서론
해당 논문이 발표된 2015년도에도 DNN을 통한 이미지 인식, 특히 분류(classification)는 많은 데이터셋에서 인간 수준 혹은 그 이상의 성능을 달성했다고 평가됩니다. 그러나 인간과 컴퓨터간의 차이는 여전히 존재하는데요, 예를 들어 인간의 경우 구분할 수 없을 정도의 작은 노이즈를 통해 DNN을 완벽하게 속일 수 있습니다. 이러한 접근법의 예시는 2015년 ICLR에 발표된 이안 굿펠로우의 논문 Explaining and Harnessing Adversarial Examples에 판다그림으로도 유명합니다. 사람이 구분하지 못하는 차이로 인해 판다로 옳게 예측했던 모델이 동일한 컨텐츠를 긴팔원숭이라고 예측하게 되는데, 이러한 예시를 통해 아직 컴퓨터와 인간의 비전이 동일하게 작동하지는 않음을 확인할 수 있습니다.

이러한 반례 중 하나로 해당 논문은 overconfidence 문제에 대해 밝힙니다. overconfidence란, 실제로는 의미가 없는 컨텐츠, 즉 인간의 입장에서는 인식할 수 없는 이미지에서 DNN이 패턴을 인식하여 특정 클래스라고 높은 확률로 예측하는 현상입니다. 논문에서는 모델을 속일 수 있는 의미가 없는 패턴 (이하, evolved image)을 생성하여 DNN모델이 쉽게 속는 현상을 입증합니다. 아래가 논문에서 사용한 evolved image의 예시입니다.

방법
논문은 실험을 위한 DNN 모델로 딥러닝 프레임워크 중 하나인 Caffe 가 제공하는 AlexNet과 LeNet 아키텍쳐를 사용했습니다. 해당 아키텍쳐의 선정 이유는 당시에 가장 많이 사용되었다고 하네요. 또한 데이터셋으로는 ILSVRC 2012 ImageNet과 MNIST 데이터셋을 이용했습니다. ImageNet 데이터셋의 실험을 위해서는 AlexNet, MNIST 데이터셋의 실험을 위해서는 LeNet을 사용했다고 하네요. 다음으로 evolved image의 생성 방식은 아래 Figure2와 같습니다. 다윈 진화론에서 영감을 받은 evolutionary algorithms (EAs)를 통해 생성했다고 하는데요, 해당 알고리즘은 특정 이미지(논문에서는 organisms라고 표현합니다) 집단을 갖고있습니다. 이 집단에서 반복적으로 데이터를 선택(Selection)하고 해당 데이터에 다양한 변동을 가합니다. 이후 DNN을 통해 평가했을 때 입력된 label로 예측될 확률이 가장 높은 이미지를 선택하여 evolved image가 됩니다. 이때, DNN을 통한 평가과정이 fitness function입니다. 위가 일반적인 EAs의 작동 과정이며, 해당 논문에서는 MAP-Elites[6]라는 기존 방법론을 통해 evolved image를 생성했다고 합니다.
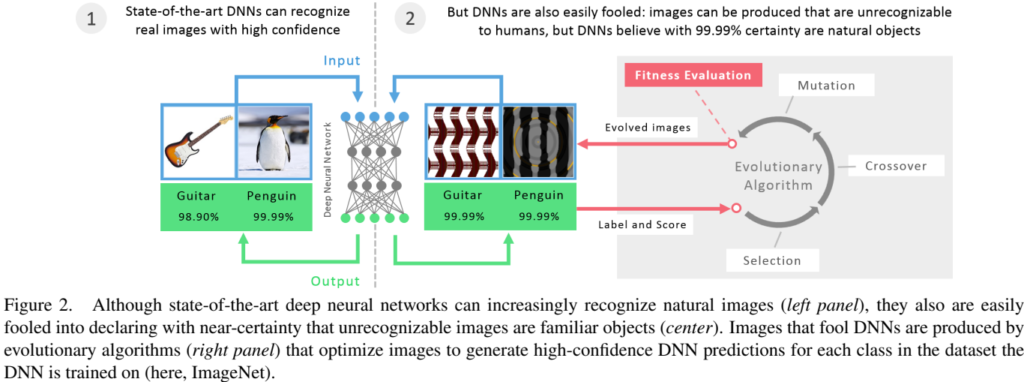
본 논문에서 생성한 evoloved image는 크게 두 타입으로 나뉘는데, DNN만 이해할 수 있는 direct encoding 방식으로 생성한 이미지와 DNN과 사람이 모두 이해할 수 있는, 즉, 일관된 표현과 규칙성을 갖도록하는 Indirectly encoding 방식으로 생성한 이미지입니다. direct encoding이란 EAs로 생성된 이미지를 직접 이미지 사이즈로 표현한 것이며 indirectly encoding은 별도의 compositional pattern-producing network (CPPN, wiki) 모델을 거쳐 생성한 이미지이며 PicBreeder.org[25] 아래는사이트에서 생성한 indirectly encoded image의 예시입니다. direct encoded image의 예시는 figure1의 1행, 2행과 같습니다.

