이번에 가져온 논문은 ConvNeXt V2라는 논문입니다. 해당 논문을 알게 된 건 지난번 연구실에서 동료 연구원들이 CNN 기반으로 Masked AutoEncoder(MAE)기반의 학습을 한 논문이 있다고 하길래, MAE와 ConvNeXt 논문을 재밌게 읽었던 저로써 흥미가 생겨서 이번에 읽고 리뷰를 하게 되었습니다.
Intro
먼저 Masked AutoEncoder(MAE)라고 하는 논문이 최근에 워낙 유명하다보니 간략하게만 소개를 드리면, MAE는 영상에 마스킹을 적용하여, 시각적으로 보이는 부분을 토대로 마스킹이 된 영역을 복원하는 Masked Image Modeling(MIM) 방식의 pretext task를 통해 모델을 사전학습 하는 Self-supervised learning method라고 이해하시면 됩니다.

사실 GT 정보 없이 영상만으로 사전 학습을 진행하여 좋은 가중치를 구하는 방식 자체는 다양하지만, 본 리뷰에서는 해당 논문과 제일 밀접한 MIM 기반 방식에 대해서만 집중을 하고자 합니다. 영상에 마스킹을 씌워서 이를 복원하는 것을 pretext task로 지정한 논문들은 이 그림1의 Masked AutoEncoder라는 방법론 이전에도 몇번 제안이 되었습니다.
다만 CNN기반의 모델들에서 이러한 pretext task로 사전 학습을 하는 것은 그렇게 좋은 성능을 보여주지 못하였으며, 따라서 비전 도메인에서는 별다른 관심을 받지 못하였습니다. 하지만 NLP 분야에서 BERT라는 방법론이 이러한 Masking 기반의 Self-sup learning이 좋은 성능을 보여주었다는 사실과 NLP 도메인에서 좋은 성능을 보여주는 Transformer라는 모델의 구조가 Vision domain에서도 넘어오면서 다시 한번 Masking 기반의 pretext task가 관심을 보이게 되었으며 결과적으로 매우 성공적인 self-supervised learning의 사례로 남게 되었습니다.
다만 이는 Transformer 계열의 architecture에 한해서만 좋은 이점을 볼 수 있었다는 점이며, 여전히 CNN 구조에서는 이러한 pretraining 방식이 성능의 좋은 이점을 가져오는 것이 쉽지 많은 않았습니다. 이러한 관점에서, 본 논문의 저자들은 CNN에서도 MIM 기반의 사전학습으로 우수한 weight을 배울 수는 없는 것인지에 대한 고민이 있었으며 결과적으로 ConvNeXt라는 최첨단의 CNN 모델 구조를 베이스로 삼아 MIM 기반의 Self-sup을 성공적으로 학습시키고자 노력합니다.
여기서 재밌는 점은 저자들이 self-supervised learning 도메인의 연구들과 supervised learning 도메인의 연구들이 이상하게도 따로 연구된다는 인상을 강하게 받았다고 합니다. 이게 무슨 의미냐면, 영상의 label 값을 학습에 사용하는 supervised learning 쪽 도메인에서는 model의 architecture 연구를 메인으로 연구를 수행하는 반면에, self-supervised learning에서는 이렇게 supervised domain에서 연구된 model의 architecture(Resnet, ViT 등등)를 그대로 활용함으로써 말그대로 학습 방법에 대해서만 깊은 고민과 연구를 진행하고 있다는 것입니다.
하지만 본 논문의 저자들이 생각하였을 때, Self-supervised learning(즉 여기 논문에서는 MIM 기반의 pretext task)에 대하여 학습 방법론 자체에 매달리는 것 뿐만 아니라 모델의 근본적인 구조도 변경을 해줄 필요가 있다고 합니다. 즉 저자가 주장하고 싶은 것은 Supervised learning 쪽 연구들은 model architecture 바꾸는 것에만 혈안이 되어있고, Self-sup 연구분야는 pre-training 방식에 대해 연구하는 것에 혈안이 되어 있어서 architecture를 전혀 건드리지 않고 있으며, 따라서 self-sup learning에 적합한 architecture 변경점도 연구를 해야한다고 주장합니다.
이러한 저자들의 관점을 이해하셨으면, 앞으로 저자들이 논문에서 소개할 내용들(즉, MIM 기반의 self-sup learning이 CNN 계열 모델(i.e., ConvNeXt)에 성공적으로 적용하기 위한 과정) 중에는 MAE의 학습 framework 보다는 architecture 관점에서의 변경점이 더 많은 내용을 차지할 것이라는 것을 이해하실 수 있을 거라고 생각합니다.
자 그러면 이제 본질적인 문제로 다시 돌아와보죠. MIM 기반의 Self-supervised learning을 CNN 계열의 모델 구조에 학습시킬 때 우리는 어떠한 문제들을 직면할 수 있을까요? 가장 첫번째 문제로는 MAE가 특별한 Encoder-Decoder 설계를 가져야만 한다는 점입니다.
조금 더 구체적으로 설명드리면, ViT의 경우 encoder decoder의 구조 설계가 순차적인 데이터를 처리하는 것이 가능하기에, 연산량이 많이 필요한 인코더에서는 visible patch에 대해 집중함으로써 pretraining cost를 줄일 수 있었습니다. 쉽게 말해서 마스킹이 된 영역은 고려하지 않고, 시각적으로 보이는 패치들에 대해서만 상관관계를 인코더에서 계산하기 때문에 모델이 보이는 대상들에 대한 유의미한 관계를 학습할 수도 있었고, 또 연산량 자체도 적게 든다는 것이죠.(마스킹이 되지 않은 영역들만 인코더 계산에 사용되므로.)
반면에 CNN의 경우에는 sliding window 방식으로 쭉 연산이 들어가기 때문에 masking 처리가 된 feature map 또한 연산에 사용됨으로써 학습 비용이 많이 들게 됩니다. 게다가 이러한 모델의 구조와 모델을 학습시키는 목적 함수 간에 연관성이 크게 떨어지게 되는 경우에는 좋은 사전 학습을 기대하기 어렵다고 합니다.
이 말의 의미를 놓고 보았을 때, ViT의 구조는 MIM 기반의 목적 함수와 매우 적합하지만, CNN의 구조는 그렇지 않다는 것을 의미하는 것으로 볼 수 있고, 리뷰의 초반 부에서도 설명드렸다시피 경험적으로 저희는 많은 CNN 모델들이 MIM 기반의 사전학습을 진행할 시에 좋은 성능에 달성할 수 없었다는 것을 확인했습니다.
결과적으로, 본 논문에서 저자는 MAE 학습 방식과 CNN의 구조 등을 동시에 고려하고 변경함으로써, 성공적으로 ConvNet의 MIM 기반 self-sup learning을 수행하였습니다. 본 논문의 대략적인 Contribution은 아래와 같습니다.
- 3d point cloud의 컨셉에서 영감을 받아 masked input을 sparse patch의 집합으로 보고 sparse convolution을 적용하여 masking이 안된 부분에 대해서만 연산을 수행함.(마치 ViT가 마스킹이 안된 영역에 대해서만 관계를 고려하는 것처럼.)
- decoder 구조 역시 ConvNext block 하나로 구성함. (계층적 구조의 CNN(UNet) 혹은 Transformer를 활용하지 않음.)
- feature collapse 현상을 해결하기 위하여 Gobal Response Normalization layer라는 것을 제안. 이는 supervised learning에서의 고정된 네트워쿠 구조를 고정한체 MAE에 재사용해야하는 경우에도 활용하기 좋다는 점.
