
안녕하세요.
segmentation 논문을 계속해서 들고 오다가 산자부 과제를 본격적으로 시작해야 해서 OCR 논문을 읽게 되었습니다.
사실 오늘 리뷰할 논문은 저번주에 윤서님이 리뷰한 논문과 동일합니다.
그럼에도 제가 해당 논문을 리뷰한 이유는 아래와 같습니다.
- 산자부에서 수행해야 하는 task는 character 단위로 직사각형 bbox를 예측하는 것이며, 이때 rotation 정보도 함께 예측해야 합니다.
본 논문의 경우 word 단위로 rotation을 고려한 직사각형의 bbox를 예측합니다. - OCR 논문들은 코드 공개가 거의 되어있지 않습니다.
과제 수행에 있어서 코드작업을 해야 하는데 대부분의 논문들의 코드가 공개되어 있지 않습니다. Task의 특성인가 봅니다. 하지만 본 논문은 unofficial 코드이긴 합니다만 누군가가 구현해 놓은 코드가 있어서 해당 논문을 base로 선정할 계획입니다. 그렇기 때문에 본 논문을 선정하게 되었습니다.
아무튼 뭐 위의 이러한 이유 때문에 윤서님이 리뷰한 논문인데도 불구하고 한번 읽어보고 리뷰를 하게 되었네요..ㅎ 그럼 리뷰 시작하겠습니다.
1. Introduction
제목에서도 알 수 있다시피 본 논문은 text spotting이라고 하는 task를 수행합니다.
text spotting은 text detection + text recognition 을 둘 다 수행하는 것입니다.
주어진 이미지에서 text 에 해당하는 영역을 detect 하고, 어떤 text인지 recognition까지 하는 것이죠.
본 논문이 게재된 2018년을 기준으로 이전 대부분의 방법론들은 detection과 recognition을 구분해서 2개의 분리된 task로 바라보았습니다. 그렇기 때문에 해당 방법론들의 모델은 detection과 recognition을 수행하는 모델을 따로 구성하는 방식이였고, detection과 recognition 학습 과정에서 서로가 주고 받을만한 시각적인 공통적 특징들을 무시한다는 한계점이 존재하죠. 그리고 end-to-end 학습도 불가능하구요.
그렇기 때문에 2018년도쯤 부터 본 논문 뿐만 아니라 mask textspotter 등 다른 여러 논문들에서 detection과 recognition을 동시에 수행하는 end-to-end 학습 파이프라인이 제시되었습니다. 이전 학습 모델들과 비교했을 때 end-to-end의 학습이 가능하다는 장점이 존재하며, detection과 recognition을 수행할 때 필요한 feature extraction 을 하나의 encoder로 수행함으로써 두 task의 correlation을 고려해서 특징을 더 잘 추출할 수 있게 되었습니다. 말이 조금 복잡할 수 있는데, 그냥 하나의 encoder로 feature를 추출해서 해당 feature를 detection과 recognition에 동일하게 사용한다는 말입니다.
또한 두 과정을 한번에 수행함으로써 속도 측면에서도 훨씬 더 빨라진 것을 아래 그림 1 을 통해 확인할 수 있네요.
추론 시간이 약 절반 가까이 줄어든 이유는 아무래도 encoder를 통과하는 과정이 기존 2번 -> 1번으로 줄어들었기 때문이라고 볼 수 있겠네요.

본 논문에서 제안한 end-to-end architecture 그림은 아래 Method 섹션에서 설명 드릴 예정이고,
우선 본 논문의 contribution을 말씀드리고 Introduction을 마무리 짓겠습니다.
<Contribution>
- end-to-end로 학습이 가능하고, 회전(orientation)을 고려했으며, 추론 시 빠르게 동작하는 text spotting 모델을 제안
– 하나의 encoder로 feature extraction을 수행한 후 detection과 recognition을 동시에 수행하기 때문에 real-time으로 동작 - RoIRotate 를 설계함.
– encoder를 통과한 feature map에서 회전된(oriented) text 영역을 추출하기 위함이며, 해당 과정을 통해 end-to-end로 한꺼번에 학습이 가능해짐.
– (Method 에서 설명드리겠습니다.) - ICDAR 2015, ICDAR 2017 MLT, ICDAR 2013 데이터셋에서 detection과 spotting 성능으로 SOTA 달성
2. Method
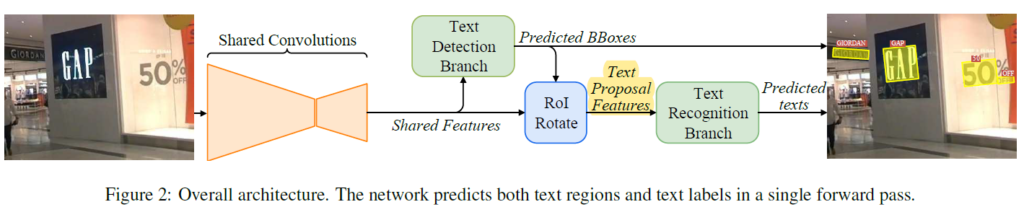
본 모델의 전체 구조는 크게 아래의 4가지로 나눠서 살펴볼 수 있습니다.
- Shared Convolutions
- Text Detection Branch
- RoIRotate
- Text Recognition Branch
4가지 구성 요소는 그림 2의 모델 전체 구조에 하나씩 대응됩니다.
이 중 Text Detection Branch 에 사용된 모델은 Text Detection 을 수행하는 ‘[CVPR 2017] EAST: An Efficient and Accurate Scene Text Detector’ 논문의 내용을 대부분 그대로 사용하였습니다.
그럼 4가지를 순서대로 설명 드리도록 하겠습니다.