결과
MNIST

위는 두가지 타입으로 생성된 evolved image의 예시이며 각 데이터에 대해 99.99%의 신뢰도로 예측을 함을 확인하였다. 즉 모델이 해당 데이터와 손글씨를 구별하지 못함을 알 수 있습니다. 또한 우측의 Indirectly Encoding 방식으로 생성된 이미지를 통해 해당 현상에 대해 직관적으로 분석할 수 있는데, 예를 들어 1로 예측한 evolved image는 수직 패턴이, 2로 예측된 evolved image는 수평 패턴이 반복적으로 발생하는것으로 보아 네트워크가 실제 데이터를 통해 학습한 특정 패턴이 overconfidence의 원인이 됨을 알 수 있습니다.
ImageNet
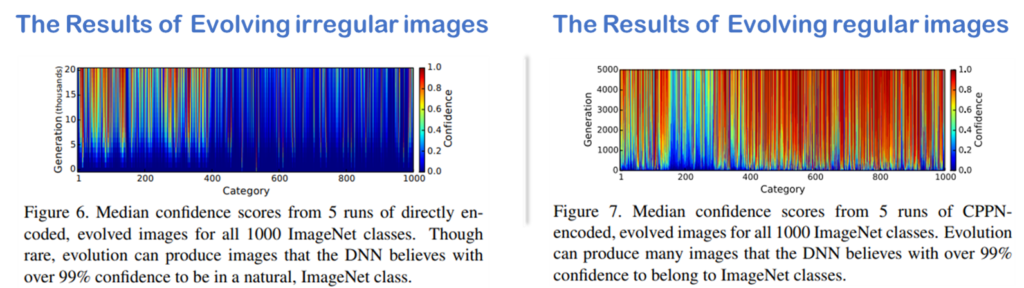
overfitting이 쉬운 MNIST와 다르게 ImageNet 실험은 조금 더 어려웠다고 하는데요, 특히 directly encoded EA를 통한 실험은 비교적 뚜렷한 overconfidence 현상을 보이지 않았다고 합니다. ImageNet 실험에 사용된 evolved image의 예시는 위의 figure1과 같으며 아래는 그 결과입니다. y 축이 confidence score이며 x축은 각 class를 의미합니다. directly encoded된 irrigular 패턴의 evolved image(좌측)의 경우에는 45개의 클래스에서만 99% 이상의 overconfidence가 발생할 수 있었습니다. 반면 indirect encoding을 이용해 생성한 evolved image(우측)의 경우 대부분의 클래스에 99.99% 이상의 overconfidence를 발생하는 evolved image가 존재함을 확인할 수 있습니다. 해당 실험에서 evolving regular images를 통해 네트워크가 학습한 대상의 차별적 특징을 확인할 수 있는데, 예를 들어 figure1의 3행 2열의 불가사리(starfish)를 보면 물을 대표하는 파란색과 불가사리의 대표색인 오랜지색이 동시에 패턴으로 나타남을 확인할 수 있습니다.
overconfidence 현상을 더 뜯어보기 위해 해석 가능한 evolving regular image를 통해 추가적인 실험을 진행하였는데요, 가장 먼저 패턴 반복에 의한 인식 확신 향상을 보았습니다. CPPNs은 패턴 생성 네트워크로, 특정한 패턴을 규칙성 있게 생성합니다. 따라서 evolving regular image의 예시들을 보면 특정 패턴이 반복되는 것을 확인할 수 있습니다. 이러한 반복을 제거하면 모델의 예측 confidence가 어떻게 변화하는지 확인한 결과는 다음과 같습니다.

