안녕하세요, 양희진입니다.
이번에도 6D Pose estimation 관련 논문입니다. 예전에 꽤 최근에 이 논문을 찾게 되었고, 수식적인 부분은 꽤 어려웠으나 괜찮은 접근법인 것 같아 한 번 리뷰를 해보았습니다.

Abstract
복잡한 환경에서 물체의 pose R, t에 대한 6DoF를 단일 RGB이미지에서 직접 regression 하는 것은 여전히 어려운 문제입니다. 최근에는 end-to-end 방식이 높은 효율로 유망한 결과를 보여주고 있지만, pose의 정확도 측면에서 정교한 PnP/RANSAC-based 접근 방식과 비교하면 여전히 성능이 떨어집니다. 이번에 소개할 SO-Pose는 이러한 단점을 self-occlusion에 대한 예측을 통해 단점을 해결하여 3D 오브젝트에 대한 two-layer representation을 구축함으로써 end-to-end 방식의 6D pose estimation의 정확도를 크게 향상시켰습니다. SO-Pose라는 이름의 프레임워크는 단일 RGB 이미지를 입력으로 받아 shared encoder와 두 개의 seperate decoder를 활용하여 2D-3D correspondence와 self-occlusion 정보를 각각 생성합니다. 그런 다음 두 output을 fusion하여 6DoF pose 파라미터를 직접 regression시킵니다. correspondence, self-occlusion 및 6D pose를 align하는 cross-layer consistency를 통합하여 정확도와 강인함을 더욱 향상시켜 다양한 challenge 데이터셋에서 SOTA를 달성하거나 비슷하게 나왔다고 합니다.
1. Introduction
6D pose estimation을 하는 것은 로봇의 grasping과 planning, AR(Augmented Reality), Autonomous driving을 포함한 high-level computer vision task에서 필수적인 단서로 채택된 상태라고 합니다. (?)
딥러닝의 성공에 힘입어 최근 방법은 복잡한 환경에서도 6D pose를 높은 정확도 및 효율로 추정을 할 수 있게 되었다고 합니다. 거의 모든 프레임워크들은 2D-3D correspondence를 먼저 설정한 다음 RANSAC-based PnP(Perspective-n-Point)알고리즘을 사용하여 6D pose 를 계산하는 2-stage strategy를 사용하고 있습니다. 해당 방법은 좋은 결과를 얻을 수 있는 반면에 end-to-end로 학습을 할 수 없기 때문에 pose의 최적화를 위한 추가 계산이 들어가게 됩니다. 또, 6D pose를 직접 예측하는 대신 surrogate training loss(self-supervised)를 적용하면 더 차별적인 처리 및 학습이 불가능하고 다른 다운스트림 task를 통합할 수 없다고 합니다.
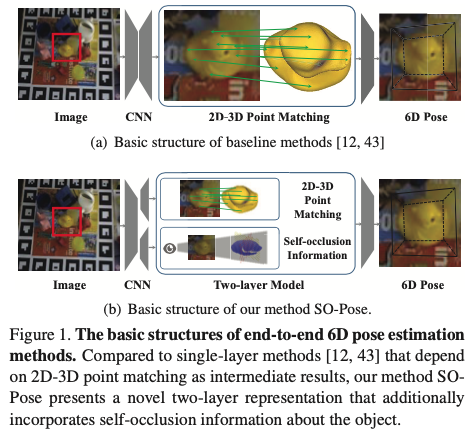
2-stage로 접근하는 방법론이 해당 분야에 대해 지배적이긴 하지만 end-to-end 방식으로 6D pose를 제안하는 방법도 있습니다. 대체적으로 그림1(a)와 같이 dense correspondence-based intermediate geometric representation으로부터 직접 6D pose를 학습합니다. 하지만 end-to-end 방식은 지속적으로 개선되고 있지만, multi-view consistency check, symmetry analysis, disentangled prediection을 활용하는 2-stage 방식에 비해 여전히 열등합니다.
end-to-end 방법의 정확도를 제한하는 요소는 무엇일까요? clutter scene에 대한 심층 조사 결과, 네트워크가 최적에 가까워지는 동안에도 texture가 없는 물체 표면의 고유한 매칭의 ambiguity로 인해 노이즈로 인한 mis-matching 오류가 불가피하며, 그 결과 하나의 correspondence field가 유사한 fitting error를 가진 여러 6D 포즈에 corresponding하는 경우가 많다는 것을 관찰할 수 있었습니다. 이로 인해 학습 과정이 원하지 않는 곳으로 수렴하게 되어 전반적인 6D 포즈 추정 성능이 저하됩니다. 노이즈로 인한 error를 제거하는 것은 간단하지 않으므로 이 문제에 대한 대안은 correspondence field를 3D 오브젝트의 보다 정확한 표현으로 대체하여 노이즈의 영향을 줄이는 것입니다.