일단 1번과 2번의 변경점만으로도 MIM 기반의 사전 학습이 베이스라인 대비 좋은 성능을 보여주었다고 합니다. 하지만 fine-tuning 성능이 supervised method와 비교해서 여전히 낮게 나왔으며, 이는 기존 ViT 기반의 MAE 방법론들이 자신들이 제안한 사전 학습을 하게 되면 supervised learning 보다 더 좋은 성능을 달성할 수 있었다는 경향성과 반대되는 상황이었습니다.
따라서 저자가 정량적, 정성적으로 이러한 원인을 분석해본 결과 자신들의 사전 학습 방식을 적용하게 될 경우 ConvNeXt의 feature map에서 collapse 현상이 발생하게 되었으며, 이를 해결해주기 위해 GRN이라는 새로운 normalization layer를 제안하였다고 합니다. 이 feature collapse 현상 및 GRN에 대한 내용 등은 밑에 method에서 보다 자세하게 다루겠습니다.
Fully Convolutional Masked Autoencoder(FCMAE)
일단 본 논문의 가장 큰 핵심은 모든 레이어가 convolution으로 구성이 된다는 점입니다. 이것은 마치 이전에 제안된 ConvNeXt v1 논문이 ViT를 저격하며 CNN도 충분히 ViT처럼 성능을 낼 수 있다! 라는 것을 이점으로 세운 것처럼, ViT 구조에서 잘 동작하는 MAE를 저격하기 위해 CNN으로도 충분히 MAE를 잘 해낼 수 있다! 라는 느낌을 받도록 섹션 제목을 지은 것 같습니다.
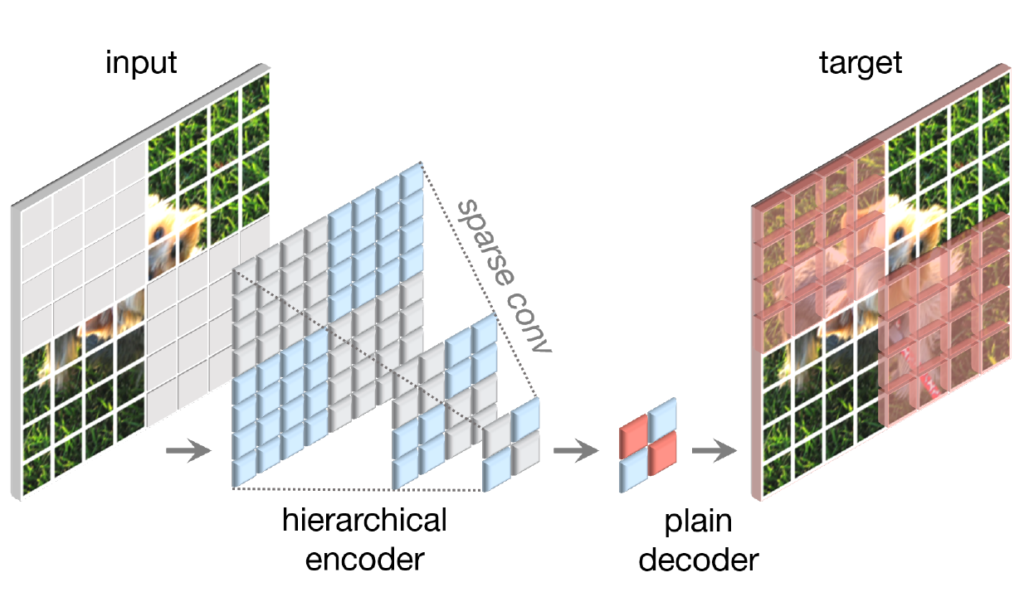
그림2를 보시면 논문에서 제안하는 FCMAE의 전체적인 프레임워크를 확인하실 수 있는데, 요약하면 계층적 구조의 encoder가 있고, 해당 계층적 구조의 encoder는 sparse convolution을 활용하며, decoder로써는 plain decoder(즉 하나의 ConvNeXt block)로 구성이 된다고 합니다.
Masking Strategy
먼저 MIM 논문이라면 빠질 수 없는 마스킹 전략에 대한 소개입니다. 내용이 간단해서 빠르게 살펴보면, CNN은 계층적 구조를 가지고 있기에, 어떤 스테이지의 scale에 맞춰서 마스킹 크기를 정할 것인지에 대하여 고민을 하였으며, 결과적으로 마스킹되는 패치의 비율은 32×32수준으로 진행하였다고 합니다.(제일 마지막 스테이지가 입력 해상도의 1/32 스케일이기 때문)
그리고 마스킹 비율은 60%로 설정하였으며, 기존 MAE와 동일하게 random masking 전략을 취했다고 합니다. 마지막으로 data augmentation으로는 random resized cropping만 활용하는 등 기존 MAE와 유사하게 데이터 증강을 강하게 하지 않는 모습이네요.
Encoder design
다음은 Encoder 구조를 어떻게 설계하는지에 대한 내용입니다. 일단 앞에서도 소개드렸다시피 백본네트워크로는 ConvNeXt 모델을 활용합니다. 이러한 ConvNeXt에 MIM 기반 사전 학습을 성공적으로 수행하기 위해서 저자는 가장 먼저 마스킹된 영역에 대해 정보를 복붙하도록 학습하는 shotcut을 어떻게든 막아야만 한다고 주장합니다.
이러한 숏컷 문제에 대하여 ViT의 경우에는 단순히 마스킹이 안된 영역에 대해서만 입력으로 넣어줌으로써 모델이 주변 이웃 영역을 참고하여 복붙하는 것이 아닌 각 패치들에 대한 의미론적인 관계를 잘 고려할 수 있다고 합니다. 반면에 CNN과 같이 2D image 구조를 온전히 유지해야만 하는 방법론에서는 결국 마스킹처리가 된 영역들도 함께 데이터로 들어가기 때문에 ViT처럼 마스킹이 안된 패치만을 입력으로 사용함으로써 문제를 해결하는 것이 불가능하게 됩니다.
단순한 해결책으로는 BEiT처럼 학습 가능한 마스크 토큰을 입력단에 사용하는 것이 있다고 합니다. 하지만 이 방식은 pre-training 방식의 효율성을 떨어트리며(learnable parameter가 더 늘어나기 때문), 학습과 평가의 결과가 불일치하는 문제가 발생(test time에서는 마스크 토큰이 없기 때문)한다고 합니다.
따라서 저자들은 어떻게 이 문제를 해결할지 고민하던 끝에 point cloud를 입력으로 활용하는 3D vision task의 sparse convolution에 강한 영감을 받았다고 합니다. 즉 sparse point cloud처럼 마스킹된 영상들을 2D sparse array로 볼 수 있지 않을까? 라는 것이죠.
저자는 이러한 관점에서 곧바로 ConvNeXt의 Standard Convolution을 Sparse convolution으로 변경하는 작업에 착수합니다. 보다 구체적으로, 인코더의 standard convolution layer를 sparse convolution으로 변환시켜서 오직 보이는 데이터에 대해서만 컨볼루션 연산을 수행할 수 있도록 하는 것이죠.
게다가 이러한 sparse convolution layer들은 fine-tuning 단계에서 어떠한 추가적인 기법 없이 기존의 standard convolution으로 변경이 용이하다는 이점이 존재하기 때문에 MIM을 통한 사전 학습 단계에서만 sparse convolution을 사용하고, 실제 fine-tuning에서는 standard 버전으로 변경하게 됩니다.
이렇듯 ConvNeXt 모델을 인코더의 큰 틀로 사용하면서 Standard Convolution을 Sparse Convolution으로만 변경한 것이 Encoder design에서의 핵심이자 모든 것으로 이해하시면 됩니다.