이 결과를 통해 알수있는 내용은 다음과 같습니다. 먼저 반복되는 패턴의 일부를 제거하면 confidence의 하락이 발생하는데, 이는 각 패턴이 모델의 confidence에 영향을 미친다는 뜻 입니다. 즉 이미지의 특정 feature(예를 들어 여우의 귀)가 반복되는것이 모델의 확신도 향상에 긍정적인 영향을 준다는 것인데, 이는 DNN이 객체의 글로벌 구조보다 낮은 수준과 중간 수준의 특징을 학습하는 경향이 있음을 의미한다고 합니다. DNN이 전역 구조를 제대로 학습하고 있었다면, 많은 쌍의 동일 패턴 (예를 들어 반복되는 여우 귀)과 같은 자연적인 이미지에 거의 나타나지 않는 하위 구성 요소의 반복을 포함하는 경우 더 낮은 DNN 신뢰도 점수를 받아야 하기 때문입니다.
또한 Figure 7에서 low confidence를 보인 클래스는 개와 고양이 인데, 이는 해당 클래스가 다른 클래스에 비해 데이터셋 갯수가 많기 때문이라고 분석합니다. 즉, overfitting이 덜 될수록 모델을 속이기 어려워진다는 것입니다.
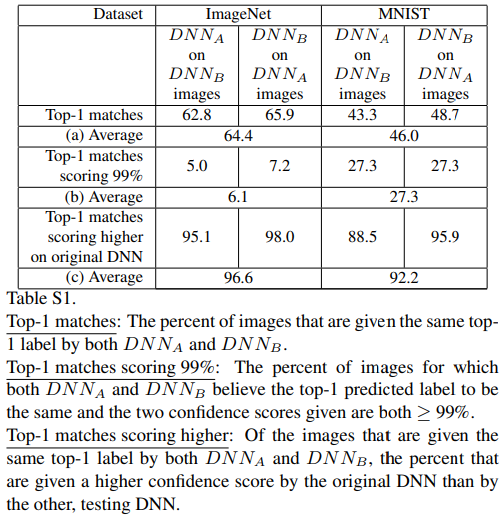
정리하면 DNN overconfidence현상이 나타나거나 잘 속는 이유는 모델이 학습시 데이터의 전반적인 정보를 학습하는 것이 아니라 차별적인 패턴을 위주로 학습하기 때문입니다. 본 논문이 제시한 두번째 의문은 그렇다면 하나의 DNN을 속인 특정한 패턴이 다른 DNN을 속일 수 있는가, 즉, 모든 DNN이 특정 클래스에 대해 유사한 패턴을 학습하는 가? 입니다. 이를 실험하기 위해 DNN(A)로 생성한 CPPN-encoded image를 DNN(B)의 입력으로 하여 실험을 진행했을때 결과는 아래와 같습니다. 이때 두 네트워크 A, B는 랜덤 초기화 파라미터만 다르며 논문에서는 결과를 통해 서로 다른 두 네트워크 A, B가 일반화된 패턴을 학습한다고 언급합니다. 표의 결과는 다음과 같습니다. 실제로 꽤 많은 evolved image가 두 네트워크에서 동일한 label 로 예측됩니다. ImageNet은 약 60%, MNIST에서는 약 40%가 그렇습니다. 그리고 전체 이미지의 약 5%는 ImageNet에서 A네트워크와 B 네트워크의 예측값이 동일하며, 그 확신도도 99% 이상입니다. MNIST는 약 27% 대로 더 많은 데이터가 이러한 예시에 포함됩니다. ImageNet에서는 두 네트워크에 동일한 Top1 prediction을 갖는 envolved image 중 약 95% 이상이 원본 네트워크에서 예측한 확신도보다 높은 확신도를 갖으며 MNIST도 88% 이상의 envolved image에서 같은 현상을 보임을 확인할 수 있습니다. 두 결과가 데이터셋의 크기, 클래스의 갯수 등에 의해 차이점이 있지만, 결과적으로 A네트워크와 B 네트워크가 특정 입력에 대해 공유하는 예측을 함을 확인할 수 있습니다.
