이번에 가져온 논문도 지난번과 동일하게 Optical Flow 관련 논문입니다. 제가 최근에 optical flow 관련해서 적용해보면 좋을 것 같은 아이디어가 하나 떠올라서 이를 적용하기 전에 관련 분야의 주요 논문들을 서베이하느라 리뷰에도 optical flow를 자주 가져오네요. 아무튼 리뷰 시작하겠습니다.
Intro
지난 주에 작성했던 리뷰와 마찬가지로, optical flow에 대한 task부터 설명드리면 해당 task는 비디오 프레임들 사이에 픽셀 레벨에서의 모션 정보를 추정하는 task를 의미합니다. 즉 연속된 프레임으로부터 픽셀들이 얼만큼 움직였는지 방향 벡터를 계산하는 것이죠.
오래전, 전통적인 optical flow 방법론들은 영상의 영역들이 시각적으로 정합이 맞도록 하는 data term과 한 그리드에서 주변의 모션들이 서로 비슷할 것이라는 regularization term을 구분두어 이들을 함께 고려하여 최적화하는 방식으로 flow map을 추정하였습니다.
하지만 전통적인 기법들은 위의 data term과 regularization term 등이 rule based로 작성되어 구현되었기 때문에, 다양한 corner cases(즉 복잡한 상황들)에도 강건하게 동작하는 것은 여전히 어려움이 존재한다고 합니다.
이러한 전통적 기법과 달리, 딥러닝 기반 방법론들은 모델이 곧바로 두 입력 프레임에 대하여 flow를 예측하여 정답 값과 비교하는 방식의 지도 학습을 통해 준수한 성능과 빠른 추론 속도를 지닐 수 있었다고 합니다. 이러한 딥러닝 기반 방법론들의 성공을 시작으로, 향후 optical flow estimation 연구의 방향은 학습을 더욱 쉽게하고 다양한 상황에 일반화 성능을 보여줄 수 있는 효율적인 네트워크 구조를 설계하는 것이 주된 목표가 되었다고 합니다.
저자는 이러한 흐름에 발맞추어, Recurrent All-Pairs Field Transforms(RAFT)라는 새로운 optical flow 모델 구조를 제안합니다. RAFT의 구성 요소는 크게 3가지로 (1) 영상의 각 픽셀 별로 유의미한 벡터를 추출할 수 있는 특징 추출기, (2) 각 feature pair에 대하여 픽셀 레벨의 상관관계를 고려한 4D correlation map을 생성하는 correlation layer, (3) 반복적으로 예측한 flow map을 재조정하는 recurrent GRU 기반의 update operator로 구성이 되어있습니다.
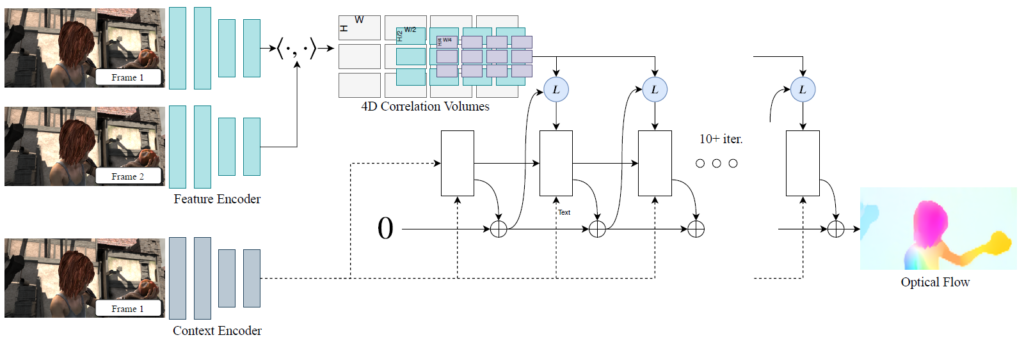
저자는 RAFT 모델의 구조를 만들 때 전통적인 최적화 기반 방법론들을 많이 참고하였다고 합니다. 즉 feature extractor는 픽셀레벨 별 특징들을 잘 추출하고, correlation layer 부분은 픽셀들 사이에 시각적 유사도를 잘 계산할 수 있으며, update 연산자는 반복적인 최적화 알고리즘의 단계들을 묘사하여 설계되었습니다.
하지만 각각의 단계가 전통적인 기법의 파이프라인과 유사하다는 것일 뿐, 각 스텝 별 내부의 동작 방식은 차이가 많이 나는데 실제 RAFT의 경우 특징과 모션 정보들이 모두 학습을 통해 계산이 되기에 훨씬 더 유연하게 동작하고 좋은 성능을 보여줄 수 있습니다.
또한 RAFT 모델과 이전 방법론들의 차이점(특별한 점)을 간략히 소개드리면 첫째로, RAFT는 고해상도의 단일 flow field를 업데이트 하는 방식을 취하게 됩니다. 이는 저해상도에서 초기 flow map을 추정하여 점차 고해상도로 보정하는 Coarse-to-fine 형식의 방법론들과 큰 차이가 있다고 볼 수 있습니다.
Coarse-to-fine 형식의 방법론들은 fine scale resolution에서 flow map을 추정해 large displacement를 해결하고 점차 middle-Coarse 식으로 해상도를 넓혀가면서 small displacement를 해결하는 방법에서 비롯되는데, 이러한 방식은 작거나 빠른 물체에 대하여 정확한 flow map을 추정하기가 어려울 뿐더러, multi-stage의 순차적인 학습으로 인하여 많은 학습 iteration이 필요하다는 단점이 있다고 합니다.
