masked autoencoding은 language와 image domain에서 self-supervised learning에 큰 성공을 거두었다. 하지만 masking방식 기반의 pretraining은 3d point cloud를 이해하는데 있어서 이점을 아직 보여주지 못했다. 이에 대해 논문에서는 기존의 pointnet과 같은 backbone이 학습 중에 masking으로 인한 데이터 분포와 test 데이터의 분포 간 불일치를 적절하게 처리할 수 없기 때문이라고 지적한다. 본 논문에서는 point cloud에 대해 변별력있는 mask pretraining transformer framework인 MaskPoint를 제안함으로써 이 격차를 해소하고자 한다. 여기서 핵심 아이디어는 point cloud를 discrete occupancy value로 표현하고(0 또는 1) masked object points와 sampling된 noise point 사이의 간단한 이진 분류를 수행한다. 이러한 방식을 통해 point cloud를 sampling할 때 sampling variance에 강인하며 풍부한 표현을 학습할 수 있었다고 한다.
Introduction
최근에 self-supervised learning이 많은 발전을 이뤄내고 있다. 특히 masked autoencoding task는 masked된 data를 unmasked된 data로부터 reconstruct인데, 이 masked autoencoding방식이 self-supervised learning에서 text understanding에 많이 사용되어왔고 이어서 최근에 image understanding에서도 좋은 결과를 보여주고 있다. 하지만 이 masked autoencoding이 point cloud data에서는 text나 image에서의 성능 level을 보여주지 못하고 있다고 한다. self-supervised learning방식은 실제 세계에서 취득한 3d point cloud의 정확한 annotation을 하는데 필요한 비용과 어려움을 해결해줄 수 있고, 또한 masked autoencoding은 3d point cloud에서 각 point를 masking하는 것은 어렵지 않은 일이기 때문에 충분히 적용할만한 가치가 있다고 생각된다. 저자는 point cloud data에서 다른 text나 image domain level의 성능을 보이지 못하는 이유에 대해 pointnet과 같은 standard backbone은 masking으로 인한 train과 test data의 mismatch한 분포를 다루기가 어렵기 때문이라고 주장한다. pointnet과 같은 경우 local한 영역의 정보를 aggregate하여 사용하는데 이때 masking을 하게되면 local한 영역의 정보가 drastical하게 손상되고 masked training scene과 unmasked test scene의 주변 local영역에 대한 분포 차이가 커지기 때문이라고 한다. 반면 transformer의 경우 self-attention을 통해train data scene에서 masking되지 않은 부분만 처리할 수 있으며 masking된 부분에 영향을 받지 않는다. 이러한 특성이 transformer가 point cloud에 대한 self-supervised masked autoencoding의 이상적인 backbone이 될 수 있다고 한다.
image 이해를 위한 sota방식인 MAE(masked autoencoder)는 image patch의 랜덤한 집합을 masking하고 transformer encoder를 masking되지 않은 patch에 적용하며, masking된 patch의 positional encoding을 받아들이는 transformer decoder를 훈련시켜 원래 pixel값을 복원하게된다. 하지만 여기서 3d point cloud의 경우 2d image와는 다르게 masking된 point cloud의 위치를 복원해야하는데 3d point의 raw representation은 공간적인 xyz 위치이기 때문에 pixel값을 사용하는 2d 방식을 direct하게 사용할 수 없을 것이다. xyz의 위치정보를 예측하기 위해 decoder를 학습시키는 것은 어짜피 positional encoding을 통해 정보를 얻을 수 있으니 trivial한 일이고 meaningful한 feature를 얻기는 어려울 것이다.
따라서 본 논문에서는 point cloud masked autoencoding을 위해 간단한 binary point classification 목표를 제안한다. 먼저 points들을 local neighbors로 grouping하고 랜덤하게 masking을 한다. 그리고 transformer encoder는 unmasked point group을 사용하여 self-attention을 통해 각 group을 encoding한다. transformer decoder는 masking된 point에서 real query를 sampling하고 fake query는 전체 3d space에서 random하게 sampling한다. 그리고 deocder query와 encoder output간 cross-attention을 수행하고 decoder 출력에 binary classification head를 적용하여 real query와 fake query를 구별하도록 한다. 이러한 design이 local한 visible point group에서 3d object 모양을 추론하는데 효과적이라고 한다. 기존의 point cloud에 self-supervised를 적용한 방법 중 대표적인게 point-BERT가 있는데 이 방식은 사전학습시 많은 연산량을 요구해서 시간이 오래걸린다는 단점이 있다고 한다. 본 논문에서 제안하는 방법론과 비교했을 때 transformer encoder를 활용하여 unmasked point에만 처리하면 되기 때문에 사전 학습에서 4배 이상 빠른 속도를 보일 수 있었다고 한다.
정리하자면 main contribution은 아래와 같다.
1. novel masked point classification transformer, MaskPoint, for self-supervised learning on point clouds
2. simple and effective approach, and achieving sota performance on a variety of downsteam tasks(such as object classification, object detection, part segmentation, few-show object classification)
3. show that a standard transformer architecture can outperform sophisticatedly designed poitn cloud backbones for the first time.