Main Contribution
- 각 3D 물체의 two-layer representation에서 6D pose를 직접 regression하는 방법인 SO-Pose 제안
- self-occlusion 및 2D-3D correspondence을 같이 사용하여 3D 공간에서 각 물체에 대한 2-layer representation을 적용하고, 이를 활용하여 2개의 cross-layer consistency을 적용하는 것을 제안
- SO-Pose는 다양하고 challenge한 데이터셋에서 SOTA를 달성하였고, 당시 다른 방법들과 비교했을 때, 비슷한 정확도를 달성하면서 훨씬 빠름
2. Related Works
monocular 6D pose estimation 관련 작업은 크게 세 가지로 분류가 되는데요. 특히, 최종 6D pose를 직접 regression하는 방법도 있지만, pose의 차후 retrieval을 위해 latent embedding을 학습하거나 2D-3D correspondence를 사용하여 잘 정립된 RANSAC/PnP 패러다임을 통해 6D 포즈를 푸는 방법도 있습니다.
- 6D pose를 직접 regression 하는 방법입니다.
[15]은 SSD를 확장하여 6D 물체의 pose를 추정하고 regression 문제를 classification 문제로 전환합니다. 후속 연구 [24]에서는 여러 가설을 활용하여 ambiguity에 대한 강인함을 개선하기 위해 여러 가설을 활용하였습니다. [26]은 projective contour alignment에서 얻은 아이디어를 활용하여 포즈를 추정합니다. 다른 몇 가지 작업에서도 포인트 매칭 loss를 사용하여 3D에서 pose를 직접 최적화합니다. 마지막으로, [12]와 [43]은 모두 2D-3D correspondece를 설정하지만 end-to-end 방식으로 PnP를 학습하려고 시도했습니다.
[12] Yinlin Hu, Pascal Fua, Wei Wang, and Mathieu Salzmann. Single-stage 6d object pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2930–2939, 2020.
[15] Wadim Kehl, Fabian Manhardt, Federico Tombari, Slobo-dan Ilic, and Nassir Navab. Ssd-6d: Making rgb-based 3ddetection and 6d pose estimation great again. In The IEEE International Conference on Computer Vision (ICCV), Oct. 2017.
[24] Fabian Manhardt, Diego Martin Arroyo, Christian Rup- precht, Benjamin Busam, Tolga Birdal, Nassir Navab, and Federico Tombari. Explaining the ambiguity of object detection and 6d pose from visual data. In Proceedings of the IEEE International Conference on Computer Vision, pages 6841–6850, 2019.
[26] Fabian Manhardt, Wadim Kehl, Nassir Navab, and Federico Tombari. Deep model-based 6d pose refinement in rgb. In ECCV, 2018.
[43] Gu Wang, Fabian Manhardt, Federico Tombari, and Xi- angyang Ji. Gdr-net: Geometry-guided direct regression network for monocular 6d object pose estimation. In CVPR, June2021.
- pose 추정을 위해 latent embedding을 사용하는 방법입니다.
이렇게 학습된 embedding은 inference 중에 retrieval에 활용될 수 있습니다. [38]은 Augmented Auto Encoder(AAE)를 사용하여 low-dimensional pose embedding을 학습합니다. 2D object detector를 사용하여 이미지 공간에서 객체를 localize한 후, detection된 latent representation을 계산하고 미리 계산된 codebook과 비교하여 pose를 검색합니다. 여러 객체에 대한 확장성을 더욱 향상시키기 위해 각 객체에 대해 별도의 디코더와 함께 단일 공유 인코더를 사용할 것을 제안된 연구도 있습니다.
[38] Martin Sundermeyer, Zoltan-Csaba Marton, Maximilian Durner, Manuel Brucker, and Rudolph Triebel. Implicit 3d orientation learning for 6d object detection from rgb images. In Proceedings of the European Conference on Computer Vision (ECCV), pages 699–715, 2018.
- 마지막으로, 마지막 단계는 2D- 3D 대응을 설정한 후 RANSAC/PnP를 사용하여 pose 문제를 해결하기 위한 기반이 됩니다.
[28]은 물체 표면에서 멀리 떨어진 키포인트는 더 큰 오차를 유발하므로, 대신 가장 먼 지점 샘플링을 기반으로 물체 모델에서 여러 키포인트를 샘플링한다는 것을 입증했습니다. [36]는 hybrid representation을 도입하여 [28]을 따르고 좀 더 발전시켰습니다. 그러나 주목할 만한 점은 이에 에 속하는 대부분의 연구들이 dense 2D-3D coorespondence를 구축한다는 것입니다. 이러한 방법은 다양한 challenge한 benchmark 데이터셋에서 우수한 성능을 보이는 방법 중 하나입니다.
[28] Sida Peng, Yuan Liu, Qixing Huang, Xiaowei Zhou, and Hu- jun Bao. Pvnet: Pixel-wise voting network for 6dof pose estimation. In CVPR, 2019.
[36] Chen Song, Jiaru Song, and Qixing Huang. Hybridpose: 6d object pose estimation under hybrid representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 431–440, 2020.