반면에 RAFT와 같이 high-resolution의 단일 해상도에서 반복적으로 업데이트 과정을 이루어 나가게 될 경우, 작거나 빠르게 움직이는 객체에 대하여 놓치는 현상을 쉽게 극복할 수 있다고 저자는 주장합니다. 근데 이렇게 고해상도에서 flow map을 추론하게 되면 receptive field의 한계로 인하여 Large Displacement를 해결하는데 있어 어려움이 있지는 않을까 생각이 들 수 있습니다.
이러한 문제를 해결하고자 RAFT는 위에서도 언급한 update operator를 통해 flow map을 반복적으로 추론 및 보정을 수행합니다. 즉 이전의 추정했던 flow map에 다시 한번 flow map을 추론함으로써 refinement를 진행하고, 따라서 large displacement도 해결할 수 있다는 것이죠. 그리고 밑에서 자세히 다루겠지만, Correlation volume을 생성할 때 multi-scale의 pyramid 방식으로 생성해서 사용하기 때문에 이러한 multi-scale이 large&small displacement에 강건하게 동작할 수 있도록 도와준다고 합니다.
사실 이전의 연구들 역시 iteration 기반으로 추론 및 보정하는 방식을 채택하고는 했습니다. 하지만 저자의 주장에 따르면 이전의 많은 연구들은 반복횟수에 따른 가중치를 부여하지는 않기에 반복 횟수가 특정 횟수로 제한된다는 단점이 존재한다고 합니다.
또한 저자는 이전 딥러닝 방법론 중에서 recurrent의 컨셉을 적극 활용한 방법론은 FlowNetS 혹은 PWC-Net이라고 하는 딥러닝 기반 optical flow의 근본?에 해당하는 architecture를 그대로 recurrent unit으로 활용했다고 합니다. 이렇게 되면 문제가 recurrent를 수행하기 위한 모델 자체가 상당히 무겁거나(FlowNetS의 경우 38M Paramters), pyramid level(즉 resolution에 따른 multi-scale 크기)에 따라 반복 횟수가 제한되어 버리는 단점이 존재한다고 합니다.
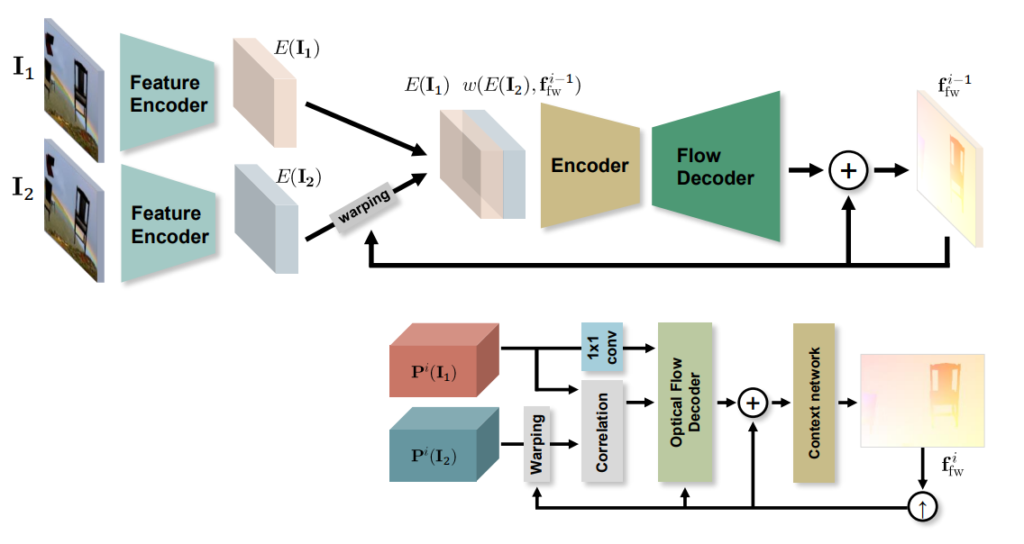
반면에 저자의 RAFT 방법론의 경우에는 밑에서도 설명드리겠지만 LSTM과 유사한 설계 방식으로 update operator 모듈을 구현하였기에 이론상 100번이 넘는 횟수에 대해서도 반복적으로 refinement를 수행할 수 있다는 이점이 있으며, 모듈의 크기도 고작 2.7M 파라미터 밖에 안되어 가볍다는 이점이 있습니다.
결과적으로 저자는 자신들이 제안하는 RAFT가 다음 3가지의 이점이 있다고 설명합니다.
- 성능이 좋다! – 평가 데이터 셋인 KITTI와 Sintel Dataset에서 이전 SOTA 논문 대비 각각 16%(5.10 vs 6.10), 30%(2.855 pixels vs 4.098 pixels)의 에러 감소율을 보임으로써 성능 향상이 인상적이다.
- Generalization 성능이 좋다! – 오직 합성 데이터 셋만으로 학습하더라도 RAFT는 KITTI 데이터 셋에서 이전 SOTA 방법론 대비 약 40%(5.04 vs 8.36)의 에러 감소율을 보여주었다.
- 매우 높은 효율성! – 1088×436 해상도를 가지는 비디오에서 FPS가 10정도 나옴(1080Ti GPU 기준)
Methods
그럼 방법론에 대해서 디테일하게 알아볼까요? 일단 optical flow는 두 프레임 I_{1}, I_{2} 사이에 픽셀 레벨의 모션(u, v, 축에 대한 dense map f^{1}, f^{2} )을 추정한다고 했습니다. 즉 I_{2} 와 I_{1}[/latex의 관계를 [latex] (u', v') = (u + f^{1}(u), v + f^{2}(v) 로 나타낼 수 있습니다.