2.1. Shared Convolution
위 그림 2의 모델 전체 구조에서 Shared Convolutions 그림을 보시면 Feature Extraction을 수행하는 Encoder 말고도 뒤쪽에 조금 더 shallow한 decoder가 붙어 있는 것을 보실 수 있습니다.
해당 구조를 조금 더 자세하게 그려놓은 것이 아래의 그림 3 입니다.
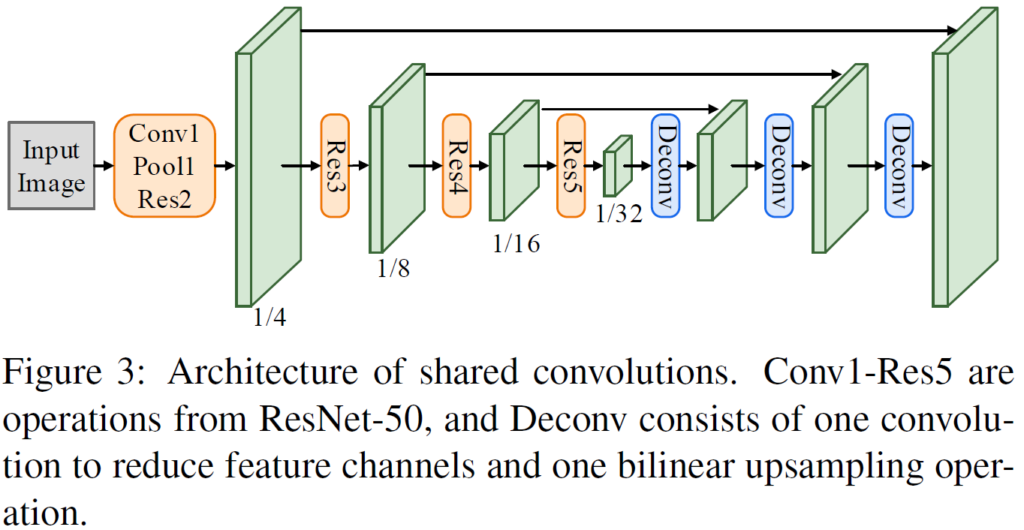
사실 뭐 거창해 보이지만 별거 없습니다.
주황색으로 색칠한 부분은 그냥 5개의 층으로 구성된 ResNet-50 백본을 나타내는 것이구요,
FPN(Feature Pyramid Network)에서 영감을 받아 3개의 층으로 구성된 Deconv 연산을 추가적으로 구성한 것입니다.
해당 과정에서 Low level feature와 High level feature를 concat하여 multi scale을 고려한 feature를 생성함으로써 좀 더 풍부한 정보를 가지는 feature를 생성할 수 있습니다.
위 Shared Convolution 과정을 통해 결과적으로 기존 이미지 대비 1/4 작아진 feature map을 생성할 수 있게 됩니다.
그렇다면 왜 굳이 3번의 deconv를 통해 기존 이미지 대비 1/4 사이즈의 feature map으로 upscaling을 하는 것일까요? 그냥 Encoder만 통과 시켜서 1/32 사이즈의 feature map을 사용하면 안될까요?
이는 OCR task 자체의 특수성(?) 때문입니다.
CNN의 receptive field적인 관점으로 바라보면 high level feature 대비 low level feature의 receptive field가 더 작습니다. 그리고 OCR은 보통 natural scene이나 영수증 등의 상황에서 작은 text box를 검출하고 인식하는 것이지요.
이렇게 작은 text box가 대부분인 OCR의 특수성을 고려해서 FPN 구조를 추가해서 3번의 deconv를 통해 조금 더 upscaling 된 feature map을 생성하게 되는 것입니다.
2.2. Text Detection Branch
다음은 Text Detection 과정입니다.
위의 Shared Convolution 을 통해 추출된 feature를 가지고 detection을 수행하는 것이죠.
모델 구성은 아주아주 간단합니다. 놀랍게도 아래와 같이 그냥 1개의 conv layer만을 사용했습니다.
nn.Conv2d(256, 6, kernel_size=1)
그렇다면 detection branch의 출력은 왜 6채널 일까요?
이는 아래 그림을 통해서 명쾌하게 이해할 수 있습니다.
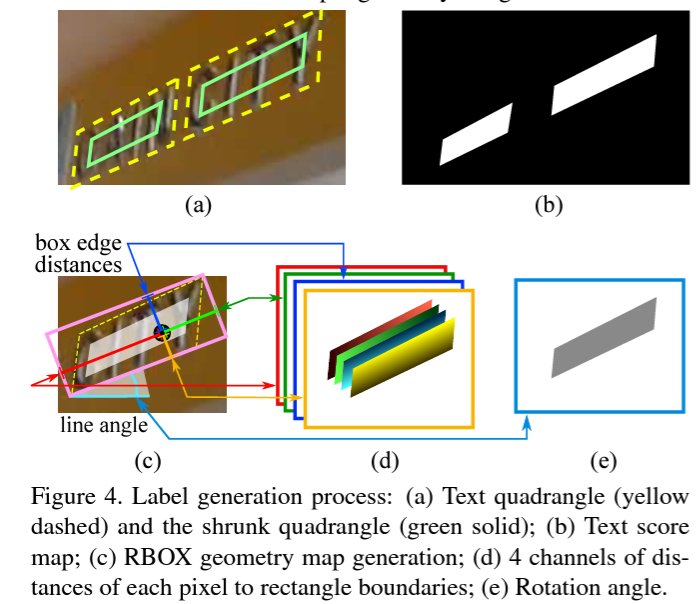
i) Pixel-wise Score Map: 1채널 – (Classification)
그림 4-(a) 에서 노란색 점선 박스는 gt bounding box를 의미합니다.