3. Methodology

식 (1)은 이미지 I가 주어졌을 때, 신경망을 활용하여 I에서 상대적인 회전 R과 이동 t로의 매핑 f(\cdot)을 학습하여 타겟 물체를 물체 좌표계에서 카메라 좌표계로 변환하고 이때 \Theta는 사용되는 네트워크에서 학습 가능한 파라미터를 의미합니다. clutter한 환경에서는 (self-) occlusion으로 인해 사용 가능한 객체 정보가 심각하게 제한되는 경우가 일반적으로 많습니다. 또한 occlusion 상태에서 3D 회전 파라미터를 직접 regression 하는 것은 어려운 것으로 입증이 되었습니다. 저자는 3D reconstruction의 multi-layer 모델에서 영감을 받아 correspondence에만 의존하는 single-layer 접근 방식보다 좀 더 완전한 기하학적 특징을 포착하기 위해 눈에 보이는 2D-3D correspondence와 보이지 않는 self-occlusion 정보를 결합하여 3D 공간에서 객체에 대한 two-layer representation을 사용할 것을 제안합니다. 이를 통해 self-occlusion, correspondence field, 및 6D pose를 align을 맞추기 위해 2개의 cross-layer consistency을 적용하여 노이즈의 영향을 줄이고 다양하고 어려운 상황에서 pose estimation 성능을 향상 시킵니다.
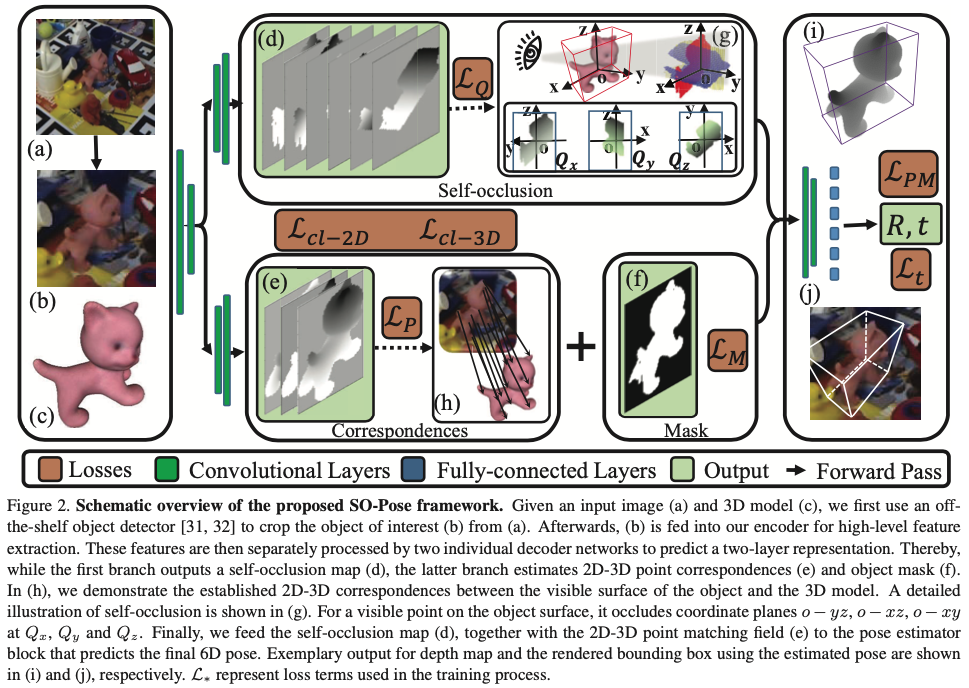
3.1. Self-occlusion for Robust Pose Estimation
대부분의 CNN-based 6D pose estimation 접근 방식은 물체의 보이는 부분에만 초점을 맞추고 occlusion된 부분에 대해서는 무시합니다. 하지만 실제 환경은 complex하며 물체의 가시영역이 매우 제한적이거나 texture 정보가 거의 표시 되지 않는 경우가 많습니다. 이에 따라 single-layer representation은 물체의 기하학적 특징을 완전하게 + 정확하게 encoding을 할 수 없기 때문에 6D pose에 ambiguity를 초래시킵니다. 3D recontruction의 multi-layer model과 유사하게 저자는 3D 객체를 더 풍부하게 representation하기 위해 self-occlusion 정보를 활용하려고 시도했다고 합니다. 그림2(d),(e)를 보면 추정된 2D-3D correspondence와 self-occlusion을 결합하여 3D 공간에서 물체의 pose를 describe하기 위한 two-layer represenation을 만듭니다. 카메라 중앙에서 방출되어 물체를 통과하는 광선을 상상해보면, 이 광선은 여러 다른 지점에서 물체 표면과 교차하면서, 이 중 첫 번째 광선은 표시가 되지만 다른 광선은 모두 self-occlusion 됩니다. 영감을 받은 3D recontruction의 multi-layer model에서는 self-occlusion된 점을 기록하는 것과 다르게 각 광선과 물체의 좌표 평면 사이의 교차점 좌표를 기록한다고 합니다.