Decoder Design
MIM 사전 학습을 위한 디코더 구조는 다음과 같이 정리가 가능합니다.
- ConvNeXT 블록을 디코더로 활용
- 인코더와 디코더의 비대칭 구조(즉 인코더가 훨씬 더 무겁고, 디코더는 매우 가벼운) 구조를 채택.
2번처럼 디코더를 가볍게 가져간 이유에 대해 디코더를 계층적 구조로 무겁게 혹은 transformer를 사용해보기도 했지만 결과적으로 단순한 ConvNeXt block 하나가 사전학습 시간이나 fine-tuning accuracy 관점에서 좋았기 때문이라고 합니다. 실제로 그림1의 MAE 논문과 SimMIM 논문에서도 그랬듯이, MIM 기반의 사전학습에서 decoder는 가벼울수록 좋다는 실험 결과들이 많이 나왔습니다.
이는 아무래도 decoder가 더 무겁고 많은 연산량을 차지하게 되면, reconstruction 단계에서 encoder보다 decoder가 끼치는 영향력이 더 커지기 때문에 decoder에서 좋은 가중치가 학습이 될 수 있으며, 이는 transfer learning에서 사용하게 될 Encoder한테 좋은 가중치가 학습되기 힘들다는 것을 의미하게 됩니다.
이러한 경향성은 ViT 모델 뿐만 아니라 ConvNeXt와 같은 CNN 계열에서도 마찬가지의 경향성이 나타난 것으로 이해하시면 될 것 같습니다.
Reconstruction target
다음은 masking된 영역에 대해서 무엇으로 복원할지에 대한 reconstruction target 관련 내용입니다. 기존 MAE 논문과 동일하게 RGB 영상 자체를 복원하고자 하였으며, 이때 RGB 패치들은 정규화되어 있는 상태라고 합니다. loss function은 MSE error를 사용합니다.
FCMAE
아무튼 위에서 소개드린 Encoder와 Decoder 구조, 마스킹 전략 및 reconstruction target까지를 다 포함해서 저자는 Fully Convolutional Masked AutoEncoder(FCMAE)라고 명칭을 붙였습니다. 이러한 FCMAE의 framework의 효과를 입증하기 위해 저자는 ConvNext-Base model을 기준으로 여러가지 ablation study를 진행합니다.
곧 소개드릴 Ablation study의 실험 환경에 대해서 소개드리면, ImageNet-1K 데이터 셋에 대하여 사전 학습은 800에포크, fine-tuning은 100 에포크로 진행하였으며 ImageNet-1K validation set에 대한 top-1 accuracy를 측정하게 됩니다. 입력 영상의 해상도로는 224×224를 사용하고 있으며 center crop을 진행하였다고 하네요.
먼저 Sparse Convolution을 사용했을 때와 그렇지 않았을 때의 Top1 accuracy는 아래와 같습니다.
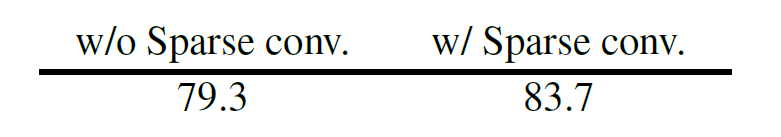
성능이 4.4% 차이가 날정도로 매우 크게 차이나는 것을 확인하실 수 있는데, 이러한 결과를 토대로 저자들은 좋은 성능을 달성하기 위해서는 masked region으로부터 정보의 누수를 막아야하는 것이 매우 중요하다는 것을 실험적으로 밝혀내었다고 합니다.

그 다음으로 decoder의 설계 방식과 깊이 그리고 너비 등 다양한 조건에 대한 ablation study를 위에서 확인하실 수 있습니다. 왼쪽부터 차례대로 요약드리면 UNet(skip connection 포함)구조와 ConvNeXt Block이 모두 동일한 finetuning 성능을 달성하지만 UNext 구조의 경우 계층적으로 연산 및 해상도를 키우다보니 학습 시간이 5시간 넘게 더 걸린다는 단점이 있기에 ConvNeXt Block 구조 하나만을 채택한 모습입니다.
그리고 이러한 ConvNeXt Block은 단 한개만을 사용하더라도 좋은 성능을 보여줄 수 있었으며 차원은 256과 512가 동일한 성능을 달성하였다고 합니다. 결과적으로 width로 512 길이의 차원을 사용했다고 하는데 성능이 같다면 연산량 측면에서 256을 쓰는게 더 낫지 않을까 생각이 들지만 저자들이 왜 256 대신 512를 골랐는지에 대한 이유를 따로 설명하지는 않네요.
위에 결과들만 놓고보면 FCMAE를 통하여 CNN에서도 성공적으로 MIM 기반의 사전학습을 수행할 수 있는 것이 아닐까?라는 생각이 들지만 사실 큰 문제가 하나 존재합니다.

바로 supervised learning의 성능을 이기지 못한다는 점이죠. 물론 제일 좌측에 supervised learning을 100에포크만 돌리는 baseline 성능과 대비해서는 FCMAE가 1%의 성능 향상이 있다는 이점이 있지만, 기존의 ConvNeXt v1에서 리포팅한 성능인 300에포크까지의 지도학습 성능이 83.8이라고 보았을 때, FCMAE의 사전 학습 방식이 이를 넘지 못한 것은 매우 아쉬울 상황입니다.
이 분야에 익숙치않으신 분들이라면 원래 supervised learning과 비교하여 GT 전혀 안쓰는 self-supervised learning으로 supervised learning과 유사한 성능을 달성한거면 그 자체로 훌륭한 것이 아닌가?라는 생각이 드실 수 있으실 겁니다.
하지만 최근 Self-supervised learning 연구들을 살펴보면, supervised learning보다 self-sup이 더 좋은 성능을 보여주고 있기 때문에, 위에 FCMAE가 마주한 경향성은 transformer 기반의 MAE 방법론들이 보여주었던 경향성과 반대인 상황으로 볼 수 있으며, 결과적으로 저자들은 ConvNext가 기존 Transformer based model과 달리 새로운 문제를 직면했다고 판단하게 됩니다.
Global Response Normalization(GRN)
저자들은 무엇이 이러한 경향성을 만들어낸 것인지에 대하여 분석을 하였으며, 결과적으로 Global Response Normalization(GRN)이라는 기법을 통해서 밑에서 소개드릴 ConvNeXt가 겪은 문제점을 해결하고 결과적으로 supervised learning의 성능보다 더 우수한 fine-tuning 성능을 달성하게 됩니다.
그럼 먼저 저자들이 무엇이 문제라고 생각했는지에 대하여 분석 과정 및 내용들을 살펴보시죠.
Feature collapse
저자들은 우선 FCMAE로 사전학습시킨 ConvNeXt-Base model의 feature space를 정성적으로 분석하였습니다. 그 결과 “Feature collapse”라는 현상이 발생한다고 주장하였는데, 여기서 저자들이 말하는 feature collapse 현상이란 feature map들이 너무 많이 비활성화 되었거나 포화되어버렸으며, 채널 전체에 대하여 활성화가 중복되어 버리는 현상이라고 말합니다.
말로만 들으면 감이 잘 잡히지 않을 수 있으니 저자들이 그렇게 판단하게 된 정성적 결과를 그림3에서 확인하면 좋을 것 같습니다.

그림3을 살펴보시면 FCMAE로 학습한 ConvNeXt-Base를 ConvNeXt v1이라고 지칭하였는데 이 ConvNeXt v1의 feature map의 각 채널들을 작은 사각형으로 모아서 시각화를 한 결과입니다. 보시면 대부분의 feature map들이 깜깜하니 아무렇지 않거나, 혹은 너무 과하게 활성화가 되어있는 모습을 보실 수 있는데, 이렇게 대부분의 특징들이 유사한 성질(즉 대부분이 다 비활성화되거나 너무 과활성화되어 있는 상태)을 띄는 현상을 feature collapse라고 표현하였습니다.