그러면 내부에 있는 저 연두색 실선 박스는 무엇일까요?
이는 text 가 존재하는, positive area를 의미하며 shrunk(축소된) box 라고 칭합니다.
아래 식을 통해서 계산이 되며, p_i는 각 gt bounding box의 x 또는 y 픽셀 좌표라고 생각하시면 됩니다.
mod는 나눗셈 연산 후의 나머지를 뜻하며, D(p_i, p_j) 는 두 픽셀 사이의 L2 Distance 입니다.
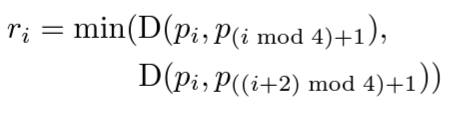
결론적으로 위 식을 통해 학습 데이터 셋의 gt bbox에 대해 1대1로 매칭되는, 실제 text 가 존재하는 positive 영역을 만들 수 있게 되고 이를 binary mask 형태로 시각화 한 것이 그림 4-(b) 입니다.
gt bbox로 부터 계산한, gt score map 이라고 부를 수 있으며 text 가 없는 negative 영역은 0, positive 영역은 1로 채워진 형태입니다.
그래서 결국 output 채널 중 첫 번째 채널에서는 이 score map을 pixel-wise로 예측하게 됩니다. 각 픽셀별로 positive 영역인지 아닌지의 확률을 예측하게 되고, gt score map과 loss를 계산하게 되죠.
ii) Pixel-wise Box Edge Distance: 4채널 – (Regression)
output 채널 중 4개의 채널은 각 픽셀별로 gt bbox의 각 edge(상,하,좌,우) 와의 거리를 예측하게 되며 의 위 그림 4-(c),(d)를 보시면 됩니다. (c)에서 한 픽셀을 기준으로 상,하,좌,우 edge와의 거리를 계산하는 것이 보이실 겁니다.
본 논문의 경우 사각형의 bbox를 예측하기 때문에 4개의 채널로 예측을 수행하게 되지만, 어떤 shape의 box를 쓰는지에 따라 채널 수를 조정하면 됩니다.
해당 채널에서의 예측은 gt score map 의 positive 영역에 대해서만 예측이 수행됩니다!
text가 아닌, background 영역에 대해선 box 정보를 예측할 필요가 없기 때문이죠.
iii) Pixel-wise Angle(Rotation) Map: 1채널 – (Regression)
그리고 마지막 채널은 각 픽셀별로 bbox의 회전 각도를 예측하는 채널입니다.
해당 채널도 마찬가지로 gt score map 의 positive 영역에 대해서만 예측이 수행됩니다!
그리고 bbox 생성 시 예측 시 gt positive 영역에 대해 에 대해 thresholding과 NMS를 적용해서 detection 결과를 예측하게 됩니다.
그런데 여기서 저자들은 실험 도중 울타리, 격자처럼 text와 비슷한 패턴을 가진 영역에 대해 positive, negative를 분류하기 어려워 한다는 점을 문제점으로 꼽았습니다. 그리고 이를 해결하기 위해 OHEM(Online Hard Example Mining) 이라고 하는 알고리즘을 적용하였습니다.
OHEM 알고리즘은 전체 sample 중 모델이 제일 헷갈려 하는 Hard Sample을 선정하는 방식이고, 해당 설명은 백 병장의 훌륭한 리뷰 로 대신하겠습니다. OHEM의 적용을 통해 결국 저자는 비슷한 패턴을 가진 영역에 대한 분류 성능을 올렸고, class imbalance 문제도 해결했다고 하네요. 또한 ICDAR 2015 dataset에서 F-score 기준 2% 향상도 이뤘다고 합니다.
그럼 이제 위에서 얻은 정보들을 바탕으로 학습 loss를 설계해야겠죠.
Detection Branch의 loss는 크게 Classification loss와 Regression loss로 나뉠 수 있습니다.
1 채널 Pixel-wise Score Map 은 결국 픽셀별로 positive 영역인지 아닌지의 확률을 예측하는 것이기 때문에 binary classifiaction loss에 사용되고, 나머지 두 정보는 Regression loss에 사용됩니다.
2.2.1. Classification Loss (Detection Branch)
두 정보(box, rotation) 가 GT score map 의 positive 영역에 대해서만 예측이 수행되는 것과 달리,
score map 예측의 경우 이미지 내 모든 픽셀에 대해서 예측을 수행하게 됩니다.
그리고 여기서 score map loss를 계산할 때 이미지 내의 모든 픽셀에 대해 계산하는 것이 아니라 GT score map(그림 4-(b)) 를 사용해서 “NOT CARE” 라고 하는 영역을 설정하고 이에 대해선 loss 계산 수행을 하지 않게 됩니다. “NOT CARE” 영역은 그림 4-(a) 에서 노란색 점선 박스(gt bbox) 와 초록색 실선 박스 (gt score map) 사이의 공간을 의미합니다.
그리고 여기서 OHEM 알고리즘을 통해 “NOT CARE” 영역을 제외한 pixel sample 중 1:3으로 positive와 negative 의 비율을 맞춰서 classifition loss를 구성했다고 합니다.
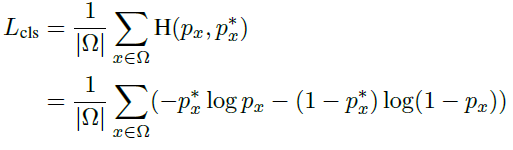
- \Omega: OHEM에 의해 결정된, loss 계산에 반영되는 pixel sample들의 집합
- |\Omega|: 집합 \Omega의 element 수
- H(p_x, p^∗_x): p_x, p^∗_x 사이의 cross-entropy loss
- p_x: score map 예측 결과
- p^∗_x: GT score map (그림 4-(b)), (0과 1로 구성된 binary map 형식)
2.2.2. Regression Loss (Detection Branch)
regression loss는 bbox 예측값으로 계산되는 IoU loss와,
angle 예측값으로 계산되는 rotation angle loss의 조합으로 구성됩니다.