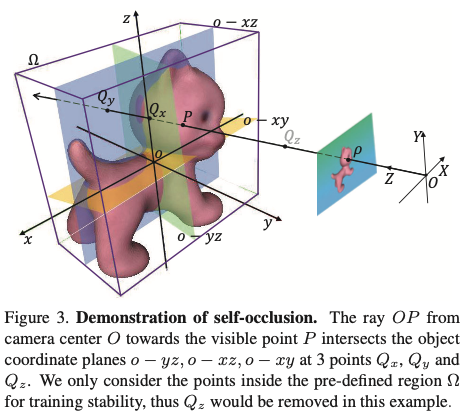
그림(3)에서 방금 전 언급한 광선 OP는 점 Q_x, Q_y, Q_z에서 오브젝트 좌표계의 o-yz, o-xz, o-xy와 교차합니다.
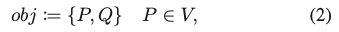
물체 obj의 경우 P, Q = {Q_x, Q_y, Q_z}를 결합하여 two-layer 모델을 나타내며 V는 카메라 좌표계를 기준으로 현재의 visible 뷰 포인트를 나타냅니다. 회전 R과 이동 t를 알면 P에서 Q를 유도할 수 있습니다.

P를 2D 이미지 평면에 projection하면 카메라 intrinsic matrix를 설명하는 K와 visible 3D point을 나타내는 P=[X_P, Y_P, Z_P]^T를 구할 수 있습니다.
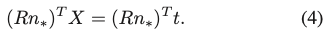
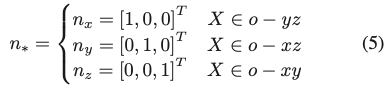
카메라 좌표계에 대한 물체의 좌표 평면은 식(4)와 같이 정의할 수 있습니다. 이때 X는 식(5)에서 주어진 좌표 평면의 3D점을 의미합니다.
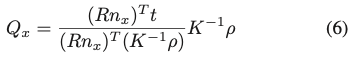
위와 같은 과정을 통해 식(6)과 같이 광선 OP가 교차하는 평면 o-yz에 위치하는 Q_x를 도출할 수 있습니다.
식(6)에서 n_x를 나머지 2개 (n_y, n_z)로 대입하면 Q_y, Q_z를 도출할 수 있을 것입니다.
P와 Q는 카메라 좌표계를 기준으로 표시되므로, 물체 좌표계를 기준으로 해당 좌표는 P_0 = R^TP-R^Tt, Q_0 = R^TQ-R^Tt로 계산됩니다. 추가적으로 물체의 diameter를 기준으로 P_0, Q_0를 정규화를 진행한다고 하는데 좌표에 대한 값들이 크면 학습이 어려워질 수 있기 때문에 정규화를 한 것으로 보입니다. 주의할 점은 카메라 중심 O와 보이는 점 P를 통과하는 광선이 객체 좌표 평면 중 하나에 평행할 수 있으므로 광선이 평면과 교차하지 않을 수 있다는 점입니다. 이러한 경우를 피하고 강인함을 높이기 위해 그림(3)과 같이 minimum bounding cuboid \Omega 내부의 교차점만 고려합니다.
식(6)의 self-occlusion의 정의를 따르면 two-layer representation은 single-layer approach에 비해 3가지의 장점이 있습니다.
- 오브젝트 표면과 무관하게 각 visible point에 대한 회전 R과 이동 t 파라미터를 사용하여 self-occlusion 좌표 Q를 도출할 수 있음 → 렌더링에서 발생하는 오류를 제거할 수 있음
- self-occlusion 좌표 Q_0는 좌표평면에 위치하므로 DOF가 2개뿐이므로, Q_0를 표현하기 위해서는 2개의 값만 예측하면 됨 → 노이즈의 영향을 줄일 수 있는 정규화 term에서 작용함
- P와 Q가 같은 선상에 위치하기 때문에 self-occlusion, 2D-3D correspondence 및 6D pose의 align을 맞추는 여러 cross-layer consistency을 도출할 수 있으므로 challenge한 상황에서도 강인함을 크게 향상 시킬 수 있음
3.2. Cross-layer Consistency
3D 공간에서 객체에 대해 추정된 two-layer representation을 사용하여 2개의 cross-layer consistency loss term을 적용하여 self-occlusion, correspondence field 및 6D pose 파라미터를 공동으로 align을 맞춰줍니다.
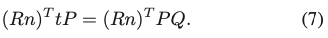
식(3)을 식(6)에 대입하고 정리하면 식 (7)을 얻을 수 있습니다.
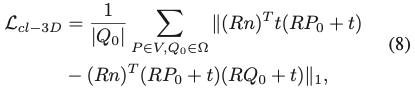
||*||_{1}은 L1 loss를 나타내고 |Q_0|은 \Omega내의 교차점 수를 나타내는 식(8)과 같이 첫 번째 cross-layer consistency를 적용합니다. 식(8)은 식(6)의 Q정의를 기반으로 3D 공간에서 2D-3D corresspondence 관계 P, self-occlusion Q, pose R, t를 함께으로 align하고 refine합니다. 첫 번째 cross-layer consistency는 3D 공간에서 적용되지만, 두 번째 cross-layer consistency는 2D 이미지 평면에서 적용하게 됩니다.
