제가 이번에 리뷰할 논문은 6D Pose Estimation 논문 중, Texture-less의 CAD 모델을 이용하는 논문입니다. 열화상 영상으로까지 6D Pose Estimation을 확장하려면, 열화상 영상에 대한 texture 정보를 포함하여 CAD 모델을 생성해야 합니다. 본 논문은 texture 정보를 사용하지 않는 방법론이기 때문에, 열화상 영상으로 확장할 때, 적용해볼만 하다 생각하여 읽게 된 논문입니다.
Abstract
RGB 이미지만을 이용하여 6D Pose를 추정하는 것은 occlusion과 symmetries(대칭적인 객체일 경우 pose가 모호하다는 문제)라는 문제가 있습니다. 또한, 전문적인 지식과 스캔 장비가 있어야 정확한 texture 정보를 가진 3D 모델을 만들 수 있다는 어려움이 있습니다. 따라서 해당 논문에서는 Pix2Pose라는object의 3D 좌표를 예측할 수 있는 방법론을 제안하여 texture 정보를 포함한 3D 모델을 사용하지 않고 pose를 예측할 수 있는 방법론을 제안하였습니다.
Pix2Pose는 auto-encoder 구조로 3D 좌표와 예측 오차를 예측하고, 픽셀별 예측값을 이용하여 2D-3D correspondence(PnP와 RANSAC을 이용하여 Pose를 추정하는 데 사용됨)를 형성합니다. 저자들의 방법론은 generative adversarial 학습을 통해, 가려진 영역의 정보를 생성하는 방식으로 occlusion에 강인하며, 저자들이 제안한 transformation loss를 통해 대칭적인 object에 대해 적절한 pose로 가이드를 할 수 있다는 장점이 있습니다. 해당 방법론은 RGB영상만을 이용한 3가지 밴치마크에서 SOTA를 달성하였다고 합니다.
Introduction
객체의 Pose를 추정하는 것은 로보틱스와 증강현실 활용 관점에서 매우 중요한 task입니다. depth 이미지를 포함하는 방법론을 통해 정확한 3D 픽셀 좌표를 제공함으로써 정확도를 상당히 높일 수 있었지만, depth 정보를 항상 활용할 수 없으므로(모바일 기기나 태블릿 등..) RGB 이밉지만을 이용하여 pose를 추정하는 연구가 진행되고 있습니다.
6D Pose Estimation에는 학습과 refinement과정에 합성 렌더링 데이터를 만드는 과정에서 texture 정보가 있는 3D model을 이용하므로 고퀄리티의 texture 정보가 포함된 3D 모델이 반드시 필요합니다.(렌더링을 통해 여러 pose를 갖는 물체의 영상을 만들어내므로) 그러나 산업에서는 texture 정보가 없는 CAD 모델을 일반적으로 사용하며, texture 정보를 생성에는 카메라와 카메라의 궤적에 영향을 받으므로 학습을 위한 고품질의 texture 정보를 보장하는 것에는 어려움이 있다고 합니다. 따라서 texture 정보가 없는 CAD 모델을 이용하여 pose를 추정하는 것이 강인성 확보에 유리하다고 저자는 주장합니다.