Related Work
Transformers
transformer는 처음에 NLP task에서 sequence 길이가 길어질수록 과거 중요한 정보에 대한 손실이 커지는 long-term dependency를 고려하고자 등장하였고 좋은 성능을 보였다. 최근에는 image나 video에서도 적용이 되는데 3d point cloud에도 적용하려는 시도가 있었다. PCT, point transformer, 3DETR같은 방법론들이 존재한다. 하지만 해당 standard transformer를 통한 방식들은 다른 sota convolution기반의 방법론들과 성능 차이가 크게 났다. 본 논문에서는 새로운 masked point classification으로 self-supervised learning을 통해 standard transformer를 point cloud에 적용했을 때 의미있는 feature 표현력을 가질 수 있었고 downstream task에서도 좋은 성능을 보일 수 있었다.
self-supervised learning
self-supervised learning(SSL)은 data자체로부터 의미있는 표현력을 학습하도록 하는 것이 목표이다. self-supervised learning도 point cloud data에 대해 적용되었었다. 하지만 3d object의 shape에서의 point sampling할 때 variance가 존재하기 때문에 original point cloud를 reconstruct하는 것은 variance를 포함할 수밖에 없다. 본 논문에서는 간단하지만 효과적인 discriminative classification task를 통한 방식으로 sampling variance에 강인한 표현력을 학습할 수 있도록 했다.
mask based pretraining
masking하는 방식은 모델의 robustness를 향상시키기 위한 방법으로 다양하게 사용된다. self-supervised learning의 경우 핵심 아이디어는 masking된 content정보를 주변 context를 기반으로 예측하도록 모델을 학습하는 방법이다. 이것을 transformer를 사용할 경우 token-based representation과 model이 long-range dependency를 고려하기 때문에 좋은 결과를 보였다고 한다. 최근에 Masked AutoEncoder(MAE)의 경우 70%이상을 masking하여 이렇게 masked된 patch를 pixel level에서 reconstruction하였다. 기존에 point cloud에 mask를 통해 transformer를 이용한 self-supervised 접근법은 Point-BERT가 유일한데, 만족할만한 성능을 얻기 위해서는 사전학습에 들어가는 시간과 비용이 크다는 단점이 존재한다. 본 논문에서 제안하는 masked point discrimination 접근방식은 Point-BERT보다 4배 빠르지만 sota 성능을 달성할 수 있었다.
정리하자면 새로운 key novelty는 discriminative point classification objective를 통해 point cloud에서 sampling variance issue를 보완하고자했다.
Approach
목표는 human supervision없이 semantic feature 표현을 학습해서 downstream point cloud에서 잘 작동하는 것이다. 저자는 self-supervised learning design을 아래 그림을 보고 영감을 얻었다고 한다.
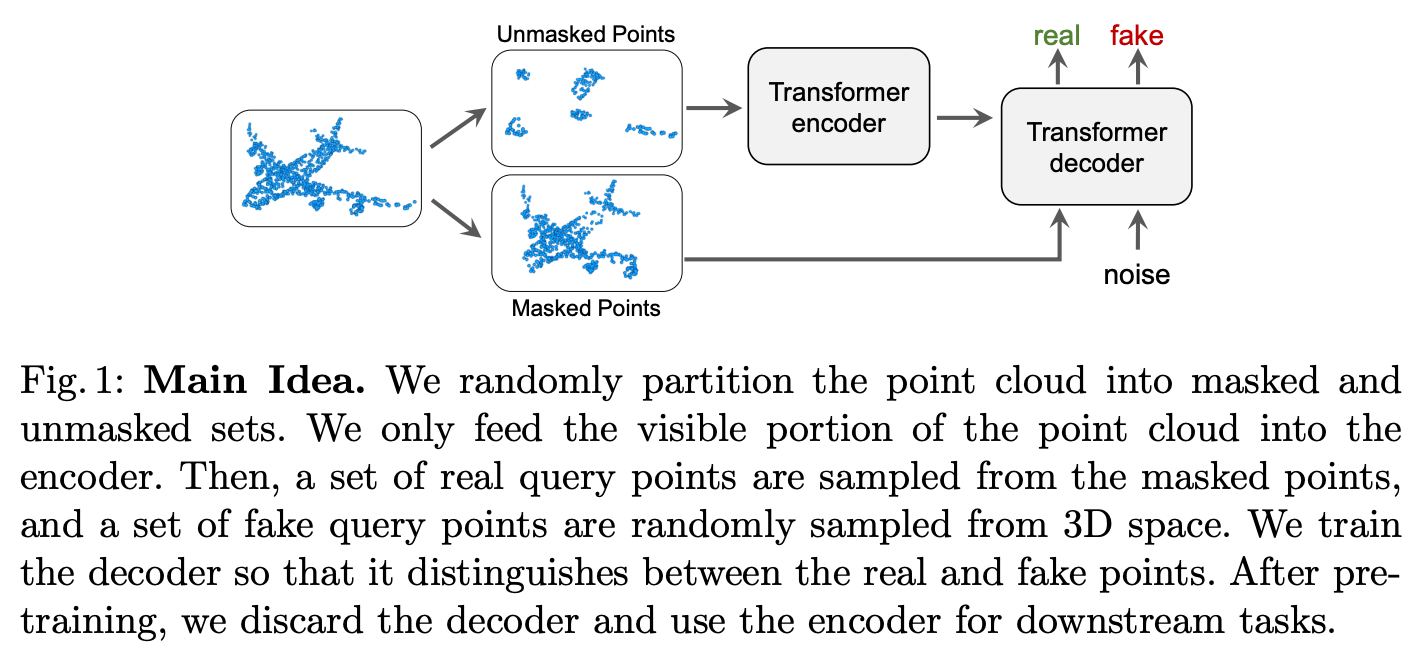
비행기가 point cloud로 표현되어있는데 masking을 많은 부분해서 unmasked points가 거의 없는 것을 확인할 수 있다. 사람의 경우에는 경험이나 의미론적인 이해를 통해 unmasked point를 보고 비행기라고 생각해서 앞부분, 날개, 꼬리부분 등을 나타내는구나라고 생각할 수도 있고 대략적인 위치까지 생각해볼 수도 있다. 즉, 다시 말하면 우리는 이미 비행기가 무엇인지 알고 있기 때문에 작은 point cloud부분만을 가지고도 누락되어있는 정보를 복구할 수도 있다. 비슷하게 visible한 부분이 주어진 point cloud의 masking된 부분에 대한 정보를 복구할 수 있도록 model을 학습시킨다면 이 model이 object의 의미론적인 정보를 학습하고 예측할 수 있을 것이다.