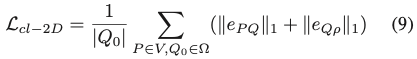
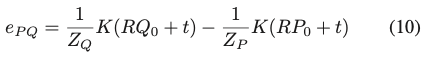
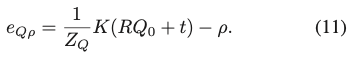
P와 Q는 같은 선상에 위치하기 때문에 투영은 이미지 평면에서 같은 점 \rho를 describe합니다. 따라서 (9), (10), (11)을 사용하여 2D consistency term을 도출할 수 있습니다. 여기서 e_{PQ}는 P와 Q를 동일한 2D 포인트에 projection할 수 있도록 강제하고, e_{Q\rho}는 Q를 Q의 해당 GT의 projection인 \rho에 projection할 수 있도록 강제합니다.
3.3. Overall Objective
SO-Pose는 단일 RGB 이미지를 입력으로 받아 3D 공간에서 물체의 6D pose 파라미터인 R, t를 직접 예측합니다. two-layer representation을 위해 네트워크를 통해 correspondence field와 3개의 self-occlusion map을 생성하게 됩니다. 두 가지 intermediate geometric 특징을 모두 concat하여 pose 예측에 전달하여 완전하게 미분 가능한 방식으로 output pose를 얻게 설계를 했다고 합니다.
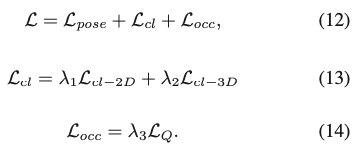
전체 목적 함수는 pose에 대한 기본적인 term(식12), cross-consistency term(식13), self-occlusion term(식14)으로 구성됩니다.
특히 L_{pose}는 correspondence field, translation parameter, visible mask, 영역 분류 및 포인트 매칭에 대한 결합된 loss term입니다.
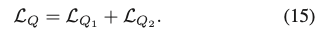
self-occlusion의 경우, L_Q는 식(15)와 같이 두 부분으로 구성됩니다.
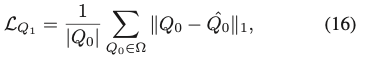
식(16)에서 Q_{1}의 경우, L1 loss를 적용하며, \hat Q_0은 GT self-occlusion 좌표입니다.
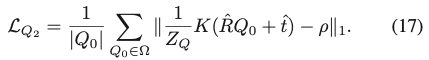
식(17)에서 Q_2의 경우, Q_1과 유사하게 projection 후 consistency를 보장하기 위해 L1 loss를 적용하였다고 합니다. \hat R과 \hat t는 R, t의 GT를 의미하고 식(17)에서 예측된 모든 self-occlusion 좌표 Q_x, Q_x, Q_z가 P에 대해 동일한 선에 위치하도록 강제합니다.
4. Evaluation
Evaluation Metrics
가장 일반적으로 사용되는 평가지표를 사용합니다.
- ADD(-s)
GT와의 편차가 물체 직경 10%(0.1d) 미만인 변환된 3D 모델 포인트의 비율을 측정하고 대칭 객체인 경우 ADD(-s)는 closet model point 편차를 측정함
- n^\circ ncm
회전에 대한 오차가 n^\circ보다 작고 이동에 대한 오차가 ncm미만인 예측된 6D pose의 비율을 측정
Comparison with State of the Art
Results on LM.
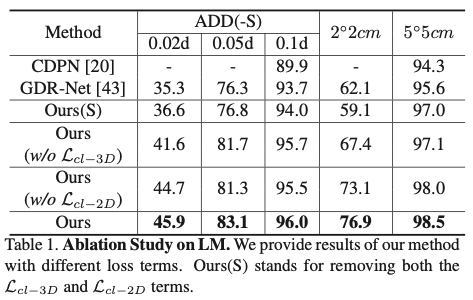
표(1)을 보면 평가 지표가 꽤 tight한 것을 볼 수 있습니다. 해당 결과에 대해 저자는 제안한 방법이 로봇 어플리케이션에서 큰 잠재력이 있음을 보여준다고 합니다.
Results on LMO.