그리고 1:3으로 positive와 negative를 맞춰줬던 Classification에서의 OHEM과는 달리,
Regression Loss에 사용되는 OHEM의 경우 positive sample 만을 사용하게 됩니다.
즉 다시 말해 “NOT CARE” 영역만 제거해서 loss를 계산했던 classification loss 와는 달리,
“NOT CARE” 영역과 negative 영역을 모두 제거한, 즉 그림 4-(b)의 gt score map 영역에 대해서만 loss를 계산한다는 뜻입니다. 실질적인 bbox의 regression이 수행되어야 하기 때문에 negative 영역에 대해선 학습이 진행되면 안되겠지요.
loss 식은 아래와 같습니다.
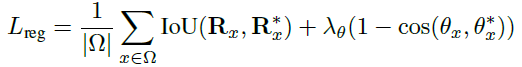
- R_x: 예측한 bounding box
- R^*_x[/latex : gt bounding box</li><li>[latex]θ_x: 예측한 orientation(회전) 정보
- θ^*_x: gt orientation(회전)
++ Detection Loss와 Regression Loss에 적용되는 OHEM에 대한 차이는 제가 잘못 이해하고 있는 부분이 있을 수도 있겠단 생각이 들어서 원문으로 대체하겠습니다.
As described in Sec. 3.2, we adopt OHEM for better performance.
For each image, 512 hard negative samples, 512 random negative samples and all positive samples are selected for classification. As a result, positive-to-negative ratio is increased from 1:60 to 1:3.And for bounding box regression, we select 128 hard positive samples and 128 random positive samples from each image for training.
그리고 위의 두 loss를 결합한 Detection Branch의 최종 loss는 아래와 같습니다.
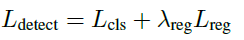
2.3. RoIRotate
2.2. 의 Detection Branch에서 예측한 RoI Detection 결과에 대해 rotation을 수행하는 RoIRotate 단계입니다.
예측한 RoI 영역들의 경우 각각 자신만의 각도로 회전된 상태일테고, Shared Convolution을 통과한 feature map에서도 동일한 각도로 회전되어 있을 것입니다. 이렇게 회전된, oriented feature region을 특정 축을 기준으로 고정해주는 과정이 필요하고 이를 수행하는 것이 RoIRotate 입니다.
아래 그림 5를 보시면 직관적으로 이해하실 수 있습니다.

본 논문에서 설계한 RoIRotate의 경우 text 길이가 모두 상이하다는 점을 고려하여 height를 고정하고, 비율은 변경하지 않는 방식을 채택했습니다. RoI 영역의 비율을 변경하지 않고 보간법을 통해 output을 계산하는 방식을 통해 타 RoI pooling이나 RoI align 방식과 비교했을 때 다양한 길이의 text recognition에 유리할 뿐더러 RoI와 feature 사이의 misalignment도 방지할 수 있다고 합니다.
텍스트 길이가 각자 다르기 때문에 가장 긴 텍스트에 맞춰서 width를 설정한 뒤 공백에 대해서는 padding을 씌워줍니다. 그리고 이렇게 padding이 적용된 영역은 loss 계산을 무시합니다.
RoIRotate 는 크게 2가지 스텝으로 나뉘어집니다.
- Detection Branch의 예측 좌표 또는 gt bbox 좌표 값의 좌표 정보와 rotate 정보를 통해서 affine transformation parameter 구하기
- 구한 affine transformation parameter를 shared feature map에 적용해서 정렬된 feature region 만들기
결국 위 과정을 통해 수행하고자 하는 것은 shared feature map에서 oriented 된 여러 feature region을 동일 height를 가지고 그림 5처럼 회전 각도도 정렬 된 feature region을 얻고자 하는 것입니다.
여기서 핵심은 Detection Branch 에서 proposal된 영역을 transformation 하는 것이 아니라, shared feature map을 transformation 한다는 것입니다.
또한 affine transformation parameter 를 구할 때 Detection Branch의 예측좌표와 gt bbox 좌표 사이의 transformation 을 계산하는 것도 아닙니다. 아래 식을 통해서 설명드리겠습니다.
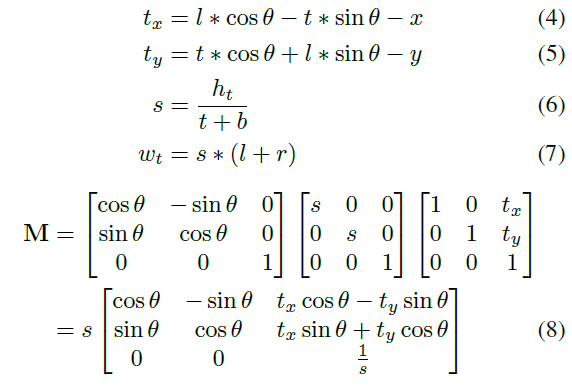
- M : 구해야 하는 affine transformation matrix
- h_t : affine transformation 이후 feature map의 height
- w_t : affine transformation 이후 feature map의 width
- (x, y) : shared feature map의 좌표
- (t, b, l, r) : text proposal과 상하좌우간의 각 거리 / gt box로도 가능
- θ : 회전정보
본 논문에서 최종적으로 RoIRotate 를 통해 수행하고자 하는 것은 encoding 을 수행 한 shared feature map에서 text 가 있을 만한 region에 해당하는 feature 영역을 변환하는 것입니다. affine transformation matrix를 적용해서 말이죠.