본 논문을 통해 우리는 DNN이 일반적으로 데이터의 차별적인 특징을 학습하며 이로인해 overconfidence 현상이 발생할 수 있음을 알 수 있습니다. 조금 더 이미지의 전반적인 정보를 인식하는 다른 네트워크, 예를 들어 2017년에 발표된 transformer 등 에서는 해당 문제를 해결할 수 있을지가 궁금하네요. 이상입니다.
참조
[6] A. Cully, J. Clune, and J.-B. Mouret. Robots that can adapt like natural animals. arXiv preprint arXiv:1407.3501, 2014. 2
[25] J. Secretan, N. Beato, D. B. D Ambrosio, A. Rodriguez, A. Campbell, and K. O. Stanley. Picbreeder: evolving pictures collaboratively online. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pages 1759–1768. ACM, 2008.
안녕하세요. 황유진 연구원님.
좋은 리뷰 감사합니다.
어렴풋이 딥러닝 모델에 이러한 문제가 있음은 알고 있었는데, 본격적으로 살펴볼 수 있는 기회가 된 리뷰였던 것 같습니다.
리뷰를 읽고 호기심이 생기는 부분이 있는데요.
1. 이 논문에서 분석한 것은 CNN, RNN 등이 아닌 완전히 FC 계층으로만 이루어진 DNN 뿐인건가요?
2. 마지막 부분에서 DNN(A)에서 학습된 CPPN이 생성한 패턴이 DNN(B)에서도 동일한 label로 예측되고, ImageNet에서 이것이 60%라는 것이, CPPN에서 만든 패턴이 DNN(B)에서도 똑같이 잘못 분류될 확률이 60%라는 것으로 이해하였는데, 그러면 나머지 40%는 오분류를 유발하기는 하나 다른 클래스로 오분류되는 것인지, 혹은 아예 결과에 영향이 없는 것인지 궁굼합니다!
감사합니다.
안녕하세요 백지오 연구원님
댓글 감사합니다
1. 우선 본 논문의 분석에 사용된 네트워크는 AlexNet이며 MNIST 실험의 경우 LeNet을 사용했다고 합니다.
2. 두 번째에 대한 답변으로는 다음과 같습니다. 우선 해당 실험은 DNN이 데이터롤 통해 학습한 패턴이 해당 네트워크에서만 적용되는지, 일반적으로 동일한 데이터셋을 통해 학습했을 때 학습하게 되는 패턴인지를 검토하는 실험이였습니다. 즉 DNN(A)+CPPN으로 생성한 패턴 P가 DNN(A)로 ‘사과’라고 예측 될 때, 이 패턴이 일반적인(공유될 수 있는) 정보라면 DNN(B)에 P를 입력해도 ‘사과’라고 예측할 것입니다. 본 리뷰의 S1 테이블에 60%는 어떠한 패턴 P에 대해서 DNN(A)와 DNN(B)가 동일하게 ‘사과’라고 예측한 정도를 말하며, 40%는 오분류가 아니라 어떠한 네트워크가 학습한 일관성이 없는 패턴이라고 이해해주시면 될 것 같습니다.
황유진 연구원님, 좋은 리뷰 감사합니다.
사람은 기본적으로 배경지식을 활용해 시작 정보 처리에 이용하지만, DNN 기반 모델들은 그렇지 못하고 크게 의미가 없는 부분까지 학습해버려서 overconfidence 문제가 발생하네요. DNN의 가장 큰 한계점 중 하나인 것 같습니다.
혹시 이런 문제점을 보완하는, 다시말해서 이미지 데이터에서 의미있는 부분만 선별적으로 주목해 학습에 활용하는 방법론이 요즘에는 있을까요? 꽤 예전 방법론이고 DNN의 고질적인 문제라 이를 보완하는 방법론이 나왔을것 같기도 한데 궁금합니다.