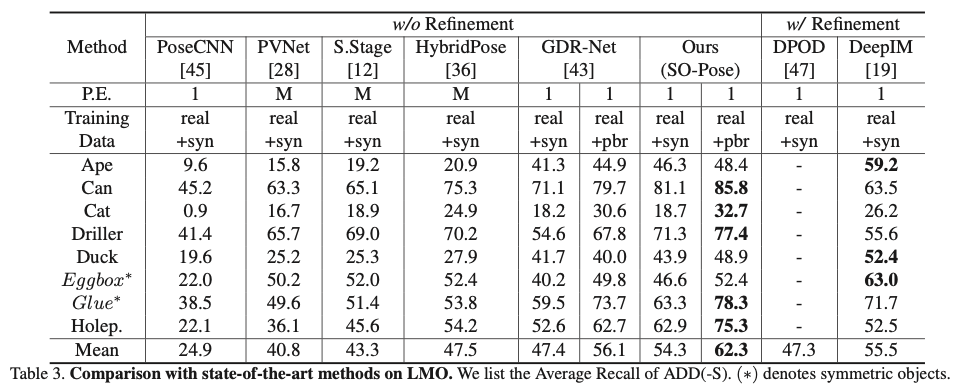
real+syn 데이터로 학습을 하는 경우 refinement-base 방법론과 비슷한 성능을 보이며 real+pbr 데이터로 학습을 하는 경우 8개의 객체 중 5개의 객체에서 SOTA를 달성한 것을 확인 할 수 있으며 평균이 다른 모델에 비해 큰 차이가 나는 것을 확인할 수 있습니다.
( pbr은 pysically-based rendered 데이터를 의미합니다. 즉, 추가적인 렌더링 데이터라고 생각하시면 좋을 것 같습니다. syn은 synthetic 데이터로 합성데이터를 의미합니다. )
Results on YCB-V.
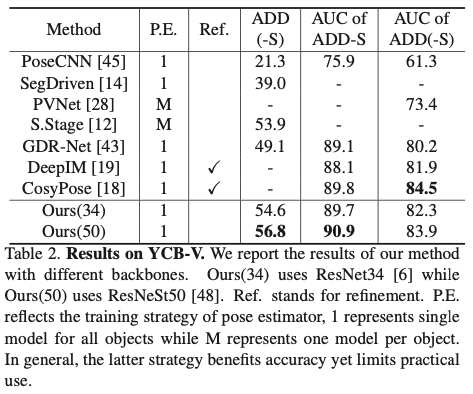
Ours(34, 50)은 ResNeSt(34, 50)입니다. CosyPose와 비슷한 결과를 얻었지만, CosyPose는 refinement 중심 방법론이기 때문에 좀 느린 반면에 SO-Pose는 최종 6D Pose 를 얻기 위해 단 한 번의 forward pass만 필요하기 때문에 훨씬 빠르게 task를 수행할 수 있다고 합니다.
Ablation Study
Effectiveness of cross-layer consistency.
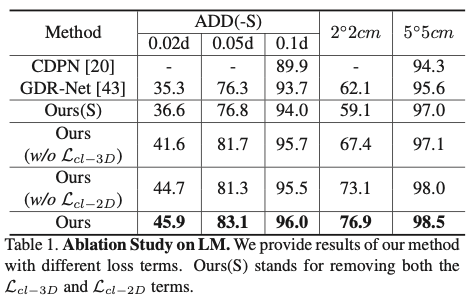
표(1)을 다시 보면 cross-layer consistency의 효과를 보여줍니다. 각 term을 제거하여 6D pose에 미치는 영향을 관찰하고 해당 실험을 통해 cross-layer consistency의 유용성을 확인할 수 있었다고 합니다.
Benefits of employing self-occlusion.
self-occlusion이 pose의 퀄리티에 대해 향상시킨다는 것을 보여주기 위해 2-stage 방법인 CDPN을 사용하였다고 합니다. CDPN은 2D-3D correspondence에서 3D 회전 R을 추출하기 위해 RANSAC/PnP에 기반을 두는 방법론입니다.
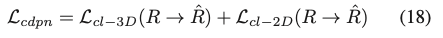
식(18)과 같이 cross-layer 구성 term을 약간 수정하였습니다. 기본적으로 consistency term인 L_{cdpn}은 L_{cl-3D}및 L_{cl-2D}의 예측 회전 R을 GT 회전 \hat R로 대체하여 계산됩니다. L_{cdpn}을 제외한 CDPN의 모든 원래 loss term은 보존됩니다.
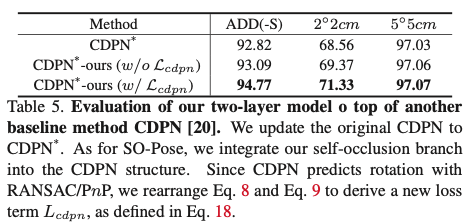
표(5)에서 볼 수 있듯이, CDPN에 two-layer 모델을 도입한 후 모든 metric에 대해 성능이 다시 크게 향상됩니다. 이는 저자가 제안한 two-layer 모델의 일반화 가능성을 명확하게 보여줍니다.
5. Conclusion
이렇게 SO-Pose를 리뷰해보았습니다. 저자는 향후에 2-layer model을 self-supervise 6D pose estimation 및 category-level의 보이지 않는 물체 분석에 통합하는 것에 집중을 할 것이라고 합니다.
안녕하세요. 리뷰 잘 보았습니다.