그리고 인트로 및 그림 1에서 소개드렸다시피, RAFT는 크게 (1) 특징 추출기, (2) Correlation volume, (3) Update Operator로 구성이 되어있습니다. 그럼 각각의 단계에 대해서 설명해보도록 하겠습니다.
Feature Extraction
먼저 특징 추출기는 당연하게도 Convolutional Network를 의미하며 이를 통해 입력 영상으로부터 특징을 추출합니다. 조금 더 구체적으로는, 6개의 residual block으로 구성이 되어 있는데 입력 해상도 대비 1/2, 1/4, 1/8에 해당하는 feature map들의 연산에 사용될 residual block이 각각 2개씩 구성이 되어 있습니다. 이러한 feature extractor는 I_{1}, I_{2} 각각에 대해 개별적으로 입력을 태워 특징맵을 출력합니다.
또한 이러한 특징 추출기 외에도 context extractor라는 네트워크가 별개로 존재하는데, 해당 네트워크는 첫번째 영상(i.e., I_{1})으로부터 영상의 문맥 정보를 추출하는 네트워크입니다. 따라서 첫번째 영상에 대해서만 연산을 해주면 되고, 네트워크의 구조는 위에 Feature extractor랑 동일하다고 합니다.
Computing Visual Similarity
그 다음에는 두 영상의 특징 맵 간에 상관관계를 계산하는 단계입니다. optical flow의 경우에는 첫번째 영상으로부터 두번째 영상까지 얼만큼 이동했는지 모션 벡터를 계산하는 task이기 때문에 두 영상 사이에(정확히는 두 영상 내 픽셀들 간에) 대응관계를 학습하는 것이 매우매우 중요합니다.
따라서 RAFT에서는 두 영상 사이에 대응관계를 나타낼 수 있는 correlation volume이라는 것을 생성합니다. 이때 이 correlation volume이라는 것은 두 입력 영상의 특징맵( g_{\theta}(I_{1}) \in \mathcal{R}^{H \times W \times D} , g_{\theta}(I_{2})\in \mathcal{R}^{H \times W \times D} 간에 내적을 수행하면 쉽게 계산할 수 있습니다.
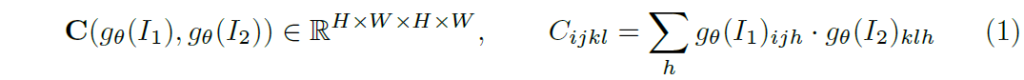
즉 채널축(D)에 대하여 내적을 수행하여 최종적으로 HxWxHxW 차원의 correlation volume을 생성하는 것이죠. 이러한 방식으로 correlation volume을 계산할 수 있게 되는데, 여기서 한가지 중요한 점은 RAFT에서는 Correlation volume을 피라미드 형식으로 만들어서 사용한다는 점입니다.
즉 수식 1을 통해 만들어진 Correlation volume을 C_{1} 라고 하였을 때, C_{1}에 뒤에 두 차원(즉 C_{1} \in \mathcal{R}^{H_{1} \times W_{1} \times H_{2} \times W_{2}} 에서 H_{2} \times W_{2} 부분)에 대하여 average pooling을 적용함으로써 multi-scale의 correlation volume을 생성하게 됩니다. 즉 C_{2}, C_{3}, C_{4} 는 뒤의 두 차원들이 각각 \frac{H_{2}}{2} \times \frac{W_{2}}{2}, \frac{H_{2}}{4} \times \frac{W_{2}}{4}, \frac{H_{2}}{8} \times \frac{W_{2}}{8} 의 크기를 가지게 되는 것이죠.
위에 제 설명이 쉽게 이해가 안가시면 그림3을 참고해보시면 좋을 것 같습니다. 첫번째 영상에 특정 한 픽셀에 대하여 두번째 영상 모든 픽셀에 대한 correlation volume이 C_{1}이라면, C_{2}, C_{3} 는 C_{1}에 대하여 2x2, 4x4 등으로 묶어서 패치 단위로 생각한다는 것입니다.

Correlation Look up
위에서 소개드린 correlation volume은 optical flow에서 없어서는 안될 매우 중요한 요소 중 하나이지만 사실 spatial dimension에 대한 정보들을 살려두는 내적 연산 방식은 연산 복잡도가 영상의 해상도의 제곱에 해당하게 됩니다.
근데 인트로에서도 소개드렸다시피 RAFT의 장점이 update operator를 통하여 많은 수의 iteration을 돌아 refinement를 한다는 것인데, 이러한 flow map의 refinement 과정을 반복적으로 진행할 때마다 correlation volume을 매번 계산하게 되면 상당히 많은 연산량으로 인하여 추론 속도가 매우 느려지게 될 것입니다.
따라서 저자들은 (한번만 계산한)correlation pyramid로부터 앞으로 n번의 refinement를 할 때 correlation volume을 그 스텝에 사용할 수 있도록 하는 lookup operator L_{c} 를 새롭게 제안합니다. lookup 연산에 대해서 간략히 소개드리면 현재 추정된 optical flow map f_{1}, f_{2} 이 있다고 하였을 때, 첫번째 영상의 한 점과 대응되는 두번째 영상 내 한 점은 x' = (u+f^{1} (u), v+f^{2}(v)) 꼴로 나타낼 수 있다고 하였습니다. 이때 x' 주변에 local grid를 다음과 같이 정의하였다고 합니다.