하지만 사람도 예를 들어 날개의 정확한 두께나 비행기의 정확한 길이와 같은 정보는 명확하게 예측하기 어렵기 때문에 모든 masking된 points들을 정확하게 복원하는 것은 어렵고 불가능할 수 있다. 대신 3d space에서 3d point를 sampling하여 해당 point가 object에 속하는지를 판단하는 것은 좀 더 쉽게 답할 수 있을 것이다. 이것처럼 discriminative point classification task는 reconstruction task보다 덜 모호하다. 하지만 적은 수의 visible points에서 masking된 points를 추론하기 위해서는 object의 semantic한 정보에 대한 깊은 이해가 필요하다.
Masked Point Discrimination
우선 전체적인 approach가 어떻게 작동하는지 살펴보면 먼저 input point cloud P ∈ RN×3를 random하게 masked M과 unmasked U로 나눈다. 여기서는 transformer encoder를 사용하여 self-attention을 통해 sparse하게 분포되어있는 unmasked tokens U들 간 상관관계를 modeling하게되고 encoding된 latent representation tokens L를 얻게된다. 그리고 real query point집합 Qreal과 fake query points집합 Qfake를 sampling한다. Qreal은 masked point 집합 M에서 sampling하고 Qfake는 전체 3d space에서 random하게 sampling한다. 그리고 각 decoder query q ∈ {Qreal, Qfake}와 encoder output L 간 cross attention CA(q,L)을 통해 masking된 query point와 masking하지 않은 points들간 relationship을 modeling한다. 그리고 binary classification head를 통해 real과 fake query를 구별한다.
Discarding Ambiguous Points
위의 과정 중 3d space에서 random하게 fake query point를 sampling할 때, 어떤 points들은 object surface에 가까운 points들이 sampling될 것이다. 이런 points들은 실제 대상 object에 존재하지만 label이 fake이기 때문에 훈련에 어려움을 줄 수 있고 실제로 vanishing gradient문제를 일으킬 수 있다고 한다. 따라서 안정적인 학습을 위해 object point로부터 euclidean 거리가 γ보다 작은 fake query points pˆ ∈ Qfake들을 제거했다 (pi ∈ P: mini ||pˆ−pi ||2 < γ). γ은 input point cloud size에 따라 dynamic하게 설정되었다.
3D Point Patchification
point 하나씩 transformer encoder로 입력하면 연산량이 너무 많아지기 때문에 patch단위로 embedding하기위해 3d point patch로 변환하게 된다. input point cloud P ∈ RN×3가 있을 때 S points {pi}i=1S들이 farthest point sampling을 통해 patch center로 sampling된다. 그리고 각 patch center마다 k nearest neighbors를 합쳐 3d point patch {gi}i=1S를 생성한다. 이후에 pointnet을 통해 각 3D point patch gi ∈ Rk×3 를 encoding하여 feature embedding fi ∈ Rd을 얻는다. 이 과정을 통해 S개 token과 각 token의 상응하는 features {fi}i=1S, center coordinates {pi}i=1S를 얻는다.
Transformer Architecture
전체 network의 architecture는 아래 figure 2와 같다.