그리고 이 affine transformation matrix에는 rotation, scaling, tranlation 정보가 필요합니다.
우선 식 (4),(5)는 translation 정보를 계산하기 위한 식입니다.
shared feature map 내의 임의 점 (x,y)에 대해서 계산한다고 가정하겠습니다.
(x, y) 좌표에서 예측한 text proposal이 있을 것이고 이때의 정보를 (t, b, l, r), θ 라 하겠습니다.
여기서 우리는 이 text proposal 영역을 crop 해서 잘라내고 평행이동과 회전을 시켜서 특정 축(y축) 을 기준으로 정렬해야 합니다. 평행이동을 한다는 말은 다시 말하면 기존 text proposal 좌상단의 좌표를 0,0으로 보내겠다는 말이 되겠죠? 회전은 말 그대로 회전이구요.
이를 식으로 녹여낸 것이 (4),(5) 입니다.
현재 (x,y)라는 좌표는 원점이 share feature map 전체의 좌상단을 기준으로 표기가 된 것입니다. (in 원점좌표계)
만약 text proposal 좌상단을 (0,0)로 설정해서 (x,y) 좌표를 box 좌상단 기준 좌표계로 표현하면 어떻게 표기될까요? (l,t) 가 됩니다. detection branch에서 예측하는 l과 t 값이 무엇인지 복기해보시면 이해가 수월하실겁니다.
아무튼 정리하자면 식 (4),(5)는 text proposal 좌상단의 좌표를 (0,0)으로 만들어주기 위한 tranlation value를 구하는 식이 됩니다.
(해당 블로그의 그림을 참고하시면 이해에 용이하실겁니다)
그리고 식 (6)과 (7)은 scale 과 관련된 값입니다.
본 논문에서는 h_t를 8로 세팅했기 때문에 그에 맞게 scale 값이 계산되어서 transformation matrix 계산에 반영이 되게 됩니다.
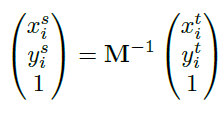
그리고 위 식을 통해서 앞서 구한 affine transformation matrix 인 M의 역행렬을 곱해주게 됩니다. shared feature map의 (x,y)라는 좌표에 말이죠.
그림 5의 좌상단에 있는 TEMT 라는 글씨를 기준으로 affine transformation 과정을 한번 생각 해 봅시다.
육안으로 봤을때 수행한 과정은
text proposal 영역만큼 자르기 =>y축 기준으로 회전(angle 0으로 만들기) =>height를 8로 설정하기(with scaling) => 원점 이동(좌상단을 0,0으로 만들기!!)
뭐 이정도가 되겠네요.
text proposal 영역만큼 자르는 건 그냥 예측한 bbox 의 좌표값으로 자르면 되는것이고, 뒤에 따라오는 3가지 과정은 각각 식 4의 M을 구성하는 3가지 구성요소 입니다.
결국 지금까지의 과정을 다시 짚어보면
i) Detection Branch에서 이미지가 입력으로 들어왔을 때 서로 다른 크기와 각도를 가지는 여러 text proposal들을 detect
ii) RoIRotate 과정을 통해 서로 다른 크기와 각도를 가지는 여러 text proposal 들을 동일 크기, 각도로 만들기.
뭐 이런 과정을 수행한 것입니다.
2.4. Text Recognition Branch
다음은 Recognition 입니다.
위의 ii) 과정을 통해 동일 크기를 가지는 text proposal 에 해당하는 shared feature 를 구했을겁니다. 요 녀석의 height는 8이겠죠.
아무튼 해당 feature는 최종적으로 Recognition Branch를 통과하게 되는데 과정은 아래와 같습니다.
- VGG-style sequential conv
- height 축으로만 축소가 일어나는 pooling
- one bi-directional LSTM
- one fully-connection layers
- CTC decoder
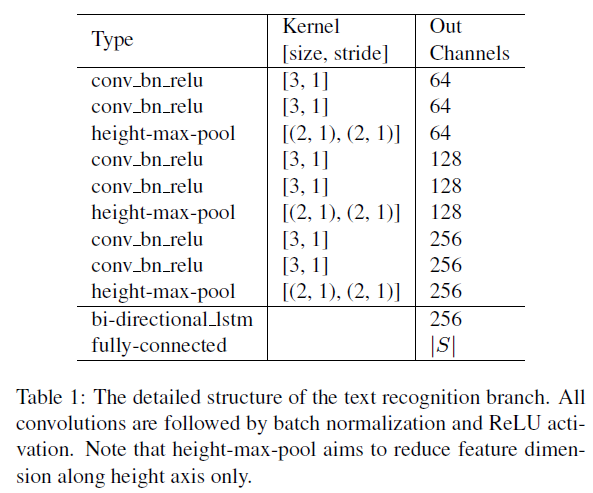
사실 본 논문에서 recognition 모델의 구조를 새롭게 설계한 건 아니고
'[TPAMI 2016] An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition'
논문의 구조를 그대로 차용한것입니다.
동작 과정에 대해 설명드리면 우선 text proposal 에 해당하는 shared feature가 sequential하게 구성된 conv_bn_relu 와 height 축으로의 maxpool 과정을 통해 점차 high level feature를 얻게 됩니다.
위 과정까지 수행했을 때 feature map의 shape을 B,C,H,W 라고 합시다.
이를 RNN 기반의 모델인 bi-directional LSTM의 입력으로 넣기 위해 B,C,H의 shape을 가지는 l1,,,lw 의 feature vector로 재구성 합니다.
앞, 뒤 정보를 함께 고려하여 recognition을 수행하는 task의 특성 상 bi-directional LSTM을 사용했다고 합니다,.