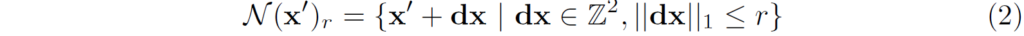
즉 local grid는 L1 distance를 사용하여 x'의 r 반경 안을 지칭하는 offset 집합을 의미하는 것이죠. 이렇게 현재 flow map으로 계산한 local grid는 correlation volume에서 저희가 필요한 부분을 indexing할 수 있도록 활용이 됩니다. 조금 개념이 헷갈릴 수도 있는데 쉽게 말해서 local grid란 현재 단계에서 추정된 flow map을 토대로 target 지점에 해당하는 point(x') 주변부분(dx)의 영역들을 의미하며, 해당 영역들의 결과값을 가지고 correlation volume의 뒤에 두 차원( H_{2} \times W_{2} 의 값들을 indexing하게 됩니다.
이렇게 인덱싱을 한 최종 결과값은 H_{1} \times W_{1} \times (2r+1)^{2} 의 크기를 가지는 feature map으로 변환이 됩니다. 정리하면 뒷단의 두 차원을 모두 활용하는 것이 아닌 target point에 대한 (2r+1) 반경만큼의 주변 영역들만 인덱싱하여서 특징맵으로 만든 후 update operator의 입력으로 활용하고자 한 것이죠.
이 local grid는 correlation volume의 scale에 맞게끔 계산이 되는데 쉽게 말해 correlation pyramid에 각 스케일별로 local grid 역시 동일한 스케일에 맞추어서 계산이 되고 인덱싱을 수행하게 됩니다. 이렇게 인덱싱된 correlation map들은 채널 축으로 concatenation이 되어 하나의 단일 feature map으로 활용됩니다.(즉 H_{1} \times W_{1} \times 4*(2r+1)^{2} )
Iterative Updates
다음은 RAFT의 마지막 단계인 update operator에 관한 내용입니다. 해당 부분은 말 그대로 optical flow를 추정하는 모듈, 이전 단계의 정보와 현 단계의 정보를 취합하는 update 등의 내용이 담깁니다.
먼저 모델은 flow map을 반복적으로 시퀀스하게 추정할 수 있으며( f_{1}, ..., f_{N} ) 이때 시작 지점의 flow map은 0으로 초기화됩니다. 이는 첫번째 영상과 두번째 영상 사이에 움직임이 전혀 없는 0이라는 의미이며 이러한 0에서 시작하여 점차 첫번째 영상이 두번째 영상에 얼만큼 움직였는지를 찾아가는 것이죠.
즉 update operator는 f_{0}=0 에서 시작하여 k번째에서는 f_{k} = f_{k-1} + \delta f로 구할 수 있게 됩니다. 즉 NLP 분야의 RNN이나 LSTM처럼 이전 단계에서의 예측값이 hidden unit으로써 계속 저장이 되며 현 단계에 값에 반영이 된다는 것이죠.
이러한 updater operator의 입력으로는 위에서 얘기했던 correlation pyramid에서 계산된 correlation map과 이전 단계에서 계산된 flow map 자체를 2개의 컨볼루션을 태워서 계산한 flow feature, 그리고 context encoder에서 나온 context feature map까지 총 3가지의 정보들을 concatenation하여 입력으로 사용합니다.
그럼 이제 update operator의 구조에 대해서도 좀 살펴보죠. update operator는 LSTM과 유사하다고 했는데 조금 더 자세히 말하면 Gated recurrent unit과 동일하다고 보시면 됩니다. Gated recurrent unit는 LSTM과 유사한 구조이면서도 LSTM보다 더 적은 파라미터 수와 output gate를 가지고 있는 모듈 구조라고 합니다.

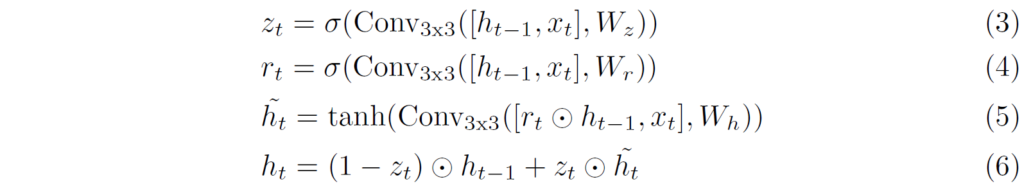
저도 GRU 구조에 대해서 자세히 공부해보고 그런 것은 아니라 자세한 설명은 어렵지만, 정리해보면 입력으로 이전 state의 정보( h_{t-1} )과 현재 단계의 정보(x_{t})가 입력으로 들어가고 이때 각각 r_{t}, z_{t}, \tilde{h}_{t}라는 것을 계산하게 됩니다.
이때 이 r_{t}, z_{t}는 h_{t-1}과 x_{t}를 함께 입력으로 하여 서로 다른 가중치로 연산을 해주어 만들 수 있는데, RAFT에서는 FC layer가 아닌 3x3 convolution을 활용하여 계산이 됩니다. 그리고 이렇게 계산된 r_{t}는 \tilde{h}_{t} 를 구할 때 입력으로 들어가는 h_{t-1} 에 곱해짐으로써 현 단계( h_{t} )를 계산할 때 이전 단계( h_{t-1} )의 값을 얼만큼 반영할지로 활용이 됩니다.
그리고 z_{t} 역시 해당 값 자체는 현재 단계의 state에 곱해지고, (1- z_{t} )는 이전 단계의 state에 곱해짐으로써 현재 단계와 이전 단계가 각각 얼만큼 반영이 될지를 결정하는 요소라고 생각하시면 될 것 같습니다.