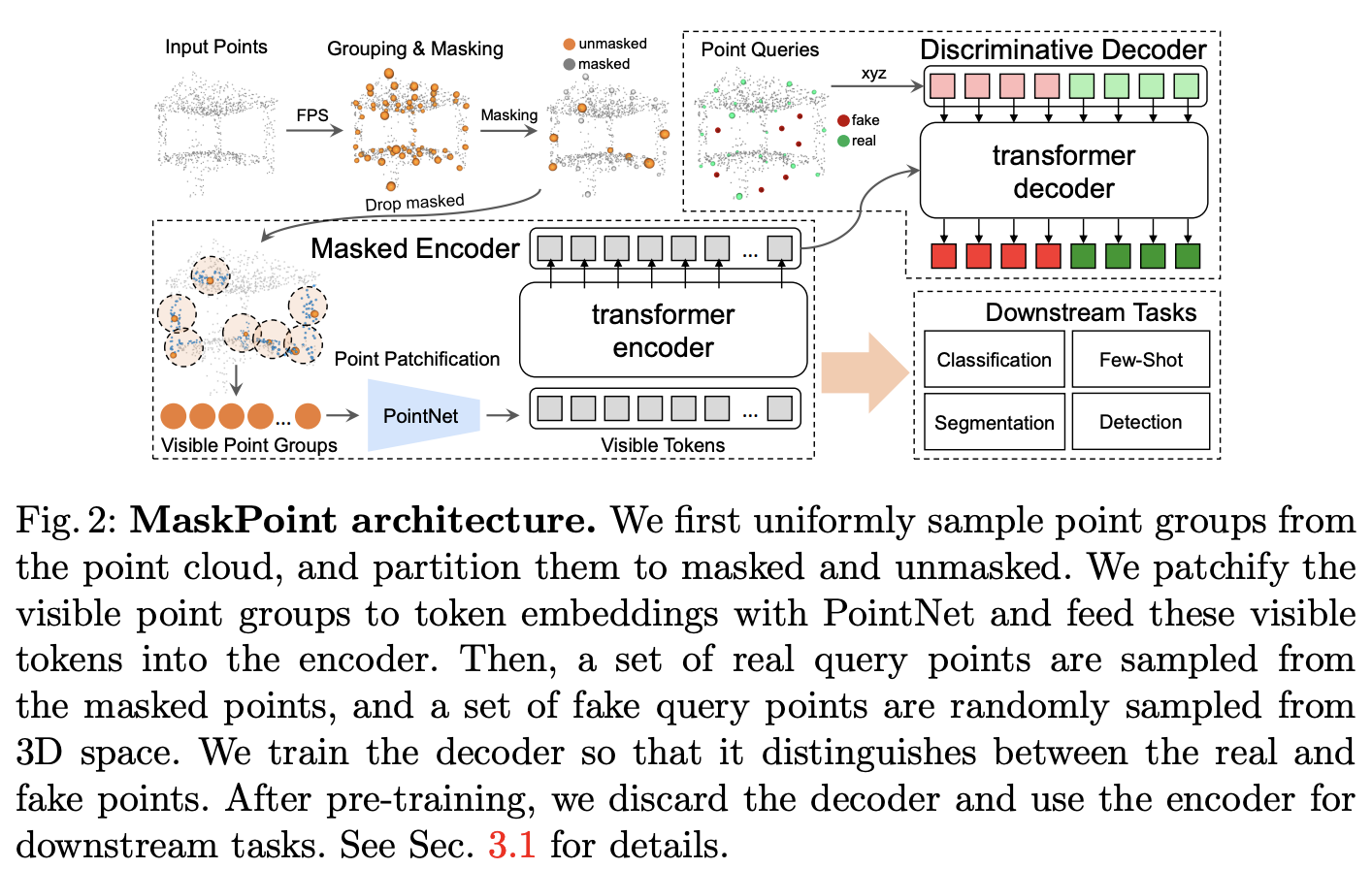
여기서는 encoder가 multi-head self-attention(MSA)과 feed forward network(FFN)으로 구성된 standard transformer의 encoder를 encoding backbone으로 사용했다. transformer의 encoder를 통과하기 전에 위에서 설명한대로 patch-wise feature {fi}i=1M 를 구성했다. notation이 조금 헷갈릴 수 있겠지만 위에 token 수가 S에서 M으로 바뀐 것이다. 이 patch feature {fi}i=1M에 MLP positional embedding {posi}i=1M을 적용하고 class token E[s]를 patch feature 앞에 추가해서 encoder의 input은 다음 수식과 같이 나타내게된다 I0 = {E[s],f1 + pos1 , · · · ,fM + posM}. 그리고 n개의 transformer block을 통과하고 나서 각 point patch에 대한 feature embedding In = {En[s],fn1 , · · · ,fnM}을 얻게 된다.
decoder에서는 Nq real query points Qreal와 Nq fake query points Qfake를 sampling하게된다. encoder output In과 positional embedding {posi}i=1M ,그리고 Qreal, Qfake와 그 positional embedding {posiQ}i=12N을 transformer decoder에 전달한다. decoder output은 MLP classification head를 통과하며 classification head는 binary focal loss를 이용하여 학습된다.
downstream task를 할 때에는 point patchification module과 transformer encoder의 pretrained weight가 초기화에 사용된다.