질문이 몇가지 있는데 먼저, 2-stage 방식들은 multi-view consistency check, symmetry analysis, disentagled prediction 등을 활용하기에 End-to-End 방식보다 성능이 더 좋다고 하였는데, 각각에 언급해주신 방법들의 컨셉 혹은 목적에 대해서 간략하게 소개해주실 수 있나요?
그리고 end-to-end 방법론들의 정확도 하락이 원인으로 1) clutter scene에 대한 심층 조사 결과, 2) textureless 표면에서의 매칭 불확실성 등이 있다고 하는데 먼저 clutter scene에 대한 심층 조사 결과라는 의미가 무엇인지 궁금하고, 추가로 이러한 문제를 2-stage 기법들은 어떻게 해결하나요? 위에서 언급한 symmetry analysis 등의 기법들이 이 문제들을 해결할 수 있는 것인가요? (2번의 문제 같은 경우에는 RANSAC이 outlier로 제거함으로써 해결하는 것 같긴 한데..)
그리고 논문의 핵심 contribution 중 하나로 2-layer representation이라는 단어가 자주 등장하는데, 이 2-layer representation이라는 단어의 의미가 무엇인가요? 혹시 self-occlusion을 수행하는 부분과, correspondence를 매칭하는 부분 2가지 stream으로 나뉘어진 것을 2-layer representation이라고 지칭하는 것인가요?
그리고 해당 논문에서 self-occlusion이라는 개념이 중요한 것으로 보여지는데 self-occlusion에 대해서 정의를 다시 한번 설명해줄 수 있나요? 리뷰 내용에 “카메라 중앙에서 방출되어 물체를 통과하는 광선을 상상해보면, 이 광선은 여러 다른 지점에서 물체 표면과 교차하면서, 이 중 첫 번째 광선은 표시가 되지만 다른 광선은 모두 self-occlusion 됩니다. ” 라는 내용만으로는 self-occlusion 된다는 것이 무엇을 의미하는지 잘 모르겠네요.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
Q. 2-stage 방식들은 multi-view consistency check, symmetry analysis, disentagled prediction 등을 활용하기에 End-to-End 방식보다 성능이 더 좋다고 하였는데, 각각에 언급해주신 방법들의 컨셉 혹은 목적에 대해서 간략하게 소개해주실 수 있나요?
A. multi-view consistency check은 CosyPose, symmetry analysis은 EPOS, disentagled prediction CDPN에서 나오는 각각의 방법론들입니다. CosyPose와 EPOS는 제가 아직 읽지 않은 논문이라 컨셉을 잘 모르지만 CDPN 같은 경우는 물체가 존재하는 영역에 대해 검출한 후 해당 물체의 영역에 대해 각각 다른 방법론을 적용하여 R, T를 추론하는 방법론입니다.
Q. end-to-end 방법론들의 정확도 하락이 원인으로 1) clutter scene에 대한 심층 조사 결과, 2) textureless 표면에서의 매칭 불확실성 등이 있다고 하는데 먼저 clutter scene에 대한 심층 조사 결과라는 의미가 무엇인지 궁금하고, 추가로 이러한 문제를 2-stage 기법들은 어떻게 해결하나요? 위에서 언급한 symmetry analysis 등의 기법들이 이 문제들을 해결할 수 있는 것인가요? (2번의 문제 같은 경우에는 RANSAC이 outlier로 제거함으로써 해결하는 것 같긴 한데..)
A. 심층 조사라는 말은 딱히 뜻이 있는 것이 아니고, 저자가 clutter scene에 대해 깊게 분석을 했다는 의미입니다. 신정민 연구원님이 말씀하신대로 2-stage의 방법론으로 clutter scene에 대해서 강인하게 작동할 수 있게 됩니다. 일반적으로 2-stage의 방법론에는 PnP/RANSAC을 사용하여 문제를 해결하려고 하기 때문에 feature point matching을 어떻게 잘 해줄지에 대한 연구가 계속 진행되는 것으로 알고 있습니다.
Q. 논문의 핵심 contribution 중 하나로 2-layer representation이라는 단어가 자주 등장하는데, 이 2-layer representation이라는 단어의 의미가 무엇인가요? 혹시 self-occlusion을 수행하는 부분과, correspondence를 매칭하는 부분 2가지 stream으로 나뉘어진 것을 2-layer representation이라고 지칭하는 것인가요?
A. 이해해주셔서 감사합니다. 신정민 연구원님 말씀대로 2가지로 나뉘는 항목을 말하는 게 맞습니다.
Q. 해당 논문에서 self-occlusion이라는 개념이 중요한 것으로 보여지는데 self-occlusion에 대해서 정의를 다시 한번 설명해줄 수 있나요? 리뷰 내용에 “카메라 중앙에서 방출되어 물체를 통과하는 광선을 상상해보면, 이 광선은 여러 다른 지점에서 물체 표면과 교차하면서, 이 중 첫 번째 광선은 표시가 되지만 다른 광선은 모두 self-occlusion 됩니다. ” 라는 내용만으로는 self-occlusion 된다는 것이 무엇을 의미하는지 잘 모르겠네요.