아무튼 이러한 GRU 기반의 update operator 연산을 통하여 RAFT는 이전 단계의 flow map으로부터 현재 단계의 flow map을 잘 refinement 할 수 있게 되었으며 이 모듈 하나로 반복해서 refinement하기 때문에 매우 적은 파라미터 수로도 구현이 가능하였습니다.
이렇게 updater operator에서 나온 현재 단계의 state( h_{t] 에 대하여 2개의 컨볼루션을 태우면 현재 단계의 flow map 변화량(즉 \delta f )가 추론이 됩니다. 이렇게 추론된 flow map은 원본 해상도 대비 1/8 크기의 해상도를 지니고 있기 때문에 원본 해상도만큼의 upsampling 과정이 필요하게 됩니다.
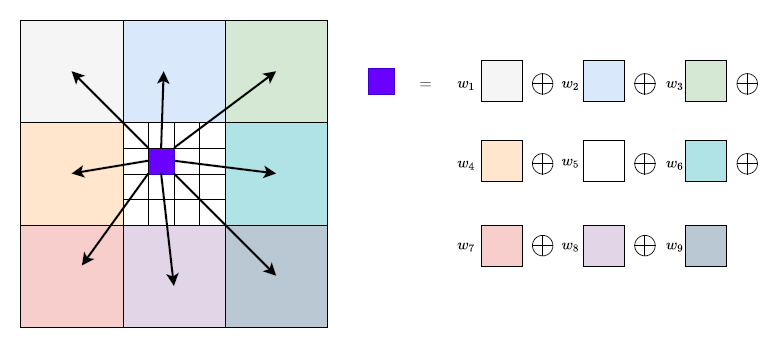
이때 단순하게 bilinear 방식의 interpolation을 사용해도 되겠습니다만, 그렇게 될 경우 디테일한 정보들이 많이 보완되기는 어렵게 됩니다. 따라서 저자는 새로운 upsampling 방식을 제안하였는데, 그냥 쉽게 요약하면 컨볼루션 2개 태워서 H/8 \times W/8 \times (8 \times 8 \times 9) 크기의 마스크를 만든 뒤 9에 해당하는 차원에 softmax를 취해서 가중치 필터를 만든 뒤 계산된 flow map에게 weighted combination을 해주면 원본 해상도 크기의 flow map을 생성할 수 있다고 합니다. 실제 pytorch에서는 unfold 연산을 통해서 구현을 하였다고 합니다.
Loss function
모델 학습은 실제 GT 정보와 예측된 정보 간에 지도학습 방식으로 이루어집니다. 다만 RAFT의 경우 interative하게 flow map을 예측하다보니 loss를 계산할 때도 1~N번째의 flow map에 대하여 모두 loss를 계산하였으며 이때 뒤로 가면 갈수록 loss scale에 더 많은 가중치를 주었다고 합니다.
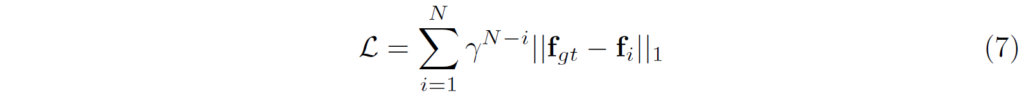
Experiments
그럼 실험 섹션에 대해서 다루도록 하겠습니다. 평가 데이터 셋으로는 지난번 리뷰와 동일하게 Sintel과 KITTI 데이터 셋을 활용하고, 학습에는 합성 데이터 셋인 FlyingChiars와 FlyingThings를 활용합니다.
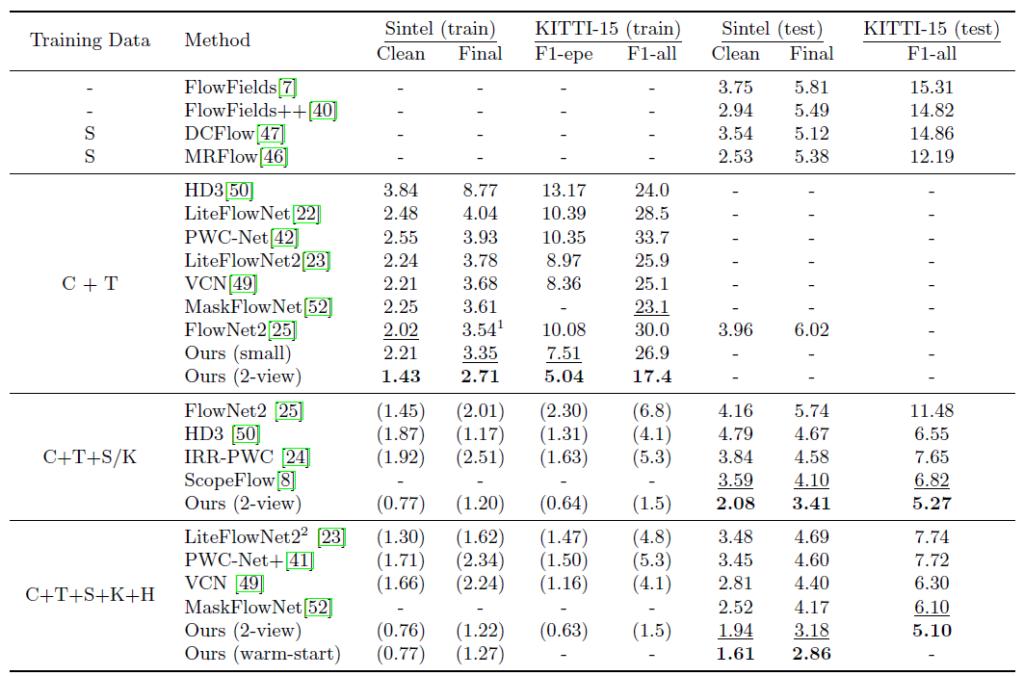
사실 해당 논문이 3년전 논문이라서 그 당시의 타 방법론들과 비교하여 성능이 어떤지 비교하는 부분은 지금 현재에 와서는 그리 중요하다고 보기 어려워 내용을 깊게 다루지 않겠습니다. 요약하면 RAFT가 이전의 방법론들(PWC-Net, FlowNet2)등과 비교하여 매우 압도적인 성능을 보여주고 있다고 말씀드릴 수 있을 것 같습니다.