An Information Theoretic Perspective
이상적으로는 model이 point cloud의 풍부한 feature representation을 학습하기를 원한다. encoder E의 latent representation L은 원래 point cloud P를 복구시키기위한 충분한 정보를 제공해야한다. 즉 P와 L가 가지는 상호 정보를 최대화 해야한다. 이것을 논문에서는 I(P;L)로 나타냈다. 하지만 P에서 L과 관련된(연관된) P의 정확한 확률 분포를 알아야 하기 때문에 I(P;L)를 direct하게 추정하는 것은 어렵다고 한다.
따라서 여기서는 3d bounding box 내 point에 대해 occupancy values라는 것을 통해 point cloud distribution을 표현한다 B ∈ {x, y, z, o}L, where (x, y, z) ∈ R3 , o ∈ {0, 1}, L은 sampling된 points. 결국 real, fake query points에 대해 상응하는 occupancy label을 할당하여 binary classification objective로 model의 output을 최적화한다.
Why not reconstruction, as in MAE?
여기서는 기존 image에 대한 Masked AutoEncoder(MAE) 접근 방식에 사용된 reconstruction objective(masking되지 않은 point에서 original point cloud를 reconstruction)가 point cloud 설정에 작동하지 않는 이유에 대해 설명한다.
먼저 MAE에서 self-supervised learning은 입력 image의 unmasked patch를 기반으로 masking된 patch를 재구성한다. 특히 masking된 각 image patch query에 대한 2d spatial position이 주어졌을 때 rgb pixel값을 생성하는 것이 목표이다. 하지만 3d의 경우 masking된 3d point patch query에 대한 spatial xyz값을 생성하는 것이기 때문에, 이것은 query에 해당하는 spatial한 정보가 이미 포함되어있어 model입장에서는 trivial한 것이다. 따라서 model이 의미있는 feature representation을 학습하는 것을 막는다고 한다.
또 point cloud에 대한 reconstruction objective의 또 다른 문제는 point sampling variance가 존재한다는 것이다. 좀 더 자세히 설명하자면 object의 실제 3d 모양은 continuous한 surface를 가지지만, point cloud는 연속적이지 않고 discrete하게 sampling된다. 예를 들어 point cloud 2개를 sampling하여 하나를 gt, 다른 하나를 model의 예측으로 표시한다고 가정해보았을 때 두 point cloud집합 모두 object의 동일한 geometric shape을 반영하지만, 두 point cloud set 사이의 Chamfer distance(두 point cloud set간의 shape 차이를 측정하는데 사용)는 0이 아니게될 것이다. 아래 그림을 보면 이해가 수월할 것 같다.
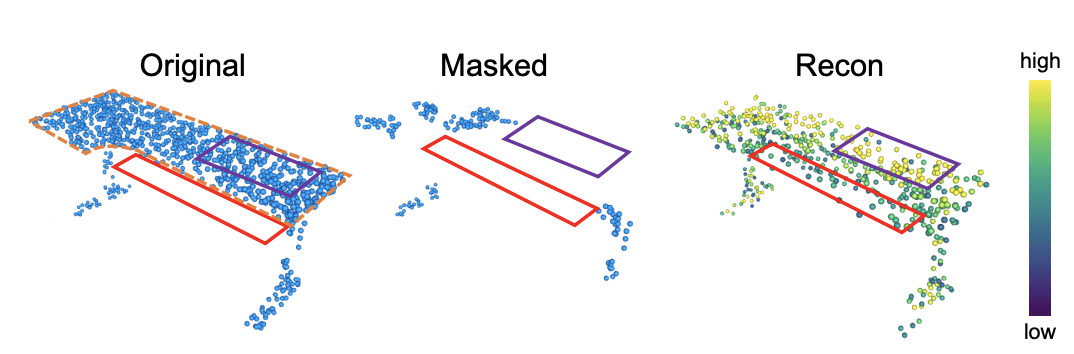
이 경우에 loss를 줄이는 방향으로 학습하게 되면(chamfer distance를 0으로) 첫 번째 point cloud set과 비슷해지도록 예측을 생성하게 될텐데 이 방식은 실제 object의 분포 중 한 표본을 따라 가는 것이기 때문에 불필요하게 어렵게 최적화하는 문제가 될 수 있다고 한다.
Experiments
실험은 object classification, part segmentation, object detection, few-shot object classification에 대해 수행했는데 object detection에 대해서만 살펴보도록 하겠다. 먼저 dataset은 single-view depth map(rgbd) video인 ScanNet을 사용했다. 이때 rgb정보는 사용하지 않고 geometry 정보만 사용했다고 한다. 그리고 여기서는 pre-training시 scannet 전체 dataset의 일부분을 사용했는데 10 frame마다 sampling해서 사용했고 이를 ScanNet-Medium이라고 표현한다. pre-training할 때 각 3d scene에서 2만개의 points를 sampling해서 사용했고 총 2048개 group을 생성했으며 각 group은 64개의 points를 포함한다.

transformer encoder는 12개 layer를 가지는 standard transformer encoder를 사용했고 encoder block의 hidden dimension은 384, head는 6개로 했다. transformer decoder는 single-layer transformer decoder를 사용했다.