특히 ConvNeXt 블록 안에 1×1 convolution으로 구성된 MLP Layer가 있는데 해당 layer를 통해 차원이 확장된 이후 이러한 feature collapse 현상이 크게 관측된다고 합니다.
Feature cosine distance analysis
하지만 정성적 결과만으로는 모델의 문제점을 정확하게 판단하기 어려우니, 저자들은 정량적으로도 feature collapse 상황을 판단할 수 있도록 채널축에 따른 feature map들 끼리의 cosine distance를 계산하였습니다.
보다 구체적으로 X \in R^{H \times W \times C}라는 feature map이 있다고 하였을 때, X_{i} \in R^{H \times W} 는 i번째 채널의 feature map이라고 볼 수 있을 것이며, 이 i번째 feature map과 j번째 feature map간에 pair-wise cosine distance를 계산하게 되는 것입니다. (즉, \frac{1}{C^{2}} \Sigma^{C}_{i} \Sigma^{C}_{j} \frac{1-cos(X_{i}, X_{j})}{2} 를 통해 계산)
여기서 cosine distance가 작게 나올수록 feature들 간에 서로 중복되는 값을 많이 가진다는 의미이며, 반대로 값이 크게 나올수록 더 다양한 feature들이 분포한다는 것을 확인할 수 있습니다. 저자들은 FCMAE로 학습한 ConvNeXt와 지도 학습으로 학습한 ConvNeXt 뿐만 아니라 MAE 방식으로 사전 학습된 ViT 모델에 대하여도 Cosine Similarity를 계산하였으며, 이때 입력으로 사용된 영상들은 ImageNet-1K validation set에서 서로 다른 클래스로부터 1000장의 영상을 랜덤샘플링하였다고 합니다.
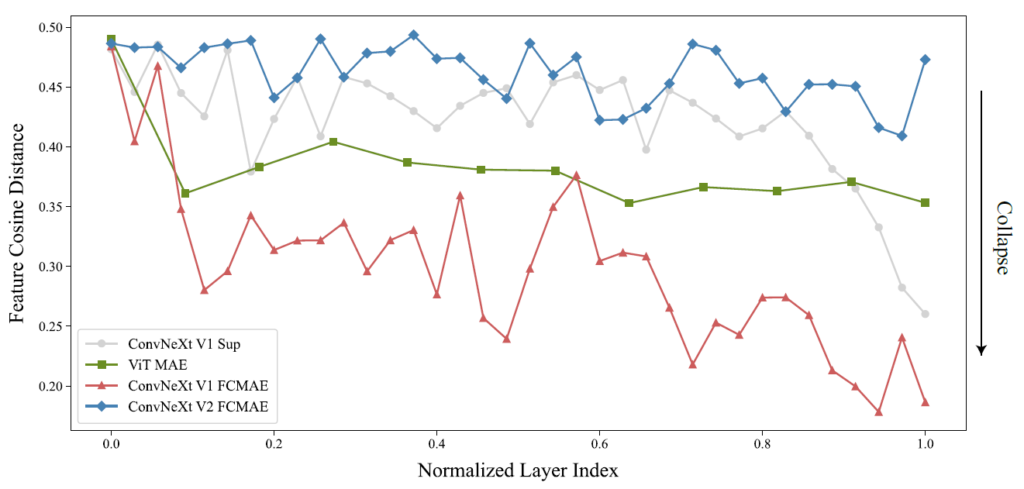
결과는 그림 4에서 확인하실 수 있습니다. 보시면 지도 학습으로 학습한 ConvNeXt와 FCMAE로 사전 학습한 ConvNeXt모델 모두 뒷단에 레이어로 갈수록 cosine distance가 크게 줄어드는 모습입니다. 다만 FCMAE의 경우에는 뒷단의 레이어 뿐만 아니라 앞단에서도 cosine distance의 값 자체들이 크게 저하되는 경향성을 보실 수 있으며 이는 모델의 전반적인 깊이에서 중복되는 feature map들이 많아 feature collapse 현상이 발생한다고 볼 수 있습니다.
반면에 자기지도학습 분야에서 좋은 성능을 보여주는 MAE 기반으로 학습한 ViT의 경우에는 전반적인 깊이에서 모두 일정한 수준의 cosine distance를 보여주었는데, 저자는 이러한 경향성이 FCMAE로 사전학습한 ConvNeXt와 다른 모습이며 이러한 차이가 ViT에서는 지도학습을 뛰어넘는 성능을 달성할 수 있었지만 ConvNeXt에서는 그렇지 못한 이유가 아니었을까 판단합니다.
Approach
정성적으로 그리고 정량적으로도 feature collapse 현상(즉, 채널축에 따른 feature map들간에 중복되는 현상들)이 나타나는 것을 확인하였으니, 이 현상을 줄일 수 있는 새로운 해결책이 필요한 상황입니다. 이 문제를 해결하기 위해서는 feature map들이 서로 다양한 표현들을 가질 수 있도록 해주어야만 하는데, 저자는 재밌게도 측면 억제(lateral inhibition)라는 컨셉을 가지고 나옵니다?
이 측면 억제라는 것은 실제 뇌과학 쪽에서 사용되는 개념인지라 저도 자세히는 모르지만, 해당 용어의 이점으로 활성화된 뉴런의 반응을 더 강하게 하고, 개별 뉴런의 대조와 선별성을 증가시킬 뿐만 아니라, 전체 뉴런들에 거쳐 반응의 다양성을 증가시키는데 도움이 되는 것이라고 합니다.
아무튼 이러한 측면 억제를 딥러닝쪽으로 끌고오게 되면, response normalization이라는 방식으로 구현이 가능하다고 합니다. 그래서 저자들은 global response normalization(GRN)이라고 하는 새로운 response normalization layer를 제안하는데, 해당 정규화 레이어는 채널의 선별성과 대비를 향상시키는 것에 목적을 두었다고 합니다.
GRN layer는 크게 3가지 단계로 구성이 되어있는데, 1)global feature aggregation, 2) feature normalization, 3) feature calibration 순서로 존재합니다.
가장 먼저 feature aggregation부터 살펴보시죠. feature aggregation은 spatial feature map X_{i} 를 global function 함수를 통해 global vector로 변환하는 과정을 의미합니다.
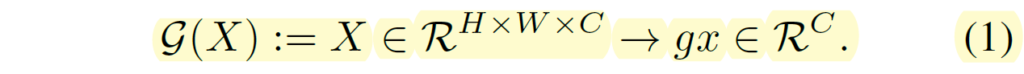
저희한테 가장 친숙한 global function이라 함은 global average pooling(GAP) layer가 있겠습니다만, 사실 저자들이 실제 GRN을 구현할 때는 GAP 기법을 global function으로 사용하지 않았다고 합니다. 저자들도 GAP로 pooling을 해보았지만 성능 이점에 큰 도움을 받지는 못하였다고 하고, 오히려 L2 Norm이 가장 좋은 성능을 보여주었기에 L2 norm 방식으로 pooling을 진행하였습니다.
그 다음에는 response normalization function을 수식1을 통해서 구한 aggregated value에다가 적용해주는 과정을 수행합니다. 결과적으로, 이 response normalization function은 standard divisive normalization으로 구현이 가능합니다.