예시로 Sintel(train) Clean 상황에서 타 방법론들은 2점대에 머무는 판변에 RAFT 혼자서 1.43이라는 월등한 수치를 보여주고 있습니다. 물론 지금 23년도 기준으로는 SOTA 논문들이 1.01~1.10에 수치를 보여주고 있기에 RAFT의 성능이 현재 기준으로는 많이 뒤처진다고 볼 수 있지만 그 당시에 방법들과 비교하면 매우 월등한 수치를 보여주었으며 따라서 best paper로 선정된 것이 아닐까 합니다.
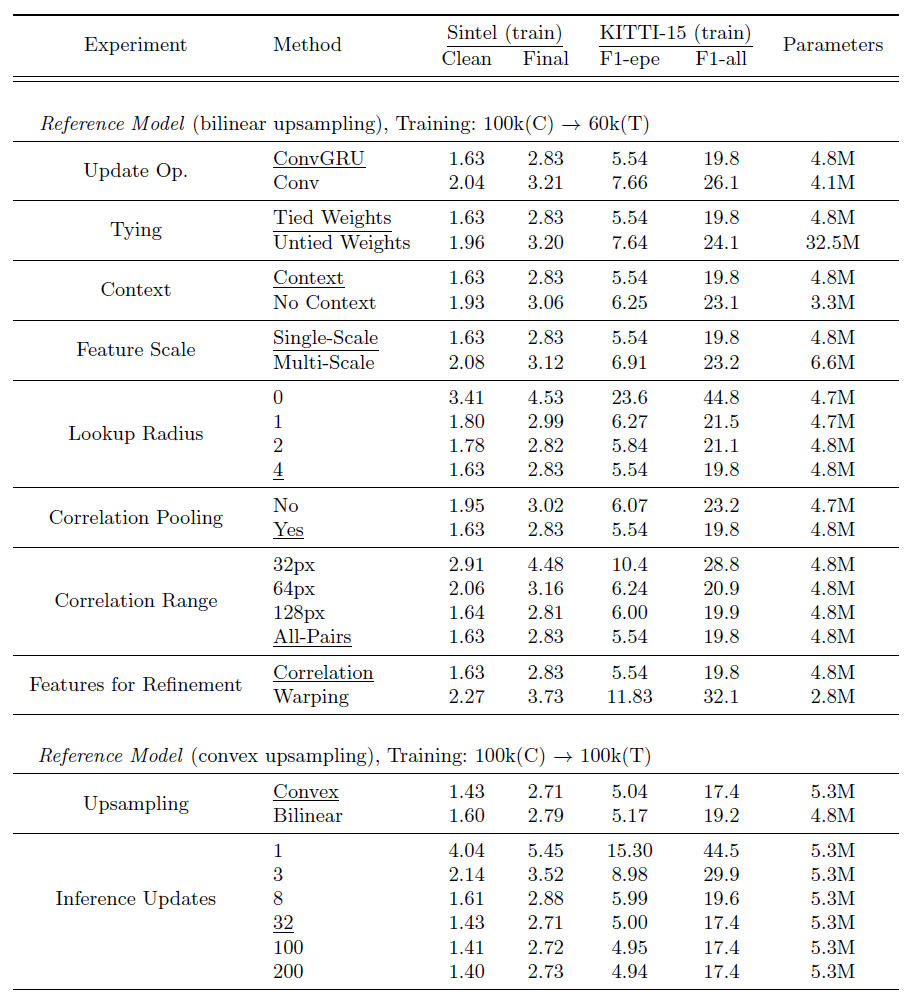
다음은 Ablation Study 관련된 내용입니다. 정말 다양한 요소들에 대하여 ablation 실험을 진행하였는데 위에서부터 차례대로 설명해보겠습니다.
- Update Operator: 먼저 update operator 관련 실험입니다. 본문에서도 얘기했다시피 RAFT는 update operator로 GRU 구조의 모델을 활용하였다고 합니다. 여기서 이 ConvGRU 모듈을 단순히 3개의 convolution layer로 바꾸게 될 경우에 모든 데이터 셋 및 평가 지표에서 성능이 하락하는 것을 볼 수 있습니다. 따라서 optical flow를 update 할 때는 GRU의 컨셉이 훨씬 좋은 것을 알 수 있습니다.
- Tying: 다음은 Weight Tying에 대한 실험입니다. 해당 실험에 대해 쉽게 요약하면 optical flow를 예측할 때 N번 반복해서 refinement를 거치게 될텐데, 이때 N번 refinement를 수행하기 위해서 N개의 ConvGRU를 놓을지, 혹은 하나의 ConvGRU의 가중치를 계속 공유해서 N번 반복할지에 대한 실험을 의미합니다. 결과적으로 하나의 모듈에서 가중치를 공유하는 것이 N개의 GRU 모듈을 놓는 것보다 성능적인 측면에서, 그리고 학습 파라미터 관점에서 모두 좋은 것을 볼 수 있었습니다.