기존에 Point-BERT에서는 object-level의 classification과 segmentation task에 대해서만 실험결과를 보였는데 저자는 더 challenging한 scene-level인 ScanNetv2에서 3d object detection에 대한 평가도 수행했다고 한다. ScanNetV2는 real-world에서 취득한 indoor scenes으로 구성된 rgbd dataset으로 axis-align bounding box(AABB) 형태로 18개의 object categories가 labeling되어있다.
본 논문에서는 3d object detection을 평가할 때 기존에 가장 비슷한 모델인 Point-BERT와 비교를 했다. downstream model는 Ours(MaskPoint)와 point-BERT모두 3DETR을 사용했다. 3DETR은 end-to-end방식의 transformer를 기반으로하는 3d object detection pipeline이다. finetunning시에 input point cloud는 pointnet++에서 points를 sampling하는데 사용되었던 set abstraction layer(SA layer, votenet에서도 사용됨)를 통해 2048 points로 downsampling된다.
아래 Table 5에서 실험 결과를 확인할 수 있다.

가로선 아래 부분만 집중해보면 되는데 본 논문에서 제안하는 방법인 MaskPoint가 다른 3d object detection model인 3DETR보다 2%정도 좋은 성능을 보이는 것을 알 수 있다. 또 기존 방법론 중 가장 비슷한 방법론인 point-BERT와 비교했을 때 point-BERT는 오히려 성능이 하락한 것을 확인할 수 있는데, 내부적으로 높은 비율의 masking된 token으로부터 학습된 dVAE가 의미있는 표현력을 얻는데 방해를 주었을 것이라고 한다. 또 3DETR에서는 encoding layer의 수가 증가할수록 detection 성능 변화가 미미했는데, MaskPoint의 경우 encoding layer를 3에서 12로 해주었을 때 더 좋은 성능을 보이는 것을 알 수 있다. 이 결과를 통해 large unlabeled dataset으로부터 사전학습을 하는 것이 모델 encoder가 더 풍부한 표현력을 담을 수 있는 능력이 있다는 것을 보여준다. 가로선 위의 방법론들은 단순히 비교를 위해 성능을 reporting해놓았는데 transformer based가 아닌 votenet을 기반으로 하는 방법론들이라 fair한 비교를 하기는 어렵다. 그래도 전반적인 성능의 경향성을 보았을 때 transformer를 기반으로 하는 방법론들이 self-supervised learning에서 더 좋은 결과를 보이는 것을 알 수 있다.
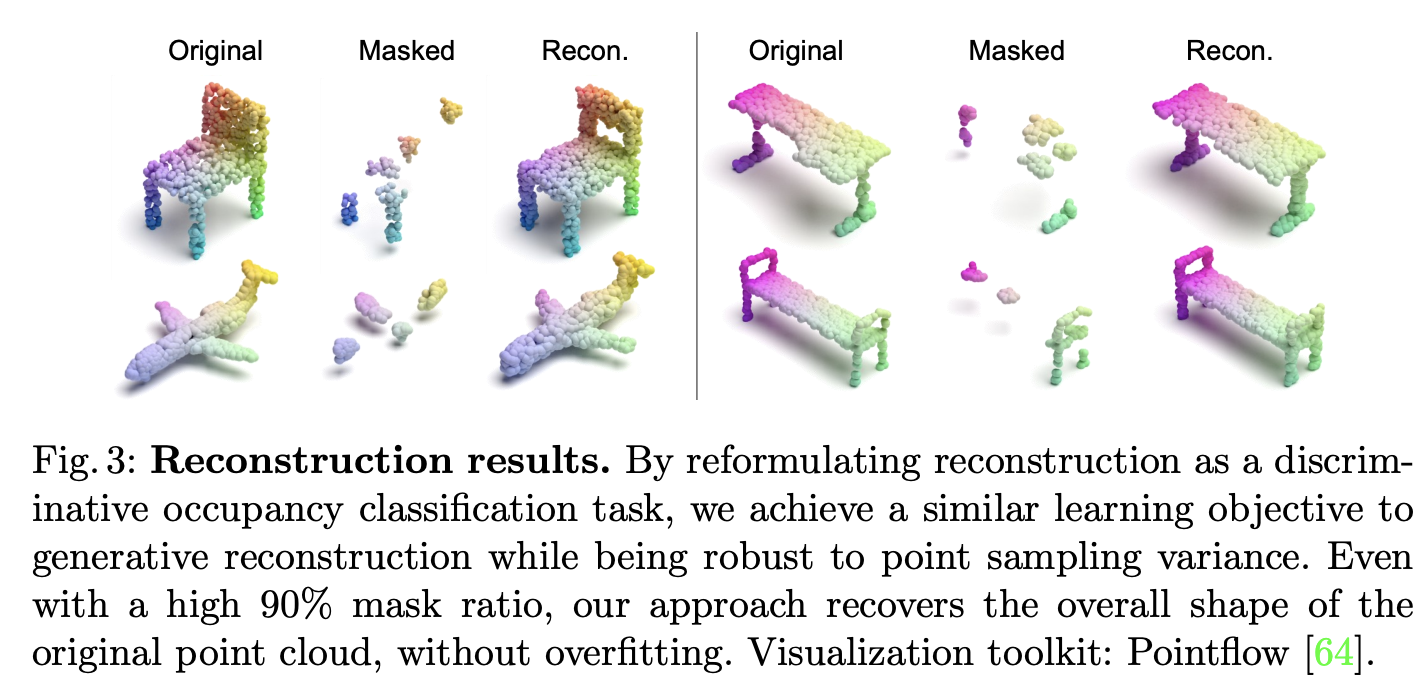
아래 Figure 3은 decoder를 통해 reconstruction quality를 정성적으로 평가한 그림이다. 90%의 mask ratio를 주고 original point cloud의 전반적인 shape을 잘 복원한 것을 확인할 수 있다.