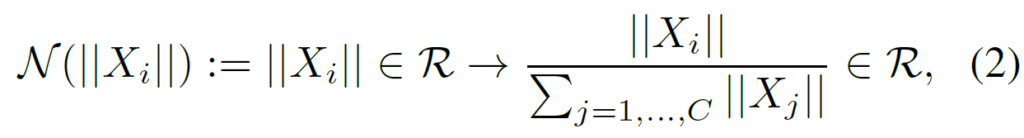
여기서 ||X_{i}|| 는 i번째 채널의 L2 norm 값을 의미합니다. 직관적으로, 수식2는 다른 채널들과 i번째 채널 간에 상대적인 중요도를 계산하는 것으로 이해하시면 쉽습니다. 이러한 상대적인 중요도를 계산하는 행위는 채널들간에 특징 경쟁을 유도할 수 있다고 저자는 설명합니다.
마지막으로 이렇게 계산된 feature normalization score를 원본 입력에게 곱해줌으로써 feature calibration을 수행하게 됩니다.
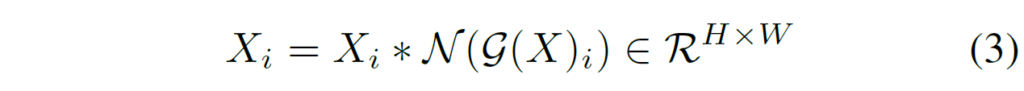
GRN이 feature collapse 현상을 얼만큼 해결했는지를 다시 보기 위해서는 그림 3과 4를 다시 참고하시면 좋을 것 같습니다. 그림3에서 ConvNeXt v2 라고 명시된 부분이 GRN layer가 추가된 것인데 그렇지 않은 것보다 feature map이 너무 과하게 활성화 되지도, 또 너무 비활성화 되지도 않은 모습을 확인하실 수 있으시며, 또한 그림4에서의 cosine distance 역시 전반적인 layer 깊이에서 모두 높은 수준의 distance 값을 지니고 있는 모습입니다.
이러한 GRN layer를 구현하는 것은 매우 간단합니다. 어떠한 learnable paramter도 존재하지 않고 위의 수식3개에 해당하는 코드 3줄만을 추가해주면 되는 것이기 때문입니다.

위에 그림은 GRN을 pytorch 스타일로 구현할 떄의 pseudo code입니다. L2 norm 계산을 통해 global pooling을 진행해준 후 평균으로 나눠주고 이를 입력 X에 곱해주면 되는 것이지요. 근데 위에 수식 3과 pseudo code에서 한가지 다른점이 있다면 수식 3의 경우 X * nx로 GRN 연산이 끝이나야만 하지만 pseudo code에서는 gamma, beta 뿐만 아니라 원래의 input X까지 더해주는 residual connection이 포함되어 있습니다.
저자는 최적화를 더 쉽게 하기 위해 2개의 learnable paramter 감마와 베타를 추가하였으며, 또한 input과 GRN layer의 output을 더해주는 residual connection을 추가하였다고 합니다. 이러한 Residual Connection의 중요성은 밑에서 소개드릴 table-c에서 확인하실 수 있습니다.

일단 중간 정리를 좀 해보죠. 그림5는 GRN Layer에 대한 ablation study에 표를 나열한 것입니다. 먼저 a는 gobal aggregation을 수행하는 함수로 GAP를 사용할 것인지, L1, L2 norm을 사용할 것인지에 대한 여부인데 GAP보다는 norm 계열 그중에서도 특히 L2 norm을 사용하는 것이 가장 좋은 성능을 달성하였다고 합니다.
그리고 Normalization 연산의 경우에는 평균을 빼고 표준편차로 나누는 정규화 방식과 norm 크기의 평균으로 나누어 버리는 standard divisive normalization이 비슷하면서 가장 좋은 성능을 보여주었습니다. 그래도 0.1 차이가 났기 때문에 저자들은 후자를 선택한 모습입니다.
또한 표(c)의 경우에는 residual connection을 사용했을 때와 안했을 때의 여부를 의미하는데 residual connection을 적용한 것이 훨씬 더 좋은 성능을 보여주는 것을 확인하실 수 있습니다.
ConvNeXt V2
자 그러면 아직 다루지 못한 d, e, f에 대해서 알아보도록 하시죠. 지금까지 설명한 GRN layer를 ConvNeXt Block에 이식함으로써 저자들은 ConvNeXt Version 2라는 명칭을 부여합니다. 여기서 기존의 ConvNeXt(i.e., version1)과의 차이를 그림6을 통해서 살펴보겠습니다.
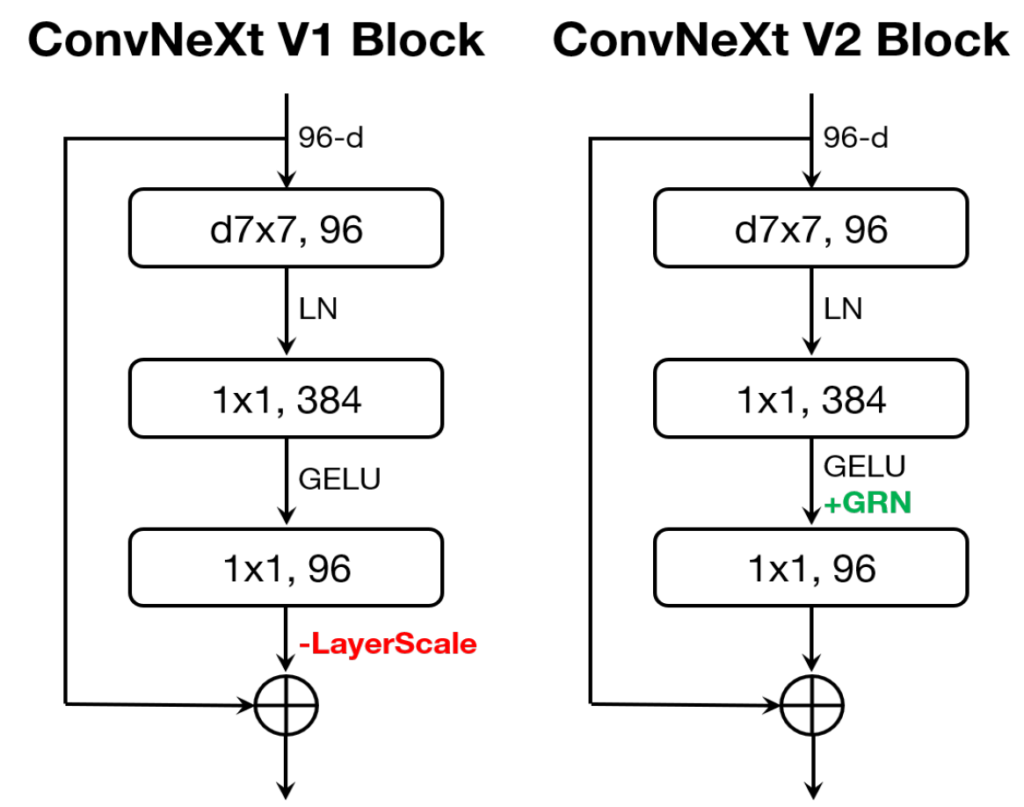
version 1부터 살펴보시면 7×7 커널 사이즈의 Depth-wise convolution을 활용하는 모습입니다. 여기서 1×1 convolution을 2개 적용하여 채널을 확장했다가 다시 축소하는 과정을 거치며, 그 사이에 Layer Normalization과 GELU activation function이 사용됩니다. 그리고 residual connection을 수행하기 이전에 한번 더 Layer normalization을 통한 scaling 과정을 거치게 되는 것이 version 1의 구조입니다.