- Context: 다음은 Context Encoder의 유무에 대한 실험입니다. Context Encdoer는 Feature Extractor와 동일한 구조이면서 첫번째 영상에 대해서만 context feature를 추출한다고 말씀드렸습니다. 이러한 Context Encoder의 output 값이 ConvGRU 모듈의 입력으로 사용되지 않을 경우 성능이 꽤나 감소되는 것을 확인할 수 있습니다. 저자는 입력 영상에 대한 Context 정보가 들어가야만 flow map의 boundary 등과 같은 영역들이 잘 표현될 수 있었다고 합니다.
- Feature Scale: 다음은 Correlation Volume을 만들 때, Feature Extractor에서 추출한 Feature map의 Scale을 1/8의 결과만을 사용할 것인지 아니면 multi-scale로 확장해서 계산할 것인지 대한 결과입니다. 결론만 말씀드리면 1/8의 single scale만을 활용해서 correlation volume을 만드는 것이 세세한 매칭을 잘 할 수 있어 가장 효과적이라고 합니다.
- Lookup Radius: lookup radius는 4D correlation volume을 3D correlation map으로 만들기 위하여 현재 예측된 flow map으로 local grid를 생성 후 indexing하는 과정이라고 설명드렸습니다. 여기서 이 local grid를 생성하는 범위(r)를 몇으로 설정하느냐에 따른 분석 실험입니다. 결과적으로 r의 값을 크게 할 수록 대체로 좋은 성능을 보여주는 것을 확인할 수 있었습니다.
- Correlation Pooling: RAFT는 multi-scale의 feature map으로 correlation volume을 만드는 것이 아닌, Single-scale의 feature map으로 Correlation volume을 만든 후 맨 뒤에 두 차원에 대하여 avgpooling을 수행함으로써 2번째 이미지에 대한 spatial 차원 축을 multi-scale로 가져간다고 설명드렸습니다. 이러한 pooling을 과정을 적용하지 않았을 경우에 성능이 크게 감소하는 것을 볼 수 있는데, 저자는 pooling을 과정을 통하여 large displacement에서의 대응관계까지도 함께 고려할 수 있어 성능을 향상시킬 수 있었다고 합니다.
- Correlation Range: 다음은 Correlation volume을 계산할 때 spatial range 값을 몇으로 할지 설정입니다. 즉 두 feature map 사이에 내적을 할 때 일정한 범위의 window 내에서 수행할지(Local), 혹은 전체 feature map에 대하여 모두 계산할지(Global)에 대한 실험입니다. 결과적으로 Ragne 값은 크면 클수록 좋은 성능을 보여주는데, 이때 재밌는 점은 Sintel에서는 128px 범위와 global에 대한 성능이 매우 유사하다는 것입니다. 이는 Sintel의 경우 128픽셀 이내에 displacement가 모두 정의되어서 그렇다고 소개하는데 KITTI의 경우에는 128픽셀 그 이상의 displacement가 발생하는 경우가 있기에 global하게 연산하는 것이 더 좋은 성능을 이끌어낼 수 있다고 합니다. 결과적으로 저자는 이렇게 데이터 셋마다 차이가 나는 상황에서 range 값을 하드코딩하는 것보다는 그냥 전체에 대해 계산하는 것이 여러 상황에서 일반적으로 잘 동작할 것으로 판단하였습니다.(물론 그만큼 속도는 더 느려지겠지만요.)
- Features for Refinement: 해당 실험은 쉽게 말해서 Correlation Volume을 lookup 방식으로 indexing하여 refinement하는 것이 아니라, 이전 방법론들처럼 feature map 자체를 예측된 flow map을 통하여 warping하는 방식으로 보정하는 실험을 의미합니다. 이러한 warping 기반의 보정 방식은 모든 데이터 셋에서 매우 떨어지는 성능을 보여줍니다.
- Upsampling: 다음은 1/8 scale의 flow map을 원본 해상도로 upsampling하는 방식에 대한 실험입니다. 일반적인 bilinear interoplation과 달리 저자가 제안하는 Convex 방식의 upsampling이 더 좋은 모습을 보여주고 있는데, 저자는 자신들이 제안하는 샘플링 방식이 경계면을 더 잘 보완하고 추정한다고 합니다.
- Inference updates: 마지막으로 inference 과정에서 update 횟수를 몇번 지정할지에 대한 실험입니다. 물론 RAFT가 학습단계에서는 11번의 update를 통해서 학습을 진행하였지만 GRU 모듈을 활용한 덕분에 이론적으로 (시간만 제공된다면) 100번 200번 넘는 횟수로 보정을 할 수 있습니다. 일단 실험적으로는 32번의 반복 끝에 최적의 성능을 달성하였으며 그 이후에 더 많은 횟수로 업데이트하는 것은 그리 유의미한 성능을 일으키지는 못했다고 합니다.
Timing and Parameter Counts
다음 실험 결과는 타 방법론들 대비 추론 속도와 파라미터 크기에 대한 비교 결과를 나타냅니다.