그래서 masking ratio가 어떻게 되는지 계속 궁금했는데 ablation study에서 드디어 보여준다. 먼저 Table 6의 (a),(b)에서 masking 비율에 따른 영향을 보여준다.
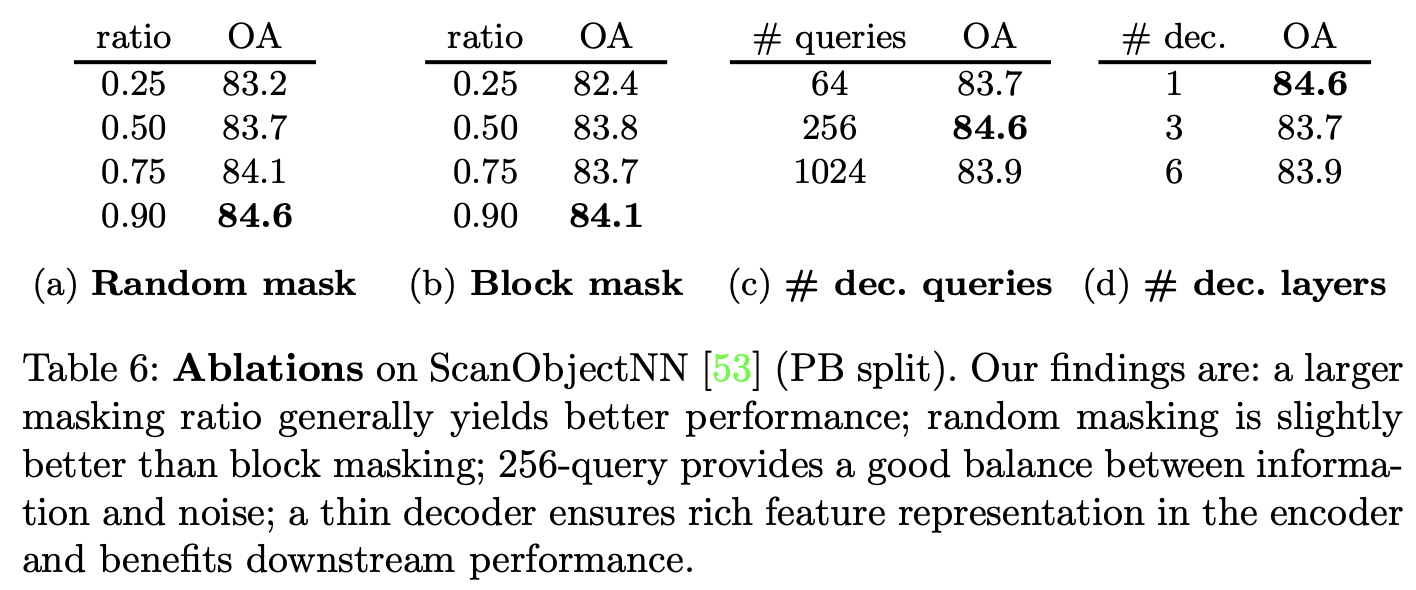
전반적으로 random masking을 하든 block masking을 하든 높은 masking ratio을 설정할수록 더 좋은 성능을 보이는 것을 알 수 있다. 아마 높은 비율로 masking을 하면 더 어렵고 의미있는 정보를 가지도록 pretraining이 되는 것 같다. 또 masking할 때 어떤 masking ratio를 설정하든 random masking이 block masking보다 전체적으로 좋은 성능을 보이는 경향성이 있다. 따라서 저자는 random masking을 90%의 masking ratio로 설정했다고 한다. 참고로 random masking과 block masking이 각각 무엇인지는 아래 그림을 통해 이해할 수 있을 것이다. 말그대로 masking하는 형태를 의미한다.

Table 6의 (c),(d)의 경우 pretraining decoder의 구조에 대한 ablation이다. decoder의 query 수는 classification해야하는 real points와 fake points 수의 비율에 영향을 미칠텐데 query를 256개로 할 때 가장 좋은 결과를 보인다. query가 너무 많으면 noise가 많이 포함될 수 있고 또 너무 적으면 학습할 때 충분한 정보를 얻지 못할 수 있기 때문인 것 같다.