ConvNeXt v2도 레이어의 구조는 동일합니다. depth wise convolution 1개와 2개의 1×1 conv layer로 구성이 되어 있으며 residual connection도 동일하게 수행을 합니다. 다만 저자들이 GRN을 제안했던 이유는 feature map들이 중복되는 feature collapse 현상을 방지하기 위함이었으며, 해당 현상이 1×1 conv를 통해 차원을 확장하는 부분(즉 96 차원에서 384 차원으로 확장되는 단계)에서 자주 발생하기 때문에 GELU 다음에 GRN 연산을 수행해주게 됩니다.
그런데 어찌보면 GRN도 역시나 normalization을 수행하는 역할이기 때문에, GRN 대신에 흔하게 사용하는 다른 normalization 기법(Batnch Norm, Layer Norm 등)을 적용해볼 수도 있겠습니다. 이러한 실험을 진행한 것이 그림 5의 d 테이블입니다.
저자는 Local Response Normalization(LRN)과 Batch Normalization(BN), 그리고 Layer Normalization(LN)을 GRN 위치에 대신하는 ablation study를 진행하였으며, 그 결과 GRN이 가장 좋은 성능을 달성하였고 그 외에 기법들은 성능을 더 낮추는 경향성을 보여주었습니다.
먼저 LRN은 global context가 부족하여 nearby neighbor 내에서만 채널의 대비가 향상되었으며, BN의 경우 batch axis에 대한 정규화이다보니 masked input을 전혀 고려하지 못하였다고 합니다. 마지막으로 LN의 경우 global mean and variance를 정규화함으로써 feature competition을 격려하긴 하지만 그래도 성능 향상을 뚜렷하게 불러오지는 못하였다고 합니다.
Relation to feature gating methods
앞에서 소개드린 것은 feature normalization 기법에 대한 실험이었다면 지금은 feature gating method에 대한 실험을 진행합니다. 사실 백본쪽 논문에 관심이 있으신 분들이라면 SENet(Squeeze and Excite)과 CBAM(convolutional block attention module)에 대해서 한번쯤은 들어보셨을 겁니다.
이 방법론들은 쉽게 설명드리면 feature map의 채널(혹은 spatial)정보들 중에서 중요한 것들에 집중하고 모으자는 목적으로 달성된 방법론들입니다. 어찌보면 GRN 역시도 feature map의 다양성과 대비, 선별성을 향상시키고자 하였으며 그 과정에서 상대적인 중요도를 계산하는 등 feature gating 과정을 진행하기 때문에 해당 방법론들과의 비교가 분명히 필요해보입니다.
결과는 그림5-(e)에서 확인하실 수 있듯이, GRN이 가장 좋은 성능을 보여줍니다. 근데 성능의 차이가 0.1, 0.2 정도로 밖에 나지 않아서 결과적으로 SE module과 CBAM과 같이 feature aggregation이 성능 향상에 중요한 이점을 취한다는 것은 분명히 할 수 있을 것 같습니다.
여기서 저자들은 SE와 CBAM과 같은 방법론들도 효과적으로 동작하지만 이 모듈들은 결국 mlp layer 등으로 구성되어 있기에 연산량과 learnable paramter가 필연적으로 발생하지만, 자신들이 제안하는 GRN은 이러한 learnable paramter가 없고 단순하다는 점에서 구현 및 적용이 더 쉽다는 이점을 계속해서 언급합니다.
The role of GRN in pre-training/fine-tuning
다음은 GRN을 언제 사용할지에 대한 실험인데, 이부분은 단순해서 빠르게 결과만 설명하고 넘어가겠습니다. 결국 그림5-(f)에서 결과를 보실 수 있다시피 GRN은 pretraining과 fine-tuning 모든 과정에서 들어가야만 효과를 볼 수 있으며 어느 한곳에만 들어가고 다른 한 곳의 학습 단계에서 빠지게 되면 성능 향상의 이점을 보지 못한다는 내용입니다.
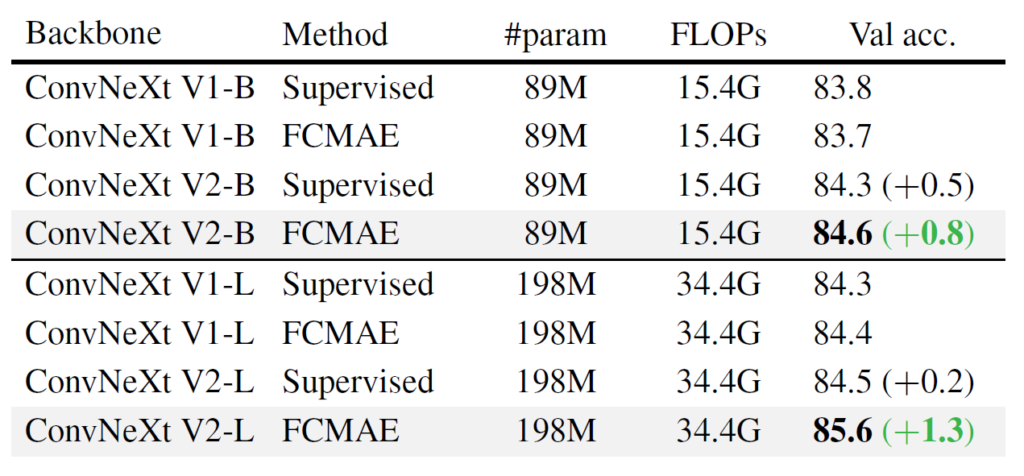
결과적으로 이러한 노력과 실험 끝에 저자들은 CNN 계열의 모델에서도 MIM 기반의 pre-training 방식을 통하여 supervised learning 성능을 뛰어넘는 결과를 달성하게 됩니다.

그리고 이것은 단순히 기존의 self-sup 연구들처럼 Learning framework만을 고려하였다면 해결할 수 없었던 문제였으며, 자신들처럼 learning framework 뿐만 아니라 architecture 관점에서도 깊은 고민과 설계를 했기에 이러한 성능을 달성할 수 있었다는 식의 내용이 다수 있네요. (대충 아래 표가 그런 내용임.)
ImageNet Experiments
실험이 너무 많아서 이를 쭉 설명하느라 리뷰가 매우 길어졌네요. 실험 쪽 섹션은 비교적 간단하니 빠르게 훑고 리뷰 마무리 짓도록 하겠습니다.
Model scaling
model scaling과 관련된 내용입니다. 이 부분은 ConvNeXt의 가장 작은 버전인 Atto model(3.7M)부터 시작하여 가장 큰 모델인 Huge model(650M)까지의 다양한 크기에 대해서도 FCMAE 프레임워크가 항상 fully supervised learning과 비교하였을 때 더 좋은 성능을 달성하는 경향성을 보였다고 주장합니다.