최근 CNN을 이용한 연구들을 통해 texture 정보가 없는 3D 모델을 이용하는 것의 가능성을 확인하였고, CNN을 이용하는 방법론들의 가장 큰 문제는 occlusion과 symmetric 입니다. symmetiric의 경우 렌더링 이미지의 범위를 제한하여 학습하거나 pose GT가 있는 실제 이미지에 대해 범위를 벗어난 pose에 대해서 대칭 pose로 변환하는 연구가 진행되었습니다. 그러나, 이러한 방법론은 실린더와 같이 한 축에 대해 연속적이고 무한하게 대칭적인 경우로, 박스와 같이 한축에대해 유한하게 대칭적인 경우에는 적용이 어렵습니다. 따라서 저자들은 이러한 경우에도 가장 유사한 pose로 변환할 수 있는 loss 연구가 필요하다고 합니다. (transformer loss제안)
본 논문의 contribution을 정리하면
- 제안한 Pix2Pose 프레임워크를 통해 RGB 영상과 texture 정보가 없는 3D 모델을 학습에 이용하여 강인한 Pose 추정이 가능
- transformer loss라는 새로운 loss를 제안하여 대칭적인 객체에 대해 고려함
- 3가지 밴치마크에서 SOTA 달성
Related Work
Generative model
auto-encoder를 이용한 생성 모델은 노이즈를 제거하거나 이미지의 누락된 부분을 복구하는데 사용되었습니다. 최근 GAN을 이용하여 image-to-image translation, 이미지 인페인팅과 노이즈 제거 등 이미지의 품질 향상을 위한 연구들이 수행되었고, Keep it unreal**에서는 real depth 이미지로부터 합성 depth 이미지로 변환하여 분류와 pose estimation을 추정하는 연구가 수행되었습니다. 저자들은 이러한 기존 연구로부터 영감을 받아 GAN을 이용한 auto-encoder 구조를 학습하여 color 이미지를 변환하여 정확한 좌표값을 구하고, 인페인팅 작업을 통해 occlusion 된 영역의 값을 복구합니다.
**Sergey Zakharov er al. Keep it unreal: Bridging the realism gap for 2.5 d recognition with geometry priors only. In International Conference on 3D Vision (3DV), 2018.
Pix2Pose
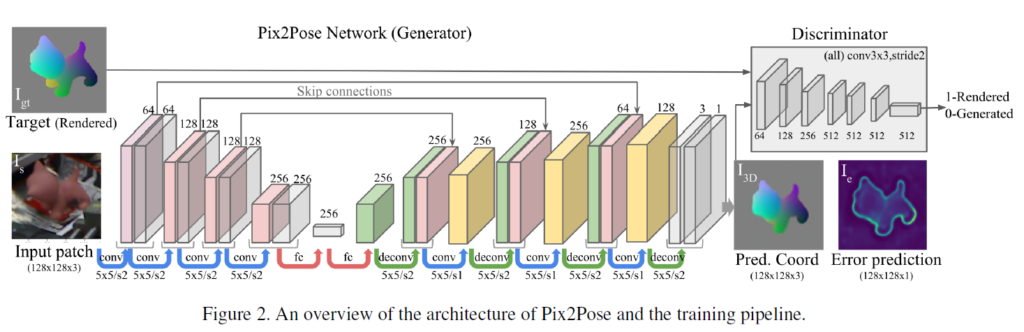
figure 2와 같이 Pix2Pose는 객체를 포함하는 crop된 영역을 이용하여 3D 좌표를 예측합니다. occlusion된 영역의 3D 좌표를 복구하고 pose를 추정하기 위해 객체의 모든 픽셀을 이용하여 강인하게 pose를 추정합니다. 네트워크는 각 객체에 대해 학습되고 3D 모델의 texture 정보는 학습과 inference에서 모두 사용하지 않습니다.
Network Architecture
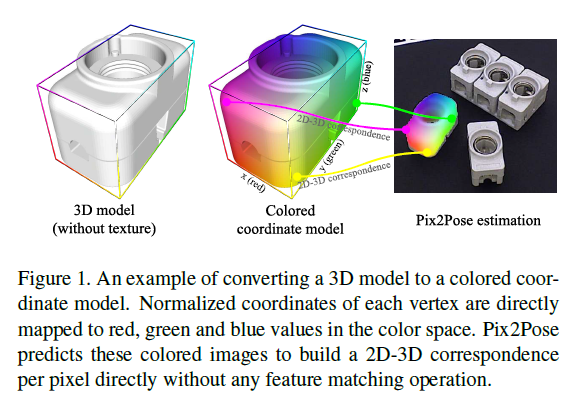
figure 2에서 확인할 수 있듯이 입력은 detector로 예측된 바운딩 박스를 이용하여 객체 영역을 crop한 이미지I_s이고, output은 정규화된 각 픽셀의 3D 좌표 I_{3D}와 기대 error I_e 입니다. Pix2Pose 네트워크를G라 했을 때, I_{3D},I_e = G(I_s)입니다.
crop된 이미지 패치는 128x128x3으로 조정됩니다. low-level feature map의 디테일한 정보를 유지하기 위해, skip-connection을 이용하여 앞의 3개 layer의 feature map 절반을 decoder로 복사하였고, encoder와 decoder사이에 256차원의 FC 레이어를 적용하였습니다. 또한, 마지막 레이어에 3 채널과 tanh 활성화 함수로 갖는 레이어의 출력을 이용하여 3D 좌표인 I_{3D}를 생성하였고, 1채널과 sigmoid를 활성화 함수로 하는 레이어의 출력을 통해 예상 오차I_e를 추정합니다.