이후 fc layer 를 통과해서 채널 수가 S로 바뀌게 되는데 이는 character의 전체 class 수 입니다.
영어 알파벳 수 + 숫자 수 등 어떤 언어를 예측하느냐에 따라 다르게 세팅되겠죠. 각 채널별로 어떤 character인지의 확률을 output으로 내보내게 됩니다.
이제 마지막으로 CTC 알고리즘을 적용해야 하는데요,
이는 text or speech recognition에서 많이 사용된다고 합니다.
이는 아래 그림 6에서 잘 나타내줍니다.

예를들어 우리가 예측해야 하는 text가 hello 였다고 가정해봅시다.
하지만 hello 뿐만 아니라 다른 다양한 길이를 가지는 text들이 존재할테고, 아까 RoIRotate에서 이들의 width를 고정해준다고 했습니다.
즉 가장 긴 text를 기준으로 width값이 설정되어있을테고, 위의 경우엔 fc layer를 통과해서 나온 최종 output이 "hello" 가 아니라 "hhe lll llo" 입니다. 이를 실제의 text recognition 결과로 바꾸기 위해서 CTC 알고리즘이 적용되는것입니다.
공백을 고려하여 중복을 없애주면 최종적으로 hello 라고 하는 결과가 도출됩니다.
(+여기서 부가적으로 width를 더 잘게 나누면 정확한 예측이 수행되지 않을까 생각이 드네요)
어쨋든 위의 이러한 과정을 통해 최종적으로 Text Recognition까지 수행할 수 있게 됩니다.
그러면 다음으로는 Recognition Branch에 적용되는 loss에 대해 알아봅시다.
2.4.1 Recognition Branch Loss
우선 CTC 알고리즘을 통과한 최종 output은 S라는 전체 character 수에 대한 확률을 채널축으로 가지는 어떠한 확률분포일것입니다. 이를 x라고 하고, gt label을 y^*라고 했을 때 y^*에 대한 조건부 확률을 아래 형태로 정의할 수 있습니다.
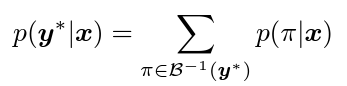
그리고 식 6을 사용해서 이의 log likelihood의 합을 최대화하는 방향으로 학습을 진행하도록 설계한 recog loss가 식 7입니다.
(아직 Text Recognition 분야의 loss 계산에 대해 공부가 부족하여 설명이 빈약합니다. 다음 리뷰에선 더 보충하도록 하겠습니다)
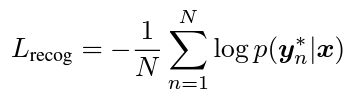
- N: 입력 이미지 내 text regions의 수
- y_n^*: Recognition Label (gt)
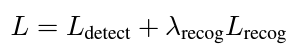
그리고 앞선 2.2절의 Detection Branch Loss와 방금 설명드린 Recognition Branch Loss를 더해서 최종 end-to-end 학습을 위한 Loss를 설계합니다. 여기서 \lambda_{recog} 는 1로 세팅했다고 합니다.
3. Experiment
3.1. Datasets
Synth800k
약 800,000장의 규모로 이루어진 합성 dataset입니다.
실제 real 자연 이미지에 합성으로 text를 붙여 넣어서 구성하였다고 합니다. 아래처럼 말이죠.
보통의 벤치마킹 datasets의 경우 띄워쓰기를 기준으로 word 단위의 annotation 만을 수행하는데,
본 dataset은 word 뿐만 아니라 개별 글자인 character 단위로도 annotation을 제공하곤 합니다.
(그렇기 때문에 character 단위의 검출을 수행하고자 하는 연구, 프로젝트에서 활용 가치가 있죠)
또한 위 dataset은 Real Driving Scene이나 표지판 등 실제 OCR이 적용될 만한 곳과는 도메인의 차이가 꽤나 존재합니다. 그 대신 800,000장이라고 하는 어마무시한 규모를 자랑하죠.
그래서 대부분의 Text Spotting task에서는 위 dataset을 pre-training 용으로 사용하게 됩니다.
우선 모델을 1차적으로 ImageNet Pretrained 시키고,
2차적으로 위 Synth800k Dataset을 사용해서 중간 train 시킨 다음에,
마지막으로 풀고자 하는 도메인 dataset으로 fine-tuning 하는 방식으로 말이죠.
아래에 설명드릴 dataset이 흔히들 벤치마킹 하는 dataset 입니다.
(++이렇게 pretrain 용도로 사용되다 보니 특별히 train과 test로 split 되어있지 않습니다.)
ICDAR 2013

229장의 학습 이미지, 그리고 233장의 테스트 이미지로 구성되어 있습니다.
ICDAR 2015, ICDAR 2017과 달리 본 dataset은 회전 정보가 반영되어있지 않고, 오로지 horizontal한 text만을 보유하고 있습니다.
그리고 이 Dataset은 lexicon(사전) 이라고 불리는 txt 파일을 제공하며 이는 그 수에 따라 "Strong", "Weak", 그리고 "Generic" 으로 구성됩니다. 그리고 아래 평가 Table을 보시면 아시다시피 S, W, G에 따라 성능을 각자 다르게 리포팅 한 것을 볼 수 있습니다.
Strong은 학습, 평가 이미지에 존재하는 모든 단어 정보를 가지고 있고,
Weak은 평가 이미지에 존재하는 모든 단어 정보를 가지고 있으며,
Generic은 90,000개의 단어 정보를 가지고 있습니다.
lexicon(사전)은 평가 단계에서 적용이 되는 기법인데, 사전에 들어있는 모든 단어에 대해 식 6의 조건부 확률을 계산하고 가장 높은 확률(가능성)을 가지는 단어를 예측으로 삼는 것입니다.