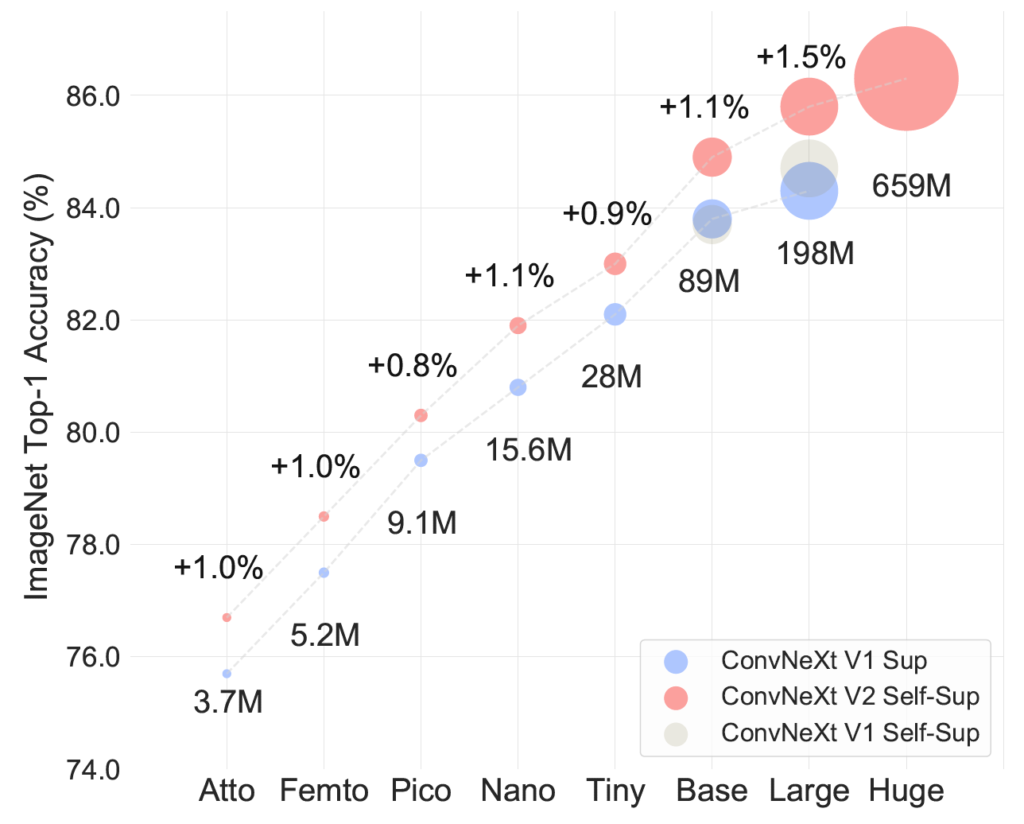
그만큼 FCMAE의 learning framework와 GRN layer가 안정적으로 잘 동작한다는 것을 보여주는 것이 아닐까 생각이 듭니다. 근데 개인적으로 이러한 모델 사이즈 말고도 resnet과 같이 정말 많이 사용되는 cnn 모델에다가 fcmae 방식의 학습을 적용해봤으면 어떨까 싶네요.
Comparisons with previous methods
다음은 기존의 다른 self-sup 방법론들과의 비교 실험입니다. 언급되는 방법론으로는 ViT 백본에 BEiT와 MAE 기반 학습 방식 그리고 swin transformer에 SimMIM 기반 학습 방식에 대한 비교 실험입니다. 이 논문에서는 MIM 기반의 사전학습 방법론들과 비교만을 계속 진행하는 모습이네요.
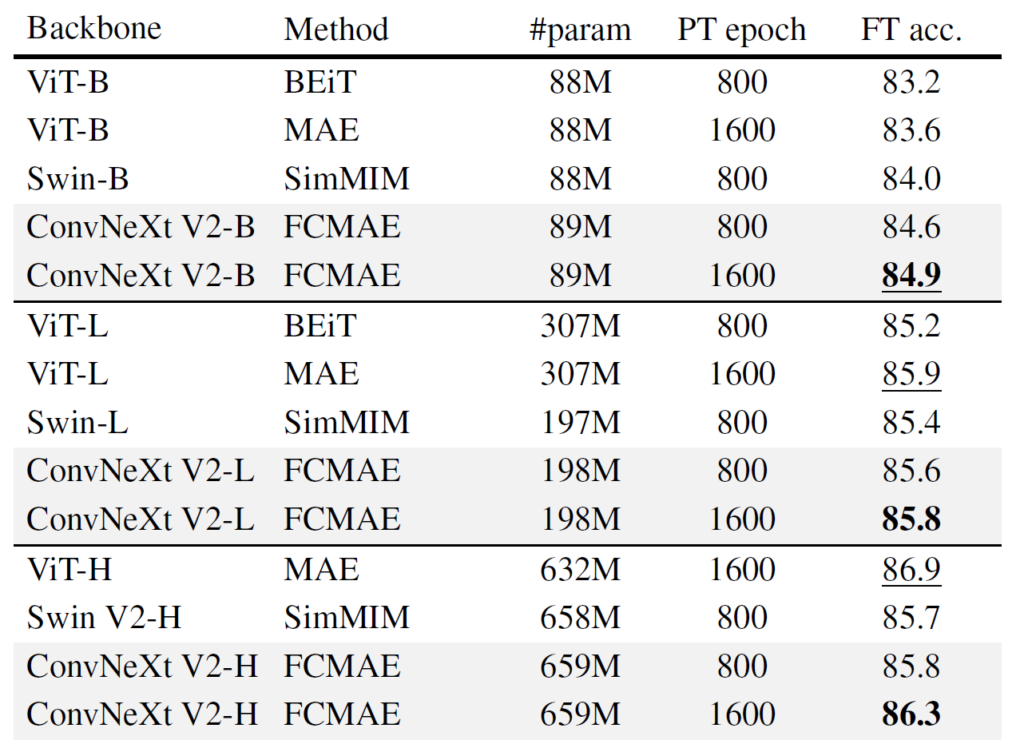
첫번째 관전 포인트는 Swin transformer를 기반으로 하는 SimMIM과 비교해서 모든 모델 사이즈에서 더 좋은 성능을 보여주었다는 점이겠으며, 두번째로 ViT의 MAE와 비교해서는 Large model에서 ConvNeXt v2가 더 적은 파라미터수를 가지고 있음에도 불구하고 유사한 성능을 보여주었다고 합니다.(198M vs 307M)
하지만 Huge model에서는 ViT 모델이 훨씬 더 좋은 성능을 보여주었는데, 이는 아마도 ViT 모델이 self-sup 기반의 사전학습에 더 많은 이점을 가지는 것이 아닐까라고 저자는 판단하고 있습니다.
ImageNet-22K intermediate fine-tuning
다음은 ImageNet-22k에 대한 fine-tuning 성능에 대한 실험입니다. 해당 실험은 먼저 FCMAE로 사전 학습 후 22K 데이터 셋으로 fine-tuning한 다음 마지막으로 1K 데이터셋으로 fine-tuning하여 평가한 결과입니다.
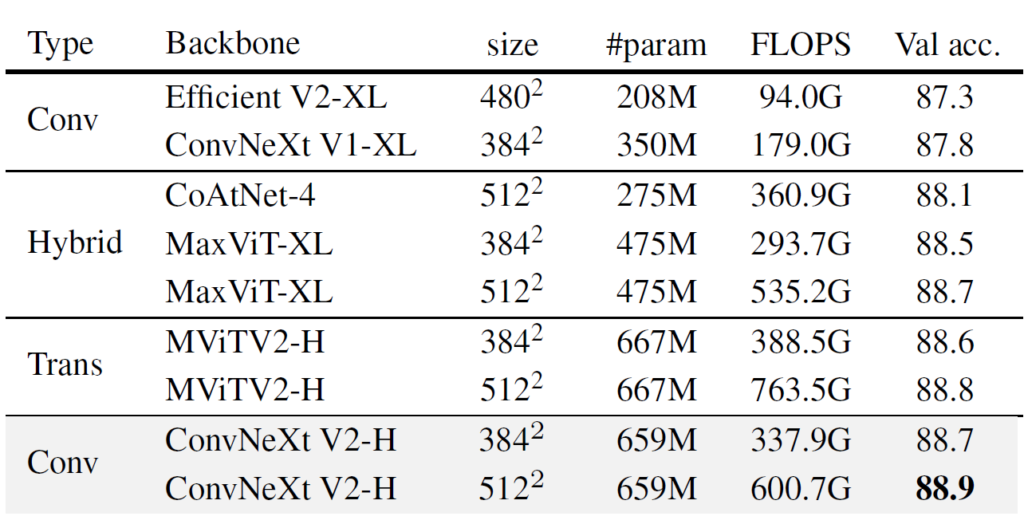
위에 표 역시도 결과적으로 자신들이 Convolution, Transformer, Hybrid(Conv+Transformer) 모두와 비교하였을 때 가장 성능이 좋았다고 합니다. 확실치는 않습니다만 아마 저 위에 Convolution, Transformer, Hybrid 모두 FCMAE 방식으로 사전 학습을 시킨 후의 성능을 비교한 것인 것 같습니다. 즉 위에 실험은 GRN layer가 들어간 ConvNeXt V2의 구조적 변경점에 대한 이점을 어필하고자 이런 실험을 한 것 같습니다.(만약 타 방법론들은 그냥 fully supervised learning으로 진행한 것이라면 형평성에 어긋날 것 같네요.)