또 decoder의 layer를 1로 했을 때 가장 좋은 결과를 보였다. 저자는 encoder에서 feature encoding만 하고 decoder에서는 pretraining objective로 encoding된 features를 잘 projection하기만을 원했고 이러한 각 역할이 balance하지 않으면 model performance를 해칠 수 있다고 한다. single-layer decoder에서도 충분히 point discrimination task를 잘 수행할 수 있다고 판단했기 때문에 따라서 decoder의 layer를 1로 설정했다.
Conclusion
본 논문에서는 discriminative masked point cloud pretraining framework를 제시했다. 기존의 다른 transformer기반 sota model(point-BERT)보다 빠르게 pretraining을 할 수 있었고 더 좋은 성능을 낼 수 있었다는 것이 장점으로 보인다. 제안하는 MaskPoint에서는 occupancy value(0,1)를 통해 point cloud를 표현하여 간단하지만 효과적으로 binary pretraining objective function(focal loss)를 적용할 수 있었다. 여러 downstream task에서 실험을 통해 그 효과를 증명했고 object detection에서도 기존 sota방법론보다 더 좋은 성능을 보일 수 있었다. 저자는 이후에 point cloud에서 mask기반의 self-supervised learning에 대해 연구할 계획이라고 하며 마친다.
안녕하세요 ! 좋은 리뷰 감사합니다.
transformer decoder에서 fake query라는 것을 샘플링하는 이유가 무엇인가요 ..? 마스킹되지 않은 전체 3차원 공간에서 포인트간의 관계를 파악하기 위함이라고 이해를 했는데 설명 중에 “object의 surface에 가까운 point들이 샘플링되는데 이러한 포인트들은 실제 대상 object에 존재하지만 label이 fake이기 때문에 훈련에 어려움을 준다” 라고 말씀을 하셔서 잘 매칭이 되지 않아 질문 드립니다.
댓글 감사합니다.
우선 fake query를 sampling하는 것은 autoencoder를 이해해야할 것 같은데요, real query와 fake query를 sampling하고 encoder를 통해 real query의 표현특성을 학습하고 decoder에서 real과 query를 구별하게됩니다. 간단히 예를 들자면 위조지폐를 판별하기 위해 실제 지폐와 위조 지폐를 샘플링하여 decoder에서 입력된 지폐가 실제 지폐인지 위조 지폐인지를 판별한다고 이해하시면 도움이 될 것 같습니다.
뒤에 매칭이 되지 않는다고 한 설명은 fake query를 sampling할 때 3d space전체에서 sampling하게 되는데 이때 object surface의 points들을 sampling하면 사실 이 point들은 real인데 fake로 labeling된다는 뜻입니다.
안녕하세요. 좋은 리뷰 감사합니다.
이 분야에 대해서 이해도가 낮지만 그래도 논문에서 제시하는 아이디어가 참신하다는 느낌을 받았는데요. 분야에 대해서 이해도가 낮아 이해하기 어려운 부분이 있었습니다. point sampling variance 인데요.
“object의 실제 3d 모양은 continuous한 surface를 가지지만, point cloud는 연속적이지 않고 discrete하게 sampling된다. 예를 들어 point cloud 2개를 sampling하여 하나를 gt, 다른 하나를 model의 예측으로 표시한다고 가정해보았을 때 두 point cloud집합 모두 object의 동일한 geometric shape을 반영하지만, 두 point cloud set 사이의 Chamfer distance(두 point cloud set간의 shape 차이를 측정하는데 사용)는 0이 아니게될 것이다. 아래 그림을 보면 이해가 수월할 것 같다. 이 경우에 loss를 줄이는 방향으로 학습하게 되면(chamfer distance를 0으로) 첫 번째 point cloud set과 비슷해지도록 예측을 생성하게 될텐데 이 방식은 실제 object의 분포 중 한 표본을 따라 가는 것이기 때문에 불필요하게 어렵게 최적화하는 문제가 될 수 있다고 한다. ”
라고 하셨는데 point sampling variance라는 것 때문에 최적화가 힘들다는 문제가 발생한다는 것은 이해하였는데 정확히 이것이 무엇인지 잘 이해가 안됩니다. point sampling variance에 대해서 조금 더 쉽게 예를 들어서 설명해주실 수 있을까요?
댓글 감사합니다.
저도 self-supervised learning 논문은 처음 보는거라 이해도가 높지는 않네요. 정리하자면 point sampling variance에 대해 이해가 필요하다고 하신 거 같은데 experiment바로 위에 있는 그림을 참고하시면 이해가 수월할 것 같네요. original과 recon 이미지를 참고하면 좋을 것 같은데, sampling한 point가 모두 동일한 물체의 shape을 반영하고 있지만 완전히 일치하는 point를 sampling하지는 않다는 것이 point sampling variance 말 그대로이고, 만약 이 차이를 줄이기 위해 최적화를 하는 것은 이미 물체의 shape을 반영하고 있는 point의 특정 분포 중 하나를 단순히 따라 가려고 하는 것이기 때문에 의미없다고 주장하고 있습니다.