면 됩니다. 흠… 학습 시간이나 GPU 갯수등은 공개가 안되어있네요. 일단 모델 자체도 간단하고, 다른 방법론보다 적은 데이터셋을 쓰니까 더 빠르긴 할겁니다. 보통은 [표 7]의 괄호 안이 학습 시간이었던 것 같은데, 여기는 명확하게 안적혀있긴 하네요.