Network Training
학습의 목표는 각 픽셀의 예상 오차를 추정 하며 target 좌표 이미지와 예측된 3D 좌표 이미지 I_{3D} 사이의 오차를 최소화하도록 하는 것입니다.
Transformer loss for 3D coordinate regression
target 이미지를 복원하기 위해 각 픽셀의 평균 L1 distance를 이용합니다. reconstruction loss \mathcal{L}_r는 아래의 식(1)로 정의가 되며, 이때 객체 영역이 중요하므로 object mask에 해당하는 영역에 가중치를 부여하여 오차를 측정합니다.
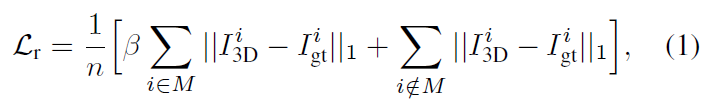
- n: 픽셀의 수
- I^i_{gt}: target 이미지의 i번째 픽셀
- M: 모든 영역이 보일 때의 object mask로, 해당 마스크는 가려진 영역도 포함하므로 보이지 않는 영역에 대해서도 예측할 수 있도록 해줍니다. 즉, 이미지는 가려져지만, 마스크에서는 해당 영역도 고려하여 mask 정보를 주는 것입니다.
그러나 위의 식(1)은 symmetric에 대한 고려를 할 수 없고, 픽셀별 좌표의 장점을 유지하기 위해 저자들은 target 이미지에 3D transformation을 곱하여 대칭 pose로 변환한 뒤, 대칭 pose 후보들 중 가장 작은 오차를 갖는 pose를 이용하도록 하였다고 합니다. 저자들이 제안한 transformer loss는 아래의 식으로 정의가 되며, 해당 loss의 효과는 ablation study에서 확인하실 수 있습니다.
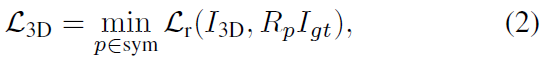
- R_p ∈\mathbb{R}^{3⨉3}: 주어진 pose에 대한 identity matrix를 포함한 symmetric pose 집합 sym의 transformation
- sym는 사전에 정의
Loss for error prediction
I_e는 target image I_{gt}와 예측된 I_{3D}의 오차를 예측하는 값으로, reconstruction loss \mathcal{L}_r를 이용하고, 이때 객체 영역에서 불이익이 크지 않도록 하기 위해 \beta =1로 설정합니다. 따라사 error prediction에 대한 loss \mathcal{L}_e는 아래의 식으로 정의되고, 이때 error는 sigmoid의 범위로 제한됩니다.
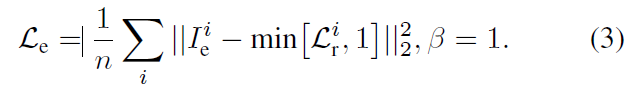
Training with GAN
Pix2Pose는 컬러 이미지를 객체의 3D 좌표 이미지로 변환하는 것으로 GAN 방식을 이용합니다. GAN의 Discriminator loss 함수인 \mathcal{L}_{GAN}은 네트워크 학습에 사용되며, figure 2에서 확인할 수 있듯이 Discriminator는 target과 예측된 I_{3D}를 구별하려 하며, loss는 아래와 같이 정의됩니다.