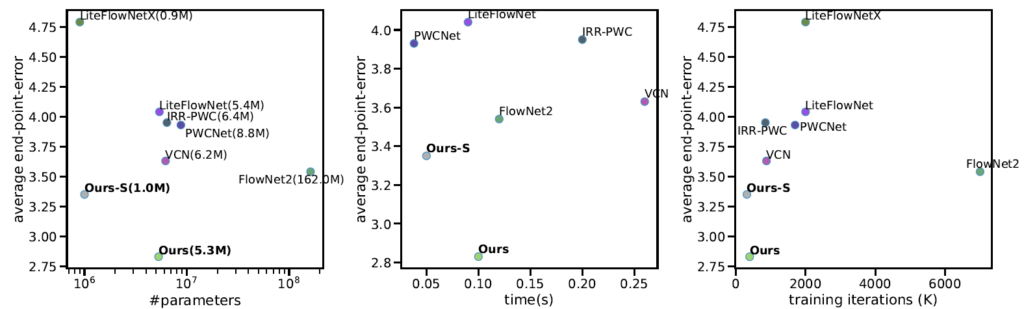
위에 그림을 보시면 제안하는 RAFT 방법론이 타 방법론들 대비해서 비슷한 파라미터 수를 가지고 있으면서도 크게 성능을 압도하는 것을 볼 수 있습니다(좌측 그래프). 그리고 가운데 그래프에서는 제안하는 방법론이 LiteFLowNet과 비슷한 추론속도(약 100ms 정도)를 보여주고 있지만 성능은 매우 큰 폭으로 이기고 있음을 보여주고 있으며, 마지막으로 우측 그래프에서는 RAFT가 더 적은 학습 iteration을 돌고도 빠르게 좋은 성능으로 수렴한다는 점을 언급하고 있습니다.
Qualitative Results
정성적 결과들을 보여드리면서 리뷰를 마무리 짓도록 하겠습니다.




결론
제가 최근들어 optical flow 분야에 대한 방법론들을 쭉 훑고 있으면서 느끼는 것이, 요새 SOTA 논문들이 대부분 RAFT의 컨셉을 여전히 많이 활용하고 있으며, 비교 대상으로도 많이들 사용하고 있는 것 같습니다. 물론 지금 SOTA 방법론들과 RAFT의 성능 차이는 RAFT가 그 당시 19년도 SOTA 방법론들과 비교하였을 때 보여주었던 성능만큼 차이가 나긴 하지만, RAFT가 3년전 논문임에도 불구하고 여전히 많은 파급력을 일으키고 있다는 생각이 드네요. 논문을 읽어보면 정말 핵심만을 집중적으로 말하는 글 덕분에 쉽게 컨셉을 이해할 수 있으며(그 덕분에 오히려 이해가 안되는 부분은 계속 안되긴 합니다허허) 모처럼 좋은 논문을 읽은 것 같아서 좋습니다.
안녕하세요, 좋은 리뷰 감사합니다.
optical flow에 대해 맛만 보려고 했더니 내용이 엄청 어려운 것 같습니다..
간단한 질문 하나가 있습니다. 그림1에서 4 번째 단락에서 coarse-to-fine 형식의 방법론에 대해 저자가 단점을 언급한 부분이 있습니다.
이전에 제가 리뷰한 논문 중에서 coarse-to-fine 방법론을 적용하여 문제를 해결해 나가는 내용을 다루었고 최근 연구에서 coarse-to-fine 방법론을 많이 적용하는 추세라고 알고 있었으나, 언급하신 해당 단점들은 task가 optical flow를 예측하는 것이기 때문에 수반되는 문제인지 궁금합니다.
감사합니다.
안녕하세요.
질문해주신 내용에 제 생각을 말씀드리면, optical flow 혹은 segmentation 등과 같이 pixel level에서의 dense한 preidction을 수행하기 위해서는 사실 local 정보들을 잘 보고 표현할 수 있어야만 합니다. 하지만 그렇다고해서 고해상도의 feature map에 대하여 반복적인 컨볼루션 연산을 수행하는 것은 많은 연산량을 필요로 합니다.
따라서 희진님이 리뷰해주신 논문들도 그렇고 대부분의 vision task에서는 Coarse-to-Fine이라는 컨셉을 활용합니다. 즉 글로벌하게 한번 틀을 잡아놓고, 점차 해상도 혹은 스케일을 키워가면서 세부적인 디테일들을 분석하겠다는 것이죠. 연산량 측면에서 그리고 컨셉적인 측면에서 놓고 보았을 때 Coarse-to-Fine은 차선책으로써 매우 훌륭하다고 볼 수 있습니다.
하지만 제가 처음에 언급한 문제점인 High Resolution에서의 많은 연산량을 최소화할 수만 있다면? 그러면 굳이 Coarse-to-Fine 형식을 고집할 필요가 없지 않을까요? RAFT 저자는 Coarse-to-Fine 형식과 유사하게 연산량 측면에서 강한 이점을 가지면서도 High-Resolution에서 반복적인 연산 혹은 업데이트를 할 수 있다면 훨씬 더 좋을 것이라고 판단하였으며 따라서 저자가 제안하는 GRU 기반의 updater operator를 통하여 single scale에서도 연산량을 가볍고 빠르게 동작시킬 수 있도록 한 것입니다.
물론 그렇다고해서 저자가 Coarse-to-Fine 자체가 잘못됐다고 주장하는 것은 아닙니다. Coarse-to-Fine 개념에서 이 Coarse라고 하는 것이 결국 영상의 전반적인 큰 문맥을 볼 수 있는 수단이기 때문에 영상 인식 관점에서 매우 중요한 요소이기도 합니다. 저자도 이를 인지하여 Correlation Volume을 생성할 때 avgpooling 과정을 통하여 multi-scale(즉 coarse~fine 단계의 volume)을 형성하여 flow 예측에 사용합니다.
즉 Coarse-to-Fine 컨셉은 연산량 관점 뿐만 아니라 영상의 전반적인 문맥부터 세부적인 디테일까지 모두 고려할 수 있는, 영상을 다루는 분야에서는 적용하면 성공이 보장되는 컨셉이라고 생각합니다.