Strong->Weak->Generic으로 갈 수록 포함하는 단어 수가 적어지기 때문에 그에 따라 성능도 감소하겠죠.
다만 Strong일 경우 모든 단어에 대해 조건부 확률을 계산해야 하기 때문에 시간이 오래 소요된다는 단점이 존재합니다.
ICDAR 2015

1000장의 학습 이미지, 그리고 500장의 테스트 이미지로 구성되어 있습니다.
ICDAR 2013과는 다르게 oriented(회전) text 를 포함하고 있구요.
그리고 해당 dataset도 "Strong", "Weak", 그리고 "Generic" 의 3단계로 구성된 lexicon이 존재합니다.
ICDAR 2017 MLR

ICDAR 2017 MLR 데이터셋은 작은 규모를 가진 앞선 두 데이터셋과는 달리 7200장의 학습이미지, 1800장의 검증이미지, 그리고 9000장의 평가 이미지로 구성되어 있습니다. 또한 9개의 다국어 언어 text로 구성이 되어있구요.
물론 oriented(회전) text 도 포함하고 있습니다.
다만 위 데이터셋의 경우는 다국어 언어로 구성되어 있기 때문에 text spotting 벤치마크는 진행되고 있지 않고, detection에 대한 벤치마킹만 진행되고 있다고 합니다.
3.2. Text Spotting Experiment
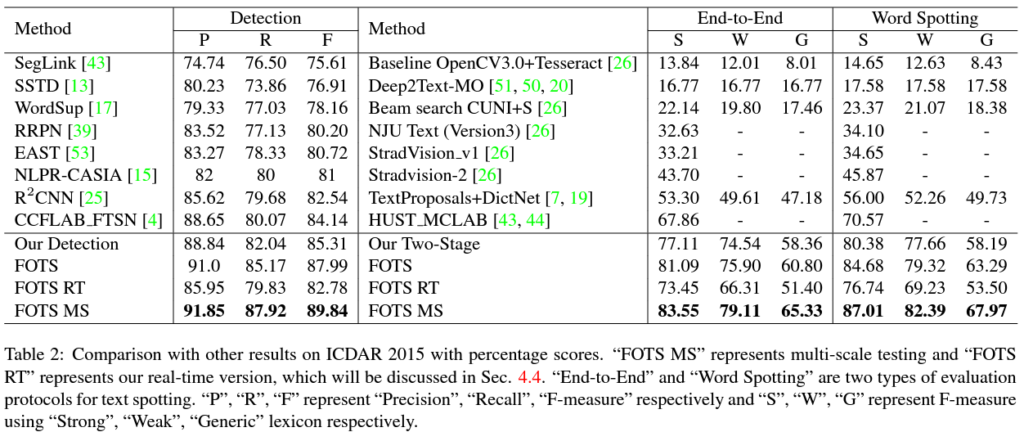
좌측 Detection 성능과, 우측 Spotting 성능이 리포팅되어 있습니다.
Detection의 경우 P: Precition, R: Recall, F: F-measure 뜻하고,
Spotting 성능에서 S, W, G는 위에서 말씀드린 lexicon중 Strong, Weak, Generic을 각각 사용한 결과입니다.
아무래도 Strong이 가장 많은 단어를 포함한 lexicon(사전) 이기 때문에 성능이 제일 높네요. 속도는 그만큼 떨어지겠지만요.
본 방법론은 end-to-end 방식인데도 불구하고 기존의 2-stage 방법론 대비 높은 성능 향상을 보여주고 있습니다.
Ours 방식 중 FOTS RT는 속도측면에서 향상을 보기 위해 backbone을 ResNet-50 => ResNet-34로 변경한 것을 의미하고, FOTS MS 는 단일 scale이 아닌 multi-scale에서 예측을 수행 한 결과입니다.
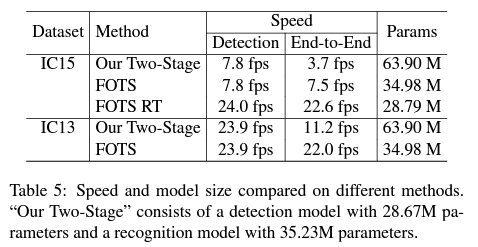
위에서 말씀드린 FOTS RT의 속도와 parameter 수 비교입니다.
2 stage->1 stage로 변경하면서 parameter는 절반가량 감소하였네요. feature를 추출하는 encoder를 detection과 recognition 모델이 share 하게 되었기 때문이죠.
그리고 이에 따른 속도 향상도 인상적입니다. 특히 FOTS -> FOTS RT로 단순 백본만 가볍게 변경했음에도 속도가 약 3배가량 빨라졌네요.

저자들이 제안한 FOTS 방법론은 기존의 Detection Encoder와 Recognition Encoder를 하나로 통합함으로써 모델의 parameter 수와 speed 측면에서 2배 가량의 향상을 이루었습니다.
이 뿐만 아니라 Detection 에서도 타 방법론보다 더 좋은 결과를 낼 수 있는데요, 이는 왜냐면 두 encoder를 share 함으로써 recognition을 통해 배울 수 있는 semantic한 의미적 정보와 character의 상세한 정보들이 detection에도 반영이 될 수 있기 때문입니다.
위의 정성적 결과를 보시면 이를 확인할 수 있고 Detection 오검출을 4가지 측면으로 나누어서 시각화 하였습니다.
- Miss: Text region을 검출하지 못함
- False: Text가 아닌 region을 Text로 오검출
- Split: Text region을 잘못 분할
- Merge: Text region을 잘못 합침
네, 이렇게 저의 OCR 첫 논문 리뷰를 마치게 되었습니다.