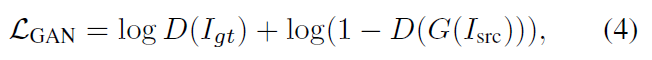
- D: discriminator 네트워크
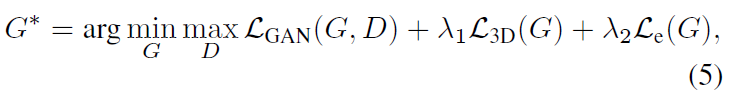
- \lambda_1, \lambda_2: balance 가중치
Pose Prediction
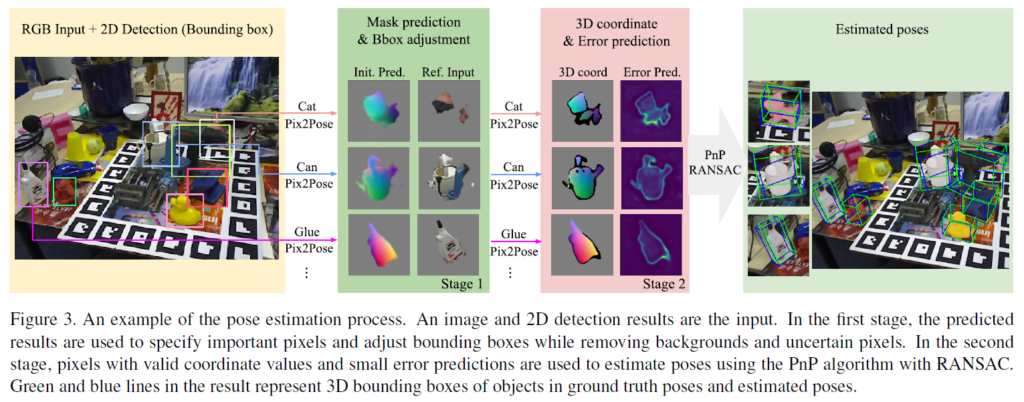
Pix2Pose의 출력을 이용하여 pose를 추정하는 과정에 대한 설명으로, process는 위의 그림 (figure 3)에서 확인할 수 있습니다. 입력 이미지로부터 mask와 bounding box를 예측하고, occlusion 된 영역이 포함될 수 있도록 1.5배 영역을 crop한 뒤 128×128 크기가 되도록 조정합니다. pose 예측은 불필요한 배경 영역을 없애는 과정과 정제된 입력을 이용하여 pose를 추정하고 최종 pose를 계산하는 2단계로 수행되며 두 단계 모두 동일한 네트워크를 이용합니다.
Stage 1: Mask prediction and Bbox Adjustment
예측된 3D 좌표 이미지 I_{3D}를 이용하여 occlusion 된 영역을 포함하여 객체의 영역을 설정합니다. error prediction은 예측 오차가 일정 threshold 이상일 경우 불확실성이 크다고 받아들여 해당 픽셀을 제거하게 됩니다. 이렇게 유효한 픽셀에 해당하는 영역만 남기는 과정이 첫번째 단계이고, figure 3의 Stage 1에서 이에 대한 결과를 확인할 수 있습니다.
Stage 2: Pixel-wise 3D coordinate regression with errors
네트워크를 이용하여 앞선 단계에서 입력 이미지에 대해 정제한 입력을 이용하여 픽셀의 3D 좌표와 예측 오차를 추정합니다. stage2의 3D coord이미지의 검정색 픽셀들은 좌표값이 0이 아니지만 오차예측이 inlier로 설정한 threshold보다 클 때 제거되는 영역들입니다. 즉, threshold보다 예측 오차가 작은 좌표값들을 이용하여 2D 이미지 좌표와 예측된 3D 좌표간의 2D-3D correspondence를 생성합니다. 이렇게 생성된 correspondence 는 RANSAC과 함께 PnP 알고리즘을 적용하여 inlier수가 최대가 되는 pose를 계산합니다. 이때, Pix2Pose는 texture 정보가 없는 3D 모델을 이용하므로, pose 추정에 렌더링이 필요하지 않아 inference를 빠르게 할 수 있습니다.
Evaluation
occlusion이 없는 객체에 대한 성능은 LineMOD, occlusion이 있는 다중 객체는 LineMOD-Occlusion과 T-less 데이터 셋을 이용하여 평가를 진행합니다. 이떄 T-Less는 texture 정보가 없는 CAD모델을 제공하며, 대부분이 symmetric한 객체이므로 Pix2Pose가 제안한 방법론의 성능 확인에 가장 적절합니다.