A. clutter한 환경에서는 occlusion으로 인해 사용 가능한 객체 정보가 심각하게 제한되는 경우가 일반적으로 많기 때문에 이러한 문제를 해결하기 위해 self-occlusion이라는 새로운 개념을 도입하여 물체 자체가 occlusion됨을 의미하며, 즉 self-occlusion된 정보를 제공하기 위해 추가적으로 네트워크에서 학습시켜 occlusion map을 얻을 결과가 그림2(d)를 구성하는 것으로 이해하였습니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
이번에 희진님께서 리뷰에서 2-stage와 end-to-end 방법론에 대해서 힘을 주신것 같아 질문이 있습니다. 6d pose estimation task에서 2-stage를 end-to-end로 바꿈으로써 직접적으로 얻을 수 있는 장점이 뭔가요?? 논문에서 계속 2-stage가 지배적이라고 하니 굳이 end-to-end로 가져가는 뭐가 좋은지 와닿지가 않네요
안녕하세요, 리뷰 읽어주셔서 감사합니다.
용어에 대해 설명이 없었기 때문에 리뷰를 읽는 부분에 대해서 어려움이 있으셨을 것 같습니다.
6D Pose estimation task를 수행하려면 가장 크게 direct method, indirect method로 나뉘어 문제를 풀게 됩니다. Direct method는 end-to-end 방법론과 동치인 표현이며 또 다른 표현으로는 direct regression이라는 표현도 사용합니다. indirect method와 같은 경우는 2-stage 방법론과 동치이며 사용되는 대표적인 방법은 PnP/RANSAC을 사용하게 됩니다. 2D detector도 2-stage는 ROI를 먼저 하고 detection을 수행하는 것처럼 2-stage 방법론도 물체 영역에 대해 detection을 수행하고 2D 이미지에 존재하지 않는 정보인 depth정보를 사용하기 위해 camera calibration과 같은 추가적인 좌표계 변환을 적용하여 2D-3D correspondence를 생성하게 됩니다. 이렇게 기하학적인 특징을 사용하게 되면 단일 2D이미지에서 바로 regression하여 수행하는 것보다 일반적으로 성능이 잘 나오는 것으로 알고 있습니다.
감사합니다.
좋은 리뷰 감사합니다.
해당 논문에서 이야기하는 occlusion은 다른 객체로 인해 가려지는 경우가 아닌, 객체 자체가 가려지는 영역에 대한 내용이 맞나요?? 맞다면 기존 occlusion 문제 정의와는 차이가 있는 것 같은데 related work등에 기존 문제 정의와 다른 이유에 대한 설명이 있을지 궁금합니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
이승현 연구원님이 말씀하신 객체 자체가 가려지는 영역을 의미하는 것이 맞습니다. inference할 때 self-occlusion으로 인해 보이지 않는 부분이 일반적으로 무시되는 경향을 가지고 문제를 접근한 것으로 알고 있습니다.
감사합니다.
안녕하세요 양희진 연구원님. 좋은 리뷰 감사합니다.
intro 부분에서 2-stage pose estimation의 단점으로 1)pose 최적화를 위한 추가적인 연산이 필요하며, 2)미분 불가능함으로 인해 downstream task와 통합이 어렵다는 설명이 있는데, 그렇다면 저자들이 end-to-end 방법을 사용하여 이를 극복한 것이 실험 결과로 나와 있나요? (1)의 경우 main contribution 세 번째에 ‘다른 방법론들과 비교했을 때, 비슷한 정확도를 달성하며 훨씬 빠름’으로 작성되어 있으나 실험 부분에는 모델 크기나 추론 시간 등의 결과가 없는 것 같아 질문드립니다.
안녕하세요, 리뷰 읽어주셔서 감사합니다.
Q. intro 부분에서 2-stage pose estimation의 단점으로 1)pose 최적화를 위한 추가적인 연산이 필요하며, 2)미분 불가능함으로 인해 downstream task와 통합이 어렵다는 설명이 있는데, 그렇다면 저자들이 end-to-end 방법을 사용하여 이를 극복한 것이 실험 결과로 나와 있나요?
A. end-to-end 방법론은 미분가능하도록 만드는 것이 초점이고, 2-stage와 같은 방법론은 매칭을 하기 위한 방법에 대해 연구하는 것이 초점이기 때문에 질문주신 end-to-end 방법론은 일반적으로 미분가능하도록 설계하여 문제를 풀어나가게 됩니다.
Q. (1)의 경우 main contribution 세 번째에 ‘다른 방법론들과 비교했을 때, 비슷한 정확도를 달성하며 훨씬 빠름’으로 작성되어 있으나 실험 부분에는 모델 크기나 추론 시간 등의 결과가 없는 것 같아 질문드립니다.
A. 속도 부분이나 정확도에 대한 성능에 대해 자세한 분석은 따로 없었고 당시 SOTA 모델이었던 GDR-Net의 AR score는 비슷하지만 SO-Pose가 좀 더 빠른 결과가 나왔다라는 시각화 결과가 있습니다.