Text Spotting이라는 분야가 Detection과 Recognition으로 나누어 져 있고, 평가 방식 또한 쉽지가 않아서 꽤나 이것저것 많은 지식들을 기초적으로 요구한다고 느꼈습니다. 그래서 읽으면서도 다른 논문들을 참고하면서 읽느라 시간이 꽤나 걸렸네요,...
암튼 리뷰는 이렇게 마무리 하고, 산자부 dataset에 ocr 모델이 잘 동작했으면 좋겠습니다..
그럼 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
OCR Task에 대해 궁금했기에 재밌게 읽긴 했지만.. 생각보다도 더 어렵네요.
자세한 리뷰 덕분에 이해가 간 부분도 많았지만 전체적으로 쉽지 않았던 것 같습니다.
그래서 현재 하신다는 데이터 셋을 보았으니, 이에 대해 궁금증이 있습니다. 해당 논문에서 그리고 일반적으로 평가하는 데이터 셋에서는 그래도 일종의 큰 문자도 있고, 객체의 크기도 다양하지만 현재 하셔야 하는 일은 작은 객체와 작은 문자인데, 이런 특수한 경우에도 잘 작동하기 위한 어떤 방법론들이 현재 존재하는지 궁금합니다ㅎㅎ
사실 작은 text만을 위한, 혹은 작은 text를 잘 detect & recognize 하기 위한 그런 특수한 상황의 논문을 아직 찾아보진 않았습니다. 이번에 리뷰한 논문의 저의 거의 첫 ocr 논문이기 때문이죠….
그런 관점에서 어떤 방법론들이 존재하는지는 잘 모르겠지만, 저희 팀은 아마 RoI를 잘 찾아내는 방향으로 우선 초점을 잡을 거 같습니다. 그 과정에서 비록 학습이 2-Stage로 이뤄지더라도 말이죠.
혹여나 해당 RoI를 찾아도 해당 영역의 해상도가 너무 낮다면, 상인님께서 저번에 말한 super resolution도 적용해봐야하나,, 싶긴 한데,, 같은 small object(text) detection 을 수행해야 하는 만큼 활발한 의사소통을 하면 좋을듯 합니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
[그림 4]에 (a)에서 연두색 실선 박스는 text가 존재하는 positive area를 의미하는데, 애초에 노란색 점선 gt bbox가 text가 존재하는 영역을 담고 있는 것 아닌가요 ? shrunk box를 보면 text가 존재하는 영역이 조금 잘리는 것 같은데 굳이 shrunk box를 사용하여 gt score map을 생성하는 이유에 대해 설명해주실 수 있나요 ? 또, 이 score map을 생성할 때 사용하는 식에서 왜 4로 나눈 후 나온 나머지를 사용하는 것인지 궁금합니다.
또 3.2에 text spotting experiment에서 Strong이 가장 많은 단어를 포함한 lexicon이기 때문에 성능이 제일 높다고 하셨는데, 제가 알기로는 Generic이 9만개의 단어를 포함하고 있는 사전으로 가장 많은 단어를 포함하고 있는 것으로 알고 있습니다. 가장 많은 단어를 포함하고 있다는 의미가 제가 이해하고 있는 것과 다른 의미일까요 ? .. ? ?
마지막으로 FOTS의 text detection branch에 사용된 모델은 text detection을 수행하는 EAST 모델을 그대로 사용하였다고 하셨는데, [Table2]에서 detection 성능만을 보았을 때 조금의 차이가 나는 이유가 궁금합니다.
감사합니다 !!!
하나씩 답변 드리겠습니다.
1. word 단위로 annotation된 gt bbox가 노란색 점선인것은 맞습니다. 하지만 모든 텍스트 영역을 박스 칠려고 하다 보니 박스 내 모든 영역이 positive라고는 볼 수 없다고 합니다. 이에 대한 저자의 견해가 EAST 논문에서는 딱히 없어서 github를 뒤져보니 관련 의견이 있어서 링크를 첨부해드릴테니 해당 issue를 참고하시길 바랍니다. (https://github.com/argman/EAST/issues/94#issuecomment-359713546)
그리고 shrunk quadrangle 생성시 4를 나누는 부분은,, 본 bbox의 꼭짓점이 4개이기 때문인데요, 특정 점을 기준으로 양 쪽 변 길이 중 짧은(min) 곳을 length 로 설정하는 것입니다. 이 부분은 EAST 논문을 참조 하시면 좋을 거 같고, (https://github.com/argman/EAST/issues/5) <-- 해당 이슈를 함께 참고하셔도 됩니다. 2. 아 단어 수로 따지면 Generic이 제일 많은것이 맞네요. 해당 내용은 정정하겠습니다 감사합니다. Generic이 제일 많은 수의 단어를 포함하기 때문에 시간적으로는 제일 오래 걸리긴 하겠지만, train이나 test dataset 의 단어를 포함하고 있는 Strong, Weak에 비해 성능은 떨어지네요. lexicon을 직접 다운해서 구성이 어떻게 되어있는지 살펴보는 것도 좋을 듯 합니다. (https://github.com/MhLiao/MaskTextSpotterV3) 여기서 구글드라이브 다운 링크를 제공하네요.
3. 이 부분은 제 리뷰 중 그림 11의 정성적 결과에 대한 설명을 참고하시면 될 거 같습니다. 결론을 말씀드리면 EAST와 FOTS가 같은 Detection 모델 구조라고 할 지라도 East의 Encoder는 Detection Loss만을 사용해서 backward 계산이 수행되지만, FOTS의 Encoder는 Detection & Recognition Loss를 함께 사용해서 backward 계산이 되죠. 그렇기 때문에 더 복합적인 정보로 상세한 표현력 & 학습을 수행할 수 있는 것입니다.
감사합니다.