Metrics
- GT pose와 예측된 pose로 구한 point들 사이의 평균 거리를 측정(아래의 식6)하고, symmetric한 객체일 경우 가장 가까운 정점까지의 거리를 측정(아래의 식7)하는 ADD metrics를 주로 이용합니다. 거리를 측정하여, 오차가 3D 모델의 직경의 10% 미만일 경우 제대로 예측한 것으로, 아닌 경우 잘못 예측한 것으로 평가합니다.
- T-Less의 경우 보이는 영역의 오차만 측정합니다.
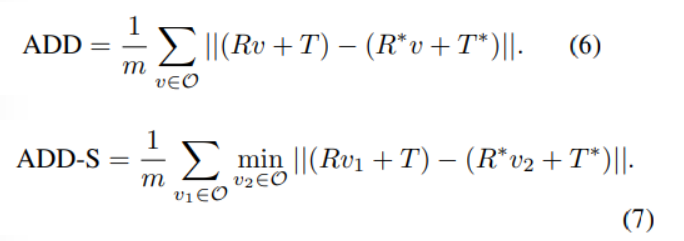
LineMOD
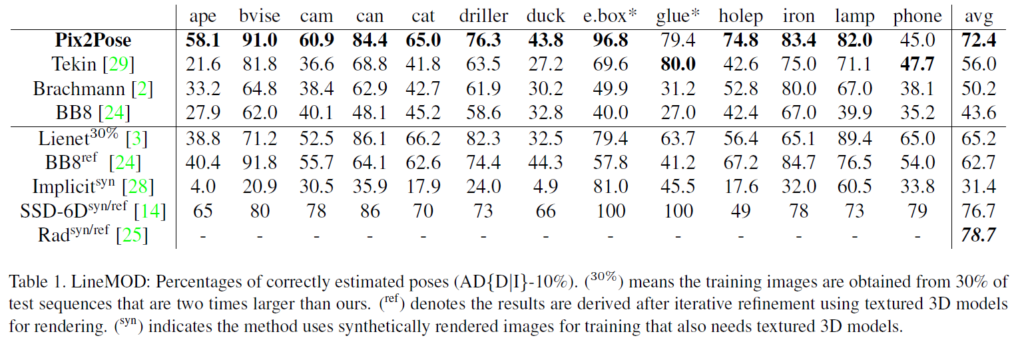
Table1의 위의 4개의 행 결과를 통해 Pix2Pose가 texture 정보가 있는 3D 모델을 이용하지 않았을 때, 다른 방법론들 대비 SOTA를 달성하는 것을 확인할 수 있습니다.
아래의 결과들은 texture 정보가 있는 3D 모델을 이용한 결과로, texture정보가 있는 방법론과 비교했을 때도 경쟁력 있는 성능을 달성한 것을 확인할 수 있습니다. 또한, refinement를 수행하지 않는 방법론과 비교했을 때는 가장 좋은 성능을 보여줍니다.
LineMOD Occlusion
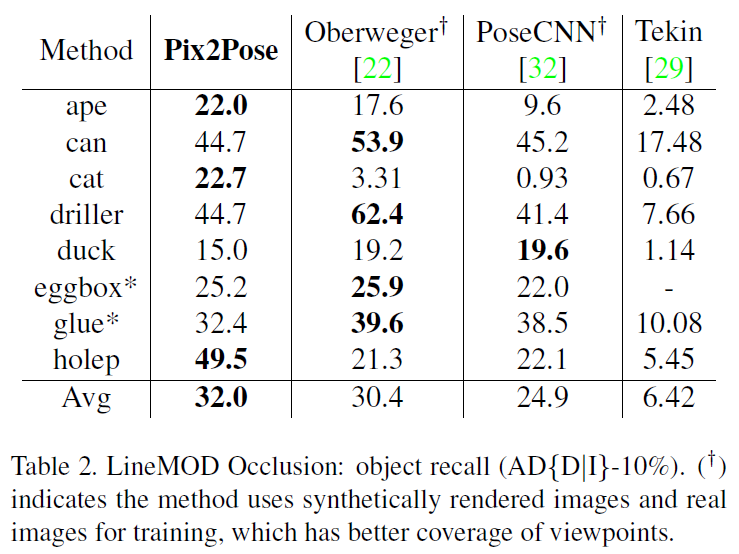
LineMOD의 test 이미지에서 8개의 object에 대해 annotation을 수행하여 생성하며, Faster R-CNN을 detector로 이용하였다고 합니다. Table 2에서 확인할 수 있듯이 Pix2Pose는 real RGB 이미지만을 이용하는 Tekin 방법론보다 성능이 크게 향상되었으며, 3개의 객체와 평균에서 다른 방법론 대비 SOTA를 달성하였습니다. Oberweger와 PoseCNN 방법론은 texture 정보가 있는 3D 모델을 이용하여 렌더링 이미지를 만들어 학습 데이터를 늘린 방법론으로, 이러한 방법론과 비교했을 때, 경쟁력 있는 성능을 달성하였습니다. (학습 데이터는 더 적지만 평균적으로는 더 좋은 성능을 보였기 때문에..)