Transfer Learning Experiments
다음은 Object Detection과 Instance/Semantic Segmentation에 대한 Transfer learning 실험 관련입니다. 아래 표에서 나오는 ConvNeXt V1은 fully supervised 방식으로 학습한 것이며, ConvNeXt V2는 FCMAE로만 사전 학습한 가중치를, 그리고 Swin Transformer의 경우에는 SimMIM 기반으로 사전학습한 가중치를 사용했다고 합니다.
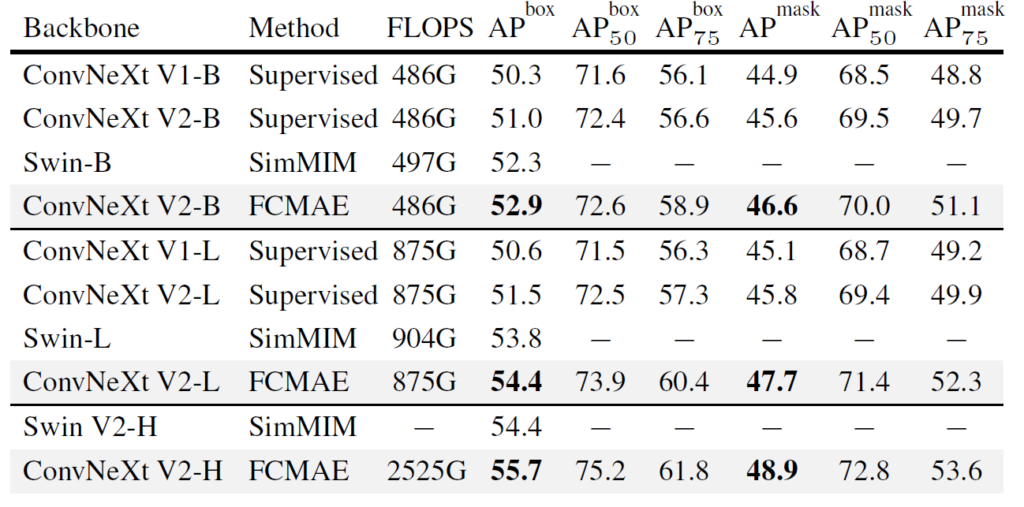
먼저 COCO 데이터 셋에 대한 겨로가입니다. 결론적으로 말씀드리면 ConvNeXt v2가 기존 ConvNeXt version 1과 비교해서도 더 좋은 성능을 보여주었으며 SimMIM 보다도 더 좋은 성능을 보여줍니다. 여기서 재밌는 점은 2가지가 있는데 똑같이 supervised learning을 하더라도 GRN layer가 추가된 version 2 모델이 항상 더 좋은 성능을 보여주고 있으며, FCMAE 를 통한 self-sup learning이 downstream task에서 훨씬 더 좋은 가중치를 제공한다는 점입니다.
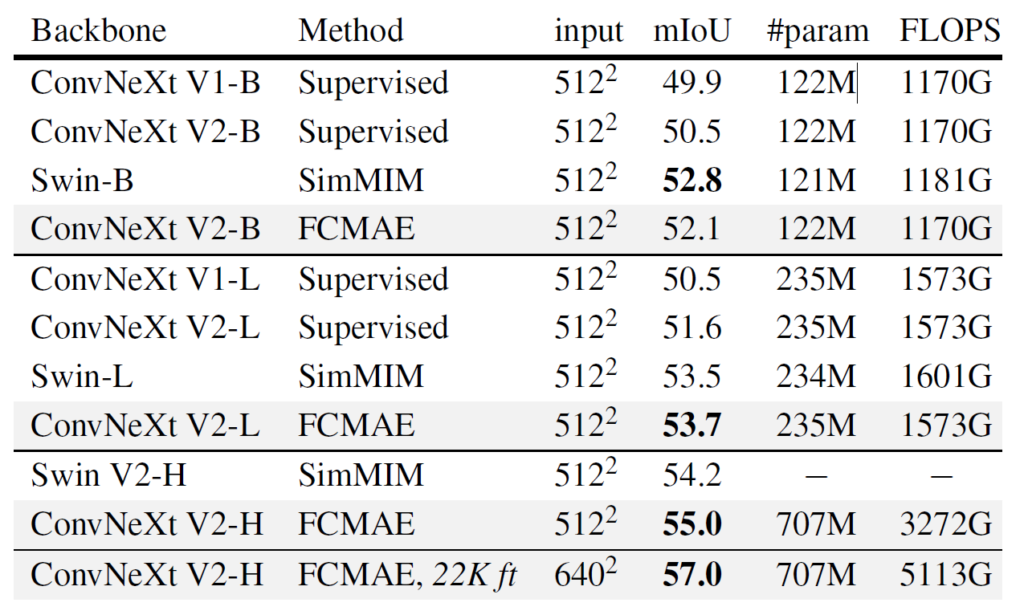
이러한 경향성은 Semantic Segmentation task에서도 그대로 나타나고 있습니다. ConvNeXt v1보다 v2가 항상 더 좋은 성능을 보여주고 있으며, 특히 FCMAE를 통핸 self-sup이 성능 향상에 큰 도움이 됩니다.
하지만 아쉬운 점은 Object detection과 달리 segmentation 쪽에서 Swin과의 성능 차이가 그리 크지 않거나 Base model 기준으로는 0.7정도의 차이로 지는 모습을 확인할 수 있었습니다.
결론
Learning framework적인 측면 뿐만 아니라 모델의 구조적인 부분까지 함께 고려하여 연구를 진행하다보니 실험의 양도 많았으며, 어쩌다보니 저도 리뷰에 많은 글을 작성하고 말았네요.(현재까지가 약 1만9천자가 넘습니다허허..)
깃허브가 공개된지 6개월이 넘었는데 아직 논문이 계속 아카이브 상태인 것으로 보아 ICCV에 냈다가 떨어졌나? 싶기도(다시 들어보니 CVPR2023에 붙었다고 하더라구요:) 한데 그래도 좋은 논문이라고는 생각이 듭니다. 문제를 정의하고 이를 해결하다가 다시 또 문제가 발생했을 때 이를 분석하고 새로 정의 및 해결하는 과정에서 연구자로서 배워가는게 충분히 있다는 생각이 듭니다.
다만 중간중간에 문제 정의 부분 혹은 왜 이런식으로 문제를 해결하려고 했는지에 대한 부분에 대해서 주관적인 생각과 단순히 실험적인 결과만으로 결정되는 부분들이 종종 보여서 한편으로 아쉽게 느껴지기도 했습니다.
그래도 많은 실험 및 고찰을 준 논문이기에 정성추bb