또한 2015년의 DNN을 이용한 이미지 인식이 인간 이상의 성능을 달성했다고 하는 것은 ResNet을 지칭하는것으로 보이는데, 본 논문에서의 DNN은 CNN을 포괄하는 개념으로 생각하면 될까요?
안녕하세요 허재연 연구원님
댓글 감사합니다
우선 논문에서 제시한 해결책은 데이터셋의 양을 늘리라는 것 입니다. 리뷰를 쓰기 전, 해당 논문의 사이태이션 논문리스트를 간단히 보았으나 네트워크의 특성을 분류하기 위한 다른 접근법에 관련한 논문은 보지 못했습니다. 다시 한번 찾게 된다면 공유 드리겠습니다.
일반적으로 DNN은 CNN을 포함하며 해당 논문에서 분석으로 사용한 논문인 AlexNet은 대표적인 CNN 프레임워크 중 하나입니다.
마지막으로 해당 논문에서 학습한 패턴을 통해 DNN이 학습 데이터의 차별적인 패턴을 학습함을 확인할 수 있었습니다. 이는 의미가 없는 부분이라기 보다, 국소적인 정보에 집중해서 학습하여 발생하는 문제로 이해하는 것이 더 좋을 듯 합니다.
안녕하세요 황유진 연구원님
2015년 논문이라 기대하면서 들어왔는데 역시군요.. 연구 잘하네요. 가장 인상깊었던 건 모델이 학습하면서 ‘일반적인 패턴을 파악한다’ 라는게 모델 의존적이지 않다는 점입니다. 그런데 DNN_A , DNN_B에 대해서만 실험을 진행했다고 하는데 이게 AlexNet이랑 LeNet인가요? 모델에 대한 자세한 정보가 있을 지 궁금합니다.
이번에 리뷰해주신 논문은 2015년에 발표된만큼… AlexNet, LeNet에 대한 연구만 리포팅 되어 있어서 아쉬움이 있는데요. 훨씬 복잡하고 해석하기 어려운 최신 연구에서는 이런 문제를 고찰한 연구가 있으면 다음 리뷰로 진행해주실 의향이 있으실지요 ㅎㅎ 아주 유익해서 기대가 되네요 ㅎㅎ 좋은 리뷰 감사합니다 : )
안녕하세요 홍주영 연구원님
댓글 감사합니다
본 리뷰의 S1표에 사용된 두 모델(DNN(A), DNN(B))은 동일한 프레임워크이며 렌덤 초기화 파라미터만 다릅니다.(MNIST는 LeNet, ImageNet은 AlexNet입니다!) 저도 최신 정보를 보고싶어서 리뷰를 쓰기 전 해당 논문의 사이테이션 리스트를 보았을 때, 급하게 보아서 그런지 발견하지 못했습니다 ㅠㅠ
혹시라도 찾게되면 바로 리뷰 진행해보겠습니다 감사합니다~
안녕하세요 황유진 연구원님 좋은 리뷰 감사합니다.
리뷰를 읽고 DNN모델은 특정 클래스에 대해 일반적인 패턴을 학습하며 이러한 경향성이 네트워크가 달라져도 유사하게 나타난다고 이해하였습니다. 논문에 사용된 DNN_A와 DNN_B는 LeNet과 AlexNet으로 알고 있는데 혹시 이 두 네트워크 이외에 다른 모델로 진행된 실험이 있는지, 있다면 또한 비슷한 결과를 내는지도 궁금합니다.
안녕하세요 천혜원 연구원님
댓글 감사합니다
우선 본 리뷰는 DNN모델이 학습 데이터에 대해 일반적인 패턴이 아닌 차별성이 있는 국소적인 패턴을 학습함을 실험으로 보인 것이며, 데이터를 통해 학습한 패턴이 특정 네트워크에 한정되는 것이 아닌, 일반성있게 학습되는 정보임을 S1 실험을 통해 다시 한번 보였습니다.
또한, DNN(A)와 DNN(B)은 동일한 네트워크 프레임이며, 초기화 파라미터만 다릅니다. 두 네트워크 이외의 다른 실험은 아쉽게 없네요..