T-Less
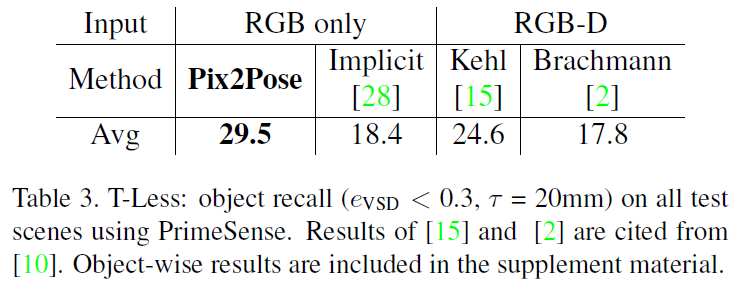
해당 데이터셋은 texture 정보가 없는 CAD 모델과, texture 정보를 재구성한 3D 모델이 모두 제공됩니다. 저자들이 장점(texture 정보가 없는 3D 모델을 이용)을 보이기 위해 texture 정보가 없는 CAD 모델을 이용하였으며, Table 3을 통해 결과를 확인할 수 있습니다. Pix2Pose가 RGB 이미지만을 이용한 다른 방법론들보다 더 우수하다는 것을 확인할 수 있습니다.
Ablation Studies
Transformer loss


loss의 유효성을 검증하기 위해 3D 좌표 영상이 z축을 중심으로 회전하며 랜더링 했을 때의 결과입니다. Figure 5를 통해 L1 loss는 \pi일 때, 사람이 판단하기에는 error가 0이 되어야 하지만 큰 오차를 가지고, 범위를 제한하는 L1 loss를 이용할 경우, 빨간색으로 칠해진 영역에서 과도하게 패널티를 주게됩니다. 이러한 loss와 비교하였을 때, transformer loss는 pose가 다를 경우 loss가 증가하고, 대칭적인 경우에 다시 loss가 줄어들도록 설계가 된 것을 확인할 수 있습니다. 또한 Table 4를 통해 transformer loss를 이용할 경우 성능이 향상되는 것을 확인할 수 있습니다.
If 3D Model is not Precise & Does GAN improve results?
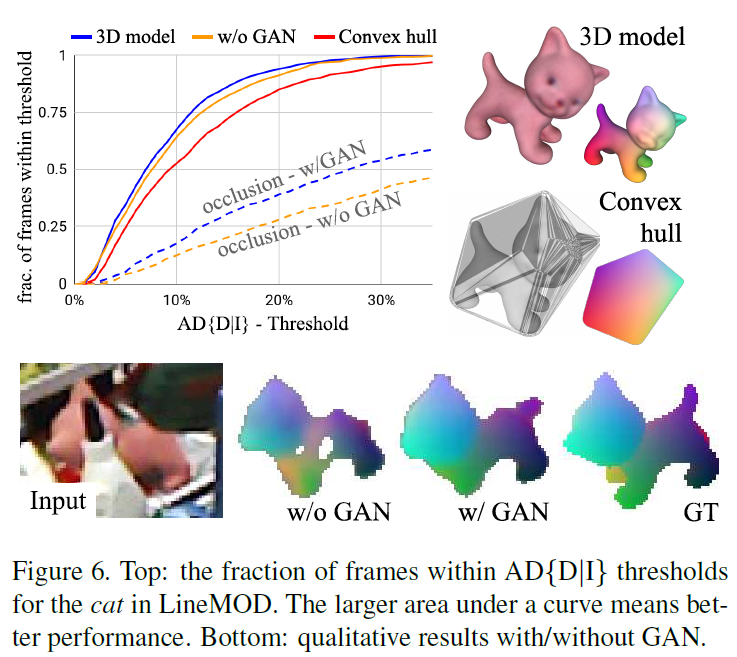
정밀한 CAD모델을 이용하지 않고 CAD 모델의 외곽을 덮는 convex hull을 이용할 경우 성능은 약간 떨어지지만 경쟁력 있는 성능 달성이 가능함을 확인할 수 있습니다.
또한, occlusion에 대한 결과를 Figure 6의 그래프에서 확인해보았을 때, GAN Loss가 total loss에 포함될 때 성능이 향상되는 것을 확인할 수 있습니다. 또한, Figure 6의 하단에서 확인할 수 있는 정성적 결과를 통해, GAN을 이용하여, 보이지 않는 영역에 대해서도 예측하도록 학습할 경우 보다 좋은 품질의 2D-3D correspondence를 만들 수 있다는 것을 확인할 수 있습니다.
Different 2D detection networks & Inference time
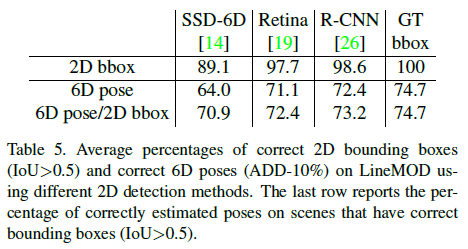
Table5는 LineMOD에서 서로 다른 2D Detector를 사용하였을 때의 성능을 타나낸 것으로, 2D Detection의 결과에 크게 영향을 받는다는 것을 보여줍니다. Inference time은 2D 네트워크에 따라 달라지 Faster R-CNN은 127ms, Retinanet은 76ms가 소요되며, 각 bounding box에 대한 pose 추정은 영역 당 25~45ms가 소요된다고 합니다.
좋은 리뷰 감사합니다.
전체적으로 autoencoder의 구조를 통해 texture가 존재하는 CAD 모델과 texture정보가 없는 모델을 가지고 학습하고 Inference시에는 textureless한 CAD model만 사용하는 것으로 이해했습니다. 그럼 해당 방식은 texture가 있는 CAD모델도 결국 학습하는 과정에서 필요한거죠? 그리고 이 방식도 class마다 따로 학습시켜야하는지 궁금합니다.
감사합니다.
댓글 감사합니다.
이해하신대로 학습에 texture 정보가 없는 CAD 모델을 이용하여 학습하고, test를 할 때는 RGB 이미지만을 이용하는 것입니다. 즉, texture 정보가 있는 CAD 모델이 없이 학습이 가능하다는 것이 해당 논문에서 강조하는 contribution입니다.
또한, 각 객체 별로 학습이 되는 방식이 맞습니다.
안녕하세요, 좋은 리뷰 감사합니다.
해당 논문은 2D detector로 먼저 물체 위치에 대한 bounding box와 그에 물체의 mask를 가지로 AutoEncoder(Generative Model)를 사용하여 Pose를 추정하는 것으로 이해했습니다.
Network Training 섹션에서 궁금한 점이 있습니다.
AutoEncoder 모델은 Transformer와 연관이 있는 건가요? Transformer Loss for 3D coordinate regression이라고 되어 있어 이해가 잘 되지 않아 질문을 남깁니다. 아니면 Transformer 모델을 backbone으로 사용한다는 뜻인가요?
감사합니다.
댓글 감사합니다.
우선 해당 모델은 CNN 기반의 방법론입니다. 본 논문에서 제안한 transformer loss란 I_{gt}에 transformation을 적용하여 대칭 pose로 변환시킨 뒤, I_{3D}와 비교하여 오차가 최소가 되는 pose를 선택하는 것을 의미합니다. 즉, 모델 관점에서 transformer가 아니라 이미지를 tansform하여 구한 pose에 대한 loss라서 for 3D coordinate regression입니다.